D o c u m e n t Classification Using D o m a i n Specific
Kanji Characters Extracted by X2 M e t h o d
Y a s u h i k o W a t a n a b e } M a s a k i M u r a t a { M a s a h i t o
Takeuchi:~
M a k o t o
N a g a o { D e p t . o f E l e c t r o n i c s a n d I n f o r m a t i c s , R y u k o k u U n i v e r s i t y , S e r e , O t s u , S h i g a , J a p g m• " 1 ' *
:~ D e p t . o f E l e c t r o n m s a n d C o m l n u m c a t l o n , K y o t o U n i v e r s i t y , Yoshida., Sa]~yo, I ( y o t o , J a p a n w a t a n a b e @ r i n s . r y u k o k u . a c . j p , { m u r a l ; a , t a k c u c h i , n a g a o } ( _ ~ p i n e . k u e e . k y o t o
n.ac.jp
A b s t r a c t
In this paper we describe a method of classifying Japanese text documents using domain specific kanji charactcrs. Text documents are generally cb~ssified by significant words (keywords) of the documents. However, it is difficult to extract these significant words from Japanese text, because Japanese texts are written without using blank spaces, such as de- limiters, and must be segmented into words. There- fore, instead of words, we used domain specific kanji characters which appear more frequently in one do- main than the other. We extracted these domain specific kanji characters by X ,2 method. Then, us- ing these domain specific kanji characters, we clas- sifted editorial columns "TENSEI J I N G O " , edito- rim articles, and articles in "Scientific American (in Japanese)". The correct recognition scores for' them were 47%, 74%, and 85%, respectively.
1
I n t r o d u c t i o n
Document cl~sification has been widely investigated for assigning domains to documents for text retrieval, or aiding human editors in assigning such domains. Various successful systems have been developed to classify text documents (Blosseville, 1992; Guthrie, 1994; Ilamill, 1980; Masand, 1992; Young, 1985).
Conventional way to develop document classifica- tion systems can be divided into the following two groups:
1. semantic approach 2. statistical approach
In the semantic approach, document classification is based on words and keywords of a thesaurus. If the thesaurus is constructed well, high score is achieved. But this approach has disadvantages in terms of de- velopment and maintenance. On the other hand, in the statistical approach, a human exl)ert classifies a sample set of documents into predefined domains,
and
the computer learns from these samples how to classify documents into these domains. ']'his ap- proach offers advantages in terms of developmentand
maintenance, but the quality of the results is not good enough in comparison with the semantic approach. In either approach, document classifica- tion using words has problems as follows:1. Words in the documents must be normalized for matching those in the dictionary and the
thesaurus. Moreover, in the case of Japanese texts, it is difficult to extract words from them, because they are written without using blank spaces as delimiters and must be segmented into words.
2. A simple word extraction technique generates to() many words. In the statistical approach, the dimensions of tim training space are too big au(l tim classification process usually fails. Therefore, the. Jal)anese document classification on
words needs a high l)recision Japanese morpholog-
ical analyzer and a great a m o u n t of lexical knowl- edge. Considering these disadvantages, we propose a new method of document classification on kanfi
character,s, on which document classification is per-
formed without a morphological analyzer and lexi- eel knowledge. In our approach, we extracted do- main specific kanji characters for' document classi- fication by the X 2 metho(I. The features of docu- lnents and domains are rel-)resented using the tim_ ture space the axes of which are these domain spe- cific kanji characters. Then, we classified Japanese documents into domains by mea~suring the similar- ity between new documents and the domains in the feature space.
2
D o c u m e n t C l a s s i f i c a t i o n o n
D o m a i n S p e c i f i c K a n j i C h a r a c t e r s
2.1 T e x t R e p r e s e n t a t i o n t)y K a n j i C h a r a c t e r s
In previous researches, texts were represented by significarlt woMs, and a word was regarded as a min- immn semantic unit. But a word is not a minimum semantic unit, because a word consists of one or more morphemes. Here, we propose the text repre- sentation by morpheme. We have applied this idea to the Japanese text representation, where a kanji character is a morpheme. Each kanji character has its meaning, and Japanese words (nouns, verbs, ad- jectives, and so on) usually contain one or more kanji characters which represent the meaning of the words to some extent.
s a m p ! e set of J a p a n e s e texts
2
x method
input
/ g
/ ? d
#
/
feature space / /
for " /
document /" /" ,#
classification /' / ,,'"" ' ,'
/////"
,,,// ...
measure the similarit
yl
'°
J
he feature s p a c e ... "
. . . classification
process
/
Z-22
philosophy . . ~
7 - ] - - - -
.J
library science . . ~
Figure 1: A Procedure ibr the l)OCllliient (;lassilication Ushlg I)olliain Sl)ecilic Kanji Characters
in one donlaii'i than the other, and extracted theni
by the X 2 m e t h o d . I,'rOlll llOW Oli, these kanji charac-
ters are called the domain specific kanji characlcrs.
T h e n , we represented the c o n t e u t e t a J a p a n e s e text x as the following vector of douiain specific kanji characters:
x = ( f l , f 2 . . . f / . . . / I ) , ( 1 )
where c o i n p o n e n t fi is the frequency o f d o n i a i n SlW. -
ciIic kanji i and I is the nuniber of all the extracted kanji characters by the X 2 lnethod. In this way, tilt'
J a p a n e s e text x is expressed as a point in the ~l. dimensional feature space the axes of which are the d o m a i n specific kanji characters. T h e n , we used this feature space for tel)resenting the features of the do- mains. Nainely, the d o m a i n vl is rel)rese.nted usilig
the feature vector of doniain specific kanji charac-
ters as follows:
Vi = ( f l , f 2 , . . . , S t , . . . , .[1). ( 2 )
We used this feature space llOt only for I, he text r e p r e s e n t a t i o n but also for the d o c u n i e n t classifica- tion. [f the d o c u m e n t classification is lJerforined Oil kanji characters, we m a y avoid the two problenls
described in Section 1.
1. It is simpler to e x t r a c t ka, iji characters than tO e x t r a c t J a p a n e s e words.
2. T h e r e a r e a b o u t 2,000 kanji char~tcte,'s t h a t a r e considered neccssary h)r general literacy. So, the rnaximuln n u m b e r of dimensiolis of the training space is a b o u t 2,000.
Of course, in our approach, the quality of the
results m a y not be as good as lit the i)revh)us al)-
preaches ilSilig the words. But it is signilicanl, I.hat
we can avoid the cost of iriorphologi(:at mialysis which
is not so perfect.
2 . 2 P r o c e d u r e t b r t h e D o e m n e n t
C l a s s i f i c a t i o n u s i n g K a n j i C h a r a c t e . r s
O u r a p p r o a c h is the following:
1. A sample set of J a p a n e s e texts is classifie.d by
a htiniaii expert.
2. Kanji characters which distribute unevenly aniong> text domahm are extracted by the X 2 Iliethod.
3. The featllre vect,ors of the doliiains are obtained by the inforniation Oll donlain specilic kanji
characters and its fr0qllOlioy o f OCCllrrellCe.
4. Tile classification system builds a feaDtlre vc(>
tor of a new doclllllel]t, COIIllJal'es il. with the
feature vectors of each doniain, an{l dcl.erlnhies the doniahi whh:h l, he docunie.nt I)c[ongs to.
Figure 1 shows it procedure for the docuinent clas-
sification /ISilI~ dOlltaill specific kanji chara.cters.
3 A u t o m a t i c E x t r a c t i o n o f ] ) O l l i a i i l
Specific
K a n j i C h a r a c l ; e r s3.1 T h e L o a r i l i n g S a m p l e
For extracting doiriain specific kanji characters and
obtaining the fea, till'e voctoi's of each domain, we ilSe
articles of "l<ncych}pedia lh:'.ibonsha" ~IrS the le/trn-
ing sa.nll)le. The reasoll why we use this encyclo- Imdia is thai, it is lmblished in the electronic form and contains a gi'oat liiiiill)oi' of articles. This en-
c.yclopedia was written by 6,727 atlthors, and COil- rains a b o u t 80,000 artich'.s, 6.52 x 107 characters,
and 7.52 X 107 kanji characters. An exanlple arti-
c.le of "Encyclopedia lloibonsha" is shown in Figure
7. U n f o r t u n a t e l y , tile articles a r e n o t classified, h u t there is the a u t h o r ' s llaliie at the end of each article and his specialty is notified in the preface.. T h e r e fore, we can chussit'y these articles into the a u t h o r s ' specialties autonlaLically.
T h e specialties used i . the encyck}l)edia are wide,
but they a.re not well balanced i Moreover, some
doniains of the a u t h o r s ' specialties contain only few
[image:2.596.101.499.61.264.2]... t i t l e ... . p r o n u n c i a t i o n
.... '.'..:_.::::::::::::::! ... k::.::---:v::.-::.:-:::::.-.-:..:'.' ... C e x t . . .
a),~(/)tc~9, - ~ @ [ 2 ~ < ~ @ , k g X { g - l ' Y - ,) > , y , ~ , : w a O g 3 e g J ; > 9 7 t ~ % ~ T ~ _
... a u t h o r
Figure 2: An E x a m p l e Article of "Encyclopedia Heibonsha"
articles. So, it is difficult to extract appropriate domain specific kanji characters from the articles which are classified into the a u t h o r s ' specialties.
Therefore, it is i m p o r t a n t to consider that 206 specialties in the encyclopedia, which represent al- most a half of the specialties, are used as the sub- jects of the domain in the Nippon Decimal Classifi- cation (NDC). For example, botany, which is one of the a u t h o r s ' specialties, is also one of the subjects of the domain in the NDC. In addition to this, the NDC has hierarchical domains. For keepiug the domains well balanced, we combined the specialties using the hierarchical relationship of the NDC. T h e procedure for combining the specialties is as follows: 1. We aligned the specialties to the domains in the NDC. 206 specialties corresponded to the do- mains of the NDC automatically, and the rest was aligned manually.
2. We combined 418 specialties to 59 code do- mains of the NDC, using its hierarchical re- lationship. 'Fable 1 shows an example of the hierarchical relationship of the NDC.
However, 59 domains are not well balanced. For ex- ample, "physics", "electric engineering", and "Ger- man literature" are the code domains of the NDC, and we know these domains are not well balanced by intuition. So, for keeping the domains well bal- anced, we combined 59 domains to 42 manually.
3.2 S e l e c t i o n o f D o m a i n S p e c i f i c K a n j i C h a r a c t e r s b y t h e X 2 M e t h o d
Using the value X 2 of the X 2 test, we can detect the unevenly distributed kanji characters and ex- tract these kanji characters as domain specific kanji characters. Indeed, it was verified t h a t X ~ method is useful for extracting keywords instead of kanji characters(Nagao, 1976).
Suppose we denote the frequency of kanji i in the domain j , m i d , and we assume that kanji i is distributed evenly. Then the value X 2 o f k a n j i i, X~,
is expressed by the equations as follows: I
j = l
d _ ( * ' d
(4)
rlzij
1
x i j k
j = l
m i d - k ,
x~.it
( s )i=1 d : l
where k is the number of varieties of the kanji char- acters and 1 is tile number of the domains. If the value X/2 is relatively big, we consider t h a t the kanji i is distributed unevenly.
T h e r e are two considerations a b o u t the extrac- tion of the domain specific kanji characters using the X 2 method. T h e first is the size of the training samples. If the size of each training sample is differ- ent, the ranking of domain specific kanji characters is not equal to tile ranking of tile value X 2. 'File sec- ond is t h a t we cannot recognize which domains are represented by the extracted kanji characters using only the value X :~ of equation (3). In other words, there is no guarantee t h a t we can extract the ap- propriate domain specific kanji characters from ev- ery domain. From this, we have extracted the fixed number of domain specific kanji characters from ev- ery domain using the ranking of the value X~ d of equation (4) instead of (3). Not only the value X~ of equation (3) but the value X~ d of equation (4) be- come big when the kanji i appears more frequently in the domain j than in the other. Table 2 shows top 20 domain specific kanji characters of the 42 domains. Further, Appendix shows tim meanings of each domain specific kanji character of "library science" domain.
3.3 F e a t u r e S p a c e f o r t h e D o c m n e n t C l a s s i f i c a t i o n
In order to measure the closeness between an un- classified document and the 42 domains, we pro- posed a feature space the axes of which are domain specific kanji characters extracted from the 42 do- mains. To represent the features of an unclassified document and the 42 domains, we used feature vec- tot's (1) and (2) respectively. To find out the closest domain, we measured an angle between the unclas- sifted d o c u m e n t and the 42 domains in the feature space. If we are given a new d o c u m e n t the feature vector of which is x, the classification system can compute the angle 0 with each vector vi which rep- resents the domain i
and find vi with
rain 0 ( vi , z ) .
i
TaMe 1: Division of the Nippon Decimal Chtssification
- technology/engineering (:lass . . . .
54(0) electrical engineering code
548 information engineering item
548.2 computers detailed item \ small items
548.23 m e m o r y Ilnit more detailed item
J
NDC is tile most popular library cl,-~ssification in Jal)an and it has tile hierarchical domains. NDC h~s the 10 classes. Fach chess is further divided into 10 codes. Each code is dcvided into t0 items, which in turn have details using one or two digits. Each domain is ~ussigned by decimal codes.
'Fable 2: Top 20 I)omain Specific Kanji Characters of tile 42 I)omains Domain
library science philosophy psychology science of religion sociology politics e c o n o l n i c s law
military science l)edagogy corn merce folklore
scientific history mathematics information science ~Lst r o n o l n y
physics chemistry earth science archeology biology botaoy zoology medical science engineering agricnlture management chemical industry machinery architectu re art
e n v i r o n m e n t printing music/dance amusement linguistics Western literature Eastern literature geography ancient history Western history F,a~ster n history
Domain Specific l(anji Characters
(BIG ~--- the vah, e X~, of equation (4) - - ~ SMALl,)
,L, ~ ~t! ~/ ;~/ ~ :7:- II1~ I~ ~J ,~ ~ iN -~fl *0~ ~B L~ ;~; ~ f~
~?. ~ ~ rOE ~"-I ~. N ~1 ,,,,~ ~~ I',~ ~;q ~ ~ q i'd~ t~1 ~.:: ~ ~., ?,~
:~ di :~I~ ~- ~ ~ ,A..5. ~ ~,l I~ :tt~ ,~ g~ ~. $~ ~_ I~ ~ ,~ -t:
:if- I~11 ~i Ell I~ F# 5'~ g': ~ ~ IIq I~ t"l .~, f~ }I~ N i~l N
.... ,~1 ~ J :~: ~ ~I _~. :~ b~ 7, ~ i~ ~ ~ ~ ~ ..~ ~.~r:
Jll Ill lt~ I1.1. ,% tile i~'~J :IE N .~Ig t~g A ~ th" llll~ 5~ N li: N I I
~¢~ ~ 1~ ~ I~1 .q~ q-: ~ ~a ~ :~ ~ .,'i'i fit ~ /~ ",g :j'~ ~ ,~
4 D o c u m e n t C l a s s i f i c a t i o n U s i n g D o m a i n S p e c i f i c K a n j i C h a r a c t e r s 4.1 E x i ) e r i m e n t a l R e s u l t s
For evaluating our approach, we used the following three sets of articles in our experiments:
1. articles in "Scientific American (in .lapanese)" (162 articles)
2. editorial columns in Asahi Newspaper "TEN- SE[ J I N G O " (about 2,000 articles)
3. editorial articles in Asahi Newspaper (about 3,000 articles)
erarchy of domains which differ from the domains of the NDC. We aligned these domains to the 42 domains described in Section 3.1. Some articles in thereof contain two or more themes, and these arti- cles are classified into two or more domains by edi- tors. For example, the editorial article ' q b o Many K a t a k a n a Words" is classified into three domains. In these cases, w e . j , d g e t h a t the result of the au- tomatic classification is correct when it corresponds to one of the domains where the d o c u m e n t is cbLs- sifted by editors. Figure 3 , Figure 4, and Figure 5 describe the variations of the classification results with respect to the number of domain specific kanji characters.
4.2 E v a l u a t i o n
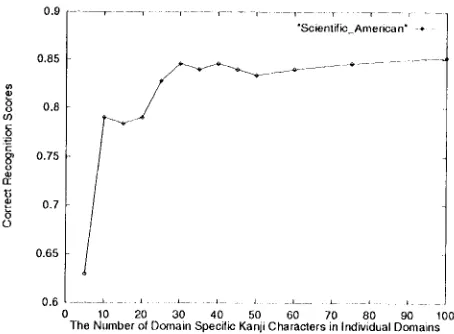
In our approach, the m a x i m u m correct recognition scores for the editorial articles and the articles in "Scientific American (in Japanese)" are 74 % and 85 %, respectively. Considering that our system uses o n l y the statistical information of kanji characters and deals with a great amount of documents which cover various specialties, our approach achieved a good result in d o c u m e n t classification. From this, we believe t h a t our approach is efficient for broadly classifying various subjects of the documents, e.g. news stories. A m e t h o d for classifying news stories is significant for distributing and retrieving articles in electronic newspaper.
T h e m a x i m u m recognition scores for " T E N S E I J I N G O " is 47 %. T h e reasons why the result is far worse than the results of the other are:
1. T h e style of the d o c u m e n t s
T h e style of " T E N S E I ,lINGO" is similar to t h a t of an essay or a novel and it is written in colloquial Japanese. In contrast, the style of the editorial articles and "Scientific American (in Japanese)" is similar to t h a t of a thesis. We think the reason why we achieved the good re- sult in the classification of the editorial articles and "Scientific American (in Japanese)" is that m a n y technical terms are used in there and it is likely that the kanji characters which represent the technical t e r m s are domain specific kanji characters in t h a t domain.
2. T w o or more themes in one document
Many articles of " T E N S E I J I N G O " contain two or more themes. In these articles, it is usual t h a t the introductory part has little relation to the main theme. For example, the article "Splendid ILetirement", whose main theme is the Speaker's resignation of the llouse of Rep- resentatives, ha~s an introductory part a b o u t the retirement of famous sportsmen. In conclu- sion, our aplJroach is not effective in classifying these articles.
However, if we divide these articles into se- mantic objects, e.g. chapter and section, these semantic objects may be classified in our ap- proach. Table 3 shows the results of classifying fifll text and each chapter of a book "Artifi- cial Intelligence and H u m a n Being". Because this book is manually classified into tile domain
g,
g
Y
o
0 . 6 - - - • ~ - - - -
0 . 5 5
0 . 5
i
0 . 4 5
0.4
0 . 3 5
0 . 3 0
" T E N S E I J I N G O "
__1 4 . . . ~ . _ _ J . L . _ _ L __& ._ L &
10 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 T h e N u m b e r o l D o m a i n S p e c i f i c K a n j i C h a r a c t e r s i n I n d i v i d u a l D o , ' n a i n s
Figure 3: Variations of the Classification Results for " T E N S E I J I N G O " by the Number of Domain Specific Kanji Characters in Individual I)omains
0 . 8 5 - , • ~ , , , , , , " e d i t o r i a l a r t i c l e s " *
0 . 8
o ~ 0 . 7 5 (,9
g
o~ 0 . 7
0.65 o
0 . 6
//:
0 . 5 5 • ~ ~ ~ L _ L . • L • 10 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 100 T h e N u m b e r of D o m a i n S p e e d i c K a n l i C h a r a c l e r s m i n d i v i d u a l D o m a i n s
Figure 4: Variations of tile ,lasslhcatlon Results for the editorial articles by the Number of Domain Specific Kanji Characters in Individual l)onmins
0 . 9 - ~ --i " f ~ ~ -- f i " r ~ - - r - " S c i e n l i l i c _ A m e r:ca n" *
0 . 8 5
0 . 8
0 . 7 5
0 . 7
0 . 6 5
0 . 6
10 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 T h e N u m b e r of D o m a i n S p e c i f i c K a n j i C h a r a c t e r s i n I n d i v i d u a l D o m a i n s
[image:5.596.329.556.65.230.2] [image:5.596.328.554.295.461.2] [image:5.596.325.552.525.692.2]Table 3: A Classification Result of a book "Artiticial Intelligm,ce and l l u m a n l~eil,g"
C h a p t e r Title l{.esult
C h a p t e r 1 C h a p t e r 2 Chal)ter 3 C h a p t e r 4 C h a p t e r 5
T h e Ability of Coml)uters Challenge to I l u m a n Recognition Aspects of Natural L a n g u a g e W h a t is the U n d e r s t a n d i n g ?
Artificial Intelligence and P h i l o s o p h y
information science information science
linguistics information science
psychology
Full Text of "Artificial Intelligence and l l u m a n Being" information science
" i n f o r m a t i o n science" in tile N DC, it is correct t h a t the s y s t e m classified this book into the " i n f o r m a t i o n science". And it is correct that the s y s t e m classified C h a p t e r 3 and C h a p t e r 5 into the "linguistics" and " p s y c h o l o g y " , respec- tively, because h u m a n language is described in C h a p t e r 3 and h u m a n psychological aspect is described in C h a p t e r 5.
5 C o n c l u s i o n
T h e quality of the e x p e r i m e n t a l results showed t h a t our apl)roach enables d o c u m e n t classification with a g o o d ac.e|lracy, and suggested the possibility for Jat)anese d o c u m e n t s to t)e represented on the basis of kanji c h a r a c t e r s they contain.
6
F u t u r e W o r k
Because the training samples are created w i t h o v t this application in mind, we m a y be able to im- prove the p e r f o r m a n c e by increasing the size of the training samples or by using different samples which have the similar styles and contents to the docu-
ments. We would also like to s t u d y the relation
between tile quality of the classification result and the size of the d o c u m e n t s .
R e f e r e n c e s
Blosseville M.J, It6brail G., Monteil M.G., Pdnot N.: "Autontatic Document Classilleation: Natural l,an- guage Processing, St~ttistical Analysis, ~tnd Expert System Techniques used together", SI(',IR '92, Pl).
51- 58, 1992.
Gnthrie I,., Walker E., Guthrie J.: "I)OCUM I",NT CI,AS SIFICATION BY MACIIINE:Theory and Practice", COLING 94, pp. 10591063, 1994.
Hamill K.A., Zamora A.: "The Use of Titles for Auto- matic Do(:ulr,ent Classifi(:ation", ,lournal of the Amer- ican Society for hfformation Science, pp. 396 402,
1980.
Masand B., Linoff G., Waltz l).: "Classifying News Sto- ries using Memory Based ll.easoning", S[GI]{ '92, pp.
59-65, 1992.
Nagao M., Mizutani M, lkeda II.: "An Automatic Method of the Extraction of Important Words from Japanese Scientific Documents" (in Japanese), Transactions of IPSJ, Vol.17 No.2, p p . l l 0 ll7, 1976.
Yonng S.R., Hayes P.J.: "Automatic Classilication and Summarization of Banking Telexcs", Proceedings of the Seco,d IEEE Conference on A[ Applications, pp.
402-408, 1985.
A p p e n d i x
The meanings of each domain speci tic kanji character of tile "library science" category are as h)llows:
write; draw; writing, art of writing, (:alligraphy, pen- manship; books, literary work; letter, note
printing block, printing plate, wood block; imblish- ing, printing; printing, edition, impression;
building, hall, mansion, manor ; suffix of public build- ing (esp. a la.rge bvilding for cultural activities), hall, edifice, pavilion;
counter for books, volumes or copies; bound book, volume, copy;
~i~ storehouse, waLrehouse, storage chamber
7-4'< basis, base, foundation; origin, source, root, begin- ning; book, volume, work, magazine; this, the so,he, the present; head, main, l)rineii)al; real, true, gen- uine; counter for cylindrical objects (bottles, pen- eils, etc)
~1~ paper; newspaper, periodical, publication
T town subsection, city block-size area; counter for dished of food, blocks of tofu, guns; two-page leaf of pal)er
[] drawing, diagram, plan, figure, illustration, picture; map, chart; systematic plan, scheme, attempt, in- ten tion;
~I] paste, glue; starch, sizing
:]q] l)ublish; publication, edit.ion, issue
~lJ print, put in print; counter for printings
Eli (vismd sign)seal, stamp, sea[ impression; sign, mark, symbol, imprint; print; India
#O} volume, I)ook; ,'oil, reel; roll up, roll, scroll, wind, coil
notebook, book, register; counter for quires (of pa- per), fohting screens, volumes of Japanese books, etc.; counter for tatami mats
magazine, periodical, suffix names of magazines of periodicals; write down, chronicle
5~ letter, character, script, inscription; writing, compo- sition, sentence, text, document, style; letters, lit- erature, the pen; culture, learning, the arts design; letter, note;
~'@ store, put away, lay by; own, possess, keep (a collec- tion of books); storehouse, storing place, trcas/lry
}/~ break, be lolded, bent; turn (left/right); yield, com- promise