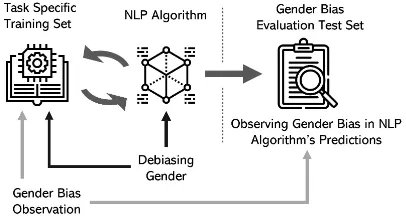
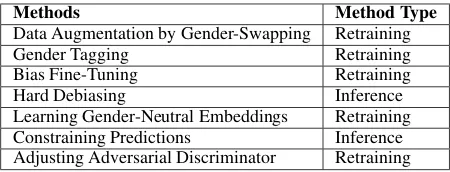
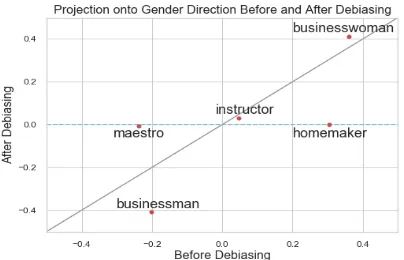
Mitigating Gender Bias in Natural Language Processing: Literature Review
Full text
Figure


Related documents
*Services obtained with an approved prior authorization shall be covered at the in-network level.. This is only
Graduate Courses at Eastern University (Department) Leadership (School of Management Studies)?. Business Ethics (School of
This paper evaluates the usability and effectiveness of runtime systems based on the Sequential Task Flow model for complex ap- plications, namely, sparse matrix
According to Finnish Accounting Act, the acquirer is obligated to amortize goodwill during its economic useful life (20 years at maximum). Under IFRS, companies are no longer
CMOS processes have been steadily improving for more than 20 years and will con- tinue to do so for at least the next decade. A good designer not only should be familiar with
S: Appropriate market costs for parking fees, citations and rates will ensure turnover in downtown and increase available parking for citizens and employees.. S: Appropriate
Tenure: As mentioned in the introduction to this section, with respect to 0-5 years of tenure, we find 6-12 years of tenure ( tenure2 ) to be statistically significant (at least
