An Effective Method to Predict Air Pollutants using
Random Forest Algorithm
Miss. Vadaka Keerthi1, Mrs. Kavitha Juliet2
Abstract: The interpolation, prediction, and feature analysis of fine-gained air quality are three important topics in the area of urban air computing. A good interpolation solves the problem that there are limited air-quality-monitor-stations whose distribution is uneven in a city; a precise prediction provides valuable information to protect humans from being damaged by air pollution; a reasonable feature analysis reveals the main relevant factors to the variation of air quality. In general, the solutions to these topics can extract extremely useful information to support air pollution control, and consequently generate great societal and technical impacts.
Keywords: Air pollution, Random Forest Algorithm, Interpolation, Prediction, Feature analysis.
I. INTRODUCTION
The interpolation, prediction and characteristic analysis of excellent grained air exceptional are three predominant matters in the location of city air computing. A desirable interpolation solves the trouble that there are constrained air satisfactory display stations whose distribution is uneven in a city; a particular prediction presents precious information to protect humans from being damaged by using air pollution; a sensible characteristic evaluation exhibits the fundamental applicable elements to the variant of air quality. In general, the options to these matters can extract extraordinarily useful records to assist air pollution control and for this reason generate fantastic societal and technical impact. However, there exist several challenges for city air computing as the associated statistics have some distinct characteristics. First, for the reason that there are inadequate air satisfactory monitor stations in a metropolis due to the excessive cost of building and keeping such a station, it is high-priced to reap labelled training samples when dealing with nice grained air quality. Second, the labelled records of the air high-quality display stations are incomplete and there exist lots of missing labels of the historical data in some time intervals for some stations. The reason for the incomplete labels is associated to the air satisfactory reveal devices. Third, kinds of urban air associated information are a number of for the improvement of statistics acquisition technologies. However, there is now not an universally widely wide-spread judgement to reveal the fundamental causes of the prevalence and dissipation of air pollution, specially the air pollution of PM2.5. Hence, it is tough to comprehend that what sorts of information are the main applicable points for interpolation, prediction and the key elements for surroundings departments to prevent and manage air pollution. This assignment is inspired to address all these challenges via using the information contained in the unlabelled information and the spatiotemporal data, and performing function resolution records and affiliation evaluation for the urban air associated data. Though labelled records are challenging or costly to obtain, massive amount of unlabelled examples can be regularly be gathered cheaply. In general, unlabelled statistics can assist in imparting statistics to higher exploit the geometric shape of the data. Moreover, most of the city air related records include both space and time information. Most of the present works remedy the troubles of interpolation, prediction and function analysis of best grained air pleasant one at a time by using extraordinary models. In this project, we propose a widely wide-spread and positive strategy to remedy the three issues in one model called Deep Air Learning (DAL), which addresses all the challenges that exist in the area of air computing simultaneously by a deep studying network.
II. RELATED WORK
2) “Spatiotemporal Interpolation Methods for Air Pollution”- This paper investigates spatiotemporal interpolation strategies for the application of air pollution assessment. The air pollutant of pastime in this paper is pleasant particulate be counted PM2.5. The choice of the time scale is investigated when applying the structure function-based method. It is observed that the size scale of the time dimension has an influence on the interpolation results. Based upon the comparison between the accuracies of interpolation results, the most tremendous time scale out of 4 experimental ones used to be chosen for performing the PM2.5 interpolation. The paper additionally evaluates the populace exposure to the ambient air pollution of PM2.5 at the county-level in the contiguous U.S. in 2009. The interpolated county-level PM2.5 has been linked to 2009 population statistics and the population with a volatile PM2.5 publicity has been estimated. The risky PM2.5 publicity capability the PM2.5 concentration exceeding the National Ambient Air Quality Standards. The geographic distribution of the counties with a risky PM2.5 exposure is visualized. This work is critical to perception the associations between ambient air pollution exposure and populace fitness outcomes.
3) “U-Air: When Urban Air Quality Inference Meets Big Data”- Information about city air quality, e.g., the attention of PM2.5, is of magnificent importance to protect human fitness and control air pollution. While there are constrained air-quality-monitor-stations in a city, air exceptional varies in city spaces non-linearly and relies upon on more than one factor, such as meteorology, traffic volume, and land uses. In this paper, we infer the real-time and pleasant grained air best statistics in the course of a city, based totally on the (historical and real-time) air satisfactory information mentioned by present screen stations and a range of facts sources we found in the city, such as meteorology, visitors flow, human mobility, shape of avenue networks, and factor of interests (POIs). We propose a semi-supervised mastering method based on a co-training framework that consists of two separated classifiers. One is a spatial classifier primarily based on an artificial neural network (ANN), which takes spatially-related features (e.g., the density of POIs and size of highways) as enter to model the spatial correlation between air characteristics of one of a kind locations. The different is a temporal classifier based totally on a linear-chain conditional random discipline (CRF), involving temporally-related features (e.g., visitors and meteorology) to mannequin the temporal dependency of air fine in a location. We evaluated our approach with enormous experiments based on five real statistics sources received in Beijing and Shanghai. The outcomes exhibit the blessings of our approach over 4 categories of baselines, such as linear/Gaussian interpolations, classical dispersion models, time-honoured classification models like choice tree and CRF, and ANN.
4) “Inferring Air Quality for Station Location Recommendation Based on Urban Big Data”- This paper tries to answer two questions. First, how to infer actual time air first-class of any arbitrary vicinity given environmental data from very sparse monitoring locations. Second, if one wishes to set up few new screen stations to enhance the inference quality, how to decide the fine locations for such purpose? The troubles are difficult in view that for most of the areas (>99%) we do now not have any air-quality information to educate a model from. We format a semi-supervised inference model utilizing existing monitoring statistics together with heterogeneous city dynamics, such as meteorology, human mobility, structure of avenue networks, and point of pastimes (POIs). We also propose an entropy-minimization model to endorse the exceptional areas to establish new monitoring stations. We consider the proposed method the usage of Beijing air satisfactory data, ensuing in clear advantages over a sequence of modern day and in many instances used methods.
III. SYSTEM ARCHITECTURE
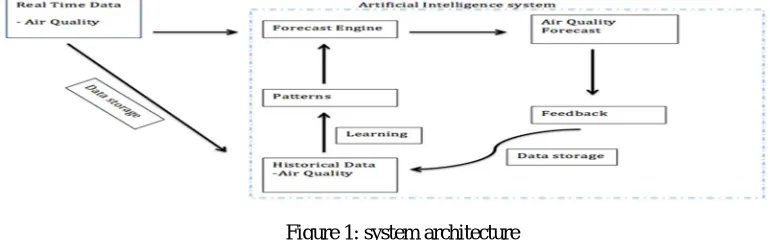
[image:2.612.105.490.595.715.2]A machine architecture format would be used to exhibit the relationship between exceptional components. Usually they are created for structures which encompass hardware and software program and these are represented in the diagram to show the interaction between them.
Figure 1: system architecture
A. Python
Python is a popular platform used for research and improvement of manufacturing systems. It is an enormous language with quantity of modules, programs and libraries that gives multiple ways of attaining a task.
Python and its libraries like NumPy, SciPy, Scikit-Learn, Matplotlib are used in records science and statistics analysis. They are also considerably used for growing scalable machine studying algorithms. Python implements famous machine studying strategies such as Classification, Regression, Recommendation, and Clustering. Python provides ready-made framework for performing facts mining duties on massive volumes of records correctly in lesser time. It includes a number of implementations performed through algorithms such as linear regression, logistic regression, Naïve Bayes, k-means, K nearest neighbour, and Random Forest.
Python is a high-level, interpreted, interactive and object-oriented scripting language. Python is designed to be extraordinarily readable. It makes use of English keywords frequently the place as other languages use punctuation, and it has fewer syntactical constructions than other languages.
1) Python is Interpreted − Python is processed at runtime via the interpreter. You do no longer need to bring together your software earlier than executing it. This is comparable to PERL and PHP.
2) Python is Interactive − you can actually sit at a Python instantaneous and engage with the interpreter at once to write your programs.
3) Python is Object-Oriented − Python supports Object-Oriented style or technique of programming that encapsulates code within objects.
4) Python is a Beginner's Language − Python is a outstanding language for the beginner-level programmers and supports the improvement of a wide range of applications from simple text processing to WWW browsers to games.
B. Machine Learning
Data science, machine learning and artificial intelligence are some of the top trending matters in the tech world today. Data mining and Bayesian analysis are trending and this is including the demand for computer learning. This tutorial is your entry into the world of computer learning.
Machine getting to know is a self-discipline that deals with programming the systems so as to make them routinely learn and improve with experience. Here, studying implies recognizing and perception the enter records and taking knowledgeable decisions based totally on the furnished data. It is very difficult to consider all the decisions based on all viable inputs. To solve this problem, algorithms are developed that build expertise from a precise information and past trip by means of making use of the standards of statistical science, probability, logic, mathematical optimization, reinforcement learning, and manage theory.
1) Steps Involved in Machine Learning: A machine getting to know project involves the following steps:
a) Defining a Problem
b) Preparing Data
c) Evaluating Algorithms
d) Improving Results
e) Presenting Results
The high-quality way to get started the usage of Python for computer gaining knowledge of is to work through a mission end-to-end and cowl the key steps like loading data, summarizing data, evaluating algorithms and making some predictions. This offers you a replicable technique that can be used dataset after dataset. You can additionally add similarly data and enhance the results.
V. ALGORITHM
A. Random Forest Algorithm
Random forests are an aggregate of tree predictors such that each tree relies upon on the values of a random vector sampled independently and with the identical distribution for all trees in the forest. The generalization error for forests converges to restrict as the variety of bushes in the wooded area will become large.
popular class. In order to grow these ensembles, often random vectors are generated that govern the growth of every tree in the ensemble.
An early example is bagging (Breiman, 1996), where to grow every tree a random selection (without replacement) is made from the examples in the education set. Another example is random cut up selection (Dietterich, 1998) the place at each node the split is chosen at random from amongst the K fine splits. Breiman (1999) generates new training sets by way of randomizing the outputs in the unique education set.
Another approach is to select the training set from a random set of weights on the examples in the coaching set. Ho (1998) has written a variety of papers on “the random subspace” method which does a random selection of a subset of facets to use to develop each tree. In an vital paper on written personality recognition, Amit and Geman (1997) define a massive wide variety of geometric points and search over a random determination of these for the best split at each node. This latter paper has been influential in my thinking.
The frequent element in all of these procedures is that for the kth tree, a random vector k is generated, independent of the previous
random vectors 1,...,k−1 however with the same distribution; and a tree is grown the use of the coaching set and k , ensuing in a
classifier h(x,k) the place x is an input vector.
For instance, in bagging the random vector is generated as the counts in N bins ensuing from N darts thrown at random at the boxes, where N is quantity of examples in the coaching set.
In random break up selection consists of a number of unbiased random integers between 1 and K. The nature and dimensionality of depends on its use in tree construction. After a large range of timber is generated, they vote for the most popular class. We call these methods random forests.
B. Definition
A random woodland is a classifier consisting of a series of tree-structured classifiers {h(x,k ), ok = 1, . . .} the place the {k} are impartial identically distributed random vectors and each tree casts a unit vote for the most popular class at input x.
VI. CONCLUSION
This paper researches three vital matters in the vicinity of urban air computing: the interpolation, prediction, and feature analysis of fine-gained air quality. The solutions to these topics can supply indispensable data to guide air pollution control, and consequently generate awesome societal and technical impacts.
Most current efforts focal point on fixing the three issues one by one with the aid of setting up different models. In this project, we improve a everyday and superb approach called DAL to unify the interpolation, prediction, feature selection and evaluation of the fine-grained air pleasant into one model. In order to improve the performance of interpolation and prediction, we utilize the intrinsic traits of the spatio-temporal facts and the records contained in the unlabeled records by means of embedding spatio-temporal semi supervised learning on the output layer of neural network.
We additionally suggest a novel approach to function selection in the input layer of neural network, whose optimization is easy to clear up and performance is nicely in eliminating the redundant or beside the point features. Combining with feature selection, association analysis discovers the significance of different input elements to the predictions of the neural networks. The proposed characteristic choice and analysis method has the capacity to expose some internal mechanism of the black box deep network models. Extensive experiments are conducted on real records sources showing that DAL is ultimate to the contrast opponents when solving the matters of interpolation, prediction, and feature analysis of fine-gained air quality.
REFERENCES
[1] Journal of the Royal Statistical Society. Series B (Methodological), vol. 58, no. 1, pp. 267–288, 1996.
[2] M. Yuan and Y. Lin, “Model selection and estimation in regression with grouped variables,” Journal of the Royal Statistical Society: Series B (Statistical Methodology), vol. 68, pp. 49–67, 2006.
[3] L. Li, X. Zhang, J. Holt, J. Tian, and R. Piltner, “Spatiotemporal interpolation methods for air pollution exposure,” in Symposium on Abstraction, Reformulation, and Approximation, 2011.
[4] Y. Zheng, F. Liu, and H.-P. Hsieh, “U-air: When urban air quality inference meets big data,” in Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’13, 2013, pp. 1436–1444.
[5] H.-P. Hsieh, S.-D. Lin, and Y. Zheng, “Inferring air quality for station location recommendation based on urban big data,” in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’15, 2015, pp. 437– 446.
[7] S. Thomas and R. B. Jacko, “Model for forecasting expressway pm2.5 concentration – application of regression and neural network models.” Journal of the Air & Waste Management Association, vol. 57, no. 4, pp. 480–488, 2007.
[8] Y. Zheng, X. Yi, M. Li, R. Li, Z. Shan, E. Chang, and T. Li, “Forecasting fine-grained air quality based on big data,” in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’15, 2015.
[9] X. Zhou, W. Huang, N. Zhang, W. Hu, S. Du, G. Song, and K. Xie, “Probabilistic dynamic causal model for temporal data,” in Neural Networks (IJCNN), 2015 International Joint Conference on, July 2015, pp. 1–8.
[10] K. P. Singh, S. Gupta, and P. Rai, “Identifying pollution sources and predicting urban air quality using ensemble learning methods,” Atmospheric Environment, vol. 80, pp. 426 – 437, 2013.