EFFECTIVE MEMORY OPTIMIZATION TECHNIQUES FOR EMBEDDED SYSTEMS AND ITS APPLICATIONS
Vanitha Padala, Dr. Amit Jain2
Department of Electronics and Communication Engineering
1,2
OPJS University, Churu (Rajasthan) – India
Abstract
The objective of this paper is to study the equipment / programming techniques to effectively use these on-chip storage structures to reduce the overall power of the memory system. The proposed techniques strive to brilliantly use the larger quantities in the memory hierarchy to provide instructions and obtain information more quickly and efficiently. In particular, three separate compiler supervisor teams were examined to help register, cache and note-taking techniques. Accompanying segments shorten them quickly. With the proliferation of mobile phones, digital cameras, PDAs and other portable computer systems, power consumption in microprocessors has become an overwhelming design problem.
1. RESEARCH BACKGROUND
These techniques focus essentially on reducing the power consumed by memories. Sometimes for simultaneous memory, dim light and storage, the power dissipation of communication is direct [1-4]. We moved to CMP architectures, with different memory models, including shared store, shared SPM and on-chip memory. The use of the memory system is a vital problem for some embedded systems that operate with strict memory problems. This is a solid inspiration for late research on reducing the amount of banks required in the middle of the implementation of a given application. Reducing the storage space requirements of an application can bring three potential benefits. First, if we design a custom memory system for a particular embedded
Figure 1 A CMP Architecture With A
Shared On-Chip Cache.
Figure 2 A CMP Architecture with a
shared on-chip SPM.
Figure 3 A CMP Architecture With
On-Chip Banked Memory.
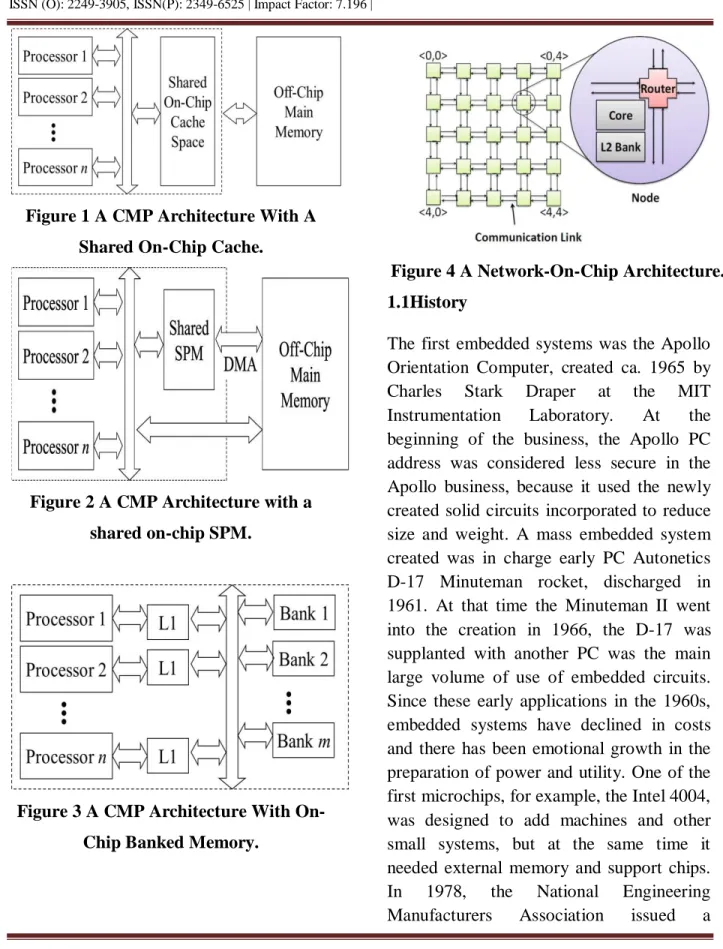
Figure 4 A Network-On-Chip Architecture.
1.1History
The first embedded systems was the Apollo Orientation Computer, created ca. 1965 by
Charles Stark Draper at the MIT
Instrumentation Laboratory. At the
beginning of the business, the Apollo PC address was considered less secure in the Apollo business, because it used the newly created solid circuits incorporated to reduce size and weight. A mass embedded system created was in charge early PC Autonetics D-17 Minuteman rocket, discharged in 1961. At that time the Minuteman II went into the creation in 1966, the D-17 was supplanted with another PC was the main large volume of use of embedded circuits. Since these early applications in the 1960s, embedded systems have declined in costs and there has been emotional growth in the preparation of power and utility. One of the first microchips, for example, the Intel 4004, was designed to add machines and other small systems, but at the same time it needed external memory and support chips.
In 1978, the National Engineering
"standard" for programmable
microcontrollers, including PC-based
controllers, for example, single-board
computers, numerical controls and event-based controls.
2. EFFECTIVE MEMORY
OPTIMIZATION TECHNIQUES
These techniques are predominantly focused on reducing the power consumed by memories. Now and then for simultaneous memory, blaze and cache, communication power dissipation is focused on. Static power is additionally vital for memory and ought to be limited. The voltage and recurrence is a complex capacity and relies
upon the system configuration and
properties of the system and applications of system. The outcomes affirm that the memory contributes essentially to the power consumption of embedded systems. [61] Uses ordinary variable supply voltage technique to lessen processor power without affect on performance. Two Finite State Machines were presented Down FSM dodges performance debasement and up FSM maintains a strategic distance from lessening in power investment funds. VSV, targets superior processes. VSV is effective in sparing power. VSV spares normal power by 33% without FSM and 21% with FSM.
One of the main factors that can slow down the use of embedded chip multiprocessor is the absence of efficient programming support. The essential problem is that consistent desktop programming is not designed to take advantage of new CMP
architectures. In fact, to perceive a real acceleration of the new CMP architectures, it is necessary to redesign the desktop programming. In particular, the robotic code logger is very necessary, since it is not practical to expect that a normal software engineer parallel a large complex embedded
application on numerous processors,
considering some factors meanwhile, for example, the code thickness, the area
information, performance, power and
resilience of the code. As the chip multiprocessors multiply, the programming compatibility for these devices will probably receive a great deal of consideration sooner rather than later.
Cache Memory: the behavior of
memory plays an important role both in terms of performance and power consumption. The cache is established between the processor and the system's main memory (RAM). The cache is faster than RAM, but does not have the fundamental memory limit. A cache is designed to move a small amount of information close to the processor.
Scratch Pad Memory: Scratch-Pad
maximum performance from application programs.
2.1 Placement Of Dynamic Instructions
Managed By The Compiler In
Scratch-Pad Memories
The subsystem that carries the guidelines
can add a large aggregated power division
spread by the processor. The team monitors
caches, called L0 cache [5] or cache loop [6,
7], experiences the negative effects of high
error rates, the complexity of the controller
and the inability to migrate loops with flow
control or calls of subroutine. Programming
monitors the notebook memory [8, 9]
reduces the computer management overhead
by relying on the compiler to migrate
sections of the code. Maintaining a strategic
distance from the complex verification of
labels and the logic of correlation, and
thanks to a better situation, notebook
memories have proved more power efficient
than the usual caches. Programming static
patterns inserts areas of code that are
executed regularly and that precede the
execution of the project. The substance of
the scratch pad is never adjusted after the
initial position. Although this technique is
effective for specific types of applications, it
is separate when a program has multiple
imperial loops that do not fit the scratchpad
altogether.
2.2 Management ofthe Partitioned Data
Cache Managed By the Compiler
Information caches have come to be
effective, as they help to dynamically trap
both spatial and spatial regions without
programming mediation. In any case, its use
in embedded areas has been limited due to
its inefficient tag control and control logic.
From one point of view, although the caches
of cooperative groups achieve high success
rates, they are detrimental to the high power
overload. On the other hand,
coordinate-mapped caches spend far less power per
contact, causing more errors.
2.3VAbM Technique
This area shows a technique for the
particular memory association of the
application in detail. VAbM obtains an AP
of the application program as information
and creates the architecture of the custom
memory that has N skeins together with the
variable subset activity Q (j) in each
memory, saves money with the size of the
bits b (j) xm (j) as a performance, which has
rationalized the consumption of power. All
factors will be served by a single district
3.ARCHITECTURE OF THE WIMS
MICROCONTROLLER
The WIMS microcontroller has been
designed to control a variety of low-power
embedded sensor systems [10]. It was
designed at the University of Michigan and
is a focal element of a small-scale,
low-power upper system used for remote
environmental monitoring and cochlear
inserts [11]. The microcontroller, produced
in 0.15 μm TSMC CMOS, appears in figure
1 and consists of three main sub-intervals:
the digital centre, the simple front-end
(AFE) and the CMOS-MEMS clock
reference. Minimizing power was a
fundamental imperative for each sub-box. A
16-bit stack / store architecture with double
operand was chosen to access the address
list to meet the power and performance
requirements of the microcontroller.
Figure 1 The WIMS microcontroller in
TSMC 0.18 μ CMOS and the WIMS
information mode.
4. CONCLUSION
In this research, we talked about the design
and implementation of a graphical
partitioning algorithm to evaluate the
benefits of designing window registration
documents. This project expands the actual
amount of accessible registers while
maintaining an established coding of
instructions. The compiler divides virtual
registers into a methodology in several
registry windows along these lines, which
reduces the general code of spill and
minimizes the overload due to window
movements and window swaps. The project
has been evaluated in a wide variety of
processors and windows configurations. The
expansion of the number of windows 1 to 2
resulted in a normal change in performance
of 10% in the case of 4 registers and 11% in
the case of 8 registers in the WIMS
processor. The comparison probe of a
powerful VLIW machine achieved a normal
performance change of 21% and 25% for
register configurations 4 and 8, separately. A
25% normal power reduction was observed
for the 2 window register 8 on the 1 window
case in the WIMS processor.Abnormal state
synthesis and ASIP design innovation
memory design which assume predominant
part in performance change so an effective
reference imitation based memory
architecture have been actualized to
diminishes the cost and deferral. By the
assistance of reference imitation cell
stockpiling region and postpone actualized
for different benchmarks, for example,
neural network or pictures optimization.
REFERENCES
[1].Yehua Du, Mingcai, Jinxiang
Dong, (2005) “Dynamic Voltage
Scaling Of Flash Memory Storage
Systems For Low Power Real Time
Embedded System”, Proceedings of
Second International conference on
Embedded systems and software
IEEE.
[2].Luca Benini, Govani D Michelli,
(1999) “System Level Power
Optimization Techniques And
Tools”, Stanford University, ACM.
[3].AlirezaPouladi, SaeidNooshabadi,
(2005)“Opcode Encoding For Low
Power Embedded Systems”,
Proceedings of 2005 IEEE
symposium on Circuits and
Systems(ISCAS)
[4].Han-Lin Li, Chia-Lin Yang,
Member, IEEE, and Hung-Wei
Tseng, (2008) “Power-Aware Flash
Memory Management in Virtual
Memory System”, IEEE
Transactions On Very Large Scale
Integration (Vlsi) Systems, 16(8).
[5].Ferreau H.J.,
S.Almér,R.Verschueren,M.Diehl,D.F
rick,A.Domahidi,J.L.Jerez, G.
Stathopoulos, C.Jones (2017)
Embedded Optimization Methods for
Industrial Automatic Control,
IFAC-PapersOnLine, Volume 50, Issue 1,
pp13194-13209
[6].Lee L. et al.(1999) Instruction Fetch
Power Reduction Using Loop
Caches for embedded applications
with Small Tight Loops. In Proc. of
the 1999 International Symposium
on on Low Power Electronics and
Design, pp267–269.
[7].Lee L. et al. Low-Cost Embedded
Program Loop Caching - Revisited.
Technical Report CSE-TR-411-99,
Univ. of Michigan, (1999).
[8].PreetiRanjan Panda, NikilDutt, and
Embedded Systems-On-Chip.
Kluwer Academic Publishers,
Norwell, MA, (1999).
[9].SumeshUdayakumaran and Rajeev
Barua. (2003)Compiler-decided
dynamic memory allocation for
scratch-pad based embedded
systems. In Proc. of the 2003
Inter-national Conference on Compilers,
Architecture, and Synthesis for
Embedded Sys-tems, pp276–286.
[10]. Eric Marsman, Robert
Senger, Michael McCorquodale,
Mathew Guthaus, Rajiv Ravindran,
Ganesh Dasika, Scott Mahlke, and
Richard Brown. (2005)A 16-bit,
Low-Power Microcontroller with
Monolithic MEMS-LC Clocking. In
Proc. of the Inter-national
Conference on Circuits and
Systems, pp 624–627.
[11]. Center for Wireless
Integrated Microsystems (WIMS).
An NSF Engineering Re-search
Center, 2000.