3936
Semantic Prefetching Based Hybrid Prediction
Model
Sonia Setia, Jyoti, Neelam Duhan
Abstract: Web prefetching is one of the significant techniques used to alleviate the rendering latency perceived by users. Various researchers have supported the concept of Web prefetching in many forms by providing numerous methods that have increased the speed of web page delivery, but delays still are incurred because they lack in the relevancy of the results. Prefetching technique could be improved by analyzing the semantics of content enhanced with domain ontology. In view of this, a Semantic Prefetching System has been proposed that makes use of both the usage data and the semantics of the content information to predict the user‘s behavior. Web content is semantically annotated with ontology terms. Semantic Weighted Log Records are introduced which contains the knowledge derived from the ontology and thesaurus, thereby allowing semantically focused set of prediction to be achieved.
Index Terms: Access Logs, Bipartite Graph, Clustering, Content, Ontology, Prediction, Prefetching, Semantic.
—————————— ——————————
1
I
NTRODUCTIONWith the continuous growth of the World Wide Web, users are experiencing access delays. They don‘t want to wait for more than few seconds. One solution is to increase the bandwidth, but this will increase the system cost. Another solution is Prefetching, which could alleviate the latency to a large extent without increasing much cost. Prefetching is defined as to fetch the web objects in advance before a request for that is made. Prefetching techniques take advantage of the spatial locality of Web Objects. Generally, a user navigates by following the hyperlinks between Web objects. That is, if object A is having a hyperlink to object B, the probability of accessing B will be increased significantly, given object A has been already accessed. Hence, if we predict and prefetch those objects which are expected to be referenced in the client‘s succeeding requests, network latency can be reduced significantly. This means the performance of a prefetching scheme mainly depends on the accuracy of the prediction algorithm. The majority of the prediction algorithms, in literature, are based upon the usage data which is available in user‘s access Logs which includes the types of activities done on the site such as user‘s id, clicked item, IP address, date and time etc. Usage-based approaches cannot make accurate predictions when there is not enough usage data or when content changes or new pages are added to the web site which are not in Access Logs. The content information and the structure of the website overcome such kind of problems [1]. In this area, several prediction methods pertaining to Web Content Mining have been proposed in literature which uses content information of web pages. These may include URLs content, abstracts, titles, and anchor texts, to describe the web pages. However, information received from such content is not necessarily a good and sufficient representation that could predict user‘s behavior in an effective manner. Therefore, it can lead to inaccurate prediction.
On the other side, prediction techniques pertaining to structure mining totally relies on the structure of the website. Poorly designed website may degrade the performance of the prediction algorithm. Therefore, structure mining also is not much useful for prediction. Due to the problems associated with these three approaches, there is a need of prediction algorithm which can take advantage of them while eliminating their drawbacks. This paper shows how content information and usage data can be used efficiently to overcome the issues pertaining to the existing approaches. Content information in the form of user‘s perspective in the form of queries is incorporated with web usage data in the form of Access Logs for making prediction which yields Semantic Prefetching Based Hybrid Prediction Model (SPHPM). The highlights of the proposed system are as follows:
1. This framework explores the content information of web pages from a new perspective in the form of queries that users searched to describe the URL pages that users clicked.
2. The proposed work makes use of bipartite graph technique to establish the relationship between the queries and the URLs contained in the access logs. The graph is then parsed and keywords are extracted from the queries, which are used to characterize web pages according to user‘s interest.
3. To make predictions for user‘s queries, instead of searching the complete set of URLs in Access Logs, Clustering can be applied on access Logs so that Cluster set of similar kind of URLs can be obtained. Then, best matched cluster with the user‘s given query can be used for making prediction. Applying the clustering on the access logs imposes the need for using a limited vocabulary to characterize the content in uniform way.
4. This prerequisite leads to the introduction of Semantic Weighted Log Records in our proposed work. These logs replace the traditional logs. To create semantic weighted log records, keywords that were extracted using bipartite graph technique are mapped to the ontology categories, which results in a uniform and limited set of vocabulary belonging to ontology as required by the clustering process. These semantically annotated clusters are then used for making predictions for users‘ queries.
In this way, the system's predictions can be enriched with
————————————————
• Sonia Setia, Computer Science, YMCA, Faridabad, India. Email: [email protected]
• Jyoti, Computer Science, YMCA, Faridabad, India. Email: [email protected]
3937 content having similar semantics.
Thus, the amalgamation of the usage data and content information to form the SPHPM resolves the problems associated with the individual approaches in the following ways:
1. Users‘ perspective is better caught with the help of queries provided by the user and establishing their relationship with those present in the access logs. Access Logs have been enhanced to Semantic Weighted Log Records to capture the semantics of the content by using Ontology and Thesaurus. This way, it enables the system to predict documents not only based on keyword matching but on semantic similarity. Thereby resulting in the broader set of more relevant predictions for users.
The remainder of the paper is organized as follows. In Section 2, recent research in the area of web mining and web prefetching is discussed. In Section 3, proposed architecture is presented in more detail. A running example is also given, that illustrates how the content is employed to enhance the prediction process. Conclusion is presented in Section 4.
2
R
ELATEDW
ORKWeb prefetching is a task to predict and fetch the next web page before user demands, based on their browsing history. Researchers have been focusing their work on improving the browsing experience for users by working on the relevancy of prediction of web pages. This work discusses various techniques and methods which have been used in developing web page‘s predictions. Among them, few of methods have been listed here which are categorized under three categories of web mining.
2.1 Prediction Algorithms based on Web Usage Mining Markov model is one of the web usage mining technique. The basic concept is to predict the next action of user, depending on the user‘s previous actions. Researchers have implemented this technique successfully in literature predicting user‘s behavior in future. Deshpande et al. [2] examined that high accuracy in the prediction of user‘s next action can be accomplished by using higher-order Markov models but due to its large number of states, method becomes very complex. Therefore, to reduce its space complexity, authors used to follow three techniques, i.e. frequency-pruning, error-pruning and support-pruning. Tak Yan et al. [3] proposed one of the Web usage mining system. Authors discovered clusters of users that exhibit similar behavior, by observing user access logs. Links are suggested dynamically to the user based in which category that user falls. The clustering approach used is affected by several limitations such as scalability and effectiveness of the results found. Bamshad Mobasher et. al. [4] proposed a system for dynamic recommendations as a list of hypertext links to users. The method was based on usage data and Website structure. F. Masseglia et al. [5] presented an integrated system called as WebTool. It was based on sequential patterns and association rules to dynamically customize the hypertext organization. In this paper [5], current user's behavior was compared to previously induced sequential patterns and resulted navigational hints were provided to the user. Bamshed Mobasher et al. [6] presented an approach based on association rule discovery and usage data-based clustering to capture common user profiles. The extracted knowledge has been used to provide
recommendations to users. The approach suggested only visited pages, but it was unable to suggest those pages which were not visited by users. Ranieri Baraglia et al. proposed a usage mining system called as SUGGEST. It was designed to dynamically generate personalized content of user‘s interest. Dimitrios Pierrakos et al. [7] proposed a method based on Web usage mining technique to identify communities of users that exhibit similar kind of navigational behavior. The information generated by the system can be used by administrator to improve the structure of Web site, or it can be used by personalization module to generate recommendations. B. Zhou et al. [8] proposed Sequential Web Access-based Recommender System (SWARS) that used sequential access pattern mining to find frequent sequential Web access patterns. The Pattern-tree was constructed from Web access patterns and which was used to generate recommendations. José Borges et al. [9] presented a Variable Length Markov Chain (VLMC), extension of a Markov chain which captured variable length history to provide better prediction accuracy while monitoring the number of states of the model. Lu et al. [10] proposed a new model based on Significant Usage Pattern (SUP). It integrated the Markov model with other data mining techniques like clustering, association rule etc. to improve the accuracy. In the first phase, authors applied Needleman-Wunsch global alignment algorithm to clickstream data for similarity computation between each pair of sessions which results in similarity matrix and then made clusters of sessions according to their similarities. In the second phase, abstracted web sessions using a concept-based abstraction approach and further first order Markov model was applied to each cluster.
2.2 Prediction Algorithms Based on Web Content Mining On the other hand, P. Venketesh et. al. [11] proposed a content-based prefetching technique which used anchor texts present in the web page for predictions. In this algorithm, ‗keyword extractor‘ extracted hyperlinks with the associated anchor texts. When a hyperlink was clicked by a user, ‗keyword extractor‘ kept the associated keywords into ‗user token repository‘. User token repository collected keywords with their count, i.e., the number of times that particular keyword is present in the hyperlink clicked by the user. In that, probability of each link was computed by applying Naïve Bayes classifier on the anchor text with reference to keywords stored in user token repository. These links with higher probabilities have been selected for prefetching. Further, Nguyen et. al. [12] also proposed a semantically enhanced method for receiving more accurate Web-page. In this, a number of queries have been developed to predict users‘ behavior. In this paper, experimental results show that this method provides an improved performance with higher accuracy than the traditional web usage mining-based methods. Further, Hu et. al. [13] proposed a scalable location prediction framework for predicting web pages. In this work, authors introduced a new concept of ‗term location vectors‘, to develop an automatic approach, also to see the importance of each term location vector for location prediction.
3938 of basically two types: ―Explicit Link Analysis‖ and ―Implicit Link
Analysis‖. Hyperlinks present on the web page are called as Explicit links. It has been proved by Davison that hyperlink information can help a lot in web search. Web designers designs the structure of the links and embeds the links in the website. Therefore, in case of ―Explicit link analysis‖ technique, user follows the design that was structured by the website designer who is responsible for making any web page important e.g. Kleinberg‘s HITS [15]. However, in ―Implicit link analysis‖ technique the importance of web page is not determined by the webpage designer but it is done by the users who are accessing that web page. More the number of users accessing the web page, more important the page is. Whenever a user accesses a web page, an implicit link is developed between the user and the corresponding web page. Further, pages are visited by the user in sequential manner, forming implicit links one after another. So, in the later case, web page is important from the user point of view. An example of Implicit Link Analysis approach is DirectHit [16]. This paper [14] used both the techniques i.e. ―Explicit link analysis‖ and ―Implicit link analysis‖ and determined the importance of web page by considering both the structure of the website and the frequency of users accessing the web page. Sonia et al. [17] proposed an approach which exploited the semantic association between tokens and semantic relation between web pages to prioritize the links. This method put the requirement for the designer to explicitly embed the semantic information with each link to describe the relation between two linked web pages. This semantic information is added during the designing of the web site. Various semantic relations were explained which are as follows:
1. Sequential relation (seq): The pages are in sequence i.e. one after another.
2. Similar relation (sim): The content of the pages are almost similar.
3. Cause-effective relation (ce): One web page is cause of another web page and the other one is its effects. 4. Implication relation (imp): The content of one web page
implies the other web page.
5. Subtype relation (st): One web page is part of another web page.
6. Instance relation (ins): A web page is instance of another web page.
7. Reference relation (ref): One web page is further explanation of another web page.
A critical look at the literature highlights the following areas of improvements:
1. Almost all these prediction algorithms use only the historical access data stored in Web access logs in order to predict future requests. Insufficient log data is a main source of inaccuracies for predictions. These access logs need to be improvised to improve the predictions for web pages.
2. Prediction models based on content mining techniques generally are focused on the anchor text of URLs to make predictions that might contain either a single token or anchor texts may even be missing. This may negatively impact the predictions. In other approaches, the whole page is scanned for either extracting the content in the form of abstracts or hyperlinks etc. This is also an inefficient approach as lot of computational time is involved.
3. Structure based prefetching techniques may degrade the performance in case of poorly designed website.
Also, almost of the prediction algorithms in literature increase the network traffic due to two main reasons:
1. Prefetched objects not used. 2. The extra information interchanged.
This in turn wastes the network bandwidth. To resolve these problems, a Semantic Prefetching based Hybrid Prediction Model is proposed in this work which utilizes both usage information and the content information in an effective way to achieve high accuracy of prediction.
3 P
ROPOSEDA
RCHITECTUREIn this section we present the architecture of Semantic Prefetching based Hybrid Prediction Model that integrates the semantics of content in the form of user‘s given query and hierarchical taxonomy (ontology) with web usage data. The need for such a system is depicted using a running example in the following subsection.
3.1 Motivating Example
Traditional history-based Prefetching systems that typically employ the data mining approaches like association rule mining etc, matches the user‘s navigational behavior with the antecedent of the rules, and then the consequent of the rules are prefetched. In order to demonstrate the need for semantic prefetching, we introduce an example. Consider an imaginary site www.sportstrip.com that is specialized in sports. Assuming association rule mining is applied and one of the many rules based on the access logs discovered is of the form as:
R:www.sportstrip.com/sport/skate.html, www.sportstrip.com/travel/skate_hotel.html --> www.sportstrip.com/training/skate.html.
Now, Table 1 presents the various URLs related to the website www. sportstrip.com
Table 1: Web pages of imaginary web portal
www.sportstrip.com
URL ID URL
URL1 www.sportstrip.com/affairs/skate.html
URL2 www.sportstrip.com /travel/skate_hotel.html URL3 www.sportstrip.com /training/skate.html URL4 www.sportstrip.com /sports/skate.html
URL5 www.sportstrip.com /wintersports/ice-skate.html URL6 www.sportstrip.com /sale/skateboard.html URL7 www.sportstrip.com /wintersports/skiing.html URL8 www.sportstrip.com /sports/tennis.html URL9 www.sportstrip.com /sale/tennisracket.html URL10 www.sportstrip.com /sale/skiboots.html
URL11 www.sportstrip.com
/atmospheric_cond/tennisracket.html URL12 www.sportstrip.com /sports/tennis/rules.html URL13 www.sportstrip.com /training/tennis.html
3939 This generally occurs when web page is new or it did not
appear in frequent rules mined by applying the association rules. Similarly, the web pages like
1. www.sportstrip.com/affairs/skate.html 2. www.sportstrip.com/travel/hotels.html
These are semantically similar to the one that is presented in the rule R. However, the system will not provide the same result to the user, since it does not identify the similarity between these URLs. To overcome this shortcoming, this paper is an effort to propose a framework that can provide the best of both the web usage data as well as the web content data that can be either from the keywords provided by the user or the anchor text related to the URL or any other related web object. The proposed framework will apply the various Data mining techniques in order to design the Semantic Web Prefetching system that would result in the Hybrid Model.
3.2 Semantic Prefetching-Based Hybrid Prediction Model From the example presented in last subsection, it is observed that if a prefetching system relies only on usage-based data, then few links may be missed which might be of most value to the user. To resolve this problem, a prefetching system has been developed which is based on semantics of the Access logs and the related content. Broadly, the SPHPM model will work in two phases as shown:
3.2.1 Offline phase
Firstly, it takes Access Logs as input and extracts the queries that describe a web page with respect to user‘s perspective and its corresponding URL. The extraction of the queries and URLs from the access logs results into a bipartite graph which then is parsed to the divide the queries into the keywords. Weights are then assigned to each keyword for a URL based on the clicks of that URL for that specific keyword. Next, these keywords are mapped to the terms of a predefined domain-specific taxonomy by using a thesaurus like Wordnet, which creates the Semantic Weighted Log Records. Semantic Weighted Log Records are same as the Processed Access logs, except it includes the ontology terms and weights, assigned to them. Data mining techniques, such as clustering are then applied on the Semantic Weighted Log Records which results in a set of clusters of URLs based on their corresponding ontology terms. These clusters are then used to enhance the prediction list for the user‘s given query.
3.2.2 Online phase
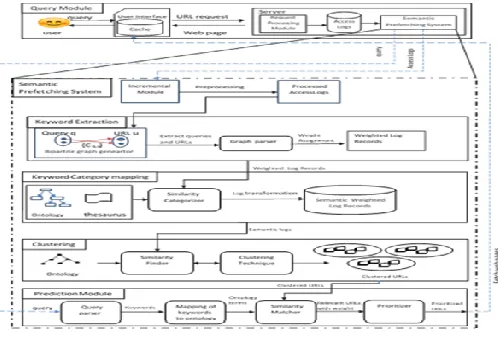
The user enters the query in the search interface. The query is then looked into the cache. If available in cache, the corresponding web page is returned. Else, the query is passed to the Server for fulfilling the user‘s request. Meanwhile, the same query is also fed to the Prefetching Module of SPHPM. This module will parse the query to the keywords which are then mapped to the corresponding ontology terms. These terms will then be fed to the similarity matcher along with the Clustered URLs which were calculated during the Offline phase. The output of this Similarity Matcher is the List of Relevant URLs which is then prioritized basis the weights received along with the List. The framework of SPHPM is shown in Fig.1.
3.3 Framework for Semantic Prefetching Hybrid Prediction Model
Semantic prefetching system sits inside the server. Initially, it takes Access Logs as input to build the prediction model. Its incremental module runs periodically to consider the updated logs. Only the fragment of new entries is considered on each run of incremental module. Its various components are described as follows:
3.3.1 Keyword Extraction Module
In order to extract keywords characterizing each Web Page, Access Logs are first preprocessed resulting in Processed Access Log records. This data is used as input for keyword extraction as shown in Fig. 1.
The log contains an entry for each request to the server by client. Each entry of the user‘s access logs is used to extract the query and corresponding clicked URL. The aggregated user‘s click between the Query and the URL are then calculated and represented through Bipartite Graph. Furthermore, the query‘s clicks reflect the users‘ confidence in the query i.e. how much close the queries are connected with the clicked URLs. Next, Graph parser parses the queries into keywords and weights are assigned to each keyword (belonging to query) for a URL based on the clicks of the URL for a specific query which results in Weighted Log records. Those Web Pages also which may be exempted by traditional systems due to any of the reasons discussed above. Based on the example presented in Table 1, the keywords describing the URLs are included in Table 2. Weights are not shown here in example because weights are only considered to prioritize the URLs which are best matched to the query. But here, our main motive is to show that our Semantic Prefetching system considers.
Fig. 1. System architecture
Table2. Keywords corresponding to URLs of www.sportstrip.com
URLs Keywords
www.sportstrip.com/affairs/skate.html Affairs, skate, sports /travel/skate_hotel.html Travel, skate, hotel
/training/skate.html Training, tutorial, sports, skate
/sports/skate.html Sports, skate
/wintersports/ice-skate.html Winter, sports, snow, ice-skate
3940
/wintersports/skiing.html Winter, sports, skiing, ice
/sports/tennis.html Sports, tennis /sale/tennisracket.html Sale, tennis, racket
/sale/skiboots.html Sale, sports, ski, skiboots
/atmospheric_cond/tennisracket.html Atmospheric condition, snow condition /sports/tennis/rules.html Sports, tennis rules /training/tennis.html Sports, training, tennis
3.3.2 Keyword-Category Mapping Module
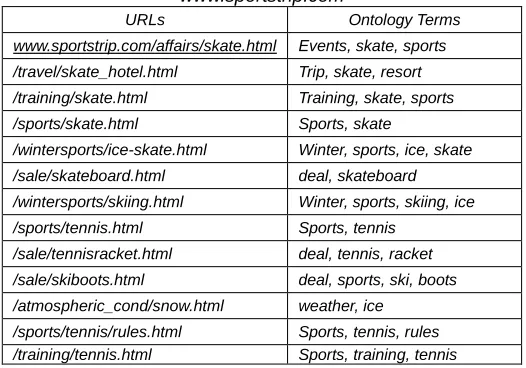
The keywords that are extracted using the above said method are the representatives of URLs. Now, Similarity Categorizer maps these keywords to the ontology categories by using a domain-specific taxonomy and a thesaurus like wordnet as shown in Fig. 1. If the taxonomy contains that keyword, then the keyword is included as it is. Otherwise, SPS finds the best match to the keyword by using the thesaurus. Now, each URL is categorized by a set of categories which are a part of taxonomy. This process is performed offline. Now, each entry of Weighted Log Records is enriched with terms that are a part of taxonomy. Finally, the output of this module will be the Semantic Weighted Log Records which resembles to the Processed Access logs and will be further processed in the same way. The ontology terms characterizing the URLs included in Table 2 are presented in Table 3.
Table 3. Categories characterizing the web pages of www.sportstrip.com
URLs Ontology Terms www.sportstrip.com/affairs/skate.html Events, skate, sports /travel/skate_hotel.html Trip, skate, resort /training/skate.html Training, skate, sports /sports/skate.html Sports, skate
/wintersports/ice-skate.html Winter, sports, ice, skate /sale/skateboard.html deal, skateboard /wintersports/skiing.html Winter, sports, skiing, ice /sports/tennis.html Sports, tennis
/sale/tennisracket.html deal, tennis, racket /sale/skiboots.html deal, sports, ski, boots /atmospheric_cond/snow.html weather, ice
/sports/tennis/rules.html Sports, tennis, rules /training/tennis.html Sports, training, tennis
3.3.3 Clustering Module
This module takes Semantic Weighted Log Records as input. Similarity Finder finds the similarity between the URLs based on their category terms which characterize them. To compute the similarity between categories, a similarity measure is used which is based on semantic proximity between sets of terms of ontology. Next, Clustering technique makes clusters of URLs based on their similarity values. The clusters which are created capture semantic relationships. These clusters of URLs are subsequently used to predict the user‘s behavior more accurately. For the given example, after applying the clustering technique to the web pages contained in the imaginary web portal, the URLs included in Table 3 are classified into three clusters based on their ontology terms.
C1: {/affairs/skate.html, /travel/skate_hotel.html,
/sports/skate.html, /training/skate.html, /sale/skateboard.html}
C2: {/wintersports/ice-skate.html, /wintersports/skiing.html,
/sale/skiboots.html
/atmospheric_cond/snow.html} C3: {/sports/tennis.html, /sale/tennisracket.html, /sports/tennisrules.html, /training/tennis.html}
3.3.4 Prediction Module
The clusters that were created in the above said module will be exploited to predict user‘s behavior, in a semantic way. User enters a query according to his interest which goes to the server through using HTTP GET method. Server responds with the list of URLs corresponding to respective query as shown in Query Module in Fig. 1. While user is viewing the current page, Prediction Module use this query for further processing so that it can predict the pages which are going to be clicked in near future. Firstly, query parser parses the query into keywords. Next, keywords corresponding to that query are mapped to a set of ontology categories. Now, query is enriched with ontology terms. Subsequently, the best match cluster is identified by computing the similarity between query and the clusters. Then, only the relevant cluster is exploited to answer the query. System computes the similarity of query to each URL only in that cluster. The output is the prioritized URLs based on their similarity to query. Corresponding web pages are fetched and stored in cache so that next user‘s request can be fulfilled through cache. Let‘s take an example, user provides query q= ‗skating hotel‘. Keywords corresponding to the given query are k= {skates, hotel} which are mapped to ontology terms ‗t‘= {skates, resort} correspondingly. Now, for the query enriched with ontology terms, best match cluster is found by computing similarity between query and clusters which is cluster C1 for the taken query example. Now, only the URLs in cluster C1 are exploited to find the relevant URLs corresponding to the given query. After computing the similarity between query and URLs in cluster C1, prioritized URLs are retrieved as depicted in Fig. 2.
Fig.2. Running example for user given query
In the proposed architecture, instead of simply extracting a set of rules including URLs, it outputs a broad set of URLs that are characterized by the thematic terms that seem to be of users‘
interest. This process considers those URLs that wouldn‘t be proposed otherwise. As mentioned earlier, a relevant page can be exempted from the prediction list if it was not visited before. For example, for the query related to skate would consider all
3941 cluster based on the similarity which is C1 in this case.
Therefore, based on the above analysis, the initial output list (as mentioned above in example in section 3.1) of URLs i.e. www.sportstrip.com /training/skate.html} is expanded include the URLs in the cluster C1 which may be important for query. Thus, the proposed architecture provides broad set of prediction list by exploring the semantics of content information and usage data. Therefore, increases the accuracy of prediction model which means prefetched objects are used by the user in their subsequent requests and network bandwidth is properly utilized.
4
C
ONCLUSIONIn this paper, Semantic Prefetching System has been proposed that integrates the Web usage mining with semantics of the query terms in order to provide accurate prediction corresponding to user‘s query. The salient feature of this work is enhancing of the access logs to Semantic Weighted Log Records, which contains semantics of the content provided by the user in the form of the query. Semantic Weighted Log Records are enriched with ontology categories which are further clustered to provide the prediction list by the Prefetching Module against the user‘s query based on the relevant cluster corresponding to query. The mapping of Access logs to Semantic Weighted Log Records is performed using a domain ontology and thesaurus. This categorization makes clustering more computational effective. Thus, it results in a broader set of prediction which is not only based on the original URLs, but also on the semantic categories related to them.
5
R
EFERENCES[1] Xu, C. Z.; Ibrahim, T I. (2004). A Keyword-Based Semantic Prefetching Approach in Internet News Service, Journal of IEEE Transactions on Knowledge and Data Engineering, Vol. 16, Issue 5.
[2] Deshpande M.; Karypis G. (2004). Selective Markov Models for Predicting Web Page Accesses, ACM transactions on Internet Technology, vol. 4, No. 2, pp. 163-184.
[3] Yan T. W., et al. (1996). From User Access Patterns to Dynamic Hypertext Linking, Computer Networks and ISDN Systems, vol. 28, no. (7–11), pp. 1007–1014. [4] Mobasher B., et al. (2000). Automatic personalization
based on Web usage mining, Communications of the ACM, vol. 43, no. 8, pp. 142–151.
[5] Masseglia F., et al. (1999). WebTool: An Integrated Framework for Data Mining, in Proceedings of the 9th International Conference on Database and Expert Systems Applications (DEXA'99), Florence, Italy, pp. 892-901.
[6] Mobasher B., et al. (1999). Creating Adaptive Web Sites Through Usage-Based Clustering of URLs, in Proceedings of the 1999 IEEE Knowledge and Data Engineering Exchange Workshop (KDEX'99).
[7] Baraglia R.; Silvestri F. (2004). An online recommender system for large Web sites, in Proceedings of the IEEE/WIC/ACM international conference on Web, Beijing, China.
[8] Pierrakos D, et al. (2001). KOINOTITES:A Web Usage Mining Tool for Personalization, in Proceedings of the Panhellenic Conference on Human Computer Interaction.
[9] Zhou B., et al. (2004). An intelligent recommender system using sequential Web access patterns, in IEEE conference on cybernetics and intelligent systems, pp. 393–398.
[10] Lu L., et al. (2005). Discovery of significant usage patterns from clusters of clickstream data, WebKDD '05, ACM, pp. 139-142.
[11] Venketesh P. (2010). Semantic Web Prefetching Scheme Using Naïve Bayes Classifier, International Journal of ComputerScience and Applications, vol. 7, no. 1, pp. 66 – 78.
[12] Nguyen T. T. S., et al. (2014). Web-Page Recommendation Based on Web Usage and Domain Knowledge, IEEE Transactions on Knowledge And Data Engineering, Vol. 26, No. 10.
[13] Hu Y., et al. (2017). Large-scale Location Prediction for Web Pages, IEEE Transactions on Knowledge and Data Engineering, Vol.29, No. 9.
[14] Chen Z., et al. (2003). A unified framework for Web link analysis.
[15] Kleinberg J. (1998). Authoritative sources in a hyperlinked environment, in: Proc. of the 9th ACM-SIAM Symposium on Discrete Algorithms.