A NOVEL APPROACH OF ROUGH SET ANALYSIS IN
DISTRIBUTED DATA MINING
Abstract:
Distributed Data Mining(DDM) has evolved into an important and active area of research because of theoretical challenges and practical applications associated with the problem of extracting, interesting and previously unknown knowledge from very large real-world databases. Rough Set Theory (RST) is a mathematical formalism for representing uncertainty that can be considered an extension of the classical set theory. It has been used in many different research areas, including those related to inductive machine learning and reduction of knowledge in Distributed data-based systems. One important concept related to RST is that of a rough relation. In this paper we presented the current status of research on applying rough set theory to DDM, which will be helpful for handle the characteristics of real-world databases. The main aim is to show how rough set and rough set analysis can be effectively used to extract knowledge from large databases.
Keywords:—Data mining, Data tables, Distributed Data Mining (DDM), Rough sets.
1. INTRODUCTION:
Data mining technology has emerged as a means for identifying patterns and trends from large quantities of data. Data mining is a computational intelligence discipline that contributes tools for data analysis, discovery of new knowledge, and autonomous decision making. The task of processing large volume of data has accelerated the interest in this field. As mentioned in Mosley (2005) data mining is the analysis of observational datasets to find unsuspected relationships and to summarize the data in novel ways that are both understandable and useful to the data owner.
Distributed Data Mining (DDM) aims at extraction useful pattern from distributed heterogeneous data bases in order, for example, to compose them within a distributed knowledge base and use for the purposes of decision making. A lot of modern applications fall into the category of systems that need DDM supporting distributed decision making. Applications can be of different natures and from different scopes, for example, data and information fusion for situational awareness; scientific data mining in order to compose the results of diverse experiments and design a model of a phenomena, intrusion detection, analysis, prognosis and handling of natural and man-caused disaster to prevent their catastrophic development, Web mining ,etc. From practical point of view, DDM is of great concern and ultimate urgency.
Rough set theory is a new mathematical approach to imperfect knowledge. The problem of imperfect knowledge has been tackled for a long time by philosophers, logicians and mathematicians. Recently it became also a crucial issue for computer scientists, particularly in the area of artificial intelligence. There are many approaches to the problem of how to understand and manipulate imperfect knowledge. The most successful one is, no doubt, the fuzzy set theory proposed by Zadeh .Rough set theory proposed by Zpawlak presents still another attempt to this problem. The theory has attracted attention of many researchers and practitioners all over the world, who contributed essentially to its development and applications. Rough set theory has an overlap with many other theories. However we will refrain to discuss these connections here. Despite of the above mentioned connections rough set theory may be considered as the independent discipline in its own rights. Rough set theory has found many interesting applications. The rough set approach seems to be of fundamental importance to AI and cognitive sciences, especially in the areas of machine learning, knowledge acquisition, decision analysis, knowledge discovery from databases,
Vuda Srinivasa Rao Research Scholar CSIT Department, JNT University , Hyderabad
Andhra Pradesh, India
Dr. S Vidyavathi Associate Professor
CSIT Department, JNT University , Hyderabad
Andhra Pradesh, India
expert systems, inductive reasoning and pattern recognition. The main advantage of rough set theory in data analysis is that it does not need any preliminary or additional information about data like probability in statistics, or basic probability assignment in Dempster-Shafer theory, grade of membership or the value of possibility in fuzzy set theory.
The proposed approach
Provides efficient algorithms for finding hidden patterns in data,
Finds minimal sets of data (data reduction),
Evaluates significance of data,
Generates sets of decision rules from data,
It is easy to understand,
Offers straightforward interpretation of obtained results,
Most algorithms based on the rough set theory are particularly suited for parallel processing. The remaining sections of the paper are organized as follows. In Section II we describe Rough sets theory in data mining .In Section III we describe Distributed Data Mining.
In Section IV we describe rough set analysis in Distributed Data Mining. In Section V we describe Computational Aspects of Rough set on DDM. In Section VI concludes the paper.
2. ROUGH SETS THEORY IN DATA MINING:
Rough set theory was developed by Zdzislaw Pawlak in the early 1980’s1. Rough set deals with classification of discreet data table in a supervised learning environment. Although in theory rough set deals with discreet data, rough set is commonly used in conjunction with other technique to do discrimination on the dataset. The main feature of rough set data analysis is non-invasive, and the ability to handle qualitative data. This fits into most real life application nicely. Rough set have seen light in many researches but seldom found its way into real world application.
Knowledge discovery with rough set is a multi-phase process consisted of mainly:
Discretization
Reducts and rules generation on training set 2.1 Mining Process:
The process of DM using rough set is a multi step process that requires a few steps. 2.1.1 Discretization:
Because rough set theory is a symbolical method rather than a numerical method, roughest theory cannot process continuous data. Discretization is a process that converts continuous data into discreet intervals to be used in roughest. There a couple of popular techniques that is used to discreetize data. The project will use Boolean reasoning technique to do the discretization on the data. The technique is moderately
simple with good results seen on most dataset.
“The tests are showing that they are very efficient from the point of view of time complexity.” “The heuristics for symbolic value partition allow to obtain more compressed for of decision algorithm .Hence, from the minimum description length principle, one can expect that then will return decision algorithms with high quality of unseen object classification.”
2.1.2. Reducts and rules generation:
Fig 1. Pseudo codes for the Holte’s lr Reducer
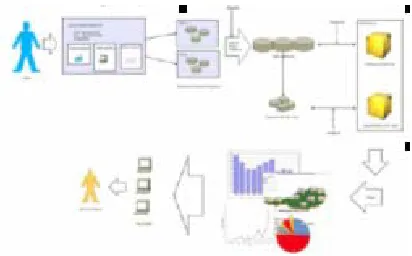
2.2 System architecture:
The overview of the architecture of the system can be seen in figure. The proposed architecture will adopt the traditional architecture of a data mining system. Data from multiple channels is collected on the operational data store for fast transaction and up to date data that can be used for the front office. Then, periodically, the data is extracted, cleans, transformed and imported into the data warehouse. The data will then will be send to the appropriate data marts for departmental use. Then, according to the needs of the user, either the enterprise data or the departmental data is sent to the OLAP tier for processing. The results is then stored and then sent to the decision makers through the use of thin clients. The overview of this architecture is seen in Figure 2 . The proposed system is pretty good in theory as it provides compartmentalization of data and collection of data from multiple channels. The architecture is simple and sticks to the basis of founded work and should provide a good base for the system.
Fig 2: the over view of proposed system Architecture
3. DISTRIBUTED DATA MINING:
pay careful attention to the distribution of data, computing and communication, in order to access and use them in a near optimal fashion. Distributed Data Mining (sometimes referred by the acronym DDM) considers data mining in this broader context. DDM may also be useful in environments with multiple compute nodes connected over high speed networks. Even if the data can be quickly centralized using the relatively fast network, proper balancing of computational load among a cluster of nodes may require a distributed approach. The privacy issue is playing an increasingly important role in the emerging data mining applications. For example, let us suppose a consortium of different banks collaborating for detecting frauds. If a centralized solution was adopted, all the data from every bank should be collected in a single location, to be processed by a data mining system. Nevertheless, in such a case a Distributed Data Mining system should be the natural technological choice: both it is able to learn models from distributed data without exchanging the raw data between different repository, and it allows detection of fraud by preserving the privacy of every bank’s customer transaction data. For what concerns techniques and architecture, it is worth noticing that many several other fields influence Distributed Data Mining systems concepts. First, many DDM systems adopt the Multi-Agent System (MAS) architecture, which finds its root in the Distributed Artificial Intelligence (DAI). Second, although Parallel Data Mining often assumes the presence of high speed met work connections among the computing nodes, the development of DDM has also been influenced by the PDM literature. Most DDM algorithms are designed upon the potential parallelism they can apply over the given distributed data.. In figure 3 a general Distributed Data Mining framework is presented. In essence, the success of DDM algorithms lies in the aggregation. Each local model represents locally coherent patterns, but lacks details that may be required to induce globally meaningful knowledge. For this reason, many DDM algorithms require a centralization of a subset of local data to compensate it. The ensemble approach has been applied in various domains to increase the accuracy of the predictive model to be learnt. It produces multiple models and combines them to enhance accuracy. Typically, voting (weighted or un-weighted) schema are employed to aggregate base model for obtaining a global model. As we have discussed above, minimum data transfer is another key attribute of the successful DDM algorithm.
Fig,3: General Distributed data mining Frame work
4. ROUGH SET ANALYSIS IN DISTRIBUTED DATA MINING:
equivalence relation. Any set of all in discernibility objects is called elementary set. Any union of elementary set is called a definable set or crisp set; otherwise a set is rough or imprecise. Thus, every rough set has a boundary that differentiates objects which cannot be classified with certainty to be an element of the rough set or of its complement. Therefore, a rough set can be replaced by a pair of crisp set, called the lower and the upper approximation. The lower approximation consists of all objects which definitely belong to the set and the upper approximation contains all objects which probably belong to the set while the boundary is the difference between the upper approximation and the lower approximation.
Rough set theory is still another approach to vagueness. Similarly to fuzzy set theory it is not an alternative to classical set theory but it is embedded in it. Rough set theory can be viewed as a specific implementation of Frege’s idea of vagueness, i.e., imprecision in this approach is expressed by a boundary region of a set, and not by a partial membership, like in fuzzy set theory.
Rough set concept can be defined quite generally by means of topological operations, interior and closure, called approximations.
Let us describe this problem more precisely. Suppose we are given a set of objects U
called the universe and an indiscernibility relation
RUU, representing our lack of knowledge about elements of U. For the sake of simplicity we assume that R is an equivalence relation.
Let X be a subset of U. We want to characterize the set X with respect to R. To this end we will need the basic concepts of rough set theory given below.
The lower approximation of a set X with respect to R is the set of all objects, which can be for certain
classified as X with respect to R (are certainlyX with respect to R).
The upper approximation of a set X with respect to R is the set of all objects which can be possibly
classified as X with respect to R (are possibly X in view of R).
The boundary region of a set X with respect to R is the set of all objects, which can be classified neither as
X nor as not-X with respect to R. Now we are ready to give the definition of rough sets .Set X is crisp (exact with respect to R), if the boundary region of X is empty. Set X is rough (inexact with respect to R), if the boundary region of X is non empty .Thus a set is rough (imprecise) if it has nonempty boundary region; otherwise the set is crisp (precise). This is exactly the idea of vagueness proposed by Frege.
The approximations and the boundary region can be defined more precisely. To this end we need some additional notation. The equivalence class of R determined by element x will be denoted by R(x). The indiscernibility relation in certain sense describes our lack of knowledge about the universe. Equivalence classes of the indiscernibility relation, called granules generated by R, represent elementary portion of knowledge we are able to perceive due to R. Thus in view of the indiscernibility relation, in general, we are an able to observe individual objects but we are forced to reason only about the accessible granules of knowledge.
Formal definitions of approximations and the boundary region are as follows:
R-lower approximation of X
U x
X
x
R
x
R
x
R
:
*
R-upper approximation of X
U x
X
x
R
x
R
x
R
:
*
R-boundary region of X
X
R
X
R
X
RN
R
*
*It is interesting to compare definitions of classical sets, fuzzy sets and rough sets. Classical set is a primitive notion and is defined intuitively or axiomatically. Fuzzy sets are defined by employing the fuzzy membership function, which involves advanced mathematical structures, numbers and functions. Rough sets are defined by approximations. Thus this definition also requires advanced mathematical concepts. Approximations have the following properties:
)
(
)
(
X
X
R
X
R
U
U
R
U
R
R
R
(
)
(
)
;
(
)
(
)
R
(
X
Y
R
(
X
)
R
(
Y
)
)
(
)
(
)
(
X
Y
R
X
R
Y
R
)
(
)
(
)
(
X
Y
R
X
R
Y
R
)
(
)
(
)
(
X
Y
R
X
R
Y
R
)
(
)
(
&
)
(
)
(
X
R
Y
R
X
R
Y
R
Y
X
)
(
)
(
X
R
X
R
)
(
)
(
X
R
X
R
)
(
)
(
)
(
X
R
R
X
R
X
R
R
)
(
)
(
)
(
X
R
R
X
R
X
R
R
It is easily seen that approximations are in fact interior and closure operations in a topology generated by data. Thus fuzzy set theory and rough set theory require completely different mathematical setting.
Rough sets can be also defined employing, instead of approximation, rough membership function.
0
,
1
:
U
R X
where
|
|
|
|
x
R
x
R
X
x
R X
and |X| denotes the cardinality of X.
The rough membership function can be used to define approximations and the boundary region of a set, as shown below:
R
X
x
U
:
XR
x
1
,
:
0
X
x
U
x
R
RX
,
X
x
U
:
0
x
1
RN
RX
R
.It can be shown that the membership function has the followingproperties [5]:
1
)
(
x
R X
iffx
R
*(
X
)
0
)
(
x
R X
iffx
U
R
*(
X
)
1
)
(
0
Rx
X
iffx
RN
R(
X
)
)
(
1
)
(
x
Rx
X R
X
U
for anyxU
(
x
)
R Y X
max(
XR(
x
),
YR(
x
))
for any xU
(
x
)
R Y X
min(
RX(
x
),
YR(
x
))
for any xUNow we can give two definitions of rough sets.
Definition 1: Set X is rough with respect to R if
R
(
X
)
R
(
X
)
. Definition 2: Set Xrough with respect to R if for some x,0
R(
x
)
1
X
.The most common representation of initial knowledge in rough set theory is in a tabular form, similar to a relational table. The column in the table represents attributes, and each row represents an object. There are two different kinds of knowledge representations, namely information systems and decision systems. 4.1. Information Systems:
An information system is the most basic kind of knowledge. It consists of a set of tuples, where each tuple is a collection of attribute values. Rough Set Analysis in KDD is based on the viewpoint that objects are known up to their description by attribute vectors: An information system Ι consists of a set U of objects, and a set Ω of attributes; the latter are functions a: U→Va which assign to each object x a value a(x) in the set Va of values which x can take under a.
4.2 Decision Systems:
A decision system is similar to an information system, but a distinction is made between condition and decision attributes. In an information system, the information is not interpreted. However, an expert may classify the different objects according to some semantic criteria, thus assigning an expert classification attribute to each object. Adding a decision attribute d to an information system creates a decision system, where the attributes A form the condition attributes. Using a single decision attribute can be done without any loss of generality, as it is possible to represent any k-size attribute set
X
x
D by a single decision attribute d. Any combination of the values for the decision attributes in D may be represented (coded) by a distinct value for d. Hence, it is sound to assume that D ={d}. A decision system
(DS) A = (U,A,{d}) is an information system for which the attributes are separated into disjoint sets of condition attributes A and a decision attributes d (A {d}=φ). Now, it should be apparent that from any given DS A = (U,A,{d}), it is possible to construct an information system by simply removing the decision attribute d from the system, giving us an information system
A’ = (U,A). In the same manner as a decision system is a specialized kind of information system, decision rules are a special kind of pattern. A decision rule represents a probabilistic
relationship between a set of conditions and a decision. Given a decision system A = (U,A,{d}), let α denote a pattern that only involves attributes in A. Let β denote a descriptor d = v, where v < Vd. The decision rule is then read as “if αthen β”,
and is denoted α→β. αis called the rule’s antecedent, and βthe rule’s consequent [4].
In practice however, generating a decision rule from a reduct or a reduct-equivalent means overlaying the attributes in the reduct over an object x, and reading off the values of a(x) for every a reduct. This means that the decision rules will always be conjunctions of descriptors (or a single descriptor, in the event that the reduct consists of a single attribute). Rules of this type are said to represent positive
knowledge, defined as follows: Given a DS A = (U,A,{d}). The decision rule α→ βis said to be a positive decision rule if αis a conjunction of descriptors that only involve attributes in A.
5. COMPUTATIONAL ASPECTS OF ROUGH SET ON DDM:
In the literature, there has long been a lack of time complexity analysis of algorithms for frequently used rough set operations. Time complexities of constructing an equivalence relation are shown to be O(lm2), where l and m are number of attributes and objects, respectively . This result corresponds to the analysis of an algorithm, reported in, where the goal is to obtain the equivalence relation according to the values of a single attribute. For a given functional dependency X→Y that holds in an information table S, we say that x
→X is superfluous (or non-significant) attribute for Y in S if and only if, X-{x}→Y still holds in S. A reduct of X for Y in S is a subset P of X such that P does not contain any superfluous attribute. If we have a metric to measure the degree of dependency, then we have a way to explore a reduct of X, with a degree of θ, where 0 ≤ θ ≤ 1 . It is shown that finding a reduct of X for Y in S is computationally bounded by l2m2 where l and m is a length of X and the number of objects in S respectively. The time complexity to find all reducts of X is O(2lJ), where J is the computational cost for finding one reduct, and l is the number of attributes in X.
6. CONCLUSIONS:
In the paper, basic concepts of distributed data mining and the rough set theory were discussed. Rough Set Theory has been widely used in DDM since it was put forward. Having important functions in the expression, study, conclusion and etc. of the uncertain knowledge, it is a powerful tool, which sets up the intelligent decision system. The main focus is to show how rough set techniques can be employed as an approach to the problem of data mining and knowledge extraction. The project shows that rough set theory can be used as a tool for knowledge discovery. Even though it is a symbolical method, application of a suitable quantization technique will allow it to perform on just about any type of data. As opposed to numerical method that cannot be adapted to be used for symbolical data. Rough set provide a useful tool that can be used on a lot of different data regardless weather it is numerical or symbolical and it also provide a non-intrusive methodology to knowledge discovery.
7.REFERENCES:
[1] Z. Pawlak, “Rough sets,” Int. J. Inform. Comput. Sci., vol. 11, no. 5, pp.341–356, 1982.
[2] P. Langley and H. A. Simon, “Applications of machine learning and rule induction,” Commun. ACM, vol. 38, no. 11, pp. 55–64, 1995.
[3] T. Y. Lin and N. Cercone, Rough Sets and Data Mining, T. Y. Lin and N. Cercone, Eds. Boston, MA: Kluwer, 2000. [4] J. G. Carbonell, Machine Learning: Paradigms and Methods, J. G. Carbonell, Ed. Cambridge, MA: MIT Press, 1990.
[5] R. S. Michalski, I. Bratko, and M. Kubat, Machine Learning and Data Mining, R. S. Michalski, I. Bratko, and M. Kubat, Eds. New York:Wiley, 1998.
[6] T. Mitchell, Machine Learning. New York: McGraw Hill, 1997.
[8] I. Uysal and H. A. Guvenir, “An overview of regression techniques for knowledge discovery,” Knowl. Eng. Rev., vol. 14, no. 4, pp. 319–340, 1999.
[9] A. Barto and R. S. Sutton, Reinforcement Learning. Cambridge, MA:MIT Press, 1998.
[10] Berry, Michael J. A (1997) Data mining techniques: for marketing, Sales and customer support, New York: John Wiley [11] I. Dűntsch. G. Gediga (1999) Rough set data analysis: A road to non-invasive knowledge discovery
[12] Holmes, G., and Nevill-Manning, C.G. (1995). Feature Selection via The Discovery of Simple Classification Rules. Proc. International Symposium on telligent Data Analysis (IDA-95), Baden-Baden, Germany.
[13] Holte R.C (Machine Learning., vol. 11, pp. 63--91, 1993) Very simple classification rules perform well on most commonly used datasets
[14] H. S. Nguyen and A. Skowron. Quantization of real-valued attributes. In Proc. Second International Joint Conference on Information Sciences, pages 34–37,Wrightsville Beach, NC, Sept. 1995.
[15] H.S. Nguyen and A. Skowron. Boolean reasoning for feature extraction problems. 10th International Symposium on Methodologies for 16 Intelligent Systems (ISMIS'97), volume 1325 of Lecture Notes in Artificial Intelligence, pages 117--126, Berlin, 1997
[16] Aleksander Øhrn. ROSETTA Technical Reference Manual. Knowledge Systems
[17] Berry, Michael J. A. (2000) Mastering data mining: the art and science of customer relationship management, New York: John Wiley
[18] Marakas, George M. (1999) Decision support systems in the twenty-first century: DSS and data mining technologies for tomorrow's manager, New Jersey: Prentice Hall
[19] L. Polkowski, A. Skowron: Rough mereological calculi granules: a rough set approach to computation, computational intelligence: An International Journal 17, 2001, 472-479 [19] Ryszard S. Michalski and Kenneth A. Kaufman, “Data Mining and Knowledge Discovery: A Review of Issues and a Multistrategy Approach”, Machine Learning and Data Mining, Methods and Applications, 1997.
[20] J.N.Kok and W.A.Kosters, “Natural Data Mining Techniques”, European Association for Theoretical Computer Science, Vol. 71, June 2000, pp.133-142.
[21] Ning ZHONG, Andrzej SKOWRON, “A Rough Set-Based Knowledge Discovery Process”, International Journal of Applied Mathematical Computer Science, 2001, Vol.11, No.3, pp.603-619.
[22] Terje Løken, “Rough Modeling Extracting Compact Models from Large Databases”, Knowledge Systems Group IDI, A thesis submitted to Norwegian University of Science and Technology, 1999.
[23] U. Fayyad, G. Piatetsky-Shapiro, and P. Smyth, “From data mining to knowledge discovery in databases”, Artificial Intelligence Magazine 17 (1996), pp.37–54.
[24] Ivo Düntsch, Günther Gediga, Hung Son Nguyen, “Rough set data analysis in the KDD process”, published in the Proceedings of IPMU 2000, pp. 220-226.
[25] Hayri Sever, “The Status of Research on Rough Sets for Knowledge Discovery in Databases”, www. cuadra.cr.usgs.gov/pubs/srj98.pdf
[26] Deogun.J, Choubey.S, Raghavan.V and Sever.H, “Feature selection and effective classifiers”, Journal of ASIS 49, 5 (1998), pp.423–434.
[27] Bell.D, and Guan.J, “Computational methods for rough classification and discovery”, Journal of ASIS 49, 5 (1998), pp.403–414. [28] Deogun.J.S, Raghavan.V.V, and Sever.H, “Exploiting upper approximations in the rough set methodology”, In The First
International Conference on Knowledge Discovery and Data Mining (Montreal, Quebec, Canada, aug 1995), U. Fayyad and R. Uthurusamy,Eds., pp.69–74.
[29] Kent.R. E, “Rough concept analysis”, In Proceedings of the International Workshop on Rough Sets and Knowledge Discovery (Banff, Alberta, Canada, 1993), pp.245–253.
[30] Andrzej Skowron, “Rough Sets in KDD”, Institute of Mathematics Warsaw University Banacha 2, 02{095, Warsaw, Poland.
Vuda .Srinivasarao received the M.Tech degree in Computer Science & Engg from the Satyabama University, in 2007. . He is research scholar in CSIT Department, JNT University Hyderabad Andhra Pradesh, India. His research interests include Network Security, Cryptography, and Data Mining & Artificial Intelligence.