Neurocomputingxxx(xxxx)xxx
Contents lists available at ScienceDirect
Neurocomputing
journal homepage: www.elsevier.com/locate/neucom
Unsupervised
framework
for
depth
estimation
and
camera
motion
prediction
from
video
Delong Yang
a, Xunyu Zhong
a,∗, Dongbing Gu
b, Xiafu Peng
a, Huosheng Hu
b a DepartmentofAutomation,XiamenUniversity,Xiamen361005,Chinab SchoolofComputerScienceandElectronicEngineering,UniversityofEssex,Colchester,CO43SQ,UK
a
r
t
i
c
l
e
i
n
f
o
Articlehistory: Received27March2019 Revised25October2019 Accepted11December2019 Availableonlinexxx CommunicatedbyLiuWeiKeywords:
Unsuperviseddeeplearning Depthestimation Cameramotionprediction Convolutionalneuralnetwork
a
b
s
t
r
a
c
t
Depthestimationfrommonocularvideoplaysacrucialroleinsceneperception.Thesignificant draw-back of supervisedlearning models is the need for vast amounts of manually labeled data (ground truth)fortraining.Toovercomethislimitation,unsupervisedlearningstrategieswithouttherequirement forgroundtruthhave achievedextensiveattention fromresearchersinthepastfewyears.Thispaper presentsanovelunsupervisedframeworkforestimatingsingle-viewdepthand predictingcamera mo-tionjointly.Stereoimagesequencesareusedtotrainthemodelwhilemonocularimagesarerequired forinference.ThepresentedframeworkiscomposedoftwoCNNs(depthCNNandposeCNN)whichare trainedconcurrentlyandtestedindependently.Theobjectivefunctionisconstructedonthebasisofthe epipolargeometryconstraintsbetweenstereoimagesequences.Toimprovetheaccuracyofthemodel,a left-rightconsistencylossisaddedtotheobjectivefunction.Theuseofstereoimagesequencesenables ustoutilizebothspatialinformationbetweenstereoimagesandtemporalphotometricwarperrorfrom imagesequences. Experimentalresultsonthe KITTIandCityscapes datasetsshow that ourmodel not onlyoutperformspriorunsupervisedapproachesbutalsoachievingbetterresultscomparablewith sev-eralsupervisedmethods.Moreover,wealsotrainourmodelontheEurocdatasetwhichiscapturedinan indoorenvironment.Experimentsinindoorandoutdoorscenesareconductedtotestthegeneralization capabilityofthemodel.
© 2019ElsevierB.V.Allrightsreserved.
1. Introduction
Depthestimationbasedonimageshasreceivedmuchattention inrecentyearsduetothepropertiessuchasconvenienceand real-time process which offerimportantinformation forsimultaneous localizationandmapping[1],self-drivingplatformsandinteractive collaborative robotics[2],etc.The purposeofdepth estimationis to predictthe distancefroma sceneto the camerabased onthe image directly. Thistopicisdivided intotwo technicalstrategies: traditionalmethodsanddeeplearningmodels.
Traditional methodsinclude structured light [3], time-of-flight
[4], structure-from-motion [5], photometric stereo method [6], stereomatching [7,8] andsymmetricmodels for3D object struc-ture estimation [9,10], etc. These methods typically formulate depth estimation as multi-views problems. Stages of traditional methods such as feature extraction, feature description, feature matching and bundle adjustment are time-consuming. In addi-tion,some regions suchasthemotorway andbuildingfacade are smooth on the surface so that few matching points can be
ex-∗ Correspondingauthor.
E-mailaddress:[email protected](X.Zhong).
tracted.Infact,extractingfeatures fromthesenon-textureregions whichlackofhigh-qualityfeaturessuchasfeaturepointsoredges. Therefore, this problem has not been resolved in the traditional way.
Toovercometheseshortcomings,convolutionalneuralnetworks (CNNs) [11–14] have beenwidely used in monocular depth esti-mation tasks, and they have achieved considerable improvement againsttraditionalmethods. Oneofthemainreasonsforthis im-provement is big data which makes CNNs obtain pixel-wise se-mantic information in all regions of images.The other reason is that the generated CNN models compute the scene depth much fasterthantraditionalmethodsinpracticalapplication.
CNN models attempt to estimate the scene pixel-wise depth mapwhichcorresponding totheimage directly.Thisstrategy has received much attention over the past several years due to its properties such as real-time processing, therefore predicting the scene depth from a single image without prior information has become a fundamental topic in computer vision. Recently, deep learning methods have been divided into two types: supervised deeplearningmethodswhichrequiregroundtruthfortrainingand unsuperviseddeeplearningmethodswithouttheneedforground truth.
https://doi.org/10.1016/j.neucom.2019.12.049
0925-2312/© 2019 Elsevier B.V. All rights reserved.
motionprediction.Itisanovelschemethatusesstereoimage se-quencesfortraining.Thenwecanusethegeneratedmodelto es-timatethedepthofmonocularimagesduringthetestingprocess. Inaddition,we canalsoobtainthecameramotionofthe monoc-ularimage sequences.Itisanunsupervisedframeworkwhichcan be trained simply using stereo image sequences without ground truth.Moreover,weconstructaleft-rightconsistencylossfunction asapartoftheobjectivefunctiontoimprovetheaccuracyand ro-bustnessofthemodel.
In summary, we propose a novelmonocular depthestimation andcameramotionpredictionschemeinanunsupervisedway.The CNNstructure andobjectivefunction arediscussed inthis paper, then we use BGD (Batch Gradient Descent) to calculate the net-work’sparametersthroughiterativecomputing.After all,the gen-erated model is utilized to obtain the monocular image’s depth mapandits corresponding cameramotioninan end-to-end way. Ourmaincontributionsareasfollows:
• Thispaperpresentsanovel frameworkthat usesstereoimage sequences as input data to learn an unsupervised model for depthestimationandcameramotionjointly.
• Wepresentanovelcompositionframeworkwithleft-right con-sistency. The framework utilizes the spatialand temporal ge-ometryconstraintstoconstructtheobjectivefunction.
• The experimentsontheKITTIandCityscapesdatasets demon-strate that our model outperforms previous unsupervised methodsandsomesupervisedmethods.
• TheexperimentsontheEurocdatasetarecompletedtotestthe generalizationcapabilityofthepresentedtechnique.
Theremainderofthispaperisorganizedasfollows:
Section 2 gives a review of related works. Section 3 gives
the detail of our end-to-end model and implementation details.
Section 4 shows experimental results on the KITTI, Cityscapes
andEurocdatasets. Finally,we give aconclusion ofthispaper in
Section5.
2. Relatedworks
There is plenty of published papers that pay close atten-tion to depth estimation from images,either using stereo image pairs, temporal image sequences or multi-view images. It is in-conceivable to understand the structure of a scene from single-view images in traditional methods. Fortunately, deep learning hasachievedgreatprosperityincomputer visionsincethe break-through work of [16]. The vast majority of depth estimation al-gorithmsbased on CNNs are supervised.These approaches need morethanonelabeleddatasettolearnparameters.Toaddressthis issue,hereweconcentrateonanunsupervisedmethodtoestimate scenedepthandpredictcameramotion.Inthefollowing,wegive abriefintroductiontothemostcloselyrelatedwork.
loopclosing.However,allthestagesmustbedesignedcarefully. Based on the fact that the structures of manyman-made ob-jectsaresymmetric,Gaoetal.[9]extendedthisinformationfrom 2Dimagesto3Dobjectreconstruction,andusedsymmetryto im-prove non-rigid structure from motion algorithms. In [10], a 3D structureandcameraprojectionestimatingmethodwasproposed. The input of thismodel came fromvarious intra-class object in-stances and the symmetry was extended to the multiple-image case.Maetal.[20]proposedalocallylineartransformingmodelto matchbothrigidandnon-rigidfeaturesofremotesensingimages. Alltheabovemethodseitherreconstructtheunderlying3D geom-etry orestablishthecorrespondentrelationshipsper-pixel among input viewstoobtain thescene depth.Nevertheless,these meth-odsusemulti-viewimagesasinputdata.
2.2. Supervisedlearningfrommonocularimage
The task of estimating scene depth from a monocular image is a challenging topic since we cannot get the geometric struc-ture by only one view image. Recently, some researchers have treated depth estimation as a supervised learningprocess. Eigen et al. [11] proposed a network which consisted of two compo-nents, the first one estimates the global structure of the scene, thenthe otheruses neighborhoodinformationto refineit.Tothe best of our knowledge, it is the first paper that predicts scene depth frommonocular imagesbased on deep CNN.On the basis ofpreviouswork, Eigenetal.[12]addressedaframeworkto pro-cessthreedifferent computervision tasks(depthestimation, sur-facenormalprediction,semanticlabeling)simultaneously.Lainaet al. [21] proposed a fully convolutional architecture to model the ambiguousmappingbetweenmonocularimagesanddepthmaps. Lietal. [22] presenteda fast-to-trainmulti-streamed CNN archi-tecturefordepthestimation.Yanetal.[23]usedsurfacenormalas areferencetoassistthetaskofmonoculardepthestimation.
Untilnow, some workshavetackled monocular depth estima-tioncombinedCNNsandRandomForests.Lietal.[24]copedwith thisproblembyregressionondeepCNNsfeatures,combineswith a post-processing refining step using conditional random fields. Royetal.[25]presentedanovelneuralregressionforestthat com-binesrandomforestsandCNNsfordepthestimationfromasingle image.Liuetal.[26] formulated depthestimationintoa continu-ous conditionalrandomfield learningproblembasedonthe con-tinuouscharacteristicofthedepthvalues.Eventhoughthe above methodshaveachievedaccurate resultsformonoculardepth esti-mation,theseapproachesrelyongroundtruthfortraining,which restrictsthegeneralizationabilityofthemodel.
2.3. Unsupervisedlearningfrommonocularimage
Inordertoovercomethelimitationofgroundtruth,some un-supervised learningframeworks forthe task ofmonocular depth Pleasecitethisarticleas:D.Yang,X.ZhongandD.Guetal.,Unsupervisedframeworkfordepthestimationandcameramotionprediction
D.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 3
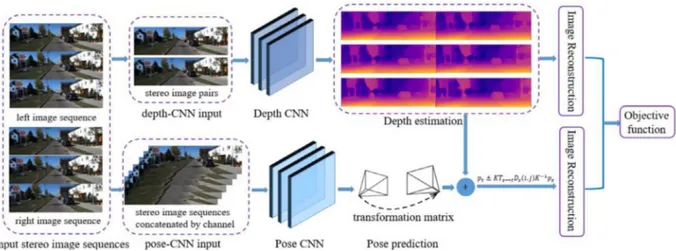
Fig.1. Overviewofourmethod.Trainingsamplesconsistofunlabeledstereoimagesequencescapturedfromabinocularcamerawhichdoesnotprovidetheposeofimage sequences.ThismodelconsistsofdepthCNNtoestimatescenedepthandposeCNNtopredictcameramotion.ThesetwoCNNsuseimagereconstructioninsteadofground truthfortraining.Theyaretrainingsynchronouslyandoperateindependently,oneforsingleviewdepthestimationandtheotherforcameramotionprediction.
estimation were presented recently. Garg et al. [13] used pairs of images withknown camera motions as input data, to learn a CNNto modelthecomplexnon-lineartransformationwhich con-verts theimagestodepth-maps.BasedonGarg’s work,Renetal.
[27] andYu et al. [28] constructed a spatial smoothness loss to add tothetotallossfunctionforunsupervisedoptical flow learn-ing.Theirworksandresultsaresimilar.Godardetal.[29] treated depthestimationasanimagereconstructionproblemduring train-ing.Alossfunctionisconstructedtolearnthecorrespondence be-tweentherectifiedstereoimagesbyusingepipolargeometry con-straints. Kuznietsov et al. [30] used predictedinverse depth and sparse ground-truth depth asinput to estimate scene depthin a semi-supervised way. Their models require an accurate extrinsic calibrationbetweenthe3D lasersensorandthecamera.YanHua andHuTian[31]proposedConvolutionalConditionalRandomField Network(CCRFN)forfeaturelearninganddepthestimation.CCRFN hastwoadvantages,oneisitdoesnotneedhand-craftedfeatures andtheotherisitmakesuseoftherelationshipbetween individ-ualfeaturesfordepthestimation.
Zhouetal.[32] proposed anunsupervisedlearningframework for the monocular depth estimation and camera motion predic-tion synchronously. To our best knowledge, it is the first paper that usesmonocularimage sequencesfortrainingandtesting.On thebasisofZhou’swork,Yinetal.[33]proposedanunsupervised learning framework named GeoNet [33], which predicts monoc-ular depth, optical flow and detect dynamic objects jointly. Luo et al. [34] come from SenseTime Research presented a method thatreformulatesthemonoculardepthestimationproblemastwo sub-problems followed by stereomatching. Pilzeret al.[35] pre-sentedanunsupervised depthestimationframeworkwhichisthe first paper that uses cycled generative networks. Moreover, it is thefirstpaperthatutilizescycledgenerativenetworkstoestimate the scene depth. Tulsiani et al. [36] proposed an unsupervised frameworkwhichwithoutusinggroundtruthdirectlyforlearning single-viewshapeandposepredictionofindoorinstances.
Theseunsupervisedlearningmodelshaveusedpairsofimages capturedfromastereocamerawithaccuratecalibrationor monoc-ular image sequences as supervision. Stereo images cannot take full advantage of temporal information. Monocularimages suffer from an inherent problem, depthambiguity, which means differ-ent depths may correspond to the objects with similar appear-ancesintheimage.However,althoughtheseunsupervisedmodels haveachievedthegoalthatestimatedscenedepthwithoutground truth,littleattentionhasbeenpaidtothestrategyofjointlyuses stereoimagepairsandimagesequencesfordepthestimation.
3. Method
In this section, we describe the unsupervised framework for depth estimation andcamera motion predictionfrom monocular videos. During training, we use stereoimage sequences captured byamovingbinocularcameraasinputdataofthedepthandpose CNNs.Inspiteofbeingjointlytrained,thesetwoCNNscanbeused independentlyinthepracticalapplication.
3.1. Overviewofourmethod
Thepresentedan unsupervisedlearningmodelcan bedivided into two parts: depth estimation andcamera motion prediction, whichcanbetrainedjointly.Thephotometricwarperrorbetween thesynthesizedandinputimageisselectedtoconstructthe super-visionsignal.
Theoverviewof ourmodelis showninFig.1. Itis composed oftwoparts,onefordepthestimationandtheotheronefor cam-eramotion prediction.The firstpart estimatesscenedepth maps throughthe depthCNN andthesecond partis conductedby the poseCNNtocompute thecameraposebetweentheimagesofan image sequence. Furthermore, in the second part, we use stereo imagesequencesandthescenedepthobtainedfromthefirstpart asinput fortraining. Considering the constraintsof stereoimage pairsandmonocularimage sequences,weobtainmorerobust re-sultsthanothermethods.Lastbutnotleast,duringtraining,a ge-ometricconsistencycheck whichimprovestheaccuracyofthe al-gorithmisaddedtotheobjectivefunction.
3.2.Depthestimation
Givenasingleimageduringtestingtimeinference,ourpurpose is to learn a function d= f
(
I)
which can estimate the per-pixel depthmapcorrespondingtotheinputimage.Thisfunctionisactually aCNNwhich hasnumerousfixed pa-rametersfordepth estimationof asingleRGBimage. While CNN is used, the depth map can be computed in an end-to-end way througha seriesof non-linearoperationsof CNN’slayers. All the parametersoftheselayershavebeenalreadycalculatedduringthe trainingprocess.Therefore,thegoaloftrainingistogetall CNN’s parameters.
Inordertoachieve thispurpose,we usestereoimage pairsas input data fortraining. It is an iterative process withthe use of BGD(BatchGradientDescent).Weconstructalossfunctionforthis Pleasecitethisarticleas:D.Yang,X.ZhongandD.Guetal.,Unsupervisedframeworkfordepthestimationandcameramotionprediction
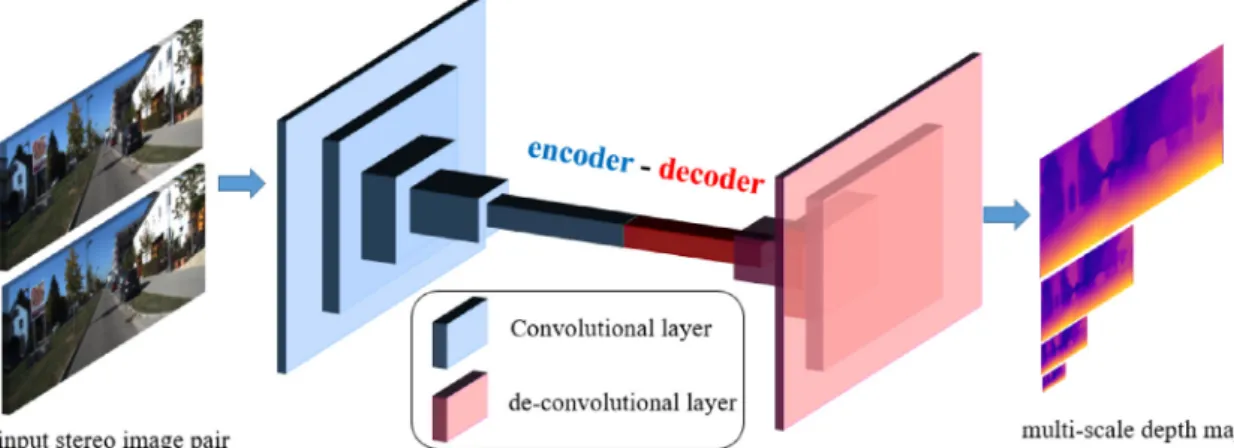
Fig.2. ArchitectureofdepthCNN.Itisanencoder-decodermodel,thewidthandheightofeachcubeindicatethespatialdimensionsoftheoutputfeaturemaprespectively. Thecubechannelindicatesthechannelsoftheoutputfeaturemapatthecorrespondinglayer.Eachreductionorincreaseinscaleindicatesachangebythefactorof2.We adopttheresidualnetarchitecturewithfourscalessidepredictions.Thekernelsizeis7forthefirstconvolutionallayerandothersare3.Thenumberofoutputchannels forthefirstconvolutionallayerissetto64andthelastis2.
BGDprocessandusesixstereoimagepairsasabatch.Each train-ingsampleisastereoimage pairwhichis composedofIl andIr,
theyarecorrespondingtotheleftandrightcolorimagewhich cap-turedfromamovingbinocularcamerasynchronously.
We usethe disparity map estimated fromthe depth CNN in-steadof tryingto estimate the scenedepth map directly.We as-sumethatall thestereoimagesare rectified[37]andthesurface is Lambertian (make the photo-consistency error is meaningful). Forastereoimagepair,wedenotethedisparitymapwhich corre-spondingtotheleftimageofthisstereoimagepairisDl,theright
synthesizedimageisreconstructed bytheformulaIr=Il
(
Dl)
.Thereconstructionfunctionwehavejustusedcanbeexpressedas:
Ir
i,j+Dl i,j=Il
(
i,j)
,(
i,j)
∈l (1)
whereIl istheleftimage oftheinputstereoimage pair,
l
istheimage pixel spacecorresponding toIl, Ir is theright synthesized
imagegeneratedfromtheleftimage andthe rightdisparitymap, (i,j)isthecoordinatesofapixelintheimage.Theleftsynthesized imageIl=Ir
(
Dr)
canbereconstructedsimilarly.Depth estimation using stereo image pairs obey primary ge-ometricconstraint, therefore,this model can be learnedwithout groundtruth. Stereo imagesarecapturedfrombinocular cameras that have good synchronization and calibration so that the pix-els in the two images of the stereo image pair have a strong correspondence.
Thesesynthesizedimagesarekeycomponentsoftheloss func-tion for our depth CNN. After obtaining the predicted disparity maps,thedepthmapd(i,j)canbecomputedbythefollowing lin-earmapping:
d
(
i,j)
=b f/D(
i,j)
(2)whereb isthebinocularcamera’sbaseline,fisthecamera’sfocal length,(i,j)isthepixelcoordinateofanimage.
Thebaselineandcamera’sfocallengthofthebinocularcamera arechangelesssothattheuseofstereoimagepairsduringtraining allowsustogettheabsolutescaleofmonoculardepthestimation. Specifically,for a stereoimage pair, each pixel inthe overlapped area of one image can find its corresponding pixel in the other image of the stereo image pair with horizontal distance (dispar-ity)[13].Thebinocularcamera’sbaselinebandthecamera’sfocal lengthfestablishtheabsolutecorrelationbetweenthescenedepth andthedisparitymap,andthedisparitymapdetermines the im-agereconstruction effectiveness whichhas asignificant influence ontheconstruction ofthe lossfunction. Ourmodelrelieson the lossfunction based onthe spatial geometryconstraints (formula
(1)and(2))torecovertheabsolutescaleforthemonoculardepth estimation and camera motion prediction duringtraining. In the testingtime,ourmodelcanbeusedtoestimateabsolutedepthfor monocularimages.
During training, six stereoimage pairs are treated asa mini-batch. Our goal is to learn a depth CNN model which generates disparitymapscorrespondingtotheinputimages.Thekeyinsight ofthismethodisthat thestereoimagepairs arefed throughthe depth CNN layers, they can produce the left-to-right and right-to-left disparity maps simultaneously. Then we use these dispar-itymapsandoriginal input stereoimage pairsto reconstructthe synthesizedstereoimages.Theloss functionisconstructed based onthe differencebetweenthesynthesizedstereoimagesandthe original stereo images. Therefore,the accuracy of disparity maps generatedbyourdepthCNNhasadecisiveeffectonimage recon-structingresults.ThearchitectureofthedepthCNNisasfollows:
The network of the depth CNN is composed of two stages namely encoder and decoder (as shown in Fig. 2). We select ResNet50asan encodertoextracthigh-levelfeaturesanduse de-convolutionasadecodertooutputdisparitymapsatfourdifferent scales.Theresolutionoftheoutputdisparitymapistwicethatof theprevious image. At eachoutput scale s,we define an itemof the loss function asL_depth for evaluating the lossof the depth CNNatthisspecifiedscale.
Taking account of the fact that images are subordinate to a great diversityof distortions duringacquisition and processing, a structuralsimilarityindex[38]isselectedformeasuring photomet-ric loss afterimage synthesizing. This image similarity measure-ment maintains an appropriate assessment between appearance similarityandmodestresilienceforimagedistortions.Inaddition, an L1-lossisadded tothe photometricimage reconstruction cost
L_apat each scale. The ultimatepurpose of our appearance loss function is to measure the difference betweenthe original input image and its corresponding synthesized image. We suppose the rightsynthesizedimage fromtheleft image isIr,the appearance
difference atscales betweenIr andtheoriginal rightimage Ir is
formulatedas: L_aprights = 1 N i,j
α
1−SSIM Ir i j,Iri j 2 +(
1−α
)
I r i j−Ii jr1 (3)whereNisthenumberoftotalpixelsintheimage,
α
isaweight parameter, i, j indicate the abscissa and ordinate of each image pixel respectively.Similarity, the appearance difference at scale s betweentheleftsynthesizedimageIl andtheoriginalleftimageIlD.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 5
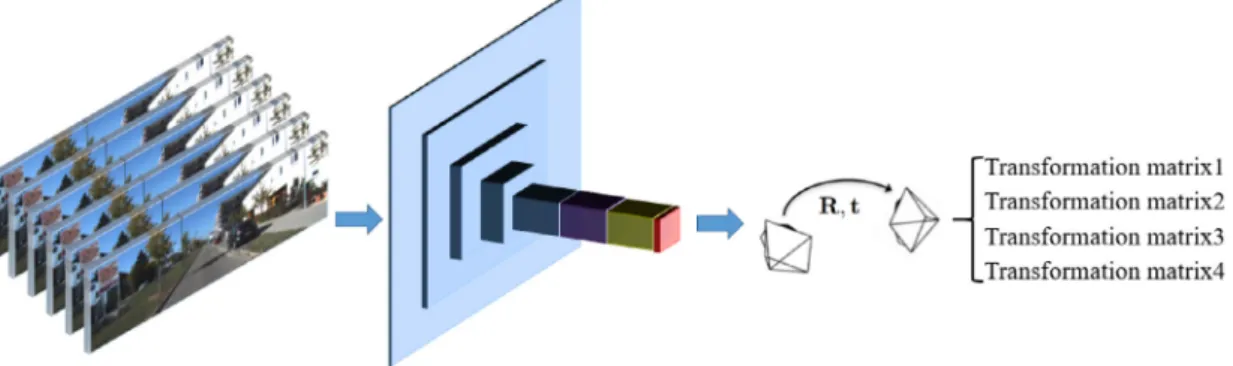
Fig.3. NetworkarchitectureoftheposeCNN.Itisanencodermodel,theoutputofthisnetworkisfourmatricescorrespondingtothetransformationsfromthesource imagestothetargetimages.Eachreductioninscaleindicatesachangebythefactorof2.Thekernelsizeis5forthefirstconvolutionallayerandothersare3.Thenumber ofoutputchannelsforthefirstconvolutionallayerissetto16.
isformulatedas: L_aple f ts = 1 N i,j
α
1−SSIM Il i j,Ii jl 2 +(
1−α
)
I l i j−Ili j1 (4)Thefinalappearancedifferenceatscalesis:
L_aps= 1 2
L_aple f ts +L_aprights (5)According to the formula (5),it is locally smooth on the dis-paritygradient.However,depthdiscontinuityoftenexistsatimage gradients in intuition.In order tofilter out outliers andpreserve sharp details, we useimage gradient toconstruct an edge-aware depthsmoothnesscosttermfortheleftimagebelow:
L_disple f ts = 1 N i,j
∂
dli j∂
xe−∂xIli j1+
∂
dli j∂
ye−∂yIli j1 (6)
Theedge-awaredepthsmoothnesscosttermfortherightimage canbeconstructedassameastheleftimage,theformulais:
L_disprights = 1 N i,j
∂
dri j∂
xe−∂xIri j1+
∂
dri j∂
ye−∂yIri j1 (7)
Therefore,thefinaledge-awaredepthsmoothnesscosttermat scalesistheaverageoftheabovelossitems.Accordingtothe for-mulas(6)and(7),thelast costtermwiththeconsiderationofthe edge-awaredepthsmoothnessisasfollows:
L_disps= 1 2
L_disple f ts +L_disprights
(8)Inordertoimprovetheaccuracyandrobustnessofourmodel, weintroduce aleft-rightconsistencypartbasedonthecoherence ofdisparity mapsbetweentheleft andrightimages.Considering the factthat disparitiesofthe leftandrightimages onthesame pixel locations are not equal, we use the left and right dispar-itymapswhichgeneratedfromthedepthCNNtosynthesizeeach other.Wedenote Dl isthe leftestimateddisparitymap andDris
therightestimateddisparitymap.Thesameimage reconstruction functionasformula(1)isusedtoreconstructthesynthesized dis-paritymaps.Thesereconstructionfunctionsareexpressedas:
Dr
i,j+Dl i,j =Dl(
i,j)
,(
i,j)
∈disp l (9)
where Dl isthe left estimated disparitymap,
disp
l is the image
pixel space corresponding to Dl, Dr is the right synthesized
dis-parity map generated from the left estimateddisparity map and the right disparity map, (i,j) is the coordinates ofa pixel inthe disparitymap.TheleftsynthesizedimageDl canbereconstructed
similarity.
Thecalculationprocedureatscalesisasfollows:
L_lrs= 1 N 2
Dl−Dr2 (10)
In the summary, the total loss for stereo image pairs at all scalesconsidersthedifferencebetweenthesynthesizedimageand the original input image, the edge-aware depth smoothness and the left-right consistency between the disparity maps. The loss functionfordepthCNNisasfollows:
L_depth=
4
s=1
μ
1∗L_aps+μ
2∗L_disps+μ
3∗L_lrs (11)where
μ
1,μ
2andμ
3 areweightparameters.3.3.Cameramotionprediction
The purpose of camera motion prediction is to learn a func-tion p=g
(
I)
whichisa CNNforpredictingthecameramotionof the input image. During training, the depth and pose CNNs are trainedsimultaneously.ThearchitectureofourposeCNNisshown inFig.3.The disparitymapsandtheircorresponding original im-agesareusedasinputdataforpredictingthecameramotion.With aview to the fact thateach image of an image sequenceis cap-tured in a very short time, and the two camerasof a binocular camera are extremely close to each other, we assume that the sceneisstaticwithoutdynamicobjects,such asmoving carsand pedestrians.The input stereo image sequence is decomposedinto the left andrightimage sequence. Eachof thesetwo image sequences is composedofthreeframes,wespecifythatthesecondimageisthe targetimageandtheothertwoimagesarethesourceimages.The camera motions of the left and right image sequences are com-putedrespectively.
The key supervision signal of the pose CNN comes from im-agesynthesize.AssimilartothedepthCNN,assumetheframesof a sequence are rectified. Letus denote{I1, I2, I3}as the
consec-utiveframesoftheleft image sequence,the middleframe ofthe sequenceisthetargetimageItandtherestarethesourceimages
In
(
n=1,3)
. We define the disparity map corresponding to eachframeofanimagesequenceasDi
(
i=1,2,3)
,andtherelativecam-eramotionestimatedby theposeCNNfromthe sourceimage to thetargetimageisdefinedasTs→t.Therelative3Dtransformation
fromthesourceimageIstothetargetimageItcanberepresented
by
pt=KTs→tDs
(
ps)
K−1ps (12)whereKisthebinocularcameraintrinsicmatrix,Dsisthe
dispar-itymapcorresponding to thesource image,ps andpt denotethe
pixelsofthesourceimageandthetargetimagerespectively. Pleasecitethisarticleas:D.Yang,X.ZhongandD.Guetal.,Unsupervisedframeworkfordepthestimationandcameramotionprediction
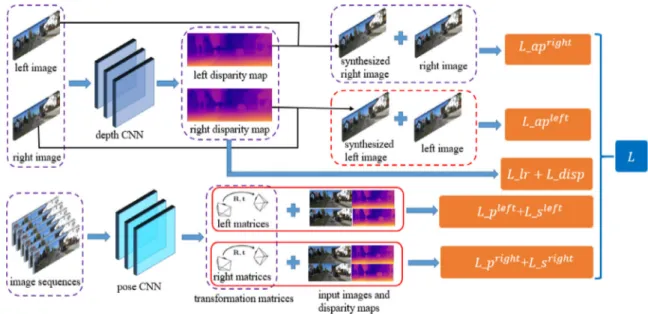
Fig.4. FordepthCNN,weusestereoimagepairsasinputdatatogeneratecorrespondingdisparitymaps.Intheprocessofimagereconstruction,forexample,weusethe leftinputimageanditscorrespondingdepthmaptosynthesizetherightimage,thenweutilizethegeneratedrightimageandtherightinputimagetoconstructtheright losspart.Theleftlosspartissimilartotherightlosspart.StereoimagesequencesarefedintotheposeCNNtocomputetransformationmatricesfromthesourceimages tothetargetimages,thenwetakeadvantageofthedepthmaps,thetransformationmatricesandtheoriginalinputimagestoconstructtheobjectivefunction.
Basedontheformula(12),wedenoteIs1→t isthesynthesized
targetimagereconstructedfromthesourceimage I1,Is2→t isthe
synthesizedtargetimagereconstructedfromthesourceimageI3.
Theformulasofthesesynthesizingprocessare:
Is1→t
(
pt)
=ItKTs1→tDs1(
ps1)
K−1ps1 (13) Is2→t(
pt)
=ItKTs2→tDs2(
ps2)
K−1ps2 (14)whereTsn→t isthetransformmetricsofthecameramotionfrom
the source image to the target image, Dsn(psn)is the depth maps
correspondingtothesourceimage.Assimilartothedepth estima-tionCNN,theapparent differencebetweenIt andthesynthesized
targetimagesIsn→t
(
n=1,2)
atscalescanbeformulatedas: Lple f ts = 1 2N n=1,2β
1−SSIM(
It,Isn→t)
2 +(
1−β
)
It−Isn→t1 (15)whereNisthenumberoftotalpixelsoftheimage,
β
isaweight parameter,dividedby2atlastbecauseitisthelossofthe synthe-sizesfromthetwosourceimagestothetargetimage.In the process of forward-backward propagation of this CNN, gradient descent is the main calculation method. For image, the gradients are mainly computed by the pixel intensity difference betweena pixel andits nearbypixels. However, some pixels are locatedin a low-texture region.In order to overcomethis draw-backandpreservethesharpdetails,wepreferadepthsmoothness losspartasfollows:
L_sle f ts = pt
∂
D(
pt)
∂
pt· e− ∂I(pt) ∂pt T (16)
Thefinalposelossfunctionataspecialscalesoftheleftimage sequenceis:
L_posele f ts =
ν
1∗L_ple f ts +ν
2∗L_sle f ts (17)where
ν
1andν
2 areweightparameters.Assameastheleftposelossfunction,theposelossfunctionat scalesoftherightimagesequenceis:
L_poserights =
ν
1∗L_prights +ν
2∗L_srights (18)Insummary,thetotallossforstereoimagesequenceatscales isthe averageofthe aboveloss items. Accordingto theformulas
(17)and(18),thelastcosttermatallscalesisasfollows:
poss_loss= 4 s=1 1 2
L_posele f ts +L_pose right s (19)3.4. Theobjectivefunction
TheoverviewofourobjectivefunctionasshowninFig.4. According to the formulas (10) and (18), with the considera-tion of the constraints of the stereo image pairs and the image sequences, the final objective function at all scales is definedas follows:
L=
λ
1depth_loss+λ
2pose_loss (20)where
λ
1 andλ
2aretheweightparametersforthedepthestima-tionandcameraposeprediction.
This article uses a stereo image sequence as input data for training,toconstructthedepthCNNandposeCNNforestimating the scene depth and predictingthe camera pose simultaneously. Sincethemodelhasbeengenerated,weusemonocularimagesas inputfortesting.
4. Experiments
In orderto evaluate theperformance ofourframework, com-prehensive experiments are conducted on the publicly available KITTI[39] andCityscapes[40] datasets. The Eurocdataset isalso usedtotrainthemodel,andvariousdatasets areusedtotestthe generalizationcapabilityofthepresentedframework.Wecompare ourapproach witha group ofstate-of-the-artschemes which in-clude supervised and unsupervised frameworks. We also deploy ourmethodontwowidely-usedCNNs(VGG-16[41]andResNet50
[42])todiscusstheeffectsofthesetwonetworkstructures.In ad-dition,weconductanablationstudytoprovethattheuseof left-rightconsistencylossduringtrainingcanimprovetheaccuracyof depth estimation. To give the qualitative and quantitative analy-sisofourmodel,fivecommonlymeasuresareselectedtoquantify Pleasecitethisarticleas:D.Yang,X.ZhongandD.Guetal.,Unsupervisedframeworkfordepthestimationandcameramotionprediction
D.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 7
ourresultsinthetaskofmonoculardepth.Moreover, weuse im-agesthatcomefromvariousdatasetsthatincludeindoorand out-door environments as input to the models which are trained on the KITTIandEurocdatasets to test thegeneralization capability. Atlast,wecomparetheresultsofourcameraposepredictionwith thatofORB-SLAM[19]andanunsupervisedmethod[33].
Inthissection,wefirstlygiveabriefdescriptionofthedatasets wehaveused.Thenweintroducethefivecommonmeasurements andourtrainingdetails.Lastly,thequalitativeandquantitative re-sultsaredisplayed.
4.1. Theexperimentaldatasets
In order to compare with prior related works on monocular depth estimation,herewe mainly use theKITTIdataset for eval-uation. We also usethe Cityscapesdataset forthe benchmarking ofcross-datasetgeneralizationability. Inaddition,weusethe Eu-roc dataset to retrain our model for indoor environment depth estimation.
The KITTI dataset has been created by Karlsruhe Institute of Technology (KIT) andToyota TechnologicalInstitute at Chicagoin 2012andithasbeenupdatedin2015.Thedatawascapturedbya drivingplatformaroundthemid-sizecityofKarlsruhe,inrural ar-easandonhighways.Upto15carsand30pedestriansarevisible per image. The rawform ofthisdataset contains42382rectified stereo image pairs from 61 scenes witha typical image size be-ing 1242∗375 pixels. Consideringconsistent comparison,we take thesplitofEigenetal.that697imagescomefrom29scenesare chosenfortesting.Wekeep29000stereoimagepairsfortraining. The Velodynelaser-scanned3Dpointsare projectedontothe im-age planesin orderto generatethe groundtruth toevaluate the model’sperformance.
The Cityscapes dataset has been created mainly by Benz. This large-scale dataset contains a diverse set of stereo im-age sequences recorded in street scenes from 50 different cities of Germany, with high-quality pixel-level annotations of 5000 frames and a larger set of 20000 weakly annotate frames. Because of theunsupervised method,the sub-datasets of Cityscapes dataset namely leftImg8bit_sequence_trainvaltest and rightImg8bit_sequence_trainvaltest are chosen for training. These twosub-datasetscontainabout15000stereoimagepairs.At train-ing time, we optionally pre-train the model on the two sub-datasetsoftheCityscapesdataset.
TheEuroc datasetconsistsofstereoimages,synchronizedIMU measurements, accurate motion andstructure groundtruth. Data of the Euroc dataset are capturedin an indoor environment and only stereo images are required for our model. The stereo im-ages arecaptured byan Aptina MT9V034 globalshutterwhichis equippedto an AscTec Firefly unmannedaerialvehicle (UAV).All thestereoimagesaremonochrome,whicharedifferentfromthose of the KITTIandCityscapes datasets. The sub-datasets which are ASLdatasetformatareusedtotrainandtestourmodel.
4.2. Measurements
Toevaluatetheaccuracyoftheproposedmethodinmonocular image depthestimation,we usethesefivescale-invariant metrics as followsto measure the errorbetween our resultsand ground truthprojectedfromthe3Dlaser.
• AbsRelativedifference(AbsRel): |N1|y∈N
|
y−y∗|
/y∗ • SquaredRelativedifference(SqRel):|N1|y∈Ny−y∗2/y∗• RMSE(linear):
1 |N| y∈Nyi−y∗i 2 • RMSE(log10):1 |N| y∈Nlogyi−logy∗i 2 • Threshold: % of yi s.t. max(
yy∗ii, y∗ i yi)
=δ
<thr, thr= 1.25,1.252,1.253.whereN isthetotalnumberofpixelsonthegroundtruth image,
yisthevalueofthepredicteddepthandy∗isthevalueofground truth.
The first four metric measures the difference compares with groundtruth,andthelast metricmeasures thepercentageofthe predicteddepth value which is within specified thresholds from the correct value. In addition, the maximum depth in the KITTI dataset isabout 80 meters, so we set our maximum predictions ofthisvalue.
Here we must state that measuring the error in depth space leadsto aprecisionresult. Especially,themetricswithout thresh-old measure maybe sensitive to thelarge errors causedby esti-matederrorsatsmalldisparityvalues.
4.3.Trainingdetails
The networks of this article are implemented by TensorFlow. TheResNet50containsabout65milliontrainableparameters,and takesmorethan23hours fortraining;the VGG16containsabout 32million trainableparametersandtakesmorethan16hoursfor training.AllthemodelsaretrainedonasingleNVIDIAGTX1080Ti GPU,and thenumber ofiteration is450 thousand. Forfair com-parisonswithotherframeworks,wetrainourmodelonthesame datasetas[32].Inordertopreventoverfitting,weperformrandom resizing,croppingandcoloraugmentationsforeach image before training.Inferencetakeslessthan25msperimage.
Intheprocessofoptimization,wesettheweightparametersas follows:
μ
1=1.0,μ
2=0.1/γ
,μ
3=1.0ν
1=1.0,ν
2=0.1/γ
,λ
1=1.0,λ
2=0.8α
=0.85,β
=0.85where
γ
isthedownscalingfactorofthelayerwhichcorresponds tothe resolutionofthe inputimage. Weuse Adamfor optimiza-tion withβ
1=0.9,β
2=0.999,=10−8. The initial learningrate
is0.0002forthefirst250thousanditerationsandhalvingituntil theend. Forthe activation function inthenetwork, we findthat exponentiallinearunits(ELU)canimprovetheaccuracycompares withrectifiedlinearunits (ReLU).The batch sizeis setto 2with eachtrainingsampleisastereoimagesequencewhichthelength issetto3.
Additional,an identicalweighting is usedfor theloss ofeach scale butled thenetwork to an unstable convergence.Moreover, wealsoemploy batchnormalizationinordertoimprovethe per-formance but findthat it is useless. In the final experiment, we excludeidenticalweightingandbatchnormalizationultimately.
4.4.Depthestimation
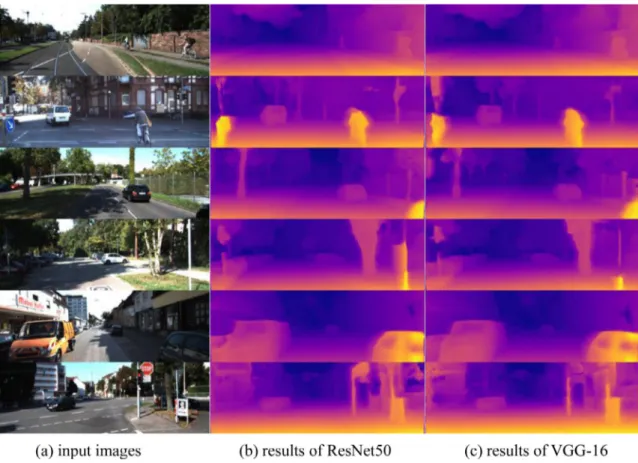
Nowadays, ResNet50 and VGG-16 networks have become the mostfamous CNN architectures. In order to compare the effects ofthesetwonetworks, we usethemasencodersto generatethe disparitymapsrespectively(asshowninFig.5)andgivethe quan-titiveresultsinTable1.
AsshowninTable1,thedifferencebetweentheResNet50and VGG-16networks reveal that theresults of ResNet50outperform that ofthe VGG-16. Qualitative comparisons can be visualized in
Fig.5. Therefore, we choose ResNet50 asan encoder ofour net-workarchitecture.
Fig.5. TheperformanceofmonoculardepthestimationbetweenResent50andVGG-16.
Fig.6. QualitativevisualresultsontheKITTIdataset.NotethattheestimationofthemodelwithELUasitsactivationfunctionisbetterthanthemodelwithReLUasits activationfunction.
D.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 9
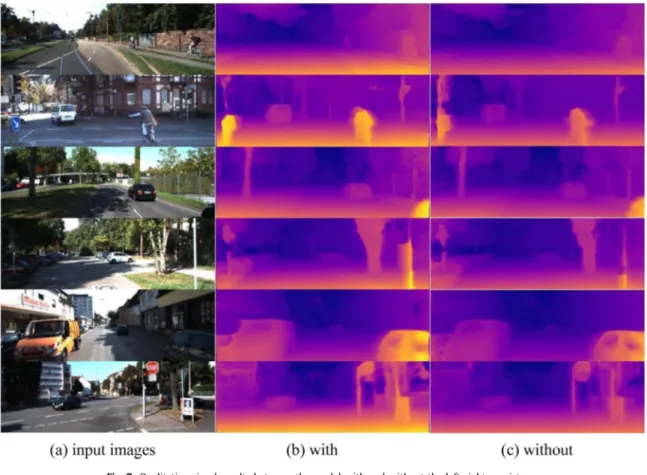
Fig.7. Qualitativevisualresultsbetweenthemodelwithandwithouttheleft-rightconsistency
Fig.8. Comparisonsofthemonoculardepthestimationresultsbetweengroundtruth,Zhouetal.[32],Geonet[33]andours.
Fig.9. ComparisonsofthemonoculardepthestimationresultsbetweenthemodelstrainedontheKITTIdataset,theCityscapesdataset,theKITTI+Cityscapesdatasets.
Fig.10. ComparisonsofthemonoculardepthestimationresultsbetweenthemodelstrainedontheKITTIdataset,theCityscapesdataset,theKITTI+Cityscapesdatasets.
D.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 11
Table1
ResultsofourmonoculardepthestimationmethodwiththeuseofResNet50networkandVGG networkfortraining.
Network
lowerisbetter higherisbetter
AbsRel SqRel RMSE REMSlg10 δ≤ 1.25 δ≤1.252 δ≤1.253 ResNet50 0.142 1.259 5.768 0.229 0.801 0.933 0.976 VGG-16 0.146 1.304 6.021 0.242 0.785 0.928 0..965
Table2
ResultsofourmethodwiththeuseofReLUandELUastheactivationfunctionfortraining. Activation
function
lowerisbetter higherisbetter
AbsRel SqRel RMSE REMSlg10 δ≤ 1.25 δ≤1.252 δ≤1.253 ReLU 0.151 1.325 5.957 0.242 0.793 0.905 0.967 ELU 0.142 1.259 5.768 0.229 0.801 0.933 0.976
Table3
Qualitativecomparisonsbetweenthemodelwithandwithouttheleft-rightconsistency. left-right
consistency
lowerisbetter higherisbetter
AbsRel SqRel RMSE REMSlg10 δ≤ 1.25 δ≤1.252 δ≤1.253 with 0.142 1.259 5.768 0.229 0.801 0.933 0.976 without 0.147 1.285 5.902 0.235 0.785 0.912 0.958
Table4
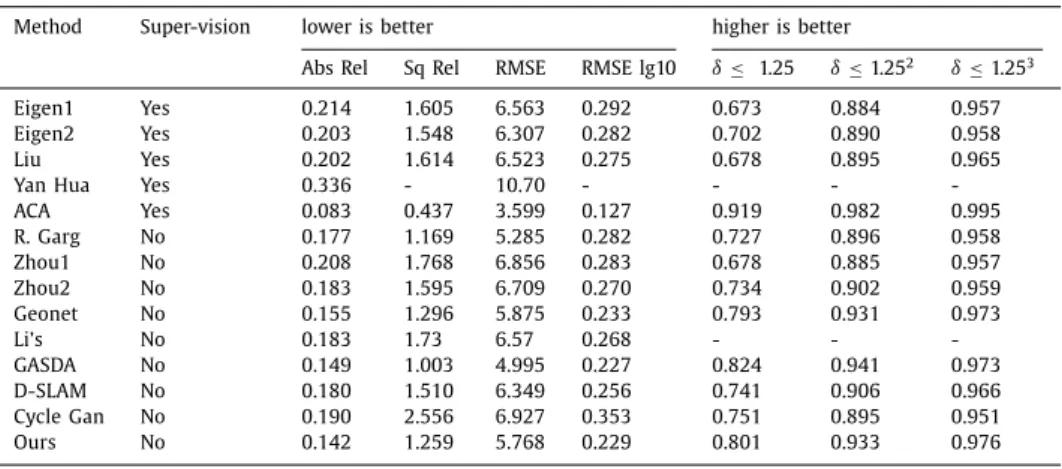
MonoculardepthestimationresultsonKITTI2015dataset.
Method Super-vision lowerisbetter higherisbetter
AbsRel SqRel RMSE RMSElg10 δ≤ 1.25 δ≤1.252 δ≤1.253 Eigen1 Yes 0.214 1.605 6.563 0.292 0.673 0.884 0.957 Eigen2 Yes 0.203 1.548 6.307 0.282 0.702 0.890 0.958 Liu Yes 0.202 1.614 6.523 0.275 0.678 0.895 0.965 YanHua Yes 0.336 - 10.70 - - - -ACA Yes 0.083 0.437 3.599 0.127 0.919 0.982 0.995 R.Garg No 0.177 1.169 5.285 0.282 0.727 0.896 0.958 Zhou1 No 0.208 1.768 6.856 0.283 0.678 0.885 0.957 Zhou2 No 0.183 1.595 6.709 0.270 0.734 0.902 0.959 Geonet No 0.155 1.296 5.875 0.233 0.793 0.931 0.973 Li’s No 0.183 1.73 6.57 0.268 - - -GASDA No 0.149 1.003 4.995 0.227 0.824 0.941 0.973 D-SLAM No 0.180 1.510 6.349 0.256 0.741 0.906 0.966 CycleGan No 0.190 2.556 6.927 0.353 0.751 0.895 0.951 Ours No 0.142 1.259 5.768 0.229 0.801 0.933 0.976
It is important to select a suitable activation function forthe design ofa CNN.Themostcommonlyused activation functionis therectifiedlinearunit(ReLU).However,throughexperiments,we foundthatthenetworkwiththeexponentiallinearunit(ELU)has amoreprecisepredictioncomparedwiththenetworkwithReLU.
Table2showsthequalitativecomparisonsontheKITTIdataset
andtheresultscanbevisualizedinFig.6.
Moreover, aleft-rightconsistency losspartisputforward.We usestereoimagepairsasinputdatafortrainingandeachofthem producesadisparitymap.Toachievemoreprecisedisparitymaps, theabsolutevalueoftheleftdisparitymapshouldbeequaltothat oftherightdisparitymap. Inordertoproof theleft-right consis-tency losspartcan improvethe accuracyofthe proposed model, weusetheobjectivefunctionwithouttheleft-rightconsistencyto trainthemodel.Table3showsthequalitativecomparisonsonthe KITTIdatasetandFig.7givesthevisualresults.
Wecompare ourproposed method withsome state-of-the-art depthestimationapproachesincluding(1)Eigenetal.[11]Coarse (Eigen1); (2) Eigen et al. [12] Fine (Eigen2); (3) Liu et al. [26];
(4) Yan Hua et al. [23]; (5) R. Garg et al. [13]; (6) Zhou et al.
[32](Zhou1);(7)Zhouetal.updated(Zhou2)[32];(8)Geonet[33];
(9) UndeepVo [43]; (10) GASDA [44]; (11) ACA (attention-based context aggregation method) [45]; (12) depth-SLAM [46]; (13)
Cycle-Gan[35].Thesemethodsincludeseveralsupervisedmethods and some unsupervised methods. The performance is shown in
Table4.
AsshowninTable4,ourunsupervisedapproachperforms com-parablywithseveralsupervisedmethodssuch asEigenetal.and Yanet al.we alsocompare our methodwithsome unsupervised methodsasbaselines.AsshowninTable4,ourmodeloutperforms mostapproaches but inferior to ACA [45] which introduces self-attentiontoa supervisedframework inallmeasurements.Weare Pleasecitethisarticleas:D.Yang,X.ZhongandD.Guetal.,Unsupervisedframeworkfordepthestimationandcameramotionprediction
Fig.11. Monoculardepthestimationresults.(a)Inputimages:inputimagescomefromtheEurocdatasetrandomly;(b)depthmaps(E):thegenerateddepthmapsbythe modelwhichistrainedontheEurocdataset,(c)depthmaps(K):thegenerateddepthmapsbythemodelwhichistrainedontheKITTIdataset.
alsoinferiortoGASDA[44]whichisbasedonthegeometry-aware symmetricdomainadaptationinpartofthemeasurements. More-over,forthe visual SLAMapproach [46] that addedunsupervised learning-based depth estimation,we achieve a better resultthan it.Fig.8provides some comparablevisual examples betweenour resultandthesebaselines.
To evaluate the generalization ability of ourmonocular depth estimation method,we apply our initial model whichtrained on KITTI dataset to estimate the disparity maps of the images se-lected from the Cityscapes dataset. The Cityscapes dataset we have used consists of stereo RGB image pairs, thus our method can train on this data directly. Here we train the model on the Pleasecitethisarticleas:D.Yang,X.ZhongandD.Guetal.,Unsupervisedframeworkfordepthestimationandcameramotionprediction
D.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 13
Fig.12. Monoculardepthestimationresults.(a)Inputimages:inputimagescomefromtheEurocdatasetrandomly;(b)depthmaps(K):thegenerateddepthmapsbythe modelwhichistrainedontheKITTIdataset,(c)depthmaps(E):thegenerateddepthmapsbythemodelwhichistrainedontheEurocdataset.
Cityscapesdatasetsolelyandshowthesamplepredictionsby this initial Cityscapes model, the test images come from the KITTI dataset.ThenweusetheKITTIdatasetandtheCityscapesdataset to train a new model. Moreover, we also give the depth esti-mation results of Zhou’s [32] and Geonet [33] that trained on these two datasets. Quantitative results on the test set of the KITTI dataset are shown in Table 5. In the table, ours (K) de-notes the model trained on the KITTIdataset, ours (CS) denotes the model trained on the Cityscapes dataset, ours (K+CS) de-notes the modeltrained on theKITTI datasetand the Cityscapes dataset.
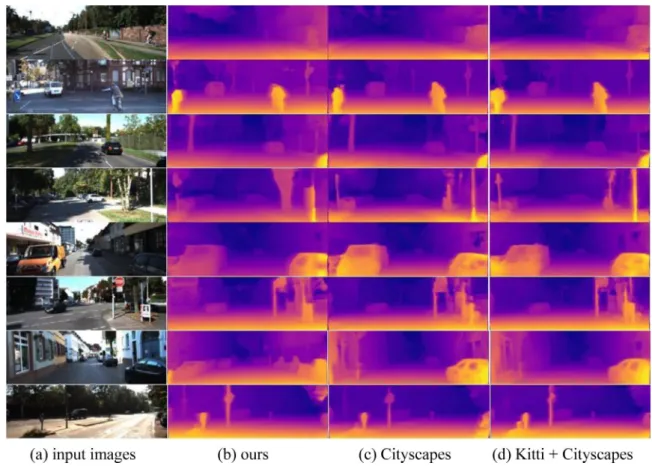
Fig.9 providesthe resultsofthe proposedmodel thattrained on the two datasets. Fig. 9 (a) is the raw input images selected from the KITTI dataset, Fig. 9 (b) and (c) are the visual results of our model that trained only on the KITTI dataset and the Cityscapesdatasetrespectively,Fig.9(c)isthevisualresultsofour modelthattrainedontheKITTIdatasetandtheCityscapesdataset. These pictures show that the model trainedon the two datasets produces superior results on thin structures such as trees and lamppost. The modeltrained onlyon theCityscapes dataset can-notcapturethedetailsontheboundariessuchascars.The exper-imental results show that the generalization abilityof themodel needstobestrengthened.Inaddition,weusetheimagesselected fromthe Cityscapesdataset to test ourmodels which trainedon theKITTIdatasetandtheCityscapesdataset.Theresultsareshown inFig.10.
AsshowninFig.10,(a)istherawinput imagesselectedfrom theCityscapesdataset,(b)isthegroundtruthcorrespondingtothe rawinput images,(c)and(d) arethe visual resultsofourmodel that trained on the KITTI dataset and the Cityscapes dataset re-spectively.
4.5. TrainingontheEurocdataset
Until now, all the models are trained on the KITTI and Cityscapesdatasets,imagesofthesetwo datasetsarecapturedon cars inoutdoorenvironments.Toexpand theapplicationrangeof our algorithm, we use the Euroc dataset to train the model. We
downloaded allthe rawdata fromtheofficial websiteofthe Eu-rocdataset.Forthesub-datasetnamedMH_01_easy.zipofthe Eu-rocdataset,thenumberofleftimagesis3682,butthenumberof rightimages is 2273,hence, we only use imagesof MH_01_easy subdatasetforinference.Thereststereoimagesofthedatasetare chosentotrainandtestourmodel.
We use the same architecture to train the model for the in-doorenvironment.22977stereoimagesareusedfortraining,and thetotalnumberofiteration stepsisabout280thousand. During training,differentimageenhancementtechnologiesareutilizedto increase thediversity ofthetraining data.Becauseof all the im-agesoftheEuroc datasetare monochrome,single-channelimages areemployedtoinference.
Asshowninfig.11,onlysingleimagesoftheEurocdatasetare requiredtogeneratethedepthmaps.Weusetwomodelsthatare trainedon the Euroc and KITTIdatasets respectively to infer the depth maps.The visual resultsof themodel which istrained on the Euroc dataset (Fig. 11(b)) are superior to that of the model whichistrainedon theKITTIdataset(Fig.11(c)).From Fig.11(c), we can hardly get depth information from the depth maps but theobjects suchasdesk, door,whiteboard areclearinFig. 11(b). The results demonstrate that the model which are trained on a relatively fixed scene can be only tested on the very similar scene.
4.6.Generalizationcapabilitytests
Dataset plays an important role in the performance of the trained model. To test the generalization capability of the pro-posed algorithm, we first use several images selected from the KITTIdatasetasinputtothemodels,thevisualresultsareshown inFig.12.Then we usesome imagescomefromvarious datasets as input to the different models respectively. The used datasets include the ICLNUIM dataset [46], SUN3D dataset [47] andTUM RGBD dataset [48] for indoor environments, and the nuScenes dataset [49] for outdoor environments. Experimental results for generalizationcapabilitytestsareshowninFig.13.
Fig.13. Generalizationcapabilitytests.(a)inputimagesdenotetheinputimagescomefromthedifferentdataset,(b)depthmaps(E)denotethegenerateddepthmapsby themodelwhichistrainedontheEurocdataset,(c)depthmaps(K)denotethegenerateddepthmapsbythemodelwhichtwo-lossontheKITTIdataset.
D.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 15
Table6
AbsoluteTrajectoryErroronKITTI2015odometrydataset. Method Seq.09 Seq.10 ORB-SLAM(full) 0.014±0.008 0.012±0.011 ORB-SLAM(short) 0.064±0.141 0.064±0.130 GeoNet 0.012±0.007 0.012±0.009 D-SLAM 0.017±0.008 0.015±0.017 Ours 0.012±0.006 0.012±0.007
AsshowninFig.12,weusethemodelwhichistrainedonthe KITTIdataset toestimate theoutdoor scenedepth, thevisual re-sultsare superior tothe depthmapswhich aregenerated bythe modeltrainedontheEurocdataset.Combinedwiththeresultsof
Fig.11,itisfurtherprovedthatthetestingsceneshouldbesimilar tothetrainingscene.
AsshowninFig.13(a),theinputimagesarecomefromthe ICL-NUIM,SUN3D,TUMRGB-DandnuScenesdatasets,fromtopto bot-tom.Twoimagesofeachdatasetarechosenfordisplay.The gener-ateddepthmapsbythetwomodelswhicharetrainedonthe Eu-rocandKITTIdatasetscanbeobtainedinFig.12(b)andFig.12(c), respectively.Forimagesthatcomefromthedatasetsthatare col-lectedinindoorenvironments, depthmaps(E) areobviously supe-riortothedepthmaps(K)andviceversa.
The experimentsofFig. 13reveal that theperformance ofthe model displaysstrongcorrelationswiththe traineddataset. Even thoughthepresentedtechniquehassomeadvantagessuchas real-timeprocess,pixel-wisegenerateddepthimages,onlyasingle im-age is required for inference, its generalization capability cannot comparewiththetraditionalmethods.
4.7. Cameraposeestimation
Inordertoevaluatetheperformance ofourposeCNN,we ap-ply ournetworkto theofficial KITTIodometrysplitthat contain-ing11drivingsequenceswithgroundtruthodometry.Theground truth odometryis obtainedthroughthe IMU andGPS. Wedivide these11sequencesintotwoparts: the00-08sequences for train-ing andthe 09-10sequencesfortesting. Wecompareourcamera poseestimationwithtwomonocular ORB-SLAMnamelyfull ORB-SLAM(using all framesof the driving sequence)and short ORM-SLAM(using 5 frames snippets). Moreover, we also compare our methodwithastate-of-the-artunsupervisedframeworkwhichhas done anythinglikeworkingfordepthestimationandcamera pre-diction.AsshowninTable6,eventhoughweuseshortsequences for training, our method outperforms these two competing baselines.
BycomparingwithtraditionalmethodssuchasORB-SLAM,we establish an end-to-end modelto compute all frames of a video whileORB-SLAMcreateskeyframestomeetthereal-time require-ment.Inaddition,themulti-octavestructureofCNNmakesus ex-tracthigh-levelfeaturesofeachframeinanautomaticway. There-forewecanobtaindenseimageinformationwhileORB-SLAMonly used thesparse map. However, thereare a few problemswe are unable tosolvenow.ORB-SLAMcan processmonocularimage se-quencesforindoorandoutdoorscenesbutwecanonlydealwith scenarios similar toourtrainingset.Because thestrategy of ana-lyzing big data to construct the model,the generalization ability of ORB-SLAM outperformsour model.Consequently,in our opin-ion, our model and ORB-SLAM are two different strategies and each method works better fordifferent application types.Maybe thecombinationofthesetwostrategies isthefutureresearch di-rection.Infact, thereare alreadysomemethods [46] take advan-tage of deep learning technologies to extend the source of the scene depthinformation andimprovetheperformance of the vi-sualSLAMsystem.
5. Conclusion
Inthiswork,weproposeajointlyunsupervisedlearning frame-work fordepth estimationandcamera motion estimation.Stereo image sequencesare usedfortrainingandmonocular imagesare usedfortesting.The utilizationofstereoimage sequencescannot onlyovercomescaleambiguityformonoculardepthestimationbut alsoimprovetheaccuracyofcameramotionpredictionfor tempo-ralimagesequences.Comparewiththepreviousworks,the perfor-manceof ourmethod is closeto supervised learningapproaches and better than most unsupervised methods. Moreover, experi-mentsforgeneralizationcapabilitytestsofthepresentedtechnique areconductedonmultipledatasets.
Therearestilla fewchallengestobementioned.Althoughthe resultsshow thatourmethodhassuperior accuracycompared to someexistingunsupervised methods,butdonotachieve state-of-the-artinallmetrics.Inaddition,ourunsupervisedframework as-sumesthesceneisstaticandthereisnoocclusioninthesceneso thatthismethodcannothandledynamicobjects.Inthefuture,an extensivestudyoftheobjectivefunctionfordepthestimationand CNNarchitecture fortackling dynamicobjects will be taken into consideration.
DeclarationofComeptingInterest
None.
Acknowldgements
We thankthe professorsof University ofEssex, Dongbing Gu, andHuosheng Hu for their help. We also thank the anonymous reviewersfortheirpositivecomments.Thispaperissupportedby
theFundamentalResearchFundsfortheCentralUniversitiesunder
Grant20720190129.
References
[1] F.Fraundorfer,C.Engels,D.Nistér,Topologicalmapping,localizationand nav-igationusing imagecollections, in:Proceedings ofthe IEEE Conferenceon IntelligenceRobotsandSystems,2007,pp.3872–3877,doi:10.1109/IROS.2007. 4399123.
[2] C.Chen,A.Seff,A.Kornhauser,J.Xiao,DeepDriving:Learningaffordancefor directperceptioninautonomousdriving„ in:ProceedingsoftheIEEE Confer-enceonComputerVision,2015,pp.2722–2730,doi:10.1109/ICCV.2015.312. [3] D.Scharstein,R.Szeliski,High-accuracystereodepthmapsusingstructured
light,in:ProceedingsoftheIEEEConferenceonComputerVisionandPattern Recognition,2003,pp.195–202,doi:10.1109/cvpr.2003.1211354.
[4] J.Zhu,L.Wang,R.Yang,J.E.Davis,Z.Pan,Reliabilityfusionoftime-of-flight depthandstereogeometryforhighqualitydepthmaps,IEEETrans.Pattern Anal.Mach.Intell.33(2011)1400–1414,doi:10.1109/TPAMI.2010.172. [5] S.G.Wysoski,L.Benuskova,N.Kasabov,Fastandadaptivenetworkofspiking
neuronsformulti-viewvisualpatternrecognition,Neurocomputing71(2008) 2563–2575,doi:10.1016/j.neucom.2007.12.038.
[6] C. Hernandez, G. Vogiatzis, R. Cipolla, Multiview photometric stereo, IEEE Trans.PatternAnal.Mach.Intell.30(2008)548–554,doi:10.1109/TPAMI.2007. 70820.
[7] Y.Bahroun,A.Soltoggio,Onlinerepresentationlearningwithsingleand multi-layerhebbiannetworksforimageclassification,in:Proceedingsofthe Inter-nationalConferenceonArtificialNeuralNetworks,2017,pp.354–363,doi:10. 1007/978-3-319-68600-4_41.
[8] W.Luo,A.G.Schwing,R.Urtasun,EfficientDeepLearning forStereo Match-ing,in:ProceedingsoftheIEEEConferenceonComputerVisionandPattern Recognition,2016,pp.5695–5703,doi:10.1109/cvpr.2016.614.
[9] Y. Gao, A.L. Yuille, Symmetric non-rigid structure from motion for category-specific object structure estimation, in: Proceedings of the Eu-ropean Conference on Computer Vision, 2016, pp. 408–424, doi:10.1007/ 978-3-319-46475-6_26.
[10]Y.Gao,A.L.Yuille,Exploitingsymmetryand/ormanhattanpropertiesfor3D objectstructureestimationfromsingleandmultipleimages,in:Proceedings ofthe IEEE Conferenceon ComputerVisionand Pattern Recognition,2017, pp.6718–6727,doi:10.1109/CVPR.2017.711.
[11]D.Eigen,C.Puhrsch,R.Fergus,DepthMapPredictionfromaSingleImage us-ingaMulti-Scale DeepNetwork,AdvancesinNeuralInformationProcessing Systems(2014)2366–2374,doi:10.1007/978-3-540-28650-9_5.
fromexamples,in:Proceedingsofthe IEEEConferenceonComputerVision andPatternRecognitionWorkshops,2012,pp.16–22,doi:10.1109/CVPRW.2012. 6238903.
[18] K.Karsch,C.Liu,S.B.Kang,Depthextractionfromvideousingnon-parametric sampling,IEEETrans.PatternAnal.Mach.Intell.36 (2014)775–788,doi:10. 1007/978-3-642-33715-4_56.
[19] R.Mur-Artal,J.M.M.Montiel,J.D.Tardos,ORB-SLAM:AVersatileandAccurate MonocularSLAMSystem,IEEETrans.Rob.31(2015)1147–1163,doi:10.1109/ TRO.2015.2463671.
[20]J.Ma,H.Zhou,J.Zhao,Y.Gao,J.Jiang,J.Tian,RobustFeatureMatchingfor RemoteSensingImageRegistrationviaLocallyLinearTransforming,IEEETrans. Geosci.RemoteSens.53(2015)6469–6481,doi:10.1109/TGRS.2015.2441954. [21]I.Laina,C.Rupprecht,V.Belagiannis,F.Tombari,N.Navab,Deeperdepth
pre-dictionwithfullyconvolutionalresidualnetworks,in:ProceedingsoftheIEEE InternationalConference on3D Vision,2016,pp.239–248,doi:10.1109/3DV. 2016.32.
[22]J. Li,R.Klein, A.Yao,A Two-StreamedNetworkfor Estimating Fine-Scaled DepthMapsfromSingleRGBImages,in:ProceedingsoftheIEEEConference onComputerVision,2017,pp.3392–3400,doi:10.1109/ICCV.2017.365. [23]H.Yan,S.Zhang,Y.Zhang,L.Zhang,Monoculardepthestimationwith
guid-anceofsurfacenormalmap,Neurocomputing280(2018)86–100,doi:10.1016/ j.neucom.2017.08.074.
[24]B.Li,C.Shen,Y.Dai,A.VanDenHengel,M.He,Depthandsurfacenormal es-timationfrommonocularimagesusingregressionondeepfeaturesand hier-archicalCRFs,in:Proc.IEEEComput.Soc.Conf.Comput.Vis.PatternRecognit. 07-12-June,2015,pp.1119–1127,doi:10.1109/CVPR.2015.7298715.
[25]A.Roy,S.Todorovic,MonocularDepthEstimationUsingNeuralRegression For-est,in:ProceedingsoftheIEEEConferenceonComputerVisionand Pattern Recognition,2016,pp.5506–5514,doi:10.1109/cvpr.2016.594.
[26]F.Liu,C.Shen,G.Lin,Deepconvolutionalneuralfieldsfordepthestimation from asingle image,in: Proceedingsof theIEEE Conference on Computer Visionand PatternRecognition, 2015,pp.5162–5170,doi:10.1109/CVPR.2015. 7299152.
[27]E.Ilg,N.Mayer,T.Saikia,M.Keuper,A.Dosovitskiy,T.Brox,FlowNet2, Evolu-tionofopticalflowestimationwithdeepnetworks,in:ProceedingsoftheIEEE ConferenceonComputerVisionandPatternRecognition,2017,pp.1647–1655, doi:10.1109/CVPR.2017.179.
[28]J.J.Yu,A.W.Harley,K.G.Derpanis,Back tobasics:Unsupervised learningof opticalflowviabrightnessconstancyandmotionsmoothness,in:Proceedings oftheEuropeanConferenceonComputerVision,2016,pp.3–10,doi:10.1007/ 978-3-319-49409-8_1.
[29]C.Godard,O.MacAodha,G.J.Brostow,Unsupervisedmonoculardepth esti-mationwithleft-rightconsistency,in:ProceedingsoftheIEEEConferenceon ComputerVisionand PatternRecognition, 2017,pp.6602–6611,doi:10.1109/ CVPR.2017.699.
[30]Y.Kuznietsov,J.Stückler,B.Leibe,Semi-superviseddeeplearningfor monocu-lardepthmapprediction,in:ProceedingsoftheIEEEConferenceonComputer Visionand PatternRecognition,2017,pp.2215–2223,doi:10.1109/CVPR.2017. 238.
[31] Y.Hua,H.Tian,Depthestimationwithconvolutionalconditionalrandomfield network,Neurocomputing214(2016)546–554,doi:10.1016/j.neucom.2016.06. 029.
[32]T.Zhou,M.Brown,N.Snavely,D.G.Lowe,Unsupervisedlearningofdepthand ego-motionfromvideo,in:ProceedingsoftheIEEEConferenceonComputer VisionandPatternRecognition,2017, pp.6612–6621, doi:10.1109/CVPR.2017. 700.
[33]Z.Yin,J.Shi,GeoNet:UnsupervisedLearningofDenseDepth,OpticalFlowand CameraPose,in:ProceedingsoftheIEEEConferenceonComputerVisionand PatternRecognition,2018,pp.1983–1992,doi:10.1109/CVPR.2018.00212. [34]Y.Luo,J.Ren,M.Lin,J.Pang,W.Sun,H.Li,L.Lin,SingleViewStereo
Match-ing,in:ProceedingsoftheIEEEConferenceonComputerVisionandPattern Recognition,2018,pp.155–163,doi:10.1109/CVPR.2018.00024.
U.Franke,S.Roth,B.Schiele,TheCityscapesDatasetforSemanticUrbanScene Understanding, in:Proceedings ofthe IEEEConference onComputerVision andPatternRecognition,2016,pp.3213–3223,doi:10.1109/CVPR.2016.350. [41]K.Simonyan,A.Zisserman,Verydeepconvolutionalnetworksforlarge-scale
image recognition,Proceeding ofthe International Conference on Learning Representations,2015,pp.1–14.
[42]K.He,X.Zhang,S.Ren,J.Sun,DeepResidualLearningforImageRecognition, in:ProceedingsoftheIEEEConferenceonComputerVisionandPattern Recog-nition,2015,pp.770–778,doi:10.1109/CVPR.2016.90.
[43]R.Li,S.Wang,Z.Long,D.Gu,UnDeepVO:MonocularVisualOdometrythrough UnsupervisedDeepLearning,in:ProceedingsoftheIEEEInternational Confer-enceonRoboticsandAutomation,2017,pp.7286–7291,doi:10.1109/ICRA.2018. 8461251.
[44]S.Zhao,H.Fu,M.Gong,D.Tao,Geometry-AwareSymmetricDomain Adapta-tionforMonocularDepthEstimation,in:ProceedingsoftheIEEEConference on Computer Visionand Pattern Recognition, 2019, pp.9788–9798.http:// arxiv.org/abs/1904.01870.
[45]Y. Chen, H. Zhao, Z.Hu, Attention-based context aggregation networkfor monoculardepthestimation,CoRR(2019)abs/1901.10137.
[46]M. Geng, S. Shang, B. Ding, H. Wang, P. Zhang, L. Zhang, Unsupervised Learning-basedDepthEstimationaidedVisualSLAMApproach,CircuitsSyst. SignalProcess.(2019)1–28,doi:10.1007/s00034-019-01173-3.
[47]A.Handa,T.Whelan,J.McDonald,A.J.Davison, AbenchmarkforRGB-D vi-sualodometry,3DreconstructionandSLAM,in:ProceedingsoftheIEEE In-ternational Conference on Robotics and Automation, 2014, pp. 1524–1531, doi:10.1109/ICRA.2014.6907054.
[48]J.Xiao,A.Owens,A.Torralba,SUN3D:Adatabaseofbigspacesreconstructed usingSfMandobjectlabels,in:ProceedingsoftheIEEEConferenceon Com-puterVision,2013,pp.1625–1632,doi:10.1109/ICCV.2013.458.
[49]J.Sturm,W.Burgard,D.Cremers,EvaluatingEgomotionand Structure-from-Motion Approaches Using the TUM RGB-D Benchmark, in: Proceedings of the International ConferenceonIntelligent RobotsandSystems, IEEE,2012, pp.299–319,doi:10.1136/ICRA.2012.45940.
DelongYangreceivedtheB.Sc.inSchoolofMathematical SciencefromHuaibeiNormalUniversity,Huaibei,China, andtheM.Sc.inSchoolofSciencefromJimeiUniversity, Xiamen,China.HeiscurrentlypursuingthePh.D.degree intheDepartmentofAutomation,XiamenUniversity, Xi-amen,China.Hisresearchinterestsincluderobotics, com-putervision,deeplearningandimageprocessing.
XunyuZhongreceivedtheM.E.degreeinmechatronics engineeringfromHarbinEngineeringUniversity,Harbin, Heilongjiang,China,in2007andthePh.D.degreein con-troltheory and control engineering from Harbin Engi-neeringUniversity,in2009.HeiscurrentlyanAssociate Professorwith the Department of Automation, Xiamen University, Xiamen, China. His current research inter-estsincluderobotmotionplanning,autonomousrobotics, deeplearningandcomputervision.
D.Yang,X.ZhongandD.Guetal./Neurocomputingxxx(xxxx)xxx 17
DongbingGu(SM’07) receivedthe B.Sc.and M.Sc. de-grees in control engineeringfrom the Beijing Institute ofTechnology, Beijing, China, and the Ph.D. degreein roboticsfromtheUniversityofEssex,Colchester,U.K.He wasanAcademicVisitingScholar attheDepartment of EngineeringScience, University ofOxford, Oxford, U.K., from 1996 to1997. In 2000, he joined the University of Essex as a Lecturer, where he is a Professor with theSchoolofComputerScienceandElectronic Engineer-ing.Hiscurrentresearchinterestsincluderobotics, multi-agentsystems,cooperativecontrol,modelpredictive con-trol,visualSLAM,wirelesssensornetworks,andmachine learning.
XiafuPengreceivedtheM.S.andPh.D.degreesin con-trolscience fromthe Harbin EngineeringUniversity,in 1994 and 2001 respectively. He is currently a Profes-sorwiththeDepartmentofAutomation,Xiamen Univer-sity,Xiamen,Chian.Hiscurrentresearchinterestsinclude thenavigationand motioncontrolofrobots.Prof.Peng is aFellow of the Fujian Association for the advance-mentofAutomationandPower,andaSeniorMemberof theChineseInstitute ofElectronics.He isthe recipient oftheprovincial/ministerialScientificand Technological ProgressAward.
Huosheng Hu (M’94–SM’01)received the M.Sc. degree inindustrial automation fromCentral SouthUniversity, China, in 1982, and the Ph.D.degree inrobotics from theUniversityofOxford,U.K.,in1993.Heiscurrentlya ProfessorwiththeSchoolofComputerScienceand Elec-tronicEngineering,UniversityofEssex,U.K.,leadingthe Robotics ResearchGroup.His research interestsinclude behavior-based robotics,human– robotinteraction, em-beddedsystems,multi-sensordatafusion,machine learn-ing algorithms,mechatronics,pervasivecomputing,and servicerobots.Hehasauthoredover500papersin jour-nals,books,andconferencesintheseareas.Heisafellow oftheInstituteofEngineeringandTechnologyandthe In-stituteofMeasurementandControl,U.K.,andaCharteredEngineer.Hereceiveda numberofbestpaperawards.HehasbeentheProgramChairoramemberofthe AdvisoryCommitteeofmanyIEEEinternationalconferences,suchastheIEEEICRA, IROS,ICMA,andROBIO.HecurrentlyservesastheEditor-in-Chiefofthe Interna-tionalJournalofAutomationandComputingandtheOnlineRoboticsJournalandthe ExecutiveEditoroftheInternationalJournalofMechatronicsandAutomation.