Highly-Dependable and Long-Lifetime Data-Driven Networking
Processor with Energy Assurance Capability
Shuji SANNOMIYA and Hiroaki NISHIKAWA
Graduate School of Systems and Information Engineering, University of Tsukuba,
Tsukuba Science City, Ibaraki, Japan
Abstract— In addition to thrifty power consumption, failure detection is one of the crucial issues to exploit large wire-less network systems realized by battery-operated wirewire-less devices while keeping system maintenance cost acceptable. CUE, a data-driven networking processor, exploits passive and on-demand (data-driven) processing manner exhaus-tively to its circuit implementation level and thus its power consumption is reduced as low as essentially required. This essential power consumption also results in strong correla-tion between consumpcorrela-tion current and processing load of the CUE. By virtue of this strong correlation, failures changing consumption current can be detected by comparing run-time consumption current with a current range estimated with a given typical processing load beforehand. In this paper, a parallelized pipeline with shortcut to realize load distribution is proposed to smooth the run-time processing load in order to assure the estimation on the current range, and its effectiveness is proven by circuit simulation. Keywords:data-driven processor, real-time multiprocessing, self-timed pipeline, sensor network, machine-to-machine, internet of things
1. Introduction
Wireless network systems composed by battery-operated wireless devices can be easily installed into existing con-structions and infrastructures and thus they are one of promising technologies to realize convenience and safety for both human life and social infrastructure, compared with wired systems. To exploit such systems largely, not only long-lifetime but also high dependability are indispensable because the power budget of battery is strictly limited and doubtful devices make system maintenance cost unaccept-able for large scale systems.
In order to realize highly dependable and long-lifetime devices, the authors have studied a series of data-driven networking processor, named CUE [1], which can provide the wireless devices with not only ultra-low-power feature but also unique observability resulting in autonomous detec-tion of the doubtful devices. The CUE is an embodiment of data-driven principle by which operation execution is initiated on the arrival of input data as long as computational resources (i.e. pipeline stages) are available. This passive operation execution makes it possible to realize real-time
multiprocessing indispensable for networking under time-constraints defined by communication protocols without ex-trinsic program-execution overheads such as context switch-ing and interrupt handlswitch-ing resultswitch-ing in power dissipation.
The data-driven principle is also realized in the circuit im-plementation of the CUE by using self-timed elastic pipeline in which each pipeline stage autonomously transfers valid data based on local negotiation between adjacent pipeline stages. As a result of this local data transfer, pipeline stages with valid data are exclusively driven in the CUE, and thus switching power concentrates into the processing of valid data naturally while the other empty pipeline stages are powered off to reduce leakage power [2]. Moreover, the supply-voltage of the self-timed pipeline without any global-clock can be scaled anytime without suspends, and thus the power consumption can be reduced as low as essentially required by using run-time voltage scaling technique [2]. The ultra-low-power feature of the CUE has already been demonstrated in our previous studies [3].
In addition to the ultra-low-power consumption, the es-sential power consumption of the CUE provides direct observability on the processing load through consumption current because the power in the CUE is consumed only to processing data and thus the consumption current has strong correlation with the number of processing data (i.e. process-ing load). By virtue of this strong correlation, consump-tion current in operaconsump-tion is foresaw under a given typical processing load, and thus the energy which dominates the battery-operated lifetime of system devices can be estimated before the installation of the devices. This foreseeability of the lifetime leads to the drastic reduction of the system main-tenance costs. For instance, the schedule of the replacement of battery can be designed and optimized before the system installation, and thus the working for battery replacement each time the battery runs down becomes no longer required. Moreover, the foreseeable consumption current makes it possible to detect the failures of devices autonomously after the system installation. This is because unexpected failures resulting in the change of the consumption current can be de-tected by measuring the consumption current and comparing the measured result with the amount of consumption current estimated before operation. For instance, the malfunction of the peripheral units such as sensors changes the processing load of the CUE and this change can be detected via the
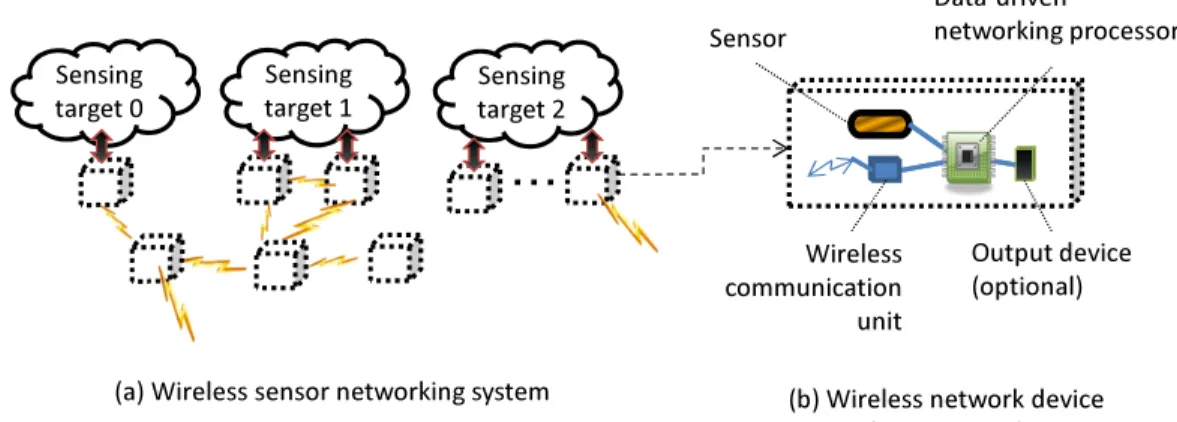
^ĞŶƐŝŶŐ ƚĂƌŐĞƚϬ ^ĞŶƐŝŶŐ ƚĂƌŐĞƚϭ ^ĞŶƐŝŶŐ ƚĂƌŐĞƚϮ ;ĂͿtŝƌĞůĞƐƐƐĞŶƐŽƌŶĞƚǁŽƌŬŝŶŐƐLJƐƚĞŵ tŝƌĞůĞƐƐ ĐŽŵŵƵŶŝĐĂƚŝŽŶ ƵŶŝƚ KƵƚƉƵƚĚĞǀŝĐĞ ;ŽƉƚŝŽŶĂůͿ ĂƚĂͲĚƌŝǀĞŶ ŶĞƚǁŽƌŬŝŶŐƉƌŽĐĞƐƐŽƌ ^ĞŶƐŽƌ
䞉䞉䞉
;ďͿtŝƌĞůĞƐƐŶĞƚǁŽƌŬĚĞǀŝĐĞ ;ƐĞŶƐŽƌŶŽĚĞͿFig. 1: An example: data-driven wireless sensor networking sytem.
consumption current of the CUE, and a wireless network device which transfers unusual data changes the processing load of the CUE in its circumjacent devices, and this change can be also detected via consumption current. This autonomous detection of the failures becomes indispensable in the future wireless network systems because it becomes especially difficult to find out a device with failure in large scale systems especially in the era of Trillion Sensor Universe advocated by Dr. Janusz Bryzek.
To assure the estimation of the consumption current in operation, unpredictable changes of the consumption current should be minimized. In this paper, a pipeline structure implementing the CUE is designed to reduce the dynamic change of the consumption current. The number of oper-ations executed concurrently may change according to the data arrival timing even when processing the same number of data. In the CUE, the supply-voltage is regulated according to the number of operations executed concurrently to realize the ultra-low-power consumption. On the other hand, the regulation of the supply-voltage may change the consump-tion current significantly because the consumpconsump-tion current is in proportion to the square of voltage. Unfortunately, it is difficult to predict the arrival timing of all data precisely. Under this practical constraint, to realize both the ultra-low-power consumption and faithful estimation of the con-sumption current in operation, a parallelized pipeline with shortcut is proposed to realize load distribution at pipeline stage level for smoothing the number of operations executed concurrently. The effectiveness of the proposed pipeline is evaluated through a concrete protocol processing.
2. Data-driven networking processor
In this section, the necessity of both ultra-low-power consumption and failure detection is discussed with an ex-planation of data-driven wireless sensor networking system which is a wireless network system. Moreover, requirements on data-driven networking processor are discussed.
2.1 Data-driven wireless sensor networking
system
Wireless sensor networking systems provide a variety of services such as security, infrastructure monitoring, and disaster prevention, by networking sensors spread on sensing targets as shown in figure 1(a). Although the wireless sensor networking systems can be easily installed because of the absence of wiring, system maintenance cost to keep the wireless devices alive and healthy may increase in large scaled systems due to the replacement or charge of dis-charged batteries and checking of the operation of every device. Therefore the key to realize large scale wireless networking systems is to reduce the frequency of the battery replacement/charge and the work for operation checking as low as possible.
As illustrated in figure 1(b), data-driven wireless sensor networking system realizes ultra-low-power consumption to save the batteries drastically and failure detection to eliminate the need for operation checking, by introducing ULP-DDCMP (Ultra-Low-Power Data-Driven Chip Multi-processor) [4]. As shown in figure 2, the ULP-DDCMP is a chip multiprocessor version of the CUE, and it is realized by interconnecting a ultra-low-power version of the CUE, named ULP-CUE by using a token router which is a switch based multi-stage interconnection network whose switch is realized by merge (M) stages which accept data from two preceding stages in order of arrival and transfers the accepted data to a succeeding stage and branch (B) stages which transfer each data to one of two succeeding stages selectively.
Figure 3 shows the ULP-CUE’s circular pipeline which is indispensable to naturally realize the iteration of operation execution in which operation result is transferred to the input of the succeeding operation. The circular pipeline of the ULP-CUE consists of matching memory (MM) to detect the arrival of operands, program storage (PS) to fetch operations, functional processing unit (FP) to execute the operations
/ŶƚĞƌĐŽŶŶĞĐƚŝŽŶEͬt /Ŷ KƵƚ h>WͲ hϬ h>WͲ hϮ h>WͲ hϭ h>WͲ hϯ ;ĂͿϰͲĐŽƌĞĐŚŝƉŵƵůƚŝƉƌŽĐĞƐƐŽƌ ;ďͿ/ŶƚĞƌĐŽŶŶĞĐƚŝŽŶEͬt;ŶĞƚǁŽƌŬͿ ;ĐͿ^t;ƐǁŝƚĐŚͿ ^t ^t ^t ^t D D
Fig. 2: Data-driven networking chip multiprocessor (an ex-ample of 4-core). D͗DĞƌŐĞ ͗ƌĂŶĐŚ DĂƚĐŚŝŶŐ DĞŵŽƌLJ WƌŽŐƌĂŵ ^ƚŽƌĂŐĞ &ƵŶĐƚŝŽŶĂů WƌŽĐĞƐƐŝŶŐ hŶŝƚ ĂƚĂͲ DĞŵŽƌLJ ĐĐĞƐƐ /Ŷ Ɖ Ƶ ƚ KƵ ƚƉ Ƶ ƚ D D hůƚƌĂͲůŽǁͲƉŽǁĞƌĚĂƚĂͲĚƌŝǀĞŶŶĞƚǁŽƌŬŝŶŐƉƌŽĐĞƐƐŽƌ;h>WͲhͿ LJƉĂƐƐƌŽƵƚĞ;ƐŚŽƌƚĐƵƚͿ
Fig. 3: Circular pipeline to realize ULP-CUE.
and memory access (MA) to read and write data. With this structure, the concurrent operations of target programs can be naturally exploited over the circular pipeline as long as the pipeline stage is available, as a result of data-driven program execution, i.e. no context switching and scheduling are required. Moreover, the circular pipeline is optimized for protocol handling whose operations are mainly unary, by providing shortcut to bypass the MM when unary operations are executed [4].
To realize the passive and on-demand processing to the circuit implementation, the whole stages are realized by us-ing ultra-low-power self-timed elastic pipeline (ULP-STP). In the ULP-STP, only pipeline stages with valid data are driven exclusively as a consequence of the localized data transfer called handshake. Figure 4 shows the structure of the ULP-STP in which each stage consists of a data-latch (DL), functional logic (FL) and transfer control unit (C). The ULP-STP is a kind of asynchronous bundled data pipelines, and it employs phased handshake [5]. Based on the four-phased handshake, the valid data in the STP are transferred between adjacent stages, as follows.
• Reset: After the assertion of the reset signal, the C negates both its send signal representing transfer request and ack signal representing acknowledge.
• The C asserts its ack signal after its send signal is asserted.
• After the assertion of the ack signal, the preceding C negates its send signal.
• After the negation of the send signal, the C asserts both its gate open signal (cp) and its send signal and it negates concurrently its ack signal, only if the ack signal is negated. As a result, the data is latched in the
> ϭ > Ϯ > ϯ ϭ Ϯ ϯ &> ϭ &> Ϯ >͗ĂƚĂͲ>ĂƚĐŚ&>͗&ƵŶĐƚŝŽŶ>ŽŐŝĐ͗dƌĂŶƐĨĞƌŽŶƚƌŽů W͗WŽǁĞƌŽŶƚƌŽůW^͗WŽǁĞƌ^ǁŝƚĐŚ ƐĞŶĚϬ ĂĐŬϬ ƐĞŶĚϭ ĂĐŬϭ ƐĞŶĚϮ ĂĐŬϮ ƐĞŶĚϯ ĂĐŬϯ &> ϯ ĐƉϭ ĐƉϮ ĐƉϯ WŝƉĞůŝŶĞƐƚĂŐĞ ^ĐĂůĞĚs s^^ W W^ ^ƵƉƉůLJǀŽůƚĂŐĞ ;sͿĐŽŶƚƌŽů ďĂƐĞĚŽŶ ĐŽŶƐƵŵƉƚŝŽŶ ĐƵƌƌĞŶƚ /^^ s
Fig. 4: Self-timed elastic pipeline with run-time voltage scaling and power gating.
stage to which the C belongs.
• The succeeding C repeats the above steps similarly to the C.
This handshake concentrates dynamic consumption cur-rent into the pipeline stages with valid data naturally while the power control and power switch power off the empty pipeline stages to reduce the leakage current through the empty stages. Moreover, the signal propagation delay of the DL, FL and C are changed at equal rate according to the supply-voltage, and thus the supply-voltage of the ULP-STP can be scaled at run-time while the rate of change of the voltage is moderate enough to guarantee the transistor switching, i.e., the throughput and processing time of the ULP-DDCMP can be changed during the execution of target programs.
The ultra-low-power consumption of the ULP-DDCMP realized by the ULP-STP has already been demonstrated [3].
2.2 Requirement for energy assurance
Figure 5 shows the measured values of the throughput and current consumption of the ULP-CUE in a prototype of the ULP-DDCMP. As a proof of the essential power consumption of the ULP-DDCMP, both the throughput and current consumption increase when the occupancy rate of the ULP-STP increases, i.e. they increase when the amount of processing load increases. Moreover, the consumption current has strong correlation with the processing load. This strong correlation makes it possible to estimate consumption current in operation (I[A]) according to the processing load in operation beforehand by using a system level simulator [6] and to calculate battery-operated lifetime (T[sec.] =W/I) of the wireless networking devices by using theIand a given ampere-hour capacity (W[Ah]) before the start of the oper-ation of the devices. This predictability on the lifetime leads to the economical design of the battery replacement/charge schedules.
Ϭ͘Ϭ Ϭ͘Ϯ Ϭ͘ϰ Ϭ͘ϲ Ϭ͘ϴ ϭ͘Ϭ ϭ͘Ϯ Ϭй ϮϬй ϰϬй ϲϬй ϴϬй ϭϬϬй ϭϮϬй ϭϰϬй s ĂůƵĞ;ŶŽƌŵĂůŝnj ĞĚ 䠅 WŝƉĞůŝŶĞŽĐĐƵƉĂŶĐLJƌĂƚĞ;ŶŽƌŵĂůŝnjĞĚͿ dŚƌŽƵŐŚƉƵƚ ŽŶƐƵŵƉƚŝŽŶĐƵƌƌĞŶƚ 㻰㼑㼟㼕㼓㼚㻌 㼠㼍㼞㼓㼑㼠 dŚƌŽƵŐŚƉƵƚ ŽŶƐƵŵƉƚŝŽŶĐƵƌƌĞŶƚ EKd͗ dŚĞǀĂůƵĞƐĂƌĞŶŽƌŵĂůŝnjĞĚƚŽďĞϭ͘ϬĂŶĚϭϬϬйƌĞƐƉĞĐƚŝǀĞůLJ ǁŚĞŶƚŚƌŽƵŐŚƉƵƚĂĐŚŝĞǀĞƐƚŚĞĚĞƐŝŐŶƚĂƌŐĞƚ͘ 㻻㼢㼑㼞㼘㼛㼍㼐㻌㼞㼑㼓㼕㼛㼚
Fig. 5: Direct correlation between throughput and consump-tion current. Ϭ͘Ϭ Ϭ͘ϱ ϭ͘Ϭ ϭ͘ϱ Ϯ͘Ϭ Ϯ͘ϱ ϯ͘Ϭ Ϭй ϮϬй ϰϬй ϲϬй ϴϬй ϭϬϬй ϭϮϬй ϭϰϬй dŚƌ ŽƵŐŚƉƵƚ ;EŽƌŵĂůŝnj ĞĚͿ WŝƉĞůŝŶĞŽĐĐƵƉĂŶĐLJƌĂƚĞ;ŶŽƌŵĂůŝnjĞĚͿ sDz s 㻰㼑㼟㼕㼓㼚㻌 㼠㼍㼞㼓㼑㼠 㻻㼢㼑㼞㼘㼛㼍㼐㻌㼞㼑㼓㼕㼛㼚 EKd͗ dŚĞǀĂůƵĞƐĂƌĞŶŽƌŵĂůŝnjĞĚƚŽďĞϭ͘ϬĂŶĚϭϬϬйƌĞƐƉĞĐƚŝǀĞůLJ ǁŚĞŶƚŚƌŽƵŐŚƉƵƚĂĐŚŝĞǀĞƐƚŚĞĚĞƐŝŐŶƚĂƌŐĞƚ͘
Fig. 6: Run-time scaling of throughput design target.
On the other hand, the processing load may change in operation due to failures such as malfunction of the sensors and also the consumption current may change due to the change of the processing load as well as operating environment changes such as the change of temperature. Therefore, the actual battery-operated lifetime may differ from the calculation. Fortunately, by virtue of the strong correlation, such failures and contingencies in the data-driven wireless networking system can be detected by mea-suring the consumption current in operation. In particular, ampere-hour capacity during a certain timet[sec.], which is denoted by Wt[Ah], can be calculated as explained above,
and discharge capacity (d[Ah]) which is the production of the measured run-time consumption current within thetand t is compared to the Wt. The deviance of the d from the
the range of theWtmeans that the failures or contingencies
occur. In operation, devices whose d becomes out of the Wtinform the failures/contingencies occurrence to the other
devices or the center of management with a request to settle the failures/contingencies. This autonomous detection
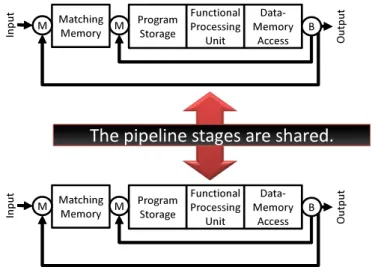
DĂƚĐŚŝŶŐ DĞŵŽƌLJ WƌŽŐƌĂŵ ^ƚŽƌĂŐĞ &ƵŶĐƚŝŽŶĂů WƌŽĐĞƐƐŝŶŐ hŶŝƚ ĂƚĂͲ DĞŵŽƌLJ ĐĐĞƐƐ /ŶƉƵƚ KƵƚƉƵƚ D D DĂƚĐŚŝŶŐ DĞŵŽƌLJ WƌŽŐƌĂŵ ^ƚŽƌĂŐĞ &ƵŶĐƚŝŽŶĂů WƌŽĐĞƐƐŝŶŐ hŶŝƚ ĂƚĂͲ DĞŵŽƌLJ ĐĐĞƐƐ /ŶƉƵƚ KƵƚƉƵƚ D D
dŚĞƉŝƉĞůŝŶĞƐƚĂŐĞƐĂƌĞƐŚĂƌĞĚ͘
dŚĞƉŝƉĞůŝŶĞƐƚĂŐĞƐĂƌĞƐŚĂƌĞĚ͘
Fig. 7: Load distribution between two parallel pipelines.
of the failures leads to the elimination of the health checking operations.
In addition to these energy assurance features, the ULP-DDCMP provides a natural tolerance against the processing load fluctuation. As shown in the figure 5, as a result of the handshake, the throughput is kept at a maximum value without any additional controls when the pipeline occupancy rate exceeds the design target and reaches overload region temporarily. However, the processing time increases when the pipeline occupancy rate is in the overload region because data transfer at some pipeline stages is postponed until the succeeding stages completes the data processing and becomes empty. To avoid this processing time increase, as shown in figure 6, the supply-voltage is controlled according to the pipeline occupancy rate observed through the con-sumption current and it is increased to speed-up the ULP-DDCMP before the observed pipeline occupancy rate falls into the overload region.
This run-time supply-voltage control may change the con-sumption current widely because the concon-sumption current is in proportion to the square of the supply-voltage. In order to preserve the consumption current in operation within the estimated range, dynamic processing load fluctuation should be suppressed as possible from the viewpoint of the energy assurance of ULP-DDCMP.
3. Fine-grain load distribution to
en-hance elasticity
In this section, the pipeline structure of the ULP-DDCMP is redesigned to suppress the dynamic processing load fluc-tuation. In chip multiprocessor structures, processing cores share the processing load among them, and usually a set of data is the unit of processing load distribution. For instance, a packet is a unit to be assigned to one of the processing cores in protocol handling. On the other hand, the actual
WƌŽŐƌĂŵ
^ƚŽƌĂŐĞ
&ƵŶĐƚŝŽŶĂů
WƌŽĐĞƐƐŝŶŐ
hŶŝƚ
ĂƚĂͲ
DĞŵŽƌLJ
ĐĐĞƐƐ
D
DĂƚĐŚŝŶŐ
DĞŵŽƌLJ
WƌŽŐƌĂŵ
^ƚŽƌĂŐĞ
&ƵŶĐƚŝŽŶĂů
WƌŽĐĞƐƐŝŶŐ
hŶŝƚ
ĂƚĂͲ
DĞŵŽƌLJ
ĐĐĞƐƐ
/ŶƉƵƚ
D
D
D
KƵƚƉƵƚ
D
^ŚŽƌƚĐƵƚ
KƵƚƉƵƚ
D
/ŶƉƵƚ
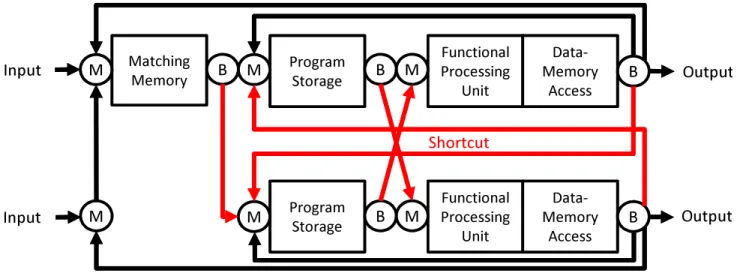
Fig. 8: ULP-CUE-P.processing load of a unit may differ due to the amount and value of the assigned data. To smooth the processing load fluctuation finely, deeper load distribution should be realized.
3.1 Utilization of ULP-STP’s elasticity
Although the packet handling time is in the order of hundreds µsec. according to the actual demonstration ex-periments [4], it is practically difficult to estimate the arrival timing of all packets in the hundredsµsec.order, and thus the number of packets processed concurrently may differ from the estimated value. Fortunately, in the ULP-STP, the number of operations executed concurrently is temporally smoothed as a result of the handshake and thus the pipeline occupancy rate may be kept before the overload region when the number of packets processed concurrently changes. However, this elasticity of the ULP-STP is available when the number of packets processed is within a certain value, and therefore the run-time load distribution is necessary to keep the elasticity of every ULP-STP available.
From the viewpoint of the fair sharing of the processing load among ULP-CUE’s, the processing load should be finely distributed, i.e. operation level load distribution is preferable instead of conventional packet level load distri-bution. However such fine grain load distribution results in the increase of both power consumption and processing time due to the intensive usage of the interconnection net-work among the ULP-CUE’s because every data transferred among the ULP-CUE’s goes through the interconnection network shown in the figure 2. In this paper, the pipeline of the ULP-DDCMP is restructured by integrating the operation execution pipeline and the interconnection network to realize operation level load distribution without overheads.
3.2 Parallelized self-timed elastic pipeline with
shortcut
The pipeline occupancy rate of each processing core, ULP-CUE, of the ULP-DDCMP is determined by the num-ber of operations executable concurrently, and thus sharing the operations among the ULP-CUE’s fairly results in the reduction of the pipeline occupancy rate of each ULP-CUE. That is, the fair sharing of operations suppresses the occurrence of the situation where the pipeline occupancy rate falls into the overload region. To realize such fair sharing of operations, the pipeline structure should be redesigned to avoid the intensive usage of the MM, PS, FP, MA of a specific processing core, as shown in figure 7.
To realize completely fair sharing of operations, all of operations fetched in the PS should be assigned among all of the FP, MA and MM fairly. In this paper, sharing is studied among two ULP-CUE’s as a minimum configuration. To make it possible to assign any of operations to both ULP-CUE’s, the PS’s store the same target program. The operations fetched in the PS’s are distributed in round-robin fashion between two FP’s to realize fair sharing. To realize this distribution, branch (B) stages whose output is transferred to alternately upper path and lower path and merge (M) stages to merge the outputs from the B’s are added to provide shortcut for load distribution between two parallel circular pipelines. As for the MM, the output data is distributed in round-robin fashion as well as the fetched operations.
Figure 8 illustrates the redesigned pipeline named ULP-CUE-P (ULP-CUE with parallelized circular operation ex-ecution pipeline). In the ULP-CUE-P, the MA’s share one physical memory realized by 2-port RAM to preserve co-herency of stored data. Moreover, the MM’s are unified as one because binary operations are a minority in protocol handling. For instance, the binary operations occupy only
DD
ϭͬϮ DDϮͬϮ Ɖ ϭͬϮW^ ϮͬϮW^ ϭͬϯ&W Ϯͬϯ&W ϯͬϯ&W DϭͬϮ DϮͬϮ h& ϭͬϮ h&ϮͬϮ DƐ ů Dů Ɛ Dŝ DĞ Ğ ď DƉ W^
ϭͬϮ ϮͬϮW^ džů džDů ϭͬϯ&W Ϯͬϯ&W ϯͬϯ&W DϭͬϮ DϮͬϮ džƐ
džDƐ džDĞ džĞ džď džDŝ /ŶƉƵƚ KƵƚƉƵƚ /ŶƉƵƚ KƵƚƉƵƚ
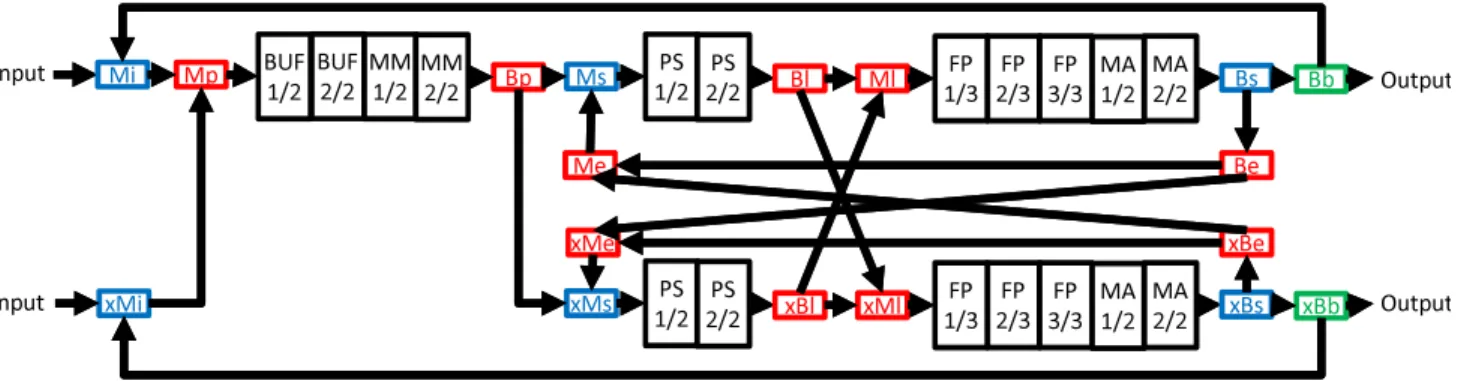
Fig. 9: Designed circuit of ULP-CUE-P.
approximately 20% of UDP/IP handling program. With the proposed pipeline structure, the operations are distributed fairly between two parallel pipelines without transferring the interconnection network between processing cores which are essentially unnecessary to execute target operations.
3.3 Evaluation on load distribution
To evaluate the processing load distribution capability of the proposed ULP-CUE-P, the circuit of the ULP-CUE-P is simulated. The circuit of the ULP-CUE-P is described at RTL (Register Transfer Level) by utilizing the RTL de-scription and pipeline tact information of the ULP-DDCMP. The circuit size of the ULP-CUE-P is comparable to that of the two ULP-CUE’s, and thus the simulation result of the ULP-CUE-P is compared with that of the two ULP’s.
To realize the proposed ULP-CUE-P, the merge and branch stages described blow are added in addition to the MM, PS, FP, MA and MM.
• Mi: a merge stage to accept input data
• Bs: a branch stage to realize the shortcut
• Ms: a merge stage to realize the shortcut
• Bb: a branch stage for binary operation and output
• Bp: a branch stage for distributing the binary operations
• Be: a branch stage for distributing the unary operations
• Mp: a merge stage for binary operations
• Me: a merge stage for unary operations
• Bl: a branch stage for sharing operations
• Ml: a merge stage for sharing operations
Figure 9 shows the circuit of the ULP-CUE-P. The branch and merge stages of the lower pipeline are labeled with "x" to distinguish those of the upper pipeline. The ULP-CUE-P has only one MM, and thus a buffer stage named BUF is added to compensate one of two MM’s existing in the conventional two ULP-CUE’s. This is because the reduction of the number of pipeline stages increases the pipeline occupancy rate against the same processing load. To annotate the signal propagation delay in the ULP-DDCMP to the described circuit, the pipeline tact extracted through the circuit simulation of the post-layout circuit of the prototype
LSI of the ULP-DDCMP which is shown in figure 10 is set to every pipeline stage of the described circuit.
In the simulation, the conventional ULP-CUE is realized by disabling the branch stages, Bp, Bl and Be for load distribution. To confirm that the processing time increase due to the processing load fluctuation is suppressed by the ULP-CUE-P, the processing time of a protocol handling program is measured through the simulation. As the pro-tocol handling program, a data-driven program of UDP/IP handling is used because its connection-less packet transfer results in low-power consumption indispensable in battery-operated wireless devices and thus it is one of the protocols expected to be used in the wireless ad hoc networking systems. Figure 11 shows the measured results of ULP-CUE-P and two ULP-CUE’s. As shown in the result, the processing time increase in the ULP-CUE-P (proposed) is within approximately 4% when three packets are processed simultaneously while approximately 18% processing time increases in the two ULP-CUE’s (conventional). This is a proof that the processing load fluctuation is suppressed by the proposed pipeline structure.
4. Conclusions
This paper describes a parallelized self-timed pipeline with shortcut to exploit the energy assurance capability of the data-driven networking processor CUE, in order to preserve the ultra-low-power consumption of the CUE and to assure the estimation of the CUE’s energy and consumption current in operation. The proposed pipeline is evaluated through an RTL simulation with UDP/IP handling and it is proven that the processing load fluctuation resulting in the change of the consumption current in operation can be suppressed by the operation level load distribution realized by the proposed circuit.
The proposed circuit is an implementation of the operation level load distribution for two circular pipelines (processing cores), and its scalability for 4 or more pipelines should be further studied because the multiport memory required to preserve the stored data coherency is cannot be scaled without overhead. On the other hand, the consumption
Fig. 10: Prototype of data-driven networking chip multiprocessor. Ϭ͘Ϭ Ϭ͘Ϯ Ϭ͘ϰ Ϭ͘ϲ Ϭ͘ϴ ϭ͘Ϭ ϭ͘Ϯ
ϭ
Ϯ
ϯ
Wƌ
ŽĐĞƐƐŝŶŐ
ƚŝŵĞ;ƌ
Ă
ƚŝŽͿ
DƵůƚŝƉůŝĐŝƚLJ
ᥦᡭἲ
ᚑ᮶ᡭἲ䠄
h>WͲhdžϮ
㸧
;dŚĞŶƵŵďĞƌŽĨhWͬ/WƉĂĐŬĞƚƐ
ƉƌŽĐĞƐƐĞĚĐŽŶĐƵƌƌĞŶƚůLJͿ
WƌŽƉŽƐĞĚ
ŽŶǀĞŶƚŝŽŶĂů
;h>WͲhdžϮͿ
Fig. 11: Processing time of UDP/IP protocol handling.
current on a program can be easily estimated and observed if the program is allocated to a processing cores group different from the other groups which execute the other programs in target application, and the proposed circuit may be sufficient to become one of the processing cores groups, i.e. the proposed circuit can be the unit of the program allocation in chip multiprocessor. To examine this possibility and demonstrate the practical effectiveness of the proposed pipeline architecture, the proposed circuit is now being evaluated through a system level simulation [6] of an actual data-driven wireless sensor networking system. The result of the further evaluation will be presented at the conference.
Acknowledgement
Although it is impossible to give credit individually to all those who organized and supported our project, the authors would like to express their sincere appreciation to all the colleagues in the project.
This research work was supported in part by START program (Program for Creating Start-ups from Advanced Research and Technology) of MEXT (Ministry of Education, Culture, Sports, Science and Technology) and IS program of Semiconductor Technology Academic Research Center (STARC). The CAD tools for the evaluation in this work is supported by VDEC (VLSI Design and Education Center), the University of Tokyo in collaboration with Synopsys, Inc.
References
[1] Hiroaki Nishikawa, “Design Philosophy of a Networking-Oriented Data-Driven Processor: CUE,” IEICE Transactions on Electronics, Vol.E89-C No.3, pp.221-229, Mar. 2006.
[2] Kei Miyagi, Shuji Sannomiya, Makoto Iwata, and Hiroaki Nishikawa, "Low-Powered Self-Timed Pipeline with Variable-Grain Power Gating and Suspend-Free Voltage Scaling," in Proc. of PDPTA, pp.618-624, July 2013.
[3] Kazuhiro Aoki, Hiroshi Ishii, Makoto Iwata, and Hiroaki Nishikawa, “A Comprehensive Evaluation of ULP-DDNS by Platform Simulator,” in Proc. of PDPTA, pp.445-451, July 2012.
[4] Shuji Sannomiya, Kazuhiro Aoki, Makoto Iwata, and Hiroaki Nishikawa, “Power-Performance Verification of Ultra-Low-Power Data-Driven Networking Processor: ULP-CUE,” in Proc. of PDPTA, pp.465-471, July 2012.
[5] C. J. Myers, “Asynchronous circuit design,” Univ. of Utah John Wiley & Sons, Inc., 2001.
[6] Kazuhiro Aoki, Shuji Sannomiya, and Hiroaki Nishikawa, “Data-Driven Sensor Networking System Simulator,” in Proc. of PDPTA, July 2015.(to be published)