How Much Can We Generalize from Impact Evaluations?
Eva Vivalt∗
New York University
April 30, 2015
Abstract
Impact evaluations aim to predict the future, but they are rooted in particular contexts and results may not generalize across settings. I founded an organization to systematically collect and synthesize impact evaluation results on a wide variety of interventions in development. These data allow me to answer this and other questions for the first time using a large data set of studies. I examine whether results predict each other and whether variance in results can be explained by program characteristics, such as who is implementing them, where they are being implemented, the scale of the program, and what methods are used. I find that when regressing an estimate on the hierarchical Bayesian meta-analysis result formed from all other studies on the same intervention-outcome combination, the result is significant with a coefficient of 0.5-0.7, though the R2 is very low. The program implementer is the main source of heterogeneity in results, with government-implemented programs faring worse than and being poorly predicted by the smaller studies typically implemented by academic/NGO research teams, even controlling for sample size. I then turn to examine specification searching and publication bias, issues which could affect generalizability and are also important for research credibility. I demonstrate that these biases are quite small; nevertheless, to address them, I discuss a mathematical correction that could be applied before showing that randomized controlled trials (RCTs) are less prone to this type of bias and exploiting them as a robustness check.
∗
E-mail: eva.vivalt@nyu.edu. I thank Edward Miguel, Bill Easterly, David Card, Ernesto Dal B´o, Hunt Allcott, Elizabeth Tipton, David McKenzie, Vinci Chow, Willa Friedman, Xing Huang, Michaela Pagel, Steven Pennings, Edson Severnini, seminar participants at the University of California, Berkeley, Columbia University, New York University, the World Bank, Cornell University, Princeton University, the University of Toronto, the London School of Economics, the University of Ottawa, and the Australian National University, among others, and participants at the 2015 ASSA meeting and 2013 Association for Public Policy Analysis and Management Fall Research Conference for helpful comments. I am also grateful for the hard work put in by many at AidGrade over the duration of this project, including but not limited to Jeff Qiu, Bobbie Macdonald, Diana Stanescu, Cesar Augusto Lopez, Jennifer Ambrose, Naomi Crowther, Timothy Catlett, Joohee Kim, Gautam Bastian, Christine Shen, Taha Jalil, Risa Santoso and Catherine Razeto.
1
Introduction
In the last few years, impact evaluations have become extensively used in development eco-nomics research. Policymakers and donors typically fund impact evaluations precisely to figure out how effective a similar program would be in the future to guide their decisions on what course of action they should take. However, it is not yet clear how much we can extrapolate from past results or under which conditions. Further, there is some evidence that even a similar program, in a similar environment, can yield different results. For example, Boldet al. (2013) carry out an impact evaluation of a program to provide contract teachers in Kenya; this was a scaled-up version of an earlier program studied by Duflo, Dupas and Kremer (2012). The earlier intervention studied by Duflo, Dupas and Kremer was implemented by an NGO, while Boldet al. compared implemen-tation by an NGO and the government. While Duflo, Dupas and Kremer found positive effects, Bold et al. showed significant results only for the NGO-implemented group. The different findings in the same country for purportedly similar programs point to the substantial context-dependence of impact evaluation results. Knowing this context-dependence is crucial in order to understand what we can learn from any impact evaluation.
While the main reason to examine generalizability is to aid interpretation and improve predic-tions, it would also help to direct research attention to where it is most needed. If generalizability were higher in some areas, fewer papers would be needed to understand how people would behave in a similar situation; conversely, if there were topics or regions where generalizability was low, it would call for further study. With more information, researchers can better calibrate where to direct their attentions to generate new insights.
It is well-known that impact evaluations only happen in certain contexts. For example, Figure 1 shows a heat map of the geocoded impact evaluations in the data used in this paper overlaid by the distribution of World Bank projects (black dots). Both sets of data are geographically clus-tered, and whether or not we can reasonably extrapolate from one to another depends on how much related heterogeneity there is in treatment effects. Allcott (forthcoming) recently showed that site selection bias was an issue for randomized controlled trials (RCTs) on a firm’s energy conservation programs. Microfinance institutions that run RCTs and hospitals that conduct clinical trials are also selected (Allcott, forthcoming), and World Bank projects that receive an impact evaluation
Figure 1: Growth of Impact Evaluations and Location Relative to Programs
The figure on the left shows a heat map of the impact evaluations in AidGrade’s database overlaid by black dots indicating where the World Bank has done projects. While there are many other development programs not done by the World Bank, this figure illustrates the great numbers and geographical dispersion of development programs. The figure on the right plots the number of studies that came out in each year that are contained in each of three databases described in the text: 3ie’s title/abstract/keyword database of impact evaluations; J-PAL’s database of affiliated randomized controlled trials; and AidGrade’s database of impact evaluation results data.
are different from those that do not (Vivalt, 2015). Others have sought to explain heterogeneous treatment effects in meta-analyses of specific topics (e.g. Saavedra and Garcia, 2013, among many others for conditional cash transfers), or to argue they are so heterogeneous they cannot be ade-quately modelled (e.g. Deaton, 2011; Pritchett and Sandefur, 2013).
Impact evaluations are still exponentially increasing in number and in terms of the resources devoted to them. The World Bank recently received a major grant from the UK aid agency DFID to expand its already large impact evaluation works; the Millennium Challenge Corporation has committed to conduct rigorous impact evaluations for 50% of its activities, with “some form of credible evaluation of impact” for every activity (Millennium Challenge Corporation, 2009); and the U.S. Agency for International Development is also increasingly invested in impact evaluations, coming out with a new policy in 2011 that directs 3% of program funds to evaluation.1
Yet while impact evaluations are still growing in development, a few thousand are already complete. Figure 1 plots the explosion of RCTs that researchers affiliated with J-PAL, a cen-ter for development economics research, have completed each year; alongside are the number of development-related impact evaluations released that year according to 3ie, which keeps a
direc-1While most of these are less rigorous “performance evaluations”, country mission leaders are supposed to identify
tory of titles, abstracts, and other basic information on impact evaluations more broadly, including quasi-experimental designs; finally, the dashed line shows the number of papers that came out in each year that are included in AidGrade’s database of impact evaluation results, which will be described shortly.
To summarize, while we do impact evaluation to figure out what will happen in the future, many issues have been raised about how well we can extrapolate from past impact evaluations, and despite the importance of the topic, previously we were unable to do little more than guess or examine the question in narrow settings as we did not have the data. Now we have the opportunity to address speculation, drawing on a large, unique dataset of impact evaluation results.
I founded a non-profit organization dedicated to gathering this data. That organization, Aid-Grade, seeks to systematically understand which programs work best where, a task that requires also knowing the limits of our knowledge. To date, AidGrade has conducted 20 meta-analyses and systematic reviews of different development programs.2 Data gathered through meta-analyses are the ideal data to answer the question of how much we can extrapolate from past results, and since data on these 20 topics were collected in the same way, coding the same outcomes and other variables, we can look across different types of programs to see if there are any more general trends. Currently, the data set contains 637 papers on 210 narrowly-defined intervention-outcome combi-nations, with the greater database containing 14,993 estimates.
The data further allow me to examine a second set of questions revolving around specification searching and publication bias. Specification searching refers to the practice whereby researchers artificially select results that meet the criterion for being considered statistically significant, biasing results. It has been found to be a systematic problem by Gerber and Malhotra in the political science and sociology literature (2008a; 2008b); Simmons and Simonsohn (2011) and Bastardi, Uhlmann and Ross (2011) in psychology; and Brodeur et al. (2012) in economics. I look for evidence of specification searching and publication bias in this large data set, both for its own importance as well as because it is possible that results may appear to be more “generalizable” merely because they suffer from a common bias.
I pay particular attention to randomized controlled trials (RCTs), which are considered the
“gold standard” in the sciences and on which development economics has increasingly relied. It is possible that the method may reduce specification searching due to its emphasis on rigor or the increased odds of publication independent of results. It is also possible that RCTs may be done in more selected settings, leading to results not generalizing as well. I will shed light on both of these potential issues.
The outline of this paper is as follows. First, I define generalizability, present some basic statis-tics about it, and use leave-one-out cross-validation to check what kinds of study characterisstatis-tics can help predict another study’s results better than placebo data. I also conduct leave-one-out hi-erarchical Bayesian meta-analyses of all but one result within an intervention-outcome combination and check to what extent these meta-analysis results, which theoretically might provide the best estimates of a given program’s effects, predict the result left out. Since some of the analyses will draw upon statistical methods not commonly used in economics, I will use the concrete example of conditional cash transfers (CCTs), which are relatively well-understood and on which many papers have been written, to elucidate the issues.
Regarding specification searching, I first conduct caliper tests on the distribution of z-statistics, seeing whether there is a disproportionate number of papers just above the threshold for statistical significance compared to those just below the threshold. The data contain both published papers and unpublished working papers, and I examine how much publication bias there appears to be for results that are significant.
After examining how much these biases are present, I discuss how one might correct for them when considering generalizability. There is a simple mathematical adjustment that could be made if one were willing to accept the constraints of a fixed effects meta-analysis model.3 However, I show this would not be an appropriate model for these data. Instead, I turn to using RCTs, which I show do not suffer as much from these biases, as a robustness check.
While this paper focuses on results for impact evaluations of development programs, this is only one of the first areas within economics to which these kinds of methods can be applied. In many of the sciences, knowledge is built through a combination of researchers conducting individual studies and other researchers synthesizing the evidence through meta-analysis. This paper begins that natural next step.
3
2
Theory
2.1 Heterogeneous Treatment Effects
I model treatment effects as potentially depending on the context of the intervention. Each impact evaluation is on a particular intervention and covers a number of outcomes. The relationship between an outcome, the inputs that were part of the intervention, and the context of the study is complex. In the simplest model, we can imagine that context can be represented a “contextual variable”,C, such that:
Zj “α`βTj`δCj`γTjCj `εj (1)
wherej indexes the individual,Z represents the value of an aggregate outcome such as “enrollment rates”,T indicates being treated, andCrepresents a contextual variable, such as the type of agency that implemented the program.4
In this framework, a particular impact evaluation might explicitly estimate:
Zj “α`β1Tj`εj (2)
but, as Equation 1 can be re-written asZj “α` pβ`γCjqTj`δCj`εj, whatβ1 is really capturing is the effect β1
“ β`γC. When C varies, unobserved, in different contexts, the variance of β1
increases.
This is the simplest case. One can imagine that the true state of the world has “interaction effects all the way down”.
Interaction terms are often considered a second-order problem. However, that intuition could stem from the fact that we usually look for interaction terms within an already fairly homogeneous dataset -e.g. data from a single country, at a single point in time, on a particularly selected sample. Not all aspects of context need matter to an intervention’s outcomes. The set of contextual variables can be divided into a critical set on which outcomes depend and an set on which they do not; I will ignore the latter. Further, the relationship betweenZ andC can vary by intervention or outcome. For example, school meals programs might have more of an effect on younger children,
4
Z can equally well be thought of as the average individual outcome for an intervention. Throughout, I take high values for an outcome to represent a beneficial change unless otherwise noted; if an outcome represents a negative
but scholarship programs could plausibly affect older children more. If one were to regress effect size on the contextual variable “age”, we would get different results depending on which intervention and outcome we were considering. Therefore, it will be important in this paper to look only at a restricted set of contextual variables which could plausibly work in a similar way across different interventions. Additional analysis could profitably be done within some interventions, but this is outside the scope of this paper.
Generalizability will ultimately depend on the heterogeneity of treatment effects. The next section formally defines generalizability for use in this paper.
2.2 Generalizability: Definitions and Measurement
Definition 1 Generalizability is the ability to predict results accurately out of sample.
Definition 2 Local generalizability is the ability to predict results accurately in a particular out-of-sample group.
Any empirical work, including this paper, will only be able to address local generalizability. However, I will argue we should not be concerned about this. First, the meta-analysis data were explicitly gathered using very broad inclusion criteria, aiming to capture the universe of studies. Second, by using a large set of studies in various contexts and repeatedly leaving out some of the studies when generating predictions, we can estimate the sensitivity of results to the inclusion of particular papers. In particular, as part of this paper I will systematically leave out one of the studies, predict it based on the other studies, and do this for each study, cycling through the stud-ies. As a robustness check I do this for different subsets of the data.
There are several ways to measure predictive power. Most measures of predictive power rely on building a model on a “training” data set and estimating the fit of that model on an out-of-sample “test” data set, or estimating on the same data set but with a correction. Gelman et al. (2013) provides a good summary. I will focus on one of these methods - cross-validation. In particular, I will use the predicted residual sum of squares (PRESS) statistic, which is closely related to the mean squared error and can also be used to generate anR2-like statistic. Specifically, to calculate it one follows this procedure:
1. Start at study i“1 within each intervention-outcome combination.
2. Generate the predicted value of effect sizeYi,Ypi, by building a model based onY´i, the effect sizes for all observations in that intervention-outcome except i. For example, regress Y´i “ α`βC´i`ε, whereCrepresents a predictor of interest, and then use the estimated coefficients to predictYpi. Alternatively, generate Ypi as the meta-analysis result from synthesizingY´i.
3. Calculate the squared error,pYi´Ypiq2.
4. Repeat for each i‰1.
5. Calculate PRESS“řnpYi´Ypiq2
To aid interpretation, I also calculate the PRESS statistic for placebo data in simulations. The models for predicting Yi are intentionally simple, as both economists and policymakers often do not build complicated models of the effect sizes when drawing inferences from past studies. First, I simply see if interventions, outcomes, intervention-outcomes, region or implementer have any explanatory power in predicting the resultant effect size. I also try using the meta-analysis result M´i, obtained from synthesizing the effect sizes Y´i, as the predictor of Yi. This makes intuitive sense; we are often in the situation of wanting to predict the effect size in a new context from a meta-analysis result.
When calculating the PRESS statistic, I correct the results for attenuation bias using a first-order approximation described in Gelman et al. (2013) and Tibshirani and Tibshirani (2009). Representing the cross-validation squared errorpYi´Ypiq2 as CV,biasy “CV´ĚCV.
While predictive power is perhaps the most natural measure of generalizability, I will also show results on how impact evaluation results correlate with each other. The difference between correlation and predictive power is clear: it is similar to the difference between an estimated coefficient and an R2. Impact evaluation results could be correlated so that regressing Yi on explanatory variables likeM´i could result in a large, significant coefficient on theM´i term while still having a low R2. Indeed, this is what we will see in the data.
2.3 Models Used in Meta-Analyses
This paper uses meta-analysis as a tool to synthesize evidence.
As a quick review, there are many steps in a meta-analysis, most of which have to do with the selection of the constituent papers. The search and screening of papers will be described in the data section; here, I merely discuss the theory behind how meta-analyses combine results.
One of two main statistical models underlie almost all meta-analyses: the fixed-effect model or the random-effects model. Fixed-effect models assume there is one true effect of a particular program and all differences between studies can be attributed simply to sampling error. In other words:
Yi “θ`εi (3)
whereθ is the true effect andεi is the error term.
Random-effects models do not make this assumption; the true effect could potentially vary from context to context. Here,
Yi “θi`εi (4)
“θ¯`ηi`εi (5)
where θi is the effect size for a particular study i, ¯θ is the mean true effect size, ηi is a particular study’s divergence from that mean true effect size, andεi is the error.
When estimating either a fixed effect or random effects model through meta-analysis, a choice must be made: how to weight the studies that serve as inputs to the meta-analysis. Several weighting schemes can be used, but by far the most common to use are inverse-variance weights. As the variance is a measure of how certain we are of the effect, this ensures that those results about which we are more confident get weighted more heavily. The variance will contain a between-studies term in the case of random effects. Writing the weights asW, the summary effect is simply:
M “
řk
i“1WiYi řk
i“1Wi
with standard error břk1 i“1Wi.
To build a hierarchical Bayesian model, I first assume the data are normally distributed:
Yij|θi„Npθi, σ2q (7)
where j indexes the individuals in the study. I do not have individual-level data, but instead can use sufficient statistics:
Yi|θi„Npθi, σi2q (8)
whereYi is the sample mean and σi2 the sample variance. This provides the likelihood forθi. I also need a prior for θi. I assume between-study normality:
θi „Npµ, τ2q (9)
whereµ andτ are unknown hyperparameters.
Conditioning on the distribution of the data, given by Equation 8, I get a posterior:
θi|µ, τ, Y „Npθˆi, Viq (10)
where
ˆ θi“
Yi σ2 i ` µ τ2 1 σi2 `
1 τ2
,Vi “ 1 1 σi2 `
1 τ2
(11)
I then need to pin down µ|τ and τ by constructing their posterior distributions given non-informative priors and updating based on the data. I assume a uniform prior for µ|τ, and as the Yi are estimates ofµwith variance pσi2`τ2q, obtain:
µ|τ, Y „Npµ, Vˆ µq (12)
where
ˆ µ“
ř iσ2Yi
i`τ2
ř i
1 σ2
i`τ2
,Vµ“ ÿ
i 1 1 σ2
i`τ2
For τ, note that ppτ|Yq “ ppppµµ,τ|τ,Y|Yqq. The denominator follows from Equation 12; for the numer-ator, we can observe that ppµ, τ|Yq is proportional to ppµ, τqppY|µ, τq, and we know the marginal distribution of Yi|µ, τ:
Yi|µ, τ „Npµ, σi2`τ2q (14)
I use a uniform prior for τ, following Gelman et al. (2005). This yields the posterior for the numerator:
ppµ, τ|Yq9ppµ, τq ź
i
NpYi|µ, σ2i `τ2q (15)
Putting together all the pieces in reverse order, I first simulate τ, then generate ppτ|Yq using τ, followed by µand finally θi.
Unless otherwise noted, I rely on this hierarchical Bayesian random effects model to generate meta-analysis results.
3
Data
This paper uses a database of impact evaluation results collected by AidGrade, a U.S. non-profit research institute that I founded in 2012. AidGrade focuses on gathering the results of impact eval-uations and analyzing the data, including through meta-analysis. Its data on impact evaluation results were collected in the course of its meta-analyses from 2012-2014 (AidGrade, 2015).
AidGrade’s meta-analyses follow the standard stages: (1) topic selection; (2) a search for rel-evant papers; (3) screening of papers; (4) data extraction; and (5) data analysis. In addition, it pays attention to (6) dissemination and (7) updating of results. Here, I will discuss the selection of papers (stages 1-3) and the data extraction protocol (stage 4); more detail is provided in Appendix B.
3.1 Selection of Papers
The interventions that were selected for meta-analysis were selected largely on the basis of there being a sufficient number of studies on that topic. Five AidGrade staff members each independently made a preliminary list of interventions for examination; the lists were then combined and searches done for each topic to determine if there were likely to be enough impact evaluations for a
meta-analysis. The remaining list was voted on by the general public online and partially randomized. Appendix B provides further detail.
A comprehensive literature search was done using a mix of the search aggregators SciVerse, Google Scholar, and EBSCO/PubMed. The online databases of J-PAL, IPA, CEGA and 3ie were also searched for completeness. Finally, the references of any existing systematic reviews or meta-analyses were collected.
Any impact evaluation which appeared to be on the intervention in question was included, barring those in developed countries.5 Any paper that tried to consider the counterfactual was considered an impact evaluation. Both published papers and working papers were included. The search and screening criteria were deliberately broad. There is not enough room to include the full text of the search terms and inclusion criteria for all 20 topics in this paper, but these are available in an online appendix as detailed in Appendix A.
3.2 Data Extraction
The subset of the data on which I am focusing is based on those papers that passed all screening stages in the meta-analyses. Again, the search and screening criteria were very broad and, after passing the full text screening, the vast majority of papers that were later excluded were excluded merely because they had no outcome variables in common or did not provide adequate data (for example, not providing data that could be used to calculate the standard error of an estimate, or for a variety of other quirky reasons, such as displaying results only graphically). The small overlap of outcome variables is a surprising and notable feature of the data. Ultimately, the data I draw upon for this paper consist of 14,993 results (double-coded and then reconciled by a third researcher) across 637 papers covering the 20 types of development program listed in Table 1.6 For sake of comparison, though the two organizations clearly do different things, at present time of writing this is more impact evaluations than J-PAL has published, concentrated in these 20 topics. Unfortu-nately, only 318 of these papers both overlapped in outcomes with another paper and were able to
5
High-income countries, according to the World Bank’s classification system.
6Three titles here may be misleading. “Mobile phone-based reminders” refers specifically to SMS or voice
re-minders for health-related outcomes. “Women’s empowerment programs” required an educational component to be included in the intervention and it could not be an unrelated intervention that merely disaggregated outcomes by gender. Finally, micronutrients were initially too loosely defined; this was narrowed down to focus on those providing zinc to children, but the other micronutrient papers are still included in the data, with a tag, as they may still be
be standardized and thus included in the main results which rely on intervention-outcome groups. Outcomes were defined under several rules of varying specificity, as will be discussed shortly.
Table 1: List of Development Programs Covered
2012 2013
Conditional cash transfers Contract teachers
Deworming Financial literacy training Improved stoves HIV education
Insecticide-treated bed nets Irrigation
Microfinance Micro health insurance
Safe water storage Micronutrient supplementation Scholarships Mobile phone-based reminders School meals Performance pay
Unconditional cash transfers Rural electrification
Water treatment Women’s empowerment programs
73 variables were coded for each paper. Additional topic-specific variables were coded for some sets of papers, such as the median and mean loan size for microfinance programs. This paper focuses on the variables held in common across the different topics. These include which method was used; if randomized, whether it was randomized by cluster; whether it was blinded; where it was (village, province, country - these were later geocoded in a separate process); what kind of institution carried out the implementation; characteristics of the population; and the duration of the intervention from the baseline to the midline or endline results, among others. A full set of variables and the coding manual is available online, as detailed in Appendix A.
As this paper pays particular attention to the program implementer, it is worth discussing how this variable was coded in more detail. There were several types of implementers that could be coded: governments, NGOs, private sector firms, and academics. There was also a code for “other” (primarily collaborations) or “unclear”. The vast majority of studies were implemented by academic research teams and NGOs. This paper considers NGOs and academic research teams together because it turned out to be practically difficult to distinguish between them in the studies, especially as the passive voice was frequently used (e.g. “X was done” without noting who did it). There were only a few private sector firms involved, so they are considered with the “other” category in this paper.
Studies tend to report results for multiple specifications. AidGrade focused on those results least likely to have been influenced by author choices: those with the fewest controls, apart from fixed effects. Where a study reported results using different methodologies, coders were instructed to collect the findings obtained under the authors’ preferred methodology; where the preferred methodology was unclear, coders were advised to follow the internal preference ordering of priori-tizing randomized controlled trials, followed by regression discontinuity designs and differences-in-differences, followed by matching, and to collect multiple sets of results when they were unclear on which to include. Where results were presented separately for multiple subgroups, coders were similarly advised to err on the side of caution and to collect both the aggregate results and results by subgroup except where the author appeared to be only including a subgroup because results were significant within that subgroup. For example, if an author reported results for children aged 8-15 and then also presented results for children aged 12-13, only the aggregate results would be recorded, but if the author presented results for children aged 8-9, 10-11, 12-13, and 14-15, all subgroups would be coded as well as the aggregate result when presented. Authors only rarely reported isolated subgroups, so this was not a major issue in practice.
When considering the variation of effect sizes within a group of papers, the definition of the group is clearly critical. Two different rules were initially used to define outcomes: a strict rule, under which only identical outcome variables are considered alike, and a loose rule, under which similar but distinct outcomes are grouped into clusters.
The precise coding rules were as follows:
1. We consider outcome A to be the same as outcome B under the “strict rule” if outcomes A and B measure the exact same quality. Different units may be used, pending conversion. The outcomes may cover different timespans (e.g. encompassing both outcomes over “the last month” and “the last week”). They may also cover different populations (e.g. children or adults). Examples: height; attendance rates.
2. We consider outcome A to be the same as outcome B under the “loose rule” if they do not meet the strict rule but are clearly related. Example: parasitemia greater than 4000/µl with fever and parasitemia greater than 2500/µl.
Clearly, even under the strict rule, differences between the studies may exist, however, using two different rules allows us to isolate the potential sources of variation, and other variables were coded to capture some of this variation, such as the age of those in the sample. If one were to divide the studies by these characteristics, however, the data would usually be too sparse for analysis.
Interventions were also defined separately and coders were also asked to write a short descrip-tion of the details of each program. Program names were recorded so as to identify those papers on the same program, such as the various evaluations of PROGRESA.
After coding, the data were then standardized to make results easier to interpret and so as not to overly weight those outcomes with larger scales. The typical way to compare results across different outcomes is by using the standardized mean difference, defined as:
SM D“ µ1´µ2 σp
where µ1 is the mean outcome in the treatment group, µ2 is the mean outcome in the control group, and σp is the pooled standard deviation. When data are not available to calculate the pooled standard deviation, it can be approximated by the standard deviation of the dependent variable for the entire distribution of observations or as the standard deviation in the control group (Glass, 1976). If that is not available either, due to standard deviations not having been reported in the original papers, one can use the typical standard deviation for the intervention-outcome. I follow this approach to calculate the standardized mean difference, which is then used as the effect size measure for the rest of the paper unless otherwise noted.
This paper uses the “strict” outcomes where available, but the “loose” outcomes where that would keep more data. For papers which were follow-ups of the same study, the most recent results were used for each outcome.
Finally, one paper appeared to misreport results, suggesting implausibly low values and standard deviations for hemoglobin. These results were excluded and the paper’s corresponding author contacted. Excluding this paper’s results, effect sizes range between -1.5 and 1.8 SD, with an interquartile range of 0 to 0.2 SD. So as to mitigate sensitivity to individual results, especially with the small number of papers in some intervention-outcome groups, I restrict attention to those standardized effect sizes less than 2 SD away from 0, dropping 1 additional observation. I report
main results including this observation in the Appendix.
3.3 Data Description
Figure 2 summarizes the distribution of studies covering the interventions and outcomes consid-ered in this paper. Attention will typically be limited to those intervention-outcome combinations on which we have data for at least three papers, with an alternative minimum of four papers in the Appendix.
Table 12 in Appendix C lists the interventions and outcomes and describes their results in a bit more detail, providing the distribution of significant and insignificant results. It should be empha-sized that the number of negative and significant, insignificant, and positive and significant results per intervention-outcome combination only provide ambiguous evidence of the typical efficacy of a particular type of intervention. Simply tallying the numbers in each category is known as “vote counting” and can yield misleading results if, for example, some studies are underpowered.
Table 2 further summarizes the distribution of papers across interventions and highlights the fact that papers exhibit very little overlap in terms of outcomes studied. This is consistent with the story of researchers each wanting to publish one of the first papers on a topic. We will indeed see that later papers on the same intervention-outcome combination more often remain as working papers.
A note must be made about combining data. When conducting a meta-analysis, the Cochrane Handbook for Systematic Reviews of Interventions recommends collapsing the data to one observa-tion per intervenobserva-tion-outcome-paper, and I do this for generating the within intervenobserva-tion-outcome meta-analyses (Higgins and Green, 2011). Where results had been reported for multiple subgroups (e.g. women and men), I aggregated them as in the Cochrane Handbook’s Table 7.7.a. Where results were reported for multiple time periods (e.g. 6 months after the intervention and 12 months after the intervention), I used the most comparable time periods across papers. When combining across multiple outcomes, which has limited use but will come up later in the paper, I used the formulae from Borenstein et al. (2009), Chapter 24.
Table 2: Descriptive Statistics: Distribution of Narrow Outcomes Intervention Number of Mean papers Max papers
outcomes per outcome per outcome
Conditional cash transfers 10 16 28
Contract teachers 1 3 3
Deworming 12 13 18
Financial literacy 1 5 5
HIV/AIDS Education 3 8 10
Improved stoves 4 2 2
Insecticide-treated bed nets 1 9 9
Irrigation 2 2 2
Micro health insurance 1 2 2
Microfinance 5 4 5
Micronutrient supplementation 23 27 47
Mobile phone-based reminders 2 4 5
Performance pay 1 3 3
Rural electrification 3 3 3
Safe water storage 1 2 2
Scholarships 3 2 2
School meals 3 3 3
Unconditional cash transfers 3 2 2
Water treatment 2 5 6
Women’s empowerment programs 2 2 2
Average 4.2 5.9 8.0
Table 3: Differences between vote counting and meta-analysis results Meta-analysis result
Negative Insignificant Positive Total Vote counting result and significant and significant
Negative 0 0 0 0
Insignificant 1 30 14 45
Positive 0 1 21 22
4
Generalizability of Impact Evaluation Results
4.1 Method
The first thing I do is to report basic summary statistics. I ask: given a positive, significant result - the kind perhaps most relevant for motivating policy - what proportion of papers on the same intervention-outcome combination find a positive, significant effect, an insignificant effect, or a negative, significant effect? How much do the results of vote counting and meta-analysis di-verge? Another key summary statistic is the coefficient of variation. This statistic is frequently used as a measure of dispersion of results and is defined as σµ, where µ is the mean of a set of results and σ the standard deviation.7 The set of results under consideration here is defined by the intervention-outcome combination; I also separately look at variation within papers. While the coefficient of variation is a basic statistic, this is the first time it is reported across a wide variety of impact evaluation results. Finally, I look at how much results overlap within intervention-outcome combinations, using the raw, unstandardized data.
I then regress the effect size on several explanatory variables, including the leave-one-out meta-analysis result for all but study i within each intervention-outcome combination, M´i. Whenever I use M´i to predict Yi, I adjust the estimates for sampling variance to avoid attenuation bias. I also cluster standard errors at the intervention-outcome level to guard against the case in which an outlier introduces systematic error within an intervention-outcome. While the main results are based on any intervention-outcome combination covered by at least three papers, as mentioned I try increasing this minimum number of papers in robustness checks that are included in the Appendix. Finally, I construct the PRESS statistic to measure generalizability, as discussed in Section 2.2. In order to be able to say whether the result is large or small, I also calculate an R2-like statistic for prediction and conduct simulations using placebo data for comparison. The R2-like statistic is theR2P r from prediction:
R2P r“1´PRESS SST ot
(16)
7
where SST ot is the total sum of squares. In the simulations, I randomly assign the real effect size data to alternative interventions, outcomes, or other variables and then generate the PRESS statistic and the predicted R2P r for these placebo groups.
4.2 Results
4.2.1 Summary statistics
Summary statistics provide a first look at how results vary across different papers.
The average intervention-outcome combination is comprised 37% of positive, significant results; 58% of insignificant results; and 5% of negative, significant results. To gauge how stable results are, suppose we know that one study in a particular intervention-outcome combination found a positive, significant result (the kind of result one might think could influence policy); drawing another study at random from the set, there is a 60% chance the new result will be insignificant and a 8% chance it will be significant and negative, leaving only about a 32% chance it will again be positive and significant.
The differences between meta-analysis results and vote counting results are shown in Table 3. Only those intervention-outcomes which had a vote counting “winner” are included in this table; in other words, it does not include ties. That the meta-analysis result was often positive and signifi-cant or negative and signifisignifi-cant when the vote counting result was insignifisignifi-cant is likely a function of many impact evaluations being underpowered.
In the methods section, I discussed the coefficient of variation, a measure of the dispersion of the impact evaluation findings. Values for the coefficient of variation in the medical literature tend to range from approximately 0.1 to 0.5. Figure 3 shows its distribution in the economics data, across papers within intervention-outcomes as well as within papers.
Each of the across-paper coefficients of variation was calculated within an intervention-outcome combination; for example, the effects of conditional cash transfer programs on enrollment rates. When a paper reports multiple results, the previously described conventions work to either select one of them or aggregate them so that there is one result per intervention-outcome-paper that is used to calculate the within-intervention-outcome, paper coefficient of variation. The
across-Figure 3: Distribution of the Coefficient of Variation
paper coefficient of variation is thus likely lower than it might otherwise be due to the aggregation process reducing noise.
The within-paper coefficients of variation are calculated where the data include multiple results from the same paper on the same intervention-outcome. There are several reasons a paper may have reported multiple results: multiple time periods were examined; the author used multiple methods; or results for different subgroups were collected. In each of these scenarios, the context is more similar than it typically is across different papers. Variation within a single paper due to different specifications and subgroups has often been neglected in the literature but constituted on average approximately 67% of the variation across papers within a single intervention-outcome combination. As Figure 3 makes clear, the coefficient of variation within the same paper within an intervention-outcome combination is much lower than that across papers. The mean coefficient of variation across papers in the same intervention-outcome combination is 1.9; the mean coefficient of variation for results within the same paper in the same intervention-outcome combination is lower, at 1.2, a difference that is significantly different in a t-test atpă0.05.8
The coefficient of variation clearly depends on the set of results being considered. Outcomes were extremely narrowly defined, as discussed; interventions varied more. For example, a school meals program might disburse different kinds of meals in one study than in another. The con-texts also varied, such as in terms of the implementing agency, the age group, the underlying rates 8All these results are based on truncating the coefficient of variation at 10 as in Figure 3; if one does so at 20,
of malnutrition, and so on. The data are mostly too sparse to use this information, however, a few papers considered the same programs; the average coefficient of variation within the same intervention-outcome-program combination, across papers, was 1.5.
To aid in interpreting the results, I return to the unstandardized values within intervention-outcome combinations. I ask: what is the typical gap between a study’s point estimate and the average point estimate within that intervention-outcome combination? How often do the confidence intervals around an estimated effect size overlap within intervention-outcomes?
Table 4 presents some results, excluding risk ratios and rate ratios, which are on different scales. The mean absolute difference between a study’s point estimate and the average point estimate within that intervention-outcome combination is about 90%. Regarding the confidence intervals, a given result in an intervention-outcome combination will, on average, have a confi-dence interval that overlaps with about 85% of the conficonfi-dence intervals of the other results in that intervention-outcome. The point estimate will be contained in the confidence interval of the other studies approximately half of the time.
4.2.2 Regression results
Do results exhibit any systematic variation? This section examines whether generalizability is associated with study characteristics such as the type of program implementer.
I first present some OLS results. As Table 5 indicates, there is some evidence that studies with a smaller number of observations have greater effect sizes than studies based on a larger number of observations. This is what we would expect if specification searching were easier for small datasets; this pattern of results would also be what we would expect if power calculations drove researchers to only proceed with studies with small sample sizes if they believed the program would result in a large effect size or if larger studies are less well-targeted. Interestingly, government-implemented programs fare worse even controlling for sample size (the dummy variable category left out is “Other-implemented”, which mainly consists of collaborations and private sector-implemented in-terventions). Studies in the Middle East / North Africa region may appear to do slightly better than those in Sub-Saharan Africa (the excluded region category), but not much weight should be put on this as very few studies were conducted in the former region.
on the RHS of the regression that is fit; for example, the first row uses the fitted Ypi from regress-ingYi“α`řnβnInterventionin`εi whereIntervention comprises dummy variables indicating different interventions. The PRESS statistic and R2P r from each regression of Y on assorted C is listed, along with the average PRESS statistic andR2P rfrom the corresponding placebo simulations. It should be noted that, unlike R2,R2P r need not have a lower bound of zero. This is because the predicted residual sum of squares, which is by definition greater than the residual sum of squares, can also be greater than the total sum of squares. The p-value gives how likely it is the PRESS statistic is from the distribution of simulation PRESS statistics, using the standard deviation from the simulations.9 As Table 6 shows, one can distinguish the interventions, outcomes, intervention-outcomes, and regions in the data better than chance. The implementer dummy does not have significant predictive power here.
One might believe the relatively poor predictive power is due to too many diverse interventions and outcomes being grouped together. I therefore separate out the two interventions with the largest number of studies, CCTs and deworming, to see if patterns are any different within each of these interventions.
Results are weaker here (Table 7). While this could partially due to reduced sample sizes, it also suggests that there are many different sources of heterogeneity in the data.
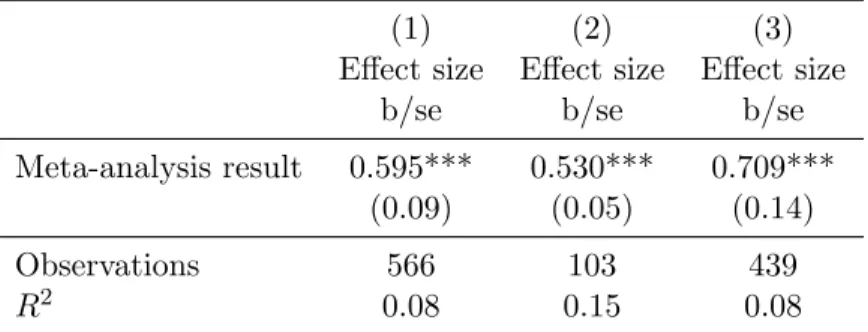
Table 8 presents more PRESS statistics, this time using the leave-one-out meta-analysis result from within intervention-outcome combinations to predict the result left out. The significance of the meta-analysis results is striking compared to that of the earlier results, but the lowR2P r should be noted.
The regressions in Table 9 show some of the key takeaways of this paper in an easily digested format. The relationship between the PRESS statistics and a regression model can also be seen by comparing Tables 8 and 9. In both cases, the meta-analysis result is a significant predictor of the effect size, but the R2 or RP r2 is also low in both tables. Table 9 also suggests that government-implemented programs do not fare as well on average.
9
Table 4: Differences in Point Estimates
Intervention Outcome Mean estimate Mean difference Units
Conditional Cash Transfers Attendance rate 0.07 0.03 percentage points Conditional Cash Transfers Birth in a medical facility 0.07 0.06 percentage points Conditional Cash Transfers Enrollment rate 0.08 0.06 percentage points Conditional Cash Transfers Height 0.99 0.03 cm
Conditional Cash Transfers Height-for-age -0.01 0.17 z-score
Conditional Cash Transfers Labor force participation -0.03 0.03 percentage points Conditional Cash Transfers Labor hours -1.99 1.64 hours/week Conditional Cash Transfers Pregnancy rate -0.03 0.04 percentage points Conditional Cash Transfers Probability skilled attendant at delivery 0.12 0.06 percentage points Conditional Cash Transfers Probability unpaid work -0.06 0.07 percentage points Conditional Cash Transfers Retention rate -0.01 0.01 percentage points Conditional Cash Transfers Test scores 0.06 0.09 standard deviations Conditional Cash Transfers Unpaid labor hours -1.51 0.97 hours/week Conditional Cash Transfers Weight-for-age 0.19 0.25 z-score Conditional Cash Transfers Weight-for-height 0.12 0.09 z-score
Contract Teachers Test scores 0.18 0.06 standard deviations Deworming Attendance rate 0.03 0.02 percentage points
Deworming Birthweight 0.00 0.01 kg
Deworming Height 0.09 0.28 cm
Deworming Height-for-age 0.16 0.21 z-score
Deworming Hemoglobin 0.06 0.11 g/dL
Deworming Malformations 0.05 0.05 percentage points Deworming Mid-upper arm circumference 0.08 0.22 cm
Deworming Test scores 0.08 0.03 standard deviations
Deworming Weight 0.14 0.25 kg
Deworming Weight-for-age 0.14 0.21 z-score Deworming Weight-for-height 0.09 0.18 z-score
Financial Literacy Has savings 0.02 0.01 percentage points Financial Literacy Probability has taken loan 0.03 0.05 percentage points Financial Literacy Savings -17.40 67.18 current US$ HIV/AIDS Education Pregnancy rate -0.01 0.01 percentage points HIV/AIDS Education Probability has multiple sex partners 0.23 0.22 percentage points HIV/AIDS Education Probability sexually active -0.02 0.02 percentage points HIV/AIDS Education STD prevalence 0.09 0.10 percentage points HIV/AIDS Education Used contraceptives 0.04 0.07 percentage points Irrigation Consumption 838.55 887.56 current US$ Irrigation Total income -6.20 89.13 current US$ Micro Health Insurance Household health expenditures 0.17 0.18 current US$ Micro Health Insurance Probability of inpatient visit 0.00 0.01 percentage points Micro Health Insurance Probability of outpatient visit 0.00 0.03 percentage points
Microfinance Assets 21.81 79.83 current US$ Microfinance Consumption -3.52 4.27 current US$ Microfinance Probability of owning business 0.05 0.03 percentage points Microfinance Profits -14.41 55.06 current US$ Microfinance Savings 41.06 56.02 current US$ Microfinance Total income 23.54 18.20 current US$
Micronutrients Height 0.07 0.36 cm
Micronutrients Height-for-age 0.06 0.11 z-score
Micronutrients Hemoglobin 0.08 0.30 g/dL
Micronutrients Mid-upper arm circumference 0.04 0.11 cm
Micronutrients Test scores 0.01 0.11 standard deviations
Micronutrients Weight 0.09 0.13 kg
Micronutrients Weight-for-age 0.05 0.09 z-score Micronutrients Weight-for-height 0.03 0.08 z-score
Performance Pay Test scores 0.13 0.06 standard deviations Rural Electrification Enrollment rate 0.08 0.01 percentage points Rural Electrification Study time 1.10 0.88 hours/week Rural Electrification Total income 42.46 42.23 current US$ Scholarships Attendance rate 0.01 0.00 percentage points Scholarships Enrollment rate 0.01 0.00 percentage points Scholarships Test scores 0.11 0.08 standard deviations School Meals Enrollment rate 0.11 0.10 percentage points School Meals Height-for-age 0.15 0.06 z-score
School Meals Test scores 0.12 0.12 standard deviations Unconditional Cash Transfers Enrollment rate 0.12 0.12 percentage points Unconditional Cash Transfers Test scores 0.06 0.02 standard deviations Unconditional Cash Transfers Weight-for-height 0.02 0.04 z-score
Women’s Empowerment Savings 24.16 21.69 current US$ Women’s Empowerment Total income 6.83 1.04 current US$
Table 5: Regression of Effect Size on Study Characteristics
(1) (2) (3) (4) (5)
Effect size Effect size Effect size Effect size Effect size
b/se b/se b/se b/se b/se
Number of -0.018*** -0.019*** -0.015**
observations (100,000s) (0.01) (0.00) (0.01)
Government-implemented -0.163*** -0.150**
(0.06) (0.06)
Academic/NGO-implemented -0.070 -0.075
(0.04) (0.05)
RCT 0.049
(0.04)
East Asia -0.015
(0.03)
Latin America -0.006
(0.04)
Middle East/North 0.284**
Africa (0.11)
South Asia 0.009
(0.04)
Constant 0.120*** 0.199*** 0.080*** 0.114*** 0.201*** (0.00) (0.04) (0.03) (0.02) (0.04)
Observations 534 634 634 534 534
R2 0.19 0.23 0.22 0.22 0.20
Table 6: PRESS statistics andR2P r: All interventions
C dummies P RESS P RESSSim p-value RP r2 R2P rSim R2P r-R2P rSim Intervention 46.1 47.2 0.063 -0.01 -0.03 0.02
Outcome 45.6 49 <0.001 0.01 -0.07 0.07
Intervention & Outcome 46 49.9 <0.001 0.00 -0.09 0.09
Region 45.5 46 0.021 0.00 -0.01 0.01
Implementer 46.3 46.4 0.764 -0.01 -0.01 0.00
One may be concerned that low-quality papers are either inflating or depressing the degree of generalizability that is observed. There are infinitely many ways to measure paper “quality”; I consider two. First, I consider only those papers that were randomized controlled trials. Sec-ond, I use the most widely-used quality assessment measure, the Jadad scale (Jadad et al., 1996). The Jadad scale asks whether the study was randomized, double-blind, and whether there was a description of withdrawals and dropouts. A paper gets one point for having each of these
charac-Table 7: Within-intervention PRESS statistics and R2P r CCTs
C dummies P RESS P RESSSim p-value R2P r R2P rSim R2P r-R2P rSim Outcome 6.9 7.1 0.676 -0.09 -0.12 0.03
Region 6.5 6.8 0.215 -0.02 -0.07 0.05
Implementer 6.6 6.6 0.762 -0.04 -0.04 0.00 Deworming
C dummies P RESS P RESSSim p-value R2P r R2P rSim R2P r-R2P rSim Outcome 10.7 10.8 0.924 -0.05 -0.06 0.01 Region 10.4 10.5 0.309 -0.02 -0.03 0.01 Implementer 10.4 10.5 0.543 -0.02 -0.03 0.01
Table 8: PRESS statistics and R2P r using Within-Intervention-Outcome Meta-Analysis Results to Predict Estimates from Different Implementers
Meta-Analysis Result P RESS P RESSSim p-value R2P r R2P rSim R2P r-R2P rSim M (on full sample) 41.9 46 <0.001 0.09 0.00 0.09 M (on govt only) 9.3 9.9 0.028 0.02 -0.04 0.06 M (on acad/NGO only) 32.4 35.7 <0.001 0.09 -0.01 0.09
teristics; in addition, a point is added if the method of randomization was appropriate, subtracted if the method is inappropriate, and similarly added if the blinding method was appropriate and subtracted if inappropriate. This results in a 0-5 point scale. Given that the kinds of interventions being tested are not typically readily suited to blinding, I consider all those papers scoring at least a 3 to be “high quality”. Tables 13 and 14 in the Appendix provide robustness checks using these two quality measures. Table 15 also considers those intervention-outcome combinations with at least four papers; Table 16 includes the one observation previously dropped for having an effect size more than 2 SD away from 0; in Table 17, I use a fixed effect meta-analysis to create the leave-one-out meta-analysis results.
To illustrate the mechanics more clearly, Figures 4 and 5 show the density of results according to a hierarchical Bayesian model with an uninformative prior.10 Figure 4 shows the results within one intervention-outcome combination: conditional cash transfers and enrollment rates. The dark dots correspond to the aggregated estimates of the government versions of the interventions; the light, the academic/NGO versions. The still lighter dots found in figures in the Appendix
repre-10
Table 9: Regression of Effect Size on Hierarchical Bayesian Meta-Analysis Results
(1) (2) (3)
Effect size Effect size Effect size
b/se b/se b/se
Meta-analysis result 0.595*** 0.530*** 0.709*** (0.09) (0.05) (0.14)
Observations 566 103 439
R2 0.08 0.15 0.08
The meta-analysis result in the table above was created by synthesizing all but one observation within an intervention-outcome combination; that one observation left out is on the left hand side in the regression. All interventions and outcomes are included in the regression, clustering by intervention-outcome. Column (1) shows the results on the full data set; column (2) shows the results for those effect sizes pertaining to programs implemented by the government; column (3) shows the results for academic/NGO-implemented programs.
sent those papers with “other” implementers (collaborations or private sector implementers). The dashed black line shows the overall weighted mean.
The two panels on the right side of Figure 4 give the weighted distribution of effects according to a hierarchical Bayesian model. In the first panel, all intervention-implementer pairs are pooled; in the second, they are disaggregated. This figure graphically depicts what a meta-analysis does. We can make a similar figure for each of the 48 intervention-outcome combinations on which we have sufficient papers (available online; for details, see Appendix A).
To summarize results further, we may want to aggregate up to the intervention-implementer level. Figure 5 shows the effects if the meta-analysis were to aggregate across outcomes within an intervention-implementer as if they were independent. This figure is based on only those in-terventions that have been attempted by both a government agency and an academic team or NGO.
The standard errors here are exceptionally small for a reason: each dot has aggregated all the results of all the different papers and outcomes under that intervention-implementer. Every time one aggregates in this fashion, even if one assumes that the multiple observations are correlated and corrects for this, the standard errors will decrease. The standard errors are thus more indicative of how much data I have on those particular programs - not much, for example, in the case of academic/NGO-implemented unconditional cash transfers.
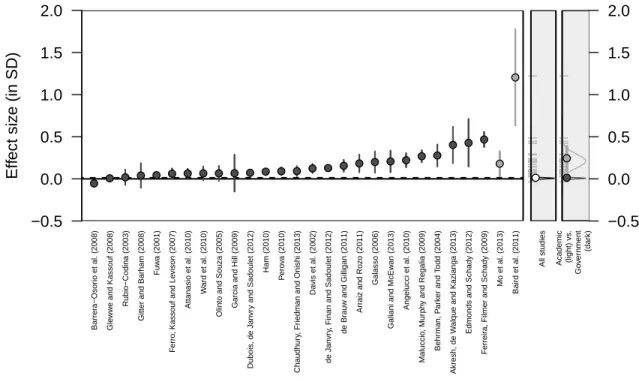
Figure 4: Example of Hierarchical Bayesian Meta-Analysis Results: Conditional Cash Transfers and Enrollment Rates
Eff
ect siz
e (in SD)
−0.5 0.0 0.5 1.0 1.5 2.0 −0.5 0.0 0.5 1.0 1.5 2.0 Barrer a−Osor
io et al. (2008)
Gle
ww
e and Kassouf (2008) Rubio−Codina (2003)
Gitter and Barham (2008)
Fuw
a (2001)
F
erro
, Kassouf and Le
vison (2007)
Attanasio et al. (2010)
W
ard et al. (2010)
Olinto and Souza (2005)
Garcia and Hill (2009)
Dubois
, de J
an
vr
y and Sadoulet (2012)
Ham (2010) P ero v a (2010) Chaudhur y, Fr
iedman and Onishi (2013)
Da
vis et al. (2002)
de J
an
vr
y, Finan and Sadoulet (2012) de Br auw and Gilligan (2011) Arr
aiz and Roz
o (2011)
Galasso (2006)
Galiani and McEw
an (2013)
Angelucci et al. (2010)
Maluccio
, Mur
ph
y and Regalia (2009)
Behr
man, P
ar
k
er and T
odd (2004)
Akresh, de W
alque and Kazianga (2013)
Edmonds and Schady (2012)
F
erreir
a, Filmer and Schady (2009)
Mo et al. (2013)
Baird et al. (2011)
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
All studies−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
Academic (light) vs
. Go v er nment (dar k)
This figure provides the point estimate and confidence interval for each paper’s estimated effect of a conditional cash transfer program (intervention) on enrollment rates (outcome). The first grey box on the right hand side of the figure shows the aggregate distribution of results using the hierarchical Bayesian procedure, and the second grey box farther to the right shows the distributions for the government-implemented and academic/NGO-implemented studies separately. Government-implemented programs are denoted by dark grey, while
academic/NGO-implemented studies are in lighter grey. The even lighter dots in other figures found in the Appendix represent those papers with “other” implementers (collaborations or private sector implementers). The data have been converted to standard deviations for later comparison with other outcomes. Conventions were followed to isolate one result per paper. These are detailed in the Appendix and in the online coding manual, but the main criteria were to use the result with the fewest controls; if results for multiple time periods were presented, the time period closest to those examined in other papers in the same intervention-outcome was selected; if results for multiple subgroups were presented, such as different age ranges, results were aggregated as these data were typically too sparse to do subgroup analyses. Thus, the data have already been slightly aggregated in this figure.
the outcomes are not comparable. Still, unless one expects a systematic bias affecting government-implemented programs differently vis-a-vis academic/NGO-government-implemented programs, it is clear that the distribution of the programs’ effects looks quite different, and the academic/NGO-implemented programs routinely exhibit higher effect sizes than their government-implemented counterparts. Figure 5 also illustrates the limitations of meta-analyses: while the academic/NGO-implemented
Figure 5: Government- and Academic/NGO- Implemented Projects Differ Within the Same Inter-ventions
Eff
ect siz
e (in SD)
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 −1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
Conditional cash tr
ansf
ers
Contr
act teachers De
w or ming Financial liter acy HIV/AIDS Education Microfinance Micron utr ient supplementation P erf or mance pa y School meals
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
All studies−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
Academic (light) vs
. Go v er nment (dar k)
This figure focuses only on those interventions for which there were both government-implemented and academic/NGO-implemented studies. All outcomes and papers are aggregated within each
intervention-implementer combination. While it appears that the academic/NGO-implemented studies do better overall, the higher weighting of some of the better government-implemented interventions (in particular, conditional cash transfer programs, which tend to have very large sample sizes) disguises this. This figure both illustrates that academic/NGO-implemented programs seem to do better than government-implemented programs and shows why caution must be taken in interpreting results.
studies do better overall, the higher weighting of some of the better government-implemented interventions hides this in the results in the side panel. This again points to the fact that what one is aggregating over and the weighting scheme used is important.
5
Specification searching and publication bias
Results on generalizability could be biased in the presence of specification searching and publi-cation bias. In particular, if studies are systematically biased, they could speciously appear to be more generalizable. In this section, I examine these issues. First, I test for specification searching and publication bias, finding that these biases are quite limited in my data, especially among ran-domized controlled trials. I then suggest a mathematical correction that could be applied, much in
the spirit of Simonsohnet al.’s p-curve (2014), which looks at the distribution of p-values one would expect given a true effect size. I run some simulations that show that my mathematical correction would recover the correct distribution of effect sizes. However, since that approach depends on a key assumption that there is one true effect size and all deviations are noise, and one might want to weaken that assumption, I show how one might do that. Finally, I restrict attention to just the subset of studies that had been RCTs, as I showed they did not appear subject to the same biases, and repeat the earlier analyses.
5.1 Specification searching: how bad is it?
5.1.1 Method
To examine the issue of specification searching, I start by conducting a series of caliper tests, following Gerber and Malhotra (2008a). As they describe (2008b), even if results are naturally concentrated in a given range, one should expect to see roughly comparable numbers of results just on either side of any threshold when restricting attention to a narrow enough band. I consider the ranges 2.5%, 5%, 10%, 15% and 20% above and below z=1.96, in turn, and examine whether results follow a binomial distribution around 1.96 as one would expect in the absence of bias. I do these tests on the full data set - here there is no need to consider only those results for intervention-outcome combinations covered by a certain number of papers, for example - but then also break it down in several ways, such as by RCT or non-RCT and government-implemented or non-government-implemented.
When doing this kind of analysis, one should also carefully consider the issues arising from having multiple coefficients coming from the same papers. Gerber and Malhotra (2008a; 2008b) address the issue by breaking down their results by the number of coefficients contributed by each paper, so as to separately show the results for those papers that contribute one coefficient, two coefficients, and so on. I also do this, but in addition use the common statistical method of aggregating the results by paper, so that, for example, a paper with four coefficients below the threshold and three above it would be counted as “below”. The approach followed in Gerber and Malhotra (2008a; 2008b) retains slightly different information. While it preserves the number of coefficients on either side of the threshold, it does not reduce the bias that may be present if one
or two of the papers are responsible for much of the effect. By presenting a set of results collapsed by paper, I can test if results are sensitive to this.
5.1.2 Results
I begin by simply plotting the distribution of z-statistics in the data for different groups. The distributions, shown in Figure 6, are consistent with specification searching, particularly for government-implemented programs and non-RCTs: while noise remains, mostly from using multi-ple results from the same study, which tend to be clustered, there appears to be a bit of a deviation from the downward trend around 1.96, the threshold for statistical significance at the 5% level for a two-sided test. These are “de-rounded” figures, accounting for the fact that papers may have pre-sented results which were imprecise; for example, specifying a point estimate of 0.03 and a standard error of 0.01. Since these results would artificially cause spikes in the distribution, I re-drew their z-statistics from the uniform range of possible results (00..025015 ´00..03505), as in Brodeuret al. (2012).
Figure 6: Distribution of z-statistics
This figure shows histograms of the z-statistics, by implementer and whether the result was from an RCT. A jump around 1.96, the threshold for significance at the 5% level, would suggest that authors were wittingly or unwittingly selecting significant results for inclusion.
Table 10: Caliper Tests: By Result
Over Caliper Under Caliper p-value All studies
2.5% Caliper 119 92 <0.10 5% Caliper 190 176
10% Caliper 353 357 15% Caliper 519 526 20% Caliper 675 706 RCTs
2.5% Caliper 79 74 5% Caliper 123 135 10% Caliper 253 274 15% Caliper 376 404 20% Caliper 498 543 Non-RCTs
2.5% Caliper 40 18 <0.01
5% Caliper 67 41 <0.05
10% Caliper 100 83 15% Caliper 143 122 20% Caliper 177 163
Table 11: Caliper Tests: By Paper
Over Caliper Under Caliper p-value All studies
2.5% Caliper 54 43
5% Caliper 71 71
10% Caliper 81 101 15% Caliper 100 119 20% Caliper 104 129 RCTs
2.5% Caliper 35 36
5% Caliper 51 57
10% Caliper 59 80 <0.10 15% Caliper 71 91
20% Caliper 72 96 <0.10 Non-RCTs
2.5% Caliper 19 7 <0.05
5% Caliper 20 14
10% Caliper 22 21 15% Caliper 29 28 20% Caliper 32 33
Overall, these figures look much better than the typical ones in the literature. I designed AidGrade’s coding conventions partially to minimize bias,11which could help explain the difference. The government z-statistics are perhaps the most interesting. While they may reflect noise rather than bias, it would be intuitive for governments to exert pressure over their evaluators to find significant, positive effects. Suppose there are two ways of obtaining a significant effect size: putting effort into the intervention (such as increasing inputs) or putting effort into leaning on the evaluators. For large-scale projects, it would seem much more efficient to target the evaluator. While this story would be consistent with the observed evidence, many other explanations remain possible.
Turning to the caliper tests, I still find little evidence of bias (Tables 10 and 11). For the caliper tests, I use the raw rather than de-rounded data, as de-rounding could mask subtle jumps at z=1.96. Whether considering results independently or collapsed by paper, non-RCTs appear to suffer from bias, but RCTs perform much better. It should be recalled that as the distribution of the z-statistics is skewed, we should expect to see fewer results just over as opposed to just under the threshold for significance for a wide enough band, which is indeed what we see for RCTs. The results, especially for RCTs, mark a great difference from Gerber and Malhotra’s results on the political science (2008a) or sociology (2008b) literature. I reproduce one of their tables in the Appendix to illustrate (Table 19), as the difference between my results and their row of mostly pă0.001 results is striking.
5.2 Publication bias
Turning to publication bias, published impact evaluations are more likely to have significant findings than working papers, as we can see in Table 12. RCTs are also greatly selected for publi-cation. However, once controlling for whether a study is an RCT, publication bias is reduced.
As discussed, an attempt was made to be very comprehensive in the data gathering process, and both published and unpublished papers were searched for and included. I can therefore re-run the main regressions separately for published and unpublished papers (Table 18 in the Appendix). Results are fairly similar. The coefficient on the meta-analysis term is marginally not significant