DOI : https://doi.org/10.32628/CSEIT195439
Secure Data Compression Scheme for Scalable Data in Dynamic Data Storage
Environments
K. Suvetha Bharathi, K. Palanivel
Department of Computer Science, AVC College, Mayiladuthurai, India
ABSTRACT
With the continuous and exponential increase of the number of users and the size of their data, data deduplication becomes more and more a necessity for cloud storage providers. By storing a unique copy of duplicate data, cloud providers greatly reduce their storage and data transfer costs. These huge volumes of data need some practical platforms for the storage, processing and availability and cloud technology offers all the potentials to fulfill these requirements. Data deduplicationis referred to as a strategy offered to data providers to eliminate the duplicate data and keeps only a single unique copy of it for storage space saving purpose. This paper, presents a scheme that permits a more fine-grained trade-off. The intuition is that outsourced data may require different levels of protection, depending on how popular content is shared by many users. A novel idea is presented that differentiates data according to their popularity. Based on this idea, an encryption scheme is designed that guarantees semantic security for unpopular data and also provides the higher level security to the cloud data. This way, data de-duplication can be effective for popular data, whilst semantically secure encryption protects unpopular content. Also, the backup recover system can be used at the time of blocking and also analyze frequent login access system.
Keywords : Data storage, Chunks, Similarity matching, Data security, Backup Recovery
I. INTRODUCTION
Now a day there is growth in information. With infinite storage space provide by cloud service provider users tend to use as much space as they can and vendors constantly look for techniques aimed to minimize redundant data and maximize space savings. Users will access information according to their needs and most users access same information again and again, the cost of computation, application hosting, content storage and delivery is reduced significantly. The cloud makes it possible for you to access your information from anywhere at any time. Cloud provides benefits such as, flexibility, disastracter, recovery, software updates automatically, pay- per-use model and cost reduction.[3] While a traditional
duplicate copies of many pieces of data. For example, the same file may be saved in several different places by different users, or two or more files that aren't identical may still include much of the same data. Along with low ownership costs and flexibility, users require the protection of their data and confidentiality guarantees through encryption. To make data management scalable deduplication we are use Encryption for secure deduplication services. [1] Unfortunately, deduplication and encryption are two conflicting technologies. While the aim of deduplication is to detect identical data segments and store them only once, the result of encryption is to make two identical data segments in distinguishable after being encrypted. This means that if data are encrypted by users in a standard way as like shared authority, the cloud storage provider cannot apply deduplication since two identical data segments will be different after encryption. On the other hand, if data are not encrypted by users, confidentiality by cannot be guaranteed and data are not protected against curious cloud storage providers. There are two types of deduplication in terms of the size: (i) file-level deduplication, which discovers redundancies between different files and removes these redundancies to reduce capacity demands, and (ii) blocklevel deduplication, which discovers and removes redundancies between data blocks. The file can be divided into smaller fixed-size or variable-size blocks. Using fixed size blocks simplifies the computations of block boundaries, while using variable-size blocks. A technique which has been proposed to meet these two conflicting requirements is Tag generation and AES Scheme whereby the encryption key is usually the result of the hash of the data segment. Although encryption seems to be a good candidate to achieve confidentiality and deduplication at the same time, it unfortunately suffers from various well-known weaknesses. The confidentiality issue can be handled by encrypting sensitive data before outsourcing to remote servers. Along with low ownership costs and flexibility, users require the protection of their data
and confidentiality guarantees through encryption. In this paper, we address the a for mentioned privacy issue to propose a shared authority to the files which Deduplicted based privacy preserving authentication for the cloud data storage, which realizes authentication and authorization without
compromising a user’s private information. The basic data chunk similarity is shown in fig 1.
Figure 1 : Data deduplication
II. RELATED WORK
incremental data sets can be improved significantly over existing approaches.
T. Yang, et.al,…[2] implemented a highly scalable
two-phase TDS approach for data anonymization based on MapReduce on cloud. To make use of the parallel capability of MapReduce on cloud, classification required in an anonymization process is split into two phases. In the first one, original datasets are partitioned into a group of small datasets, and those datasets are anonymized in parallel, creating intermediately results. In the second one, the intermediate results are aggregated into one, and further anonymized to achieve consistent k-anonymous data sets. It leverages MapReduce to accomplish the concrete computation in both phases. A group of MapReducejobs are deliberately designed and coordinated to perform specializations on data sets collaboratively. It evaluates the approach by conducting experiments on real-world data sets. Experimental results show that with the approach, the scalability and efficiency of TDS can be improved. It evaluate the approach by conducting experiments on real-world data sets. Experimental results demonstrate that with the approach, the scalability and efficiency of TDS can be improved significantly over existing approaches. The major contributions of the research are threefold. Firstly, it creatively applyMapReduce on cloud to TDS for data anonymization and deliberately design a group of innovative MapReduce jobs to concretely accomplish the specializations in a highly scalable fashion. Secondly, it propose a two-phase TDS approach to gain high scalability via allowing specializations to be conducted on multiple data partitions in parallel during the first phase.
N. Laptev, et.al,…[3] analyzedEarly Accurate
Result Library framework (EARL) has been designed and developed to provide this much needed functionality thus bridging the gap between the mushrooming data-sizes and the response time requirements. To achieve this, we explore and apply powerful methods and models developed in statistics
to estimate results and the accuracy obtained from sampled data. We propose a method and a system that optimize the work-flow computation on massive data-sets to achieve the desired accuracy while minimizing the time and the resources required. In this demonstration we will present the EARL prototype1 and its intuitive GUI interface which helps the user
through the successive phases of ‘big data’ analytics.
This prototype represents also the starting point for a formal study of the tool usability we are planning to conduct. The early approximation techniques presented are also important for fault-tolerance, where only a portion of the data is available and the error estimation is required to determine if node recovery is necessary. Delta maintenance techniques reuse the results across samples of different sizes, while the integration with the popular MapReduce framework allows for exploiting the inherent
parallelism of bootstrapping. Furthermore EARL’s
simple API allows for easy specification of mining algorithms that take full advantage of framework.
T. Condie, et.al,…[4] implemented The
unified machine cluster. Yet, the data scientist is still left with the problem of finding the right system and programming model for their data-analysis task, assuming one even exists, and staging their solution in production.
A. Aboulnaga, et.al,…[5] provide the framework for
Parallel database systems and MapReduce systems (most notably Hadoop) are essential components of
today’s infrastructure for Big Data analytics. These
systems process multiple concurrent workloads consisting of complex user requests, where each request is associated with an (explicit or implicit) service level objective. For example, the workload of a particular user or application may have a higher priority than other workloads. Or, a particular workload may have strict deadlines for the completion of its requests. The research area of Workload Management focuses on ensuring that the system meets the service level objectives of various requests while at the same time minimizing the resources required to achieve this goal.
III. EXISTING METHODOLOGIES
Many systems have been developed to provide secure storage but traditional encryption techniques are not suitable for compression purposes. Deterministic encryption, in particular convergent encryption, is a good candidate to achieve both confidentiality and compression but it suffers from well-known weaknesses which do not ensure protection of predictable files against dictionary attacks. And also existing system makes use of proxy re-encryption, has been proposed but information on performance and overhead were not provided. Unfortunately, compression loses its effectiveness in conjunction with end-to-end encryption. End-to-end encryption in a storage system is the process by which data is encrypted at its source prior to ingress into the storage system. It is becoming an increasingly prominent requirement due to both the number of security
incidents linked to leakage of unencrypted data and the tightening of sector-specific laws and regulations. Clearly, if semantically secure encryption is used, file compression is impossible, as no one apart from the owner of the decryption key can decide whether two cipher texts correspond to the same plaintext. Trivial solutions, such as forcing users to share encryption keys or using deterministic encryption, fall short of providing acceptable levels of security. As a consequence, storage systems are expected to undergo major restructuring to maintain the current disk/customer ratio in the presence of end-to-end encryption. The design of storage efficiency functions in general and of compression functions in particular that do not lose their effectiveness in presence of end-to-end security is therefore still an open problem. The existing methodologies contain:
3.1 File-level de-duplication
It is commonly known as single-instance storage, file-level data de-duplication compares a file that has to be archived or backup that has already been stored by checking all its attributes against the index. The index is updated and stored only if the file is unique, if not than only a pointer to the existing file that is stored references. Only the single instance of file is saved in
the result and relevant copies are replaced by “stub”
which points to the original file.
3.2 Traditional Encryption algorithm:
Although it is known that data deduplication gives more benefits, security and privacy concerns arise
because the user’s sensitive data is susceptible to both
deduplication almost impossible in this traditional approach. The basic step of the algorithm as shows: KeyGenSE: k is the key generation algorithm that
generates κ using security parameter I
EncSE (k, M): C is the symmetric encryption
algorithm that takes the secret κ and message M and
then outputs the ciphertext C;
DecSE (k, C): M is the symmetric decryption algorithm
that takes the secret κ and ciphertext C and then
outputs the original message M.
3.3 Limitations:
• Compression check only with file name and not file content
• Could not achieve secure access control under a dynamic ownership changing environment • Security degradation of the cloud service
IV.PROPOSED METHODOLOGIES
Storage efficiency functions such as compression and compression afford storage providers better utilization of their storage back ends and the ability to serve more customers with the same infrastructure. Data compression is the process by which a storage provider only stores a single copy of a file owned by several of its users. There are four different compression strategies, depending on whether compression happens at the client side (i.e. before the upload) or at the server side, and whether compression happens at a block level or at a file level. Compression is most rewarding when it is triggered at the client side, as it also saves upload bandwidth. For these reasons, compression is a critical enabler for a number of popular and successful storage services that offer cheap, remote storage to the broad public by performing client-side compression, thus saving both the network bandwidth and storage costs. The goal of the system is to guarantee data confidentiality without losing the advantage of compression. Confidentiality must be guaranteed for all files, including the predictable ones.
The security of the whole system should not rely on the security of a single component (single point of failure), and the security level should not collapse when a single component is compromised. We consider the server as a trusted component with respect to user authentication, access control and additional encryption. The server is not trusted with respect to the confidentiality of data stored at the cloud storage provider. Therefore, the server is not able to perform offline dictionary attacks. Anyone who has access to the storage is considered as a potential attacker, including employees at the cloud storage provider and the cloud storage provider itself. In our threat model, the cloud storage provider is honest but curious, meaning that it carries out its tasks but might attempt to decrypt data stored by users. And also implement back up recover scheme to recover data at the time of infrequent access. Admin can be sent alert to every 3 days, one week, two weeks and three weeks. If the users not login to the system means, automatically recover the data and forward to alternate storage with mobile intimation.
4.1 Block cipher algorithm
In
cryptography
, ablock cipheris adeterministic
algorithm
operating on fixed-length groups ofbits
, calledblocks, with an unvarying transformation that is specified by asymmetric key
. Block ciphers operate as importantelementary components
in the design of manycryptographic protocols
, and are widely used to implementencryption
of bulk data. Iterated product ciphers carry out encryption in multiple rounds, each of which uses a different subkey derivedfrom the original key. One widespread
U.S.
National Institute of Standards and Technology
, NIST) in 1977 was fundamental in the public understanding of modern block cipher design. It alsoinfluenced the academic development
of
cryptanalytic attacks
. Bothdifferential
andlinear
cryptanalysis
arose out of studies on the DES design. As of 2016there is a palette of attack techniques against which a block cipher must be secure, in addition to being robust againstbrute force attacks
. Even a secure block cipher is suitable only for the encryption of a single block under a fixed key. A multitude ofmodes of operation
have been designed to allow their repeated use in a secure way, commonlyto achieve the security goals
of
confidentiality
andauthenticity
. However, block ciphers may also feature as building-blocks in other cryptographic protocols, such asuniversal hash
functions
andpseudo-random number generators
. One important type of iterated block cipher known as asubstitution-permutation network
(SPN)takes a block of the plaintext and the key as inputs, and applies several alternating rounds consisting of asubstitution stage
followed by apermutation
stage—
to produce each block of cipher text output.The non-linear substitution stage mixes the key bits with those of the plaintext, creating Shannon'sconfusion
. The linear permutation stage then dissipates redundancies, creatingdiffusion
. Asubstitution box
(S-box)substitutes a small block of input bits with another block of output bits. This substitution must beone-to-one
, to ensure invertibility (hence decryption). A secure S-box will have the property that changing one input bit will change about half of the output bits on average, exhibiting what is known as theavalanche effect—
i.e. it has the property that each output bit will depend on every input bit.4.1.2 Pseudo code for Block Cipher algorithm:
Step 1: Fractioning of the text into 64-bit (8 octet) blocks;
Step 2: Initial permutation of blocks;
Step 3: Breakdown of the blocks into two parts: left and right, named L and R;
Step 4: Permutation and substitution steps repeated 16 times (called rounds);
Step 5: Re-joining of the left and right parts then inverse initial permutation.
4.2 Block level data chunk similarity
Block compression requires more processing power than the file compression, since the number of identifiers that need to be processed increases greatly. Correspondingly, its index for tracking the individual iterations gets also much larger. Using of variable length blocks is even more source-intensive. Moreover, sometimes the same hash number may be generated for two different data fragments, which is called hash collisions. If that happens, the system will not save the new data as it sees that the hash number already exists in the index. The algorithm steps as follows
BlockTag(FileBlock) - It computes hash of the File block as file block Tag;
DupCheckReq(Token) - It requests the Storage Server for Duplicate Check of the file block.
FileUploadReq(FileBlockID, FileBlock, Token) – It uploads the File Data to the Storage Server if the file block is Unique and updates the file block Token stored.
FileBlockEncrypt(Fileblock) - It encrypts the file block with Convergent Encryption, where the convergent key is from similarity checking of the file block;
TokenGen(File Block, UserID) – the process loads the associated privilege keys of the user and generate token.
4.2.2 Psuedo code for secure data compression: Step 1: User profiling: Client registration and log-in Step 2: Session password: Token generation and verification
Step 3: Client initiates file transfer (upload/download). Step 4: File-upload: check for duplicate
Step 5: If duplicate at any of file name and file content, create file pointer and store in CSP
Step 6: If no duplicate found, store encrypted file in CSP.
Step 7: File-download: Data owner to decrypt and download file.
Step 8: Server sync with client and completes file upload/download process
Step 9: Check Login time of user after 3 days, 1 week, 2 week and 3 Weeks
Step 10: If no login means, send mobile intimation to user
Step 11: Recover the files and forward to alternative mail
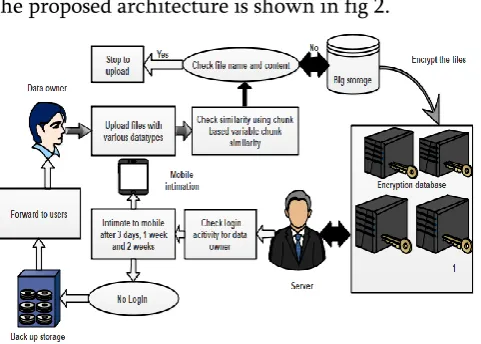
The proposed architecture is shown in fig 2.
Figure 2 : Proposed Framework
4.3 ADVANTAGES
• Dynamic updation can be implemented in cloud storage. File and file content analyzed
• Security is high and to provide data integrity to all data owners
V. CONCLUSION
The notion of authorized data de-duplication technique is specialized data compression technique which eliminates redundant data as well as improves storage and bandwidth utilization. Symmetric encryption technique is proposed to enforce confidentiality during de-duplication, which encrypt data before outsourcing. Security analysis demonstrates that the schemes are secure in terms of insider and outsider attacks. To better protect the data backup, session time analysis of user is presented along with TTL property, to address problem of data blockages in real time cloud environments.
VI. REFERENCES
[1]. X. Zhang, C. Liu, S. Nepal and J. Chen, “An
Efficient Quasiidentifier Index based Approach for Privacy Preservation over Incremental Data
Sets on Cloud,” Journal of Computer and System
Sciences (JCSS), 79(5): 542-555, 2013.
[2]. X. Zhang, T. Yang, C. Liu and J. Chen, “A
Scalable Two-Phase Top-Down Specialization Approach for Data Anonymization using
Systems, in MapReduce on Cloud,” IEEE
Transactions on Parallel and Distributed, 25(2): 363-373, 2014.
[3]. N. Laptev, K. Zeng and C. Zaniolo, “Very fast
estimation for result and accuracy of big data
analytics: The EARL system,” Proceedings of the
29th IEEE International Conference on Data Engineering (ICDE), pp. 1296-1299, 2013. [4]. T. Condie, P. Mineiro, N. Polyzotis and M.
Weimer, “Machine learning on Big Data,”
Proceedings of the 29th IEEE International Conference on Data Engineering (ICDE), pp. 1242-1244, 2013.
[5]. Aboulnaga and S. Babu, “Workload management for Big Data analytics,”
Conference on Data Engineering (ICDE), pp. 1249, 2013
[6]. M. Abadi, D. Boneh, I. Mironov, A.
Raghunathan, and G. Segev,“Message-locked encryption for lock-dependent messages,” in
Advances in Cryptology - CRYPTO 2013 - 33rd Annual Cryptology Conference, Santa Barbara, CA, USA, August 18-22, 2013. Proceedings, Part I, 2013, pp. 374–391.
[7]. L. Wang, J. Zhan, W. Shi and Y. Liang, “In cloud,
can scientific communities benefit from the
economies of scale?” IEEE Transactions on
Parallel and Distributed Systems 23(2): 296-303, 2012.
[8]. B. Li, E. Mazur, Y. Diao, A. McGregor and P. Shenoy, “A platform for scalable one-pass
analytics using mapreduce,” in: Proceedings of
the ACM SIGMOD International Conference on Management of Data (SIGMOD'11), 2011, pp. 985-996.
[9]. R. Kienzler, R. Bruggmann, A. Ranganathan and
N. Tatbul, “Stream as you go: The case for incremental data access and processing in the
cloud,” IEEE ICDE International Workshop on
Data Management in the Cloud (DMC'12), 2012 [10]. C. Olston, G. Chiou, L. Chitnis, F. Liu, Y. Han, M. Larsson, A. Neumann, V.B.N. Rao, V. Sankarasubramanian, S. Seth, C. Tian, T.
ZiCornell and X. Wang, “Nova: Continuous pig/hadoop workflows,” Proceedings of the
ACM SIGMOD International Conference on Management of Data (SIGMOD'11), pp. 1081-1090, 2011.
[11]. K.H. Lee, Y.J. Lee, H. Choi, Y.D. Chung and B. Moon, “Parallel data processing with mapreduce: A survey,” ACM SIGMOD Record
40(4): 11-20, 2012.
[12]. T. Jiang, X. Chen, Q. Wu, J. Ma, W. Susilo, and
W. Lou, “Secure and efficient cloud data Deduplication with randomized tag,” IEEE
Trans. Information Forensics and Security, vol. PP, no. 99,
[13]. Y. Zhou, D. Feng, W. Xia, M. Fu, F. Huang, Y.
Zhang, and C. Li, “Secdep: A user-aware efficient fine-grained secure Deduplication scheme with multi-level key management,” in
IEEE 31st Symposium on Mass Storage Systems and Technologies, MSST 2015, Santa Clara, CA, USA, May 30 - June 5, 2015, 2015, pp. 1–14. [14]. Z. Yan, W. Ding, X. Yu, H. Zhu, and R. H. Deng,
“Deduplication on encrypted big data in cloud,”
IEEE Trans. Big Data, vol. 2, no. 2, pp. 138–150, 2016.
[15]. “Prism (surveillance program),”
https://www.theguardian.com/us-news/ prism. [16]. R. Bhaskar, S. Guha, S. Laxman, and P. Naldurg,
“Verito: A practical system for transparency and accountability in virtual economies,” in 20th
Annual Network and Distributed System Security Symposium, NDSS 2013, San Diego, California, USA, February 24-27, 2013, 2013. [17]. D. Boyd, K. Crawford, S. Shaikh, and V.
Ravishankar, “Six provocations for big data,”
Six-provocations-for-Big-Data1.pdf.
[18]. X. Yang, R. Lu, H. Liang, and X. Tang, “SFPM: A
secure and fine-grained privacy-preserving matching protocol for mobile social
networking,” Big Data Research, vol. 3, pp. 2–9, 2016.
[19]. A. K. Mohan, E. Cutrell, and B. Parthasarathy,
“Instituting credibility, accountability and
transparency in local service delivery?: helpline
and aasthi in karnataka, india,” in International
conference on information and communication technologies and development, ICTD 2013, Cape Town, South Africa, December 7-10, 2013, Volume 1: Papers, 2013, pp. 238 247.
[20]. D. Boneh, E. Goh, and K. Nissim, “Evaluating 2
-dnf formulas on ciphertexts,” in Theory of
[21]. D. Boneh and B. Waters, “Conjunctive, subset, and range queries on encrypted data,” in Theory
of Cryptography, 4th Theory of Cryptography Conference, TCC 2007, Amsterdam, The
Netherlands, February 21-24, 2007,
Proceedings, 2007, pp. 535–554.
[22]. T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein, Introduction to Algorithms (3. ed.). MIT Press, 2009.
[23]. D. E. Knuth, The Art of Computer Programming, Volume III: Sorting and Searching. Addison-Wesley, 1973.
[24]. G. Ateniese, K. Fu, M. Green, and S.
Hohenberger, “Improved proxy re-encryption schemes with applications to secure distributed
storage,” ACM Trans. Inf. Syst. Secur., vol. 9, no.
1, pp. 1–30, 2006.
Cite this article as :
K. Suvetha Bharathi, K. Palanivel, "Secure Data Compression Scheme for Scalable Data in Dynamic Data Storage Environments", International Journal of Scientific Research in Computer Science, Engineering and Information Technology (IJSRCSEIT), ISSN : 2456-3307, Volume 5 Issue 4, pp. 229-237,
July-August 2019. Available at doi :
https://doi.org/10.32628/CSEIT195439