ABSTRACT
FONSECA, ALEJANDRO. Iterative Multi-Bounce Global Illumination Through Brute-Force Rasterization-Based Sampling. (Under the direction of Benjamin Watson.)
We present an extension of Hachisuka’s Parthenon final gather algorithm, that computes
partial multi-bounce global illumination effects at interactive frame rates. Our contribution re-lies in the application of a brute-force approach to further parallelize global directional sampling
via multi-depth and multi-direction, single-pass geometry processing with the aid of the
graph-ics processing unit (GPU). Our method’s main advantages are based on its complete reliance on the GPU, its compatibility with typical rasterization-based techniques, its support for fully
dynamic scenes, and its conceptual simplicity. Overall results analysis exposes the algorithm’s
c
Copyright 2011 by Alejandro Fonseca
Iterative Multi-Bounce Global Illumination Through Brute-Force Rasterization-Based Sampling
by
Alejandro Fonseca
A thesis submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Master of Science
Computer Science
Raleigh, North Carolina
2011
APPROVED BY:
Christopher Healey Robert M. Young
DEDICATION
I would like to dedicate this work to everyone who has been a part of my life until now. Every
moment that I have spent interacting with the world, I have gained knowledge that has lead me to be the person that I am today. This is why, the contribution made today through this
work, could not have been achieved without any of the people who have crossed my path to
BIOGRAPHY
Alejandro Fonseca was born in Medell´ın, Antioquia, Colombia on August 6 of 1985. After
moving to North Carolina, United States in 2001, he completed High School and two years of community college before transferring to North Carolina State University where he obtained
his B.S. in Computer Science on December of 2007. On January of 2009, he enrolled in the
M.S. program at North Carolina State University, where we began his research on GPU-based interactive global illumination under the supervision of Dr. Benjamin Watson. His research
interests include photo-realistic rendering and global illumination, and real-time GPU-based
ACKNOWLEDGEMENTS
First, I would like to start by thanking my mother, my father, and my sister, who are a part of
me and to whom I owe a great part of the personal strength that has let me achieve this thesis as well as many more things in life.
Secondly, I would like to thank the great institution of North Carolina State University,
which has adopted me for a total of four years and never gave up on me. I would like to thank the Department of Computer Science, all the staff, and all my professors. I would like
to thank Dr. Robert M. Young and Dr. Christopher Healey for agreeing to be a part of my
thesis committee, and I would like to extend my special gratitude to Dr. Benjamin Watson who believed in me and gave me the opportunity to work in a great project that will hopefully
become a stepping stone for much more innovation to come. Additionally, I would like to thank
David Luebke from NVIDIA Corporation, who has provided good input in order to help gear this project in the right direction; and also, to Daniel Whright and Marting Mittring from Epic
Games, who helped me improve my perspective on this work through their thoughts and ideas.
Finally, I would like to thank all my friends that were there with me when the books and the bits were not, because the additional colors that they provide, help me paint a much clearer
TABLE OF CONTENTS
List of Tables . . . vi
List of Figures . . . vii
1 Introduction . . . 1
2 Related Work. . . 3
2.1 Ray Tracing . . . 3
2.2 Photon Mapping . . . 3
2.3 Classic Radiosity . . . 4
2.4 Other Approximations . . . 5
3 Algorithm . . . 7
3.1 Overview . . . 7
3.2 Data Structures . . . 8
3.3 Pseudocode . . . 9
3.4 Rasterization-Based Sampling . . . 11
3.5 Global Illumination . . . 13
3.6 Implementation Details . . . 16
4 Results . . . 18
4.1 Speed . . . 18
4.2 Quality . . . 26
4.3 An Informed Guess . . . 29
5 Discussion and Future Work . . . 34
6 Conclusion . . . 35
LIST OF TABLES
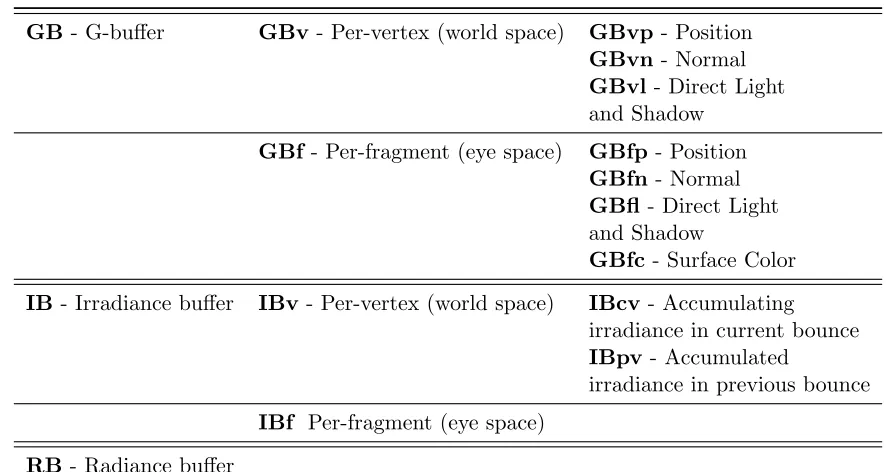
Table 3.1 Algorithm Buffers . . . 9
Table 3.2 Pseudocode . . . 10
Table 4.1 Performance Testing Parameters . . . 20
Table 4.2 Geometric Levels Of Detail (LOD) (vertices/triangles) . . . 20
LIST OF FIGURES
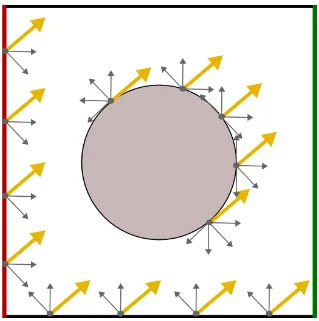
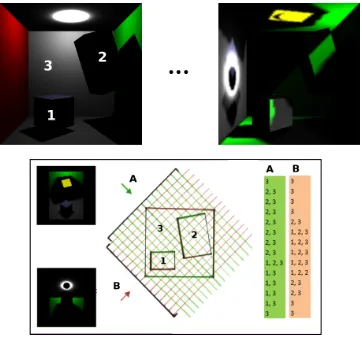
Figure 3.1 Our (and Hachisuka’s) approach samples globally defined directions (yel-low arrows), while other techniques sample locally defined directions (gray arrows). . . 11 Figure 3.2 Simplified Illustration of Sampling.. Illustration of sampling of
Cor-nell box scene, containing objects 1, 2, and 3, (top-left) in directions A and B (bottom). Scene is rasterized in each direction. Lists on right illustrate object fragment data that gets stored in each per-pixel, per-direction ar-ray (bottom). Data is then projected onto the scene’s geometry (top-right). 14 Figure 3.3 Irradiance Neighborhood. Each vertex is passed the indices to its
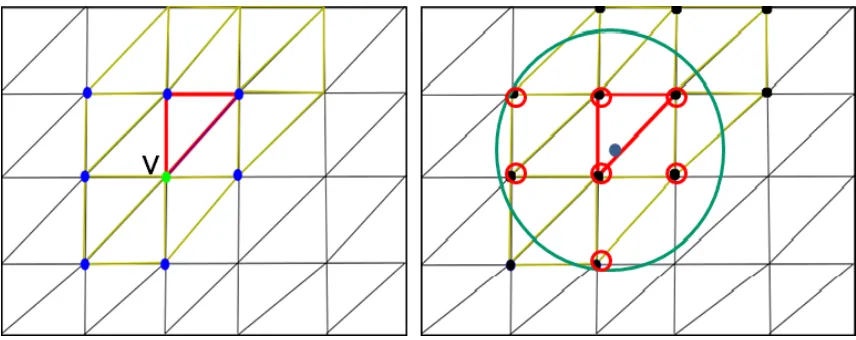
neighbor vertices, which are defined at mesh compile time (left). Each fragment interpolates irradiance from the neighbor vertices of the trian-gle to which it belongs that are within a radius slightly larger than the triangle’s longest edge (right). . . 16 Figure 3.4 Direct light (left), indirect light (middle), direct plus indirect light (right) 17
Figure 4.1 Reference images generated with Maya’s MentalRay (left) and with high resolution sampling of our algorithm (right). Cornell Box (top), museum (middle), kitchen (bottom). . . 19 Figure 4.2 BCount of Per-Fragment Gather. Speed in seconds (top) and RMSD
(bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) 21 Figure 4.3 BCount of Per-Vertex Gather. Speed in seconds (top) and RMSD
(bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) . . . 22 Figure 4.4 BDCount of Per-Fragment Gather. Speed in seconds (top) and
RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) . . . 22 Figure 4.5 BDCount of Per-Vertex Gather. Speed in seconds (top) and RMSD
(bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) . . . 23 Figure 4.6 FDCount of Per-Fragment Gather. Speed in seconds (top) and
RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) . . . 23 Figure 4.7 FDCount of Per-Vertex Gather. Speed in seconds (top) and RMSD
(bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) . . . 24 Figure 4.8 RBRes of Per-Fragment Gather. Speed in seconds (top) and RMSD
(bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) 24 Figure 4.9 RBRes of Per-Vertex Gather. Speed in seconds (top) and RMSD
Figure 4.10 LOD of Per-Fragment Gather. Speed in seconds (top) and RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right) . . . 25 Figure 4.11 LOD of Per-Vertex Gather. Speed in seconds (top) and RMSD
(bot-tom) for each scene: Cornell box (left), museum(middle), kitchen (right) . 26 Figure 4.12 Overall performance obtained in seconds (vertical axis), with different
triangle counts (horizontal axis). Per-fragment final gather (top) and per-vertex final gather (bottom) . . . 27 Figure 4.13 Results with low resolution per-fragment final gather. Edge preserving
filter applied to final image (left) (0.6148s), no filter used (right) (0.581s). Both images are generated with LOD4(1458/2304), 128x128 RBRes, 3 BCount, 220 BDCount, 660 FDCount. . . 28 Figure 4.14 Visual artifact caused by low RBRes. High RBRes (left), low RBRes in
per-fragment final gather (middle), low RBRes in per-vertex final gather (right). . . 28 Figure 4.15 Visual trade-off between LOD and FDCount for per-vertex final gather.
Top, left to right: LOD4(1458/2304), 880 FDCount, 0.295s; LOD5(5202/9216), 880 FDCount, 0.6502s; LOD6(19602/36864), 880 FDCount, 1.998s.
Bot-tom, left to right: LOD6(19602/36864), 440 FDCount, 1.6182s; LOD6(19602/36864), 880 FDCount, 2.2728s; LOD6(19602/36864), 1320 FDCount, 2.874s. All
images were generated with 32x32 RBRes, 2 BCount, 220 BDcount, and no post-processing filter. . . 29 Figure 4.16 Cornell box generated using per-fragment final gather (left), achieved
with LOD3(450/576), RBRes 128x128, 3 BCount, 220 BDCount, 1320 FDCount, and edge preserving filter (463.8ms, 2fps). Using per-vertex final gather (right), achieved with LOD4(1458/2304 ), RBRes 32x32, 2 BCount, 220 BDCount, and 880 FDCount, and edge preserving filter (312.4ms, 3fps)(Screen Resolution 720x720). . . 30 Figure 4.17 Museum scene generated using per-fragment final gather (top), achieved
with LOD3(6773/11038), RBRes 256x256, 2 BCount, 44 BDCount, 990 FDCount, and edge preserving filter (1.39s). Using per-vertex final gather (bottom), achieved with LOD3(6773/11038), RBRes 32x32, 2 BCount, 220 BDCount, and 880 FDCount (0.7282s)(Screen Resolution 1024x720). 32 Figure 4.18 Kitchen scene generated using per-fragment final gather (top), achieved
1 Introduction
The indirect lighting and shadow effects obtained using global illumination algorithms are
a critical component of realism in computer graphics imagery. Yet, the complexity of the computations accurate global illumination requires has kept implementations from achieving
real-time or even interactive performance. Fortunately, recent advances in graphics processing
unit (GPU) architecture have allowed real progress toward the achievement of interactive global illumination [13] [22] [33] [35] [38].
Our own contribution in this effort is a brute force extension of the rasterization-based
final gather algorithm introduced by Hachisuka’s Parthenon renderer [13]. Where Hachisuka implemented only global illumination’s final gather (a high resolution sampling of the last
reflection of light before it reaches the eye) on the GPU, our method implements the entire global
illumination simulation on the GPU. To improve speed, we take advantage of new features in the latest GPU architectures that allow processing of multiple depths and views in a single pass.
Although current performance does not match that of the current fastest published algorithms
[22] [35] [38] [17], we provide plausible results at interactive speeds and suggest directions for improvement in the short term. The main advantages our algorithm offers are:
• Scalability: Our approach is completely reliant on traditional GPU-based rasterization,
and requires minimal CPU-GPU interaction after per-frame setup . Therefore, as the GPU improves, so will our algorithm’ s speed and quality.
• Portability: Because our work is based, it fits easily into existing
rasterization-based pipelines, and can take advantage of many effects and optimizations applied in
rasterization.
• Animation: As a brute-force approach, this work does not rely on complex
accelera-tion structures such as kd-trees, and is not directly sensitive to the amount or type of
animation.
• Simplicity: We sample Kajiya’s well-known rendering equation [16] using an extreme form
of the widely-used deferred shading technique (which saves intermediate rendering results off-screen). Our approach also requires neither significant CPU-GPU interaction, nor
complex acceleration structures. For these reasons, our approach is conceptually simpler
than comparable techniques.
Our current implementation does have significant limitations. As noted above, it is
GPU speed, it makes extensive use of regular sampling, which introduces bias into its results:
this includes both the regular view sampling of rasterization, and Parthenon’s regular angular sampling. Finally, our solution does not incorporate a solution for area light sources (which
produce soft shadows under direct illumination) or specular surfaces (which produce caustic
2 Related Work
Since the introduction of the rendering equation by Kjiya [16], a wide variety of algorithms
have been proposed to solve it accurately. Since this work is aimed toward the achievement of real-time global illumination, this section will mainly concentrate on reviewing recent work that
revolves around the same idea. In order to obtain a comprehensive review of the fundamentals
of global illumination, refer to Dutr´e et al. [8].
2.1
Ray Tracing
In computer graphics, ray tracing refers to the process of tracing light backwards from the eye’s
point of view, to the surfaces in the scene, to the light sources [36]. Throughout the years, ray tracing’s robustness has lead it to be the preferred method for computing advanced global
illumination effects [33]. However, due to the complexity of calculations needed for obtaining
meaningful results, ray tracing has generally been limited to obtaining solutions through off-line rendering. Yet, advances in hardware have allowed the development of strategies for producing
high-quality ray traced images at interactive frame rates in the recent years. Wald et al.
present a comprehensive review of the best methodologies currently being used for interactive and animated ray tracing in their 2001 [34] and 2007 [33] State of the Art STAR reports. Most
recently, NVIDIA has developed the Optix general purpose ray tracing engine, which is designed to perform ray tracing on highly parallel architectures [26]. The Optix engine was tested with
McGuire and Luebke’s Image Space Photon Mapping (ISPM) renderer [22], obtaining significant
speed-ups over the originally published version [26].
2.2
Photon Mapping
As introduced by Jensen [14], photon mapping is a two pass approach that simulates the view
independent distribution of light on a scene. In the first pass, it emits and bounces light com-ponents (photons) from the light source and stores them on geometry aligned maps. In the
second pass, it estimates irradiance at arbitrary surface points by either gathering the
contri-bution of surrounding photons, or scattering the contricontri-bution of each photon to surrounding areas. Photon mapping is considered one of the most efficient methods for computing high
fre-quency lighting effects produced by specular surfaces (caustics). This special characteristic has sparked much interest on this technique, which has lead to the pursue of efficient and correct
implementations of it [15]; some of which are mentioned in the following paragraphs.
implementa-tion of a kNN-grid method on screen space, and renders a final image using a stochastic ray
tracer implemented on a fragment program [27]. Kr¨uger uses point sprites in conjunction with GPU ray tracing for high quality point rendering [19]. Szirmay-Kalos et. al. [32] and Shah et
al. [31] present two slightly different real-time photon tracing methods that use image-space
calculations to approximate object-ray intersections. Yao et al. improve the accuracy of these approaches by introducing the use of multiple cube maps to increase the visibility coverage
required to perform accurate image space photon-tracing [38].
McGuire and Luebke present ISPM, an approach that accelerates the two most expensive stages of photon mapping (photon emission and radiance estimation), through the application of
GPU-based image space algorithms. Intermediate photon tracing is performed on a multi-core
CPU environment with the Optix engine [26]. The algorithm’s main disadvantage is its reliance on CPU photon tracing, which limits its scalability and its support of procedural techniques
implemented on GPU; however, their results yield high quality imagery at highly interactive
frame rates for partially animated scenes [22].
Finally, Fabianowski and Dingliana [10] and Wang et al. [35] present alternatives that
take advantage of CUDA-enabled architectures to compute fast photon mapping (CUDA is
NVIDIA’s general purpose programming interface for its GPUs). Fabianowski and Dinglina use photon differentials to speed up photon retrieval. Their approach produces plausible
re-sults for static scenes, with dynamic lights and cameras, at interactive frame rates [10]. Wang et al. on the other hand, make heavy use of k-d trees to speed up photon tracing, adaptively
select shading points for performing the final gather, and extract light cuts from the photon
tree to estimate irradiance at high speeds, producing a wide range of high quality effects at interactive frame rates [35].
2.3
Classic Radiosity
Classic radiosity computes indirect diffuse light by dividing the scene into surface segments, creating links among those surface segments, and estimating the global illumination at each
surface segment based on the light received from other surface segments that are visible from
that location [12]. A few researchers have achieved plausible global illumination effects for diffuse scenes at interactive frame rates by implementing variations of classic radiosity on the
GPU. Dachsbacher et al. reformulate the rendering equation to calculate global illumination
through an iterative process that ignores expensive visibility checks for radiosity links; instead, it applies the concept of anti-radiance to subtract radiance that is transported through occluders
(opaque objects that block light) in previous iterations [5]. Addtionally, work presented by Dong et al. [7] and Ritschel et al.[28] implements variations of hierarchical radiosity, which
radiance. Dong et al.’s main contribution comes from eliminating the need to perform expensive
visibility checks by simply updating hierarchy links to only store shortest links [7]. On the other hand Ritschel et al. make use of compressed cube maps placed on clusters of coherent surface
patches to perform fast visibility tests [28].
2.4
Other Approximations
A final body of work focuses on achieving good approximations of global illumination without
direct application of its traditional methods. The dominant approaches here use view space buffers and virtual point light sources (VPLs). The following discussion focuses on these two
main approaches.
Deferred Shading. A number of techniques make use of intermediate data structures defined relative to the eye’s and/or light’s points of view. These view space buffers are very well
suited for GPU processing given that transforming 3D geometry into 2D view space buffers has
always been the main purpose of GPUs. One influential technique that applies this concept is Dachsbacher and Straminger’s reflective shadow map (RSM) approach [3]. Traditional shadow
maps store geometry data as seen from the light’s point of view, which is used to later determine
whether the surfaces in the scene are lit or in shadow [37]. RSMs extend this technique by not only storing geometry data but by also emitting radiance to visible surfaces at buffer
creation time, and subsequently gathering indirect radiance from each of the points affected
by the RSM for every pixel in a subsequent rendering pass. This technique ignores indirect occlusion at radiance gather time, but obtains acceptable results at interactive frame rates
[3]. Dachsbacher and Straminger then optimize this technique, by reducing the irradiance
estimation time through limiting the size of the area from which each pixel gathers radiance to small neighborhoods delimited by screen space defined quadrilaterals (”splats”) [4]. Nichols and
Wayman further improve this algorithm through the development of spatially adaptive splats; thus, improving its computational efficiency [24][25]. Finally, Mcguire and Luebke accelerate
photon mapping through the use of RSMs to emit photons from light sources to the scene and
through the use of 3D splats to efficiently estimate radiance through a scatter operation [22].
Virtual Point Lights (VPLs). Several other techniques make use of virtual point light sources (VPLs). The concept of VPLs was introduced by Keller in his instant radiosity
algo-rithm [18]. In his work, Keller emits a finite number of photons from the light source into the scene. He calls these photons VPLs, and treats them as point lights for direct illumination in
a GPU-supported final gather [18]. Laine et al. produced partial global illumination results
at run-time based on a validity metric [20]. Ritchel et al. greatly improve quality and
perfor-mance of the instant radiosity algorithm through the use of coherently packed low-resolution shadow maps to emit light from VPLs generated with RSMs. Their technique also provides
the possibility of obtaining multi-bounce solutions, and is also useful for obtaining other global
illumination effects, such as area light source lighting, at interactive speeds, [29]. Finally, Ka-planyan and Dachsbacher obtain a coarse approximation of indirect light through the use of
two cascaded 3D grids called light propagation volumes (LPVs). One volume is used to store
irradiance values estimated from nearby surfaces and RSMs, and to adaptively propagate light at different levels of detail. The other volume is used to store an estimated volumetric
repre-sentation of blockers (occluding objects). This method achieves real-time performance at the
expense of some quality, which is acceptable for their purpose [17].
High-Quality Global Illumination Rendering Using Rasterization. Most importantly in our context, Hachisuka’s final gather technique accelerates the sampling of the reflective hemisphere. This technique stores the values of globally defined directional samples, obtained
through orthographic rasterization, into off-screen buffers. Directional occlusion is computed
3 Algorithm
3.1
Overview
In order to produce a partially complete global illumination solution, we sample light using the
following formulation of the rendering equation:
L(x→Θ) =Le(x→Θ) +Lr(x→Θ) (3.1)
where global illumination fromL(x→Θ), is the sum of emitted light,Le(x→Θ), and reflected
light,Lr(x→Θ). Lr(x→Θ) can be decomposed into two components:
Lr(x→Θ) =Ldirect+Lindirect
Ldirect(x→Θ) =
NL
X
i=1 Z
Ai
Le(y→yx~ )fr(x, ~xy→Θ)G(x, y)V(x, y)dAy (3.2)
Lindirect(x→Θ) = Z
Ωx
Li(x←Ψ)fr(x,Ψ→Θ)cos(Nx,Ψ)dwΨ (3.3)
Li(x←Ψ) =Lr(r(x,Ψ)→ −Ψ) (3.4)
Indirect light is calculated by sampling the reflected radiance from all the visible points found in all the directions Ψ over the hemisphere centered around pointx;r(x,Ψ) in equation
3.4 is the term that ensures visibility. fr denotes the bidirectional reflectance distribution
function (BRDF) that describes the reflectance of the surface at point x from direction Ψ to direction Θ; and, finally, the cosine defines the amount of incident energy received from Ψ given
the angle at which light arrives at surface pointx [8].
Direct light, on the other hand, is calculated by explicitly sampling the surface of NL light
sources; which is why it is estimated using integration over surfaces rather than directions [8].
In this equation, Le(y→yx~ ) is the radiance emitted from point y on the sampled light source
to surface point x; fr is again the BRDF that reflects from the light vector to Θ; G is the
geometry term, which depends on the squared distance, rxy, between points x and y, and the
relative orientation of the surfaces around them:
G(x, y) = cos(Nx,Ψ)cos(Ny,−Ψ) r2
xy
(3.5)
V(x, y) =
1 if x andy are mutually visible 0 if x andy are not mutually visible
(3.6)
Our current implementation only supports point light sources, which is why we must make
some assumptions in order to accurately model light emission. We assume that an
omni-directional point light source is a sphere centered at the location of the point and that it has an arbitrary radiusR. When sampling a single light, we assume that the light ray,l, starts at the
surface point being shaded,x, and points in the direction of the center of the sphere; therefore,
the actual distance,rxy, fromxtoyis the length oflminusR. The following equation describes
how the light integral is approximated from all lights:
Ldirect= 1 N
N
X
i=1
Le(yi→y~ix)fr(x, ~xyi →Θ)G(x, yi)V(x, yi)
pL(Ki)p(yi|ki)
(3.7)
WherepL(ki) is the discrete probability density function for selecting sampleiover all lights,
p(yi|ki) is the probability density function for selecting pointyi in lightki, and N is the total
amount of samples distributed over all lights [8]. Since we use uniform light source selection
and uniform sampling of light source area, by sampling NL lights, once per-frame each, then
pL(k) = 1/NL and p(y|k) = 1/ALk (where ALk is the area of sphere k), turning equation 3.7
into:
Ldirect=
NL
X
k=1
ALkLe(yk→y~kx)fr(x, ~xyk→Θ)G(x, yk) (3.8)
In order to simplify the comparison of our results with reference images in section 4, we do
not display the spheres corresponding to each light source in our imagery, but the results are always modeled assuming light is sampled from each sphere only once per-frame. The remainder
of this section explains in more detail how our algorithm samples indirect light.
3.2
Data Structures
Our algorithm uses two types of buffers. One type is used to maintain information about the
surface properties (G-buffers), and the other type is used to capture radiance and accumulate irradiance.
There are two types of G-buffers. The per-vertex G-buffer (GBv) stores per-vertex model
data in world space (including vertex position, normal, and direct lighting and shadow). The per-fragment G-buffer (GBf) stores per-fragment surface data for fragments that are visible
from the eye (including position, normal, direct lighting and shadow, and surface color).
Table 3.1: Algorithm Buffers
GB- G-buffer GBv - Per-vertex (world space) GBvp- Position GBvn- Normal GBvl - Direct Light and Shadow
GBf - Per-fragment (eye space) GBfp - Position GBfn - Normal GBfl- Direct Light and Shadow
GBfc - Surface Color IB- Irradiance buffer IBv - Per-vertex (world space) IBcv- Accumulating
irradiance in current bounce IBpv - Accumulated
irradiance in previous bounce
IBf Per-fragment (eye space) RB- Radiance buffer
storing accumulated irradiance for each world space vertex (IBv), and one for storing
accumu-lated irradiance for each visible fragment in eye space (IBf). Finally, the algorithm uses a buffer which stores radiance and depth obtained from all the fragments generated while sampling a
particular set of global directions in a single pass (RB). Table 3.1 summarizes the types of
buffers and their nomenclature.
In addition to the buffers described above, we also store precomputed direction data,
gener-ated by using stratified sampling, on the GPU. In stratified sampling, the sphere describing the
sampling domain is divided into equally sized pieces, an then samples are generated at random locations within each piece. Finally, we store scene graph transformation matrices on the GPU
in order to minimize the overhead caused by setting global variables for GPU shaders.
3.3
Pseudocode
The core of the algorithm is located in the SphereSampling sub-routine. This sub-routine is a
modified version of the original technique presented by Hachisuka [13], which obtains indirect diffuse light by sampling global directions. Overall, the algorithm is composed of three main
stages: G-buffer creation, indirect light sampling, and final gather. Table 3.2 illustrates a
Table 3.2: Pseudocode
/* G-buffer stage */
CalculateDirectLightingAndShadows () //Use algorithm of choice CreateGBuffers ()
/* Indirect light sampling stage */ FORall bouncesDO
SphereSampling(Ni,GBv,IBpv,IBcv) IBpv = IBcv
END FOR
/* Final gather stage */ EITHER
SphereSampling (Nf,GBf,IBpv,IBf) OR
SphereSampling(Nf,GBv,IBpv,IBcv)
Rasterize IBcv into eye space, gather using a Gaussian kernel, store in IBf END
Final image is the eye space projection of (GBfl + IBf)
SphereSampling (N,GB,IBi,IBo) // Parameters:
// N - total number of directions to be sampled, // GB - G-Buffers used to sample geometry,
// IBi - Irradiance Accumulated in previous bounce, // IBo - buffer to which to accumulate new irradiance
clear IBo
FOR CEILING(N/k) DO clear RB
in k directions, sample direct light, depth and radiance from IBi, store in RB project radiance in RB onto geometry GB and accumulate into IBo
3.4
Rasterization-Based Sampling
The technique we use to sample radiance for a single bounce is very similar to the one proposed
by Hachisuka, with a few modifications. The main goal of this routine is to sample the radiance contribution that is incident to every surface sample in the scene from as many directions as
possible, in parallel. Since the radiance coming from a particular direction is calculated in
parallel for all surface samples, such a direction is called a global direction, see Figure 3.1. Note that this global direction sampling scheme differs from most other global illumination renderers,
which use a different set of directions at every location in the scene.
As in Hachisuka’s approach, the incident radiance coming from a global direction is sampled
Figure 3.1: Our (and Hachisuka’s) approach samples globally defined directions (yellow ar-rows), while other techniques sample locally defined directions (gray arrows).
in two passes. First, we rasterize the scene using an orthographic projection that aligns its
the scene, all geometry must fall inside the viewing frustum. Every pixel that results from
this rasterization contains the color of a single fragment which in theory should intersect a ray that has its origin at the location of the pixel in the near clipping plane and is traced
in the global direction. The location of the returned fragment depends on the type of depth
test performed by the z-buffer, i.e. nearest returns nearest, farthest returns farthest, etc. The second pass consists of projecting the fragment data obtained from the rasterization onto the
scene geometry and adding it to the accumulated irradiance.
Since traditional rasterization returns a single fragment per-pixel, extra steps need to be taken in order to obtain information from all depth layers (not just the front-most or hindmost
surfaces) in the scene and, thus, account for occlusion. Without such steps, every part of the
scene would be illuminated by the reflected light from the surface that is front-most, or hind-most, in the current global direction, not the surface that actually reflects light onto each part.
While Hachisuka uses depth peeling to traverse through depth layers in multiple passes, we
process all depth layers in a single pass, which improves performance. OpenGL 4 extensions allow random access writes to GPU buffer objects (memory arrays) from fragment shaders,
making the single pass depth processing task easy to implement: the fragments at different
depths within each pixel are stored in an unsorted array. For each fragment processed by the fragment shader, if the fragment is front-faced (if the dot product of its normal and the global
direction is less or equal to zero), its color and its eye-space depth are stored in the first available slot of its corresponding per-pixel array in the RB buffer. In order to keep track of the next
available memory slot, we maintain a counter per-pixel in the RB buffer, which can be trivially
implemented by using atomic operations on GPU memory. Since fragments do not arrive to the fragment shader in depth order, each per-pixel array resulting from this initial pass contains an
arbitrarily ordered set of fragments. In order to minimize the number of fragment operations
at sampling time, scene lighting is calculated in the vertex shader, using the precomputed lighting from the GBvl and IBpv buffers. Although not yet tested, interesting effects might
be achievable by performing complex per-fragment operations, such as environment map based
reflections and refractions, at sampling time, at the expense of performance.
The second pass of this process simply traverses the scene geometry stored in the G-buffer
(either GBv or GBf, depending on the stage), and calculates the light that reaches each geometry
sample in it. For each geometry sample x that is back-faced (the dot product of its normal and the global direction is greater than zero), the direction’s orthographic projection is used
to obtain the location of the corresponding fragment data array from the RB buffer. Once the
corresponding fragment data array is obtained, the shader traverses through all of its elements to find the fragment that would contribute radiance to x, which would be the fragment with
the smallest depth that is not smaller than x’s depth in that particular direction. In order to
closest to the generated buffer coordinates, and to linearly interpolate between them to obtain
more exact depth and color values. The results are then accumulated in one of the IB buffers (either IBcv or IBf, depending on the algorithm stage).
In order to sample multiple global directions in a single pass, we use a geometry shader
to replicate each incoming triangle (hardware currently only allows replication for a subset of k = 22 directions). Each replicated triangle is transformed into the orthographic space
corresponding to one of the subset’s global directions. Now, each pixel entry in the RB buffer
contains a 2D array: 22 global directions each of which contains a depth array. We modify the second pass correspondingly to collect irradiance over the direction subset, rather than only
one direction. Figure 3.2 illustrates a summary of the directional sampling process.
Currently, RB buffer memory allocation uses a na¨ıve greedy method, which is conservative but wasteful of space. Initially, the maximum number of depth layers in a scene is estimated
off-line. Then, a contiguous block of memory of sizeRB view Size ∗ depth layer estimate ∗ k
is allocated one time. For example, consider the kitchen scene in Figure 4.1, which has an estimate of 15 depth layers. With RB view size of 256x256 pixels, were each pixel corresponds
to a 128 bit block of memory, andk= 22. This results in the allocation of 330MB of memory.
Although the total buffer memory can be reduced by approximately half by decreasing the number of bits in each memory slot, it is likely that much memory will still remain unused.
Optimizing RB buffer layout should be the focus of future research.
3.5
Global Illumination
The process described in section 3.4 is used to sample indirect light from the environment for
a single bounce. In order to obtain a complete global illumination solution, light must also be sampled from the light sources and it must be bounced across the geometry multiple times.
This section describes how to achieve such an effect.
G-buffer Creation. In the first stage, one G-buffer is created by rendering position, normal, and lighting to per-vertex off-screen buffers (GBvp, GBvn, and GBvl). Another G-buffer is
created by rendering position, normal, lighting, and surface color to per-fragment off-screen buffers (GBfp, GBfn, GBfl, and GBfc). Direct light stored in GB{v|f}l, can be obtained by
applying any shadow algorithm. Our current implementation uses a na¨ıve omni-directional
shadow mapping algorithm [11].
Indirect Light Sampling. For this stage the algorithm calls SpehereSampling for a user-defined number of bounces. The directions that we sample per-bounce are pre-computed using
Figure 3.2: Simplified Illustration of Sampling.. Illustration of sampling of Cornell box scene, containing objects 1, 2, and 3, (top-left) in directions A and B (bottom). Scene is rasterized in each direction. Lists on right illustrate object fragment data that gets stored in each per-pixel, per-direction array (bottom). Data is then projected onto the scene’s geometry (top-right).
avoid temporal discontinuities. Before the initial bounce, both IBv buffers are cleared. At each
bounce we call SphereSampling once, passing as parameters the number of user specified
per-bounce directions, GBv as the G-buffer to be processed in the projection pass, IBpv as the source of indirect light, and IBcv as the destination of the newly accumulated light. Subsequently, we
swap IBcv and IBpv so that the newly obtained irradiance can be used in the next bounce, and
clear IBcv so that we can again accumulate newly sampled radiance.
Final Gather. The indirect multi-bounce sampling stage typically yields a coarse solution due to the low spatial density with which light is accumulated (one sample at each vertex), and
simple methods to address this issue.
With the first method we accumulate radiance per-fragment by running a super-sampled version of the SphereSampling sub-routine for the last bounce, passing as parameters a high
number of global directions, GBf as the G-buffer to be processed in the projection pass, IBpv
as the source of indirect light, and IBf as the destination of newly accumulated light.
With the second method we obtain a solution by accumulating radiance per-vertex in the
last bounce and then performing a per-fragment Gaussian interpolation that obtains irradiance
values from surrounding triangle vertices. In order to be able to do this, we store the indices to such neighboring vertices whose normal is similarly oriented (i.e. the dot product of both
normals is greater than zero) into vertex arrays at mesh compile time (during pre-computation).
Currently a maximum of eight neighboring indices are stored per-vertex, which requires two vertex arrays of four components each. At run-time time, we use a geometry shader to obtain
the collection of unique neighbor indices for each triangle, including the indices of the vertices
that form the triangle itself. Each fragment performs a weighted interpolation of color from neighboring vertices through the use of a Gaussian filter, as a function of distance.
Even though this way of collecting the unique set of neighbor indices is simple to implement,
it introduces more run-time computations, which affects speed. Alternatively, we could pre-compute this unique set at mesh compile time by more cleverly selecting each vertex’s neighbors.
To make sure that the color of each fragment is influenced by the color of its containing triangle, each fragment interpolates irradiance from vertices whose distance to it is less than
a radius slightly larger than the length of the triangle’s longest edge. Per-vertex data such as
position, normal and accumulated irradiance are obtained through texture look-ups from the GBv and IBcv buffers using the vertex neighbor indices. Figure 3.3 illustrates the neighborhood
data used for irradiance interpolation.
In order to obtain a reasonable solution, each vertex should have a fairly dense sampling of the radiance coming from every direction in the hemisphere. We, therefore, sample the last
bounce slightly more densely than other bounces. However, our testing shows that this last
bounce need not be as densely sampled as it must for the per-fragment final gather.
As we shall see, per-fragment final gather produces high quality imagery, but is relatively
slow. Per-vertex final gather is, on the other hand, 3-5 times as fast at the expense of some
high-frequency detail. Section 4 discusses the trade-offs presented by this choice in more detail.
Rendering. The final step of the algorithm simply adds the direct light stored in GBf to the indirect light accumulated in IBf to obtain the final image (recall section 3.3) (Figure 3.4). In
Figure 3.3: Irradiance Neighborhood. Each vertex is passed the indices to its neighbor vertices, which are defined at mesh compile time (left). Each fragment interpolates irradiance from the neighbor vertices of the triangle to which it belongs that are within a radius slightly larger than the triangle’s longest edge (right).
3.6
Implementation Details
Platform. We generated all results on a 32-bit Windows machine with an Intel Core Duo CPU running at 2.4 GHz, with 4GB RAM, and an NVIDIA GeForce GTX 465 graphics card with 1024MB of video memory. We coded our prototype in OpenGL. We implemented our
indirect light sampling and final gather shaders using GLSL, while G-buffer creation, final
rendering, and shadow algorithm shaders were implemented using Cg. (Cg was the initial shading language of choice; however, GLSL was subsequently needed to take advantage of some
key features provided by OpenGL. Eventually, all shaders will be fully migrated to GLSL.)
Buffers. The application makes extensive use of vertex buffer objects (VBOs), frame buffer objects (FBOs) and textures. VBOs are used to maintain raw model data, as well as transfor-mation data for efficient shader access. We use 32-bit floating point textures to store the GB
and IB buffers, and update them with off-screen rendering using FBOs. We allocate the RB
buffer as a 32bit floating point 2D texture array and implement it with the GL EXT shader -image load store extension.
OpenGL 4. Starting with OpenGL 3.0, NVIDIA added a set of extensions that introduced the concept of bindless graphics [1]. The main goal of bindless graphics is to reduce the CPU
overhead of rendering geometry batches, permitting geometry to be loaded directly onto the
Figure 3.4: Direct light (left), indirect light (middle), direct plus indirect light (right)
computation, atomic operations on both textures and buffer objects are supported. These features are critical for maintaining performance, because they remove a significant amount of
overhead introduced by state changes in a highly iterative approach such as this. Also, they
permit increased parallel sampling (across multiple depth layers and multiple global directions). However, we have not yet performed a detailed analysis of the exact performance contributions
of each of these elements.
BRDF. No experimentation has been conducted with BRDFs other than the uniform Lam-bertian BRDF. Due to the uniform nature of the hemisphere sampling and the iterative nature
of the radiance estimation (a subset of the directions at a time), it might be non-trivial to compute some BRDFs. However, in theory, if the BRDF of the surface is separable (the 4D
BRDF is equal to the product of two 2D functions), the appropriate scales can be applied at
the appropriate step of the sampling process to obtain a correct calculation; on the other hand, if the BRDF is not separable, approximations of the integral can be made at the appropriate
4 Results
In order to evaluate our algorithm’s effectiveness, we chose five of the most significant rendering
parameters (discussed below) and sampled each of them independently across three different test scenes, while holding other parameters constant. We then recorded execution times for
the two stages that were the primary focus of this work: indirect light sampling and the final
gather, as well as for the execution of the entire algorithm. In addition, we compared the rendered results to two reference images, one generated with Maya’s MentalRay, the other with
a high resolution (but slow) configuration of our algorithm Figure 4.1. The comparison was
performed both visually and by computing the root mean square difference (RMSD) between each result and both reference images. Initially, Maya’s MentalRay appeared to be a good
choice for creating reference imagery due to its known wide spread use and because it was
readily available to us. However, we learned that MentalRay offered imprecise rendering control to reproduce physically equivalent lighting conditions, which made it very difficult to duplicate
our rendering environment. The high resolution imagery rendered with our algorithm lets us
control for this difference.
We performed this evaluation for both the per-fragment and the per-vertex final gathers.
Table 4.1 contains the complete list of measured parameters, as well as the sampled values for
each. Table 4.2 shows the different geometric levels of detail for every scene.
We used three different test scenes (Figure 4.1). The first test scene is the the standard
Cornell box, containing two cubic objects inside. Its geometric level of detail (LOD) varies
from 36 triangles to∼30K triangles, its estimated maximum depth complexity is of three depth layers, and it has one light source. The other two scenes were obtained form the benchmark for
animated ray tracing test bed (BART) [21]. One scene is a museum room which varies from ∼10K to ∼20K triangles in our testing, has two light sources and has an estimated maximum
depth complexity of six to seven depth layers. The last scene is a kitchen, which varies from ∼100K to∼130K triangles in our testing, and has an estimated maximum depth complexity of
15 depth layers and contains four light sources, which are all located above the dining table.
All the images of the Cornell box were rendered with a screen resolution of 720x720, while the
images of the BART scenes were produced at a screen resolution of 1024x720.
4.1
Speed
Overall results indicate that the parameters that most significantly affect algorithmic speed are
Table 4.1: Performance Testing Parameters
RB Buffer Screen Res (RBSRes)
Per-Fragment Gather 32x32 64x64 128x128 384x384 Per-Vertex Gather 32x32 64x64 128x128 384x384
Geometric Level of Detail (LOD)
Per-Fragment Gather LOD 1 LOD 2 LOD 3 LOD4 LOD 5 LOD 6 Per-Vertex Gather LOD 1 LOD 2 LOD 3 LOD4 LOD 5 LOD 6
Indirect Light Bounce Count (BCount) Per-Fragment Gather 2 4 8 16 Per-Vertex Gather 2 4 8 16
Directions Per Bounce (BDCount)
Per-Fragment Gather 22 44 88 110 220 440 Per-Vertex Gather 22 44 88 110 220
Final Gather Directions (FDCount)
Per-Fragment Gather 220 440 660 880 1320 Per-Vertex Gather 110 220 440 660 880
Base Cases RBSRes LOD BCount BDCount FDCount Per-Fragment Gather 256x256 LOD4 6 220 1320
Per-Vertex Gather 256x256 LOD4 5 44 220
Table 4.2: Geometric Levels Of Detail (LOD) (vertices/triangles)
Scene LOD1 LOD2 LOD3
Cornell Box 72/36 162/144 450/576 Museum 6241/10438 6421/10618 6773/11038 Kitchen 66961/109857 67069/109979 67274/110267
LOD4 LOD5 LOD6
and 4.3) reduces speed and has little effect on error in the per-fragment gather while
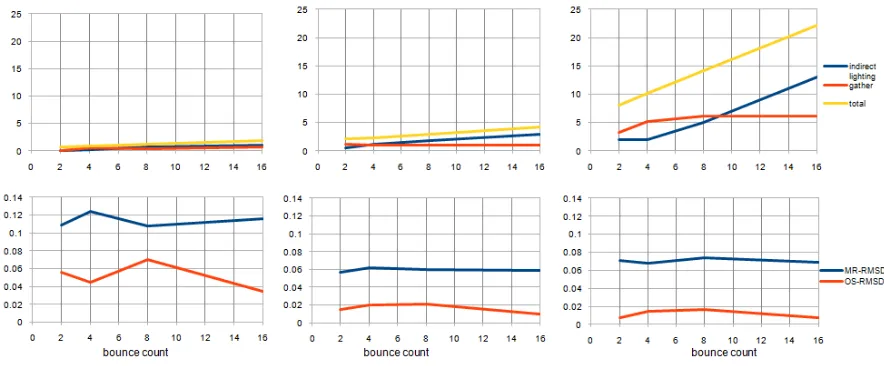
counter-intuitively increasing error in the per-vertex gather, evidence that bounces should be minimized. Increasing the number of sampled global directions during indirect light sampling (BDCount,
Figures 4.4 and 4.5) reduces speed and can reduce error slightly, evidence that BDCount should
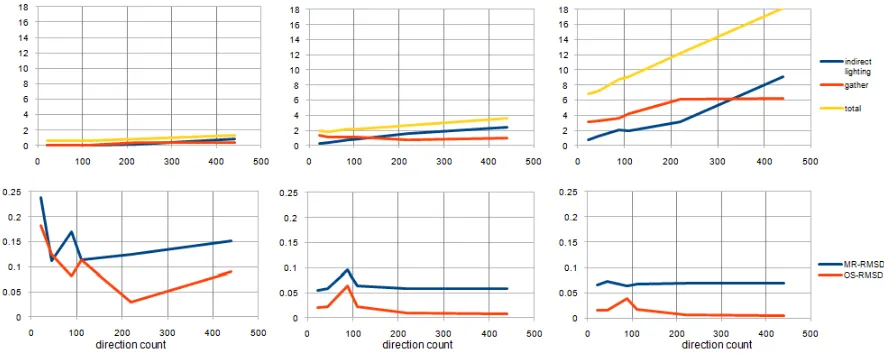
be slightly above minimum. Increasing the number of sampled global directions during final gather (FDCount, Figures 4.6 and 4.7) reduces speed and can cause meaningful reductions in
error, evidence that FDCount should be neither especially low nor specially high.
Raising the screen resolution of the RB buffer (RBRes) reduces speed slightly less than
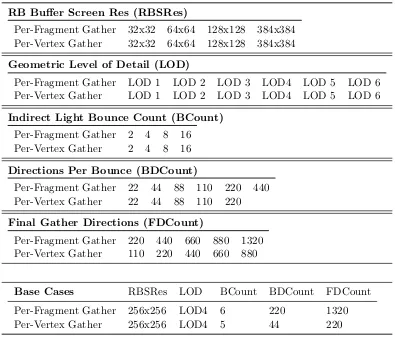
Figure 4.2: BCount of Per-Fragment Gather. Speed in seconds (top) and RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right)
the already discussed parameters (Figure 4.8 & Figure 4.9). We reached a memory barrier at 384x384. Since RBRes had little effect on error, these results suggest that RBRes should be
minimized.
Increasing LOD (Figures 4.10 and 4.11) reduces speed slightly, but above a slightly elevated floor, brings little improvement in error. This suggests that it be lowered to that floor. By
comparing variations in speed due to changes in LOD across scenes (Figure 4.12), we notice that
although the the Cornell box and the museum have similar LODs, the indirect light sampling and final gather times are slower for the museum. We believe this is due to the greater depth
complexity of the museum scene, which seems to have a multiplicative effect on speed.
Perhaps the most significant result is shown by comparing the per-fragment and per-vertex
Figure 4.3: BCount of Per-Vertex Gather. Speed in seconds (top) and RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right)
Figure 4.5: BDCount of Per-Vertex Gather. Speed in seconds (top) and RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right)
Figure 4.7: FDCount of Per-Vertex Gather. Speed in seconds (top) and RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right)
Figure 4.9: RBRes of Per-Vertex Gather. Speed in seconds (top) and RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right)
Figure 4.11: LOD of Per-Vertex Gather. Speed in seconds (top) and RMSD (bottom) for each scene: Cornell box (left), museum(middle), kitchen (right)
to obtain plausible results, it is much faster, but it introduces more error.
4.2
Quality
As discussed in section 4.1, the inconsistent effect that BCount had in error lead us to conclude
that it has little significance in quality. On the other hand, when BDCount and FDCount show effects on numerical error, only FDCount has a significant perceptual effect. This is expected,
since FDCount directly affects the irradiance approximation computed right before the light
reaches the eye. The main perceived error is cased by the quantization that results from sampling the viewing hemisphere. As mentioned in section 3.5, we apply an edge preserving
filter when necessary, in order to reduce this error (Figure 4.14).
Even though changes in RBRes evidence a not so significant effect on numerical error, small resolutions do produce a visually perceivable artifact (Figure 4.14). The causes of this artifact
are best explained by the quantization that results from only using the front most fragment seen
from a particular surface point in a particular direction without considering pixel coverage. We consider, however, that given its small impact across all scenes, RBRes should be minimized to
favor speed.
While LOD does not have significant effects on quality when performing per-fragment final
gather, it does have a significant visual effect when using per-vertex final gather (Figure 4.15).
Figure 4.13: Results with low resolution per-fragment final gather. Edge preserving filter applied to final image (left) (0.6148s), no filter used (right) (0.581s). Both images are generated with LOD4(1458/2304), 128x128 RBRes, 3 BCount, 220 BDCount, 660 FDCount.
detail, we must increase the LOD of the scene. However, as LOD increases and the capacity to
approximate detail increases, the capacity to capture artifacts caused by having low FDCount also increases (see Figure 4.11 and top-right of Figure 4.15). For this reason, we must find a
good balance between LOD and FDCount in order to be able to take advantage of the improved
speed offered by the per-vertex final gather.
Figure 4.15: Visual trade-off between LOD and FDCount for per-vertex final gather. Top, left to right: LOD4(1458/2304), 880 FDCount, 0.295s; LOD5(5202/9216), 880 FDCount, 0.6502s; LOD6(19602/36864), 880 FDCount, 1.998s. Bottom, left to right: LOD6(19602/36864), 440 FDCount, 1.6182s; LOD6(19602/36864), 880 FDCount, 2.2728s; LOD6(19602/36864), 1320 FDCount, 2.874s. All images were generated with 32x32 RBRes, 2 BCount, 220 BDcount, and no post-processing filter.
4.3
An Informed Guess
After obtaining quality and speed measurements, and identifying the main trade-offs between
pro-duce both good quality and speed for each scene (Figure 4.16, Figure 4.17, Figure 4.18). Based
on the inferences made in the previous discussion, we constructed the following table to help us identify the main impacts and choose the best configurations (Table 4.2).
Table 4.3: Overall effects of each parameter on each measure. + denotes increment in mea-sure’s value, ++ denotes significant increment. - denotes decrement, and – denote significant decrement. (v) denotes perceptually significant effects, and n/s denotes no significance. Most obvious trade-offs are colored in red .
CORNELL BOX
Gather Measure RB Res Poly Count Bounce Dirs/Bounce Gather Dirs
Method Count
Per-Frag Error (v) n/s - - (v)
Time + ++ ++ + +
Per-Vert Error n/s (v) n/s – (v) – (v)
Time + ++ + + n/s
MUSEUM
Gather Measure RB Res Poly Count Bounce Dirs/Bounce Gather Dirs
Method Count
Per-Frag Error (v) n/s - - – (v)
Time + + ++ + +
Per-Vert Error n/s (v) + (v) –
Time + + ++ + +
KITCHEN
Gather Measure RB Res Poly Count Bounce Dirs/Bounce Gather Dirs
Method Count
Per-Frag Error n/s + n/s - (v)
Time + + ++ + +
Per-Vert Error n/s (v) + (v) (v)
5 Discussion and Future Work
Given that our algorithm presents a brute force approach for sampling space, it suffers from
several drawbacks that highly affect quality at the cost of performance and vice versa. This implies a lot of potential for improvement.
Although we have analyzed the high-level impact that different sampling parameters have
on both speed and quality, we are still unsure about the effects that the low-level architectural aspects of the GPU have in our implementation. We must perform a detailed analysis of the
different tasks that the GPU performs at different stages of our algorithm, and optimize for
performance. Some aspects we plan to explore with this end include the redistribution of data to improve data coherence, the redistribution of rasterization tasks to improve computational
coherence at the shader level, and the efficient packing of data to improve transfer speeds.
Additionally, we must explore ways to perform unbiased sampling by both randomizing directional sampling across geometry, as well as light path length. We believe that this is
achievable through the redistribution of sampling in our current technique; however, the main
challenge is to maintain performance as randomization will introduce incoherent computations. Alternatively, we may also explore integration with other techniques that are more flexible in
this sense, i.e. VPLs and ray tracing.
Another area where much improvement can be achieved lays within the exploration of adap-tive techniques in order to reduce the amount of computations needed to obtain good qualities.
One direction that holds much potential in this regard is the application of spatially adaptive
techniques on both geometry and screen space. These techniques concentrate most computa-tions only in areas where change is most noticeable; thus, reducing the total amount of required
computations. Examples of these approaches are given by [17], [25], and [35]. Another
promis-ing area of improvement is concerned with the exploration of temporally adaptive techniques. Such techniques may be used to take advantage of the spatial, as well as temporal, coherence
inherent to the highly uniform sampling methodology used by our approach, both across sam-pling directions as well as across frames. Some applicable techniques include [6] and [23].
Finally, since our algorithm does not produce direct soft shadows nor caustics, we must
explore approaches that allow us to include these effects. Given that pure rasterization, the method in which our technique is based, is unfeasible for producing soft shadows and caustics,
6 Conclusion
We present a brute force approach that obtains indirect lighting effects found in global
illumi-nation, via iterative rasterization. The technique improves Hachisuka’s Parthenon final gather approach by providing a multi-bounce solution, and by allowing extra parallelization through
the simultaneous processing of multiple depth layers and multiple global directions. The main
advantages of this work are given by its full reliance on the GPU, its compatibility with raster-ization approaches, its fully dynamic nature and its relative simplicity. The algorithm’s main
limitations arise from its biased distribution of spatial samples, its lack of support for area light
sources (which produce soft shadows under direct illumination) and specular surfaces (which produce caustics through the refocusing of light), and its current speed. However, discussion
suggests that there are good reasons to believe that our current implementation has not reached
its full potential due to implementation specific issues, and that there is much room for addi-tional improvement through the application of adaptive techniques to improve the algorithm’s
REFERENCES
[1] Bindless graphics tutorial, Apr 2009. texttthttp://developer.nvidia.com/object/bindless -graphics.html.
[2] Opengl 4.1 support, Aug 2010. texttthttp://developer.nvidia.com/object/opengl -driver.html.
[3] Dachsbacher, C., and Stamminger, M. Reflective shadow maps. In Proceedings of
the 2005 symposium on Interactive 3D graphics and games (New York, NY, USA, 2005), I3D ’05, pp. 203–231.
[4] Dachsbacher, C., and Stamminger, M.Splatting indirect illumination. InProceedings
of the 2006 symposium on Interactive 3D graphics and games(New York, NY, USA, 2006), I3D ’06, pp. 93–100.
[5] Dachsbacher, C., Stamminger, M., Drettakis, G., and Durand, F. Implicit
visibility and antiradiance for interactive global illumination. In ACM SIGGRAPH 2007 papers (New York, NY, USA, 2007), SIGGRAPH ’07.
[6] Dayal, A., Woolley, C., Watson, B., and Luebke, D.Adaptive frameless rendering.
InACM SIGGRAPH 2005 Courses (2005), ACM, p. 24.
[7] Dong, Z., Kautz, J., Theobalt, C., and Seidel, H.-P. Interactive global
illumina-tion using implicit visibility. In Proceedings of the 15th Pacific Conference on Computer Graphics and Applications (Washington, DC, USA, 2007), pp. 77–86.
[8] Dutre, P., Bala, K., and Bekaert, P. Advanced Global Illumination. A. K. Peters,
Ltd., Natick, MA, USA, 2002.
[9] Everitt, C. Interactive order-independent transparency. White paper, nVIDIA 2, 6
(2001), 7.
[10] Fabianowski, B., and Dingliana, J. Interactive global photon mapping. Computer
Graphics Forum 28, 4 (2009), 1151–1159.
[11] Gerasimov, P.Omnidirectional shadow mapping.GPU Gems: Programming Techniques,
Tips, and Tricks for Real-Time Graphics (2004), 193–204.
[12] Goral, C., Torrance, K., Greenberg, D., and Battaile, B. Modeling the
[13] Hachisuka, T.High-quality global illumination rendering using rasterization.GPU Gems
2 (2005), 615–633.
[14] Jensen, H. Global illumination using photon maps. In Proceedings of the eurographics
workshop on Rendering techniques ’96 (London, UK, 1996), pp. 21–30.
[15] Jensen, H. Realistic Image Synthesis Using Photon Mapping. A. K. Peters, Ltd., Natick,
MA, USA, 2009.
[16] Kajiya, J. The rendering equation. In Proceedings of the 13th annual conference on
Computer graphics and interactive techniques (New York, NY, USA, 1986), SIGGRAPH ’86, pp. 143–150.
[17] Kaplanyan, A., and Dachsbacher, C. Cascaded light propagation volumes for
real-time indirect illumination. In Proceedings of the 2010 ACM SIGGRAPH symposium on Interactive 3D Graphics and Games (New York, NY, USA, 2010), I3D ’10, pp. 99–107.
[18] Keller, A. Instant radiosity. InProceedings of the 24th annual conference on Computer
graphics and interactive techniques (New York, NY, USA, 1997), SIGGRAPH ’97, pp. 49– 56.
[19] Kr¨uger, J., B¨urger, K., and Westermann, R. Interactive screen-space accurate
photon tracing on GPUs. InRendering Techniques (Eurographics Symposium on Rendering - EGSR) (June 2006), pp. 319–329.
[20] Laine, S., Saransaari, H., Kontkanen, J., Lehtinen, J., and Aila, T.
Incre-mental instant radiosity for real-time indirect illumination. InProceedings of Eurographics Symposium on Rendering (2007), Citeseer, pp. 277–286.
[21] Lext, J., Assarsson, U., and Moeller, T. BART: A benchmark for animated ray
tracing. IEEE Computer Graphics & Applications 21, 2 (2001), 22–31.
[22] McGuire, M., and Luebke, D.Hardware-accelerated global illumination by image space
photon mapping. InProceedings of the 2009 ACM SIGGRAPH/EuroGraphics conference on High Performance Graphics (New York, NY, USA, August 2009).
[23] Nehab, D., Sander, P., Lawrence, J., Tatarchuk, N., and Isidoro, J.Accelerating
real-time shading with reverse reprojection caching. In Proceedings of the 22nd ACM SIGGRAPH/EUROGRAPHICS symposium on Graphics hardware (2007), Eurographics Association, pp. 25–35.
[25] Nichols, G., and Wyman, C. Multiresolution splatting for indirect illumination. In
Proceedings of the 2009 symposium on Interactive 3D graphics and games (New York, NY, USA, 2009), I3D ’09, pp. 83–90.
[26] Parker, S., Bigler, J., Dietrich, A., Friedrich, H., Hoberock, J., Luebke, D., McAllister, D., McGuire, M., Morley, K., Robison, A., and Stich, M. Optix:
a general purpose ray tracing engine. ACM Trans. Graph. 29 (July 2010), 66:1–66:13.
[27] Purcell, T., Donner, C., Cammarano, M., Jensen, H., and Hanrahan, P.Photon
mapping on programmable graphics hardware. InACM SIGGRAPH 2005 Courses (New York, NY, USA, 2005), SIGGRAPH ’05.
[28] Ritschel, T., Grosch, T., Kautz, J., and Seidel, H.-P. Interactive global
illumi-nation based on coherent surface shadow maps. InProceedings of graphics interface 2008 (Toronto, Ont., Canada, Canada, 2008), GI ’08, pp. 185–192.
[29] Ritschel, T., Grosch, T., Kim, M. H., Seidel, H.-P., Dachsbacher, C., and Kautz, J. Imperfect shadow maps for efficient computation of indirect illumination.
ACM Trans. Graph. 27 (December 2008), 129:1–129:8.
[30] Ritschel, T., Grosch, T., and Seidel, H.-P. Approximating dynamic global
illumi-nation in image space. In Proceedings of the 2009 symposium on Interactive 3D graphics and games (New York, NY, USA, 2009), I3D ’09, pp. 75–82.
[31] Shah, M., Konttinen, J., and Pattanaik, S. Caustics mapping: An image-space technique for real-time caustics.Visualization and Computer Graphics, IEEE Transactions on 13, 2 (2007), 272 –280.
[32] Szirmay-Kalos, L., Asz´odi, B., Laz´anyi, I., and Premecz, M. Approximate
Ray-Tracing on the GPU with Distance Impostors. In Computer Graphics Forum (2005), vol. 24, Wiley Online Library, pp. 695–704.
[33] Wald, I., Mark, W., G¨unther, J., Boulos, S., Ize, T., Hunt, W., Parker, S., and Shirley, P. State of the art in ray tracing animated scenes. In STAR Proceedings
of Eurographics 2007 (Sept. 2007), D. Schmalstieg and J. Bittner, Eds., The Eurographics Association, pp. 89–116.
[34] Wald, I., and Slusallek, P. State of the art in interactive ray tracing. InState of the
Art Reports, EUROGRAPHICS 2001. EUROGRAPHICS, Manchester, United Kingdom, 2001, pp. 21–42.
[36] Whitted, T. An improved illumination model for shaded display. ACM, New York, NY,
USA, 1998, pp. 119–125.
[37] Williams, L. Casting curved shadows on curved surfaces. SIGGRAPH Comput. Graph.
12 (August 1978), 270–274.
[38] Yao, C., Wang, B., Chan, B., Yong, J., and Paul, J. Multi-Image Based Photon