AUSTRALIAN JOURNAL OF BASIC AND
Open Access Journal
Published BY AENSI Publication
© 2016 AENSI Publisher All rights reserved
This work is licensed under the Creative Commons Attribution International License (CC BY). http://creativecommons.org/licenses/by/4.0/
To Cite This Article: Anand Kannan, Anitha
Murphy. An Intelligent Phrase Extraction Approach from Social Networks for User Classification 132, 2016
An Intelligent Phrase Extract
Classification
1Anand Kannan, 2Anitha Kathirvel, 3Siddharth
1.2.3.4Department of ICT, KTH University, Swe 5Department of Mathematics, KTH University 6Sweden, Founder, JLM Quality Test, Sweden
Address For Correspondence:
Anand Kannan, Department of ICT, KTH University, Sweden
A R T I C L E I N F O
Article history:
Received 04 December 2015 Accepted 22 January 2016 Available online 14 February 2016
Keywords:
Text classification, Text mining, Phrase extraction, Feature selection, Social network analysis, Neural classifier, Support vector machine and Bayesian classification algorithm
Social network analysis using information technology and compu different users by forming interes discussions among different users applied to find users with same inte collaborative learning and coordinated wor wants to learn a new subject throu giving a query to the search engine words given by the user as query 2013) . In such applications, text technique for the retrieval of text. B involves classification of textual i Güngör, 2010; Ogura, H., 2011) . Si are unordered collection of te text mining using clustering or clas and are discriminant in nature. M
Phrases are formed by a se (Iswarya, R., 2014). Selection of
AUSTRALIAN JOURNAL OF BASIC AND
APPLIED SCIENCES
ISSN:1991-8178 EISSN: 2309-8414 Journal home page: www.ajbasweb.com
© 2016 AENSI Publisher All rights reserved
This work is licensed under the Creative Commons Attribution International License (CC BY). http://creativecommons.org/licenses/by/4.0/
Anand Kannan, Anitha Kathirvel, Siddharth Madan, Pradeep Peirisand Weherage, Henrik Sjöström and Jason An Intelligent Phrase Extraction Approach from Social Networks for User Classification. Aust. J. Basic & Appl. Sci.,
Extraction Approach from Social Net
th Madan, 4Pradeep Peirisand Weherage, 5Henrik Sjöström and 6Jason
weden ty, den
Department of ICT, KTH University, Sweden
A B S T R A C T
Abstract- Text Mining plays an important role in social network analysis. It involves the extraction of the relevant key words from a given text which is collected from facebook comments. Mining of textual information from facebook comments helps to find the user interests which can be used to form interest groups. Moreover, text mining tasks involve the application of syntax and semantics, text classification and text clustering for effective concept extraction and document summarization. The extraction of words and phrases as features for classification is useful for enhancing the classification accuracy. This paper proposes a new technique to find the important key words and co-occurrence of terms which are used as features for classification. The proposed system performs text classification using three classifiers namely Neural Classifier, Naive Bayes Classifier and Support Vector Machines Classifier to classify the sentences on the facebook discussions related Computer Science domain and the results obtained from these are used to form interest groups by sending invitations.
INTRODUCTION
ng data mining techniques is emerging as a major puter applications which helps to establish a strong
st groups. The purpose of social network analysis using the textual contents where one form of a
nterest which can be used to form discussion for inated working environment through web. In such a
rough e-learning, he searches for related informat e. The search engine provides relevant information
y for web search using page ranking algorithms ( Meiyappan Yuvarani, N., classification is considered as an important
Based on the previous literature, it is known t information into one the pre-defined categories ( . Since, the texts involved are collected from the
ext. Therefore, the relevant text to the user query ssification. In natural language sentences, phrases ar . Moreover, generalizations of n-grams constitute equence of terms which are placed adjacent to each correct phrases from natural language sentence
Kathirvel, Siddharth Madan, Pradeep Peirisand Weherage, Henrik Sjöström and Jason
Aust. J. Basic & Appl. Sci., 10(2):
125-al Networks for User
ason Murphy
Text Mining plays an important role in social network analysis. It involves the extraction of the relevant key words from a given text which is collected from textual information from facebook comments helps to find the user interests which can be used to form interest groups. Moreover, text mining tasks involve the application of syntax and semantics, text classification and text t extraction and document summarization. The extraction of words and phrases as features for classification is useful for enhancing the classification accuracy. This paper proposes a new technique to find the important key which are used as features for classification. The proposed system performs text classification using three classifiers namely Neural Classifier, Naive Bayes Classifier and Support Vector Machines Classifier to classify sions related Computer Science domain and the results obtained from these are used to form interest groups by sending invitations.
area in the field of g relationship between sis is to analyze the f artificial intelligence is forums that can lead to scenario, when a user tion from the web by n by applying the key Meiyappan Yuvarani, N., and widely accepted that text classification ( Levent Özgür, Tunga web databases which has to be obtained by are formed by words ute a phrase.
126 Anand Kannan et al, 2016
Australian Journal of Basic and Applied Sciences, 10(2) Special 2016, Pages: 125-132
challenging task in text mining. Many techniques are available in the literature for the extraction of phrases and to classify sentences based on phrases ( Meiyappan Yuvarani, N., 2013; Furnkranz, J., 1998; Bekkerman, R., J. Allan, 2004) . Among them, the n-gram approach is the most important and widely
used approach for classifying the phrases. Moreover, an n-gram consists of one or more words
including its subcategories namely monograms, bigrams and trigrams. Since the phrase patterns are sequence of words, the accuracy of the text classification algorithm is improved when phrase patterns are used rather than words.
In this work, a new algorithm is proposed to extract phrases from facebook comments and to classify the users based on their interest. In addition, it provides recommendations using rules to join
as members to existing groups and also to form new groups. This work not only considers the use of
Syntactic phrases and Statistical phrases but also the semantics of the corresponding sentences for providing effective grouping of users. For this purpose, the syntactic phrases are arranged according to the underlying grammatical relations. Moreover, this work uses a look up table consisting of all possible phrases in English language. This is provided as an option in this work since the phrase construction and the application of these phrases for social network analysis are the most challenging tasks as far
as Information Retrieval systems are concerned. Since when the size of n grows exponentially, the
computational complexity of the system also increases. So the size of n is limited to have only up to n=5.
In this work, instead of testing unigrams with bigrams, the bigrams and trigrams are tested
separately. In the literature, it is proved that unigrams alone do not produce adequate features representation than bigrams. Hence, this work considers n-grams up to n=5 to produce better results. Moreover, three classifiers namely the neural classifier, Bayesian Classifier and Support Vector Machines are used in this work for classifying the documents made from the facebook comments effectively. This helps to group the user based on their interests, mainly in subjects to be learned. For this purpose, keywords are extracted in the form of phrases in the Computer Science domain which are used as features for classification.
The remainder of this paper is organized as follows: Section 2 shows the related works in this area. Section 3 depicts the architecture of the system proposed in this work. Section 4 explains the proposed
algorithm for social network analysis. Section 5 details the results obtained from this work and
provides suitable discussions. Section 6 gives conclusions on this work and also suggests suitable future works.
I. Literature Survey:
There are many works in the areas of natural language processing, information retrieval, social network analysis and classification which are found in the literature ( Porter, M.F., 1980; Porter, M.F., 2001; Sebastiani, F., 2002; Leopold Edda and Kindermann Jörg, 2002) Among them, neural classifier, Bayesian classification algorithm and Support Vector machines ( Leopold Edda and Kindermann Jörg, 2002) are the major classification algorithms which can be used for text categorization effectively. Moreover, classification is a form of Supervised Learning and hence it is trained and tested. In this work, three classifiers namely neural classifier, Bayesian classifier and support vector machine are used for classification.
The use of n-grams is already discussed in the literature by many researchers ( Tan, C.M., 2002) . Stemming algorithms are proposed by various researchers in the area of natural language processing ( Porter, M.F., 1980; Porter, M.F., 2001) . It is useful to find the root word from the full word. Text categorization is another area of research which is useful for text classification (Kindie Biredagn Nahato, 2015; Joachims, T., 1998; Sannasi Ganapathy, 2013). Comparing with clustering, classification algorithms provide more features for grouping in text classification ( Scott, S., S. Matwin, 1999; Karthiga, S., 2014; Alvaro Ortigosa, 2014) . The use of Parts of Speech (POS) tagging in Natural Language Processing (NLP) helps to perform syntax analysis effectively using an unambiguous grammar (Toutanova, K., 2003; Toutanova, K. and C.D. Manning, 2000).
The use of soft computing techniques for text mining is becoming popular due to its ability to solve the problems intelligently by providing rules through classification (Sebastiani, F., 2002; Scott, S., S. Matwin, 1999; Alvaro Ortigosa,2014). Moreover, the use of data mining techniques such as clustering and classification applied on text documents is an area of interest for many researchers in the area of information retrieval and web search in the recent years (Scott, S., S. Matwin, 1999; Karthiga, S., 2014; Alvaro Ortigosa, 2014; Madsen R.E., 2004).
social network groups for computer science domain is proposed in this paper.
An n-gram is the sub-set/sequence of n items from an existing set/sequence. They are used in a wide
range of areas such as sequence analysis and NLP. For instance, the set/sequence of characters
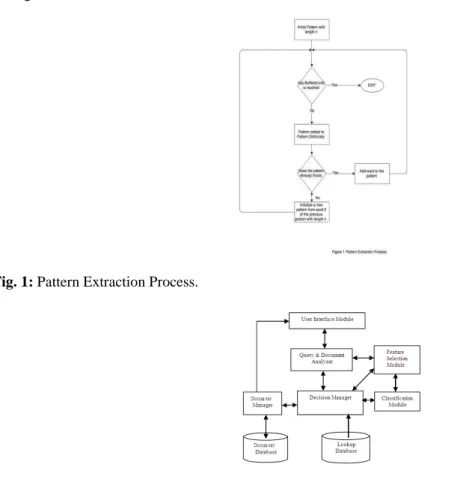
“Ichigo Kurosaki” has a bigram of (Ic, ch, hi …). These types of outputs can be used for research and development in areas statistical translations and checks. Pattern Extraction is another important feature which is the parsing of an existing arrangement/set to discover or fetch specific sequential patterns. In n-gram (and also bigram, by extension) the length of the pattern is fixed. Refer Appendix-1 for an example and pseudo-code.
II. System Architecture:
Figure 1 shows the architecture of the system proposed in this paper. It consists of eight components namely user interface, query and document analyzer, decision manager, feature selection module, classification module, document manager, document database and lookup database. The user can interact with the system through the user interface.
Fig. 1: Pattern Extraction Process.
Fig. 2: System architecture.
The query given by the user is given to the query analyzer. The query and document analyzer searches the
facebook for user discussions based on the query. The discussions are analyzed and they are stored in the
document database. The decision manager is responsible for controlling the entire system. The feature selection module is responsible for forming n-grams. The classification module classifies the documents and submits them to the decision manager. The decision manager uses the classified results and lookup table to make decisions on formation of groups. After forming groups the user interface is informed by the decision manager through document manager. The document manager is responsible for managing the discussions made by group members and their profiles.
III. Proposed Work:
Bag-of-Words approach is used in this work for representing the documents effectively. Moreover, the facebook comments by one user are collected and a document is made from the collection. Similarly, many
128 Anand Kannan et al, 2016
Australian Journal of Basic and Applied Sciences, 10(2) Special 2016, Pages: 125-132
The next step in this process is the generation of n-grams. For this purpose, the proposed system performs feature selection using association rule mining. The Apriori algorithm is used in this work for performing join and prune operations effectively to find the rules. The join operation is used to combine two or more related terms to form a phrase. The prune operation is used to remove the irrelevant words based on minimum support. Before generating phrases using n- grams, pre-processing is performed using stop word removal and stemming. Finally, features are selected based on the minimum support values, relevancy score and mutual information gain ratio values. After feature selection, Term frequency and Inverse Document Frequency values are computed to find the occurrence the phrases in documents. Now, the documents are classified using three classifiers namely neural classifier, Bayesian Classifier and Support Vector Machines to form user groups. The users are advised to join other similar groups also as recommendations based on their areas of interest with respect to e-learning in all the subjects of Computer Science at the Undergraduate level.
Lewis (1992a) [21] gave a more itemized examination of why expressions did not do well. He expressed 6 attributes that were alluring characteristics of text content
A.Classification:
•
Low number of indexing terms•
Flat distribution of attributes of indexing terms•
Absence of redundancy among terms•
Indexing of term values with low noise•
Absence of uncertainty for linguistically inferred terms•
Terms ought to be identified with the classes to be impelledBigrams helps the classification task easier when compared with unigram and other n-grams. The qualitative feature of bigram is better when features are selected correctly. Finally, classification using support vector machines provide better results by deciding whether the given phrase belong to a particular category or not and assigning a label to each phrase. Finally, the users are grouped based on the category to which they are belonging to and then interest groups are formed.
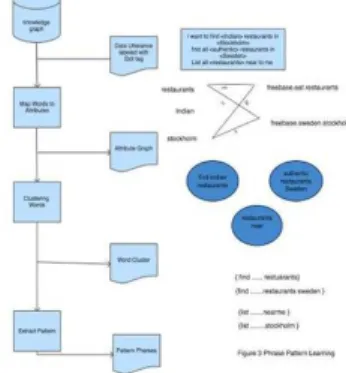
Pattern learning based on knowledge graphs is accomplished by constraining the search space while extracting ordered phrase patterns from unordered sub- sets and by ignoring ordered sets [23]. In this way dependencies can be identified without having to process the entire data. The ability to decouple pattern extraction makes for effective use of untagged data.
As shown in Figure-3, the word mapping to attributes using intuition that knowledge graph entries of a given set/sequence can be linked to task and topic of the user’s actions. The search space is then restrained using attribute mapping from the knowledge graph. Individual items in each pattern (like words) then become pivots in the pattern based on the similarity of their attributes. A natural interpretation of clusters can be brought about based on an agglomerative approach.
Finally ordered patterns of phrases from clusters of unordered pivots. Pivot sequences from the same cluster are tracked based on training data mapped to clusters.
Fig. 3: Phrase Pattern learning.
RESULT AND DISCUSSION
The experiments in this work have been carried out using real dataset collected from facebook based on discussions by users related to the Computer Science domain.
Table I: Bigrams Computer Science Category.
Computer Science Computer Networks Data Mining System Software Artificial Intelligence Game Playing Query Processing Concurrency Control Information Systems Unix Internals Java Programming Routing Protocols Table II: Trigrams for Computer Science Category
Knowledge Based Systems Advanced Computer Architecture
Software Project Management Graphics and Multimedia Wireless Communication Technologies
Service Oriented Architecture Digital Image Processing Fourth Generation Languages
Table 3 depicts the pruning parameters namely the n rate, the CPU time in seconds and the number of
Table III: Pruning parameters.
Pruning Grams
Set of words
1
DF : 3 2
TF : 5 3
4 1
DF : 5 2
TF : 10 3
4 1
DF : 10 2
TF : 20 3
4
From Table 3, it can be observed that the using pruning.
Figure 2 shows the classification accuracies of three classifiers namely Neuro classifier, Bayesian Classifier and Support Vector machines after feature selection with feature n
and pentagram.
From figure 2, it is observed that the classification accuracy is more for bigrams in comparison with other n-grams. This is due to the fact that bigrams are mostly used in computer science domain.
classification accuracy is more for SVM when it is compared with the other two classifiers. This is due to the fact that SVM classifies the categories
Fig. 2: Classification Accuracy Analysis
Figure 3 shows the accuracy analysis of classification on user based documents collected from comments. This experiment is carried out without feature selection and with feature
Information Technology Computer Architecture Data Warehousing Software Engineering Heuristic Search Knowledge Representation Transaction Management Network Security Operating Systems Compiler Design Web Technology Soft Computing Category.
Trigrams for Computer Science
Systems Database System Concepts
Architecture Software Quality Assurance
Management Management Information
Multimedia Data Communication Networks
Wireless Communication Technologies Human Computer Interaction
Architecture Social Network Analysis
Processing Expert Database Systems
Languages
Table 3 depicts the pruning parameters namely the n- values with their frequency count, the average error rate, the CPU time in seconds and the number of features.
Error rate CPU Secs.
47.07 0.92 n.a.
46.18 0.94 12686.12
45.28 0.51 15288.32
45.05 1.22 15253.27
45.18 1.17 14951.17
45.51 0.83 12948.31
45.34 0.68 13280.73
46.11 0.73 12995.66
46.11 0.72 13063.68
45.88 0.89 10676.43
45.53 0.86 13080.32
45.58 11640.18
45.74 0.62 11505.92
From Table 3, it can be observed that the n-grams with frequency based pruning provide better efficiency
Figure 2 shows the classification accuracies of three classifiers namely Neuro classifier, Bayesian Classifier and Support Vector machines after feature selection with feature namely unigram, bigram, trigram, tetra gram
From figure 2, it is observed that the classification accuracy is more for bigrams in comparison with other grams. This is due to the fact that bigrams are mostly used in computer science domain.
classification accuracy is more for SVM when it is compared with the other two classifiers. This is due to the fact that SVM classifies the categories efficiently.
Analysis.
Figure 3 shows the accuracy analysis of classification on user based documents collected from comments. This experiment is carried out without feature selection and with feature selection
Technology Architecture Engineering Representation Management Concepts Assurance Management Information Systems
Data Communication Networks Interaction Analysis
Systems
values with their frequency count, the average
error-No. of features 71.731 36.731 113.716 155.184 189.933 22.573 44.893 53.238 59.455 13.805 20.295 22.214 23.565
grams with frequency based pruning provide better efficiency
Figure 2 shows the classification accuracies of three classifiers namely Neuro classifier, Bayesian Classifier amely unigram, bigram, trigram, tetra gram
From figure 2, it is observed that the classification accuracy is more for bigrams in comparison with other grams. This is due to the fact that bigrams are mostly used in computer science domain. Moreover, classification accuracy is more for SVM when it is compared with the other two classifiers. This is due to the
130 Anand Kannan et al, 2016
Australian Journal of Basic and Applied Sciences, 10(2) Special 2016, Pages: 125-132
Fig.3. Accuracy Analysis.
From figure 3, it can be observed that the classification accuracy is more after feature selection. However, bigrams are classified better than other n-grams.
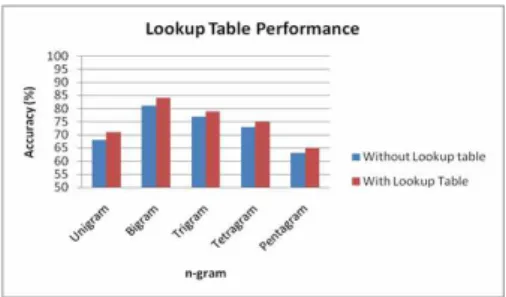
Fig. 4: Lookup Table Performance Analysis.
Figure 4 shows the performance analysis of the proposed system with lookup table and without lookup table for SVM classification.
Form figure 4, it is observed that the classification accuracy is increased when lookup table is used for validating the phrases.
Conclusion And Future Works:
In this paper, a new method for extracting the phrases is proposed for performing text classification based on social network analysis from facebook with a focus on Computer Science domain. From the experiments conducted in this work, it is proved that extraction of phrases using bigram based approach provides better results than other n-grams. The efficiency of the proposed system has been enhanced using effective feature selection and look up dictionary. Finally, it is observed that the use of SVM for classification has provided better classification accuracy than the other existing systems. Future works in this direction can be the use of intelligent agents for effective communication and coordination among the users of facebook.
REFERENCES
Meiyappan Yuvarani, N., Ch. S.N. Iyengar, A. Kannan, 2013. “Improved concept-based query expansion using Wikipedia”, International Journal of Computer Networks and Distributed Systems, 11(1): 26-41.
Levent Özgür, Tunga Güngör, 2010. “Text classification with the support of pruned dependency patterns”, Pattern Recognition Letters, 31(12): 1598-1607.
Ogura, H., H. Amano, M. Kondo, 2011. “Comparison of Metrics for Feature Selection in Imbalanced Text Classification,” Expert Systems with .Applications., 5: 4978–4989.
Iswarya, R., V. Pandiyaraju, S. Muthuraj Kumar, A. Kannan, 2014. “A Survey on Identification and Extraction of Phrases Based Method for Text Classification”, Proceedings of the International Conference on Intelligent Information Technologies, 284-290.
Furnkranz, J., 1998. “A Study Using n Gram Features for Text Categorization”, Technical ReportOEFAI-TR-930, Australian Research Institute For Artificial Intelligence., Austria.
Bekkerman, R., J. Allan, 2004. Using Bigrams in Text Categorisation.Technical Report IR-408,Center of Intelligent Information Retrieval ,UMass Amherst.
Porter, M.F., 1980. “An Algorithm for Suffix Stripping”, Program, 14: 130-137. Porter, M.F., 2001. “Snow ball: A Language for Stemming Algorithms”.
Sebastiani, F., 2002. “Machine Learning in Automated Text Categorization”, ACM Computing Surveys, 34(1): 1-47.
Tan, C.M., Y.F. Wang, C.D. Lee, 2002. “The Use of Bigrams to Enhance Text Categorization,” In,Information Processing Management, 38: 529–546.
Kindie Biredagn Nahato, Harichandran Khanna Nehemiah, Arputharaj Kannan”, 2015. Knowledge Mining from Clinical Datasets Using Rough Sets and Back propagation Neural Networks”, 460189: 1-13.
Joachims, T., 1998. “Text Categorization with Support Vector Machines:Learning with many Relevant
Features,” In:Proceedings of the 10th European Conference on Machine Learning Springer-Verlag,UK, 137– 142.
Sannasi Ganapathy, Kanagasabai Kulothungan, Sannasy Muthurajkumar, Muthuswamy Vijayalakshmi, Yogesh Palanichamy, Arputharaj, Kannan, 2013. “Intelligent feature selection and classification techniques for intrusion detection in networks: a survey. EURASIP Journal on Wireless Communication. and Networking, 271.
Scott, S., S. Matwin, 1999. ”Feature Engineering for text Classification”, In Proceedings so of the 16th International Conference on Machine Learning(ICML-99), Morgan Kaufmann, Bled , Slovenia, 379-388.
Karthiga, S., Sundan Bose, Arputharaj Kannan, SpyNetMiner, 2014.An Outlier Analysis to Tag Elites in Clandestine Social Networks. International Journal of Data Warehousing and Mining, 10(1): 32-54.
Alvaro Ortigosa, José, M. Martín, Rosa M. Carro, 2014. “Sentiment analysis in Facebook and its application to e- learning”, Computers in Human Behavior, Elsevier, 3: 527–54.
Toutanova, K., D. Klein, C.D. Manning, Y. Singer, 2003. “Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network,” in Proc.NAACL, 173– 180.
Toutanova, K. and C.D. Manning, 2000. “Enriching the Knowledge Sources used in a Maximum Entropy Part-of- Speech Tagger,” in Proc. EMNLP, 63–70.
Madsen R.E., S. Sigurdsson, L.K. Hansen and J. Lansen, 2004. “Pruning the Vocabulary for Better Context Recognition”, 7th International Conference on Pattern Recognition.
Lewis, D., 1992a. Representation and Learning in Information Retrieval. Technical Report UMCS-1991-093. Department of Computer Science, University of Massachusetts, Amherst, MA.
“N-gram and Fast Pattern Extraction Algorithm - Code Project.” [Online]. Available:
http://www.codeproject.com/Articles/20423/N-gram- and-Fast-Pattern-Extraction-Algorithm. [Accessed: 29-Oct-2015].
“Learning Phrase Patterns for Text Classification Using a Knowledge Graph and Unlabeled Data - Microsoft Research.” [Online]. Available: httpfault.aspx?id=226224.
[Accessed: 29-Oct-2015].
APPENDIX-I:
Please find an example [22] of the n-gram algorithm with the input following sequence – “w0w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6”.
132 Anand Kannan et al, 2016