The representation of
alveolar nasals and laterals in
Southern Mandarin
by
Anton J. Wierenga
B.A. (Chinese Language & Literature and Political Science), University of Alberta, 2015
Thesis Submitted in Partial Fulfilment of the Requirements for the Degree of
Master of Arts
in the
Leiden University Centre for Linguistics Faculty of Humanities
Acknowledgements
I would like to express my gratitude to my supervisor, Professor Yiya Chen. Her
course Sounds of Chinese allowed me to begin to investigate the world of Chinese
phonetics. Professor Chen's expertise in speech perception, experimental design and
phonetics has been invaluable in improving the quality of the study.
I would also like to thank the other staff at Leiden University whom I have had the
pleasure of studying with and helping me along my academic journey. To Patsy Casse,
for helping me to navigate all of the administrative hoops to complete my degree and
graduate. I am indebted to Jos Pacilly for his help in using the multitude of specialist
equipment in the phonetics laboratory and his suggestions regarding the design of my
experiment in E-Prime. I am also thankful to Daan van de Velde for troubleshooting
and suggesting solutions for my experimental design issues in E-Prime. I am also
thankful to my classmate, Jiashuo Zhang, for her willingness to help me make my
experiment a success by spending long hours in the recording booth with me. To my
other classmates and colleagues, Leiming Wu, Wenyu Huang, Yanhong Zhu who
helped to get the experiment ready for deployment, I am extremely grateful for your
time and effort sharing your thoughts and ideas with me. Without your feedback, the
experiments could not have proceeded as well as they did. I am also very grateful to
Jiaying Yu for taking the time to check and correct my English-Mandarin translations
of all of the instruction sets and other documentation required for an experiment to
take place.
A very special acknowledgement to my teacher Professor Kuo-Chan Sun, for his
is infectious and he never fails to bring a smile to my face. His determination to push
me beyond what I could ever have dreamed of accomplishing is one of the biggest
reasons why I have continued my research into the field of linguistics. Professor Sun
is one of the most intelligent, hardworking and caring people that I know, and I am
very fortunate that our paths crossed.
Last, but not least, I wish to acknowledge the support given to me by my parents.
Without their unconditional love and understanding, I would not be where I am today.
Table of Contents
Acknowledgements...ii
List of Tables...vi
List of Figures...vii
Chapter 1 : Introduction...1
1.1 Purpose of the study...1
1.2 Southern Mandarin...2
1.2.1 Húběi dialects...4
1.3 Chinese Syllables...5
1.4 Alveolar Consonants...6
Chapter 2 : Literature Review...9
2.1 Theoretical Models...9
2.1.1 Perceptual Assimilation Model...9
2.1.2 Speech Learning Model...12
2.2 Form Priming...14
2.3 L2 Perception...15
2.3.1 Asymmetrical L2 lexical representations...18
2.4 Methodological Issues...20
2.5 Summary...22
Chapter 3 : Lexical Decision Experiment...23
3.1 Rationale...23 3.2 Methodology...25 3.2.1 Participants...25 3.2.2 Stimuli...26 3.2.3 Recording...29 3.2.4 Procedure...30 3.3 Results...31 3.4 Discussion...33
3.4.2 Interest Pairings...36
3.5 Conclusion...36
Chapter 4 : Elicitation Experiment...38
4.1 Rationale...38
4.2 Methodology...38
4.2.1 Participants...38
4.2.2 Stimuli...39
4.2.3 Procedure...39
4.3 Results...41
4.4 Discussion...46
4.5 Conclusion...46
Chapter 5 : General Discussion...47
5.1 Overview of the study...47
5.2 Summary of experimental results...47
5.3 Limitations of study...47
5.4 Theoretical Implications...50
Chapter 6 : Conclusion...52
6.1 Directions for future research...52
6.2 Conclusion...54
References...56
Appendix I: Questionnaire...60
List of Tables
List of Figures
Figure 1: Southern Mandarin Map...3
Figure 3.1: Lexical Decision Procedure...30
Figure 3.2: Control Group Response Times...32
Figure 3.3: Phoneme Mapping Diagram...34
Figure 4.1: Elicitation Experiment Procedure...40
Figure 4.2: Alveolar Plosive Un-aspirated and Aspirated Waveforms...42
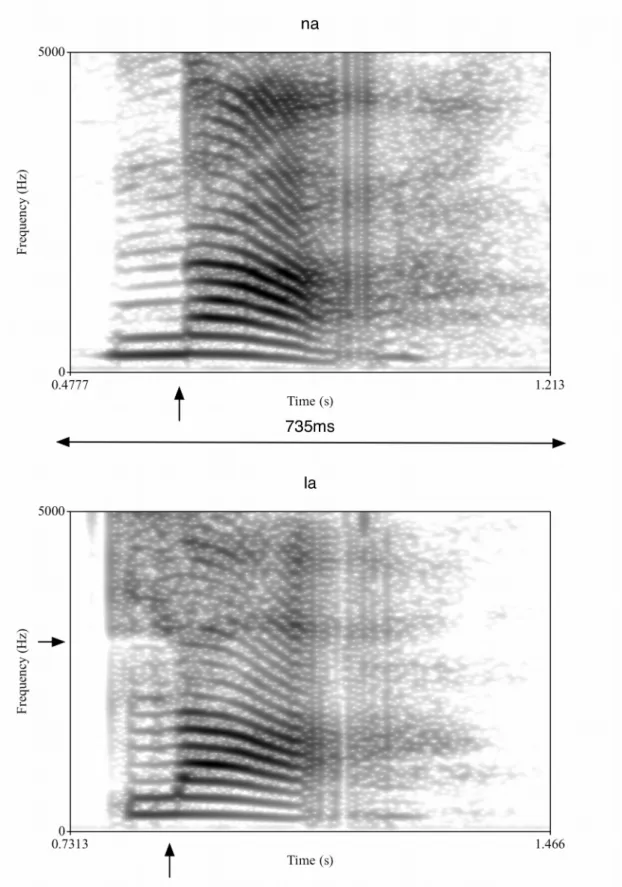
Figure 4.3: Spectrograms for alveolar nasals and laterals...43
Chapter 1 : Introduction
Speech perception and production are important areas of research in the field of
second language acquisition. Some people may find it difficult to distinguish between
certain sounds in a second language (L2). An example of this type of phenomenon can
be found in the region of China spanning across the provinces of Húběi, Húnán,
Jiāngxī, and Sìchuān. Speakers hailing from this region often are unable to
differentiate between an alveolar nasal [n] and an alveolar lateral [l]. For example,
when asked to attempt to say a well-known Mandarin tongue twister Niú láng liàn Liú
niáng, only one of the two initial consonants is produced. This means that the phrase
may become either Niú náng niàn Niú niáng* or Liú láng liàn Liú liáng*.
1.1 Purpose of the study
This thesis will examine the cognitive representation of alveolar nasals and laterals in
Southern Mandarin speakers by conducting a psycholinguistic lexical priming
experiment and an elicitation experiment. These experiments will provide essential
data to determine exactly how these two critical consonants are mapped in the brain. It
seems that a consonant from the critical pair is chosen at random and then applied for
the duration of a production without variation. However, the literature seems to refute
this rudimentary observation with evidence of asymmetry, i.e. a preference should be
shown for one of the consonants over the other. This research will explore this
1.2 Southern Mandarin
The main language of study in this thesis is a specific dialect group of Mandarin. The
term “Mandarin” refers to the language also known as pǔtōnghuà, guānhuà, guóyǔ, or
huáyǔ. This is defined in Chen (1999) as “the standard form of Modern Chinese with
the Beijing phonological system as its norm of pronunciation, and Northern dialects as
its base dialects, and looking to exemplary modern works in báihuà1 for its
grammatical norms.” The following figure illustrates the consonant distribution found
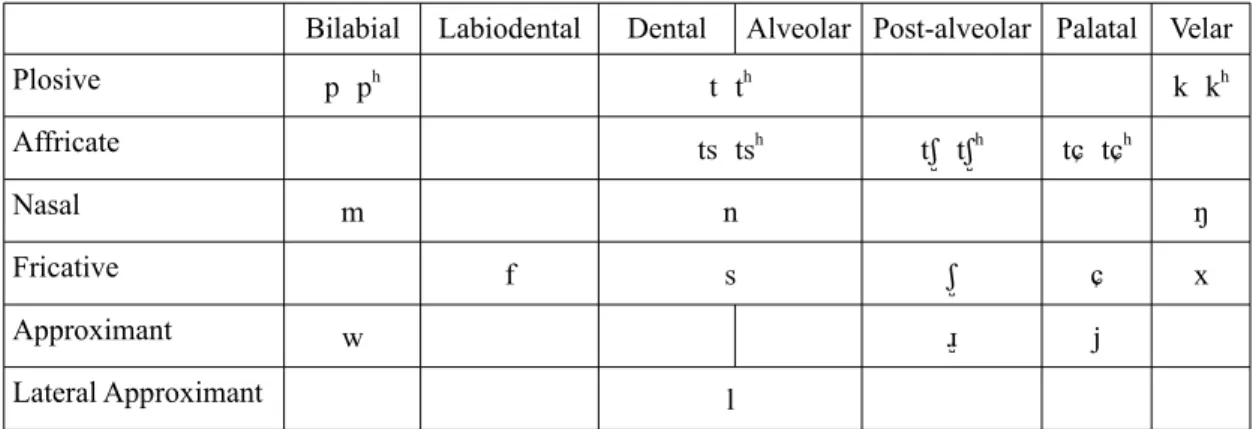
in standard Mandarin (Lee & Zee, 2016).
Bilabial Labiodental Dental Alveolar Post-alveolar Palatal Velar Plosive p ph t th k kh
Affricate ts tsh tʃʃ tʃʃh tɕ tɕh
Nasal m n ŋ
Fricative f s ʃʃ ɕ x
Approximant w ɹʃ j
Lateral Approximant l
Table 1: Mandarin Consonants
According to Norman (1988), Mandarin can be divided up into 4 subgroups:
Northern, Northwestern, Southwestern and Eastern. The boundaries that he draws up
are largely based on the political geography of China, which reflect the borders of
provinces. Southwestern Mandarin is a dialect spoken in Húběi, Sìchuān, Yúnnán,
Guìzhōu, northwestern Guǎngxī, and the northwestern corner of Húnán. An
approximation of the areas where the dialect is found has been drawn below.
However, it is important to note that these are only approximations; borders between
dialects are notoriously difficult to classify, let alone draw on maps. Norman (1988)
remarks “an example of a very weak dialectal boundary is that dividing the Xiāng
dialects from Mandarin.” This is important because the Xiāng dialects are spoken in
the central and southwestern parts of Húnán province; adjacent to the dialect of
interest in this study. Because of this ambiguity, I will use the term “Southern
Mandarin” to denote Mandarin dialects spoken in a non-northern area, i.e. in contrast
with the Northern and Northwestern dialects of Norman's (1988) classification.
Norman (1988) continues to explain the differences among these dialect groups and
subgroups by giving some “general observations,” of which one is quite worthy of
mentioning. His third observation notes: “many Mandarin dialect groups (and dialects
of other groups as well) confuse n and l in various ways; in some they are in free
variation, as in Lánzhōu; others have only l (Nánjīng) or only n (Chóngqìng).” As
Lánzhōu is located outside of our area of interest, its case will not be dealt with here.
A future study may, however, be interesting to carry out in this city to see whether or
not the experimental results are replicable.
1.2.1 Húběi dialects
Chao Yuen-Ren's (1948) survey into the Hubei dialects provides some insight to this
issue. His survey elicited pronunciation data by asking his subjects to read passages of
texts and then transcribing them.
『還有時候同一個字有時讀這個音值有時讀那個音值而讀者不覺 得有什麼分別,例如湖北好些地方同一個人讀‘奴’字有時候讀
lu,有時候讀nu而自己不覺得有兩種讀法,這叫做“變值音位”, 標作l~n。在拼字時就選一個較多見的值的符號,例如n,來代表
這音位。』(Chao, 1948 pp. 7)
“Sometimes the same character will be read with one phonetic value and sometimes it will be read with a different phonetic value, but the reader doesn't think that there is any difference. For example, in many
areas of Hubei province, one person reading the character nu will sometimes say 'lu,' and sometimes say 'nu.' The reader will not think
that there are two different readings of the character. This is called 'phonemic variation,' as in l~n. When transcribing the characters, the more frequent form is chosen, such as 'n,' to represent the phoneme.”2
Chao himself noted that this variation between [n] and [l] existed, and even felt it
worthy enough to write about because of the lack of distinctiveness that the speaker
claimed to recognise. This is somewhat similar to what I personally experienced when
traveling through the region myself, with interlocutors being less aware of the
contrasts between [n] and [l] than of other phonemic contrasts in Mandarin.
The data from the study shows evidence of the indistinctness of [n] and [l] in the
transcriptions of the passages. It appears that Chao found subjects representing 64
different dialects present in Hubei. Each subject read a standardised passage, and the
pronunciation of each character. This phenomenon leads directly to the experiment
conducted in Chapter 4 to examine directly the acoustic properties of the sounds
spoken by Southern Mandarin speakers in comparison to those of speakers of standard
Mandarin.
1.3 Chinese Syllables
Mandarin Chinese has a relatively simple formula for creating syllables given in (1).
(1) (C)(M)V(V/N)
In this representation, each letter stands for a different component of a syllable in
Mandarin. C stands for a consonant, which can be chosen from a repertoire of 21
consonants, such as [t]. These consonants are largely voiceless (except [m], [n], [l],
[ʐ]), despite their forms in pinyin which allude to a system influenced by written
English. For example, the letter t in pinyin represents a [th], just like in English when
the t is written at the beginning of the word. The letter d on the other hand, is a [t] in
IPA. M stands for a medial, which is realised as a glide, or semi-vowel. There are 3
medials or on-glides in Mandarin: [j], [w] and [ɥ]. V stands for a vowel, which can be
any of 8 vowels, such as [ə]. N stands for a terminal nasal, of which there are two in
Mandarin: [n], and [ŋ].3 All syllables follow this structure, with optional elements
being enclosed by brackets. The minimum requirement for a syllable in Mandarin
Chinese is therefore a vowel, and there are plenty of examples of this, such as è [ə]
“hungry.” The last component of a syllable is the tone, of which there are 4 in
Mandarin. It should be noted that research has been done that separates the tone from
the “segment” of a syllable (Goldsmith, 1976). In this case, the segment is a tier of a
syllable that holds information pertaining to the place and manner of articulation,
while tone occupies a separate tier; this is called autosegmental phonology. These
tones are transcribed using a number between one and four. Tone 1 is a long,
high-level tone. Tone 2 is a mid-high rising tone. Tone 3 is a low rising tone. Tone 4 is a
short high falling tone. A common way of notating tones in Mandarin is to use a scale
of 1-5, where 1 is low and 5 is high, developed by Chao (1930).
Current linguistic researchers (see Sun, 2006) further divide syllables up into two
distinct parts: an initial, and a final. The initial component is made up of (C) and can
be either empty or filled, as denoted by the brackets in (1). This position plays a
central role to the effect that is studied in this experiment. The remaining elements of
the syllable are classified as the final.
1.4 Alveolar Consonants
As noted earlier, Mandarin Chinese has an inventory of 21 consonants. Of these, there
are four that are classified as alveolar. An alveolar sound is made using the tongue tip
or blade at the alveolar ridge, which is located on the gum tissue just behind the upper
front teeth. Both of the consonants that are critical to this thesis are articulated in this
place, albeit in different ways. An [n] sound is an alveolar nasal, meaning that the
velum is lowered and air is channeled through the nasal cavity. An [l] on the other
hand, is an alveolar lateral consonant. A lateral is a sound that is made by touching the
tongue blade to the alveolar ridge but allowing for the passage of air to the left and
right edge of the tongue.
These two consonants also share many phonological features. As they are both
shared. The only differences are in the following features: continuant, approximant,
lateral, and nasal.
The continuant feature denotes a characteristic where the oral tract is not completely
closed. For example, fricatives such as [s] and [z], are ascribed with this feature as
there is a constant flow of air through the mouth when they are produced. A stop such
as [t] however, would not be classified this way, as a stop by nature stops the flow of
air through the oral cavity.
The approximant feature indicates the characteristic of two articulators, in the case of
[l] the tongue and alveolar ridge, coming close to touching each other, but fail to
actually connect. This may seem counter-intuitive, but if we had a complete
connection between the tongue and alveolar ridge during the articulation of [l], then
we would not have any air able to escape the mouth.
The lateral feature signifies the free flow of air along both sides of the tongue, but
cannot pass unimpeded through the middle of the mouth. In English, the [l] phoneme
is the only example of a consonant with this feature.
The nasal feature denotes the lowering of the velum so that air passes through the
nasal cavity. These sounds often influence preceding vowels giving them nasal
qualities in languages like French.
Given twenty-five different phonological features which each take one of three
attributes (+, -, or 0)4, the [n] and [l] phonemes are remarkably similar. This similarity
(1988) have found that the two sounds may be used interchangeably without any clear
Chapter 2 : Literature Review
This chapter consists of five parts: Section 2.1 examines the theoretical models about
L2 speech perception. The two theories that are looked at in depth are Best's
Perceptual Assimilation Model (PAM) (Section 2.1.1) and Flege's Speech Learning
Model (SLM) (Section 2.1.2). Section 2.2 reviews some relevant literature and
explains the principals of form priming. Section 2.3 is a review of some previous
studies in L2 perception This section forms a baseline point for the present study
insofar as the development and carrying out of the study are concerned. Section 2.4
will examine some methodological issues that have been found in previous studies
that have affected the present study.
2.1 Theoretical Models
Before analysing two of the theoretical models that I will use to analyse the results of
the research, it bears mentioning that there are other language acquisition theories,
such as Patricia Kuhl's Native Language Magnet model (NLM), but that will not be
discussed below.
2.1.1 Perceptual Assimilation Model
The Perceptual Assimilation Model (PAM) is a theory developed by Catherine Best in
order to account for a new category of second language perception. Previously posited
theories such as NLM and SLM failed to explain the ability of English listeners to
discriminate Zulu clicks despite these listeners having never heard the language
Polka (1991) researched the ability of English speakers to distinguish the four Hindi
dental-retroflex stop voicing contrasts, and found that there was no pattern in the
results (cited in Best, McRoberts, & Goodell, 2001). This finding is interesting
because three of the voicing contrasts do not occur in English, while only one voicing
is shared with English. It would seem logical that the English speakers would be able
to contrast the one voicing that occurs in their native phonological inventory with any
of the others. However, the participants exhibited no such pattern, rather some
participants could discriminate between the four contrasts at an “excellent” level,
while others could not.
A second experiment that was instrumental in developing PAM was a study by Best
that showed that American English speakers consistently showed good discrimination
of Zulu clicks without any prior training. These sounds, that involve the inhalation of
air into the mouth and then releasing the pressure at a place of articulation (like the
lips for a bilabial click), do not form a part of speech sounds in English insofar as they
do not form a component of English words like they do in a language like Zulu. Yet
these different clicks can be readily distinguished by English speakers without any
previous exposure.
PAM works by dividing up sounds into three different classes that are then
“assimilated to the native system of phonemes.” (Best, 1995). The first class is called
Categorised, the second class is called Uncategorised, and the third is called
Non-assimilable non-speech sound. A Categorised sound is a non-native sound that is
deemed to be a close enough fit to a native phoneme for it to be categorised as such.
An Uncategorised sound is deemed to be somewhere in between two or more native
dissimilar from a native phoneme that it is no longer classified as a speech sound. In
the above Zulu example, the clicks would be explained by PAM as falling into the
third class whereby the sounds are not processed as speech sounds, but rather as
general non-speech sounds.
To discriminate non-native sounds, a listener would need to also have the ability to
compare cross-categorical non-native sounds. The PAM accounts for several pairings
of the different classes so as to explain perceptual differences between non-native
sound contrasts. The first, called Two Category assimilation (TC), is when two
non-native phonemes assimilate to two different non-native phonemes that are both similar to
the non-native phonemes. If the two non-native phonemes are assimilated equally
well to a single native phoneme, this is called Single Category assimilation (SC).
When the two non-native phonemes assimilate asymmetrically to a single native
phoneme, i.e. one non-native phoneme is a “better/worse” fit than the other, then this
is called Category Goodness (CG). If a non-native phoneme is Categorised while the
contrasting item is Uncategorised, then this is called Uncategorised-Categorised (UC).
When both items are Uncategorised, this is called Uncategorised speech (UU).
Finally, when both items are too disparate from a native phoneme, they are called
Non-Assimilable (NA).
These various combinations of non-native sounds into the three different classes
permits the creation of a theoretical hierarchy of perceptual discrimination. To make
an example out of one of the two studies mentioned above, I will apply the PAM to
attempt to explain the results. The study of Hindi stop voicing contrasts is probably
best explained by presupposing either a CG or SC combination. In this situation, both
the same phoneme. This classification necessarily inhibits the ability to discriminate
between the two non-native phonemes. If the stop voicing contrasts are all mapped to
a single phoneme with equal goodness of fit as in SC, then the results will vary at
random. If there are slight differences in the goodness of fit, like in CG, then some
speakers may be able to discriminate better between certain combinations if there is a
large enough difference in the goodness of fit, however, it is not going to be as good
as if it were a TC. This gives a perceptual hierarchy whereby TC>CG>SC (Best,
1995).
The PAM remains a popular theory for explaining phenomena in language acquisition,
and as a result, it will be discussed with relation to the results of the experiments in
this study.
2.1.2 Speech Learning Model
The Speech Learning Model (SLM) was postulated to address issues in second
language acquisition just like the aforementioned PAM. Using data from his previous
research, Flege (1995) developed the theory to make predictions about L2 acquisition
and address the role of age in acquisition. To this end, I will first quickly review the
critical period hypothesis before explaining SLM.
The critical period hypothesis (Lenneberg, 1967) posits that the plasticity of the brain
changes at a certain point in time such that language becomes more difficult to
acquire, and near impossible to acquire “fluently.” This hypothesis is supported by
studies like Curtiss (1977) who researched a child “Genie,” who had been completely
isolated for the first thirteen years of her life, and who displayed serious deficiencies
critical period hypothesis supposes that after a certain period of time has passed (the
critical period), certain neurological functions diminish such that acquisition of a
language after the period has expired is more cumbersome and will never be as adept
as the L1.
Flege's SLM is similar in some ways to Best's PAM, but is also different in several
important ways. Flege (1995) develops his theory in the form of four “postulates,” or
assumptions, and then lists eight hypotheses. The idea is that the ability to learn an L2
in the same way that an L1 is learned in childhood is preserved throughout life.
“Phonetic categories” are created in long-term memory to classify speech sounds from
an L1, and are changed throughout life when an L2 is acquired to reflect the new
phonemes of the L2. However, all of these phonetic categories exist in a common
“space,” which requires effort from the bilinguals in order to maintain the contrasting
categories (Flege, 1995).
These postulates naturally give way to the hypotheses. Flege (1995) suggests that L1
and L2 phonemes are related to each other at the allophonic level rather than the
“more abstract” phonemic level. A new phonetic category can be created if the
difference between an L1 phoneme and an L2 phoneme is phonetically discernible.
The ability of people to discern these phonetic differences decreases as the subject's
age increases (Flege, 1995). This means that an older subject would be less able to
hear the phonetic differences between two phonemes. Category formation can be
inhibited when a single phonemic category is used to process two or more L2 sounds,
and the way in which the sounds are neurally mapped in the brain in an L2 speaker
may differ from the mapping in an L1 speaker (Flege, 1995). Finally, the production
2.2 Form Priming
One of the pioneering studies in form priming examined orthographic and
phonological similarity in contrast with variations of colour on prime and target words
(Tanenhaus, Flanigan, & Seidenberg, 1980). The study forms the basis of form
priming used in later studies (Zwitserlood, 1996). There are two different types of
form priming, the first one being direct and the other mediated. This study employs
the direct form priming paradigm, where “the prime and target are related in form but
not in any other aspects” (Zwitserlood, 1996). This contrasts with mediated priming in
that mediated priming uses primes that are “not form-related to the target,” but instead
to a keyword that is not presented (Zwitserlood, 1996). A prime is simply a stimulus
item that is related to another stimulus item called a target. For example, in this
experiment the word dǎn is used once as a prime (i.e. it occurs first), for the
associated target tǎn (which occurs later). In order to test both directions, the order of
items may change across participants or groups or experiment sessions.
Another feature of the form priming paradigm is the ability to use nonce words, which
are words that do not have a meaning. A well-known example of nonce words is
Lewis Carroll's (1872) poem Jabberwocky which uses words such as “vorpal” and
“brillig.” These kinds of nonce words can be created in other languages as well,
including Mandarin Chinese. To create these nonce words, strings of pronounceable
pinyin were created and then checked against a corpus to verify that there are no
characters with a given pinyin. For example, the nonce word rǐ, for which there are no
associated characters, and it would be considered to be nonsense if uttered by a native
Lee's (2007) study into lexical tone processing is a good example of form priming in
practice. His experiment was designed to explore the relationship between tone and
segments by using different combinations of stimuli. For example, one of the
experiments had four different prime-target relationships. One of them shared
segmental structure, but differed in tone; a second shared tone but differed in
segmental structure, a third shared both tone and segment (identical primes and
targets), and the final pair were unrelated in terms of tone and segmental structure
(Lee, 2007). The study also incorporated nonce words as fillers.
2.3 L2 Perception
There have been numerous studies conducted in second language perception and
slightly fewer about second language production over the past decade. This section
will only review a concise selection of works that are relevant to the present study.
The way in which L2 words are processed in the brain is influenced by the L1
phonological system. In order to evaluate the degree to which this occurs, Ju & Luce
(2004) performed a study using eye-tracking technology on English-Spanish
bilinguals. The experiment focused on the difference between these two languages in
voice onset time (VOT) and presented distractors that were similar to the
acoustic-phonetic input but from the other language. For example, where the English word
“pliers” was used as a distractor, the actual Spanish target playa “beach” was
phonologically similar (Ju & Luce, 2004). The recordings all had proper Spanish VOT
half the time, and English VOT for the other half. Besides the changing VOT, nothing
else in the utterances was changed. In this eye-tracking experiment, four pictures were
had to click on the corresponding picture. Only one of the images matched the spoken
word, one of the images was an “interlingual distractor” (such as pliers for the word
playa), and two images were control distractors (Ju & Luce, 2004). The results of the
experiment show that when an English VOT is used, more of the Spanish-English
bilinguals showed fixations on the phonologically similar English word. This
demonstrates the precise matches necessary for the activation of both languages upon
hearing an utterance (Ju & Luce, 2004). For example, if the Spanish word is spoken
with the native VOT, there is no difference between the two control distractors and the
interlingual distractor in terms of fixation time. This means that the English distractor
word is not activated in the mental lexicon when the VOT does not match. However,
when the VOT does not match the word (e.g. playa with English VOT), then multiple
activations occur as posited in the neighbourhood activation model (Luce & Pisoni,
1998).
Hayes-Harb and Masuda (2008) looked at the development of lexical representation
of the Japanese /kk/ (geminte) and /k/ (singleton) consonants in native English
speakers learning Japanese. To this end, three different groups were compared: a
group of native Japanese speakers, a group of students who had taken two semesters
of Japanese in university, and a group of students with no experience with Japanese.
The no experience group received some training in the form of a word list before
completing the tests. The results show that the Japanese native speakers performed at
a very high level as expected. The experienced learners performed better than the
inexperienced learners, forming a point in the middle in terms of accuracy on a lexical
decision task. Differences were more disparate when the geminate consonants were
much higher accuracy than the inexperienced learners. The groups were then asked to
go through another experiment eliciting spoken tokens from each subject. These
tokens were then evaluated by native speakers on a “goodness” scale. Again, the
comparisons show the native speakers as having the highest “goodness” rating,
followed by the experienced learners with the inexperienced learners scoring very
low. The results of the test indicate that experienced learners have an improved ability
to encode and produce geminate consonants accurately, though it does not approach
native levels (Hayes-Harb & Masuda, 2008). The results of this study suggest that
given a long period of acclimatisation to another language (L2), the ability of the L2
speaker to produce a “good” form of a non-native contrast, such as a
geminate-singleton contrast for English speakers, increases. This suggests that there may be a
higher likelihood of the Southern Mandarin dialect speakers being able to produce a
“good” form of an interest consonant, such as an [n] simply due to the number of
years spent being exposed to the L2 (Mandarin).
Finally, Zhang, Samuel and Liu (2012) did an experiment examining Mandarin
contrasts in native Cantonese speakers. This study forms the basis of the present
study. The reason for this, is that this study examines Mandarin and another Chinese
dialect, and is therefore more directly applicable to this research than a study that
looks at Spanish and English for example. Zhang et al. (2012) conducted three
experiments to determine the exact phones that were to be tested. The first experiment
identified the most difficult consonant and tonal contrasts for native Cantonese
speakers using an inventory of nine Mandarin consonants and six Mandarin tone
contrasts (Zhang et al., 2012). The experiment paired each consonant with a single
consonant. The tone contrasts used the segment pa with each of the different tone
contrasts. The results of this experiment led the researchers to choose the /ts'/-/tʂ'/
contrast alongside a T2-T3 tone contrast, as the Cantonese speakers had one of the
lowest accuracy rates relative to the other chosen contrasts. The second experiment
used the Garner speeded classification paradigm. In this experiment, participants were
told to listen only to the vowel and press on the key corresponding to the vowel, while
ignoring attempting to ignore the initial consonant and/or tone. The third experiment
changed the focus from perceptual processing to lexical representation using a
“medium-term auditory repetition priming paradigm” (Zhang et al., 2012). The results
of the priming experiment show that Mandarin speakers only exhibit priming when a
particular item is repeated. In other words, native speakers were always able to
distinguish between the different initial and tones. The Cantonese speakers
contrastively showed a priming effect in one direction only (for more asymmetric
patterns, see section 2.3.1). When the /ts'/ initial preceded the /tʂ'/, a priming effect
was found, but in the opposite direction, there was no evidence of priming. This
result, as it seems to be more generalisable (as in section 2.3.1), may provide some
background for a hypothesis in the present study whereby one of the phones is
represented in the phonemic inventory, while the other gets mapped to it only when
presented (as in the PAM model's single category assimilation set (SC), see section
2.1.1), and would show some kind of asymmetric priming effect similar to that found
in Zhang et al. (2012).
2.3.1 Asymmetrical L2 lexical representations
Moving to a more narrow field, Weber & Cutler (2004) performed an eye-tracking
than using VOT as the differentiator, Weber & Cutler used vowel differences. The
difference between the vowel in “pencil” [ɛ] and “panda” [æ] is often confused by
Dutch listeners, as the native phoneme inventory contains only one of the above
vowels [ɛ] but not [æ] (Weber & Cutler, 2004). A similar setup to Ju & Luce (2004)
was used, in that there were four different images presented, with one correct answer,
one vowel distractor, and two control distractors. For example, when the word
“pencil” was given, a picture of a pencil was shown as one of the images, while a
panda was another image, and a strawberry and dress were shown as the control
distractors. The results of the experiment show an asymmetry in that when “pencil”
was presented, “panda” did not show any more fixations than the other distractors,
however when “panda” was presented, “pencil” did show more fixations. The results
suggest that there is no separate phonetic category for the [æ] vowel, instead it is
mapped to the native [ɛ] and so when the word is being said, immediately following
the production of the first vowel by the speaker, the Dutch listener will have to choose
between the two possible candidates [phæn] and [phɛn] until the remainder of the
utterance is produced. In the other direction, because there is an exact match of
vowels, there is no priming of the incorrect option. This supports the research by Ju &
Luce in that exact acoustics influence the activation of L2. A further part of the
experiment investigated Dutch nouns with phonological similarity to English nouns,
similar to Ju & Luce (2004). In this experiment, the results show that English words
will activate similar Dutch words, for example “desk” causes interference with Dutch
deksel “lid.” In contrast, monolingual English speakers did not show similar fixation
patterns. This shows that there is more lexical competition in non-native speakers than
A second study by Cutler, Weber & Otake (2006) examined native Japanese speakers
on their ability to discriminate between the English /l/ and /r/. The design of the
experiment was similar, though instead of varying vowels, consonants were varied.
The experimenters used an eye-tracking paradigm, and so had four images for each
utterance and compared the fixation times for each image to get their result. In a
similar fashion to the results of the Dutch experiment above, the Japanese speakers
showed an asymmetric activation pattern. When an English /r/ was presented, the /l/
distractor experienced greater fixation times than when an /l/ was presented with an /r/
distractor. The results of the experiment show that the L2 listeners are able to
distinguish the two phonetic categories, but they are unable to perceive the difference
when the non-dominant phoneme is uttered until a difference is heard and processed.
These two studies show that asymmetric processing of certain phonemes in an L2
environment is indeed possible and common. Given the data from Chao (1948), it is
probable that there may be a similar phenomenon occurring in Southern Mandarin
speakers who demonstrate great influence by their native dialect. In this respect, the
Southern Mandarin speakers would be similar to the Japanese speakers in that there is
just one phonetic category in their native phonemic inventory, either /n/ or /l/, and
when the other is heard, it is automatically mapped to the category that exists from the
L1 inventory. In other words, there has not been enough focused input to start to
create the new category.
2.4 Methodological Issues
As will be discussed in section 5.3, there are several important methodological issues
(2004) note that word frequency can play an important role in lexical activation.
However, it is very difficult to control each stimulus item such that there is no
absolute difference between items in a pair. In the present study, the frequencies of the
all the words were compared to each other using statistical analysis to mitigate this
issue.
Furthermore, several of the important studies reviewed in the above sections used
different experimental paradigms to collect data, including eye-tracking. Each
paradigm has its own advantages and disadvantages, and one way to overcome some
of them is to incorporate several different experiments into one study in order to
account and compensate for methodological problems.
Due to the kind of indirect priming used in the experiment, there was a wide range of
ISIs between the onset of the prime and target. This is because the distance between
the two stimulus pairs was varied randomly between 8-20 across the trials, following
the same indirect priming paradigm as Zhang et al. (2012). However, the random
variation can somewhat compensate for the changes, as there were no pairings that
were selected for shorter or longer ISIs deliberately.
Another methodological issue is the “goodness” of the nonce words. Nonce words
were selected by a non-native speaker for usage in the experiment based on the word
list used by Lee (2007), however all of the target-phoneme related words were
excluded. This was possible because Lee's (2007) stimulus list was much longer than
2.5 Summary
The present study on the lexical representations in Southern Mandarin speakers
endeavours to address two issues. The first is on the processing of the segmental
differences [n] and [l] in lexical representations. Based on data collected in Chao
(1948), we know that there was variation among certain Southern Mandarin dialects
in terms of [n] and [l] phones being present in the dialects. It is also known that
present day speakers make mistakes when speaking Mandarin with regards to the use
of [l] and [n] phones where appropriate. The second looks at the acoustic production
of key words in both Mandarin and native local dialects. All of the experiment data
was to be collected from a control group of native Beijing Mandarin speakers and an
interest group of speakers from Southern Mandarin dialect areas. To address these
issues, two experimental paradigms were used: a lexical decision task (Chapter 3) and
Chapter 3 : Lexical Decision Experiment
The goal of this experiment was to examine whether minimal pairs of words
containing the consonants of interest (l/n) are stored as homophones in native lexical
representations. A lexical decision task was used to investigate processing in
conditions where the initial consonants were manipulated. Section 3.1 discusses the
rationale for the experiment. Section 3.2 reports on the methodology of the study,
including the participants (3.2.1), stimuli (3.2.2), recording (3.2.3), and procedure
(3.2.4). The results of the experiment are presented in section 3.3. A short discussion
of the results is presented in section 3.4.
3.1 Rationale
Further to Chao's (1948) research on the dialects of Hubei province, this research
project is aimed at examining the influences of these dialects on the lingua franca:
Mandarin Chinese. Many of the dialects in Chao's (1948) compendium exhibit forms
of assimilation whereby an [l] becomes an [n] or vice-versa. This phenomenon has
been observed in the surrounding regions in present day China, and is something that
people who have moved to these areas from other parts of China notice in their
conversations with people from these affected areas. For example, people living in the
city of Changsha seem to show random variation in their production of these two
phonemes. Sometimes an [l] in Mandarin will be spoken as an [n] and vice-versa.
This study looks to investigate the representation and production of these phonemes in
experienced non-native speakers. As the two phones had already been determined by
These initial experiments included a discrimination test and a Garner test to verify that
the particular phonemes chosen were appropriate for study. The final experiment used
a medium term priming paradigm to examine lexical processing of Mandarin contrasts
in native Cantonese speakers. This study uses a similar methodology to find out about
the lexical representations that are stored in the brain, as well as their associated
production patterns (see Chapter 4) following a similar line of thought as Hayes-Harb
& Masuda (2008) who investigated Japanese geminate consonant discrimination and
production in L2 speakers. Further experiments conducted by Weber & Cutler (2004)
and Cutler et al. (2006) show an asymmetric mapping phenomenon whereby one
particular order of the stimuli showed priming whilst the other order showed
inhibition. The priming phenomena is “a change in the ability to identify or produce
an item as a result of a specific prior encounter with the item” (Schacter & Buckner,
1998). This paradigm will permit for examining whether a similar asymmetrical
representation exists in the particular case of Southern Mandarin speakers. The
experimental design considers the possibility that the internal mapping of phonemes is
interconnected and overlapping. As a result, it is possible that two different sounds
map to the same representation in the lexical inventory as is predicted in the PAM
(Best, 1995).
This experiment examines the possibility of a similar phenomenon in Standard
Chinese when it is a shared L1 with a local dialect. It may be that [n] and [l] become
mapped to the same lexical representation similar to what occurs in the above
3.2 Methodology
3.2.1 Participants
There were fifteen native speakers of Mandarin Chinese (12 females and 3 males)
who participated in the study. None of the participants reported any vision or hearing
problems. The average age of the participants was 21 years old (range: 20-23).
Participants were all students at Leiden University in either an undergraduate program
studying for a Bachelors degree (n=10) or a graduate program studying for a Masters
degree (n=5). Participants' English language abilities were not assessed as all of the
documentation had been translated into Mandarin Chinese prior to the experimental
sessions.
Most of the participants had lived the majority of their lives in Beijing (n=9). The
remaining participants came from parts of northern China (n=3) and Taiwan (n=3). All
speakers reported that their L1 native language was Mandarin Chinese ( 中 文
[Mandarin Chinese] n=1, 普通话 [Mandarin Chinese] n=9, 北京话 [Beijing dialect]
n=2, 華語 [Mandarin Chinese] n=1, 國語 [Mandarin Chinese] n=1, 漢語 [Mandarin
Chinese] n=1). This was vocally confirmed after questioning by the researcher due to
the multitude of different written forms that have similar meanings. Two participants
reported a language other than Mandarin Chinese that was spoken at home (陕西话
[Shǎnxī (also Shaanxi) dialect] n=1, and 闽南话 [Mǐnnán dialect] n=1).
The participants' parents spoke a wider variety of languages, but when asked to
elaborate on the usage of the languages used at home, all of the participants, except
for 2, said that their parents would only speak in Mandarin Chinese, and would rarely
3.2.2 Stimuli
Three types of monosyllabic words were used for the experiment. The three categories
were (1) target, (2) control, and (3) filler. Words categorised as target words had an
initial that was either a [n] or [l], for example nǚ and lǎo. Words in the control
category had an initial that was either a [th] or [t], for example tiē and duì5. Words in
the filler category had any initial that was not a part of the interest or control group,
for example [ʃ] or [m] in shēng and mèng. A total of forty monosyllabic words were
selected for the interest and control groups of words. A further eighty monosyllabic
words were selected for the filler words, and eighty monosyllabic nonce words were
created using the same constraints as the real words in the filler category.
Each word that was selected for inclusion in the experiment had an associated
minimal pair. These minimal pairs differed only in the initial consonant in the interest
and control groups, all other phonetic components were controlled. For example, the
word tài was selected for the control group. The associated minimal pair item is dài.
Written in IPA, these two words are [thai˥] and [tai˥] respectively, identical save for
the initial consonant. Pairings for the filler words and nonce words did not follow this
minimal pairing scheme as they were not key lexical items.
Four different conditions were developed in accordance with Zhang et al. (2012).
These conditions varied across the four different lists so that each possible pairing
only occurred once throughout the four lists. Each list was made up of 288 words.
One word of the pairing was considered to be an “A” and the other the “B.” In the
first condition, two “As” would be given. In the second condition, two “Bs” would be
condition, a “B” would be given, followed by an “A.” A sample distribution of
conditions across the four lists is given in the figure below. This kind of configuration
allows us to examine all of the potential relationships between the two words.
List 1 List 2 List 3 List 4
/tài/-/dài/ Con 1: /tài/-/tài/ Con 2: /dài/-/dài/ Con 3: /tài/-/dài/ Con 4: /dài/-/tài/ /nín/-/lín/ Con 2: /lín/-/lín/ Con 3: /nín/-/lín/ Con 4: /lín/-/nín/ Con 1: /nín/-/nín/
Table 2: Conditions across Lists
The pairs were entered into a spreadsheet and then repeatedly randomised using a
feature of the spreadsheet program. In order to get a similar result to Zhang et al.
(2012), the distance between the pairs needed to also be randomised. To this end,
another column in the spreadsheet was created and an integer between 8 and 20 was
generated using the RANDBETWEEN(8; 20) function. Once this was completed for
the first list, all of the other lists were generated using the same ordering as the first
list. The first list was manually checked over to avoid potential conflicts of similar
segments occurring close together to create an effect. The lists then had their
conditions changed so that they matched the table above. Each pair was only present
in one condition on each list and no pair was presented with the same condition across
lists.
A characteristic of Mandarin Chinese is that there are many homophones, identical in
terms of the segment and tone at the lexical level. For example, 是 “to be,” 市 “city,”
and 示 “to show” are all pronounced shì. As a result, words that did not have any
remaining, were words with homophones selected. In this case, the most frequently
occurring of the homophones was chosen.
Moreover, the relative frequencies of the selected words was controlled. This was
done to avoid the possibility of creating an artificial effect whereby more frequently
occurring words would be responded to faster and more accurately than a similar
word with a lower frequency. The minimal pairs chosen had similar frequencies to
each other, and the overall frequency of the words across all of the lists were kept as
similar as possible. Word frequencies were first taken from the Academia Sinica
Balanced Corpus of Modern Chinese6, and then checked against the larger the Jun Da
(2004) corpus7. This was done for two reasons: (1) to verify against anomalies
between corpora, and (2) to compensate for any skewing of the word frequencies and
differences in pronunciation caused by corpora from two different regions of the
Mandarin-speaking world. For example, if a word in the Academia Sinica corpus had
a relatively low frequency for a word, and the Jun Da corpus also had a relatively low
frequency for a word, then that word would be classified as low frequency. However,
if the Academia Sinica corpus classified a word as high frequency when Jun Da did
not, then the word would be discarded. In the situation where Jun Da had a high
frequency word where the Academia Sinica corpus did not, the Jun Da frequency
would continue to be used as the interest group and control group both are from
mainland China. Furthermore, some words in the Academia Sinica corpus use the
Taiwan pronunciation which differs from the pronunciation in mainland China. A
widely known example of this is the word for “rubbish” 垃圾. In Taiwan, this word is
pronounced lèsè, however, in mainland China it is pronounced lājī. In this case, the
Academia Sinica frequency would not be counted.
Nonce words were also used in the experiment. These are all pronounceable words
that could theoretically be written in pīnyīn, but have no meaning. A pronounceable
word in this context means that the combination of sounds is phonotactically legal,
but is not present in the actual language. These words were all checked in the Jun Da
corpus to verify that there were no words that appeared when a particular pīnyīn was
queried in the database. For example, the nonce word rǐ was coined for the purposes
of the experiment. When this is entered into the Jun Da database, there are no results
given, meaning that this word was verified as being non-existent, and therefore
classifiable as a nonce word.
3.2.3 Recording
A female native Mandarin speaker from Beijing read all 288 stimulus syllables (both
words and nonce words) into a Sennheiser MKH416T short shotgun interference tube
microphone connected to a Roland UA-55 Quad Capture USB audio interface
connected to a desktop PC running Microsoft Windows 7. The recording was done in
a soundproof chamber at the Leiden University Phonetics Laboratory using Audacity
2.0.2 (Audacity Team, 2012). Before the recording, the speaker and the researcher
went through all of the stimuli together to ensure that there would be no issues
producing the stimuli during the recording session. The speaker read through the list
of stimulus items one at a time. The audio tokens were recorded at a sampling rate of
44,100 Hz. In order to account for natural variations in speech, each of the stimulus
researcher and the clearest token was selected for the experiment. Each individual
token was down-sampled to 22,050 Hz and converted to the Waveform Audio File
Format (WAV) for compatibility with E-Prime psychological experiment software
(Psychology Software Tools, 2012).
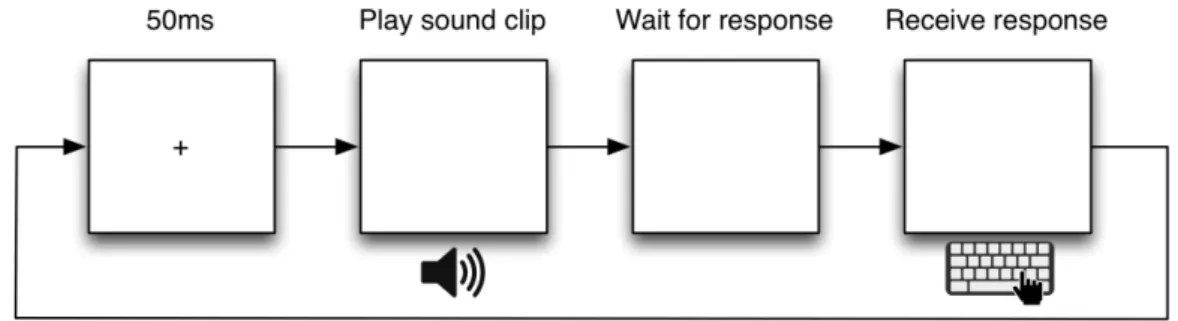
3.2.4 Procedure
Participants were tested in the Leiden University Phonetics Laboratory. Before the
experiment started, the participants were asked to fill out a questionnaire about their
language background. The questionnaire collected information such as age, gender,
education level, birthplace, languages spoken, languages and birthplace of the parents,
and hearing or vision problems. The questionnaire was developed based on Li et al.'s
(2014) LHQ 2.0 language questionnaire. As all of the participants were international
students from China, it was assumed that their level of Mandarin was sufficient to
collect data. Participants were also asked to read through a page outlining the ethical
constraints and requirements of the experiment in accordance with Leiden University
Centre for Linguistics guidelines.
Participants were seated in front of a computer screen in the phonetics laboratory and
given headphones to wear over their ears. They were instructed to press two keys on
the keyboard in order to complete the experiment.
A practice session preceded the test. The words used in the practice session were not
repeated in the remainder of the experiment. The practice session was to help all of
the participants become familiar with the format of the experiment before data
collection began. The practice session included both real words and nonce words to
they thought the utterance that they heard could be classified as a word. The
participant would see a fixation point in the centre of the screen before every sound
was played.
Responses were entered through a keyboard. Participants were instructed to press the
“k” key for a word response and the “j” key for a nonce word response. Participants
were asked to place their right hand index finger and right hand middle finger over the
“j” and “k” keys respectively. This hand placement follows proper QWERTY
keyboarding technique and also prevented any possible bias that may have been
caused by using two different hands to respond. All participants were asked to
respond as quickly and as accurately as possible. The stimuli was presented using
E-Prime psychological experiment software version 2.0.10 (Psychology Software Tools,
2012). Speed and accuracy of the responses were measured and recorded by E-Prime.
Each item-pair was only presented once to the participants. No feedback was given.
3.3 Results
The experiment was originally intended to be conducted with two different groups of
participants, Mandarin speakers from Beijing and northern China forming the control
group and Mandarin speakers from Hubei and other surrounding areas forming the
interest group. However, due to technical difficulties with E-Prime, data from the
interest group was unable to be collected.
Before conducting statistical analysis on the results, all of the filler and nonce words
were removed from the analysis. Any incorrect responses were also removed from the
analysis. Overall accuracy for the experiment was high, at 89.77%. There was a
significant effect when subjects were considered as factors against response accuracy
(F1,14 = 3.098, p < .001). However, further analysis suggests that the variation across
the participants never exceeded six percentage points (max = 0.05903) and therefore
the significant result can be disregarded.
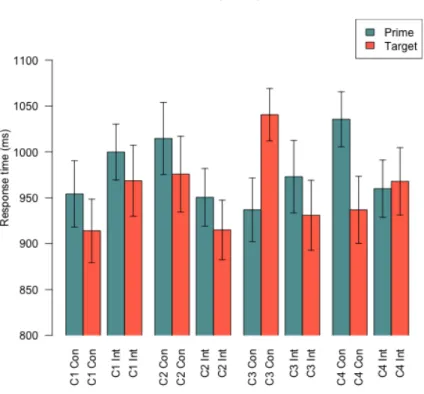
Figure 3.2 shows the effects of the different conditions on response times. A one-way
ANOVA did not yield a significant overall effect OF condition ON response time
(F1,806 = 1.908, p > .05). This means that there is little statistical variation between the
different conditions considered against the response times. A one-way ANOVA did
give a significant effect comparing the prime and target conditions and their response
times (F1,806 = 5.278, p < .05). This effect was expected, as the priming paradigm
presupposes that the conditions, if any effect is present, will create a difference
between the prime and target conditions across the experiment.
The x-axis of Figure 3.2 expresses the different word types and the conditions. In
order to save space, conditions are abbreviated to “C” followed by the number as
given in Table 2. “Con” stands for the control set of items (i.e. /t/-/d/) and “Int” stands
3.4 Discussion
The results demonstrated that there was a priming effect shown on conditions 1 and 2.
This was expected because both of the conditions are simply repeated presentation of
the same stimulus. While the result was not statistically significant, a trend can be
seen by observing the above figure. This indicates that the priming model may not be
as reliable in a study like this in comparison to a more prominent priming model, such
as those experiments conducted by Lee (2004) with an ISI of 250ms between pairs. As
this experiment used a less salient priming paradigm, the results may not be as clear
as they may have been had a different form priming paradigm been used.
Continuing with the discussion of conditions 1 and 2, the noticeable changes in
response times across the control and interest word pairs may be due to random
variation. All of the error bars for these columns show overlaps meaning that there are
no significant differences between them.
3.4.1 Control Pairings
The third condition (/t/-/d/) and fourth condition (/d/-/t/) in the control pairing shows
an inhibition effect between the prime and target in the control pairing. The third
condition result suggests that a [th] initial is inhibiting the processing of a [t] initial,
whilst a priming effect can be seen when the order of presentation is reversed in the
fourth condition, a [t] initial primes a [th] initial. The difference between the two
phonemes is the presence of aspiration, i.e. the difference between the “t” in “two”
and the “t” in “computer.” In English, an initial “t” is always aspirated, whereas when
it occurs within a word segment, there is generally no aspiration and it sounds more
like a “d.” Apart from the aspiration, the place of articulation is identical between the
two phonemes. This suggests that the aspirated phoneme acts as a subset of the
non-aspirated phoneme. That is to say that the brain first processes the [t] and
subsequently categorises the sound as aspirated [th]. Once this has occurred, the next
sound must skip over the initial processing and try to match it with the previous
aspirated sound, and when the match does not occur, it begins from the beginning,
returning to the [t] sound, and a consequence, taking much longer to process.
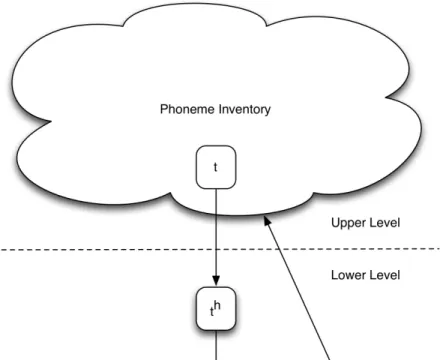
This kind of lexical representation is further supported by the significant priming
effect found in condition four. In this condition, a [t] is presented first. The brain has
phonemic inventory. When a [th] is then subsequently heard, a comparison is made
between [t] and [th] and the correct phoneme is selected. In this case, the narrowing of
the phonemic candidates has already taken place, and since [th] appears to be
categorised as a subset of [t], the selection occurs very quickly. A visual representation
of what this effect could look like is given in figure 3.3.
This phenomenon may be indicative of a larger effect on phonemic activation in
Mandarin Chinese where aspirated consonants are compared with their non-aspirated
counterparts. A further study could be conducted that examines this effect in more
detail.
3.4.2 Interest Pairings
The interest pairings in conditions three and four did not seem to generate much
variation beyond what was reasonably expected. In condition three, there was a slight
priming effect shown that by and large mimics the effects shown in conditions one
and two. This effect may not be a true effect, and may be due to random variation in
the results.
The case of condition four seems likely to be due to random variation as well. In this
condition a very minute inhibition effect may be seen. However, this effect is very
small with a difference of less than 10ms. The error bars are nearly identical, which
suggests that there may simply be no effect when an /l/ precedes an /n/, whereas there
is a slight priming effect when /n/ precedes an /l/. However, these results are both
non-significant, as the response time variation across the tokens intersect with one another
within each condition.
The initial experiment was designed to compare the results of the control group of
native northern Mandarin speakers with the interest group of L2 Southern Mandarin
speakers from the southern provinces where Mandarin is spoken. However, due to
technical issues, the interest group data was not attainable. This presents another
opportunity for further research in comparing the results gathered by this experiment
and comparing them to the results found using a different population, for example,
from the area of interest in southern China.
3.5 Conclusion
In this chapter, the results of the first experiment, a lexical decision task, are
an in-depth discussion of the procedures and methodology behind the development
and execution of the experiment. Section 3.3 presents the results and section 3.4
Chapter 4 : Elicitation Experiment
The goal of this experiment was to examine the production of certain initial
consonants for comparison with the results of the previous experiment. An elicitation
task was used to extract verbal tokens from participants. Section 4.1 discusses the
rationale for the experiment. Section 4.2 reports on the methodology of the study,
including the participants (4.2.1), stimuli (4.2.2), and procedure (4.2.3). The results of
the experiment are presented in section 4.3. A short discussion of the results is
presented in section 4.4.
4.1 Rationale
Further to the priming experiment in chapter 3, this study additionally examines the
acoustic properties of select [n] and [l] words in an attempt to discern whether
listeners are properly categorising vocal forms of the interest group. The reason for
this goes back to Chao's (1948) volume describing the Hubei dialects. However, this
study will make recordings of each individual producing specific words, rather than
notating down the sound that was heard. This provided for greater analysis once the
experimental data was collected.
4.2 Methodology
4.2.1 Participants
4.2.2 Stimuli
Two types of monosyllabic words were used for the experiment. These words were
taken from the lists already developed for the lexical decision task (see Chapter 3).
The two categories were (1) interest, and (2) filler. Words categorised as interest
words had an initial that was either a [n] or [l], for example nǚ and lǎo. Words in the
control category had an initial that was either a [th] or [t], for example tiē and duì. A
total of eighty monosyllabic words were selected for the elicitation task. No nonce
words were used.
Each word that was included in either (1) or (2) had an associated minimal pair that
differed only in the initial consonant. For example, the word tài was selected for the
control group. The associated minimal pair item is dài.
Written in IPA, these two words are [thai˥] and [tai˥] respectively, identical save for
the initial consonant.
4.2.3 Procedure
Participants were tested in the Leiden University Phonetics Laboratory. Prior to
commencing the experiment, the participants were requested to fill out a questionnaire
about their language background. The questionnaire collected information such as
birthplace, languages spoken, languages of the parents, etc (see Appendix I). The
questionnaire was developed based on Li et al.'s (2014) LHQ 2.0 language
questionnaire. As all of the participants were international students from China, it was
assumed that their level of Mandarin was sufficient to collect data. Participants were
asked to read through a page outlining the ethical constraints and requirements of the
Participants were seated in front of a computer screen in a sound-proof booth in the
phonetics laboratory. A Sennheiser MKH416T short shotgun interference tube
microphone connected to a Roland UA-55 Quad Capture USB audio interface was
positioned a short distance in front of the participant's mouth once they were seated
comfortably. At the beginning of the experiment, participants were instructed to press
the spacebar to begin the experiment, and follow the instructions given on the screen.
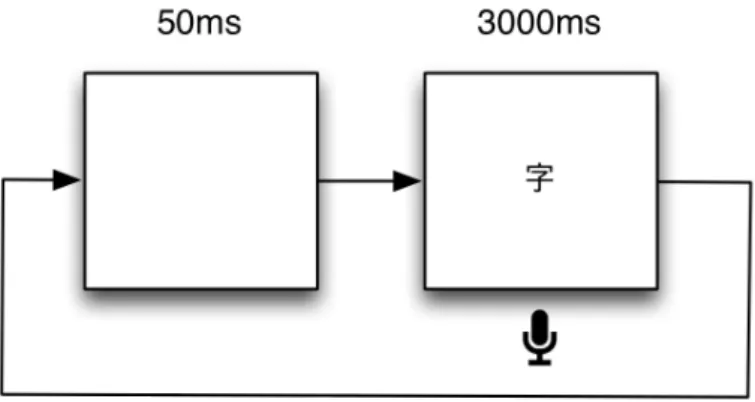
After the experiment began, the participant would see a Chinese character displayed
on the screen. Participants were asked to say the character aloud when they saw it.
The data collection software, E-Prime (Psychology Software Tools Inc, 2012), only
accepted audio data while a character was displayed on the screen. In order to provide
the participant with ample time to respond, as well as prevent audio clipping,
parameters were set to display the character and accept audio input for 3000ms.
Following the character, a blank screen was displayed for 500ms before continuing to
the next character. Responses were recorded by E-Prime. Each character was only

![Figure 4.2: Un-aspirated [t] and Aspirated [t h ] Alveolar Plosive Waveforms](https://thumb-us.123doks.com/thumbv2/123dok_us/8296963.2197272/50.892.136.760.115.981/figure-aspirated-t-aspirated-t-alveolar-plosive-waveforms.webp)
![Figure 4.4: Spectral Slices for [n] and [l]](https://thumb-us.123doks.com/thumbv2/123dok_us/8296963.2197272/52.892.138.757.112.923/figure-spectral-slices-for-n-and-l.webp)
