International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)227
A Survey on Visual Cryptography using Image Encryption and
Decryption
Prakash Chandra Jena
1, Nikunja Kanta Das
21,2
Orissa Engg. College, BBSR
Abstract— Cryptography is the study of mathematical techniques which is related to the aspects of Information Security, such as confidentiality, data security, entity authentication and data origin authentication. But Visual cryptography (VC) is a new technique pertaining to information security that uses simple algorithm unlike traditional cryptography which incorporates complex, computationally intensive algorithms. Visual information of pictures, text etc. are dealt with in order to encrypt in progressive and unexpanded VC algorithm. We have only a few pieces of shares and get an outline of the secret image. This is done by increasing the number of the shares being stacked. So that the details of the hidden information can be revealed progressively. In this paper, we proposed a brand new sharing scheme of progressive VC to produce pixel unexpanded shares. Therefore, no one can obtain any hidden information from a single share that leads to ensure security. During superimposing k (sheets of share) the white pixels being stacked into black pixels, the possibility of white pixels remains 1/n, whereas the possibility of black pixels rises to k/n. This sharpens the contrast of the stacked image and the hidden information. Therefore, after superimposing all of the shares, the contrast rises to (n − 1)/n which is apparently better than the traditional ways that can only obtain 50% of contrast. Consequently, to contrast the number of pixel position and to find more clarified image in filtration. Hence, a clearer recovered image can be achieved. But now we have taken image formats as Joint Photographic Experts Group (JPEG) . The new method averts the lossy Discrete Cosine Transform and quantization and can encrypt and decrypt JPEG images lossless. The security test results indicate the proposed methods have high security. Since JPEG image formats are popular contemporarily, this paper shows that the prospect of image encryption & decryption is promising.
Keywords— Visual Cryptography, Encryption, Decryption.
I. INTRODUCTION
Cryptography (or cryptology; from Greek, "hidden,
secret"; and graphein, "writing”, logia, "study",
respectively) is the practice and study of techniques for secure communication in the presence of third parties (called adversaries).
More generally, it is about constructing and analyzing protocols that overcome the influence of adversaries and which are related to various aspects in information security such as data confidentiality, data integrity, and authentication. Modern cryptography intersects the disciplines of mathematics, computer science, and electrical engineering. Applications of cryptography include ATM cards, computer passwords, and electronic commerce. Cryptography prior to the modern age was
effectively synonymous with encryption, the conversion of
information from a readable state to apparent nonsense. The originator of an encrypted message shared the decoding technique needed to recover the original information only with intended recipients, thereby precluding unwanted persons to do the same. Since World War I and the advent of the computer, the methods used to carry out cryptology have become increasingly complex and its application more widespread.
Until modern times cryptography referred almost
exclusively to encryption, which is the process of
converting ordinary information (called plaintext) into
unintelligible gibberish (called ciphertext). Decryption is
the reverse, in other words, moving from the unintelligible
ciphertext back to plaintext. A cipher (or cypher) is a pair
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)228 In colloquial use, the term "code" is often used to mean any method of encryption or concealment of meaning.
However, in cryptography, code has a more specific
meaning. It means the replacement of a unit of plaintext (i.e., a meaningful word or phrase) with a code word (for
example, wallaby replaces attack at dawn). Codes
are no longer used in serious cryptography—except incidentally for such things as unit designations (e.g., Bronco Flight or Operation Overlord)—since properly chosen ciphers are both more practical and more secure than even the best codes and also are better adapted to computers.
Cryptanalysis is the term used for the study of methods for obtaining the meaning of encrypted information without access to the key normally required to do so; i.e., it is the study of how to crack encryption algorithms or their implementations.
Some use the terms cryptography and cryptology
interchangeably in English, while others (including US
military practice generally) use cryptography to refer
specifically to the use and practice of cryptographic
techniques and cryptology to refer to the combined study of
cryptography and cryptanalysis. English is more flexible
than several other languages in which cryptology (done by
cryptologists) is always used in the second sense above. In the English Wikipedia the general term used for the entire
field is cryptography (done by cryptographers).
The study of characteristics of languages which have some application in cryptography (or cryptology), i.e. frequency data, letter combinations, universal patterns, etc., is called cryptolinguistics.
Secret sharing refers to method for distributing a secret amongst a group of participants, each of whom is allocated a share of the secret. The secret can be reconstructed only when a sufficient number of shares are combined together; individual shares are of no use on their own.
More formally, in a secret sharing scheme there is one dealer and n players. The dealer gives a secret to the players, but only when specific conditions are fulfilled. The dealer accomplishes this by giving each player a share in
such a way that any group of t (for threshold) or more
players can together reconstruct the secret but no group of
fewer than t players can. Such a system is called a (t, n)
-threshold scheme (sometimes it is written as an (n, t)
-threshold scheme).Secret sharing was invented
independently by Adi Shamir and George Blakley in 1979. Secret sharing schemes are ideal for storing information that is highly sensitive and highly important. Examples include: encryption keys, missile launch codes, and numbered bank accounts.
Each of these pieces of information must be kept highly confidential, as their exposure could be disastrous, however, it is also critical that they not be lost. Traditional methods for encryption are ill-suited for simultaneously achieving high levels of confidentiality and reliability. This is because when storing the encryption key, one must choose between keeping a single copy of the key in one location for maximum secrecy, or keeping multiple copies of the key in different locations for greater reliability. Increasing reliability of the key by storing multiple copies lowers confidentiality by creating additional attack vectors; there are more opportunities for a copy to fall into the wrong hands. Secret sharing schemes address this problem, and allow arbitrarily high levels of confidentiality and reliability to be achieved.
Limitations of secret sharing schemes
Several secret sharing schemes are said to be information theoretically secure and can be proved to be so,
while others give up this unconditional security for
improved efficiency while maintaining enough security to be considered as secure as other common cryptographic primitives. For example, they might allow secrets to be protected by shares with 128-bits of entropy each, since each share would be considered enough to stymie any conceivable present-day adversary, requiring a brute force
attack of average size 2127.
Common to all unconditionally secure secret sharing schemes, there are limitations:
Each share of the secret must be at least as large as
the secret itself. This result is based in information
theory, but can be understood intuitively. Given t-1
shares, no information whatsoever can be determined about the secret. Thus, the final share must contain as much information as the secret itself.
All secret sharing schemes use random bits. To
distribute a one-bit secret among threshold t people,
t-1 random bits are necessary. To distribute a secret of
arbitrary length entropy of (t-1)*length is necessary.
Lossless data compression
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)229 Lossless compression is used when it is important that the original and the decompressed data be identical, or when no assumption can be made on whether certain deviation is uncritical. Typical examples are executable programs and source code. Some image file formats, notably PNG, use only lossless compression, while others like TIFF and MNG may use either lossless or lossy methods. GIF uses a lossless compression method, but most GIF implementations are incapable of representing full color, so they quantize the image (often with dithering) to 256 or fewer colors before encoding as GIF. Color quantization is a lossy process, but reconstructing the color image and then re-quantizing it produces no additional loss.
Lossless compression techniques
Lossless compression methods may be categorized according to the type of data they are designed to compress. Some main types of targets for compression algorithms are text, executables, images, and sound. Whilst, in principle, any general-purpose lossless compression algorithm (general-purpose means that they can handle all binary input) can be used on any type of data, many are unable to achieve significant compression on data that is not of the form that they are designed to deal with. Sound data, for instance, cannot be compressed well with conventional text compression algorithms.
Most lossless compression programs use two different kinds of algorithms: one which generates a statistical model for the input data, and another which maps the input data to bit strings using this model in such a way that "probable" (e.g. frequently encountered) data will produce shorter output than "improbable" data. Often, only the former algorithm is named, while the second is implied (through common use, standardization etc.) or unspecified.
Statistical modelling algorithms for text (or text-like binary data such as executables) include:
Burrows-Wheeler transform (BWT; block sorting
preprocessing that makes compression more efficient)
LZ77 (used by Deflate)
LZW
PPM
Encoding algorithms to produce bit sequences are:
Huffman coding (also used by Deflate)
Arithmetic coding
Many of these methods are implemented in open-source and proprietary tools, particularly LZW and its variants. Some algorithms are patented in the USA and other countries and their legal usage requires licensing by the patent holder. Because of patents on certain kinds of LZW compression, some open source activists encouraged people to avoid using the Graphics Interchange Format (GIF) for compressing image files in favor of Portable Network Graphics PNG, which combines the LZ77-based deflate algorithm with a selection of domain-specific prediction filters. However, the patents on LZW have now expired.
Many of the lossless compression techniques used for text also work reasonably well for indexed images, but there are other techniques that do not work for typical text that are useful for some images (particularly simple bitmaps), and other techniques that take advantage of the specific characteristics of images (such as the common phenomenon of contiguous 2-D areas of similar tones, and the fact that colour images usually have a preponderance to a limited range of colours out of those representable in the colour space).
As mentioned previously, lossless sound compression is a somewhat specialised area. Lossless sound compression algorithms can take advantage of the repeating patterns shown by the wave-like nature of the data - essentially using models to predict the "next" value and encoding the (hopefully small) difference between the expected value and the actual data. If the difference between the predicted and the actual data (called the "error") tends to be small, then certain difference values (like 0, +1, -1 etc. on sample values) become very frequent, which can be exploited by encoding them in few output bits. This is called "Delta coding".
Lossy data compression
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)230 Types of lossy compression
There are two basic lossy compression schemes:
In lossy transform codes, samples of picture or sound are taken, chopped into small segments, transformed into a new basis space, and quantized. The resulting quantized values are then entropy coded.
In lossy predictive codes, previous and/or subsequent decoded data is used to predict the current sound sample or image frame. The error between the predicted data and the real data, together with any extra information needed to reproduce the prediction, is then quantized and coded.
Lossless vs. lossy compression
The advantage of lossy methods over lossless methods is that in some cases a lossy method can produce a much smaller compressed file than any known lossless method, while still meeting the requirements of the application.
Lossy methods are most often used for compressing sound, images or videos. The compression ratio (that is, the size of the compressed file compared to that of the uncompressed file) of lossy video codecs are nearly always far superior to those of the audio and still-image equivalents. Audio can be compressed at 10:1 with no noticeable loss of quality, video can be compressed immensely with little visible quality loss, eg 300:1. Lossily compressed still images are often compressed to 1/10th their original size, as with audio, but the quality loss is more noticeable, especially on closer inspection.
When a user acquires a lossily-compressed file, (for example, to reduce download-time) the retrieved file can be quite different from the original at the bit level while being indistinguishable to the human ear or eye for most practical purposes. Many methods focus on the idiosyncrasies of the human anatomy, taking into account, for example, that the human eye can see only certain frequencies of light. The psycho-acoustic model describes how sound can be highly compressed without degrading the perceived quality of the sound. Flaws caused by lossy compression that are noticeable to the human eye or ear are known as compression artifacts.
Lossless compression algorithms usually exploit statistical redundancy in such a way as to represent the sender's data more concisely, but nevertheless perfectly. Lossless compression is possible because most real-world data has statistical redundancy. For example, in English text, the letter 'e' is much more common than the letter 'z', and the probability that the letter 'q' will be followed by the letter 'z' is very small.
Another kind of compression, called lossy data compression, is possible if some loss of fidelity is acceptable. For example, a person viewing a picture or television video scene might not notice if some of its finest details are removed or not represented perfectly. Similarly, two clips of audio may be perceived as the same to a listener even though one is missing details found in the other. Lossy data compression algorithms introduce relatively minor differences and represent the picture, video, or audio using fewer bits.
Lossless compression schemes are reversible so that the original data can be reconstructed, while lossy schemes accept some loss of data in order to achieve higher
compression. However, lossless data compression
algorithms will always fail to compress some files; indeed, any compression algorithm will necessarily fail to compress any data containing no discernible patterns. Attempts to compress data that has been compressed already will therefore usually result in an expansion, as will attempts to compress encrypted data.
In practice, lossy data compression will also come to a point where compressing again does not work, although an extremely lossy algorithm, which for example always removes the last byte of a file, will always compress a file up to the point where it is empty.
For the past several decades, we have witnessed the rapid development of chaos theory and practices, as well as the astounding growth in the demand of transmitting images via the Internet. To reduce the flow rate of image file transmission, a lot of research on image compression has been carried out [1-3]. Joint Photographic Experts Group (JPEG) is a successful image format standard. In
JPEG, mathematical tools like discrete cosine
transformation (DCT) and quantization are introduced when processing the original image data [4]. JPEG has a great performance on reducing the image file size. However, since DCT and quantization are both lossy transformations, it is difficult to encrypt and decrypt JPEG image files lossless applying the general cryptographic scheme within the scope of bitmap images. There are several alternatives on JPEG image encryption [5-6], but none of them will produce cipher images, the pixel data of which owns a satisfied randomness.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)231
Graphics Interchange Format (GIF) is another
distinguished image format, since it has high compression ratio and animate frames [7]. Though GIF has the same RGB color space as normal bitmaps, the palette is a new case and it needs encryption as well. There are limited papers about encryption for these features now, and this paper will offer some new solutions.
Compound chaotic sequence generator based on 3D baker is an excellent stream cipher scheme for bitmaps, since it has a big enough key space, and a long sequence period due to the introduction of perturbations onto the neighbourhood of the fixed points, and high security because of the combination of diffusion and permutation [8-9]. Please note that our proposed scheme is an extension of it, expanding the scope of images to be dealt with.
The rest of this paper is organized as follows. In Section 2, there is a brief introduction to JPEG image file formats, and a discussion about compound chaotic sequence generator and permutation based on 3D baker map. The proposed methods applying the chaotic image encryption schemes to JPEG and GIF reside in Section 3 and finally the security test results and analysis of our new schemes are in Section 4, with NIST SP-800 22 test included [10].
[image:5.612.324.563.134.525.2]Nowadays, the size of storage media increases day by day. Although the largest capacity of hard disk is about two Terabytes, it is not enough large if we storage a video file without compressing it. For example, if we have a color video file stream, that is, with three 720x480 sized layer, 30 frames per second and 8 bits for each pixel. Then we need ! This equals to about 31.1MB per second. For a 650MB CD-ROM, we can only storage a video about 20 seconds long. That is why we want to do image and video compression though the capacity of storage media is quite large now. 7204803830 249Mbit/s
Fig. 1 Encoder and decoder of images
II. BASIC CONCEPTS OF DATA ENCRYPTION
The motivation of data compression is using less quantity of data to represent the original data without
distortion of them. Consider the system in Fig. 1.
(a) Original image 83261bytes
(b) Decoded image 15138bytes
There is an example in Fig. 2 using JPEG image
compression standard. The compression ratio is , 15138 / 832610 about 0.1818 , around one fifth of the original size. Besides, we can see that the decoded image and the original image are only slightly different. In fact, the two images are not completely same, that is, parts of information are lost during the image compression process. For this reason, the decoder cannot rebuild the image
perfectly. This kind of image compression is called
non-reversible coding or lossy coding. On the contrary, there is
another form called reversible coding that can perfectly
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)232
III. COMPRESSION ALGORITHMS
Prepress files are often huge so it is no more than logical that data are compressed. There are quite a few compression algorithms that can be used for both text and images. A basic knowledge about how the different algorithms work can be worthwhile.
These pages give an overview of the various compression algorithms that are used in the prepress industry. It is by no means a complete overview of all available algorithms. The following types of compression are documented in more detail:
Flate/deflate
JPEG
JPEG2000
Huffman
LZW
RLE
I have not yet documented:
CCITT group 3 & 4
JBIG
Types of compression algorithms
The above algorithms can be divided into two distinct categories: they are either lossless or lossy.
Lossless algorithms do not change the content of a
file. If you compress a file and then decompress it, it has not changed. The following algorithms are lossless:
o CCITT group 3 & 4 compression
o Flate/deflate compression
o Huffman compression
o LZW compression
o RLE compression
Lossy algorithms achieve better compression
ratios by selectively getting rid of some of the information in the file. Such algorithms can be used for images or sound files but not for text or program data. The following algorithms are lossy:
o JPEG compression
Which algorithm is best?
Unfortunately there is no fixed answer to that question. It all depends on the type of file that has to be compressed as well as the actual content of the file and the question whether you are willing to accept a lossy algorithm for that particular file. As a general rule, here is what most people in prepress use or find appropriate:
text: often not worth compressing, sometimes
RLE is used
line-art images : LZW
line-art and screened data: CCITT group 4
grayscale images: LZW for files that do not
contain too much detail
color images : JPEG if lossy compression is
acceptable
vector drawings: not supported by applications
Image Encompression with Tweaked Block Chaining A need for a new secure and fast mode of operation with less memory consumption, that offers error propagation, has demanded.In this paper, we propose a new narrow-block disk encryption mode of operation with compression. We decided to build the Tweaked Block Chaining (TBC) mode using Xor-Encrypt-Xor (XEX)[23] to inherit from its security and high performance and use CBC like operations to gain the error propagation property. This design is XEX-based TBC with CipherText Stealing(CTS) rather than Tweaked Code Book mode(TCB) as in case of XTS(XEX-based TCB with CTS). This model includes a Galois Field multiplier GF(2128) that can operate in any common field representations. This allows very efficient processing of consecutive blocks in a sector. To handle messages whose length is greater than 128-bit but not a multiple of 128-bit, a variant of Cipher Text Stealing will be used for tweaked block chaining. We named this mode Disk Encompression with Tweaked Block Chaining (DETBC). In section 2, we present Encryption with compression, and the constraints facing in the disk encryption applications. In section 3, we present tweak calculation, efficient multiplication, and exponential. Section 4 describes the implementation of our proposed scheme. Section 5 shows the performance analysis of narrow-block modes of operations that offer error propagation. Finally, section 6 concludes the work with presenting open problem.
IV. IMAGE ENCRYPTION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)233 4.1 Encryption with Compression
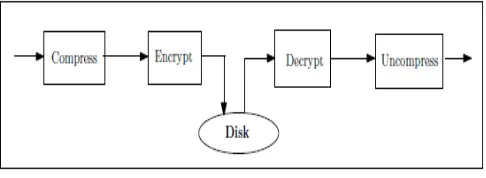
[image:7.612.54.297.185.274.2]Compress Encrypt Decrypt Uncompress Disk
Fig. 1. Steps for Disk encryption scheme.
Using a data compression algorithm together with an encryption algorithm makes sense for two reasons:
1.Cryptanalysis relies on exploiting redundancies in the
plain text; compressing a file before encryption reduces redundancies.
2.Encryption is time-consuming; compressing a file
before encryption speeds up the entire process.
In this work, we use the ”LZW 15-bit variable Rate Encoder”[15] for compression of the data. To access data from the disk, we have to first decrypt and then uncompress the decrypted data.
4.2 Image Encryption Constraints
The common existing disk constraints are:
Data size. The ciphertext length should be the same as the plaintext length.
Here, we use the current standard (512-byte) for the plaintext.
Performance. The used mode of operation should be fast enough, as to be transparent to the users. If the mode of operation results in a significant and noticeable slowdown of the computer, there will be great user resistance to its deployment.
V. IMAGE ENCOMPRESSION WITH TWEAKED BLOCK
CHAINING
5.1 Goals
The goals of designing the Disk Encompression with Tweaked Block Chaining (DETBC) mode are:
Security: The constraints for disk encryption imply that the best achievable security is essentially what can be obtained by using ECB mode with a different key per block[21]. This is the aim.
Complexity: DETBC complexity should be at least as fast as the current available solutions.
Parallelization: DETBC should offer some kind of parallelization.
Error propagation: DETBC should propagate error to further blocks (this may be useful in some applications).
5.2 Terminologies
The following terminologies are used to describe DETBC.
Pi: The plaintext block i of size 128 bits.
4 Disk Encompression with Tweaked Block Chaining
Js: The sequential number of the 512-bit sector s inside the
track encoded as 5-bit unsigned integer.
Ii : The address of block i encoded as 64-bit unsigned
integer.
Ti: The tweak i.
_: Primitive element of GF(2128):
←: Assignment of a value to a variable.
||: Concatenation operation.
PPi : Pi ⊗ Ti−1:
K1: Encryption key of size 128-bit used to encrypt the PP.
K2: Tweak key of size 128-bit used to produce the tweak .
EK2 : Encryption using AES algorithm with key K2:
DK1 : Decryption using AES algorithm with key K1:
C⊗i: The ciphertext block i of size 128 bits.
⊗: Bitwise Exclusive-OR operation.
: Multiplication of two polynomials in the finite field
GF(2128):
5.3 Tweak Calculation
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)234 1. The plaintext of size 4096-bit.
2. Encryption key of size 128 or 256-bit. 3. Tweak key of size 128 or 256-bit. 4. Sector ID of size 64-bit.
Usually a block cipher accepts the plaintext and the encryption key to produce the ciphertext. Different modes of operation have introduced other inputs. Some of these modes use initial vectors IV like in CBC, CFB and OFB modes, counters like in CTR[8]or nonces like in OCB mode [9]. The idea of using a tweak was suggested in HPC[10] and used in Mercy[16]. The notion of a tweakable block cipher and its security definition was formalized by Liskov, Rivest and Wagner[11]. The idea behind the tweak is that it allows more flexibility in design of modes of operations of a block cipher. There are different methods to calculate the tweak from the sector ID like ESSIV[13] and encrypted sector ID[14].
In this work, the term tweak is associated with any other inputs to the mode of operation with the exception of the
encryption key and the plaintext. Here, an initial tweak T0,
which is equal to the product of encrypted block address, where the block address (after being padded with zeros) is
encrypted using AES by the tweak key,and _Js,where Js is
the sequential number of the 512-bit sector inside the track
encoded as 5-bit unsigned integer and _ is the primitive
element of GF(2128), will be used as the initialization
vector (IV) of CBC. The successive tweaks are the product of encrypted block address and the previous cipher text
instead of _Js . When next sector comes into play, again
initial tweak is used, and the successive tweaks are again the product of encrypted block address and previous ciphertext. This is done so assuming that each track has 17 sectors and each sector has 32 blocks as per the standard disk structure. This procedure continues till end of the input file.
5.4 Efficient Multiplication in the finite field GF(2128)
Efficient multiplication in GF(2128) may be
implemented in numerous ways, depending on whether the multiplication is hardware or software and optimization scheme. In this work, we perform 16-byte multiplication. Let a, & b are two 16-byte operands and we consider the 16-byte output. When these blocks are interpreted as binary polynomials of degree 127, the procedure computes p =
a*b mod P, where P is a 128-degree polynomial P128(x) =
x128+x7+x2+x+1.
Multiplication of two elements in the finite field
GF(2128) is computed by the polynomial multiplication
and taking the remainder of the Euclidean division by the
chosen irreducible polynomial. In this case, the irreducible polynomial is
P128(x) = x128 + x7 + x2 + x + 1.
VI. IMAGE ENCOMPRESSION WITH TWEAKED BLOCK
CHAINING
xc mod n can be computed in time O(Lk2). Total number
of modular multiplications is at least L and at most 2L.
Therefore, time complexity is [(log c)*k2 ],
where n is a k-bit integer.
Efficient exponent in the finite field GF(2128) is
computed by the polynomial multiplication and taking the remainder of the Euclidean division by the chosen irreducible polynomial. In this case, the irreducible polynomial is
P128(x) = x128 + x7 + x2 + x + 1.
Table 2.
Algorithm for computing of z = xc mod n, where x, c and z ϵ GF(2128)
VII. IMPLEMENTATION OF THE PROPOSED SCHEME
The design includes the description of the DETBC transform in both encryption and decryption modes, as well as how it should be used for encryption of a sector with a length that is not an integral number of 128-bit blocks.
7.1 Encryption of a Data Unit.
The encryption procedure for a 128-bit block having index j is modeled with
Equation (1).
Ci ← DETBC-AES-blockEnc(Key, Pi, I, j)...(1)
where
Key is the 256-bit AES key
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)235 I is the address of the 128-bit block inside the data unit
j is the logical position or index of the 128-bit block
inside the sector Ci is the block of 128 bits of ciphertext
resulting from the operation.
The key is parsed as a concatenation of two fields of
equal size called Key1 and Key2 such that:
Key = Key1 || Key2.
The plaintext data unit is partitioned into m blocks, as follows:
P = P1 ||... || Pm−1 || Pm
where m is the largest integer such that 128(m-1) is no more than the bit-size of P, the first (m-1) blocks
P1,...,Pm−1 are each exactly 128 bits long, and the last
block Pm is between 0 and 127 bits long (Pm could be
empty, i.e., 0 bits long). The ciphertext Ci for the block
having index j shall then be computed by the following or an equivalent sequence of steps (see Figure 2):
AES-enc(K, P) is the procedure of encrypting plaintext P using AES algorithm with key K, according to FIPS-197.The multiplication and computation of power in step
1) is executed in GF(2128), where _ is the primitive
element defined in 3.2(see 3.4 & 3.5). The cipher text C is then computed by the following or an equivalent sequence of steps:
7.2 Decryption of a data unit.
The decryption procedure for a 128-bit block having index j is modeled with
Equation (2).
Pi ← DETBC-AES-blockDec(Key, Ci, I , j) ...(2)
where
Key is the 256-bit AES key
Ci is the 128-bit block of ciphertext
I is the address of the 128-bit block inside the data unit j is the logical position or index of the 128-bit block inside the sector
Pi is the block of 128-bit of plaintext resulting from the
operation
The key is parsed as a concatenation of two fields of
equal size called Key1 and Key2 such that:
Key = Key1 || Key2.
The ciphertext is first partitioned into m blocks, as follows:
C = C1 ||... ||Cm−1 || Cm
where m is the largest integer such that 128(m-1) is no more than the bit-size of C, the first (m-1) blocks
C1,...,Cm−1 are each exactly 128 bits long, and the last
block Cm is between 0 and 127 bits long (Cm could be
empty, i.e., 0 bits long).
The plaintext Pi for the block having index j shall then
be computed by the following or an equivalent sequence of steps (see Figure 4):
VIII. PERFORMANCE ANALYSIS
Security: Each block is encrypted with a different tweak T, which is the result of a non-linear function (multiplication) of encrypted file address and previous
cipher text ( _Js for 1st block), due to this step the value of
the tweak is neither known nor controlled by the attacker. By introducing the tweak, the attacker can not perform the mix-and-match attack[21]among blocks of different sectors, as each sector has a unique secret tweak. Any difference between two tweaks result full diffusion in both the encryption and decryption directions. These enhance the security.
Here we also give option for the value of _ to the user; it
reduces the probability of getting plaintext from ciphertext. This is so because same plaintext produces different cipher
text if we choose different value for _. This also increases
confusion.
Complexity: DETBC possesses high performance as it uses only simple and fast operations as standard simple shift and add (or) operators are used in the multiplication in
the finite field GF(2128) having O(1) time complexity.
Compression before encryption also enhances the speed and hence performance.
Parallelization: DETBC can be parallelized on the sector level as each sector is encrypted independently to other sectors. Also a plaintext can be recovered from just two adjacent blocks of cipher text. As a consequence, decryption can be parallelized.
Error propagation: As each block depends on its previous block, a one-bit change in a plaintext affects all following cipher text blocks. Hence, error propagation is met.
IX. CONCLUSIONS
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)236 We also calculated the time & compression ratio of image encryption & decryption process. The time & the compression ratio will be varied from picture to picture. Among various advantages of Loss Compression, we emphasized the property that which leads to a lot of interesting applications in private and public sectors of our society .In the future, the LZW Algorithms having the implementation of video, audio will be the further studied to solve the problems the noise-like shares brought about.
REFERENCES
[1 ] Bruise Schneider, Applied Cryptography, Wiley Press, Second
Edition.
[2 ] Douglas R. Stinson, Cryptography Theory and Practice, CRC Press,
Second Edition.
[3 ] Mark Nelson, Jean-Loup Gaily, The Data Compression Book, M&T
Press, Second Edition.
[4 ] William Stallings, Cryptography and Network Security, Pearson
Education, Fourth Edition.
[5 ] Anderson, R., Bihar, E.: Two practical and provable secure block ciphers: BEAR and LION. In: Gellman, D. (ed.) FSE 1996. LNCS, vol. 1039, pp. 113-120. Springer, Heidelberg (1996)
[6 ] S. Halevy and P. Roadway, A tweak able enciphering mode, in
Lecture Notes in Computer Science, D. Bone, Ed. Berlin, Germany: Springer-Vela, 2003, vol. 2729, pp. 482-499.
[7 ] A. Meekness, P. V. Borscht., and S. Vanstone. Handbook of Applied
Cryptography. CRC Press, 1996.
[8 ] D. McGrew. Counter Mode Security: Analysis and
Recommendations.
http://citeseer.ist.psu.edu/mcgrew02counter.html, 2002.
[9 ] P. Roadway, M. Bellaire, and J. Black. OCB: A block cipher mode
of operation for efficient authenticated encryption. ACM Trans. Inf. Syst. Secure., 6(3):365-403, 2003.
[10 ]R. Schroeppel. The Hasty Pudding Cipher. The first AES
conference, NIST, 1998. http://www.cs.arizona.edu/~rcs/hpc
[11 ]M. Liskov, R. L. Rivest, and D.Wagner, Tweakable block ciphers, in
Lecture Notes in Computer Science, M. Yung, Ed. Berlin, Germany: Springer-Verlag, 2002, vol. 2442, pp. 31-46.
[12 ]S. Lucks, BEAST: A fast block cipher for arbitrary block sizes. In: Horster, P. (ed.) Communications and Multimedia Security II, Proceedings of the IFIP TC6/TC11 International Conference on Communications and multimedia Security (1996)
[13 ]C. Fruhwirth, New Methods in Hard Disk
Encryption.http://Clemensendorphin.org/nmihde/nmihde-A4-ds.pdf, 2005.
[14 ]N. Ferguson. AES-CBC + Elephant diffuser: A Disk Encryption
Algorithm for Windows Vista.
http://download.microsoft.com/download/0/2/3/0238acaf-d3bf-4a6d-b3d6-0a0be4bbb36e/BitLockerCipher200608.pdf,2006.
[15 ]Lempel-Ziv-Welch. http://en.wikipedia.org/wiki/Lempel-Ziv-Welch
[16 ]P. Crowley. Mercy, A fast large block cipher for disk sector
encryption. In Bruce Schneier, editor, Fast Software Encryption: 7th InternationalWorkshop, FSE 2000, 2001.
[17 ]Mitsuru Matsui. The first experimental cryptanalysis of the data encryption standard. In Y. Desmedt, editor, Advances in Cryptology - CRYPTO 1994, number 839 in Lecture Notes in Computer Science, pages 1-11. Springer-Verlag, 1994.
[18 ]M. Abo El-Fotouh and K. Diepold, Extended Substitution Cipher
Chaining Mode. http://eprint.iacr.org/2009/182.pdf
[19 ]P. Sarkar, Efficient Tweakable Enciphering Schemes from
(Block-Wise) Universal Hash Functions. http://eprint.iacr.org/2008/004.pdf
[20 ]S. Fluhrer, Cryptanalysis of the Mercy block Cipher. In: Matsui, M.
(ed.) FSE 2001. LNCS, vol. 2355, p. 28. Springer, Heidelberg (2002)
[21 ]I. P1619. IEEE standard for cryptographic protection of data on blockoriented storage devices. IEEE Std. 1619-2007, April 2008. http://axelkenzo. ru/downloads/1619-2007-NIST-Submission.pdf
[22 ]P. Rogaway. Efficient Instantiations of Tweakable Blockciphers and
Refinements to Modes OCB and PMAC. In Pil Joong Lee, editor, Advances in Cryptology - ASIACRYPT ’04, volume 3329 of LNCS, pages 16-31, 2004.
[23 ]Latest SISWG and IEEE P1619 drafts for Tweak