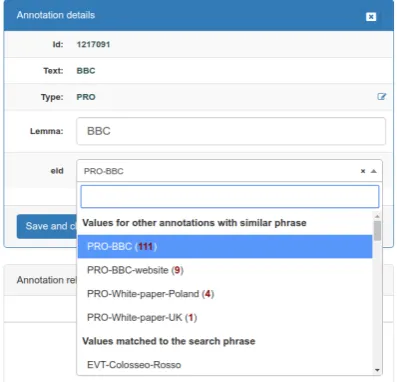
Figure 3: Batch annotation attribute editor
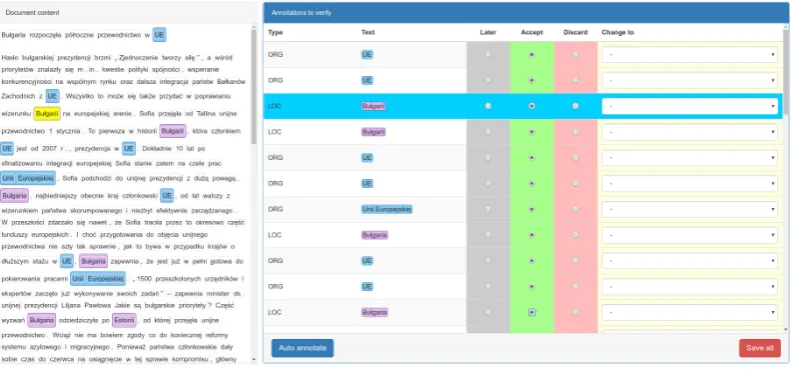
Figure 4: Auto annotation and candidate verification perspective
• Annotations with the selected value.
3.11 Export of Morphological Tagging and Annotations Agreements
For tokenized document Inforex can store up to three layers of morphological tags:
• Tagger— tags produced by a tool,
• Agreement — tags entered by a user in the agreement mode,
• Final— tags approved by the super user.
During export it is possible to define which layer of tags should be exported. It is possible to choose one of the following options (see Figure6):
• Final or tagger (if final not present)— export thefinaltags. For tokens which does not have thefinaltag ataggertag is taken.
• Final— export only the final tags. If there are tokens without final tags than the missing tags are reported as errors.
• User (agreement) — export tags created by selected user. For tokens which does not con-tain user agreement tags the tagger tags are taken.
• Tagger— export tagger tags.
3.12 Improved Support for Word Sense Annotation
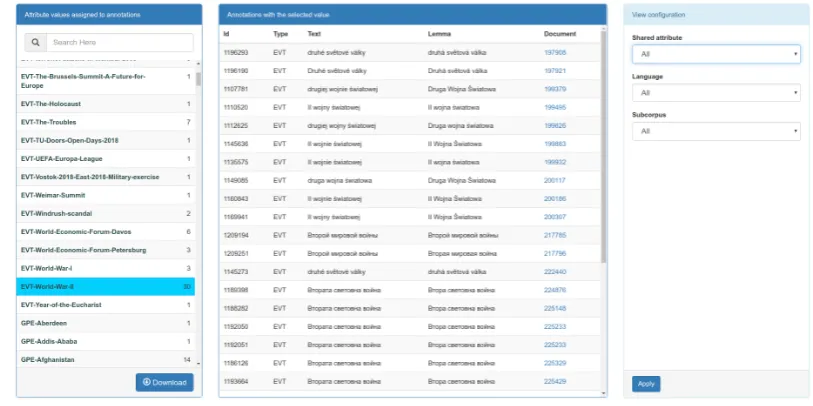
Figure 5: Annotation attribute browser
Figure 6: Export configuration dialog window
perspective. We also added the option to anno-tate the word senses in an agreement mode for fur-ther agreement (see Figure 7). Finally, we have imported all lexical units with their senses from Słowosie´c 3.2 (Piasecki et al.,2016) as an annota-tion set to Inforex.
3.13 Morphological Agreement
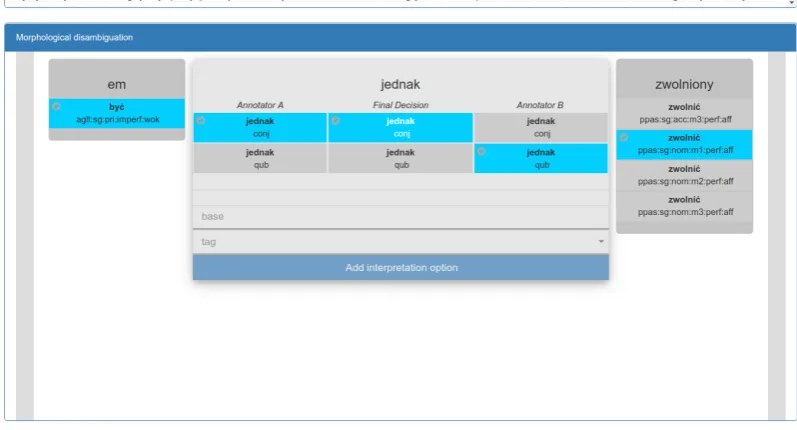
The last feature is support for morphological dis-ambiguation agreement. Inforex provides a page with morphological tag agreement across a given set of documents (see Figure8). The agreement is presented in a numerical form for each documents in the set and after a specific document a list of disagreements is presented. This feature is com-plemented by a document perspective for compar-ing and chooscompar-ing the final morphological tags (see Figure9).
4 Case Studies
In this section we present two uses cases in which various features of Inforex were used in real-life projects.
4.1 BSNLP 2019 Shared Task
Inforex was used to create the training and testing datasets for the need of 2nd Edition of the Shared Task on Multilingual Named Entity Recognition for Slavic languages7. The task aims at recogniz-ing mentions of named entities in news articles in Slavic languages, their lemmatization, and cross-language matching.
More than 10 people were involved in the an-notation process for four languages, i.e. Polish, Czech, Russian and Bulgarian. There were 1–3 annotators per language. The annotation process consists of four main steps:
1. Selection of relevant documents — the doc-ument were automatically crawled and up-loaded to Inforex, therefore some of them were duplicates or text not relevant to the sub-corpus topic. The selected documents were marked with a flagValid content.
2. Annotation of named entity mentions — the same set of five annotatation types was used to annotated all the selected documents. For Polish and Czech the annotators utilized the auto annotate feature described in Section3.7 and we were able to evaluate the usability of
7http://bsnlp.cs.helsinki.fi/shared_
Figure 7: The extended perspective for word sense annotation
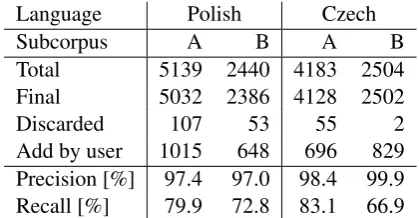
the auto annotation feature. Table1contains evaluation of the automatically recognized and added annotations for two languages and two subcorpora (each on a different topic). The auto annotation feature yielded very high precision of 97-99% with relatively high re-call of 66-82%. This means that in case of Polish and Czech subcorpora 10k out of 14k annotations were added automatically. It was a significant facilitation of the work.
3. Assignment of annotation lemmas — to as-sign lemmas the annotators utilized batch lemma editor and lemma auto fill. For the correctly added annotations the lemmas were also automatically assigned.
4. Assignment of cross-lingual identifier — the goal was to assign the same identifier for each mention across all languages referring to the same real-world entity. There were more than 4k identifiers. The annotators utilized the auto fill features described in Section3.8. The attribute browser was used to validate the entity mentions.
4.2 Polish Translation of the NTU Multilingual Corpus
An ongoing project which goal is to provide Pol-ish translation of the NTU Multilingual Corpus (Tan and Bond, 2011) which consists of two sto-ries from the Sherlock Holmes Canon (The Ad-venture of the Speckled Band and The AdAd-venture of the Dancing Men. The Adventure of the Speck-led Band is the first one translated and prepared for
Language Polish Czech
Subcorpus A B A B
Total 5139 2440 4183 2504 Final 5032 2386 4128 2502
Discarded 107 53 55 2
Add by user 1015 648 696 829 Precision [%] 97.4 97.0 98.4 99.9 Recall [%] 79.9 72.8 83.1 66.9
Table 1: Evaluation of theauto annotationfeature on the BSNLP 2019 Shared Task dataset
Figure 8: Summary of morphological disambiguation agreement
annotated. All tags verified by the team leader ob-tained the status of final annotations. They were added to the version published within CLARIN-PL infrastructure (Błaszczak et al.,2019).
Figure 10: Morphological information provided for human annotators
After the Inforex functionality was developed
and primarily used for creation of The Adventure of the Speckled Band corpus, it was successfully applied to prepare Corpus of the colloquial Pol-ish language (Oleksy, 2019) in another project. This corpus has been designed to address the prob-lem of morphological tagging of user-generated content (UGC) as part of the project ”SentiCog-nitiveServices — next generation service for au-tomating voice of customer and social media sup-port based on artificial intelligence methods”8. The whole corpus (approximately 400000 tokens) is manually annotated with morphological infor-mation and furthermore the sample of 100 docu-ments was prepared as a result of 2+1 annotation.
5 Summary
The last two years have been productive in the development of the Inforex system. Many new features and extensions were implemented during that time and the most important were presented in this paper. Majority of the features and improve-ments were dedicated by users. The most impor-tant news is the that Inforex has been finally re-leased as an open source project.
Work financed as part of the investment in the CLARIN-PL research infrastructure funded by the
Figure 9: The perspective for morphological disambiguation agreement
Polish Ministry of Science and Higher Education.
References
Marta Błaszczak, Kacper Paszke, Ewa Rudnicka, Marcin Oleksy, Jan Wieczorek, Wioleta Kobyli´nska, Dominika Fikus, and Dagmara Kałkus. 2019.
The adventure of the speckled band 1.0
(man-ually tagged). CLARIN-PL digital repository.
http://hdl.handle.net/11321/667.
Bartosz Broda, Michał Marci´nczuk, Marek Maziarz, Adam Radziszewski, and Adam Wardy´nski. 2012. KPWr: Towards a Free Corpus of Polish. In Nico-letta Calzolari, Khalid Choukri, Thierry Declerck, Mehmet U˘gur Do˘gan, Bente Maegaard, Joseph Mar-iani, Jan Odijk, and Stelios Piperidis, editors, Pro-ceedings of LREC’12. ELRA, Istanbul, Turkey.
Wei-Te Chen and Will Styler. 2013. Anafora:
A web-based general purpose annotation
tool. In Proceedings of the 2013 NAACL HLT Demonstration Session. Association for Computational Linguistics, pages 14–19.
http://www.aclweb.org/anthology/N13-3004.
Richard Eckart de Castilho, ´Eva M´ujdricza-Maydt, Seid Muhie Yimam, Silvana Hartmann, Iryna Gurevych, Anette Frank, and Chris Biemann. 2016.
A web-based tool for the integrated annotation of
semantic and syntactic structures. InProceedings
of the workshop on Language Technology Resources
and Tools for Digital Humanities (LT4DH) at COL-ING 2016. pages 76–84. http://tubiblio.ulb.tu-darmstadt.de/97939/.
Michał Marcinczuk, Marcin Oleksy, and Jan Kocon. 2017. Inforex - a collaborative system for text
cor-pora annotation and analysis. In Ruslan Mitkov
and Galia Angelova, editors, Proceedings of the International Conference Recent Advances in Nat-ural Language Processing, RANLP 2017, Varna, Bulgaria, September 2 - 8, 2017. INCOMA Ltd., pages 473–482. https://doi.org/10.26615/978-954-452-049-6 063.
Michał Marci´nczuk, Monika Za´sko-Zieli´nska, and Ma-ciej Piasecki. 2011. Structure annotation in the pol-ish corpus of suicide notes. In Ivan Habernal and V´aclav Matouˇsek, editors, Text, Speech and Dia-logue, Springer Berlin Heidelberg, volume 6836 of
Lecture Notes in Computer Science, pages 419–426.
Marcin Oleksy. 2019. Corpus of the colloquial
polish language. CLARIN-PL digital repository.
http://hdl.handle.net/11321/637.
Maciej Piasecki, Stan Szpakowicz, Marek Maziarz, and Ewa Rudnicka. 2016. PlWordNet 3.0 – Al-most There. In Verginica Barbu Mititelu, Corina For˘ascu, Christiane Fellbaum, and Piek Vossen, edi-tors,Proceedings of the 8th Global Wordnet Confer-ence, Bucharest, 27-30 January 2016. Global Word-net Association, pages 290–299.
Adam Radziszewski. 2013. A tiered crf tagger for pol-ish. InIntelligent Tools for Building a Scientific In-formation Platform.
Pontus Stenetorp, Sampo Pyysalo, Goran Topi´c, Tomoko Ohta, Sophia Ananiadou, and Jun’ichi Tsu-jii. 2012. brat: a web-based tool for NLP-assisted text annotation. InProceedings of the Demonstra-tions Session at EACL 2012. Association for Com-putational Linguistics, Avignon, France.
Liling Tan and Francis Bond. 2011. Building and annotating the linguistically diverse
NTU-MC (NTU-multilingual corpus). In
Proceed-ings of the 25th Pacific Asia Conference on Language, Information and Computation. Insti-tute of Digital Enhancement of Cognitive Process-ing, Waseda University, Singapore, pages 362–371.
https://www.aclweb.org/anthology/Y11-1038.