Analysis and Predictions on Students’ Behavior Using Decision Trees in
Weka Environment
Vasile Paul Brefelean
Babe-Bolyai University, Faculty of Economics and Business Administration,
Cluj-Napoca /Romania
[email protected]
Abstract
. Decision trees classifiers are simple and prompt data classifiers as supervised learning means with the potential of generating comprehensible output, usually used in data mining to study the data and generate the tree and its rules that will be used to formulate predictions. One of the major challenges for knowledge discovery and data mining systems stands in developing their data analysis capability to discover out of the ordinary models in data. The excellence of a university is specified among other concerns by its adapting competence to the constant changing needs of the socio-economic background, the quality of the managerial system based on a high level of professionalism and on applying the latest technologies. This article represents an implementation of a J48 algorithm analysis tool on data collected from surveys on different specialization students of my faculty, with the purpose of differentiating and predicting their choice in continuing their education with post university studies (master degree, Ph.D. studies) through decision trees.Keywords.
Decision tree, data mining, algorithm, C4.5, J48, performance measures.1. Introduction
The university as an institution is in a transitional phase [9] with the need to engage in a process of change, adjustment and innovation. The university as a community of scholars surrounded by pupils and auditors is no longer in tune with reality. The higher education institutions will only be able to solve the major challenges that they have long faced by making creative use of information and communication technologies [9].
Contemporary facts that knowledge is becoming a central economic dynamic might, with the transfer from the concept of
“information society” to that of “knowledge societies” [15], led to a re-consideration of the impact of the educational process, that universities are driven to situations of competition, among one another and with the private sector, particularly with the growth of e-learning and trans-national systems.
Two main objectives can be distinguished in the data mining process integrated in the management system: a description objective consisting in establishing the eloquent variables and its influences; and a prediction objective [21]. Data mining helps managers set up new hypothesis, in a short period of time, which was unattainable or time-consuming in the past, in view of large datasets and previous methods.
The comprehension of students’ opinions, satisfactions and discontentment regarding the each component of the educational process, and the prediction of their preference in certain fields of study, and the choice in continuing their education, is a factual and imperative preoccupation for every higher education institution manager. In the present paper the author builds a succession of decision trees based on Weka’s implemented J48 algorithm, in the attempt to differentiate and predict the students’ choice in continuing their education with post university studies.
2. The science of Data mining
Data mining is an emergent and rising area of research and development, both in academic world as well as in business, connecting interdisciplinary studies and development adjacent to diverse domains [17]. In the narrow sense, it is considered an assortment of tools and methods, one of numerous technologies required to sustain a customer-centric activity [2]. In a broader sense, data mining is an attitude stating that business events should be based on learning, that informed decisions are better than
51
uninformed decisions, and that measuring outcome is advantageous to the business [2]. Data mining is the combination of [16]:
- Statistical modeling. Linear regressions and other types of modeling analyses are common and have been used in everything from the medical processes to the credit rating of persons by financial service providers [8].
- Database storage. Today, organizations can store and query terabytes of information in data warehouse systems, and in addition, the progress of multidimensional data models, has permitted users to shift from a transactional vision of customers to a more active and analytical way. - AI technologies. Data mining started to grow during the last decade, with many commercial, medical, marketing, and manufacturing applications [25], with a future wide open in predictive analytics [1].
Various novel international research in data mining in education areas embraced: voice recognition, text and image based data mining [10], object-oriented models coupled with data mining techniques to predict the class configuration based on the course prerequisites and the prior courses taken [13], the development of digital library systems that utilize advanced data mining implemented as centralized web application with links to publicly accessible data repositories on the Internet [22] etc.
In the scientific literature there are a number of studies based on students’ evaluations, exams, behavior: experiments with the purpose of learning the factor which contributes to the high learning performance and identifying the students with high probability risk to fail exams [3] using Oracle Data Mining decision tree algorithms; quantitative methodologies adopted to mine data from Learning Management Systems (LMS) to establish usage patterns and online learning designs within the various organizational levels operating in the university [11]; data mining models based on clustering techniques used to detect cheats in online student assessments [7]; surveys and analysis intended for emphasizing the connections between the university and master degree studies and continuing education through students behavior [5],[6] which used questionnaires or data provided by database backed LMS [23].
2.1 Decision trees and algorithms
A decision tree classifier is one of the most widely used supervised learning methods used
for data exploration, approximating a function by piecewise constant regions, and does not necessitate previous information of the data distribution [17]. Decision trees models are commonly used in data mining to examine the data and induce the tree and its rules that will be used to make predictions [12]. The true purpose of the decision trees is to classify the data into distinct groups or branches that generate the strongest separation in the values of the dependent variable [18], being superior at identifying segments with a desired behavior such as response or activation, thus providing an easily interpretable solution.
The concept of decision trees was developed and refined over many years by J. Ross Quinlan starting with ID3 (Interactive Dichotomizer 3) [18], [19]. Method based on this approach use an information theoretic measure, like entropy, for assessing the discriminatory power of each attribute [17]. The major decision tree algorithms are grouped as [17]: (a) classifiers from the machine learning community: IDS, C4.5, CART; and (b) classifiers for large databases : SLIQ, SPRINT, SONAR, RainForest.
Weka workbench used in this research implements two of the most common decision tree construction algorithms: ID3 and C4.5 (called version J48). ID3 is one the more famous Inductive Logic Programming methods, developed by Quinlan [19], an attribute based machine-learning algorithm that creates a decision tree on a training set of data and an entropy measure to build the leaves of the tree. C4.5 algorithm is based on the ID3, with supplementary programming to address ID3 problems.
3. Case study – decision trees built on
surveys’ extracted data
For the present paper, using my previous experience to guide the selection process, and the experiments performed with various configurations, I opted to use the J48 because it performs better than ID3 in nearly all circumstances [19]. The basic algorithm for decision tree induction is a greedy algorithm that constructs decision trees in a top-down recursive divide-and-conquer manner. J48 is one of the most used Weka classification algorithms that offers a superior stability between precision, speed and interpretability of results.
The classification trees were constructed using the training set data, made of several
configurations, each with the same set of options, but with probably different option settings together with known class information [14]. The procedure started by partitioning the training set for every option based on the option settings, and the resulting partition was evaluated based on how well it separates the configurations of one class from those of another. The option that created the best partition became the root of the tree. To this node I added one edge for each option setting, and repeated the procedure for all subsets in the partition. The process stopped when no additional split was achievable or desirable [14].
The data used in the research was collected from senior undergraduate students at the Faculty of Economics and Business Administration in Cluj-Napoca, using on-line and written surveys in a collaborative approach. The surveys were prepared to evaluate the students’ motivation in continuing education and the fulfillment regarding the educational process [5],[6] and included multiple choice questions and several written answers, like: gender; specialization; graduated high school; university admission degree; opinions on: fundamental knowledge gained, books, course materials, case studies, curricula, practical activities, participation to grants/research contracts, recommending the specialization to future students, courses teaching methods in each of the years of study; present job; gained scholarships; parents’ material support; scholastic situation at the end of last year; last year final degree etc.
The Knowledge Flow interface provides an alternative to the Explorer for the users who like thinking in terms of how data flows throughout the system, allowing the design and execution of configurations for streamed data processing [25]. If the filters and learning algorithms are capable of incremental learning, data will be loaded and processed incrementally.
Using this module I was able to specify the data stream model (Fig. 1) by opting for Weka components (data sources, preprocessing tools, learning algorithms, evaluation methods, and visualization modules) and bond them into a directed graph that processed and investigated the data. It did not read in the dataset before learning started; instead, the data source module read the input instance by instance and passed it throughout the Knowledge Flow procession.
In order to acquire some specific results and predictions for a certain specialization, I chose only the students of two of the most significant
specializations: IE (informatica economica- Business Information Systems) and CIG (contabilitate si informatica de gestiune – Accounting). I filtered the initial collected data to separate the instances corresponding to IE specialization, and then to the CIG specialization, resulting in two files: IE.arff with 53 instances and CIG.arff with 45 instances.
In the Knowledge Flow interface I first created a data source by choosing the ARFFLoader instrument, then connected it to the arff file. In order to specify the attribute used by the class, I opted for the ClassAssigner tool connected to the DataSources through a dataset component. Following this I chose the master_doct (opinion on continuing education with post university studies) class for cross validation by J48 classifier.
The CrossValidationFoldMaker tool was attached in the data flow model to create the folds for implementing the classifier, and twice linked to the J48 component through the testSet and the trainingSet options. The next step consisted in deciding on a ClassifierPerformance Evaluation tool and its attachment to the data flow model via a batchClassifier and set the number of folds as 3. I also needed two visualization components: TextViewer connected to ClassifierPerformance Evaluator to view the data or the models in textual form, and the GraphViewer connected to J48 classifier, in order to get a graphical representation of the decision trees resulted from the cross validation for each fold.
Figure 1. The graph model built after [25] After applying the model, I achieved an accuracy of 88.68 % (for IE.arff), meaning that 47 instances out of 53 were correctly classified in or model. For the CIG.arff data file I reached 71.74% accuracy, meaning that 33 instances out of 45 were correctly classified. I also obtained the values of several performance measures for numeric prediction, presented in Table 1.
Table 1. Performance measures' results Performance measures Result IE.arff Result CIG.arff Kappa statistic 0 -0.01 MAE, mean absolute error 0.12 0.25
RMSE, root mean square error 0.26 0.41
RAE, relative absolute error (%)
67.48 86.03
RRSE,root relative squared error (%)
96.47 112.07
From the confusion matrix result for the IE.arff data I established that two instances of the Disagree class were assigned to the Agree class, four instances of the Neutral class were assigned to Agree class. For the CIG.arff three instances of the Disagree class were assigned to the Agree class, one instance of the Disagree class were assigned to the Neutral class, seven instances of the Neutral class were assigned to Agree class and two instances of the Agree class were assigned to the Neutral class .
The decision tree resulted from the first data set of the IE.arff file (Fig. 2) has as a central root joint the high_school (graduated high school) attribute, the main mean to differentiate the IE students’ choice in continuing their education. For the second level ramification, the IE students who graduated mostly a high school oriented on Information systems are influenced in their decision by the books, course materials, case studies of the highest quality they received. Examples of interpretation of the decision tree’s branches:
“If the IE students graduated a different high school from the ones presented in the questionnaire (mostly a Information systems high school), agreed they were given sufficient books, course materials, case studies of the highest quality, then they would agree to continue their education with post university studies (master degree, Ph.D. studies)”.
“If the IE students graduated a different high school from the ones presented in the questionnaire (mostly a Information systems high school), were neutral that they were given sufficient books, course materials, case studies of the highest quality, then they would be neutral to continue their education with post university studies (master degree, Ph.D. studies)”.
Figure 2. The decision tree generated from the first data set (IE.arff file)
The decision trees generated on the second and third datasets of the IE.arff file have a single leaf (Agree) due to the class merging throughout the pruning process, with 35 and 36 instances reaching that leaf.
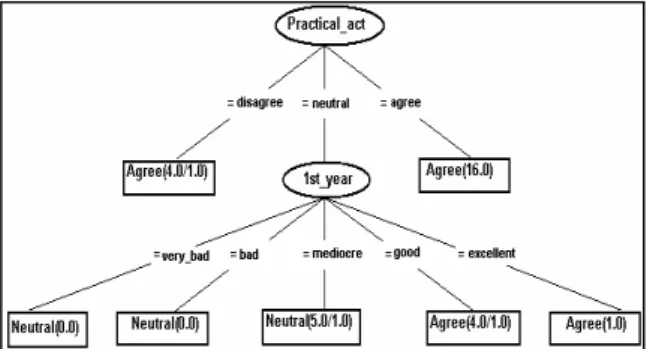
The decision tree resulted from the first data set of the CIG.arff file (Fig. 3) has as a central root joint the Practical_act (opinion on the contact made with the specialization’s real problems, in curricula’s practical activities) attribute. The second level of ramification is based on the CIG students’ opinion courses teaching methods of the 1st year of study, this year being a test for the freshmen, the knowledge achieved during it is the base for the future accounting professionals. Examples of interpretation of the decision tree’s branches:
“If the CIG students agreed they had made contact with the specialization’s real problems, in curricula’s practical activities, then they would agree to continue their education with post university studies”.
“If the CIG students were neutral regarding the contact made with the specialization’s real problems, in curricula’s practical activities, appreciate as mediocre the quality of courses teaching methods in the 1st year of study, then they would be neutral to continue their education with post university studies”.
Figure 3. The decision tree generated from the first data set (CIG.arff file)
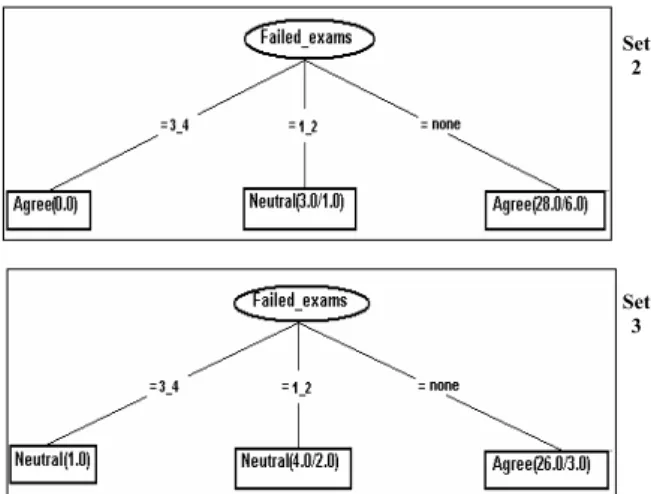
The decision trees generated from the second and third datasets of the CIG.arff file (Fig. 4) have as a central root joint the Failed_exams (scholastic situation at the end of last academic year) attribute. Examples of interpretation of the decision tree’s branches:
“If the CIG students passed all exams at the end of last academic year, then they would agree to continue their education with post university studies (master degree, Ph.D. studies)”. (valid for both datasets)
“If the CIG students didn’t pass 1 or 2 exams, then they would be neutral to continue their education with post university studies”. (valid for both datasets)
Set 2
Set 3
Figure 4. The decision trees generated from the second and third data sets (CIG.arff file) As seen in the Knowledge Flow interface, by creating partitions through cross validation I covered a way of anchoring in the results of each partition, which the Explorer Weka’s module did not present.
4. Conclusions
The current research in data mining on education issues is in a continuous evolving stage. Much improvement still needs to be done, more analysis and approaches to the study of data mining practices in higher education are needed to further develop the current research state, the practical applications, and the prediction and description tasks, which the managerial system needs.
It is important to perceive the dissimilar behaviors of the students belonging to different specializations, even though the decision trees were built on a similar model and through the same algorithm. Few IE students or none
graduated a agricultural, industrial or economic oriented high school - and they are skeptical on continuing their education. IE is a first-class specialization and also a tough one, and therefore the graduated high school – especially a theoretic (as Mathematics-Physics), and Information systems (Computers), which offer superlative background of logical and analytical knowledge – is a root joint in students’ future education.
The accounting field is essentially a practical one, playing a vital role in any company and the contact made with specialization’s real problems, in curricula’s practical activities, plays an important part in CIG students’ future choice.
In the continuous process of perfecting the educational processes and attracting the interest of new students, within the conditions of Romania’s emerging economy in the EU, there is a need in offering high quality information and knowledge to the higher education institutions’ managers. My work, from which I presented a module in this paper, has its considerable potential tasks in assisting the managers [21], the heads of the departments to a better knowledge of students’ judgments and estimations, in order to be a step forward in anticipating their choices and to take the right decisions required to meet their demands in correlation with the universities’ strategic plan [24] .
Our research guiding directions in data mining studies of students’ behavior are presently continued with concentration on the following factors: clustering techniques; decisional trees for each specialization based on several algorithms; parallel analysis with the data extracted from the master degree students to exemplify detailed behavioral models.
5. Acknowledgements
This research has been partially funded by the Faculty of Economics and Business Administration, by the CNCSIS Consortium Grant 8/2005, “Collaborative Information Systems in the Global Economy” and by the Babe-Bolyai University Priority Themes Grant 2/2005, “Collaborative Decision Support Systems in Academic Environments”.
6. References
[1] Angosta, L. Essential Guide to Data Warehousing. Prentice Hall PTR; 1st edition; 1999.
[2] Berry M, Linoff G. Data Mining Techniques: for marketing, sales, and customer relationship management -2nd ed. Wiley Publishing, Inc., Indianapolis, Indiana; 2004.
[3] Bodea C, Bodea V, Tudor CA. Data mining in higher education, The 3rd International Workshop IE&SI, Timisoara, 26-27 May 2006, p. 19-26
[4] Brefelean, V.P. Development Strategies for The Universities’ Management Using Information and Communication Technologies, InfoBUSINESS'2006 Iai, Romania, 2006.
[5] Brefelean VP, Brefelean M, Ghioiu N, Comes C-A. Continuing education in a future EU member, analysis and correlations using clustering techniques. Proceedings of The 5th WSEAS International Conference EDU '06, Tenerife, Spain, 2006. p.195-200. [6] Brefelean VP, Brefelean M, Ghioiu N,
Comes C-A. Data mining in continuing education. INTED 2007, International Technology, Education and Development Conference, Valencia, Spain, 2007.
[7] Burlak G, Munoz J, Ochoa A, Hernández J-A: Detecting Cheats in Online Student Assessments Using Data Mining. Proceedings of DMIN 2006. p. 204-210
[8] Cohen J, Cohen P, West SG, Aiken LS. Applied multiple regression/correlation analysis for the behavioral sciences. (2nd ed.) Hillsdale, NJ: Lawrence Erlbaum Associates, 2003.
[9] Cunha MM, Putnik GD, Ávila P. Towards Focused Markets of Resources for Agile / Virtual Enterprise Integration, in Advances in Networked Enterprises: Virtual Organisations, Balanced Automation, and Systems Integration, Kluwer Academic; 2000. p. 15-24.
[10] Gunter S, Bunke H. Evaluation of classical and novel ensemble methods for handwritten word recognition, Proc. IAPR Workshop on Structural and Syntactic Pattern Recognition, Lisbon, 2004.
[11] Heathcote E, Dawson S, Data Mining for Evaluation, Benchmarking and Reflective Practice in a LMS. In Proceedings E-Learn 2005 Vancouver, Canada, 2005.
[12] Introduction to Data Mining and Knowledge Discovery. Third Edition. Two Crows Corporation, Potomac, MD, USA; 1999. [13] Kalathur S, An Object-Oriented Framework
for Predicting Student Competency Level in
an Incoming Class, Proceedings of SERP'06 Las Vegas , 2006, p. 179-183
[14] Krishna A, Yilmaz C, Memon A, Porter A, Schmidt D, Gokhale A, Natarajan B. A Distributed Continuous Quality Assurance Process to Manage Variability in Performance-intensive Software, 19th ACM OOPSLA Workshop, Vancouver, 2004. [15] Loing B. ICT And Higher Education, 9th
UNESCO/NGO Collective Consultation on Higher Education, Paris; 6-8 April 2005. [16] Mena J. Investigative Data Mining for
Security and Criminal Detection, Elsevier Science, USA; 2003.
[17] Mitra S, Acharya T. Data Mining. Multimedia, Soft Computing, and Bioinformatics. John Wiley & Sons, Inc., Hoboken, New Jersey; 2003.
[18] Parr Rud, O. Data Mining Cookbook. Modeling Data for Marketing, Risk, and Customer Relationship Management. John Wiley & Sons, Inc.; 2001.
[19] Quinlan JR. Induction of decision trees. Machine Learning, volume 1. Morgan Kaufmann; 1986. p. 81-106.
[20] Quinlan JR. C4.5: Programs for Machine Learning. Morgan Kaufmann, 1993.
[21] Rusu L, Brefelean VP. Management prototype for universities. Annals of the Tiberiu Popoviciu Seminar, International Workshop in Collaborative Systems, Volume 4, 2006, Mediamira Publisher, Cluj-Napoca, Romania; 2006. p. 287-295
[22] Stone J. An Intelligent Digital Library System for Biological Data, The Faculty of the Graduate College of The University of Vermont, Master of Science Thesis, 2005 [23] Talavera L, Gaudioso E. Mining student
data to characterize similar behavior groups in unstructured collaboration spaces. Workshop on artificial intelligence in CSCL. 16th European conference on artificial intelligence, 2004. p. 17-23
[24] Universitatea Babe-Bolyai Cluj-Napoca, România (UBB). Plan Strategic de dezvoltare a Universitii Babe-Bolyai pentru perioada 2004-2007, Cluj-Napoca, Romania; 2003.
[25] Witten I H, Frank E. Data mining: practical machine learning tools and techniques, 2nd ed., Morgan Kaufmann series in data management systems, Elsevier Inc.; 2005.
![Figure 1. The graph model built after [25]](https://thumb-us.123doks.com/thumbv2/123dok_us/1961663.2790532/3.892.458.785.770.949/figure-the-graph-model-built-after.webp)