An Overview of the Current Classification
Techniques in Intrusion Detection
Buthina Al-Dhafian,Iftikhar Ahmad, Abdullah Al-Ghamid Software Engineering Department, King Saud University
Riyadh, Saudi Arabia
[email protected],[email protected],[email protected],
Abstract—During the last decade, a lot of attention has been given to intrusion detection systems (IDSs) as another security tools used to detect attacks and make working in computer systems and network more efficient and stable. However, the current challenge in these systems is consider into which is an optimal classification technique that must be used to detect intrusion in high level of accuracy. Many classification techniques have been designed in IDSs to detect attacks, where the accuracy of IDSs depends mainly on them. Numbers of studies have been proposed to enhance the performance of IDSs by increased the detection rates (DR) and decreased the false alarms rats (FAR). In this paper, we present a review of the current classification techniques that are used during designing IDSs. We also provide a review of the current dataset that are used to train and test selected classifier. The main goal of our research is to provide a review of the current classification techniques in intrusion detection in order to enhance the performance of classifier by highlighting different issues, which need to be solved. This paper seeks to help the researchers to develop an optimal classification technique by eliminating the issues that reduces the accuracy of IDSs.
Keywords—Intrusion detection; Intrusion detection systems; Classification techniques; Datasets
I. INTRODUCTION
Nowadays, the basic design of security in computer systems and network has been changed due to the huge number of attacks, which appeared because the increased in the numbers of internet users. Despite the existing tools of security systems, which protect these attacks such as firewalls, antivirus, and data encryption, it still hard to ensur that computer systems and network will be free of security flaws. IDSs are emerged as another technique which have increased the tools of security systems to monitor, identify, and detect intrusions in high level of accurecy [1].
The machanism of IDSs depends on the observation to classfiy data into normal or abnoraml behavoir. When an intrusion or suspect pattern is observed, an alarm is activated in order to take measures to maintain the integrity of the system [2]. Many IDSs have been designed to detect intrusions, although, maintaining the accuracy considered the main issue, which is mainly depends on optimal classifier selection [3]. Find the optimal classification techniques in IDSs considered as a critical issue as well, such that each classifier required to be trained with sample data in order to recognize the patterns and then it is tested with other samples in order to be efficient enough to perform well. Moreover, select the appropriate datasets, which are used in the testing and the training process
considered as a dilemma [4], which is used to evaluate IDSs. Therefore, a number of studies have been proposed using multiple of classification techniques in order to design IDSs with high level of accuracy. The main goal of our research is to present a review of the current studies that aim to improve classification in IDSs by increasing the DR and decreasing the FA using optimal classifier technique. Moreover, to highlight different issues that need to be solved during develop an optimal classification technique in IDSs.
Besides this introductory section, the remaining of this paper is organized as follow. A background study in IDSs is given in section II. A review of current classification techniques in IDSs is presented in section III. An overview of the most popular standard datasets used in IDSs are explore in section IV. A comparative analysis is discussed in section V. Finally, conclusion is drown in section VI.
II. BACKGROUND
An intrusion can be described as any event that violates systems security, occurs by an intruder. An intrusion detection (ID) considered as one of the security systems’ tools, which is used to detect intrusion in computer systems and network based on the hypothesis that the behavior of an intruder and a legitimate user vary from each other. IDSs have appeared to deal with vulnerabilities of systems security, where they are designed as complementary rather than alternative tools to these systems. The first concept of ID appeared early 1980 [5], which emphasized on a single computer system followed by the actual work done by Denning in 1987 [6] at SRI International, where intrusion detection is extended to address multiple computers in a distributed system. Few years later, many IDSs ware proposed to serve on both sides of researches and commercial world. However, they have operated based on general architectural framework [1], [2]. The main component of this architecture is a detector (also known as analysis engine), which is responsible for classifying data to normal or abnormal behavior, and considered the basis to determine the accuracy of IDSs.
IDSs work to identify the suspect behavior based on three types of detection methodologies [2], [7]: (i) Misuse-based detection (MD), which is used mainly to detect intrusions according to the predefined pattern of known attacks, the accuracy of this type considered good and theoretically, it has a very low FAR, however it cannot detect new attacks. (ii) Anomaly-based detection (AD), where detect intrusions based on a reference model of the normal behavior of the monitored
system, it has the capability to detect unknown attacks, but the FAR it very high. (iii) Stateful protocol analysis (SPA), which detects intrusion based on predetermined profiles of accepted definitions of normal protocol activity for each protocol state, it differs from AD as it depends on vendor-developed universal profiles that determine how particular protocols work. These types of detection methodologies can perform separately or integrated into one system, known as hybrid IDS [8], which constructed to avail from multiple approaches and overcame many of the issues by producing a much stronger IDS.
On the other hand, IDSs have many types of technologies, which can be categorized based on the scope of detection. These categories are [7], [9], [10]: (i) Host-based IDSs which analyze the activities that flow into the host to identify attacks, (ii) Network-based IDSs which analyze network packets that come from the outside to detect attacks, (iii) Application-based IDSs a partial set of HIDS, responsible for monitoring and analyzing the activities that have took place inside a software application. (iv) Wireless IDSs [11] which monitor and analyze the protocols of wireless networks to identify shady activities, and (v) Network Behavior Analysis (NBA) IDSs which inspect network traffic or statistics on network traffic to identify suspicious behavire. Some of these technologies can be adopted with each other to be known as Mixed IDS (MIDS) with a view to improve DR and make systems as much as possible free from attacks.
III. CURRENT CLASSIFICATION TECHNIQUES IN INTRUSION DETECTION
In literature, numerous of studies have applied different classification techniques to design IDSs; some studies have deigned IDSs by using single techniques (such as neural network, fuzzy techniques, support vector machines, etc...), and the other hand, some studies have deigned IDSs based on combining different techniques (such as hybrid or ensemble techniques). A brief overview of the current classification techniques in IDSs is listed below:
A. Approach-1
Tong et al. [8] have been proposed a hybrid RBF/Elman neural network model to be used for both AD and MD, which can efficiently detect temporally dispersed and collaborative attacks. They used a radial basis function (RBF) network as a real-time pattern classification and they applied the Elman network to restore the memory of past events. Their model takes an output of RBF as input of Elman network, while an Elman network restore each output of RBF network by keep memory of past misuse events. For their experiments, they have used DARBA dataset. The results showed that, their model can detect intrusions with higher RD and lower FPR compared with other IDSs that used neural network techniques. Additionally, the ability to determined DOS and probing attacks in IDSs is enhanced.
B. Approach-2
A new approach, which called FC-ANN have been proposed by Wang et al. [3] with the aim to enhance detecting precision for low-frequent attacks, detecting stability as well as achieving higher DR and lower FPR. Feed-Forward neural
network (FFNN) and Fuzzy c-means clustering are used for designing their approach, which designed based on the following three phases. In the first phase, a fuzzy clustering technique is used to generate different training subsets to reduce the size and complexity, while in the second phase different ANNs are trained based on different training sets. Finally, in the last phase, a meta-learner, fuzzy aggregation module, is introduced to learn and combine the different ANN’s results in order to eliminate the errors of different ANNs. For their experiment, KDD CUP 1999 dataset were used for the evaluation purpose. The results have demonstrated that, their approach has the effectiveness especially for low-frequent attacks, i.e., R2L and U2R attacks in terms of detection precision and detection stability.
C. Approach-3
A SVM-based intrusion detection system has been proposed by Horng et al. [12] with the aim of shorten the training time as well as to improve the performance of SVM classifier. Their approach combines three methods, which are a hierarchical clustering algorithm, a simple feature selection procedure, and the SVM technique. KDD Cup 1999 dataset is used for their experiments for evaluation purpose. First, they used BIRCH clustering algorithm to transform the KDD Cup 1999 dataset to a smaller sized dataset. Then, they trained SVM classifiers based on the reduced dataset with abstract data points. Finally, they used “leave-one-out” procedure in order to remove unimportant features from training set. The results have showed that the proposed system had the best performance to detect intrusion, practically; it had superior performance in the detection DoS and Probe attacks.
Approach-4
Ahmad et al. [13] have been proposed an intrusion detection system in order to overcome performance issues by using feature subset selection based on multilayer Perceptron (MLP). In their approach, Principle Components Analysis (PCA) are used for features transformation, while Genetic Algorithms (GA) are applied for search the principal feature space for a subset of features. For classification purpose, they used MLP. KDD cup 1999 was used for their experiments. Their approach was an initial effort for features subset selection in intrusion detection, which aims to find a subset of principle components by using GA to search the PCA space. The results showed that, the proposed approach have improved accuracy, simplified the architecture of intrusion detection, as well as decreased training time and computational overheads.
D. Approach-5
Chitrakar and Chuanhe [14] have proposed a new hybrid approach, which aims to make the classification operate in anomaly-based IDSs more accurate and efficient. They used K-Medoids Clustering approach to gathering similar data instances based on their behavior and applied SVM to classify data to normal or abnormal behavior. Their experiments have been evaluated based on Kyoto2006+ datasets.
The main procedure in their approach is converted the attribute of datasets into suitable types, and then normalized
them based on the need of the SVM kernel. The entire selected data are classified into [-1, 1], where -1 represents each sample with both known and unknown attack and 1 represents normal class. The experimental result referred to that, their approach has increased DR as well as decreased FPR in in superior level compared to the other hybrid approach.
E. Approach-6
A hybrid intrusion detection system for MD and AD have been proposed by Om and Kundu [15], which combines K-Means and two classifiers K-Nearest Neighbor (K-NN) and Naïve Bayes. KDD-Cup 1999 dataset are used for evaluation purpose. First, the entropy based feature selection algorithm is used to select the appropriate features. Then, k-means clustering algorithm is applied on the selected features to split the data records into normal and abnormal clusters. After that, the obtained data are classified into normal or abnormal clusters by using the hybrid classifier. The main goals in their approach were to reduce the FAR, detect the intrusions, and further classify them into four categories: DoS, U2R, R2L, and probe. As a result, they have found that the proposed approach is better than the other conventional approaches such as kMeans, kNN, and Naïve Bayes in terms of accuracy, DR, and FAR.
F. Approach-7
An optimized intrusion detection using soft computing techniques has been proposed by Ahmad et al. [16], with the aim to provide an optimal intrusion detection system that has ability to minimize amount of features and maximize DR. In their approach, KDD Cup 1999 dataset is used for evaluation purpose and PCA is applied to convert the input samples into a new feature space. Moreover, GA is used to find a suitable number of principal components, and for classification purpose, they have applied SVM. They have focused on comparing SVM performance on feature sets. First, they obtained 12 features from PCA and GA and classified them with SVM. Second, they collected 22 features directly from PCA output using the traditional method and classified them with SVM. The experimental results referred to that, the proposed method has provided an optimal intrusion detection, which is able to minimize amount of features and maximize the DR.
G. Approach-8
Kim et al. [17] have proposed a new hybrid intrusion detection which integrating hierarchically MD model and AD model to overcome performance issue. In their proposed approach, the MD has used the information of known attack to build a classifier while the AD has used information of normal traffic to build a classifier. First, the MD model is decomposed normal training data into disjoint subsets. Then MD model is applied for each separate subset of normal training data. The techniques that used for each model were C4.5 decision tree (DT) for MD model, and 1-class SVM to construct multiple AD models. For their experiments, they have used NSL-KDD data set. It has been found that the result of the proposed method is superior to the conventional methods with respect to performance for detecting unknown attacks, training and testing time.
H. Approach-9
Ahmad et al. [18] have proposed a novel method in intrusion detection to enhance the performance of the classifier, where PCA is applied for feature transformation. Moreover, GA is used to find the genetic principle components, which offer a subset of features with optimal sensitivity and the highest discriminatory power. For classification purpose, they have applied SVM, where KDD-Cup dataset is used for evaluation purpose. Their work has extended the previous work [16], and the results have showed that, the proposed method has enhanced the performance of classifier in intrusion detection by minimizing the number of features (up to 10) and maximizing the DR (up to 99.96 %).
I. Approach-10
Chaunhan et al. [19] have presented a comparison between different classification techniques, which are worked to detect intrusions and classify them into normal and abnormal behaviors. The algorithms that have been selected are J48, Naive Bayes, RIPPER (JRip), and One Rule (OneR). Their experiments were performed by using NSL-KDD dataset. WEKA platform was selected for the implementation of the selected algorithms. The results have showed that the best algorithm for classification purpose is OneR classifier, where it required the shortest time, which is around 0.45 s with 10-fold cross-validation, and 0.32 s with supplied test set compared with others classifiers.
IV. STANDARD DATASETS
One of the most important parameters which can affect the capability of the intrusion detection mechanism is dataset, where the performance of IDSs depends on its accuracy and vice versa. When the training dataset is optimally accurate with a rich content then, the efficiency of the trained system is improved. Thus, the collection of the data in order to train and test the different classfication techniques is a critical dilemma. There are three different methods for collecting data to be used for experiments in the IDSs, which are [4]: (i) real traffic, (ii) sanitized traffic, and (iii) simulated traffic. However, these methods still inefficient for training and testing classification techniques, where using the real traffic to collecting data can be very costly, sanitized traffic is more risky, while generated simulation traffic required a hard work that can make the standard constructed simulated datasets popular for evaluating IDSs. There is a number of standard datasets, which can be classified based on the network traffic such as DARBA [20], KDD-Cup [21], NSL-Cup [22], CAIDA [23], and Kyoto2006+ [24]. Accordingly, these data can be used for experiments in order to evaluate classification techniques in the field of IDSs. A. DARBA Dataset
DARPA dataset [20], [25] is the first standard corpora for evaluating computer network IDSs, which has been collected and distributed by MIT Lincoln Laboratory. Each evaluation effort built to measure the possibility of detectiton and FA for each system under test using many types of attacks. DARPA dataset was collected by set up a test bed that simulated the operation of a typical US Air Force LAN for over two months
to structure audit data to be used for evaluating algorithms in IDSs.
B. KDDCUP1999 Dataset
KDDCUP1999 dataset [21] is a connection of data transfer collected from a virtual environment to be used for the Competition of the Third International Knowledge Discovery and Data Mining Tools. This standard dataset is gathered by Stolfo et al. [26], based on the pre-processing version of data built in DARPA 1998 [20]. Each connection record is about 100 bytes, consists of 41 features, and labeled as normal or as an attack. KDDCUP1999 dataset separated into two sets, which are training set and testing set.
C. NSL-KDD Dataset
NSL-KDD dataset appeared to fix the issues occurred in KDDCUP1999 dataset, which has highly affected the performance of the evaluated systems. It proposed by Tavallaee et al. [27] as a new revised version of KDDCUP1999 dataset, and it publicly available online on [22]. The main contribution of NSL-KDD dataset, it does not include redundant records whether in train or test sets.
D. CAIDA Datasets
CAIDA datasets [23] are a collection of several different types of data, resulting from both active and passive measurement of the internet. These datasets are available to the research community with retention the privacy of individuals and organizations who donate data or network access. Established in 1997 by Dr. Kc Claffy and Tracie Monk, and located in San Diego Supercomputing Center (SDSC). The data collection for each dataset is still active and has continuing, regularly scheduled groups, or terminated and will not be resumed.
E. Kyoto 2006+ Dataset
Kyoto 2006+ dataset [24], [28] is a connection of data transfer collected from honeypots and darknets data published by Kyoto University. It appeared to fill the gap in the existing evaluation datasets, such as KDDCUP1999 dataset. Kyoto2006+ dataset built from diverse types of honeypots over three years of real traffic data from 2006 until 2009. It consists of 14 statistical features, which are derived from KDDCUP1999 dataset ignoring other features that contain redundant. As well, it includes additional 10 features for more analysis and evaluation of NIDSs.
V. COMPARATIVE ANALYSIS A. Datasets Comparison
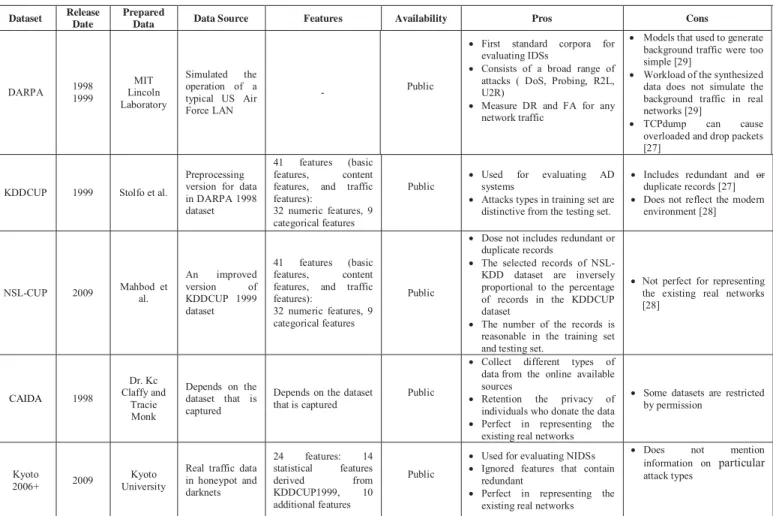
Table I presents a comparison between five types of standard datasets, which are mentioned in section V. DARPA dataset considered as a popular dataset used in IDSs to measure DR and FA for any network traffic, which consists of four types of attacks (DoS, R2L, U2R, and Probing attacks). However, it faced a set of critiques [29], where it appeared early in 1998 and 1999, using very simple models to create background traffic, and the synthesized data it does not look like to be similar background traffic in real networks. Moreover, traffic collectors that used to collect data from network traffic (i.e.
TCPdump) are extremely probable ignore packet during intensive traffic load [27]. KDDCUP1999 dataset also appeared early in 1999 as a preprocessing version for data in DARPA 1998 dataset, which classified records into 41 features that are not related to any critiques to DARBA dataset. In spite of KDDCUP1999 dataset including a huge number of attacks where the attack types in training set are not the same in testing set, it includes redundant and duplicate record, which cause overhead during the evaluation process [27]. NSL-KDD dataset also appeared as a new version from KDD Cup dataset, which has removed redundant or duplicate records in KDD-Cup dataset and represent the records in way that is more reasonable. However, it does not considered as the ideal way for representing the existing real networks [28]. The issue is not just exclusive on NSL-KDD dataset but also includes old version from DARBA 1998 and KDD Cup 1999 datasets. CAIDA datasets also appeared for evaluating IDSs, which consists of different types of datasets that are collected from the internet, which considered as a perfect resource for representing the real existing networks. Kyoto 2006+ dataset also appeared for evaluating NIDSs, and it is built by through ignoring features that contain redundant, as the previous mentioned datasets, this dataset is also the comprehensive representation for the real current networks. Although it is recently emerged, it does not mention information on particular attack types.
Standards datasets are not limited to these five types of evaluation. VELOS dataset [30] also appeared to evaluate the performance of IDSs, which includes approximately 10 gigabytes of normal and malicious traffic with nearly different kinds of the potential attacks, mainly web access attacks. This traffic is primarily in several pcap files and tcpdump text files. B. Approaches Comparsion
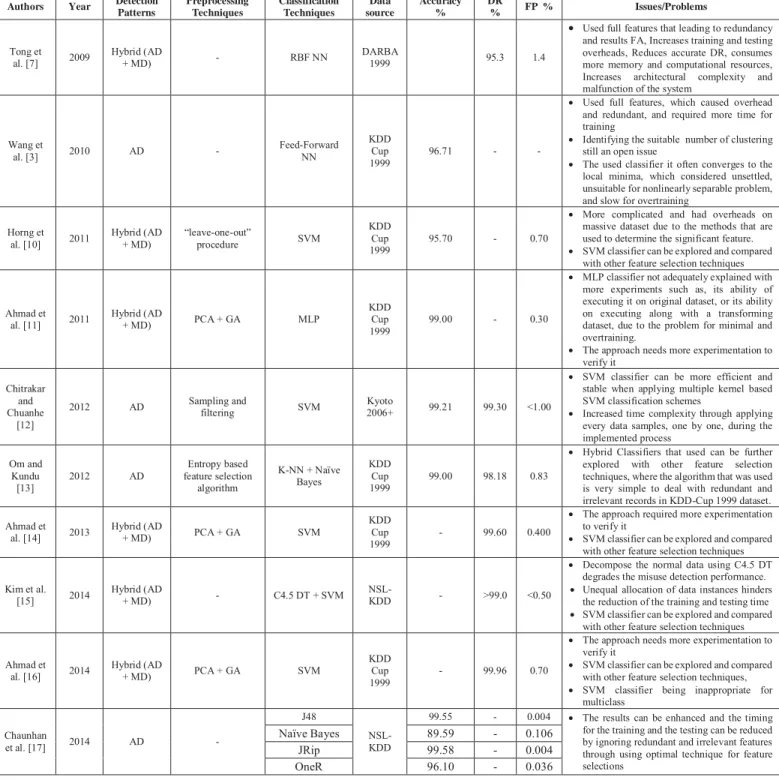
Table II presents a comparison for the approaches that were proposed and applied for intrusion detection, which are mentioned in section IV. It provides details regarding the techniques that are combined with a view to strengthen the performance of the IDSs. Moreover, it highlights different issues that need to be solved. In the hybrid approach for Tong et al. [8], despite the ability of using SVM, MPM, soft- computing, and other pattern classification technology as a pattern classification module instead of RBF neural network, it considered not suitable for classification. Results have showed its weakness compared with the other hybrid approaches. This can be due to used full features, which caused redundant and introducing overheads. Moreover, the raw feature set can confounded the classifier due to the redundancy and results FA. Further, it increases training and testing overheads, reduces accurate DR, consumes more memory and computational resources, increases architectural complexity and malfunctioning the system. The same issue appeared in [3] where they used full features, which caused overhead , and found that redundancy have reduced accuracy of DR, as well as it considered a time consuming for the training process. Moreover, they have found that the used classifier it often converges to the local minima, which considered unsettled, it also considered unsuitable for nonlinearly separable problem, and slow for overtraining. Despite using clustering approach for
TABLE I: STANDARDS’sDATASETS COMPARISON IN IDS
Dataset Release
Date
Prepared
Data Data Source Features Availability Pros Cons
DARPA 1998 1999 Lincoln MIT Laboratory Simulated the operation of a typical US Air Force LAN - Public
x First standard corpora for evaluating IDSs
x Consists of a broad range of attacks ( DoS, Probing, R2L, U2R)
x Measure DR and FA for any network traffic
x Models that used to generate background traffic were too simple [29]
x Workload of the synthesized data does not simulate the background traffic in real networks [29]
x TCPdump can cause overloaded and drop packets [27]
KDDCUP 1999 Stolfo et al.
Preprocessing version for data in DARPA 1998 dataset
41 features (basic features, content features, and traffic features):
32 numeric features, 9 categorical features
Public x Used for evaluating AD systems x Attacks types in training set are
distinctive from the testing set.
x Includes redundant and or duplicate records [27] x Does not reflect the modern
environment [28]
NSL-CUP 2009 Mahbodal. et
An improved version of KDDCUP 1999 dataset 41 features (basic features, content features, and traffic features):
32 numeric features, 9 categorical features
Public
x Dose not includes redundant or duplicate records
x The selected records of NSL-KDD dataset are inversely proportional to the percentage of records in the KDDCUP dataset
x The number of the records is reasonable in the training set and testing set.
x Not perfect for representing the existing real networks [28] CAIDA 1998 Dr. Kc Claffy and Tracie Monk Depends on the dataset that is captured
Depends on the dataset that is captured
Public
x Collect different types of data from the online available sources
x Retention the privacy of individuals who donate the data x Perfect in representing the
existing real networks
x Some datasets are restricted by permission
Kyoto
2006+ 2009 UniversityKyoto
Real traffic data in honeypot and darknets 24 features: 14 statistical features derived from KDDCUP1999, 10 additional features Public
x Used for evaluating NIDSs x Ignored features that contain
redundant
x Perfect in representing the existing real networks
x Does not mention
information on particular attack types
performance, still determine the suitable number of clustering remains an open problem. Although Horng et al. [12] have used “leave-one-out” procedure to ignore irrelevant features from dataset, it is much complicated and overheads. Despite the better results of K-NN and Naïve Bayes compared to the conventional as kMeans, kNN, and Naïve Bayes in terms of accuracy, DR, and FAR., K-NN and Naïve Bayes can be further explored with other feature selection techniques, where the algorithm that is used is characterized by simplicity for dealing with redundant and irrelevant records in KDD-Cup 1999 dataset. The hybrid approach that was proposed by Chitrakar and Chuanhe [14] also showed a better accurate result for DR and FPR. It used Kyoto 2006+ dataset for evaluation purpose, where it ignored features that contain redundant. However, SVM classifier that was used in their approach can be more efficient and stable when applying multiple kernel based SVM classification schemes. Additionally, the time complexity of k-Medoids clustering still needs to be decreased. On the other side, the approaches that presented by Ahmad et al. [13], [16], [18], which sought to improve the performance issues in IDSs, provided the better results for DR and FA. In [13] , their proposed approach was an initial effort for features subset selection, which presented in order to override feature selection issues. Their experiments showed that, the proposed approach have improved accuracy, simplified the architecture of
intrusion detection, as well as decreased training time and computational overheads. However, MLP classifier not adequately explained with more experiments, such as examining the ability of the classifier to execute well on the original dataset, or execute well on transformed dataset; this can be due to the problem for local minimal and required overtraining. Therefore, their method needs more experimentation to verify it. In [16], Ahmad et al. have used SVM classifier for their method with the aim to provide an optimal intrusion detection system that has ability to minimize amount of features and maximize DR. However, their approach required more experimentation, which can verify it. Although Ahmed et al. [18] have provided a new approach to enhance the performance of SVM classifier, and it results have showed that the proposed approach enhanced the performance of SVM classifier in intrusion detection in terms of minimizing the number of features and maximizing the DR, SVM classifier is not suitable for multiclass. Moreover, their work also needs more experimentation to verify it. Furthermore, despite the better results that have enhanced the detection accuracy which were resulted from NSL-KDD dataset, in [17], decompose the normal data using C4.5 DT degrades the misuse detection performance, and unequal allocation of data instances hinders the reduction of the training and testing time. Moreover, in [19], the results of accuracy, and time complexity, can be enhanced
by ignoring redundant and irrelevant features using optimal technique for feature selections.
Therefore, the accuracy of IDSs depends on an optimum classification technique, which is mainly depends on optimal dataset selection. Many techniques for feature selection were applied on dataset with a view to enhance the accuracy of the classifier. A numbers of studies have been presented in order to enhance the performance of IDSs by increasing DR and decreasing FPR. Thus, finding the optimal classification technique to avoid current issues in the recent techniques,
choosing suitable dataset, which includes rich types of recent attacks, and selecting a suitable features are the current important issues in the field of IDSs.
VI. CONCLUSION
Find the optimal classification technique to enhance the performance of IDSs by increasing the DR and decreasing the FA is still an ongoing area. In this paper, a review of the current classification techniques in IDSs is introduced. Moreover, a review of the most popular datasets used for train and test
TABLE II: APPROACHES COMPARISON IN IDS
Authors Year Detection
Patterns Preprocessing Techniques Classification Techniques Data source Accuracy % DR % FP % Issues/Problems Tong et
al. [7] 2009 Hybrid (AD + MD) - RBF NN DARBA 1999 95.3 1.4
x Used full features that leading to redundancy and results FA, Increases training and testing overheads, Reduces accurate DR, consumes more memory and computational resources, Increases architectural complexity and malfunction of the system
Wang et
al. [3] 2010 AD - Feed-Forward NN
KDD Cup
1999 96.71 -
-x Used full features, which caused overhead and redundant, and required more time for training
x Identifying the suitable number of clustering still an open issue
x The used classifier it often converges to the local minima, which considered unsettled, unsuitable for nonlinearly separable problem, and slow for overtraining
Horng et
al. [10] 2011 Hybrid (AD + MD) “leave-one-out” procedure SVM
KDD Cup
1999 95.70 - 0.70
x More complicated and had overheads on massive dataset due to the methods that are used to determine the significant feature. x SVM classifier can be explored and compared
with other feature selection techniques
Ahmad et
al. [11] 2011 Hybrid (AD + MD) PCA + GA MLP
KDD Cup
1999 99.00 - 0.30
x MLP classifier not adequately explained with more experiments such as, its ability of executing it on original dataset, or its ability on executing along with a transforming dataset, due to the problem for minimal and overtraining.
x The approach needs more experimentation to verify it
Chitrakar and Chuanhe
[12]
2012 AD Sampling andfiltering SVM 2006+Kyoto 99.21 99.30 <1.00
x SVM classifier can be more efficient and stable when applying multiple kernel based SVM classification schemes
x Increased time complexity through applying every data samples, one by one, during the implemented process Om and Kundu [13] 2012 AD Entropy based feature selection algorithm K-NN + Naïve Bayes KDD Cup 1999 99.00 98.18 0.83
x Hybrid Classifiers that used can be further explored with other feature selection techniques, where the algorithm that was used is very simple to deal with redundant and irrelevant records in KDD-Cup 1999 dataset. Ahmad et
al. [14] 2013 Hybrid (AD + MD) PCA + GA SVM
KDD Cup
1999 - 99.60 0.400
x The approach required more experimentation to verify it
x SVM classifier can be explored and compared with other feature selection techniques Kim et al.
[15] 2014 Hybrid (AD + MD) - C4.5 DT + SVM NSL-KDD - >99.0 <0.50
x Decompose the normal data using C4.5 DT degrades the misuse detection performance. x Unequal allocation of data instances hinders
the reduction of the training and testing time x SVM classifier can be explored and compared
with other feature selection techniques Ahmad et
al. [16] 2014 Hybrid (AD + MD) PCA + GA SVM
KDD Cup 1999
- 99.96 0.70
x The approach needs more experimentation to verify it
x SVM classifier can be explored and compared with other feature selection techniques, x SVM classifier being inappropriate for
multiclass Chaunhan et al. [17] 2014 AD -J48 NSL-KDD
99.55 - 0.004 x The results can be enhanced and the timing for the training and the testing can be reduced by ignoring redundant and irrelevant features through using optimal technique for feature selections
Naïve Bayes 89.59 - 0.106
JRip 99.58 - 0.004
selected classifier is also introduced. Each classification technique has its superiority and limitationsduring classify data into normal or abnormal, so that it is important to select an optimal one during intrusion detection process. Additionally, we have also discussed these reviews to conclude that, a set of issues must be take into consideration during development of classification techniques in IDSs, such as which is an optimal dataset that includes a rich types of recent attacks, and which features that must be selected without confused, overhead, and time-consuming selected classifier.
ACKNOWLEDGMENT
This research work is supported by Department of Software Engineering, CCIS, King Saud University, Riyadh, Saudi Arabia.
REFERENCES
[1] T. Verwoerd and R. Hunt, "Intrusion Detection Techniques and Approaches," Computer Communications, vol. 25, no. 15, pp. 1356-1365, September 2002.
[2] A. Lazarevic, V. Kumar and J. Srivastava, "Intrusion Detection: A Survey," in Managing Cyber Threats, vol. 5, Springer US, 2005, pp. 19-78.
[3] G. Wang, J. Hao, J. Ma and L. Huang, "A new approach to intrusion detection using Artificial Neural Networks and fuzzy clustering,"
Expert Systems with Applications, vol. 37, no. 9, pp. 6225-6232, September 2010.
[4] I. Ahmad, A. Abdullah and A. Alghamdi, "Artificial neural network approaches to intrusion detection: a review," in Proceedings of the 8th International Conference on the World Scientific and Engineering Academy and Society, Istanbul, Turkey, 2009.
[5] J. P. Anderson, "Computer security threat monitoring and surveillance," Fort Washington, Pennsylvania, April, 1980.
[6] D. E. Dorothy , "An Intrusion-Detection Model," Software Engineering, IEEE Transactions on, vol. 13, no. 2, pp. 222-232,
February 1987.
[7] H.-J. Liao, C.-H. R. Lin, Y.-C. Lin and K.-Y. Tung, "Intrusion Detection System: A Comprehensive Review," Journal of Network and Computer Applications, vol. 36, no. 1, pp. 16-24, 1 January 2013. [8] X. Tong, Z. Wang and H. Yu, "A research using hybrid RBF/Elman
neural networks for intrusion detection system secure model,"
Computer Physics Communications, vol. 180, no. 10, pp. 1795-1801, Octobar 2009.
[9] Y. Bai and K. Hidetsune, "Intrusion Detection Systems: technology and development," in Proceedings of the 17th International Conference on Advanced Information Networking and Applications, March, 2003.
[10] K. Scarfone and P. Mell, "Guide to Intrusion Detection," National Institute of Standards and Technology, February, 2007.
[11] R. Mirchell and I.-R. Chen, "A Survey of Intrusion Detection in Wireless Network Application," Computer Communications, vol. 42, pp. 1-23, 1 February 2014.
[12] S.-J. Horng, M.-Y. Su, Y.-H. Chen, T.-W. Kao, R.-J. Chen, . J.-L. Lai and C. D. Perkasa, "A novel intrusion detection system based on hierarchical clustering and support vector machines," Expert Systems with Applications, vol. 38, no. 1, pp. 306-313, January 2011.
[13] I. Ahmad, A. Abdullah, A. Algamdi, K. Alnfajan and M. Hussain, "Intrusion detection using feature subset selection based on MLP,"
Scientific Research and Essays, vol. 6, no. 34, pp. 6804-6810,
December 2011.
[14] C. Huang and R. Chitrakar, "Anomaly detection using Support Vector Machine classification with k-Medoids clustering," in Proceedings of the 3rd International Conference on Asian Himalayas, Kathmandu. Nepal, November, 2012.
[15] H. Om and A. Kundu, "A hybrid system for reducing the false alarm rate of anomaly intrusion detection system," in Proceedings of the 1st International Conference on Recent Advances in Information Technology (RAIT), March, 2012.
[16] I. Ahmad, A. Abdullah and A. Alghamdi, "Optimized intrusion detection mechanism using soft computing techniques,"
Telecommunication Systems, vol. 52, no. 4, pp. 2187-2195, April 2013. [17] G. Kim, S. Lee and S. Kim, "A novel hybrid intrusion detection method integrating anomaly detection with misuse detection," Expert Systems with Applications, vol. 41, no. 4, pp. 1690-1700, March 2014. [18] I. Ahmad, M. Hussain , A. Alghamd and A. Alelaiwi, "Enhancing SVM
performance in intrusion detection using optimal feature subset selection based on genetic principal components," Neural Computing and Applications, vol. 24, no. 7-8, pp. 1671-1682, June 2014.
[19] H. Chauhan, V. Kuma, S. Pundir and E. S. Pilli, "Comparative Analysis and Research Issues in Classification Techniques for Intrusion Detection," in Proceedings of the International Conference on Advanced Computing, Networking, and Informatics,, India, 2014.
[20] "DARPA Intrusion Detection Evaluation Program," MIT Lincoln Labs,
1998. [Online]. Available: http://www.ll.mit.edu/mission/communications/cyber/CSTcorpora/ide
val/index.html. [Accessed February 2015].
[21] "KDD Cup 1990 Data," 1999. [Online]. Available: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html. [Accessed February 2015].
[22] "NSL-KDD Dataset," 2009. [Online]. Available: http://nsl.cs.unb.ca/NSL-KDD/ . [Accessed February 2015].
[23] "CAIDA Dataset," CAIDA, [Online]. Available: http://www.caida.org/data/overview/ . [Accessed February 2015].
[24] "Kyoto2006+ Dataset," [Online]. Available: http://www.takakura.com/Kyoto_data/ . [Accessed February 2015].
[25] R. Lippmann, D. Fried, I. Graf, J. Haines, K. Kend, D. McClung, D. Weber , S. Webster, D. Wyschogrod, R. Cunningham and M. Zissman, "Evaluating intrusion detection systems: The 1998 DARPA off-line intrusion detection evaluation," in Proceedings of the International Conference on DARPA Information Survivability Conference and Exposition, 2000.
[26] S. J. Stolfo, W. Fan, W. Lee, A. Prodromidis and P. K. Chan, "Cost-based modeling for fraud and intrusion detection: results from the JAM project," in Proceedings of the International Conference on DARPA Information Survivability Conference and Exposition, 2000.
[27] M. Tavallaee, E. Bagheri, W. Lu and A. A. Ghorbani, "A detailed analysis of the KDD CUP 99 data set," in Proceedings of the Second IEEE international conference on Computational intelligence for security and defense applications, Ottawa, ON Canada, July, 2009. [28] H. Takakura, Y. Okabe, M. Eto, D. Inoue and K. Nakao, "Statistical
analysis of honeypot data and building of Kyoto 2006+ dataset for NIDS evaluation," in Proceedings of the First Workshop on Building Analysis Datasets and Gathering Experience Returns for Security, 2011.
[29] J. McHugh, "Testing Intrusion detection systems: a critique of the 1998 and 1999 DARPA intrusion detection system evaluations as performed by Lincoln Laboratory," ACM Transactions on Information and System Security, vol. 3, no. 4, pp. 262-294, November 2000.
[30] " VELOS Dataset," [Online]. Available: http://velos-dataset.appspot.com. [Accessed February 2015].