S
CHEMA
M
ATCHING
AND
M
APPING
-
BASED
D
ATA
I
NTEGRATION
Ph.d. Thesis by Do Hong Hai
August 2005
Interdisciplinary Center for Bioinformatics and Department of Computer Science University of Leipzig
CHAPTER 0
T
ABLE
OF
C
ONTENTS
L
ISTOFF
IGURES. . . V
L
ISTOFT
ABLES. . . IX
A
CKNOWLEDGEMENTS. . . XIII
A
BSTRACT. . . XV
P
ARTI. I
NTRODUCTIONC
HAPTER1. S
CHEMAM
ATCHING. . . .3
1.1 Motivation . . . 3
1.2 Applications of Schema Matching . . . 5
1.3 Semantic Heterogeneity . . . 7
C
HAPTER2. P
ROBLEMD
EFINITION. . . .11
2.1 Schemas . . . 11
2.2 Input Information . . . 12
2.3 Output Information . . . 13
2.4 Architecture for Generic Schema Matching . . . 14
C
HAPTER3. O
PENI
SSUESANDC
ONTRIBUTIONS. . . .17
3.1 State of the Art and Open Issues . . . 17
3.2 Contributions . . . 20
3.3 Outline . . . 22
P
ARTII. S
CHEMAM
ATCHINGA
PPROACHESC
HAPTER4. A
PPROACHC
LASSIFICATION. . . .27
4.2 Schema-based Matching . . . 28 4.3 Instance-based Matching . . . 32 4.4 Reuse-oriented Matching . . . 34 4.5 Combination Approaches . . . 36 4.6 Match Cardinality . . . 37 4.7 Summary . . . 38
C
HAPTER5. T
HEC
OMA ANDC
OMA++ A
PPROACHES. . . .39
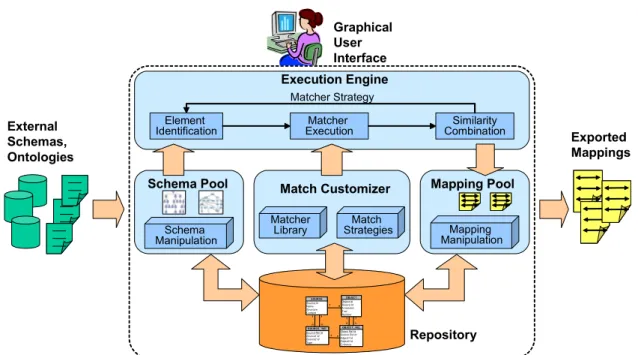
5.1 System Architecture . . . 40
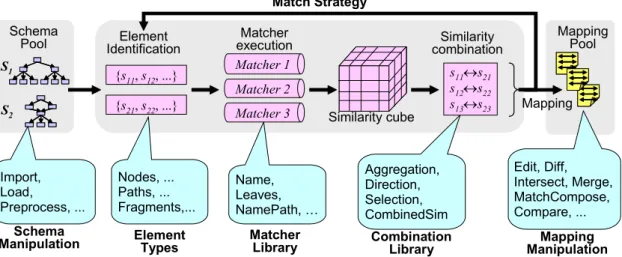
5.2 Match Processing . . . 42
5.3 Schema Import and Representation . . . 44
5.4 Matcher Library . . . 47
5.5 Mapping Representation and Manipulation . . . 50
5.6 Implementation and Use . . . 52
5.7 Summary . . . 55
C
HAPTER6. R
EUSEOFP
REVIOUSM
ATCHR
ESULTS. . . .57
6.1 Reuse Strategies . . . 57
6.2 Schema Similarity . . . 59
6.3 The MatchCompose Operation . . . 60
6.4 The Reuse Matcher . . . 62
6.5 Summary . . . 63
C
HAPTER7. M
ATCHERC
ONSTRUCTION. . . .65
7.1 CombineMatcher . . . 65
7.2 Determination of Elements/Constituents . . . 67
7.3 Combination of Similarity Values . . . 67
7.4 Configuration of Combined Matchers . . . 70
7.5 Summary . . . 72
C
HAPTER8. M
ATCHS
TRATEGIES. . . .73
8.1 Refinement of Match Results . . . 73
8.2 Context-dependent Match Strategies . . . 75
8.3 Fragment-based Match Strategies . . . 77
8.4 Summary . . . 79
C
HAPTER9. O
THERP
ROTOTYPESANDC
OMPARISON. . . .81
9.1 Schema-based Prototypes . . . 81
9.2 Instance-based Prototypes . . . 85
9.3 Ontology Matching Prototypes . . . 88
9.4 Prototype Comparison . . . 90
9.5 Summary . . . 95
P
ARTIII. S
CHEMAM
ATCHINGE
VALUATIONC
HAPTER10. E
VALUATIONC
RITERIA. . . .99
10.1 Input: Test Problems and Auxiliary Information . . . 100
10.2 Output: Match Result . . . 100
TA B L E O F CO N T E N T S I I I
10.4 Methodology: What Effort is Measured and How . . . 103
10.5 Runtime Performance . . . 104
10.6 Summary . . . 105
C
HAPTER11. C
OMA++ E
VALUATION: S
CHEMAM
ATCHING. . . .107
11.1 Test Schemas and Series . . . 107
11.2 Experiment Design . . . 108
11.3 Combination Strategies . . . 110
11.4 Match Strategies and Matchers . . . 115
11.5 Reuse Strategies . . . 120
11.6 Summary . . . 127
C
HAPTER12. C
OMA++ E
VALUATION: O
NTOLOGYM
ATCHING. . . .131
12.1 Test Ontologies and Series . . . 131
12.2 Experiment Design . . . 133
12.3 Quality and Execution Time . . . 135
12.4 Summary . . . 139
C
HAPTER13. O
THERE
VALUATIONSANDC
OMPARISON. . . .141
13.1 Individual Evaluations . . . 141
13.2 Comparative Evaluations . . . 144
13.3 Evaluation Comparison . . . 147
13.4 Contest-based Comparison . . . 148
13.5 Summary . . . 150
P
ARTIV. M
APPING-
BASEDD
ATAI
NTEGRATIONC
HAPTER14. D
ATAI
NTEGRATIONINB
IOINFORMATICS. . . .155
14.1 Molecular-biological Data . . . 155
14.2 Integration Requirements . . . 157
14.3 State of the Art . . . 158
C
HAPTER15. T
HEG
ENMAPPERA
PPROACH. . . .161
15.1 Overview . . . 162
15.2 The Generic Annotation Model . . . 163
15.3 Data Import . . . 164
15.4 View Generation . . . 165
15.5 Implementation and Use . . . 167
15.6 Summary . . . 169
C
HAPTER16. T
HEH
YBRIDI
NTEGRATIONA
PPROACH. . . .171
16.1 Overview . . . 171 16.2 Mapping Management . . . 173 16.3 Query Processing . . . 175 16.4 Summary . . . 178
P
ARTV. C
LOSINGC
HAPTER17. C
ONCLUSIONS. . . .181
17.1 Contributions . . . 181
17.2 Future Directions . . . 182
C
HAPTER18. A
PPENDIX. . . .185
18.1 New Features in Coma++ . . . 185
18.2 GUI Design in Coma++ . . . 186
18.3 Mapping Operators in Coma++ . . . 191
CHAPTER 0
L
IST
OF
F
IGURES
Figure 1.1 Schema matching for data integration . . . .4
Figure 2.1 Sample schemas for purchase order . . . .12
Figure 2.2 High-level architecture for generic match implementation . . . .14
Figure 4.1 Classification of match approaches . . . .28
Figure 5.1 Coma++ system architecture . . . .40
Figure 5.2 External and internal schema representation . . . .42
Figure 5.3 Match processing in Coma++ . . . .43
Figure 5.4 Match processing example . . . .44
Figure 5.5 Unification of alternative designs . . . .46
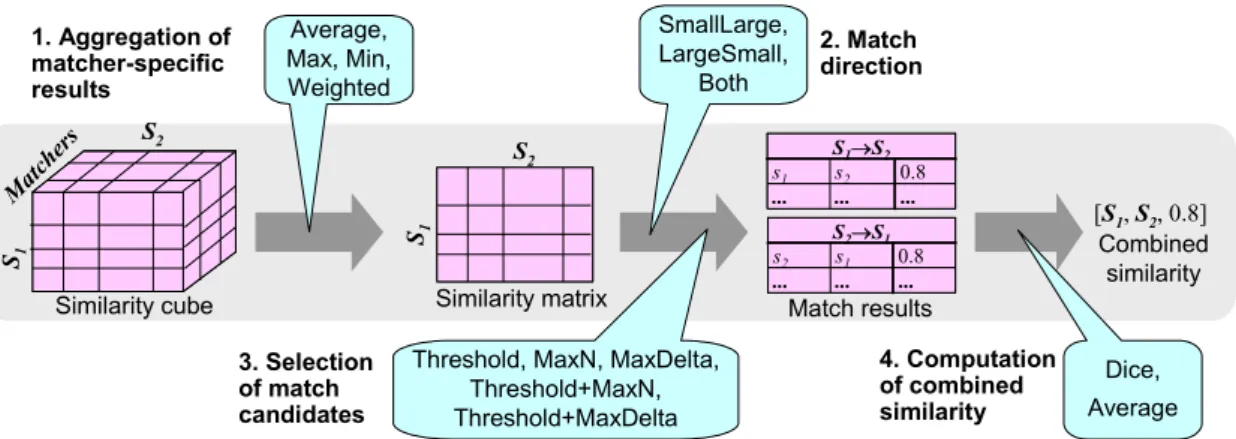
Figure 5.6 Distribution of Coma++ source code (in lines of code and percents) .52 Figure 5.7 Configuration of matchers . . . .53
Figure 5.8 Schemas loaded from the Repository for matching . . . .54
Figure 5.9 Match results in the Mapping Pool . . . .54
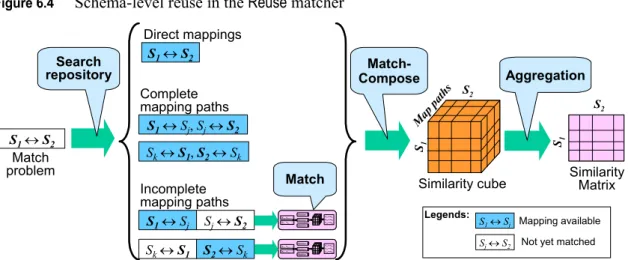
Figure 6.1 Graph of schemas and mappings for reuse . . . .58
Figure 6.2 The MatchCompose operation . . . .61
Figure 6.3 MatchCompose with undesirable m:n matches . . . .61
Figure 6.4 Schema-level reuse in the Reuse matcher . . . .62
Figure 7.1 Pseudo-code of CombineMatcher . . . .66
Figure 7.2 Combination of match results . . . .68
Figure 7.3 Computing combined similarity in the Name matcher . . . .71
Figure 8.1 CombineMatcher extended with the Refine method . . . .74
Figure 8.2 A simple match strategy . . . .74
Figure 8.3 Combining node and path matching in FilteredContext . . . .76
Figure 8.4 Fragment-based match approach . . . .78
Figure 8.5 Implementation of the fragment-based match algorithm . . . .79
Figure 10.1 Schema examples for a simple match task . . . .101
Figure 10.2 Comparing real and automatically derived correspondences . . . .102
Figure 10.3 Fmeasure and Overall as functions of Precision and Recall . . . .103
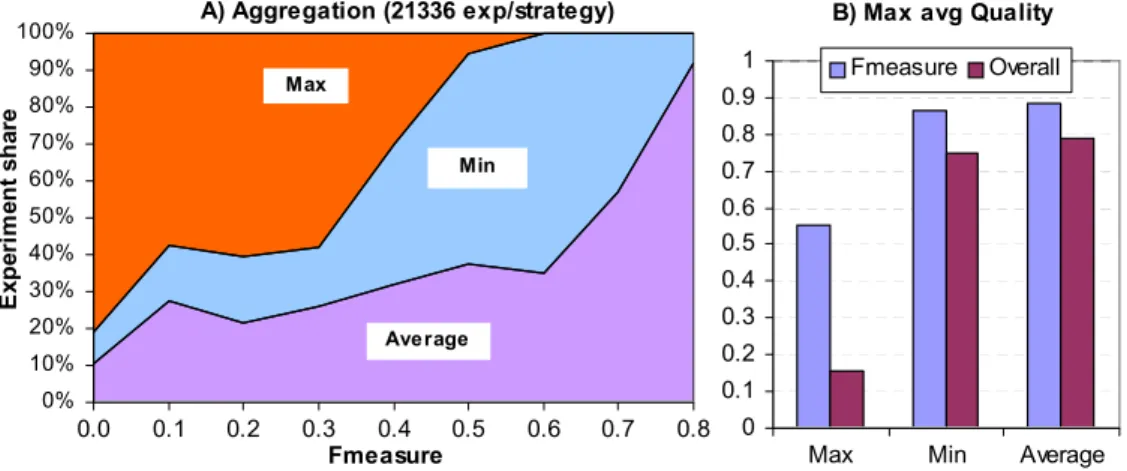
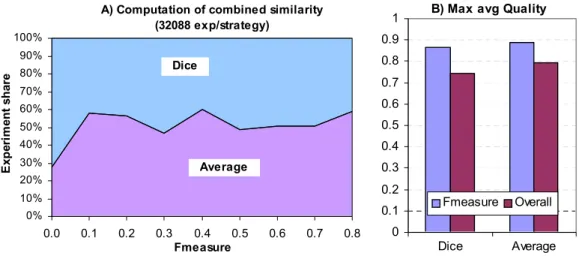
Figure 11.2 Best average quality and experiment distribution w.r.t Fmeasure . . 111
Figure 11.3 Experiment distribution and quality for aggregation . . . 112
Figure 11.4 Experiment distribution and quality for direction . . . 112
Figure 11.5 Experiment distribution and quality for selection . . . 113
Figure 11.6 Experiment distribution and quality for combined similarity . . . 114
Figure 11.7 Quality and execution times of context-based match strategies . . . . 116
Figure 11.8 Quality and execution times of fragment-based match strategies . . 117
Figure 11.9 Quality variation of AllContext and FilteredContext . . . 118
Figure 11.10 Matcher occurrence in 10 best matcher combinations . . . 119
Figure 11.11 Quality variation of Best, Default, All, and NamePath . . . 120
Figure 11.12 Graph of previous mappings and examples for mapping paths . . . 121
Figure 11.13 Quality for composition strategies . . . 123
Figure 11.14 Quality for mapping path lengths . . . 123
Figure 11.15 Quality for without and with a pivot schema . . . 124
Figure 11.16 Quality for top-K mapping paths . . . 125
Figure 11.17 Comparison of no-reuse and reuse matchers . . . 126
Figure 11.18 Execution times of the Reuse matcher . . . 127
Figure 12.1 Best task quality . . . 135
Figure 12.2 Quality variation of matcher combinations . . . 137
Figure 12.3 Quality of Best, Default, All, Name without/with Comment added . . 137
Figure 12.4 Quality and execution time for test series . . . 138
Figure 13.1 Match quality of Lsd [34] . . . 143
Figure 13.2 Match quality of SimilarityFlooding [93] . . . 144
Figure 13.3 Corpus-based (Augment) vs. Glue (Direct) and Mkb (Pivot) [92] . . . 145
Figure 13.4 Quality of single prototypes for contest tasks . . . 149
Figure 13.5 Average quality of single prototypes for test series . . . 150
Figure 14.1 Sample annotations for gene locus 353 from LocusLink . . . 156
Figure 14.2 Iterative analysis scenarios . . . 157
Figure 15.1 Genmapper architecture for annotation integration . . . 162
Figure 15.2 An annotation view for LocusLink genes . . . 162
Figure 15.3 The Generic Annotation Model . . . 163
Figure 15.4 Data parsing and import . . . 165
Figure 15.5 The algorithm for GenerateView . . . 167
Figure 15.6 Annotation query for Locuslink genes . . . 168
Figure 16.1 The hybrid integration approach and its components . . . 172
Figure 16.2 Schemas of the Mapping and ADM databases . . . 174
Figure 16.3 Query formulation on the automatically generated web interface . . . 176
Figure 16.4 Steps for creating the query plan . . . 177
Figure 18.1 Repository functionalities . . . 187
Figure 18.2 Workspace functionalities . . . 187
Figure 18.3 Match processing . . . 188
Figure 18.4 Configuration of matchers and match strategies . . . 189
Figure 18.5 Schema preprocessing . . . 189
LI S T O F FI G U R E S V I I
Figure 18.7 Step-by-step fragment-based matching . . . .191 Figure 18.8 Manual quality evaluation . . . .192
CHAPTER 0
L
IST
OF
T
ABLES
Table 4.1 Local match cardinalities . . . 37
Table 5.1 Implemented matchers in the Matcher Library . . . 48
Table 5.2 Operations on mappings . . . 50
Table 7.1 Examples for types of constituents/related elements . . . 67
Table 7.2 Construction of combined matchers . . . 71
Table 9.1 Characteristics of representative schema matching prototypes (1) . . . 91
Table 9.2 Characteristics of representative schema matching prototypes (2) . . . 93
Table 11.1 Characteristics of the test schemas . . . 107
Table 11.2 Statistics of the test series . . . 108
Table 11.3 Test configuration for combination strategies. . . 110
Table 11.4 Occurrence of combination strategies in the best experiments . . . 114
Table 11.5 Test configuration for match strategies . . . 116
Table 11.6 Test configuration for reuse . . . 122
Table 12.1 Characteristics of the test ontologies and match tasks . . . 132
Table 12.2 Statistics of the test series . . . 132
Table 12.3 Test configuration for ontology matching . . . 134
Table 13.1 Summary of selected evaluations. . . 147
Table 14.1 Data integration approaches and systems in bioinformatics . . . 158
Table 15.1 Definitions and examples for simple mapping operations . . . 166
CHAPTER 0
A
CKNOWLEDGEMENTS
First of all, I want to express my deepest gratitude to my advisor, Prof. Dr. Erhard Rahm, for his continuous and caring help, advice, and encouragement during the six years of my Ph.d. studies at the University of Leipzig. I thank him for being very patient with my questions and my progress, for the countless lessons on writing and presenting technical materials, on doing research in general, and also for the English lessons, even though he is not a language teacher.
I wish to thank my second and third reviewers, Dr. Philip A. Bernstein at Microsoft Research, Redmond, USA, and Prof. Dr. AnHai Doan at University of Illinois at Urbana-Champaign, USA, for their willingness to review my thesis and for their time and effort in doing this. Dr. Bernstein also provided very helpful comments on several of my papers.
I could not be able to finish my thesis without financial support from different scholar-ships and grants, especially, grant BIZ 6/1-1 of the DFG (Deutsche Forschungsgemein-schaft - German Research Foundation). Hence, I want to thank Prof. Dr. Erhard Rahm as well as Dr. Hans Binder and Prof. Dr. Markus Löffler at the Interdisciplinary Center for Bioinformatics, University of Leipzig, for their effort to organize and ensure my contin-uous funding so that I can fully focus on my work.
I am very grateful to all of my colleagues and friends in the Database Group of the Department of Computer Science and at the Interdisciplinary Center for Bioinformatics, University of Leipzig, for many helpful discussions, the pleasant working environment, and the many beautiful memories on our annual “workshop-vacations” in Zingst. I also want to thank Thomas Stöhr for his support in several industry projects we have done together in the first two years of my studies. I owe a very special thank to my long-term office-mate Toralf Kirsten for always being there to comment and support my work. I thank Sabine Massmann for her valuable contributions to the COMA++ system,
espe-cially, in developing the graphical user interface characterized in Section 18.2.
Special thanks go to the members of the Max Planck Institute for Evolutionary Anthro-pology, Leipzig, especially, Dr. Philipp Khaitovich and Björn Mützel, for helpful “bio-logical” comments on my implementation of the GENMAPPER system presented in
Chapter 15. Furthermore, I thank Dr. Thure Etzold and Ceara Rea at Lion BioScience, Cambridge, UK, for providing us with the SRS tool and supporting our development of
the hybrid data integration approach presented in Chapter 16. Last but not least, I thank Christine Körner for the implementation of the approach as part of her diploma thesis.
Leipzig, August 2005 Do Hong Hai
CHAPTER 0
A
BSTRACT
Schema matching aims at identifying semantic correspondences between elements of two schemas, e.g., database schemas, ontologies, and XML message formats. It is needed in many database applications, such as integration of web data sources, data warehouse loading and XML message mapping. In today's systems, schema matching is manual; a time-consuming, tedious, and error-prone process, which becomes increas-ingly impractical with a higher number of schemas and data sources to be dealt with. To reduce the amount of manual effort as much as possible, approaches to semi-automati-cally determine element correspondences are required.We start by surveying the existing approaches and prototypes for schema matching and explain their common features and applicability using a previously proposed taxonomy. We further identify the major criteria that influence the effectiveness of a match approach. We use these criteria to compare the evaluation of various recent prototypes and discuss the issues that need to be addressed in future evaluations. Besides helping us to develop and test our own system, the surveys of match approaches and of evaluations aim at guiding future implementations, so that they can be documented better, their result be more reproducible, and a comparison between different systems and approaches be easier.
Based on the insights about the state of the art, we have developed COMA (Combining
Matchers) and further extended it to COMA++, both representing generic and
customiz-able systems for semi-automatic schema matching. In particular, COMA++ offers a
plat-form for flexible combination of different match algorithms. It provides a large spectrum of individual matchers, including a novel approach reusing results from previous match operations, and various mechanisms to combine and refine matcher results. Based on this flexible infrastructure, match processing is supported as a workflow, allowing to divide and successively solve a match task in multiple stages. In particular, we implement spe-cific workflows (i.e., strategies) for context-dependent matching of schemas with shared elements and fragment-based matching of very large schemas.
With the flexibility to customize matchers and match strategies, COMA++ also represents
a platform for comparative evaluation of match approaches. In fact, we performed com-prehensive evaluations using real-world schemas found on the web and ontologies from a published ontology alignment contest. In particular, the E-business message standards involved in our evaluations are among the largest and most complex test schemas as compared to previous evaluations. COMA++ has shown high quality and fast execution
solu-tion for different domains. Especially, the quality of COMA++ in the ontology alignment
contest is comparable to that of the best performing participants. Due to the systematic evaluation, we obtain important insights on the performance of different match strategies and the impact of many factors, such as schema size, the choice of matchers and combi-nation strategies, and the reuse of previous match results. We believe that our insights can be of valuable help for the development and evaluation of further match algorithms. Building on the same idea of reusing previous match results, we have developed GEN
-MAPPER (Generic Mapper), a new approach for integrating heterogeneous web data
sources. It utilizes mappings between sources and utilizes correspondences between their objects, i.e., at the instance level. We focus on the bioinformatics domain with hundreds of publicly accessible, highly cross-referenced web data sources managing annotations and correspondences for various types of molecular-biological objects, such as genes and proteins. GENMAPPER explicitly captures existing relationships between objects to drive
data integration and combine annotation knowledge from different sources. A generic schema is used to uniformly represent object data and correspondences, making it easy to integrate new data sources and to update existing ones. To serve specific analysis needs, powerful operators are provided to derive tailored views from the generic data represen-tation. GENMAPPER has been successfully used for large-scale functional profiling of
P
A R TPART I
I
NTRODUCTION
The main theme of the dissertation is to study schema matching, the task of identifying semantic correspondences between metadata structures, such as database schemas, XML message formats, and ontologies. Solving such match problems is of key importance to service interoperability and data integration in numerous application domains, such as data warehousing, mediating over web-sources, and E-business.This introductory part consists of three chapters. In Chapter 1, we motivate the need for schema matching and discuss why it is a difficult task. In Chapter 2, we define the schema matching problem by elaborating on the notion of schemas, the input and output of a match operation, and discuss the architecture for a generic match system. Finally, we discuss in Chapter 3 the open issues in the state of the art of schema matching and give an overview about the main contributions of the dissertation.
C
H A P T E RCHAPTER 1
S
CHEMA
M
ATCHING
We start this chapter by introducing schema matching and illustrating it using a simple example. Section 1.2 then motivates the importance and pervasiveness of schema match-ing by showmatch-ing it as a fundamental step in several database applications. Section 1.3 dis-cusses how semantic heterogeneity of schemas makes schema matching a very hard problem, not only for manual, but also for automatic solution approaches.
1.1
Motivation
A schema is a structure of metadata describing how data, i.e., instances, can be stored, accessed, and interpreted by users and applications. Besides technical aspects related with the management of data, e.g., field formats and data types, schemas also address to some extent semantic aspects concerning the contents and meanings of data, such as allowable values, cardinality, integrity and referential constraints. So far, many schema languages have been developed for different application domains. Examples include the Structured Query Language (SQL) for relational schemas, the Document Type Defini-tion (DTD) and XML Schema DefiniDefini-tion (XSD) for XML document schemas, and the Web Ontology Language (OWL) for ontologies. Although exhibiting varying capabili-ties and expressiveness, they all contribute to the pervasive use of schemas in current data management and processing applications.
Schemas support declarative access to and manipulation of data. Thus they represents the prime interface for establishing interoperability between tools that depend on shared data. In fact, many applications, such as data warehousing, mediating between websites, data mining, and peer data management, integrate data from multiple sources to support comprehensive query and analysis capabilities. The process, generally termed as data integration, aims at providing a uniform and consistent view, the so-called global schema, over a set of autonomous and heterogeneous data sources, so that data residing in different sources can be accessed if it were in a single one. In practice, data integration is often done incrementally by starting with a simple global schema and adding new data sources when needed. The integration of a new data source into an existing global schema can be performed in two steps, a matching and a data transformation step. In the first step, the source schema is compared against the global schema to identify their sim-ilar and distinct elements. While the distinct elements and their instances can be taken over from the data source, the correspondences between the similar elements are needed
in the second step to generate queries for transforming their instances from the source schema into the global schema.
Figure 1.1 Schema matching for data integration
Customer • CID • Name • Address Client • Id • First • Last • Home • Phone S GS (old) S GS (new) A) Schema matching ... Hurley St. 2 Home ... 123 Phone ... Smith Last ... ... Kristen 1 First Id ... Hurley St. 2 Home ... 123 Phone ... Smith Last ... ... Kristen 1 First Id ... Hurley St. 2 Address ... ... ... 123 Kristen Smith 1 Phone Name CID ... Hurley St. 2 Address ... ... ... 123 Kristen Smith 1 Phone Name CID S-Client GS-Customer B) Data transformation Customer • CID • Name • Address • Phone Client • Id • First • Last • Home • Phone
INSERT INTO GS(CID, Name, Address, Phone) SELECT Id, Concat(First, Last), Home, Phone
FROM S
Figure 1.1 illustrates the two steps of data integration using a simple scenario, in which we want to integrate a new data source, S, to an existing global schema, GS. Both S and GS consist of one single table to store customer data, Client and Customer, respectively. As shown in Figure 1.1a (left), the comparison of S and GS unveils a number of corre-spondences between elements of the two schemas, such as Client↔Customer, Id↔CID, Home↔Address, First↔Name, and Last↔Name. In particular, both the First and Last columns in S map to the Name column in GS. An explanation for this 2:1 match relation-ship is that the formers contain the first and last name of a customer and constitute the full name represented by the latter. Furthermore, Phone in S is a unique element as it does not have a match counterpart in GS. While retaining the current elements, we may extend the global schema to cover new elements from the source schema, e.g., Phone, as shown in Figure 1.1a (right). Based on the identified correspondences, an SQL query can be generated to transform Client instances in S to Customer instances in GS as shown in Figure 1.1b. In particular, the values of the Id, Home, and Phone columns in S directly populate the CID, Address, and Phone columns, respectively, in GS, while the values of First and Last in S are concatenated to populate the Name column in the global schema. Identifying semantic correspondences between two schemas has been commonly referred to as schema matching [119, 36, 70]. In the example above, it is the key task to enable schema integration and data transformation to obtain an integrated database. In general, we observe a wide range of applications depending on semantic correspon-dences between schemas in order to ensure interoperability and support data exchange, such as database design, data warehousing, data mining, mediating between websites, message transformation in E-business, web site creation and management, application evolution, component-based development, etc. The pervasive nature of schema matching is further underlined by the large body of research work done in the corresponding domains, which have coined further terms to denote the schema matching task, such as ontology matching [35], ontology alignment [107], mapping discovery [108], and attribute matching [84].
1.2.AP P L I C A T I O N S O F SC H E M A MA T C H I N G 5
In current implementations, however, schema matching is still largely performed manu-ally by domain experts, at best supported by some graphical point-and-click interface. Obviously, manually specifying schema correspondences is a time-consuming, tedious, and error-prone process. In web-based applications and services, such a manual approach is a major limitation due to the rapidly increasing number of data sources, XML message and document schemas, and web service interfaces to be dealt with. Moreover, as systems become able to handle more complex databases and applications, their schemas become larger, further increasing the search space to be examined as well as the number of correspondences to be identified. Hence, approaches for automating the schema matching task as much as possible are badly needed to speed up the development and to simplify the maintenance and use of such applications.
1.2
Applications of Schema Matching
To motivate the importance of schema matching, we now look at some database applica-tions and illustrate how semantic correspondences are required.
Schema and Data Integration
Schema integration represents one of the most important motivation for schema match-ing work. It has been the focus of database research since the early 80s [4, 79, 122, 128], first in the context of database design and later increasingly in data integration applica-tions. The main objective is the construction of a unified schema from a set of indepen-dently developed schemas, the local schemas. Such a schema, also called the global schema, represents a semantically consistent view on a particular domain. In the context of Artificial Intelligence or the Semantic Web, schema integration corresponds to the problem of merging independently developed ontologies into a single one to construct an integrated knowledge bases [107, 70].
Since the schemas and ontologies are independently developed, they typically exhibit different structure and terminology. The integration process requires interschema rela-tionships, so that similar elements can be unified and dissimilar ones be merged under a coherent, integrated schema or view. The approaches developed so far mostly focus on resolving conflicts between two schemas, such as naming and structural conflicts, detected from given interschema relationships [4]. However, such correspondences, also known as attribute equivalences [79], object relations [122], or correspondence asser-tions [128], are typically assumed to be manually provided by users. Therefore, schema matching can support schema integration with the identification and characterization of such interschema relationships.
In addition to the schema integration task, instance data needs to be transformed from the local schemas to the global one. This is done either in advance to materialize a so-called data warehouse [22] for all analysis purposes or on-the-fly using a so-called mediator [136] for each query. In both cases, transforming data between two sources requires cor-respondences between their schemas for specifying transformation rules. Like for schema integration, the correspondences required for data transformation can be also identified with the help of schema matching.
E-Business
With the internet as a pervasive messaging medium, trading partners have more and more started to handle their business online. This comprises a variety of transactions,
such as exchanging product information, placing purchase orders, confirming and paying orders, which are carried out by exchanging electronic documents, or messages,between the business partners. Typically, each partner comes with proprietary message formats developed for own use. Between the partners, message formats may differ in their syn-tax, such as EDI (Electronic Data Interchange) structures, XML, or custom data struc-tures. They may also use different standard message schemas, such as Xcbl and OpenTrans1, which are now available due to diverse standardization efforts.
To enable systems to exchange messages with each other, application developers need to transform messages from one format to another. This has led to a new motivation for schema matching, namely to support message translation. An important task in message translation is to establish translating rules at the message schema level. Like in schema integration, there may be naming and structural conflicts, as message schemas often use different names, different data types, different ranges of values, and different groupings of fields. However, we have here typically to deal with a much higher number of sche-mas than in schema integration. Today, application developers have to handcraft how message formats are related in translation programs or scripts. This manual approach is a major bottleneck and unsuitable for dynamic environments like electronic marketplaces. Semi-automatic schema matching would reduce the amount of manual work by generat-ing a draft mappgenerat-ing between two message schemas with the most plausible correspon-dences, which an application designer can subsequently validate and modify as needed. Semantic Web
The fast growth rate of the Web makes it increasingly difficult to locate, organize, and integrate information of interest. Due to the enormous quantity of data, human users have no other choice but to depend on the support of computers to perform these tasks, i.e., to automate them as much as possible. However, most of the Web’s content today is designed for humans to read, but not for machines to interpret and manipulate automati-cally. The main idea of the Semantic Web is to enrich the current contents of Web pages with semantic descriptions, which can be parsed and understood by computer programs, like mediators and search agents, for automated reasoning [10, 65]. The enrichment is done by annotating the Web contents with ontologies, which, in the Web terms, are doc-uments formally defining the semantics of and relations between concepts. That is, data on the Web is “tagged” with concepts of an ontology to indicate its meaning and rela-tionships to other data.
However, different websites are unlikely annotated using the same ontology. Hence, querying and integrating data from multiple sources on the Semantic Web require estab-lishing semantic correspondences between concepts of their ontologies, so that the data can be unified and consistently integrated. This is essentially a match problem like find-ing correspondfind-ing elements between different databases to integrate their contents. Given the decentralized nature of the Semantic Web, there is an increasing number of independently developed ontologies, making the task of manually identifying and encod-ing such correspondences in mediators or agents unfeasible. Hence, semi-automatic sup-port in ontology matching is crucial to the success of the Semantic Web.
1.3.SE M A N T I C HE T E R O G E N E I T Y 7
Model Management
The development of data integration tools and other metadata-intensive applications is very expensive. Supporting database systems or repositories typically require a graph-based or object-oriented representation of metadata with navigational access operations in an one-object-at-a-time manner. The recently proposed approach of model manage-ment represents a promising alternative to reduce developmanage-ment efforts for such complex metadata applications [12]. In particular, model management aims at a uniform manage-ment of models, such as database schemas, ontologies, web service specifications, web-site maps, etc., and mappings between them, such as SQL views, XQuery transformations. Moreover, it specifies a set of high-level operators, such as Match (determination of correspondences between models), Merge (merging of models based on their correspondences), and Compose (composition of mappings), to manipulate models and mappings as first-class objects.
The main goal is not only to automate the operations on models and mappings as much as possible, but also to provide generic implementations for them, so that they can be employed for a large variety of application domains and are independent from the lan-guages of models and mappings. Match is a central operator in model management as demonstrated in various application scenarios [14, 13]. In particular, it produces the model mappings, which are required or manipulated by other operators. Techniques from semi-automatic schema matching [119] can be employed to implement such a Match operator. A first prototype described in [94] shows the feasibility of the model management approach and demonstrates how schema matching is integrated and employed together with other operators within script-based programs to solve data manipulation tasks.
1.3
Semantic Heterogeneity
Although being addressed by many techniques and algorithms in different fields as dis-cussed in the last section, schema matching remains a hard task and is still far away from the state of being fully automated. A number of reasons contributes to the complexity of the problem:
Sources for Semantic Information
Identifying corresponding elements between two schemas requires thorough analysis of the semantics of the schemas, in other words, reverse engineering the real-world percep-tion of the schema creators. This process, if not impossible, is very slow due to many heterogeneous information sources to be considered, such as the schemas and databases, their documentations and their creators or daily users, in order to obtain the exact under-standing of the semantics of single schema elements. Extracting semantic information from users and documentations, which in fact can be very accurate and helpful sources, is a cumbersome process as it cannot be done in an automatic or standardized way. For example, Clifton et al. report in [23] of hours of ‘human time’ making phone calls and writing letters, and weeks of ‘wait time’ in order to get access to the desired information in the match process. Hence, we typically have to resort to the information available in schemas and instances. Although it is possible to develop automatic methods to process and analyze schema and instance data, there is always some likelihood for wrong or missing match predictions depending on the quality of the given information as dis-cussed next.
Schema and Data Heterogeneity
Schemas offer different kinds of “clues”, which can be exploited to obtain a semantic understanding of the schema elements. Examples for such clues include element names, data types, allowable values, schema structures and groupings of elements, integrity con-straints, etc. However, these kinds of information may vary between schemas depending on the expressiveness of the schema language employed. Even when available, the infor-mation is often unreliable and incomplete. Both issues arise mostly due to the fact that schemas are typically developed independently by different people with different per-ception of the real world for different purposes. Examples of such metadata-level con-flicts are the following:
• The same names do not necessarily indicate the same semantics and different names may in turn be used to represent the same real-world concept.
• Element names may be encrypted or abbreviated so that they are only comprehendible to their creators.
• Integrity constraints may be hardwired in programs accessing data, and not declara-tively specified at the schema level.
• Elements may be modeled at different levels of details: address information is divided into street, zip, and city in one schema, and captured using one single field in another. Besides the metadata specified in schemas, instance data can also provide insights into the contents and meaning of schema elements. However, this information may also vary from database to database and contain inconsistencies [118], making the comparison of instances of different databases difficult. Examples for such instance-level problems are: • Different values are employed to encode the same piece of information, e.g., ’F’ and
’Female’ for gender information.
• The same values are stored with different interpretation, for example, using different measurement units like Dollar vs. Euro, different quantity units like thousands vs. millions, or different string formats (as often observed for address data).
• Instance data may contain errors, such as misspellings, missing values, transposed or wrong values, duplicate records, etc.
Both metadata- and instance-level conflicts can mislead schema matching because no similarity or incorrect similarity between schema elements may result from such cases. For the user manually performing the matching task or verifying a match result, the con-flicts lead to additional time and effort required to correctly understand the semantics of the schema elements. For automatic match approaches, the conflicts typically reduce the result quality if not properly resolved using corresponding schema transformation or data cleaning techniques.
Requirements for Match Result
Besides the heterogeneity of schemas, the intuitions behind matching also pose addi-tional challenges to schema matching. In particular, if two elements are predicted to cor-respond to each other, we expect there are no better matching elements. This however requires comparing one element in one schema with all elements in the other schema, resulting in quadratic complexity, which can be very high for large schemas and unfeasi-ble for a high number of schemas to be considered. For example, [84] reports on a project at a telecommunication company, which tried to integrate 40 databases with a
1.3.SE M A N T I C HE T E R O G E N E I T Y 9
total of 27,000 attributes, for each of which about four hours were required on average for documenting and finding the match candidate(s).
Similarly to the subjectivity of the creator in schemas, there is also subjectivity in the results of schema matching. In particular, different users may conceive different ele-ments as matching, and likewise, different automatic match techniques may predict dif-ferent correspondences. However, at the application level, where the identified correspondences are convert to program codes, no ambiguity is allowed and a match result with all correct correspondences is required. Hence, application developers are still needed at the end to verify and possibly to correct the match correspondences obtained using different approaches. Sometimes, a whole committee is required to approve the match result [23].
C
H A P T E RCHAPTER 2
P
ROBLEM
D
EFINITION
The problem of schema matching can be formulated as follows: “Given two schemas, S1 and S2, find the most plausible correspondences between the elements of S1 and S2, exploiting all available information, such as in the schemas, instance data, and auxiliary sources.” It should be solved, as far as possible, by means of automatic techniques. An imperfect result can be further examined by the user to obtain the exact correspondences between the input schemas. The main goal is to reduce the amount of manual effort as much as possible and to avoid manually solving the match problem from scratch.
In the next section we introduce the notion of schemas and illustrate it for several schema languages. We discuss in Section 2.2 different kinds of input information, which can be exploited to detect similarity of schema elements. Section 2.3 discusses the semantics of the match result. Finally, in Section 2.4, we describe an architecture for generic schema matching.
2.1
Schemas
In a match operation, the input schemas specify the elements to be matched. Therefore, it is instructive to examine some typical schemas and their elements. Depending on the application domain, schemas may be available in many different formats and languages, such as SQL, UML, DTD, XSD, and OWL. Figure 2.1 shows sample schemas for pur-chase order in SQL, XSD, and OWL, respectively. We introduce and illustrate the nota-tion of these common schema languages along with the examples shown in the figure. • SQL allows to define schemas for relational databases, to query and manipulate data
stored in such a schema. A relational schema comprises a set of tables,e.g., PO and ShipTo, representing different real-world entities. Each table in turn consists of a set of columns, e.g., shipNo, street, city, and zip for ShipTo. A column in one table may be specified as a foreign key pointing to a column in another table to capture referential constraints between different entities, e.g., from PO.shipNo to ShipTo.shipNo. Entity instances are stored as records of column values within a corresponding table.
• XSD is increasingly utilized to describe structure of XML documents for data exchange over the Web. The main components of an XSD schema are elements (e.g., PO and ShipTo), attributes, and types (e.g., POType and Address). The latter can be either complex for specifying nested sub-elements, or simple for specifying atomic data types, such as string, for an element or attribute. In an instance document of an
Figure 2.1 Sample schemas for purchase order
CREATE TABLE PO(
poNo INT,
shipNo INT, PRIMARY KEY (poNo), FOREIN KEY (shipNo) REFERENCES ShipTo(shipNo) ) ;
CREATE TABLE ShipTo(
shipNo INT,
street VARCHAR(200),
city VARCHAR(200),
zip VARCHAR(20), PRIMARY KEY (shipNo) ) ;
<xsd:element name=“PO" type=“POType"/> <xsd:complexType name=“POType">
<xsd:sequence>
<xsd:element name=“ShipTo" type="Address"/> <xsd:element name=“BillTo" type="Address"/> </xsd:sequence>
</xsd:complexType>
<xsd:complexType name="Address" > <xsd:sequence>
<xsd:element name=“Street" type="xsd:string"/> <xsd:element name=“City" type="xsd:string"/> <xsd:element name=“Zip" type="xsd:decimal"/> </xsd:sequence>
</xsd:complexType>
<owl:Class rdf:ID=“PO"/>
<owl:ObjectProperty rdf:ID="shipTo"> <rdfs:domain rdf:resource="#PO"/> <rdfs:range rdf:resource="#Organization"/> </owl:ObjectProperty>
<owl:Class rdf:about="#Organization"> <rdfs:subClassOf rdf:resource="#Agent"/> </owl:Class>
<owl:Class rdf:ID="Address"/>
<owl:ObjectProperty rdf:ID="hasAddress"> <rdfs:domain rdf:resource="#Agent"/> <rdfs:range rdf:resource="#Address"/> </owl:ObjectProperty>
<owl:DatatypeProperty rdf:ID="Street"> <rdfs:domain rdf:resource="#Address"/> <rdfs:range rdf:resource="#string"/> </owl:DatatypeProperty>
A) SQL B) XSD C) OWL
XSD schema, only elements and attributes can be instantiated, i.e., have values, while their types constrain the appearance of the values.
• OWL is commonly used for specifying ontologies on the Semantic Web. Ontologies aim at conceptualizing the knowledge of a domain and support a semantic-richer rep-resentation of the real world than database or document schemas. In particular, OWL provides XML-based constructs to define classes (e.g., PO, Organization, and Agent) and their relationships (e.g., between super- and subclasses like Agent and Organiza-tion), properties (e.g., hasAddress of Agent and Street of Address) and their value range. Similar to types in XSD, the value range of properties may be an atomic data type (e.g., string for Street) or a pre-defined class (e.g., Address for hasAddress). OWL classes may have instances, which are stored within the same XML document. For the sake of generality, we define a schema simply as a set of schema elements con-nected by some structure. For example, from a relational schema, we can extract the tables and columns as schema elements, and containment relationships between tables and columns and referential constraints expressed by foreign keys between tables as schema structure. In an XSD schema, schema elements include XML elements and attributes, while schema structure consists of containment relationships between element and sub-elements as specified by complex types. From an OWL ontology, we obtain classes and properties as schema elements, while relationships among classes and con-tainment relationships between classes and their properties constitute schema structure.
2.2
Input Information
In order to solve a given match problem, we can exploit any kinds of available informa-tion that may help to characterize the semantics of schema elements and to detect their similarity. We roughly distinguish between schema information, instance data, and aux-iliary information:
• Schema information: The input schemas already provide various kinds of information, such as element names, description, data types, schema structure and other relation-ships between elements, etc., which can be examined to characterize and compare the semantics of schema elements.
2.3.OU T P U T IN F O R M A T I O N 1 3
• Instance data: In many applications, such as data integration and transformation, instance data is available for the schemas to be matched and can also be exploited to characterize the content and semantics of schema elements.
• Auxiliary information: This category comprises all other kinds of information which can be exploited to detect similarity between schema elements. For example, we can look up semantic relationships like synonymy and hypernymy between element names in existing (general-purpose or domain-specific) dictionaries and thesauri.
2.3
Output Information
Given two input schemas S1 and S2, the match operation returns as output a mapping between them, also called the matchresult. We define a mapping to be a set of mapping elements, or correspondences, each of which specifies that certain elements of S1 are mapped, or correspond to, certain elements in S2. Each correspondence may have a map-ping expression, which specifies how the S1 and S2 elements are related with each other. We discuss the main aspects, semantics, directionality, and invertibility, for mapping expressions in the following:
• Semantics: The mapping expression may use simple relations over scalars (e.g., iden-tity), terminological relationships (e.g., synonymy, hypernymy, is-a, part-of), set-ori-ented relationships (e.g., equivalence, overlapping, subsumption), or functions (e.g., string concatenation or arithmetic functions). Functions are mathematically the most precise form of semantic correspondences, as they exactly specify how to transform instances of S1 elements in those of S2 elements. For the specification of mapping expressions, any expression language, such as SQL or XQuery, can be used.
• Directionality: Mapping expressions may be directional or undirectional. In particular, those indicating equality relations, such as identity between scalars, synonymy between terms, equivalence of sets, etc., are undirectional, while others are mostly directional, that is, differentiating between source (or domain) and target (or range) elements. A mapping is undirectional if all mapping expressions of its correspon-dences are undirectional, otherwise directional.
• Invertibility: Mapping expressions may be invertible or not. By intuition, untional expressions are the inverse of themselves, and thus invertible. However, direc-tional ones may be invertible or not. While expressions specifying 1:1 correspondences are often invertible, complex ones involving sets of schema ele-ments, such as in arithmeticfunctions, are mostly not. A mapping is invertible if all mapping expressions of its correspondences are invertible, otherwise uninvertible. Most techniques for automatic schema matching are based on heuristics that are not eas-ily captured in a precise mathematical way. The main goal is to produce a mapping that tries to approximate the understanding of what users consider to be a good match. The match result mostly consists of corresponding schema elements but does not exactly specify how the elements are related with each other, i.e., without mapping expressions. Identifying corresponding elements, i.e., schema matching, is considered the first step in creating a semantic mapping between two schemas. The second step, also called query discovery [95], is to enrich the identified correspondences with real mapping expressions so that the mapping can be employed to translate instances of the source schema into those of the target schema.
Like most previous work, we focus on the first step, i.e., to obtain correspondences with-out mapping expressions. Therefore, we represent a mapping as a similarity relation over the cross-product of the input schemas. Each pair of matching elements is captured in a correspondence attached with a similarity value to indicate the plausibility of the corre-spondence. In this simple representation, the match result can always be considered undirectional and invertible, allowing for easy manipulation and combination of map-pings. Such a similarity-based mapping can be further enhanced in the second step either manually by the user or semi-automatically [95, 28, 141] to include mapping expressions for the correspondences.
2.4
Architecture for Generic Schema Matching
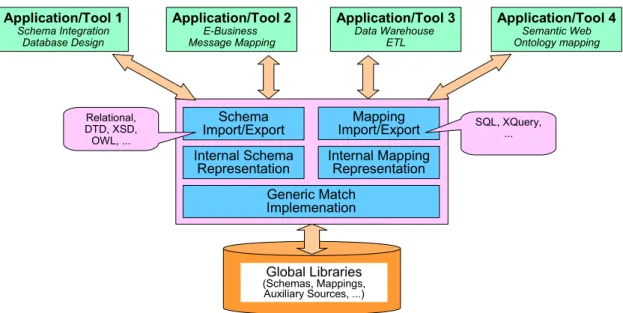
Because of the pervasiveness of schema matching, we envision a generic solution, which is suitable for different schema languages and application domains. Such a solution has high potential to be widely adopted, thereby reducing the effort otherwise required to develop many specific solutions. To achieve this goal, we need a flexible and customiz-able architecture, which can be easily extended and adapted to support a new schema language and/or application domain. Driven by this objective, Figure 2.2 shows the over-all architecture that we have kept in mind while developing our solution.
Figure 2.2 High-level architecture for generic match implementation Application/Tool 2 E-Business Message Mapping Application/Tool 4 Semantic Web Ontology mapping Application/Tool 1 Schema Integration Database Design Schema Import/Export Generic Match Implemenation Mapping Import/Export Internal Schema
Representation Internal MappingRepresentation
Global Libraries (Schemas, Mappings, Auxiliary Sources, ...) Relational, DTD, XSD, OWL, ... SQL, XQuery, ... Application/Tool 3 Data Warehouse ETL
The clients of generic schema matching are applications and tools from different domains, such as schema integration, E-business, data warehousing, and the Semantic Web. When needed, a client invokes the generic match implementation to automatically determine correspondences between relevant schemas. The implementation of schema matching may access existing libraries of schemas and mappings and other auxiliary information, such as dictionaries and thesauri, to help find correspondences. Such librar-ies may also be generated and maintained by the match implementation itself, such as for reuse purposes.
We assume that the generic match solution uses a uniform internal representation for the schemas to be matched. This significantly reduces the complexity for implementing the match algorithms as they do not have to deal with the large number of different
(hetero-2.4.AR C H I T E C T U R E F O R GE N E R I C SC H E M A MA T C H I N G 1 5
geneous) formats of schemas. Tools that are tightly integrated with the framework can work directly on the internal representation. For other tools, import/export programs are needed to translate schemas between their native representation (such as Relational/SQL, DTD, XSD, or OWL) and the internal representation. It is important to preserve all fea-tures which can help characterize the semantics of schema elements. As different schema languages typically exhibit varying modeling capabilities, we need to decide for a set of generic features to be included in the internal representation and map the language-spe-cific features to them during schema import.
Like the internal representation for schemas, the generic match solution also requires a internal representation for mappings. Assuming that all match algorithms operate on the internal schema representation, it is easy to come up with an internal representation for the generated match results. However, as external tools are unlikely to be able to under-stand this format, it is necessary to provide export programs for mappings, for example, to output the match results as SQL or XQuery queries, or in a standard format [47]. In general, it is not possible to fully automatically determine all correspondences between two schemas due to of their semantic heterogeneity. The match implementation should therefore only detect match candidates, which the user can accept, reject or change. Furthermore, the user should be able to specify correspondences for elements for which the system was unable to find match candidates. This poses high requirements to the capabilities of the user interface, which should effectively assist the user in perform-ing such manual tasks.
C
H A P T E RCHAPTER 3
O
PEN
I
SSUES
AND
C
ONTRIBUTIONS
Despite many efforts in research and industry, schema matching is largely performed manually by domain experts in current implementations. This is because still no satisfac-tory semi-automatic solution exists, which is able to scale with the proliferation and the complexity of data-sharing applications. This chapter starts by discussing the open issues in the current state of the art in semi-automatic schema matching. Section 3.2 then pre-sents the main contributions of the thesis by introducing the solutions proposed to address the identified issues. Finally, a roadmap for the rest of the thesis is given in Sec-tion 3.3.
3.1
State of the Art and Open Issues
The need for schema matching in numerous applications and the inherent difficulty of the task have led to the development of many techniques and prototypes to semi-auto-matically solve the match problem. They either address the problem for specific applica-tions, such as [7, 8, 9, 16, 20, 23, 34, 35, 40, 42, 49, 53, 54, 62, 71, 84, 97, 107, 112, 134, 143] or in a more generic way for different applications and schema languages [15, 88, 93, 96]. Some recent surveys of the match and related approaches are given in [119, 70, 31, 36]. The large amount of research work indicates the high potential of techniques and algorithms, which can be exploited for schema matching. However, we can observe a number of issues, which are not or not sufficiently addressed yet in previous work and thus require further investigation:
Expressiveness of Modern Schema Languages
Modern schema languages, e.g., W3C XSD and the new object-relational SQL versions (SQL:1999, SQL:2003), support many advanced modeling capabilities, such as user-defined types and classes, aggregation and generalization, component reuse, distributed schemas and namespaces, leading to significant complication for schema matching [120]. Mostly, such design styles can be used alternatively to model the same or similar real-world concepts, leading to different, yet semantically similar, structures in the sche-mas. Thus, matching schemas taking advantage of such powerful languages becomes a challenging task essentially depending on the detection and unification of the alternative modeling styles.
On the other hand, current match systems only focus on structurally simple schemas w.r.t. nesting levels, data types, constraints, and shared schema components. In
particu-lar, early schema languages such as DTD and SQL:1992 are mostly required as the input format. The traditional database notion of a schema is typically assumed where all instances can be described by a single monolithic schema. Likewise, most approaches assume tree-like schemas and ignore shared elements, such as the same complex types or sub-structures used at multiple places to capture the same kind of information (e.g., address data). Such shared elements may appear many times in a schema with a context-dependent semantics, which need to be differentiated for a correct matching. The treat-ment of shared eletreat-ments still requires further work in order to avoid an explosion of the search space.
Dealing with Large Schemas
Real-world schemas are constantly growing in both size and complexity in order to cope with the requirements for representing and managing data in corresponding applications. For example, the standard schemas for E-business messages developed by OpenTrans and Xcbl contain several independent parts, or subschemas, for individual transaction/ message types, each of which in turn consists of up to thousands of elements in order to be able to capture every detail of the messages. Furthermore, the schemas often use shared elements to avoid unnecessarily diverse specifications and keep a low schema complexity for easier maintenance. At the end, the match operation needs to examine a huge search space to find plausible correspondences; a major challenge, which requires very efficient approaches to deal with.
On the other hand, we observe that current match approaches are typically applied to some test schemas for which they could automatically determine most correspondences. As surveyed in [31], most test schemas were of small size of 50-100 elements. Unfortu-nately, the effectiveness of automatic match techniques studied so far typically decrease for larger schemas [29]. In particular, it is likely that large portions of one or both input schemas have no matching counterparts. Thus, matching complete input schemas may lead not only to long execution time, but also poor quality due to the large search space. Moreover, it is difficult to present the match result to a human engineer in a way that she can easily validate and correct it. A more piecemeal approach, e.g., based on the divide-and-conquer philosophy, may be more preferable in such cases with the promise for both better user control and match performance.
Combination of Match Algorithms
To achieve high match accuracy for a large variety of schemas, considering a single cri-terion (e.g., name matching) is unlikely to be successful. As a consequence, it is neces-sary to combine and utilize multiple techniques at the same time. For this purpose, previous prototypes have followed either a so-called hybrid or composite combination of match approaches. So far the hybrid approach is most common where multiple criteria or properties (e.g., name and data type) are considered within a single algorithm. Typically, these criteria are fixed and utilized in a specific way, for example, concerning the order they are evaluated, making it difficult to extend and improve the overall algorithm. By contrast, a composite match approach combines the results of several independently executed match algorithms, which can in turn be hybrid or composite. This allows for a high flexibility, as there is the potential for selecting the match algorithms to be executed based on the match task at hand. Moreover, there are different possibilities for combin-ing the individual match results. We know of only few systems followcombin-ing such a com-posite approach, in particular, [34, 35, 42]. They are limited to match techniques based on machine learning and employ a specific combination of match results. While
promis-3.1.ST A T E O F T H E AR T A N D OP E N IS S U E S 1 9
ing to improve the flexibility and quality over the hybrid approach, composite combina-tion still requires further work in order to fully exploit its potential and to examine how to best combine different matchers.
Schema Matching Evaluation
For identifying a solution for a particular match problem, it is important to understand which of the available techniques performs best, i.e., can reduce the manual work required for the match task at hand most effectively. The only way to approach this goal is to demonstrate the quality and practicability of the developed match algorithms in real-world scenarios, or better, to conduct a systematic study using a range of schema matching tasks. Evaluation thus represents an important task in developing a match solu-tion and has also been seriously considered in most previous work.
Unfortunately, the system evaluations reported in the literature so far were done using diverse methodologies, metrics, and data making it difficult to assess the effectiveness of each single system, not to mention to compare their effectiveness. Furthermore, the sys-tems are usually not publicly available making it virtually impossible to apply them to a common test problem or benchmark in order to obtain a direct quantitative comparison. Hence, it is necessary to establish a common framework for future evaluations, so that they can be documented better, their result be more reproducible, and a comparison between different systems and approaches be easier. This requires a systematic analysis of the factors influencing the quality and performance of a match approach.
Reuse of Match Results and Data Integration
Reuse aims at exploiting different kinds of auxiliary information, such as (domain-spe-cific or general-purpose) dictionaries, thesauri, ontologies, etc., to solve a match task. This can especially help in cases if schema elements cannot be compared merely using metadata in the schemas or available instance data. Current match prototypes mostly uti-lize a simple form of reuse at the level of single schema elements by looking up element correspondences in synonym tables [88, 112, 42] or by using user-specified correspon-dences to train machine-learning algorithms on instances of a schema element [34, 35]. A further generic approach is to reuse entire previously identified match results [119]. In fact, we observe that new schemas to be matched are often very similar to previously matched schemas. Reusing the existing match results can thus result in significant sav-ings of manual effort. However, the potential of this approach has not yet been studied in current schema matching work.
The idea of reuse previous match results can be further generalized to cover mappings between different kinds of objects, which may be at both the metadata and instance level. This is motivated, on the one side, by the fact that often applications employ generic schemas and store heterogeneous information, possibly mixing both metadata and instance data, in a few generic tables [11, 1]. On the other side, we observe that semantic correspondences between objects of different types are available in many domains, such as bioinformatics [51, 45, 50] and peer-to-peer data management [72]. Such correspon-dences represent valuable domain knowledge and can be re-used to inter-relate objects of interest and to integrate object information from different sources.
Graphical User Interface for Match
Given the fact that no fully automatic solution is possible, a user-friendly interface is essential for the practicability and effectiveness of a match system. On the one side, the match process should be performed interactively, so that the domain knowledge of the
user can be actively incorporated in identifying corresponding schema elements. On the other side, the effort required for interactions, such as configuration of the match opera-tion, verification and correction of automatically derived match results, should be reduced to a minimum so that it is still affordable compared to manually solving the match task from scratch.
Unfortunately, most prototypes developed so far focus on some research aspects and offer no or only a rudimentary user interface. The only system that we know of providing a comprehensive graphical user interface is CLIO [66, 105, 114, 61], a commercial tool
developed at IBM. However, CLIO focuses on the mapping discovery task to obtain
que-ries for transforming instances between two schemas. Hence, many GUI capabilities have not yet been studied, such as to customize the match operation, to visualize and deal with large schemas/match results, to manipulate and evaluate match results.
3.2
Contributions
Focusing on the open problems discussed above, the dissertation makes a number of con-tributions, which can be grouped into the four following areas:
Surveys of Match Approaches and Evaluations
To obtain a better overview about the current state of the art in schema matching, we sur-vey the existing approaches and their evaluations.
• Survey of schema matching algorithms and prototypes: There is a lot of previous work on schema matching done in different fields, such as schema translation and integra-tion, knowledge representaintegra-tion, machine learning, and information retrieval. We adopt the taxonomy proposed in [119] and perform a new survey of existing schema match-ing approaches. In particular, we differentiate and discuss schema- and instance-level, element- and structure-level, language- and constraint-based, and reuse-oriented match approaches. As for the combination of multiple matchers, hybrid and composite approaches are possible. Match approaches may further be distinguished according to the cardinalities of their results. According to the taxonomy, we review various match prototypes published in the literature. We characterize them in some detail and com-pare them and our own development.
• Survey of schema matching evaluations: Evaluation aims at proving the practicability of a match system for real-world circumstances. We identify and discuss the major cri-teria that influence the effectiveness of a schema matching approach, such as the cho-sen test problems, the design of the experiments, the reprecho-sentation of match results, the metrics used to quantify the match quality and the amount of saved manual effort, and the overall execution performance. We use these criteria to review the evaluation of various state-of-the-art systems and motivate the importance of a common frame-work to make the comparison between different systems and approaches easier.
Besides helping us to implement and test our own system, our insights on the match approaches and their evaluations can be of valuable help for the development of future schema matching systems.
Generic, Customizable, and Scalable Schema Matching Systems
The main contribution of the thesis consists in the development of two new generic and customizable schema matching systems, COMA (Combining Matchers) and its successor,