40 | International Journal of Computer Systems, ISSN-(2394-1065), Vol. 06, Issue 03, July, 2019
Implementation of Heart Disease Prediction System using Data Mining
Technique
Samradhi Mittal, Prof. Shraddha Kumar Department Computer Science and Engineering Sushila DeviBansal College of Technology Indore,
Madhya Pradesh, India
Abstract
The data mining and it’s techniques are enable us to use the historical examples to predict the upcoming events. That kind of techniques is known as the predictive data modeling. The proposed work is an application of predictive data mining system. The risk of heart disease is increases much frequently. The increase rate of heart disease requires understanding the patterns. In this context the proposed study is focused on heart disease prediction system. In this context a data mining based techniques is proposed. The proposed technique involves the use of association rules for predicting the heart disease risk. Thus first a data is collected for experimentation and system design. The obtained dataset contains the attributes and the class labels as the prediction outcome. This dataset is first preprocessed, during the preprocessing the data is transformed into a range of values. In further after conversion of data the outlier detection process is taken place. Therefore to measure the outlier and their removal the regression analysis based method is used. Finally the outcome of the outlier detection and removal process the data is used with the apriori algorithm for generation of the association rules. These recognized rules are used for classification of test dataset. Using the outcome of test data classification the performance of the proposed model is computed and compared against the traditionally available ARM based algorithm. The result shows the proposed technique is efficient and accurate as compared to the traditional ARM algorithm.
Keywords: Heart disease prediction system, data mining algorithm, association rule mining, ARM algorithm, outlier detection, regression analysis.
I. INTRODUCTION
The data mining techniques are accepted now in these days in various kinds of research and applications. The aim of these applications is to reduce the human effort and provide the accurate decision making ability. Basically the data mining techniques apply the computational algorithms which are helping the applications to analyze the data recover the target patterns. The recovered patterns using the data mining algorithms are used for various tasks such as decision making, classification, pattern recognition and others. In this presented work the predictive data mining is the main aim of study. Additionally the aim is to design and develop an efficient and accurate data model that can be used for heart disease prediction [1].
The heart disease becomes very common now in these days in any age group person. Basically the risk of heart disease increasing day by day because of the life style and stress in our daily routine. Additionally the risk level increases with the age and the weight of person. In addition of that there are more attributes are available by which the risk prediction for heart disease is possible [2]. In this context an association rule mining based predictive technique is proposed for design and implementation that accept the historical patient’s data attributes. The association rule mining is a technique that recovers the frequent patterns from the transactional data and used to
produce the rules using the frequent items. Using these attributes the proposed data model generates the rules which are used to recognize the similar patterns during the testing of data model. The proposed work involves the performance improvement technique of traditional association rule mining by introducing the outlier based rule pruning technique.
II. PROPOSED WORK
This chapter provides the understanding about the proposed system which is used for heart disease prediction. In order to provide the details the proposed methodology and required algorithm is explained.
A.System Overview
also known as the frequent item set mining. The model works on the basis of available attribute values and there frequency for computing the association rules. In this presented work the Apriori algorithm is taken in consideration for designing required system. The proposed system includes the three main modules for processing the raw data and generating the effective information. Therefore the given technique involves the outlier removal process during the preprocessing phase. In this context the regression analysis is performed on data with respect to the available class labels and the data attributes. Using this technique those data instances are removed which are demonstrating the properties of outlier. The outliers are those data objects that demonstrating the misbehavior with the other pattern. Therefore these data points are misguiding the rule generation algorithm. Therefore before processing the data noise and outliers are removed from the data and make it clean for obtaining most suitable rules. After that process the Apriori algorithm is employed and association rules are generated. These rules are used for classifying the test patterns and generating the class labels for unknown patterns. This section provides the basic overview of proposed work, the next section provides the details of the proposed system.
B.Methodology
The proposed data model for heart disease prediction system is given in figure 1. That model contains the different modules which are basically the modules that performing and producing intermediate computations.
Figure 1 heart disease prediction system
Heart disease dataset: the data mining processes are required the data for preparing data models. These data can be taken from real world survey or we can use the bench mark dataset. In this study we use the bench mark data set obtained from the UCI repository. That is a collection of online machine learning datasets.
Pre-processing: the preprocessing is an essential part of data mining. Using these techniques the data is prepared to for providing input an algorithm. Therefore it is technique to make enable the available data to use with any machine
learning and data mining algorithm. Therefore the dataset is processed here to prepare the data according to the apriori algorithm. Thus the following process is used for preprocessing of the dataset.
Input: dataset ,
Output: preprocessed data Process:
1. 2.
a. b.
i. 1.
ii.
1.
iii.
1.
iv.
1. v.
1. vi.End if c.
3.End for 4.Return
Table 1 preprocessing of data
Outlier detection and removal: after preprocessing of data, the outlier removal process is adopted for improving the quality of data. In his context the liner regression analysis is performed over dataset. Therefore first each attribute is compared with the class label of data. However, regression is used to find equations that fit data. The regression equation can use to make predictions. In linear regression analysis a correlation coefficient shows that data is likely to be and a scatter plot can also be used for the data to prepare a straight line. If you recall from elementary algebra, the equation for a line is
Therefore to calculate linear regression, the following equation can be used
y’ = a + bx.
Linear regression is a way to model the relationship between two variables. It is also recognize that equation as slope formula. The equation has the form
Y=a + bX Where Y is the dependent variable, and X is the independent variable, b is the slope of line and
a is the y-intercept.
In this context the following formula can be used for finding the values of a and b.
During this two variables are also calculated Res and Ires. Where Res is an by-1 vector of residuals and Ires is n-by-2 matrix of intervals that can be used to diagnose outliers. If the interval Ires (i, :) for observation i does not contain zero, the corresponding residual is larger than expected in 100*(1-alpha) % of new observations, suggesting an outlier.
Apriori algorithm: in order to provide the prediction for heart disease, the available dataset attributes are used with the apriori algorithm. Using the apriori algorithm the data is processed and the frequent item-sets are computed. These frequent item sets are used for providing the association rules. These rules establishing the connectivity among the different available dataset attributes. Here the classical apriori algorithm is used as component to do this work.
Rule generation: the apriori algorithm is used here for generating the rules for classification. These generated rules are known as association rules or frequent pattern rules. These rules can be used as “If – then – else” rules. Which can be used for identifying the class labels of the given unknown samples patterns.
Test samples: the generated rules in previous phase are
going to be used for classify the test data samples. Therefore the similar kinds of patterns are used for testing purpose. Therefore some samples are taken from available training dataset as a test dataset. In most of the data mining systems the 30% and 70% ratio of testing and training set are used.
Class label prediction: the class label prediction using the enhanced Apriori algorithm is the final outcome of the proposed system. Basically the rules are used to identify the class labels of the test data samples. Therefore after generation of class labels of the input test samples the performance of the system is evaluated to know how accurately the proposed system works.
C.Proposed Algorithm
The proposed algorithm is described in this section, the above described approach is presented here as the algorithm steps. The table 2. contains the required steps:
Input : training dataset D, testing dataset T Output: testing data class labels C Process:
1. 2. 3. 4.
a.
i. b.
5.End for 6.
7. 8.
a. 9.
10. Return C
Table 2. proposed algorithm
The above given table 2. demonstrate the proposed algorithm. That system accepts the dataset D as input. The dataset is first preprocessed to transform the dataset. The transformation is performed for optimizing the data for enabling it to the Apriori algorithm. After that the outlier detection process is taken place. Here for that purpose the data and class label is compared to prepare relationship among them. During this the identified outlier instance of data is also removed from the initial dataset. After preprocessing and outlier removal the apriori algorithm is applied on data. The aim is to generate the association rules suing apriori algorithm. These rules are keep preserved and used for classifying the test data.
III. RESULT ANALYSIS
This chapter provides the understanding about the performance evaluation of the implemented heart disease prediction system. In this context different performance parameter is measured and observations are reported in this chapter.
A.Accuracy
between total correctly recognized patterns and the total patterns supplied for classification.
80 82 84 86 88 90 92
1 2 3 4 5 6 7
Ac
cu
ra
cy
%
Experiments
Proposed enhanced apriori ARM algorithm
Figure 3. accuracy % Experiments Proposed
enhanced apriori ARM algorithm
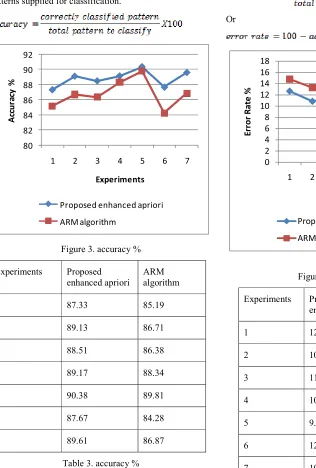
1 87.33 85.19
2 89.13 86.71
3 88.51 86.38
4 89.17 88.34
5 90.38 89.81
6 87.67 84.28
7 89.61 86.87
Table 3. accuracy %
The accuracy of the proposed enhanced Apriori algorithm and traditional ARM algorithm is demonstrated in figure 3.1 and table 3.1. The table 3. demonstrates the obtained accuracy percentage of both the algorithms. Using these observations the figure 3. is prepared the line graph. According to the given results the proposed technique classifies the data more accurately as compared to the traditional ARM algorithm.
B.Error Rate
During classification of input data samples the incorrectly predicted class labels are measured as the error rate of the system. The error rate of a data mining algorithm can be measured using the following formula:
Or
0 2 4 6 8 10 12 14 16 18
1 2 3 4 5 6 7
Er
ro
r R
at
e
%
Experiments
Proposed enhanced apriori ARM algorithm
Figure 4 error rate % Experiments Proposed
enhanced apriori ARM algorithm
1 12.67 14.81
2 10.87 13.29
3 11.49 13.62
4 10.83 11.66
5 9.62 10.19
6 12.33 15.72
7 10.39 13.13
Table 4 error rate %
The error rate of the proposed technique and traditional ARM technique is given in this section. The error rate of the system is computed in terms of percentage values. These values are listed in table 4 to show the experimental observations. In further these values are used with the line graph utility for demonstrating the comparative line graph. The developed line graph is given in figure 4. According to the shown graph the proposed technique is superior for classification and generates the less amount of error rate.
C.Memory Usages
The use of main memory by the target process is known here as the memory usages. To compute the memory usages the system usages the following formula:
Experiments Proposed
enhanced apriori ARM algorithm
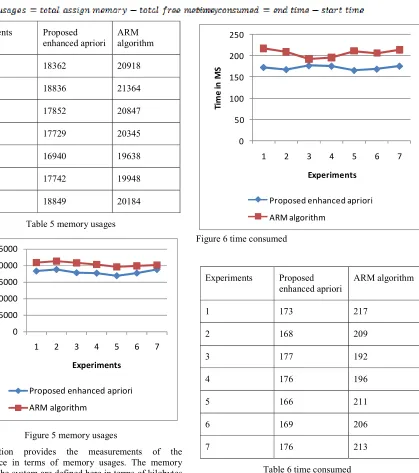
1 18362 20918
2 18836 21364
3 17852 20847
4 17729 20345
5 16940 19638
6 17742 19948
7 18849 20184
Table 5 memory usages
0 5000 10000 15000 20000 25000
1 2 3 4 5 6 7
M
em
or
y i
n
Kb
Experiments
Proposed enhanced apriori ARM algorithm
Figure 5 memory usages
This section provides the measurements of the performance in terms of memory usages. The memory usages of the system are defined here in terms of kilobytes (KB). The observed values during the experiments are notified in table 5 and their line graph format is demonstrated in figure 5. in this diagram the X axis involve the experiment number and Y axis contains the obtained memory usages in terms of KB. According to the given results the proposed work consumes the less amount of main memory as compared to the traditional ARM approach. Thus proposed technique is efficient and resource preserving technique of association rule mining.
D.Time Consumed
In order to process the data using an algorithm a particular amount of time required. However that is depends upon the amount of data provided for processing. This
consumed amount of time is denoted here as the time consumption of algorithms. To calculate the time requirements the following formula is used:
0 50 100 150 200 250
1 2 3 4 5 6 7
Tim
e i
n
M
S
Experiments
Proposed enhanced apriori ARM algorithm
Figure 6 time consumed
Experiments Proposed
enhanced apriori ARM algorithm
1 173 217
2 168 209
3 177 192
4 176 196
5 166 211
6 169 206
7 176 213
Table 6 time consumed
IV. CONCLUSION
The proposed work provides an application of data mining in the domain of heart disease prediction. In this context an association rule mining based technique is proposed and implemented. This chapter provides the summary of effort performed for the system design.
A. Conclusion
The risk of heart disease in new generation is increases day by day, a significant amount of new people is suffered from this crucial disease. That disease is increases due to various factors such as weight, food habits and daily routines. The bed habits are increasing the risk of heart disease. In this context to understand the pattern and properties of heart disease the proposed work is dedicated for recovering the attributes and preparing the data mining based model that help to understand the risk of any heart disease patient. The proposed data model is a prototype of the actual heart disease prediction system.
Thus the proposed data mining algorithm is usages the heart disease patient dataset from the UCI repository and used to prepare the rules. These rules are help to understand the association of attributes to demonstrate the risk of heart disease. The proposed data model includes first the dataset preprocessing to optimize the learning data quality. After that the regression analysis is performed the aim of regression analysis to identify the outliers from the data. During this outlier detection the removal process is also used. Finally the apriori algorithm is applied to generate the association rules. these rules are used with the test dataset for identifying the class labels for the test dataset. The implementation of the proposed heart disease prediction system is performed using JAVA technology. Additionally to store the performance of the system the MySql database is used. After successful implementation the performance of proposed apriori algorithm and traditional ARM algorithm is measured and compared. The summary of obtained performance is reported in table 7.
S.
No. Parameters Proposed technique ARM algorithm 1 Accuracy 87.33 – 90.38
% 84.28 89.81 % – 2 Error rate 9.62 – 12.67 % 10.19 –
15.17 % 3 Memory usages 17729 – 18849
KB 19638 21364 KB – 4 Time consumed 166 – 177 MS 192 – 217
MS Table 7 performance summary
According to the given results in table 4.1 the proposed algorithm demonstrates the superiority over the traditional ARM based heart disease prediction system. The proposed
model is accurate and resource preserving as compare to traditional ARM based technique.
B.Future Work
The proposed work is motivated for classifying the heart disease dataset classification more accurately as compared to the traditional ARM algorithm. In this context the proposed technique is provides a data model that optimize the performance of existing approach. In near future the following extension of the work is proposed.
1.In near future the real world data samples are collected according to the doctor’s guidelines for demonstrating actual outcomes of the system. The proposed technique current usages the simple enhancement that algorithm extended using implementation of ensemble learning concept.
REFERENCES
[1] Vikas Gupta, “A survey on Data Mining: Tools, Techniques, Applications, Trends and Issues”, International Journal of Scientific & Engineering Research Volume 4, Issue3, March-2013 1 ISSN 2229-5518
[2] Shafquat Perween, Suraiya Parveen, “Analysis of Heart Disease Prediction Techniques”, International Journal of Scientific Research Engineering & Technology (IJSRET), ISSN 2278 – 0882, Volume 7, Issue 4, April 2018
[3] Manpreet Kaur, Shivani Kang, “Market Basket Analysis: Identify the changing trends of market data using association rule mining”, Procedia Computer Science 85 ( 2016 ) 78 – 85
[4] Kainaz Bomi Sheriwala, “Data Mining Techniques in Stock Market”, INDIAN JOURNAL OF APPLIED RESEARCH, Volume 4, August 2014.
[5] S. L. Pandhripande and Aasheesh Dixit, “Prediction of 2 Scrip Listed in NSE using Artificial Neural Network”, International Journal of Computer Applications (IJCA), Volume 134, No.2, January 2016.
[6] Chirag Mewada and Rustom Morena, “Trie Based Improved Apriori Algorithm to Generate Association Rules”, International Journal of Advanced Research in Computer and Communication Engineering, Vol. 5, Issue 10, October 2016
[7] Sagar Sharma, Keke Chen, and Amit Sheth, “Towards Practical Privacy-Preserving Analytics for IoT and Cloud-Based Healthcare Systems”, IEEE Internet Computing, March-April 2018.
[8] Wenxiu Ding, Zheng Yan, and Robert H. Deng, “Privacy-Preserving Data Processing with Flexible Access Control”, Transactions on Dependable and Secure Computing, DOI 10.1109/TDSC.2017.2786247, IEEE.
[9] Richhariya Vineet, and Prateek Chourey, "A Robust Technique for Privacy Preservation of Outsourced Transaction Database", ISSN (E) (2014): 2321-8843.
[10] Terrovitis M; Poulis G; Mamoulis N; Skiadopoulos S, “Local Suppression and Splitting Techniques for Privacy Preserving Publication of Trajectories”, IEEE Transactions on Knowledge and Data Engineering, 2017, v. 29, p. 1466-1479.
[11] Marjia Sultana, Afrin Haider and Mohammad ShorifUddin, “Analysis of Data Mining Techniques for Heart Disease Prediction”, 978-1-5090-2906-8/16/$31.00 ©20 16 IEEE [12] Purushottam, Prof. (Dr.) Kanak Saxena, Richa Sharma, “Efficient