International Journal of Advanced Research in Computer Science and Electronics Engineering Volume 1, Issue 3, May 2012
Abstract— The area of clone detection has considerably evolved over the last decade, leading to approaches with better results. Since code clones are believed to reduce the maintainability of software, several code clone detection techniques and tools have been proposed. Token-by token matching technique is more expensive than line-by-line matching in terms of computing complexity since a single line is usually composed of several tokens. In this paper token based tools have been evaluated that is, CCfinder and PMD copy/paste detector on the basis of three types of metrics that is, clone set metrics , file metrics , line metrics to investigate the code clones in source files. The results of the analysis processes show that each tool has its own strengths and weaknesses and no single tool is able to identify all clones within the code.
Index Terms— Plagiarism, CCFinder , PMD copy/paste detector, clone metrics.
I. INTRODUCTION
A. Code Clone
A code clone is one of a code portions in source files that is identical or similar to each another. A software system has several clone subsystems created by duplication with slight modification. However, since the size and the degree of similarities among code segments vary, code cloning is a fairly subjective concept. It depends on the context or human judgement whether it is a code clone or not [1]. Code clones are one of the factors that make software maintenance difficult as when a fault is found in one subsystem, the engineer has to carefully modify all other subsystems. It was believed that there would be many clones in the system, but the documentation did not provide enough information regarding the clones. It was considered that these clones heavily reduce maintainability of the system; thus, an effective clone detection tools have been expected.
Manuscript received May 2012.
Rupinder Kaur, University College Of Engineering, Punjabi University Patiala., (e-mail: [email protected]). Patiala, India, 9463536647
Harpreet Kaur, University College Of Engineering, Punjabi University Patiala.9814008879, (e-mail: [email protected]),Patiala, India
Prabhjot Kaur, University College Of Engineering, Punjabi University Patiala., 9463536639., (e-mail: [email protected]). Patiala, India
B. How Do Clones Occur
Code clones do not occur in software systems by themselves. There are several factors that might force or influence the developers and/or maintenance engineers in making cloned code in the system. Software clones appear for a variety of following reasons:
1. Code reuse by copying pre-existing idioms. 2. Limitations of the programming language.
3. Deferred generalization: Code is copied and modified and only then the differences are factored out when they are all known and understood.
4. Templating: Copied text is used as a template and then customized in the pasted context.
5. Cloning by Accidents: Coincidentally implementing the same logic by different developers
C. Code Clone Types
Textual Similarity: Based on the textual similarity we distinguish the following types of clones
1. Exact clone (type 1) copied code fragment is same as the original. However, there might be a some variations in whitespaces ,comments or layouts 2. Renamed clone (type 2) is a copy where only
parameters (identifiers or literals) have been changed as shown in figure 1.
3. Gapped clone (type 3) is a copy with further modifications i.e. by deleting or adding code fragments in both fragments , we can transform them into a contiguous clone.
CCFinder extracts the following two types of code clone corresponds to a code fragment C.
Functional Similarity: If the functionalities of the two code fragments are identical or similar i.e., they have similar pre and post conditions, we call them semantic clones.
Type 4: Two or more code fragments that perform the same computation but implemented through different syntactic variants.
EVALUATION OF TOKEN BASED TOOLS
ON THE BASIS OF CLONE METRICS
Exact code clone Renamed code clone Fig 1: Exact and renamed code clone
D. Clone Detection Techniques and Tools
Many clone detection approaches have been proposed in the literature. Based on the level of analysis applied to the source code, the techniques can roughly be classified into four main categories: textual, lexical, syntactic, and semantic[3].
Text based technique: In this approach, the target source program is considered as sequence of lines/strings. Once two or more code fragments are found to be similar in their maximum possible extent (e.g., w.r.t maximum no. of lines) are returned as clone pair or clone class by the detection technique. The advantage is that the technique can be applied to any kind of programming language. The disadvantage is that minor textual modifications, for instance, changes in identifiers or layout, may mislead the analysis[10].
Token based technique: A lexical analysis turns a program into a stream of tokens (indivisible units of meaning). Clone detection then turns into the problem of finding similar token subsequences. Because of the space and time complexity linear to the program length, these approaches scale very well. Also, lexical analysis is relatively simple, so that the technique can quickly be adjusted to other languages. One of the leading state of the art token-based techniques is CCFinder [2] of Kamiya et al.
Tree-based technique: In the tree-based approach a program is pared to a parse tree or an abstract syntax tree (AST) with a parser of the language of interest. Similar subtrees are then searched in the tree with some tree matching techniques and the corresponding source code of the similar subtrees are returned as clones pairs or clone classes. The variable name and literal values of source code are discarded during tree representation. The disadvantage is the necessity to develop a parser and the overhead for parsing. One of the
CloneDR. [3]
PDG based technique: PDG [4] contains the control flow and data flow information of a program and hence carries semantic information. Once a set of PDGs are obtained from a subject program, isomorphic subgraph matching algorithm is applied for finding similar subgraphs which are returned as clones. The disadvantage of these techniques is that the analysis is quite expensive.
II CODE CLONE DETECTION TOOL: CCFinder
CCFinder (code clone finder) detects code clones from program source codes and outputs the locations of the clone pairs in the source codes. CCFinder has no GUI but it only generates character based output. The detection process consists of four steps shown in figure 2:
Step1 Lexical analysis: Each line of source files is divided into tokens corresponding to a lexical rule of the programming language. The tokens of all source files are concatenated into a single token sequence, so that finding clones in multiple files is performed in the same way as single file analysis[2].
Step2 Transformation: The token sequence is transformed, i.e., tokens are added, removed, or changed based on the transformation rules that aims at regularization of identifiers and identification of structures. Then, each identifier related to types, variables, and constants is replaced with a special token. This replacement makes code portions with different variable named clone pair.
Step3 Match Detection: From all the sub-strings on the transformed token sequence, equivalent pairs are detected as clone pairs.
Step4 Formatting: Each location of clone pair is converted into line numbers on the original source files.
The CCFinder has following characterstics:
(1) CCFinder should have industrial-size strength, and be applicable to million-line size system within affordable computation time.
(2) The language dependent part of CCFinder should be limited to small parts, and the tool has to be easily adaptable to many other languages as C, C++, Java, and COBOL. (3) CCFinder should detect clones of practical interest clones. Not only syntactically same portions, but also similar portions which are considered to be actual clones have to be effectively extracted[8].
(4) Scatter plot of code showing the code clones.
(5) It should give the graphical representation as metrics graph.
(6)CCFinder gives the source code view of files.
III PLAGIARISM DETECTION TOOL: PMD’s
Copy/Paste Detector (CPD)
The PMD open source tool provides a Copy/Paste Detector (CPD) tool for finding duplicate code. Plagiarism is intentionally or unintentionally reproducing (copying, rewording, paraphrasing, adapting, etc) work that was produced by another person(s) without proper
Source file Copied and pasted
Renamed
If(a>b) { b++; a=0; } If(x>y)
{ y++; x=1; }
{ y++; x=1;
International Journal of Advanced Research in Computer Science and Electronics Engineering Volume 1, Issue 3, May 2012
Token sequence
Mapping from transformed sequence into original
Transformed token sequence
Clones transformed sequence
Clone pairs/clone classes
Fig 2: CCFinder clone detection process
acknowledgement in an attempt to gain academic benefit.. Work that can be plagiarised includes: words (language), ideas, findings, writings, graphic representations, computer programs, diagrams, graphs, illustrations, creative work, information, lectures, printed material, electronic material, or any other original work created by someone else. It works with Java, JSP, C, C++, Fortan and PHP code. It also provides guidance on how to add other programming languages to the tool. Because it is a duplicate code detector, this tool scans the files themselves for duplicate code, hence it returns similar code found within the same file. However, it is also successful in returning similar code across different files and can be used as a tool for detecting similarity in source-code files. PMD:CPDDesigner generates a report for PMD's Copy/Paste Detector (CPD) tool. It can also generate a cpd results file in any of these formats: xml, csv or txt. PMD is a static rule set based Java source code analyzer that identifies potential problems like:
1. Possible bugs - Empty try/catch/finally/switch blocks.
2. Dead code - Unused local variables, parameters and private methods.
3. Empty if/while statements.
4. Overcomplicated expressions - Unnecessary if statements, for loops that could be while loops. 5. Suboptimal code -Wasteful String/String Buffer
usage.
6. Classes with high Cyclomatic Complexity measurements.
7. Duplicate code - Copied/pasted code can mean copied/pasted bugs, and decreases maintainability.
IV RESULTS
The aim of this paper has to identify which of the evaluated tools are best suited to support the process of software maintenance and clone detection.
Figure 3: Scatter plot of clones in CCFinder tool
The view in figure 2 shows where and how the code clones are distributed in the whole source files.
Gray vertical and horizontal lines are boundaries of the source files, that is, locations of the end-of-flies. Squares drawn by white lines (on the main diagonal line) are directories. Black lines (and dots) that located parallel to the main diagonal line are code clones The corresponding orthogonal projections to the horizontal axis and vertical axis are the locations of similar code fragments.
The longest clone (941 tokens, 191 lines) was found in a
fileC:\Users\as\Desktop\java_project_game\java_project_g
ame\ars\MainMenu.java (marked as blue square in Fig. 2).It
takes about three minutes for execution on the PC. The files are sorted in alphabetical order of the file paths, so that files in the same directory are also located nearby on the axis. A clone pair is shown as a diagonal line segment. In Fig.3, each line segment looks like a dot since each clone pair is small in comparison to the scale of the axis. Most line segments are Lexical analysis
Transformation
of the clones occur within a file or among source files at the near directories. Clone metrics have been used to investigate the code clones and the source files.
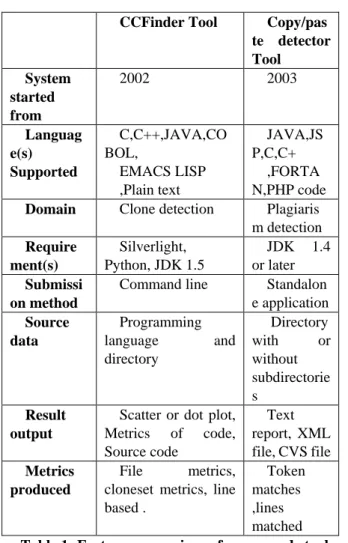
CCFinder Tool Copy/pas te detector Tool System
started from
2002 2003
Languag e(s) Supported
C,C++,JAVA,CO BOL,
EMACS LISP ,Plain text
JAVA,JS P,C,C+
,FORTA N,PHP code
Domain Clone detection Plagiaris m detection
Require ment(s)
Silverlight, Python, JDK 1.5
JDK 1.4 or later
Submissi on method
Command line Standalon
e application
Source data
Programming
language and
directory
Directory
with or
without subdirectorie s
Result output
Scatter or dot plot, Metrics of code, Source code
Text report, XML file, CVS file
Metrics produced
File metrics, cloneset metrics, line based .
Token matches ,lines matched
Table 1: Feature comparison of source code tools
This table compares the features offered by various tools that aid with the detection of source-code plagiarism detection.
In total the Graph Tool case study identified initial clones. Not all clones were found by each tool, in fact no single tool identified all clones. The initial clone numbers identified by each tool are shown within Table 2 below.
CCFinder PMD
copy/paste detector Identified
clones
by each
tool
6 4
Table 2: Total clone numbers identified by each tool
From Table 2 , it can be seen that CCFinder identified the largest number of clones, a total of 6, whereas PMD Copy/paste detector identified only 4 on giving the minimum clone length of 50.
A. Analyzing Code Clones by Metrics
The metrics enable us to answer questions, such as which
system? The followings are the 3 clone metrics on which comparison has to made :
Clone Set Metrics
LEN (length) [2]: Represent the maximum length of element(code fragment) in a given clone class. The length can be measured by the number of tokens, or the size measures such as LOC (the number of lines, including null and comment lines), or SLOC (the number of lines, except null or comment lines)
POP(population) [4] :Represent the number of element(code fragment) for a given clone class. If this value is high, it means that the similar code fragment appears in many places.
RAD(Radius) [5] :Represent the range of the source code fragments of a code clone in the directory hierarchy, when the source code is supposed to be stored in the hierarchical directory. When all the code fragments of a clone class are located in one source file, the RAD value of the clone class is equivalent to 0. When the code fragments of the clone class are located in multiple source files stored in one directory, the RAD is 1. If those sources files are stored in different directories, then RAD is the maximum depth of those sources measured from their common parent director.
RNR (ratio of non-repeated tokens) [6]:Ratio (percentage) of tokens that are not included in repeated part of a code fragment of the code clone.
We assume that the clone set S includes n code clones, c1, c2 . . . , cn, LOS whole(fi) represents the Length Of the whole token Sequence of code clone ci, and LOS repeated(fi) represents the ci Length Of repeated token Sequence of code clone , then,
Higher RNR(S) values mean that each code clone in a clone set S consists of more non-repeated token sequences. In most cases, repeated code sequences are involved in language-dependent code clones (e.g., code clones that involve consecutive if (or if-else) blocks, case entries of switch statements, consecutive variable declarations).
NIF: Count of source files that include one or more code fragments of the code clone. By definition, NIF <= POP.
LOOP: LOOP is defined as count of loops in a code fragment.
COND: COND is defined as count of conditional branches.
International Journal of Advanced Research in Computer Science and Electronics Engineering Volume 1, Issue 3, May 2012
Tools Metrics
CCFinder PMDCopy/pas
te detector
RNR .829 .240
NIF 3 2
COND 0 10
POP 2 2
Table 3: Comparing clone set metrics
In table 3 , CCFinder has more RNR value as compared to PMD copy/paste detector which shows that each code clone in a clone set consists of more non-repeated token sequences and also loop value is 0 as there is no conditional branch.
File Metrics
NBR (neighbor): Count of files that have a code-clone fragment between the file.
RSA(f) (Ratio of similarity to all other files) [9]:
Represents the ratio between the file and the extent to which the code in the file is covered by the clone pairs present in all files other than the file .It is defined by following equation:
(Len (f): token length of file f)
(Len (cf): token length of the code fragment cf)
RSI (ratio of similarity within the file) [7]: Ratio (percentage) of tokens that are covered by a code clone enclosed within the file. If a file has a RSI value close to 100%, then it is possible that the file contains a series of the similar functions or methods.
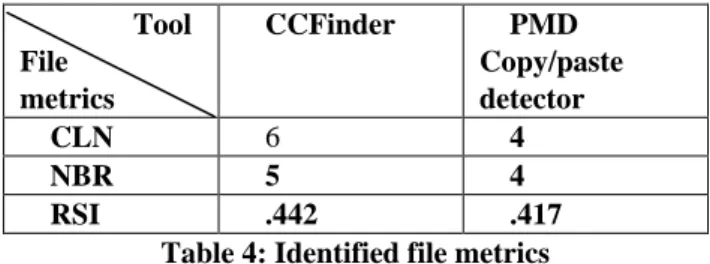
Tool File metrics
CCFinder PMD
Copy/paste detector
CLN 6 4
NBR 5 4
RSI .442 .417
Table 4: Identified file metrics
Table 4, represents more clone detected by CCFinder on giving the same source files representing more similar functions. RSI value is less than 50% evaluating file does not contain the series of similar function methods in a source code.
Line-Based Metrics
LOC: Raw line count of the source file.
SLOC: Count of lines, in case of excluding lines whithout any valid tokens. Here, the "tokens" are specific to CCFinder. (For example, definitions of simple getters/setters in Java source file will be entirely neglected by CCFinder.) Such neglected characters are shown in green color in Source Text view.
CLOC: Count of lines including at least one token of a code fragment of a code clone.
CVRL: Ratio of the lines including a token of a code fragment of a code clone. It is calculated as
CVRL = CLOC / SLOC.
CCFinder PMD
Copy/paste detector
SLOC 131 145
CLOC 109 68
CVRL .832 .468
Table 5: Identification of line based metrics
Ratio of lines including token of a code is higher for CCFinder even though the count of lines are less as compared to copy/paste detector tool shown in table 5.
V CONCLUSION
In this paper, we have presented a clone detecting token based technique with transformation rules and a token-based comparison to improve performance and efficiency. We have also proposed clone metrics that have been used to investigate the code clones and to evaluate the performance of CCFinder and PMD copy/paste detector tools. The results have identified that there is no single and outright winner for clone detection for preventive maintenance. Each tool had some factors that may ultimately prove useful to the maintainer and clone detector. Currently the output of most clone detection tools is a simple textual representation but in this paper, graphical representation will allow the user to browse summaries of each source code file detailing the clones detected across and within file structures. Furthermore the ultimate choice is most likely to differ under the circumstances at which the change proposal is made.
A further way in which this process could be improved would be to automate the collation process and to be able to pool the results of using each tool. The paper proposes that it may be possible to use a combination of tools to perform the analysis process providing that adequate means of efficiently identifying false matches
REFERENCES
[1] I.D. Baxter, A. Yahin, L. Moura, M. Sant'Anna, and L. Bier, ªClone Detection Using Abstract Syntax Trees,º Proc. IEEE Int'l Conf. Software Maintenance (ICSM '98), pp. 368-377, Nov. 1998.
[2] Toshihiro Kamiya, Shinji Kusumoto, Katsuro Inoue. CCFinder: A Multilinguistic Token-Based Code Clone Detection System for Large Scale Source Code. Transactions on Software Engineering, Vol. 28(7): 654- 670, July 2002.
[3]Ira Baxter, Andrew Yahin, Leonardo Moura, Marcelo Sant Anna Clone Detection Using Abstract Syntax Trees. In Proceedings of the
dependence graph and its use in optimization. ACM Trans. Program. Lang. Syst., 9(3):319349, 1987.
[5] Yasushi Ueday, Toshihiro Kamiyaz, Shinji Kusumotoy and Katsuro
Inoue, Gemini: Maintenance Support Environment Based on Code
Clone Analysis
[6]Y. Higo, T. Kamiya, S. Kusumoto, and K. Inoue. Method and Implementation for Investigating Code Clones in a Software System. Information and Software Technology, 49(9-10):985–998, 2007.
[7] Yoshiki Higo1,Toshihiro Kamiya2, Shinji Kusumoto1 and Katsuro Inoue1, Refactoring Support Based on Code Clone Analysis
[8] Yoshiki Higo1,Toshihiro Kamiya2, Shinji Kusumoto1 and Katsuro Inoue1Maintenance Support Tools for JAVA Programs: CCFinder and JAAT
[9]Yasushi Ueda,1 Toshihiro Kamiya,2 Shinji Kusumoto,3 and Katsuro Inoue3Code Clone Analysis Environment for Supporting Software Development and Maintenance
[10] C. K. Roy and J. R. Cordy. Scenario-based comparison of clone detection techniques. In International Conference on Program Comprehension. IEEE CS Press, 2008.
AUTHORS
Rupinder Kaur:Miss.Rupinder Kaur is currently pursuing M.TECH (final year) in department of Computer Engineering at University College of Engineering, Punjabi University, Patiala. She has done her B.TECH. in trade computer engineering from GTBKIET,Punjab Technical University, Jalandhar. She has presented many papers in national and international conferences. Her topic of research evaluation of token based tools on the basis of clone metrics.
Harpreet Kaur: Harpreet Kaur is currently Assistant Professor at University College of Engineering, Punjabi University, Patiala, India. She is
University, Patiala. She has completed her M.E(Software Engineering) from Thapar University, Patiala. She has done her B.TECH. in trade computer science and engineering from BBSBEC Fatehgarh Sahib, Punjab Technical University, Jalandhar.Three papers in international conference sand 6 in national conferences are to her credit.