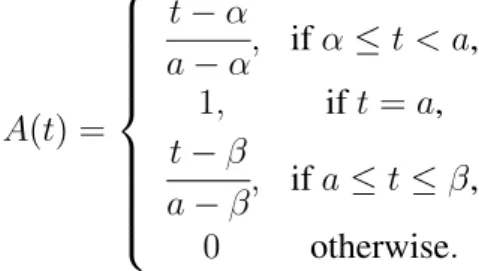Christer Carlsson
|
Robert Full ´er
Predictive Probabilistic and Predictive
Possibilistic Models for Risk
Assess-ment in Grid Computing
TUCS Technical Report
Predictive Probabilistic and Predictive
Possibilistic Models for Risk
Assess-ment in Grid Computing
Christer Carlsson
Institute for Advanced Management Systems Research
Department of Information Technologies, ˚Abo Akademi University Joukahainengatan 3-5, 20520 ˚Abo, Finland
Robert Full ´er
Institute for Advanced Management Systems Research
Department of Information Technologies, ˚Abo Akademi University Joukahainengatan 3-5, 20520 ˚Abo, Finland
TUCS Technical Report No 976, April 2010
Abstract
We show a hybrid probabilistic and possibilistic model for assessing the risk of a service level agreement for a computing task in a cluster/grid environment. Us-ing the predictive probabilistic approach we develop a framework for resource management in grid computing, and by introducing an upper limit for the num-ber of failures we approximate the probability that a particular computing task is successful. In the possibilistic model we estimate the degree of possibility of suc-cess using a fuzzy nonparametric regression technique using the possibility dis-tribution for the maximal number of failures derived from a resource provider’s observations. The probabilistic models scale from 10 nodes to 100 nodes and then on to any (reasonable) number of nodes; in the same fashion also the pos-sibilistic models scale to 100 nodes and then on to any (reasonable) number of nodes. The resource provider can use both the probabilistic and the possibilistic models to get two alternative risk assessments and then he can choose either the probabilistic or the possibilistic risk assessment; or the hybrid model – which is a cautious/conservative approach.
Keywords: Grid computing, Service Level Agreement (SLA), Predictive proba-bilities, Predictive possibilities
1
Introduction
There is an increasing demand for computing power in scientific and engineering applications which has motivated the deployment of high performance comput-ing (HPC) systems that deliver tera-scale performance. Current and future HPC systems that are capable of running large-scale parallel applications may span hundreds of thousands of nodes.
The current highest processor count is 131K nodes according to top500.org (Raju et al. 2006). For parallel programs, the failure probability of nodes and com-puting tasks assigned to the nodes has been shown to increase significantly with the increase in number of nodes. Large-scale computing environments, such as the current grids CERN LCG, NorduGrid, TeraGrid and Grid’5000 gather (tens of) thousands of resources for the use of an ever-growing scientific community. Many of these Grids offer computing resources grouped in clusters, whose owners may share them only for limited periods of time and Grids often have the problems of any large-scale computing environment to which is added that their middleware is still relatively immature, which contributes to making Grids relatively unreli-able computing platforms. Iosup et al. (2007) collected and present material from Grid’5000 which illustrates this contention. On average, resource availability (for a period of 548 days) in Grid’5000 on the grid level is 69% (±11.42), with a max-imum of 92% and a minmax-imum of 35%. The mean time between failures (MTBF) of the grid is of 7442631 seconds (around 12 minutes); at the cluster level, re-source availability varies from 39% up to 98% across the 15 clusters, the average MTBF for all clusters is 18404±13848 seconds (around 5 hours); at the node level on average a node fails 228 times (over 548 days), but some nodes fail only once or even never. Long et al. (1995) collected a dataset on node failures over 11 months by from1139 workstations on the Internet to determine their uptime intervals. Planck and Elwasif (1998) collected a dataset on failure information for a collection of 16 DEC Alpha work-stations at Princeton University; the size of this network is smaller and is a typical local cluster of homogeneous processors; the failure data was collected for 7 months and shows similar characteristics as for the larger clusters.
Schroeder and Gibson (2006) analyse failure data collected over 9 years at Los Alamos National Laboratory (LANL) and which includes 23000 failures recorded on more than 20 different systems, mostly large clusters of SMP and NUMA nodes. Their study includes root cause of failures, the mean time between failures, and the mean time to repair. They found that average failure rates differ wildly across systems, ranging from 201000 failures per year, mean repair time varies from less than an hour to more than a day. Most applications (about 70%) running in the LANL are short duration computing tasks of< 1hour, but there are also large-scale, long-running 3D scientific simulations. These applications perform long periods (often months) of CPU computation, interrupted every few hours by a few minutes of I/O for check-pointing. When node failures occur in the
LANL, hardware was found to be the single largest cause (30-60%); software is the second largest contributor (with 5-24%), but in most systems the root cause remained undetermined for 20-30% of the failures (Schroeder and Gibson 2006). They also found that the yearly failure rate varies widely across systems, ranging from 17 to an average of 1159 failures per year for several systems. The main reason for the differences was that the systems vary widely in size and that the nodes run different workloads.
Iosup et al. (2007) fit statistical distributions to the Grid’5000 data using maxi-mum likelihood estimation (MLE) to find a best fit for each of the model parame-ters. They found that the best fits for the inter-arrival time between failures, the du-ration of a failure, and the number of nodes affected by a failure, are the Weibull, Log-Normal, and Weibull distributions, respectively. The results for inter-arrival time between consecutive failures indicate an increasing hazard rate function, i.e. the longer a computing node stays in the system, the higher the probability for the node to fail, which will prevent long jobs to finish. Iosup et al. (2007) also wanted to find out if they can decide where (on which nodes or in which cluster) a new failure could/should occur. Since the sites are located and administered sep-arately, and the network between them has numerous redundant paths, they found no evidence for any other assumption than that there is no correlation between the occurrence of failures at different sites. For the LANL dataset Schroeder and Gib-son (2006) studied the sequence of failure events and the time between failures as stochastic processes. This includes two different views of the failure process: (i) the view as seen by an individual node; (ii) the view as seen by the whole system. They found that the distribution between failures for individual nodes is well mod-elled by a Weibull or a Gamma distribution; both distributions create an equally good visual fit and the same negative log-likelihood. For the system wide view of the failures the basic trend is similar to the per node view during the same time. The Weibull and Gamma distributions provide the best fit, while the lognormal and exponential fits are significantly worse.
A significant amount of the literature on grid computing addresses the problem of resource allocation on the grid (e.g. Brandt et al. 2005; Czajkowski et al. 2002, 2005; Liu et al. 2004; Magana et al. 2003). The presence of disparate resources that are required to work in concert within a grid computing framework increases the complexity of the resource allocation problem. Jobs are assigned either through scavenging, where idle machines are identified and put to work, or through reservation in which jobs are matched and pre-assigned with the most appropriate systems in the grid for efficient workflow.
In grid computing a resource provider [RP] offers resources and services to other Grid users based on agreed service level agreements [SLAs]. The research prob-lem we have addressed is formulated as follows:
o the RP is running a risk to be in violation of his SLA if one or more of the re-sources [nodes in a cluster or a Grid] he is offering to prospective customers
will fail when carrying out the tasks
o the RP needs to work out methods for a systematic risk assessment [RA] in order to judge if he should offer the SLA or not if he wants to work with some acceptable risk profile
In the context we are going to consider (a generic grid computing environment) resource providers are of various types which mean that the resources they manage and the risks they have to deal with are also different; we have dealt with the following RP scenarios (but we will report only on extracts due to space):
•RP1 manages a cluster of n1 nodes (wheren1 < 10) and handles a few (< 5) computing tasks for aT;
•RP2 manages a cluster ofn2 nodes (wheren2 < 150) and handles numerous (≈ 100) computing tasks for aT; RP2 typically uses risk models building on stochastic processes (Poisson-Gamma) and Bayes modelling to be able to assess the risks involved in offering SLAs;
•RP3 manages a cluster ofn3nodes (wheren3 <10) and handles numerous (≈
100) computing tasks for aT; if the computing tasks are of short duration and/or the requests are handled online RP3 could use possibility models that will offer robust approximations for the risk assessments;
• RP4 manages a cluster of n4 nodes (where n4 < 150) and handles numer-ous (≈100) computing tasks for aT; typically RP4 could use risk models building on stochastic processes (Poisson-Gamma) a nd Bayes modelling to assess the risks involved in offering SLAs; if the computing tasks are of short duration and/or the requests are handled online hybrid models which combine stochastic processes and Bayes modelling with possibility models could provide tools for handling this type of cases.
During the execution of a computing task the fulfilment of the SLA has the highest priority, which is why an RP often is using resource allocation models to safeguard against expected node failures. When spare resources at the RP’s own site are not available outsourcing will be an adequate solution for avoiding SLA violations. The risk assessment modelling for an SLA violation builds on the development of predictive probabilities and possibilities for possible node failures and combined with the availability of spare resources. The rest of the paper will be structured as follows: in Section 2 we will work out the basic conceptual framework for risk assessment, in Section 3-4 we will introduce the Bayesian predictive probabilities as they apply to the SLAs for RPs in grid computing, in Sections 5-6 we will work out the corresponding predictive possibilities and show the results of the validation work we carried out for some RP scenarios; in Section 7 we compute a lower limit for the probability of success of computing tasks in a grid in Section 8 there is a summary and conclusions of the study.
2
Risk assessment
There is no universally accepted definition of business risk but in the RP context we will understand risk to be a potential problem which can be avoided or mit-igated (for references see Carlsson and Weissman 2009). The potential problem for an RP is that he has accepted an SLA and may not be able to deliver the nec-essary computing resources in order to fulfil a computing task within an accepted time frameT. Risk assessmentis the process through which a resource provider tries to estimate the probability for the problem to occur withinT and risk man-agement the process through which a resource provider tries to avoid or mitigate the problem. In classical decision theory risk is connected with the probability of an undesired event; usually the probability of the event and its expected harm is outlined with a scenario which covers the set of risk, regret and reward probabil-ities in an expected value for the outcome. The typical statistical model has the following structure,
R(θ, δ(x)) =
Z
L(θ, δ(x))f(x|θ)dx (1)
whereLis a loss function of some kind,xis an observable event (which may not have been observed) an δ(x) is an estimator for a parameter θ which has some influence on the occurrence ofx. The risk is the expected value of the loss func-tion. The statistical models are used frequently because of the very useful tools that have been developed to work with large datasets.
The statistical model is influenced by the modern capital markets theory where risk is seen as a probability measure related to the variance of returns. Markowitz (1952) initiated the modern portfolio theory stating that investors should focus on selecting portfolios based on portfolios’ risk-reward characteristics instead of compiling portfolios of assets that each individually has attractive risk-reward characteristics. The risk is classified in systematic (”market”) risk and idiosyn-cratic (”company” or ”individual”) risk. The analogy would be that an RP – han-dling a large number of nodes and a large number of computing tasks – will reach a steady state in his operations so that there will be a stable systematic risk (market risk’) for defaulting on an SLA which he can build on as his basic assumption and then a (small’) idiosyncratic risk which is situation specific and which he should estimate with some statistical models.
We developed a hybrid probabilistic and possibilistic model to assess the success of computing tasks in a Grid. The model first gives simple predictive estimates of node failures in the next planning period when the under-lying logic is the Bayes probabilistic model for o bservations on node failures. When we apply the possibilistic model to a dataset we start by selecting a sample ofk observations on node failures. Then we find out how many of these observations are different and denote this number by l; we want to use the two datasets to predict what thek + 1: st observation on node failures is going to be. The possibility model
is used to find out if that number is going to be 0,1,2,3,4,5, . . . etc.; for this estimate the possibility model uses the most usual’ numbers in the larger dataset and makes an estimate which is as close as possible’ to this number. The estimate we use is a triangular fuzzy number, i.e. an interval with a possibility distribution. The possibility model turned out to be a faster and more robust estimate of the k+ 1: st observation and to be useful for online and real-time risk assessments with relatively small samples of data.
3
Predictive probabilities
In the following we will use node failures in a cluster (or a Grid) as the focus, i.e. we will work out a model to predict the probabilities thatn nodes will fail in a period covered by an SLA(n = 0,1,2,3, . . .). In the interest of space we have to do this by sketches as we deal with standard Bayes theory and modelling (for references see Carlsson and Weissman 2009).
The first step is to determine a probability distribution for t he number of node failures for a time interval (t1, t2] by starting from some basic property of the process we need to describe. Typically we assume that the node failures repre-sent a Poisson process which is non-homogenous in time and has a rate function λ(t), t >0.
The second step is to determine a distribution for λ(t)given a number of obser-vations on node failures fromrcomparable segments in the interval(t1, t2]. This count normally follows a Gamma(α, β)distribution and the posterior distribution p(λt1,t2), given the count of node failures, is also a Gamma distribution according
to the Bayes theory. Then, as we have been able to determineλt1,t2 we can
cal-culate the predictive distribution for the number of node failures in the next time segment; Bayes theory shows that this will be a Poisson-Gamma distribution. The third step is to realize that a computing task can be carried out successfully on a cluster (or a Grid) if all the needed nodes are available for the scheduled duration of the task. This has three components: (i) a predictive distribution on the number of nodes needed for a computing task covered by an SLA; (ii) a dis-tribution showing the number of nodes available when an assigned set of nodes is reduced with the predicted number of node failures and an available number of reserve nodes is added (the number of reserve nodes is determined by the resource allocation policy of the RP); (iii) a probability distribution for the duration of the task.
The fourth step is to determine the probability of an SLA failure:p1(n nodes will fail for the scheduled duration of a task)×(1−p2 (m reserve nodes are available for the scheduled duration of a task)) if we consider only the systematic risk. We need to use a multinomial distribution to work out the combinations. Consider a Grid ofkclusters, each of which containsncnodes, leading to the total number of nodesn =P
denote generally a time non-homogeneous rate function for a Poisson process N(t). We will assume that we have the RP4 scenario as our context, i.e. we will have to deal with hundreds of nodes and hundreds of computing tasks with widely varying computational requirements over the planning period for which we are carrying out the risk assessment.
Bayesian reasoning regarding uncertainty has recently gained momentum in many seemingly unrelated fields of applied sciences, ranging from genetics (Beaumont and Rannala 2004) and developmental psychology (Schultz 2007), to a bulk of applications in technology and engineering, such as aircraft navigation, computer vision, digital communication etc (Doucet et al. 2001). However, a vast majority of putative applications of this line of reasoning are surely yet unexplored, as sci-entists are successively becoming aware of the potential residing in the approach, where the cornerstone is the Bayes’ theorem (Bernardo and Smith 1994; Jaynes 2003). Even though the Bayes’ theorem itself has been present in standard text-books on probability calculus for decades, the field of statistics and uncertainty reasoning was much unaffected by its existence for the most of the 20th century. The result, which in fact is a simple consequence of the basic modern axioms of probability, was earlier usually overlooked either by the fact that its applicabil-ity was considered very limited apart from some esoteric situations, or due to the subjectivea prioriprobability judgement included in the theorem.
The very fact that traditional frequentist statistical approaches based on hypothe-sis testing and parameter estimation do not usually provide directly the sought an-swers, in particular in typical technological applications, have laid the ground for the emergence of alternative, more appropriate methods for handling uncertainty. Therefore, when the awareness of powerful Monte Carlo simulation methods to solving complex issues in Bayesian computation increased in the early 1990’s, the time was ripe for adopting the Bayesian approach to handling uncertainty in many challenging applications (see e.g. Doucet et al. 2001; Robert and Casella 2005). Additionally, the general awareness of the methodology has also sparked an interest in re-considering fairly standard statistical problems, where advanced computational methods are not necessarily needed.
To illustrate the predictive nature of Bayesian characterizations of uncertainty, we use a simple example model and contrast the strategy with the maximum like-lihood method. Other similar approaches relying on point estimates of model parameters in predictive tasks could equally be considered. Proofs of the results from standard probability calculus and Bayesian inference can be found, e.g. in Bernardo and Smith (1994). Consider a data set comprising information from six exchangeable sampling units, each of which can give raise to a numberXi of events, such as errors in coding, typing, transmission etc, fori = 1, ...,6. When Xi = 0,it is concluded that no errors occured within theith sampling unit. If it is anticipated that the number of realized errors is small in relation to the number of potentially possible errors, a Poisson distribution is one common characterization of the uncertainty related to the intensity at which the errors occur among
compa-rable sampling units. Using this distribution as the likelihood component for each of the observations, we obtain the joint conditional distribution of the data as
p(x1, ..., x6|λ)∝exp(−6λ)λ
P6
i=1xi, (2)
whereλis the unknown Poisson intensity parameter.
In the Bayesian framework uncertainty is handled by attempting to describe all unknown quantities of interest or use, by assigning them probability distributions, which encode existing knowledge. Then, depending on the purpose of the mod-eling task, various characterizations of uncertainty may be derived using the laws of probability. In our example we have a single unknown quantity, the Poisson parameterλ, for which the uncertainty is quantified prior to the arrival of the ob-servationsx1, ..., x6. The standard prior used for this purpose is the Gamma(α, β) family of distributions, which has the following density representation
p(λ|α, β) = β
α
Γ(α)λ
α−1exp(−βλ), (3)
where the two hyperparametersαandβ have the following relation to the distri-bution moments E(λ) = α β, E(λ−E(λ)) 2 = α β2. (4)
Theposteriordistribution of the intensity parameterλ, i.e. the conditional distri-bution ofλgiven the datax= (x1, ..., x6), is then also a Gamma distribution and its density function equals
p(λ|x) = (β+ 6)
α+z
Γ(α+z) λ
α+z−1exp(−(β+ 6)λ), (5)
where z = P6i=1xi is the value of the sufficient statistic for the data under the Poisson model. Under a squared error loss, the Bayesian estimate ofλequals the posterior mean, which can be written as(α+z)/(β+ 6). The asymptotic behav-ior of this estimate as a function of the number of observations, sayn, is easily characterized, because the posterior mean approaches the maximum likelihood estimateλˆ=z/n, provided thatαandβare bounded, i.e.
(α+z)/(β+n)n→∞→ ˆλ.
In many technological applications it is not of primary interest to estimate model parameters, but rather use a statistical model for handling uncertainty in a given situation. For instance, in our example it might be of interest to provide a proba-bility statement regarding whether a future number of eventsXn+1 would exceed a certain threshold, deemed crucial for the acceptability of the error rate in the system. The Bayesian answer to this question is the predictive distribution of the
anticipated future obervations, given the knowledge accumulated so far. Formally, this distribution is defined as
p(x7|x1, ..., x6) = Z ∞
0
p(x7|λ)p(λ|x1, ..., x6)dλ, (6)
wherep(λ|x1, ..., x6)is the posterior distribution
p(λ|x1, ..., x6)∝ exp(−6λ)λy βα Γ(α)λ α−1exp(−βλ) R∞ 0 exp(−6λ)λy β α Γ(α)λα −1exp(−βλ)dλ (7) ∝ exp(−6λ)λ yλα−1exp(−βλ) R∞ 0 exp(−6λ)λyλα −1exp(−βλ)dλ,
which is regonized as the Gamma(α+z, β+ 6) distribution. By evaluating the integral (6) with respect to the above Gamma distribution, we obtain a special case of a Poisson-Gamma distribution, which is a mixture of Poisson distributions. The Poisson-Gamma distribution has in this case the probability mass function
p(x7|x1, ..., x6) = (β+ 6)α+z Γ(α+z) Γ(α+z+x7) x7!(β+ 6 + 1)α+z+x7 . (8)
It is important to notice that the Poisson-Gamma mixture has higher variance than the Poisson distribution, which reflects the uncertainty remaining about the pa-rameterλafter observing the data x. This can be interpreted as an honest quan-tification of the predictive uncertainty given the axioms of probability, and the judgement that Poisson model provides an appropriate description of the event probabilities. Also, it shows that the amount of uncertainty regarding future events is underestimated, if they are quantified by using the ordinary Poisson distribution, either with a Bayesian or maximum likelihood estimate ofλ. However, when the length of the data vectorxincreases towards infinity, the Poisson-Gamma mixture tends to the ordinary Poisson distribution, which illustrates how the additional un-certainty stemming from the unknown parameter λ vanishes as the amount of data available for statistical learning increases. Assuming the observed error rates equal to x= (3,4,2,1,2,3)and β = .001, α = 1/2, in our Poisson example, a concrete comparison can be made between the Bayesian predictive distribution and the distribution obtained by replacingλ with the maximum likelihood esti-mate15/6 = 2.5.
4
Predictive Probabilities in Grid Computing
Man-agement
Dynamically gathered observations of events within a grid computing system en-able updating of the knowledge concerning the system reliability and resource
availability. It is expected that resource management should optimally be based on the characteristics learned from the particular grid under consideration. Moreover, as a grid may undergo substantial technological and operational changes during its life cycle, the actual management procedures should be allowed to continuously adapt to the eventual changes in system. By monitoring grid behavior and feeding the appropriate information to a statistical model, it is possible to better anticipate future behavior and manage risks associated with component failures. It is worth noticing that such a dynamic perspective on information processing is in a per-fect harmony with the Bayesian predictive framework, which updates knowledge about probabilities related to future events every time relevant new information is made available. The evident stochasticity of a grid, concerning the availabil-ity of a particular resource at some point in time, suggests that probabilavailabil-ity-based decisions are most appropriate in a grid environment.
Using the predictive probabilistic approach, our aim here is to develop a frame-work for resource management in grid computing. The frame-works cited earlier illus-trate the substantial level of variation that exists over different grids with respect to the degree of exploitation, maintenance policies and system reliability. Sev-eral factors are of importance when the uncertainty about the expected amount of resources available at a given time point is considered. In the current work we consider explicitly the effects of computing task characteristics in terms of execution time and the amount of resources required, as well as failure rate and maintenance for individual system components. A basic predictive model with a modular structure is derived, such that several ramifications with respect to the distributional assumptions can be made when deemed necessary for any particular grid environment.
Consider a grid ofk clusters, each of which contains nc operative units termed nodes, with the total number of nodes in the grid denoted by
n=
k X
c=1 nc.
For simplicity of notation, we will below treat the clusters as exchangeable units concerning predictive statistical learning. However, if such an assumption is deemed implausible for a particular environment, the derived model can be ap-plied separately to the individual clusters for statistical learning.
To introduce a stochastic model for tendencies of node failures, letλ(t) >0, t ≥
0, denote generally a time-nonhomogeneous rate function for a Poisson process N(t). The rate function specifies the expected number of failure events in any given time interval(t1, t2]according to
λt1,t2 =
Z t2
t1
λ(t)dt,
given by the Poisson distribution p(X =x) = e −λt1,t2(λ t1,t2) x x! , x= 0,1, ... (9)
Under many circumstances it is feasible to simplify the Poisson model by assum-ing that the rate function is constant over time, or over certain time segments. In the Poisson process it assumed that the waiting times between successive events are exponentially distributed with the rate parameter λ governing the expected waiting times. Consider a time interval (t1, t2] with the corresponding rate pa-rameter λt1,t2, such that x events have been observed during (t1, t2]. Then, the
likelihood function for the rate parameter is given by p(x|λt1,t2) =
e−λt1,t2(λ
t1,t2)
x
x! . (10)
By collecting data (counts of events)x1, ..., xrfromrcomparable time segments, we obtain the joint likelihood function
p(x1, ..., xr|λt1,t2)∝e
−rλt1,t2(λ
t1,t2)
Pr
i=1xi. (11)
In accordance with the preditive example considered in the previous section, using the Gamma prior distribution for λt1,t2 we then obtain the predictive
Poisson-Gamma probability of having y events in future on a comparable time interval, which equals (β+r)α+z Γ(α+z) Γ(α+z+y) y!(β+r+ 1)α+z+y, (12) wherez =Pri=1xi.
When a computing task is slated for execution in a grid environment, its successful completion will require a certain number of nodes to be available over a given period of time. To assess the uncertainty about the resource availability, we need to model both the distribution of the number of nodes and the length of the task required by the tasks. The most adaptable choice of a distribution for the number of nodes required, sayM, is the multinomial distribution
p(M =m) =pm, m= 1, ..., u, (13)
whereuis ana priorispecified upper limit for the number of nodes. Such a vector of probabilities will be denoted byp in the sequel. Hereucould, e.g., equal the total number of nodes in the system, however, such a choice would lead to an inefficient estimation of the probabilities, and therefore, the upper bound value should be carefully assessed using empirical evidence.
An advantage of the use of the multinomial distribution in this context is its ability to represent any types of multimodal distributions forM, in contrast to the stan-dard parametric families, such as the Geometric, Negative Binomial and Poisson
distributions. For instance, if there are two major classes of computing tasks or maintenance events, such that one class is associated with relatively small num-bers of required nodes, and the other with relatively large numnum-bers, the system behavior in this respect is well representable by a multinomial distribution. On the other hand, standard parametric families of distributions would not enable an appropriate representation, unless some form of a mixture distribution were uti-lized. Such a choice would complicate the inference about the underlying param-eters due to the fact that the number of mixture components would be unknowna priori. In general, estimation of parameters and calculation of predictive proba-bilities under a such mixture model requires the use of a Monte Carlo simulation technique, e.g. the EM- or Gibbs sampler algorithm (Robert and Casella 2005). A disadvantage of the multinomial distribution is that it contains a large number of parameters when u is large. However, this difficulty is less severe when the Bayesian approach to the parameter estimation is adopted. Given observed data on the number of nodes required by computing tasks, the posterior distribution of the probabilitiesp is available in an analytical form under a Dirichlet prior, and its density function can be written as
p(p|w) = Γ( Pu m=1αm+wm) Qu m=1Γ(αm+wm) u Y m=1 pαm+wm−1 m , (14)
wherewm corresponds to the number of observed tasks utilizing mnodes,αm is thea priorirelative weight of themth component in the vectorp, andwis the vec-tor(wm)um=1. The corresponding predictive distribution of the number of nodes re-quired by a generic computing task in the future equals the Multinomial-Dirichlet distribution, which is obtained by integrating out the uncertainty about the multi-nomial parameters with respect to the posterior distribution. The Multimulti-nomial- Multinomial-Dirichlet distribution is in our notation defined as
p(M =m∗|w) = Γ( Pu m=1αm+wm) Qu m=1Γ(αm+wm) Qu m=1Γ(αm+wm+I(m =m ∗)) Γ(1 +Pum=1αm+wm) (15) = Γ( Pu m=1αm+wm) Γ(αm∗+wm∗) Γ(αm∗ +wm∗+ 1) Γ(1 +Pum=1αm+wm).
To simplify the inference about the length of a task affecting a number of nodes we assume that the length follows a Gaussian distribution with expected valueµand varianceσ2.Let the datat1, ..., tb represent the lengths (say, in minutes) ofbtasks. This leads to the sample mean¯t =Pbi=1ti and variances2 = b−1Pbi=1(ti −¯t)2. Assuming the standard reference prior (see Bernardo and Smith 1994) for the parameters, we obtain the predictive distribution for the length of a future task, sayT, which has the T-distribution with parameters¯t,((b−1)/(b+ 1))s2, b−1,
i.e. the probability density of the distribution equals p(t|t,¯((b−1)/(b+ 1))s2, b−1) = Γ(b/2) Γ(b−21)Γ(1/2) 1 (b+ 1)s2 12 × 1 + 1 b+ 1)s2 (t−¯t) 2 −2b . (16)
The probability that a task lasts longer than any given timet equalsP(T > t) = 1−P(T ≤t), whereP(T ≤ t)is the cumulative distribution function (CDF) of the T-distribution. The value of the CDF can be calculated numerically using func-tions existing in most computing environments. However, it should also be noted that for a moderate to largeb, the predictive distribution is well approximated by the Gaussian distribution with the meant¯and the variances2 (b+1)
(b−3). Consequently, if the Gaussian approximation is used, the probabilityP(T ≤t)can be calculated using the CDF of the Gaussian distribution.
We now consider an approximation to the probability that a particular comput-ing task is successful. This happens if there will always be at least a scomput-ingle idle node available in the system in the case of a node failure. LetS = 1 denote the event that the task is successful, andS = 0the opposite event. We formulate the probability of the success as the sum of the probabilitiesP(”none of the nodes allocated to the task fail”) +Pmmax
m=1 P(”mof the nodes allocated to the task fail & at leastm idle nodes are available as reserves”). Heremmaxis an upper limit for the number of failures considered. The value can be chosen by judging the size of the contribution of each event, determined by the corresponding probability. Thus, the sum can be simplified by considering only those events that do not have vanishingly small probabilities. A conservative bound for the success probability can be derived by assuming that themfailures take place simultaneously, which leads to P(S = 1) = 1−P(S = 0) = 1− mmax X m=1
P(mfailures occur & less thanmfree nodes available)
= 1− mmax
X
m=1
P(mfailures occur)P(less thanmfree nodes available) (17)
≥1− mmax
X
m=1
P(mfailures occur)P(less thanmfree nodes at any time point)
The probability P(m failures occur) is directly determined by the failure rate model discussed above. The other term, the probabilityP(less thanmfree nodes at any time point), on the other hand, is dependent both on the level of workload in the system and the eventual need of reserve nodes by the other tasks running
Figure 1: Prediction of node failures [Prob of Failure: 0.1509012] with 136 time slots of LANL cluster data for computing tasks running for 9 days, 0 hours.
Figure 2: Probability that less thanmnodes will be available for computing tasks requiring<10nodes; the number of nodes randomly selected; 75 tasks simulated over 236 time slots; LANL
simultaneously. Thus, the failure rate model can be used to calculate the probabil-ity distribution of the number of reserve nodes that will be jointly needed by the other tasks (that are using a certain total number of nodes) during the computation time that has the distribution specified above for a single node.
The predictive probabilities model has been extensively tested and verified with data from the LANL cluster (Shroeder and Gibson 2006). Here we collected re-sults for the RP1 scenario where the RP is using a cluster with only a few nodes; the test runs have been carried out also for the scenarios RP2-4 with some varia-tions to the results.
5
Predictive possibilities
In this Section we will introduce a hybrid method for simple predictive estimates of node failures in the next planning period when the underlying logic is the Bayes models for observations on node failures that we used for the RA models in Sec-tion 3. We will introduce the new model as an alternative for predicting the
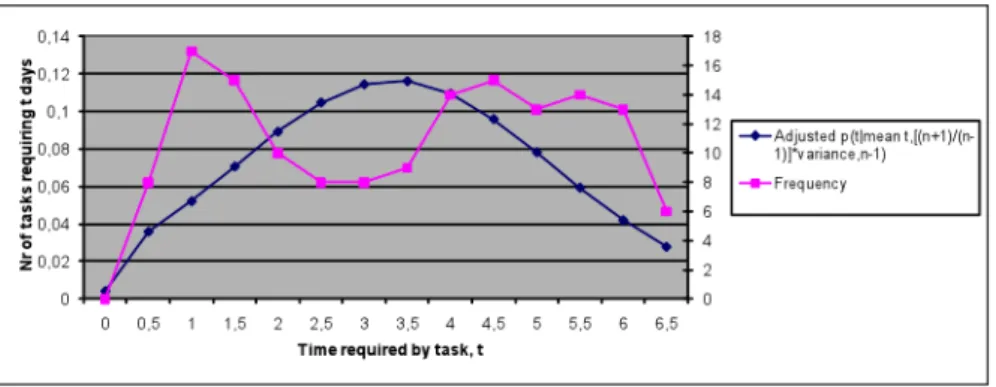
num-Figure 3: Expected time needed for a computing task t; simulated number of computing tasks requiring varioust; data from LANL
ber of node failures and use it as part of the Bayes model we have developed for predictive probabilities. In this way we will have hybrid estimates of the expected number of node failures - both probabilistic and possibilistic estimates. An RP may use either one estimate for his risk assessment or use a combination of both. In theAssessgrid projectwe have implement both models as one software solution to give the user two alternative routes.
In this Section we will sketch the possibilistic regression model which is a sim-plified version of the fuzzy nonparametric regression model with crisp input and fuzzy number output introduced by Wang et al. (2007). This is essentially a stan-dard regression model with parameters represented by triangular fuzzy numbers - typically this means that the parameters are intervals and represent the fact that the information we have is imprecise and/or uncertain.
Fuzzy sets were introduced by Zadeh (1965) to represent/manipulate data and information possessing non-statistical uncertainties. It was specifically designed to mathematically represent uncertainty and vagueness and to provide formalized tools for dealing with the imprecision intrinsic to many problems. Let X be a nonempty set. A fuzzy set fuzzy setA inX is characterized by its membership function
µA: X →[0,1],
andµA(x)is interpreted as the degree of membership of elementxin fuzzy setA for eachx∈X. It should be noted that the terms membership function and fuzzy subset get used interchangeably and we will write simplyA(x)instead ofµA(x). In many situations people are only able to characterize numeric information im-precisely. For example, people use terms such as, about $3,000, near zero, or essentially bigger than $5,000. These are examples of what are calledfuzzy num-bers. Using the theory of fuzzy subsets we can represent these fuzzy numbers as fuzzy subsets of the set of real numbers. A fuzzy numberA is a fuzzy set of the real lineRwith a normal, fuzzy convex and continuous membership function of bounded support (Carlsson and Full´er 2002). Fuzzy numbers can be considered
as possibility distributions. IfAis a fuzzy number and x∈Ra real number then A(x)can be interpreted as the degree of possibility of the statement ”xisA”. A fuzzy numberA is said to be a triangular fuzzy number, denotedA = (a, α, β), with centera, left widtha−α >0and right widthβ−a > 0if its membership function is defined by,
A(t) = t−α a−α, ifα≤t < a, 1, ift=a, t−β a−β, ifa≤t≤β, 0 otherwise.
A triangular fuzzy number with center a may be seen as a fuzzy quantity ”x is approximately equal toa”.
Figure 4: A triangular fuzzy number.
LetF denote the set of all triangular fuzzy numbers. We consider the following univariate fuzzy nonparametric regression model,
Y =F(x) +ε = (a(x), α(x), β(x)) +ε. (18)
wherexis a crisp independent variable (input) whose domain is assumed to beD, whereD ⊂ R. Y ∈ Fis a triangular fuzzy variable (output),F(x)is a mapping fromD toF is an unknown fuzzy regression function with its center, lower and upper limita(x), α(x), β(x). εmay also be considered as a fuzzy error or a hybrid error containing both fuzzy and random components.
We will take a sample of a dataset (in our case, a sample from the LANL dataset) which covers inputs and fuzzy outputs according to the regression model. Let xi, Yi be a sample of the observed crisp inputs and fuzzy outputs of model (1). The main goal of fuzzy nonparametric regression is to estimateF(x)at anyx ∈ D from (xi, Yi), i = 1,2, ..., n. And the membership function of an estimated fuzzy output should be as close as possible to that of the corresponding observed fuzzy number (Wang et al. 2007). From this point of view, we shall estimate a(x), α(x), β(x) for each x ∈ D in the sense of best fit with respect to some distance that can measure the closeness between the membership functions of the
estimated fuzzy output and the corresponding observed one. There are actually a few of the distances available. We use the distance proposed by Diamond (1988) as a measure of the fit because it is simple in use and, more importantly, can result in an explicit expression for the estimated fuzzy regression function when the local linear smoothing technique is used. LetA= (a, α1, β1), B = (b, α2, β2) be two triangular fuzzy numbers. Then the squared distance betweenAandB is defined by Diamond (1988),
d2(A, B) = (α1−α2)2+ (a−b)2+ (β1 −β2)2. (19)
Equation (19) is a measure the closeness between two fuzzy numbers andd2(A, B) =
0if and only ifA(t) =B(t)for allt ∈R. Using this distance we will extend the local linear smoothing technique in statistics to fit the fuzzy nonparametric model (18). Let us now assume that the observed (fuzzy) output isYi = (a, αi, βi), then with the Diamond distance measure and a local linear smoothing technique we need to solve a locally weighted least-squares problem in order to estimateF(x0), for a given kernelK and a smoothing parameterh, where
Kh(|xi−x0|) = K |x i−x0| h , (20)
The kernel is a sequence of weights atx0 to make sure that data that is close to x0will contribute more when we estimate the parameters atx0than those that are farther away, i.e. are relatively more distant in terms of the parameterh. Let
ˆ
F(i)(xi, h) = (ˆa(i)(x0, h),αˆ(i)(x0, h),βˆ(i)(x0, h)). (21)
be the predicted fuzzy regression function at input xi. Compute Fˆ(i)(xi, h) for eachxi and let
CV(h) = 1 l l X i=1 d2(Yi,Fˆ(i)(xi, h)) (22)
We should selecth0 so that it is optimal in the following expression
CV(h0) = min
h>0 CV(h). (23) By solving this minimalization problem, we get the following estimate ofF(x)at x0(Wang et al. 2007), ˆ F(x0) = (ˆa(x0),αˆ(x0),βˆ(x0)) = (eT1H(x0, h)aY,eT1H(x0, h)αY,e T 1H(x0, h)βY). (24)
Note 5.1. If the observed inputs are symmetric, in a way that,
thenFˆ(x0)is also a symmetric triangular fuzzy number. In fact, if thei-th
sym-metric fuzzy output is denoted byYi = (ai, ci), where
ci =ai−αi =βi−ai
denotes the spread ofYi, then the spread vector of the n observed fuzzy outputs
can be expressed as:
cY =aY −αY =βY −aY.
According to (24) we get,
ˆ
a(x0)−αˆ(x0) = ˆβ(x0)−ˆa(x0) = e1TH(x0, h)cY
and, therefore,Fˆ(x0) = (eT1H(x0, h)aY,eT1H(x0, h)cY)is a symmetric
triangu-lar fuzzy number.
6
Predictive Possibilities in Grid Computing
Man-agement
Suppose there arenobservations,x1, . . . , xn, andlof them are different. Without a loss of generality we will use the notationx1, . . . , xlfor theldifferent observa-tions. LetX0 be a possibility distribution for the values of the (n+ 1)-th input. Let us denoteΠ(X0 =x0)the degree of possibility thatX0takesx0(Carlsson and Full´er 2001, 2003). We will show a method for predicting the possibility of the statement ”x0 isX0” where x0 is a non-negative number (new arrivals, failures, etc.). Let us introduce a notation,
vi =| {j :thej-th observation is equal toxi} |.
In our case the center will beai =xi, and the lower and upper limits are,
αi =xi− vi
n, βi =xi+ vi n.
Since we work with the symmetrical case, we shall use the notation ci =
vi n.
We should choose now the kernel function andh. We choose
h= 1 n, andK(x) = 1 √ 2πexp(− x2 2),
the Gaussian kernel. Let us introduce the notation Kh(|xn−x0|)) =ki.
We calculate now the matrixeT 1H(x0, h)by, (XT(x0)W)T(x0, h)X(x0) = Pl i=1ki Pl i=1ki(xi−x0) Pl i=1ki(xi−x0) Pl i=1ki(xi−x0) 2 That is, (XT(x0)W)T(x0, h)X(x0))−1 = 1
(Pli=1ki)(Pli=1ki(xi−x0)2)−(Pli=1ki(xi−x0))2 × Pl i=1ki(xi−x0) 2 −Pl i=1ki(xi−x0) −Pli=1ki(xi−x0) Pli=1ki
Let us introduce the notations,
l X i=1 ki =s, l X i=1 ki(xi−x0) = t, l X i=1 ki(xi−x0)2 =v.
With these notations we find,
(XT(x0)W)T(x0, h)X(x0))−1XT(x0) = v−t(x1−x0) . . . v−t(xl−x0) s(x1−x0)−t . . . s(xl−x0)−t and H(x0, h) = (XT(x0)W)T(x0, h)X(x0))−1XT(x0)W(x0, h) = k1(v−t(x1−x0)) . . . kl(v−t(xl−x0)) k1(s(x1−x0)−t) . . . kl(s(xl−x0)−t) , eT1H(x0, h) = k1(v−t(x1−x0)) . . . kl(v−t(xl−x0)) , eT1H(x0, h)aY = l X i=1 xiki(v−t(xi−x0)), eT1H(x0, h)cY = l X i=1 ciki(v−t(xi−x0)).
So we can write our estimation as,
ˆ
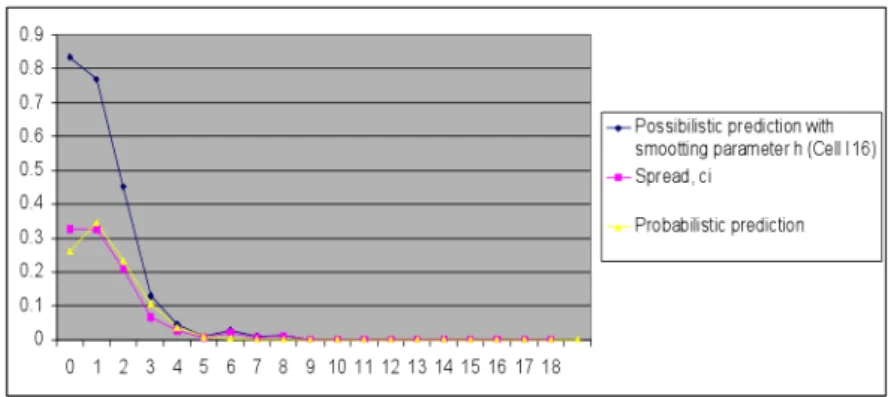
Figure 5: 4 Possibilistic and probabilistic prediction ofnnode failures for a com-puting task with a duration of 8 days on 10 nodes; 153 time slots simulated.
( l X i=1 xiki(v−t(xi−x0)), l X i=1 ciki(v −t(xi−x0))),
which is the predicted number of observations (of node failures) for the planning period we are considering. The corresponding estimate of the possibility for these observations to take place is given by, and the estimate for the possibility is,
Π(X0 =x0) = l X
i=1
ciki(v −t(xi−x0)). (25)
When we apply this model to a dataset (for instance the LANL) we start by se-lecting a sample ofnobservations (on node failures); then we find out how many of these observations are different and denote this number byl ; we want to use the two datasets to predict what then+ 1observation is going to be (the number of node failures); the possibility model is used to find out if that number is going to be0,1,2,3,4,5, . . .etc.; for this estimate the possibility model uses the ”most usual” numbers in the larger dataset and makes an estimate which is ”as close as possible” to this number; the estimate is a triangular fuzzy number, which means that we get an interval with a possibility distribution. The possibility model is a faster and more robust estimate of the n+ 1observation and will therefore be useful for online and real-time risk assessments with relatively small samples of data.
We have used this model – which we have decided to call a predictive possibility model – to estimate a prediction of how many node failures we may have in the next planning period given that we have used statistics of the observed number of node failures to build a base of Poisson-Gamma distributions (Carlsson and Weissman 2009).
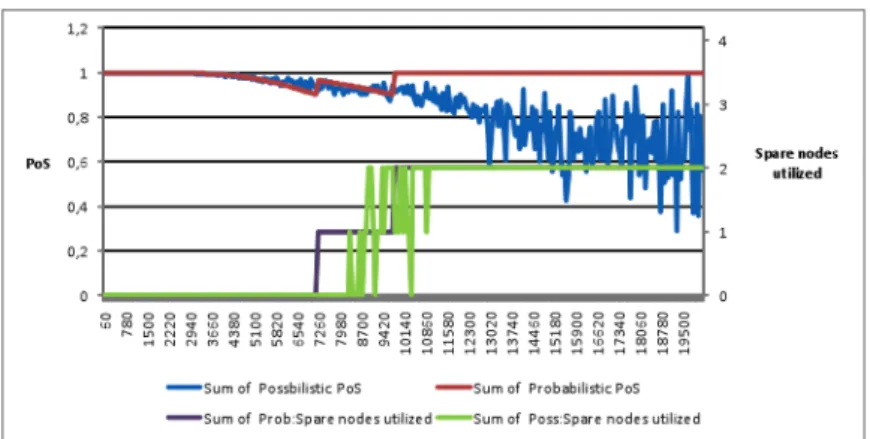
Figure 6: Comparison of probabilistic and possibilistic success for an SLA for computing tasks on a 6 node cluster with two spare nodes; simulated for 60-19500 minutes.
7
A lower limit for the probability of success of
com-puting tasks in a grid
In this Section we will consider an approximation to the probability that a partic-ular computing task in a grid is successful. This happens if there will always be at least a single idle node available in the system in the case of a node failure. In this paper we will show a lower limit for the probability of success of a computing task in a grid. We will use the Fr´echet-Hoeffding bounds for copulas to show a lower limit for the probability of success of a computing task in a cluster (or a Grid).
Copulas characterize the relationship between a multidimensional probability func-tion and its lower dimensional margins. A two-dimensional copula is a funcfunc-tion C: [0,1]2 →[0,1]which satisfies
• C(0, t) = C(t,0) = 0
• C(1, t) = C(t,1) =tfor allt∈[0,1]
• C(u2, v2)−C(u1, v2)−C(u2, v1) +C(u1, v1) ≥ 0for allu1, u2, v1, v2 ∈
[0,1]such thatu1 ≤u2 andv1 ≤v2.
Equivalently, a copula is the restriction to[0,1]2of a bivariate distribution function whose margins are uniform on [0,1]. The importance of copulas in statistics is described in the following theorem, Equivalently, a copula is the restriction to
[0,1]2of a bivariate distribution function whose margins are uniform on[0,1]. The importance of copulas in statistics is described in the following theorem (Sklar 1959):
Theorem 7.1(Sklar, [26]). LetXandY be random variables with joint distribu-tion funcdistribu-tionH and marginal distribution functionsF andG, respectively. Then there exists a copulaCsuch that
H(x, y) =C(F(x), G(y)),
Moreover, if marginal distributions, say,F(x)andG(y), are continuous, the cop-ula function C is unique. Conversely, for any univariate distribution functions
F and G and any copula C, the function H is a two-dimensional distribution function with marginalsF andG.
Thus copulas link joint distribution functions to their one-dimensional margins and they provide a natural setting for the study of properties of distributions with fixed margins. For further details, see Nelsen (1999) For any copulaCwe have,
W(u, v) = max{0, u+v−1} ≤C(u, v)≤M(u, v) = min{u, v}.
In the statistical literature, the largest and smallest copulas,M andW are gener-ally referred to as the Fr´echet-Hoeffding bounds. Let us recall that in (17) we have the notation P(success) asP(S = 1)and P(failure) asP(S = 0); furthermore, let us use the abbreviation less-than-m-anytime fir the event less than mfree nodes available at any point of time. Then we can rewrite (17) as,
P(success) = 1−P(failure)
= 1− mmax
X
m=1
P(mfailures occur & less-than-m-anytime)
= 1− mmax
X
m=1
P(mfailures occur)P(less thanmfree nodes available)
≥1− mmax
X
m=1
P(mfailures occur)P(less-than-m-anytime)
≥1− mmax X m=1 P(mfailures occur) × t∗ X j=1
P(j−1≤the length of a task< j,less-than-m-anytime)
+P(the length of a task≥t∗,less-than-m-anytime)
≥1− mmax X m=1 P(mfailures occur) × t∗ X j=1
P(the length of a task < j,less-than-m-anytime)
+P(the length of a task≥t∗,less-than-m-anytime)
Let us introduce the following notations G(m) = P(less-than-m-anytime) and F(t) = P(the duration of a task is less than t). Let t∗ be chosen such that 1 − F(t∗)>0.995. Furthermore, denote the copula ofF andGbyH, where
H(t, m) =P(the duration of a task is less than t, less-than-m-anytime). Then using the Fr´echet-Hoeffding upper bound for copulas we find that,
P(success)≥1− mmax X m=1 P(mfailures occur) × t∗ X j=1 min Γ(b/2) Γ(b−1 2 )Γ(1/2) 1 (b+ 1)s2 12 1 + 1 (b+ 1)s2 (j−¯j) 2 −2b ,
P(less thanmfree nodes at any time point)
+P(the length of a task is ≥t∗,less-than-m-anytime)
| {z }
≤0.005
If we summarize these results we get (Carlsson et al. 2009), P(success)≥1− mmax X m=1 P(mfailures occur) × t∗ X j=1 min Γ(b/2) Γ(b−21)Γ(1/2) 1 (b+ 1)s2 12 1 + 1 (b+ 1)s2 (j −¯j) 2 −b2 , P(less-than-m-anytime) .
Now we can use the new model as an alternative for predicting the number of node failures and use it as part of the Bayes model for predictive probabilities. In this way we will have hybrid estimates of the expected number of node failures -both probabilistic and possibilistic estimates. An RP may use either one estimate for his risk assessment or use a combination of both. We carried out a number of validation tests in order to find out (i) how well the predictive possibilistic models can be fitted to the LANL dataset, (ii) what differences can be found between the probabilistic and possibilistic predictions and (iii) if these differences can be given reasonable explanations. The testing was structured as follows:
•5 time frames for the possibilistic predictive model with a smoothing parameter from the smoothing function:h= 382.54×Nr of timeslots−0.5325
•5 feasibility adjustments from the hybrid possibilistic adjustment model to the probabilistic predictive model
In the testing we worked with short and long duration computing tasks sched-uled on a varying number of nodes and the SLA probabilities of failure estimates remained reasonable throughout the testing. The smoothing parameter h for the possibilistic models should be determined for the actual cluster of nodes, and in such a way that we get a good fit between the probabilistic and the possibilistic models. The approach we used for the testing was to experiment with combina-tions of h and then to fit a distribution to the results; the distribution could then be used for interpolation. We run the tests for all the RP1-RP4 scenarios (Carlsson and Weissman 2009) but here we are showing only results for the RP1 scenario (cf. fig. 5-6) in the interest of space.
8
Summary and Conclusion
We developed a hybrid probabilistic and possibilistic technique for assessing the risk of an SLA for a computing task in a cluster/grid environment. In the hybrid model the probability of success is estimated higher than in the pure probabilis-tic one since the hybrid model takes into consideration the possibility distribution for the maximal number of failures derived from the RP’s observations. The hy-brid model shows that we can increase or decrease the granularity of the model as needed; we can also approximate the probability that a particular computing task is successful by introducing an upper limit for the number of failures We note that this upper limit is an estimate which depends on the history of the nodes being used and can be calibrated to ”a few” or to ”many” nodes. The probabilistic mod-els scale from 10 nodes to 100 nodes and then on to any (reasonable) number of nodes; in the same fashion also the possibilistic models scale to 100 nodes and then on to any (reasonable) number of nodes. The RP can use both the probabilis-tic and the possibilisprobabilis-tic models to get two alternative risk assessments and then (i) choose the probabilistic RA, (ii) the possibilistic RA or (iii) use the hybrid model for a combination of both RAs – which is a cautious/conservative approach.
References
[1] Beaumont MA, Rannala B (2004) The Bayesian revolution in genetics. Na-ture Reviews Genetics, 5(4): 251-261 doi:10.1038/nrg1318
[3] Brandt JM, Gentile AC, Marzouk YM, P´ebay PP (2005) Meaningful Sta-tistical Analysis of Large Computational Clusters. In: Proceedings of the 2005 IEEE International Conference on Cluster Computing, Burlington, MA, pp 1-2 doi:10.1109/CLUSTR.2005.347090
[4] Carlsson C, Full´er R (2001) On possibilistic mean and variance of fuzzy numbers. Fuzzy Sets and Systems, 122(2):315-326 doi:10.1016/S0165-0114(00)00043-9
[5] Carlsson C, Full´er R (2002) Fuzzy Reasoning in Decision Making and Op-timization. Springer Verlag, Berlin/Heildelberg
[6] Carlsson C, Full´er R (2003) A Fuzzy Approach to Real Option Val-uation. Fuzzy Sets and Systems, 139(2):297-312 doi:10.1016/S0165-0114(02)00591-2
[7] Carlsson C, Weissman O (2009) Advanced Risk Assessment, D4.1. The AssessGrid Project, IST-2005-031772, Berlin
[8] Carlsson C, Full´er R, Mezei J (2009) A lower limit for the probability of success of computing tasks in a grid. In: Proceedings of the Tenth Inter-national Symposium of Hungarian Researchers on Computational Intelli-gence and Informatics (CINTI 2009) Budapest, Hungary, pp 717-722 [9] Czajkowski K, Foster I, Kesselman C, Sander V, Tuecke S (2002) SNAP: A
Protocol for Negotiating Service Level Agreements and Coordinating Re-source Management in Distributed Systems. Revised Papers from the 8th International Workshop on Job Scheduling Strategies for Parallel Process-ing. Lecture Notes In Computer Science, Vol. 2537, pp 153-183
[10] Czajkowski K, Foster I, Kesselman C (2005) Agreement-Based Resource Management. Proceedings of the IEEE, 93(3):631-643 doi:10.1109/JPROC.2004.842773
[11] Diamond P (1988) Fuzzy least squares. Information Sciences, 46(3):141-157 doi:10.1016/0020-0255(88)90047-3
[12] Doucet A, de Freitas JFG, Gordon NJ (2001) Sequential Monte Carlo meth-ods in practice. Springer Verlag, New York
[13] Iosup A, Jan M, Sonmez OO, Epema, DHJ (2007) On the Dynamic Resource Availability in Grids. In: Proceedings of the 8th IEEE/ACM International Conference on Grid Computing (GRID 2007), pp 26-33 doi:10.1109/GRID.2007.4354112
[14] Jaynes ET (2003) Probability theory: The logic of science. Cambridge Uni-versity Press, Cambridge
[15] Lintner J (1965) The Valuation of Risk Assets and the Selection of Risky Investments in Stock Portfolios and Capital Budgets. Review of Economics and Statistics, 47(1):1337
[16] Liu Y, Ng, AHH, Zeng L (2004) QoS Computation and Policing in Dy-namic Web Service Selection. In: Proceedings of the 13th international World Wide Web (WWW2004), pp 6673 doi:10.1145/1013367.1013379 [17] Long, D, Muir R, Golding R (1995) A Longitudinal Survey of Internet
Host Reliability. In: Proceedings of the 14TH Symposium on Reliable Dis-tributed Systems, pp 2-9
[18] Magana E, Serrat J (2007) Distributed and Heuristic Policy-Based Re-source Management System for Large-Scale Grids. Lecture Notes in Com-puter Science, Vol. 4543, pp 184-187
[19] Markowitz HM (1952) Portfolio Selection. Journal of Finance, 7(1):7791 [20] Nelsen RB (1999) An Introduction to Copulas. Springer, New York
[21] Plank JS, Elwasif WR (1998) Experimental Assessment of Work-station Failures and Their Impact on Checkpointing Systems. In: 28th International Symposium on Fault-Tolerant Computing, pp 48-57 doi:10.1109/FTCS.1998.689454
[22] Raju N, Gottumukkala N, Liu Y, Leangsuksun CB (2006) Reliability Anal-ysis in HPC Clusters. In: High Availability and Performance Computing Workshop
[23] Robert CP, Casella G (2005) Monte Carlo Statistical Methods. Springer, New York
[24] Schroeder B, Gibson GA (2006) A Large-Scale Study of Failures in High-Performance Computing Systems. In: DSN2006 Conference Proceedings, Philadelphia , pp 249-258 doi:10.1109/DSN.2006.5
[25] Schultz TR (2007) The Bayesian revolution approaches psychological development. Developmental Science, 10(3):357-364 doi:10.1111/j.1467-7687.2007.00588.x
[26] Sklar A (1959) Fonctions de R´epartition `an Dimensions et Leurs Marges. Paris, France: Publ. Inst. Statist. Univ. Paris, 1959(8):229-231
[27] Wang N, Zhang W-X, Mei C-L (2007) Fuzzy nonparametric regres-sion based on local linear smoothing technique. Information Sciences 177(18):3882-3900 doi:10.1016/j.ins.2007.03.002
[28] Zadeh LA (1965) Fuzzy Sets. Information and Control, 8(3):338-353 doi:10.1016/S0019-9958(65)90241-X
University of Turku
• Department of Information Technology
• Department of Mathematics
˚
Abo Akademi University
• Department of Computer Science
• Institute for Advanced Management Systems Research
Turku School of Economics and Business Administration
• Institute of Information Systems Sciences
ISBN 978-952-12-2430-0 ISSN 1239-1891
![Figure 1: Prediction of node failures [Prob of Failure: 0.1509012] with 136 time slots of LANL cluster data for computing tasks running for 9 days, 0 hours.](https://thumb-us.123doks.com/thumbv2/123dok_us/993239.2630546/17.892.188.704.133.325/figure-prediction-failures-prob-failure-cluster-computing-running.webp)