Episode Discovery from Event Evolution
Full text
Figure
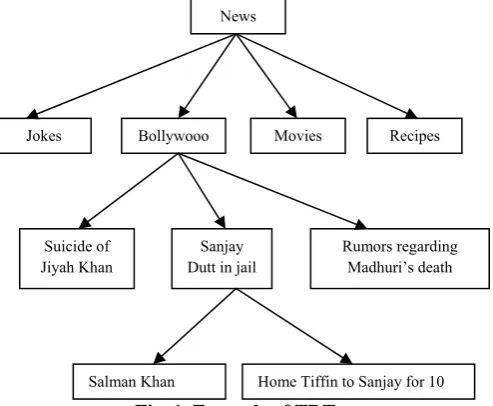
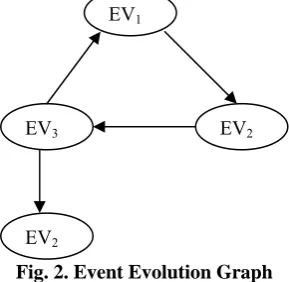
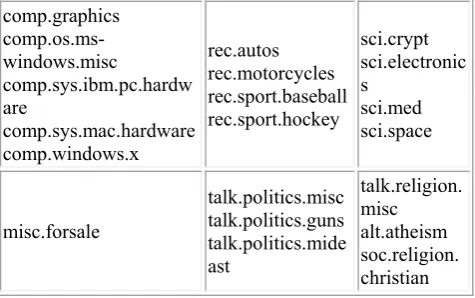
Related documents
Small groups that are formed and meeting are Men’s Bible Study, Men’s prayer group, Women’s Bible Study, and adult Sunday school. We still have a need for volunteers to help with
The Town of Mammoth Lakes will continue to be proactive in providing services, programs and keeping all of the people of Mammoth Lakes safe and supporting
Inside Clean Energy: New data from the Energy Information Administration show coal tanking, solar surging, wind growing fast and electricity usage remaining stable.
Volunteers included members of the Rotary Club of Wells, Rotarians from the Ogunquit Rotary Club and several students from the Wells High School Rotary Interact
The purpose of this dissertation was to: (1) conduct a systematic literature review to evaluate the quality of the evidence base on social skills interventions (SSIs) for
Management uses the combined loss and expense ratio calculated in accordance with statutory accounting principles applicable to property and casualty insurance companies to
Management uses the combined loss and expense ratio calculated in accordance with statutory accounting principles applicable to property and casualty insurance companies to
As we continue to bring the word of God to Immanuel Lutheran Church, we find ourselves in a challenging time in the life of this congregation.. With the upcoming retirement of
