Domain Oriented Semantic Web based Personalized Search Engine
Shruti Kohli
Department of Computer Science BIT, Noida
Sonam Arora
Department of Computer Science BIT, Noida
Abstract—Present market is dominated by such Search Engines which are working on keyword based querying system. This becomes useless and leads to wastage of user’s time if he is not aware of the keywords which are used to index desired relevant pages. For example, user enters keyword ‘Book’, now Google will show results for both ‘Reading any book’ and ‘Book a Hotel’. That means user has to look into the contents of the web pages to shortlist relevant pages which he needs. The same problem exists in case of image search engines. If query is search for images of ‘hotel in Delhi’, image result set will contain irrelevant as well relevant images. Now solution is needed where machine will itself divide the result into relevant and irrelevant images and then showing the relevant ones to the user. But this solution is not feasible one because it then has to check the content of image using image processing techniques and then checking for similarity between all the images which is not implementable for millions of records worldwide. Another solution is Semantic Web Technologies. It is an extension of the current web that allows the meaning of information to be precisely described which can be well understood by computer as well as user. Ontology is very important ingredient of Semantic Web and in this work Ontology for Hotel domain is used. User will be provided easy to use interface to query hotel ontology. Technologies used are SPARQL query language and JENA API for searching user query inside ontology. In this work focus is given over preserving user’s preferences while displaying results on the web page. Challenge was on dynamically loading the hotel dataset into ontology in RDF format. This was done using Semantic Tool which internally uses Google AJAX API for populating latest results from Internet. Advantage of using Semantic Web is that it results in only relevant images, which in turn increases Precision and Recall rates of search engine.
Keywords-SPARQL; RD; Semantic Web; Web3.0
I. INTRODUCTION
Nowadays, whatever information user needs, he gets it online, anywhere and anytime. If any user wants to visit some place, he would like to search information about that place, hotel available, weather etc beforehand. User may also like to look at images of hotels before checking their website. For this, lots of search engines are available in today’s market online. User needs to enter keyword for the query he is having and then he is flooded with images that is available online. But the problem is that information which is displayed contains relevant as well as irrelevant results. Now user’s work increases in separating his desired set of images from the pool of results displayed. This leads to wastage of time and energy. This measure which checks the efficiency of search engine in terms of number of relevant documents returned is done by two factors, Precision and
Recall. The above said weakness of today’s search engine leads to low precision and recall parameters.
This weakness can be resolved to much extent using Semantic Web Technologies. This technology works by extending the current existing web with semantics that provides meaning to that web image or document. This meaning is defined in a way that understood by machine thus reducing the effort of users in searching for relevant images. In Semantic Technologies, information is represented in a new W3C standard called Resource Description Framework (RDF). Now in Semantic technologies, ontology is main ingredient. Resource Description Framework has recommended well defined format for representing ontology.
Currently existing formats are RDF/XML, OWL, Turtle etc. Currently research on semantic technologies is in beginning stage, therefore traditional search engines like Google, Bing, Yahoo etc are still dominating the market. Let’s take illustration of query to search for “Taj Mahal”. Now the results displayed by traditional search engines will display thousands of images for “Taj Mahal in Agra” as well as “Taj Mahal casino in Atlantic, USA” Search engine will not refine the result for user. User himself has to sift through the result set to find relevant results for his use. Information retrieval in current scenario relies only on keyword searches using Google, Yahoo, Bing etc or based on simple metadata such as that of an RSS. Moreover, there is no provision to generate personalized searches easily, so users need to think and write search keywords that match their own requirements correspondingly. Such a process of searching is time consuming and requires lot of effort on human part. That means if users does not understand the keywords to be used for searching, then he can’t perform relevant information retrieval.
Now semantic searching increases this efficiency by providing only relevant results to the user. It represents the data available over internet in format of ontology, which contains the description of information using metadata. User does not need to apply effort to think for keywords that will give them the result they desire, instead the user can simply provide the search engine with whatever information it has by selecting domain.
The core idea of domain based search engine is to describe query in the form of domain description. For this user need to build a query type that is well understood by Semantic Web. This paper proposes an architecture where queries are not build using natural langue, but an easy to use user interface that help users to build complex queries they want.
II. CHALLENGES
Keyword based search is useful especially to a user who knows what keywords are used to index the images as they can easily define queries. This approach becomes problematic when the user is not aware about the way to write query such that desirable results only appear because for that he must know the semantic concepts that are used in that particular domain in which he is interested. And therefore after user enters the query, he is returned with some irrelevant images along with relevant ones.
To check this efficiency of search engine, two parameters are available that is Precision and Recall. Consider Figure 1.
Figure 1. Precision vs. Recall
Let A be number of relevant records retrieved, let B be number of relevant records not retrieved and C be the number of irrelevant records retrieved.
x Precision: Percentage of returned pages that is relevant. Or in other words the capability of minimizing the number of irrelevant links returned to the users.
Precision: - A*100/ (A+C)
x Recall: Percentage of relevant pages that is returned. Or in other words the capability of maximizing the number of relevant links returned to the users.
Recall: -A*100/ (A+B)
All search mechanism till date performs the function where precision and recall percentage is too low. For example, consider a situation when User enters “images of all hotels in Delhi” query on Google, now search results may
contain lots of unwanted image result which are of no interest to the user. Consider Figure 2.
Figure 2. Google images results
Semantic Web based search aims to provide better precise and recall rates as compared to keyword based search. Challenge is to create a domain based semantic web search engine which is highly user friendly and provide advance search options with the help of various parameters that a user can think of. User friendly in a sense that user need not think of appropriate keyword that might give them their desired result, instead the user can simply provide the search engine with whatever information it has by selecting provided options.
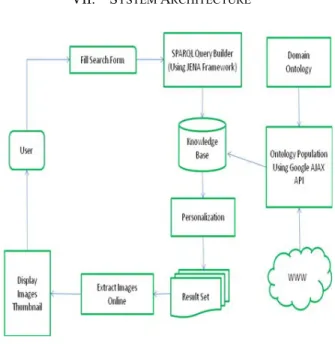
Now it is clear that Ontology is the main ingredient of Semantic Web and it is build for a particular domain. This work is using domain for Hotels available in the continent of Asia and Europe. Now the challenge is to load the RDF data in Hotel Ontology dynamically. For this, semantic tool is developed. This semantic tool is making use of Google AJAX API internally to fetch results from Google search engine. Now over these results, it employs URL checking to separate relevant results from irrelevant results. These relevant search results are then transformed into RDF format and then populated in Hotel ontology. From the given interface user chooses the desired options and then sends the query to this search engine, which in turn provides only the reliable results from the ontology.
Another challenge involved was to display results to the users such that their preferences are taken into account. For this user click history is tracked by the system.
Advantage of using Semantic Web is that user shouldn’t be aware of the concepts supporting the search to use it. Their experience should be as close as the one they currently have with the current web and the search engines they use daily.
Some of the latest works relating semantic areas are:- WANG Yong-gui and JIA Zhen [1] gave introduction to Semantic Web and its Mining and then proved that their integration can bring lot of effectiveness in Web Mining. For that they used a five step process which actually integrated Web mining with Semantic technologies.
Jiang Huiping [2] proposed a semantic web search model to enhance efficiency and accuracy of IR for unstructured and semi structured documents. He used Ranking Evaluator to measure the similarity between documents with semantic information for rapid and correct information retrieval. He introduced Search Arbiter to judge whether the query is answered by Keyword based Search Engine or Ontology Search Engine. He gave just a conceptual architecture of Semantic Web Information Retrieval System.
Saman Kamran and Fabio Crestani [3] proposed a method for developing reliable ontology using the potential users available on Social Networking Sites. They created a seven step model which takes their input and then using Wikipedia Link Based Measure (WLM) and Cosine Similarity, they calculated semantic similarity score of their inputs. This model is under construction and no evaluation available yet.
Eero Hyv¨onen, Avril Styrman and Samppa Saarela [4] in their paper have developed a method of annotating the images. They have used Promotion event images and annotated them so that an ontology structure can be established for that event. This ontology will then help in answering the queries of the user.
Waqas Ahmad and Ch Muhammad Shahzad Faisal [5] proposed a context based search, done over 300 pictures of 5 personalities, which were gathered from Google, over various contexts like playing, attending meeting etc. These images were manually annotated to make search more efficient.
Noman Hasany and Mohd. Hasan Selamat [6] presented a system where ontology for hotels is used for searching and user is given a natural language query platform for giving the queries. This paper provides the detailed construction of the Hotel Ontology using knowledge base of Malaysian hotels.
Tuan-Dung CAO, Thanh-Hien PHAN and Anh-Duc NGUYEN [7] presented a system called STAAR (Semantic Tourist Information Access and Recommending). They used Tourist ontology and helped the user in making query to it through mobile platform. In addition they also gave algorithm for suggesting travel route relevant to both criterions: itinerary length and user interest.
K.Palaniammal, Dr. M. Indra Devi and Dr.S.Vijayalakshmi [8] in their paper contributed towards semantic based searching which also gives importance to user’s priority while searching in their required domain. This system keeps a track of user’s traits like age, current status etc to understand his habits and accordingly proposes him places which he may like to visit.
P.Sheba Alice, A.M.Abirami and A.Askarunisa [9] in their paper proposed a tool enhancing a refined search retrieving only the most relevant links eliminating the other links using semantic web technologies. A user’s searched text is stemmed and compared with attributes defined in ontology.
Hannah Bast, Florian Bäurle, Björn Buchhold and Elmar Haussmann [10] in their paper discussed the pros and cons of full-text search on the one hand and ontology based search on the other hand. If user has full-text query then it can work well when relevant documents contain the keywords or
simple variations of them in a prominent way. In case user has entity oriented queries then they will work well only with ontology. It highlighted that the most challenging task is construction of ontology on any particular domain.
III. GOAL OF RESEARCH
The goal proposed in this research work is to develop system architecture for semantic web search engine for images over a specific domain that is Hotels.
In this system, ontology will be the knowledge base which will be trained in any specification like RDF, OWL or Turtle.
The process of training the ontology with reliable and latest data is done using Semantic Tool. This is Java based tool which internally fetch information from Google using Google AJAX API.
Various attributes of class Hotel are prepared on the basis of Location, Ratings, and Rate etc. User’s preferences are been tracked by the system which internally count user’s clicks per image.
User will provide query using an easy to use interface. System will Search directly in the ontology itself after which images of the relevant Hotels will be displayed sorted by user’s preferences, thus giving a self learning framework to user similar to that of Google image search.
IV. CURRENT SYSTEM ISSUES
The above proposed search system based on semantic web does not takes into consideration the user behaviour while returning the search results, which is an important requirement in order to make user aware of the most popular as well as reliable hotel images available till date over Internet. So this semantic search system focuses on using the image’s click history as a tool to track the popularity of an image.
Secondly this system will always look for latest images available online to be populated in the ontology which is done here using Google AJAX API.
V. PROPOSED SYSTEM
Here in this proposed system, a semantic web architecture has been designed and developed that can relieve the users from the overburden of doing a lot of keyword based search before getting the desired result.
Data in the ontology is in Turtle format. In this system, latest data about hotel gets populated inside ontology using Google Ajax API. It is basically Google JavaScript API which helps in loading the online search results which includes metadata as well as images directly into the web application.
This system takes the user query in the form of parameters related to that domain in a user friendly environment, develop a SPARQL query and using JENA API will give the reliable results to the user.
On clicking over the image user is redirected to the corresponding host website to which this image belongs. This internally updates the user’s preference in the
knowledge base. Next time in the results, images will be displayed in the order of user’s preferences.
VI. ONTOLOGY ARCHITECTURE
The Hotel ontology architecture used is shown below in Figure 3 in graphical format.
Figure 3. Ontology Chart
Following Turtle code gives a small skeleton for Hotel Ontology used in this system.
@prefix : <http://example/> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @prefix dc: <http://purl.org/dc/elements/1.1/> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
:1 dc:title "Hotel Green Park Chennai" ; rdfs:urls "hotelgreenpark.com/chennai/"; rdfs:imgurls "hotelgreenpark.com/chennai/images/animation.gif"; rdfs:continent "Asia"; rdfs:country "India"; rdfs:typeofroom “Double"; rdfs:typeofhotel "Five"; rdfs:rate "Expensive";
rdfs:facility "Restaurant Swimming Pool Fitness Center";
rdfs:facility2 "Internet AC TV Refrigerator King Bed";
.
:2 dc:title "Raya Inn Rajasthan" ; rdfs:urls "rayainn.com/"; rdfs:imgurls "rayainn.com/main-images/_DSC1445.JPG"; rdfs:continent "Asia"; rdfs:country "India"; rdfs:typeofroom "Twin"; rdfs:typeofhotel "Three"; rdfs:rate "Reasonably"; rdfs:facility "Restaurant";
rdfs:facility2 "Internet AC TV Refrigerator"; .
Here this ontology contains triples that are represented as Subject-Predicate-Object. For example, there is a hotel 1 which has title Hotel Green Park Chennai. So in this Subject Hotel 1 has predicate title which has object value as “Hotel Green Park Chennai”. That’s how the whole ontology is built. This ontology contains latest information which is constructed by using Google AJAX API in this system.
VII. SYSTEM ARCHITECTURE
Figure 4. Architecture
VIII. ALGORITHM A. Initial Setup:-
1) Training of Hotel Ontology with image URL is done using Semantic Tool.
xTool takes input URL through Google AJAX API based on the user's search query
2) Returned URLs are formatted as per the requirement of system, which are then used as input for the ontology
3) Using the above steps, this system will dynamically load the ontology with reliable information about hotels in Turtle format.
xIn this work, ontology contains latest information about hotels in continent of Asia and Europe. 4) For experimentation, system is trained with 200
5) For all images in the ontology an important parameter rank is used (initially set to 0).
xThis will be changed gradually while the system is used by the user
B.
Algorithm:-Pre requisite: - Hotel Ontology Search evaluation {
1) System displays the query interface to the user. 2) The input parameters given by user are then converted to SPARQL command.
3) System will then search this SPARQL query in the existing ontology using JENA API.
4) The result set obtained after matching the query, are then sorted according to the user's preferences recorded cumulatively by this search engine.
5) Users preference is recorded in the knowledge base by the system itself in the rank parameter.
6) This rank gets updated dynamically according to the following userClick algorithm.
7) userClick algorithm:-
xInitially all the images are having rank 0, so they are displayed in the order in which they are listed in the ontology.
xWhen the user clicks over any image, its rank gets incremented that indicates the current user's preference for that image.
xIn the next search, images will be sorted on the basis of their rank.
8) Now the result set returned contains the images sorted according to their rank as explained above.
9) These images as thumbnails are displayed on the web page, in order of their rank.
}
IX. TRAINING THE SYSTEM
The data of various users is collected and organized around ontology of hotel. The system has a large database of images belonging to various categories. The process of collecting latest data for hotel in the ontology is done automatically using Google AJAX API.
All the details along with the URL of image file and its category is stored in the ontology. The category of an image is identified manually and it can be anything like Location, Star Ratings, and Price etc.
X. IMPLEMENTATION
Here Semantic Tool is used to train this Hotel Ontology with the reliable data about various hotels available in Asia and Russia. This system is tested on 200 hotels. This implementation is just a simulation and can be easily extended for large dataset.
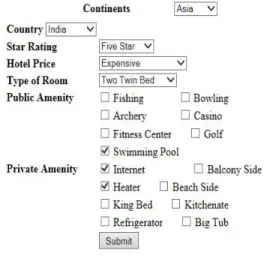
Now, user is provided with easy to use interface shown below in Figure 5 which has options that are used in his query.
Figure 5. Query Interface
For example user selects Continent as “Asia”, Country as “India”, Star Rating as “Five”, Hotel Price as “Expensive”, Type of Room as “Two Twin” and can select facilities from the above given list. This interface when submitted to the system will create a SPARQL query.
SELECT ?doc ?title ?urls ?imgurls WHERE
{ ?continent pf:textMatch "Asia" . ?country pf:textMatch "India" . ?typeofhotel pf:textMatch "Five" . ?typeofroom pf:textMatch "Twin" . ?rate pf:textMatch "Expensive" .
?facility pf:textMatch " Swimming Pool" . ?facility2 pf:textMatch " Internet Heater" . ?doc dc:title ?title .
?doc rdfs:rate ?rate .
?doc rdfs:typeofhotel ?typeofhotel . ?doc rdfs:typeofroom ?typeofroom . ?doc rdfs:facility ?facility .
?doc rdfs:facility2 ?facility2 . ?doc rdfs:continent ?contnent . ?doc rdfs:country ?country . ?doc rdfs:urls ?urls . ?doc rdfs:imgurls ?imgurls }
This query will search in the Hotel Ontology and will produce a list of hotels which satisfies above given factors. From that list it will check each image’s rank according to proposed algorithm. Now it will display the resulting images in order of their rank. That is most popular image among that result set will be displayed first and then the next popular and so on.
The example shown above is tested on small ontology of 200 hotels, following figure 6 shows subset of result images:-
Figure 6. Query Result
Here in this system, names of hotels are also displayed along with their images. User can click over any image of his choice and he will be directed to that hotel link.
XI. RESULTS AND DISCUSSION
User tested the system with some complex image queries for example “Images of Five Star Hotel in India with Swimming Pool TV AC Internet”. When user manually checked in the knowledge base of 200 hotels, the number of relevant hotels which matched his query was 44. But, after running his query through this Semantic Search System, he found 47 images.
Reason for this deviation is that this system works on union approach. Suppose use selects 2 facilities i.e. facility1 and facility2, then system should return images of only those hotels which satisfy both of them. But this system returns images of hotels which satisfies any of them. This is done with an intention that is a person generally takes decision for hotels after exploring their images and all available facilities by surfing through its website. So he may like to see even those hotels which are only providing facility1 but not facility2 along with other miscellaneous facilities.
Now according to manual checking relevant results are 44. System returned total of 47 results out of which according to the user’s perspective irrelevant records are 3.
So Precision comes out to be {44 / (44+3)} = 0.93 which is pretty good.
When same query is tested on keyword based search engine, it gave Precision of 0.075 which is very poor when compared with Precision given by Semantic based search engine that was 0.93.
On similar basis, Average precision was calculated for 5 simple queries and keyword based search gave average Precision of 0.165 whereas Semantic based Search gave average Precision of 0.95 which is a significant improvement over existing keyword based search engines.
Now Recall in this system is dependent on the strength of the knowledge base that is Ontology. Recall compares the number of relevant results returned by the system with total number of relevant hotels that actually exist. If the ontology is prepared in such a way that it contains all the relevant hotels images, then this system will surely give Recall = 1.
In this system, ontology having 200 records is used. It can be easily expanded to large dataset and its Recall will be nearing to 1 always.
XII. CONCLUSION
In this research, a model is proposed which will solve the problem of irrelevancy on the search results displayed by current image search engines using the semantic web technologies focusing on single domain that is of Hotels. This model has been tested on limited number of hotels and it has been observed that the two measures that are Precision and Recall improve significantly over currently used keyword based search engines because this model always retrieves relevant results. This improvement will surely persist for even large number of hotels.
This model can be extended for multiple domain searches to give a fully fledged experience similar to that of currently used search engines but with improved precision and recall rates.
REFERENCES
[1] WANG Yong-gui1 and JIA Zhen, “Research on Semantic Web Mining” , 2010 International Conference On Computer Design And Appliations (ICCDA 2010), 978-1-4244-7164-5 2010 IEEE. [2] Jiang Huiping, “Information Retreival and Seamtic Web”, 20I0
Technology (ICEIT 2010), 78-1-4244-8035-7/10 2010 IEEE V3-461. [3] Saman Kamran and Fabio Crestani, “Defining Ontology by Using
Users Collaboration on Social Media”, CSCW 2011, March 19–23, 2011, Hangzhou, China. ACM 978-1-4503-0556-3/11/03.
[4] Eero Hyv¨onen, Avril Styrman and Samppa Saarela , “Ontology Based Image Retrieval”, University of Helsinki, Department of Computer Science.
[5] Waqas Ahmad and Ch Muhammad ShahzadFaisal, “Context Based Image Search”, 978-1-4577 -0657 -8/11/$26.00 © 2011 IEEE . [6] Noman Hasany and Mohd. Hasan Selamat, “Answering UserQueries
from Hotel Ontology for Decision Making”, 978 -1-4577-1481-8/11/$26.00 ©2011 IEEE 123 .
[7] Tuan-Dung CAO, Thanh-Hien PHAN and Anh-Duc NGUYEN, “An
Ontology based approach to data representation and information
search in Smart Tourist Guide System”, 978-0-7695-4567-7/11 $26.00 © 2011 IEEE DOI 10.1109/KSE.2011.33.
[8] K.Palaniammal, Dr. M. Indra Devi and Dr.S.Vijayalakshmi, “An
Unfangled Approach to Semantic Search for E-Tourism Domain”,
978-1-4673-1601-9/12/$31.00 ©2012 IEEE 130 ICRTIT-2012. [9] P.Sheba Alice, A.M.Abirami and A.Askarunisa, “A Semantic Based
Approach to Organize eLearning through efficient Information
Retrieval for Interview Preparation”, 978-1-4673-1601-9/12/$31.00 ©2012 IEEE ICRTIT-2012.
[10] Hannah Bast, Florian Bäurle, Björn Buchhold and Elmar Haussmann,
“A Case for Semantic Full-Text Search”, JIWES ’12 August 12 2012, Portland, OR, USA Copyright 2012 ACM 978-1-4503-1601-9/12/08 ...$15.00.
[11] Shruti Kohli and Sonam Arora, “Topic Specific Concept Matching Based Web Semantic Search Engine”, International Journal of Computer Science & Engineering 2013.