Http://www.ijetmr.com©International Journal of Engineering Technologies and Management Research [9]
BIG DATA
Abhishek Dubey *1
*1
ASET, Amity University Madhya Pradesh, India Abstract:
The term 'Big Data' portrays inventive methods and advances to catch, store, disseminate, oversee and break down petabyte-or bigger estimated sets of data with high-speed & diverted structures. Enormous information can be organized, non-structured or half-organized, bringing about inadequacy of routine information administration techniques. Information is produced from different distinctive sources and can touch base in the framework at different rates. With a specific end goal to handle this lot of information in an economical and proficient way, parallelism is utilized. Big Data is information whose scale, differences, and unpredictability require new engineering, methods, calculations, and investigation to oversee it and concentrate esteem and concealed learning from it. Hadoop is the center stage for organizing Big Data, and takes care of the issue of making it valuable for examination purposes. Hadoop is an open source programming venture that empowers the dispersed handling of huge information sets crosswise over bunches of ware servers. It is intended to scale up from a solitary server to a huge number of machines, with a high level of adaptation to non-critical failure.
Keywords: Big Data; Hadoop; HDFS; Map Reduce Architecture.
Cite This Article: Abhishek Dubey. (2018). “BIG DATA.” International Journal of
Engineering Technologies and Management Research, 5(2:SE), 9-13. DOI:
https://doi.org/10.29121/ijetmr.v5.i2.2018.606.
1. Introduction
Http://www.ijetmr.com©International Journal of Engineering Technologies and Management Research [10]
2. Problem for Hetrogeneity and Incompleteness
At the point when people devour data, a lot of heterogeneity is serenely endured. Indeed, the Subtlety and abundance of normal dialect can give significant profundity. Notwithstanding, machine investigation calculations expect homogeneous information, and can't comprehend subtlety. In result, information must be precisely organized as an initial phase in (or before) information investigation. PC frameworks work most effectively on the off chance that they can save various things that are all indistinguishable in amount & structure. Proficient representation, get to, & examination of half-organized.
2.1.Security
The security of information is another enormous concern, and one that increments with regards to Big Info. For electrical well-being records, there are strong laws administering what should and cannot be possible. For other information, controls, especially in the United Space, are less powerful. Be that as it may, there is awesome open dread with respect to the wrong utilization of individual information, especially through connecting of information from different sources. Overseeing security is adequately both a specialized and a sociological issue, which must be tended to mutually from both points of view to understand the guarantee of huge information.
2.2.Size
The first thing comes in mind is related to its size. Of course, the term „Big‟ is there in the very name. The most challenging part in the decade is to manage this large amount of data which is rapidly increasing. This test was diminish by CPU getting speedier, after Moore's law, to give us the assets expected to adapt to expanding volumes of information. Yet, there is a crucial move in progress now: information amount is scaling quicker than the process assets, and processors pace are at rest.
2.3.Quickness
The inverse side of scale is its pace. The dissecting time of information is specifically relative to its size i.e. bigger the information set to be handled longer the time is expected to investigate it. The outline of a framework that successfully manages scale is likely additionally to bring about a framework that cans procedure an entered scale of information set speedier. In any case, it is not only this speed is normally implied when one talks about Velocity with regards to Big Data. Or Maybe, there is an obtaining rate challenge.
2.4.Human Support
Http://www.ijetmr.com©International Journal of Engineering Technologies and Management Research [11]
various areas to truly comprehend what is going on. A Big Data examination framework must bolster include from various human specialists, and shared investigation of results. These various specialists might be isolated in space and time when it is excessively costly, making it impossible to collect a whole group together in one room. The information framework needs to acknowledge this dispersed master information, and bolster their joint effort.
3. Solution for Processing on Big Data
Hadoop is a framework used to support the get readied of basic data sets in a scattered figuring environment. Hadoop was passed on by Google's MapReduce that is a thing structure where applications disengage into various parts. The Current Appache Hadoop structure contains the Hadoop Kernel, MapReduce.
3.1.HDFS Architecture
HDFS can store gigantic measures of info, size up increasingly and without dying the mistake of key parts the very pinnacle of structure without loss data. This system makes packs of machines and arranges work among them. Packs can be worked with sensible PCs. If one misses the mark, Hadoop continues working the bundle without losing data or barging in with work, by moving work to whatever is left of the machines in the get-together. HDFS coordinates keep on the party by breaking drawing nearer records into pieces, called "squares," and securing each of the pieces pointlessly over the pool of servers. In the fundamental case, HDFS stores three complete copies of each record by reiterating each piece to three unmistakable servers.
Figure 1: Hadoop Distributed File System Architecture
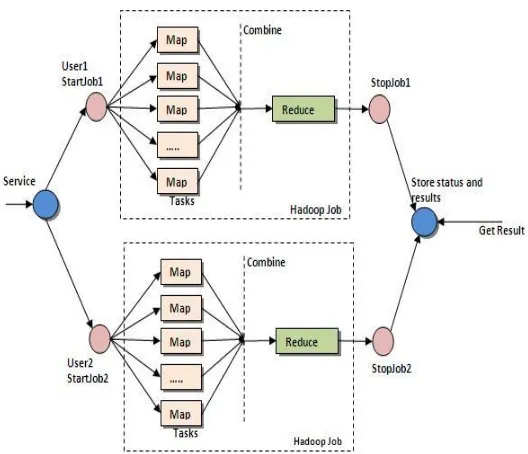
3.2.Map Reduce Architecture
Http://www.ijetmr.com©International Journal of Engineering Technologies and Management Research [12]
circumstance, this might involve applying an ETL operation on the information to deliver something usable by the expert.
In Hadoop, these sorts of operations are composed as Map Reduce occupations in Java. There are various more elevated amount dialects like Hive and Pig that make composing these projects less demanding. The yields of these occupations can be composed back to either HDFS or set in a conventional information stockroom. There are two capacities in Map Reduce are map and reduce.
Figure 2:Map Reduce Architecture
This section should provide enough detail to allow full replication of the study by suitably skilled investigators. Protocols for new methods should be included, but well-established protocols may simply be referenced. We encourage authors to submit, as separate supporting information files, detailed protocols for newer or less well-established methods.
An important aspect of all scientific research is that it be repeatable. This gives validity to the conclusions. The materials and methods section of a manuscript allow other interested researchers to be able to conduct the experience to expand on what was learned and further develop the ideas. It is for this reason that this section of the paper be specific. It must include a step-by-step protocol along with detailed information about all reagents, devices, and subjects used for the study. How the data was constructed, collected, and interpreted should also be outlined in detail, including information on all statistical tests used.
4. Conclusion
Http://www.ijetmr.com©International Journal of Engineering Technologies and Management Research [13]
issues regarding Big data are its size, non-homogeneity and non-structured data. The paper also includes the HDFS architecture and map. The paper depicts HADOOP which is an open source programming used for treatment of Big data.
References
[1] Jonathan Stuart Ward and Adam Barker “Undefined By Data: A Survey of Big Data Definitions” Stamford, CT: Gartner, 2012.
[2] Balaji Palanisamy, Member, IEEE, Aameek Singh, Member, IEEE Ling Liu, Senior Member, IEEE” Cost-effective Resource Provisioning for MapReduce in a Cloud” gartner report 2010, 25
*Corresponding author.