International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
782
SARM: An Approach for the Analysis of Association Rule
using SVM Classification Technique
Sarvesh Mishra
1, Nitin Mishra
2 1M.TECH (IT), RESEARCH SCHOLAR, NIIST, BHOPAL
2DEPARTMENT OF (IT), NIIST, BHOPAL
Abstract--In this paper the performance analysis of association rules discovering is evaluated and investigated by a novel text association rule mining approach SARM algorithm. The previous paper proposed work is implemented in this paper. Association rules are mined from the textual data using SVM Classification based association rule mining algorithm. Based on the high confidence value, a new text data is classified into one of the predefined classes. There are four types of datasets used in this experiment are Food dataset, IBM dataset, Symbolic dataset and Medical dataset in which Food and Symbolic datasets are synthetic datasets and IBM and Medical datasets are real world datasets. The experimental results shows that, this method improve the performance by significantly reducing the elapsed time required to obtain the association rules.
Keywords--SVM Classification based Association Rule Mining (SARM), Association rule mining, Classification
algorithm, Support Vector Machine (SVM) based
Classifier.
I. INTRODUCTION
Association rules express regularities that exist in a dataset. Because a vast amount of different association rules can be derived from even a tiny dataset, interest is restricted to those that occur often and that predict with a high confidence. The main task of association rule discovery is to extract frequent item sets from market basket data and to generate association rules from these frequent item sets. An association rule with confidence 100% is an exact association rule; all other association rules are approximate association rules. An association rule is of the form A ‐> B, where A is called the left hand side of the rule and B is called the right hand side of the rule. Set of association rules is derived from a set of transactions in a database. Let illustrate this with the dataset given in table 1[1]. It contains two transactions, namely T1 and T2. Each transaction happens to contain three items. For example, the items of transaction T1 are A, B and C. As the amount of possible association rules is often huge and as association rule mining is usually performed on large databases, special attention has been paid to developing efficient algorithms for association rule mining. As saw in the example given in Table 2, it is possible to generate all possible association rules based on a dataset and then calculate the support and confidence values for each of them.
However, this approach is very ineffective. A more effective approach is obtained by concentrating on the interestingness of the association rules right from the beginning. The combinations of items are called item sets, and the combinations of items with a pre-specified minimum support are called frequent item sets. The method functions so that, this research paper first creates the item sets that contain one item and that have the minimum support in the dataset. The next step is to create the item sets that contain two items based on the item sets created in the previous phase. Again, also the item sets of two have to have the minimum support. Bigger and bigger frequent item sets are created until all the possibilities given in the dataset are used. When applying association rule mining to real datasets, a major obstacle is that often a huge number of rules are generated even with very reasonable support and confidence. Post-processing can be efficiently integrated with existing rule reduction techniques to construct a concise, high-quality, and user-specific association rule set [1].
Association discovery is one of the most common data mining techniques that are used to extract interesting knowledge from large datasets [2]. Much effort has been made to use its advantages for classification under the name of associative classification [3, 4]. Association discovery aims to find interesting relationships between the different items in a database [5], while classification aims to discover a model from training data that can be used to predict the class of test patterns [6]. Both association discovery and classification rules mining are essential in practical data mining applications [2, 7], and their integration could result in greater savings and convenience for the user.
II. LITERATURE SURVEY
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
783
In this paper, the GART algorithm is proposed, which uses taxonomies to generalize association rules, and the Rule-EE-GAR computational module, that enables the analysis of the generalized rules.A problem found in the Data Mining process is the fact that several of the used algorithms generate large quantities of patterns, complicating the analysis of the patterns. This problem occurs with the association rules, a Data Mining technique that tries to identify all the patterns in a database. The use of taxonomies, in the step of knowledge post-processing, to generalize and to prune uninteresting and/or redundant rules may help the user to analyze the generated association rules. The traditional association rule mining framework produces many redundant rules. The extent of redundancy is a lot larger than previously suspected. This research paper present a new framework for associations based on the novel concept of closed frequent item sets. The number of non-redundant rules produced by the new approach is exponentially (in the length of the longest frequent item set) smaller than the rule set from the traditional approach. Experiments using several “hard” real and synthetic databases confirm the utility of our framework in terms of reduction in the number of rules presented to the user, and in terms of time.
The inductive learning of fuzzy rule-based
classification systems [9] suffers from exponential growth of the fuzzy rule search space when the number of patterns and/or variables becomes high. This growth makes the learning process more difficult and, in most cases, it leads to problems of scalability (in terms of the time and memory consumed) and/or complexity (with respect to the number of rules obtained and the number of variables included in each rule). In this paper, this research paper propose a fuzzy association rule based classification method for high-dimensional problems, which is based on three stages to obtain an accurate and compact fuzzy rule-based classifier with a low computational cost. This method limits the order of the associations in the association rule extraction and considers the use of subgroup discovery, which is based on an improved weighted relative accuracy measure to preselect the most interesting rules before a genetic post processing process for rule selection and parameter tuning. The results that are obtained more than 26 real-world datasets of different sizes and with different numbers of variables demonstrate the effectiveness of the proposed approach.
[10] Technological innovations have paved
breakthrough in faster processing of queries and
sub-second response time. Decision making and
understanding the behavior of the customer has become vital and challenging problem for organizations to sustain their position in the competitive markets.
Data mining tools have become surest weapon for analyzing huge amount of data and breakthrough in making correct decisions. The objective of Raorane A.A. et al. [9] is to analyze the huge amount of data thereby exploiting the consumer behavior and make the correct decision leading to competitive edge over rivals. Experimental analysis has been done employing association rules using Market Basket Analysis to prove its worth over the conventional methodologies.
It is observed from the analysis that the data mining tools can be effectively used for optimizing the patterns associated with dynamic behaviors of the transactions which were made by the customers in purchasing some specific products. they have used the Market basket analysis algorithm, a widely and more pre dominantly used algorithm from association rule in Data Mining. Using this algorithm the frequent transactions made by the customers have been analyzed using the support and confidence of the customers in buying associated items. By using this methodology it is seen that there exists certain association between the products at the time of purchasing the products by the customers.
Faten et al. [11], has proposed an algorithm for building ontology via set of rules generated by rule based learning system. This algorithm has extracted the rules generated from the original dataset in developing ontology elements. Domain ontology enhances the mining results of Association Rules, which also reduce the number of generated association rules. The adopted model is based on generalization and specialization processes in which the rules are filtered by metrics based on the coverage and confidence indicators. Hongyu Zhang et al. [12] have proposed the graphical representations of ontology„s to help define some complexity measures intuitively. They have classified these metrics into two sets: one for measuring the overall design complexity of an ontology (ontology- level metrics), and the other for measuring the complexity of internal structure (class-level metrics). Claudia Marinica et al [13], has used Domain Ontology„s, the integration of user knowledge in the post-processing task is strengthened. Furthermore, an interactive and iterative framework is designed to assist the user along the analyzing task. On the one hand, user domain knowledge is represented and on the other a novel technique is suggested to prune and to filter discovered rules.
III. PROPOSED TECHNIQUE
3.1 Classification
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
784
This classification is generalized such that it works for all the attributes types [1]. [image:3.595.324.520.291.405.2]3.2 Support Vector Machine (SVM) based Classifier The next architecture chosen for classification, which in turn involves training and testing, is Support Vector Machines (SVM). The use of SVM classifiers has gained immense popularity in recent years. The SVM Classifiers are comparable or even superior to the standard techniques like Bayesian classifiers or multilayer perceptions. SVMs are discriminative classifiers based on structural risk minimization principle. They can implement high dimensional feature spaces with flexible decision boundaries. In the implicit regularization of the classifier‟s complexity avoids over the fitting and mostly this leads to good generalizations. Some more properties are commonly seen as reasons for the success of SVMs in real-world problems. The optimality of the training result is guaranteed, fast training algorithms exist and little apriori knowledge is required, i.e. only a labeled training set. Determining the association rules manually is not feasible when one to deal with a real‐life dataset [1].
Fig 1. Association Rules Vs Fitness Value for Optimize System
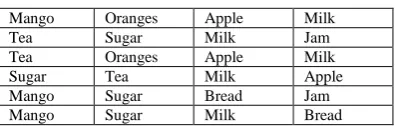
[image:3.595.51.273.407.537.2]This is why several algorithms for an efficient generation of association rules have been created. The graph obtained between fitness value and association rules shows in the Fig 1. Used the example dataset of Table 1. The amount of possible association rules is often huge and association rule mining is usually performed on very large databases, special attention has been paid to developing efficient algorithms for association rule mining.
Table 1 An example dataset.
Mango Oranges Apple Milk
Tea Sugar Milk Jam
Tea Oranges Apple Milk
Sugar Tea Milk Apple
Mango Sugar Bread Jam
Mango Sugar Milk Bread
In order to concentrate on the interestingness of the association rules right from the beginning and in order to avoid the creation of uninteresting association rules, this research paper will for the time being ignore the distinction into the right hand side and the left hand side of a rule. Instead, this research paper will just search for combinations of items that have a pre-specified minimum support.
The „database‟ below has six transactions. What association rules can be found in this set, if the minimum support (i.e coverage) is 60% and the minimum confidence (i.e. accuracy) 80% Trans_id Item list.
Table 2
Transaction-ID and Items Set of database.
Transaction-ID Items Set
1 A, B, C, D
2 E, F, D, G
3 E, B, C, D
4 F, E, D, C
5 A, F, H, G
6 A, F, D, H
3.3 SVM Classification
Support Vector Machines are based on the concept of decision planes that define decision boundaries. A decision plane is one that separates a set of objects having different class memberships. Support Vector Machine (SVM) is primarily a classier method that performs classification tasks by constructing hyper planes in a multidimensional space that separates cases of different class labels. SVM supports both regression and classification tasks and can handle multiple continuous and categorical variables. To construct an optimal hyper plane, SVM employees an iterative training algorithm, this is used to minimize an error function. According to the form of the error function, SVM models can be classified [1].
IV. EXPERIMENT AND RESULT ANALYSIS
The rule schemas are four operators:
a. Conforming
b. Pruning
c. Unexpected
d. Exceptions.
The rules are generated from SARM algorithm which is constructed and validated. Rule schemas are defined for each and every operator as follows [1]:
Let Cof. (Rsc) be the conforming rule schema, Cof. (Rsc) : M and N → O.
[image:3.595.66.264.691.754.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
785
The Rule Schema„s which are to be defined for each operator from our algorithm is Conforming Rule SchemasRsc: fa(Attributes) → fa(Values)
fa(Attributes) → { Fruits, Drinks, Foods}
fa(Values) → { Mango, Tea, Apple, Milk, Sugar, Jam, Oranges}
R1: Mango, Apple, Oranges → Fruits R2: Milk, Tea → Drinks
R3: Sugar, Bread, Jam → Foods
[image:4.595.324.553.318.415.2]The association rules similar to the above pattern has confirmed [1].
Table 3
Transaction-ID and Items Set of database.
Support % SARM Algorithm AVI Algorithm
25 756 2500
30 380 2500
35 230 2300
50 211 1100
60 189 850
70 175 900
90 176 800
[image:4.595.315.554.470.614.2]The support count denoted by N(X U Y) can be compute. Number of transaction, N is always Support (in percent for each association rule is simply a ratio between support count and the number of transaction. Support for the independent variable, n(x), is easier to compute than the support count for the union because it is only dependent on the sum of the binaries transaction record. Confidence is computing by taking ratio of support counts of the union of the dependent variable to the support count of dependent variable.
Fig 2. Performance Analysis of both algorithms
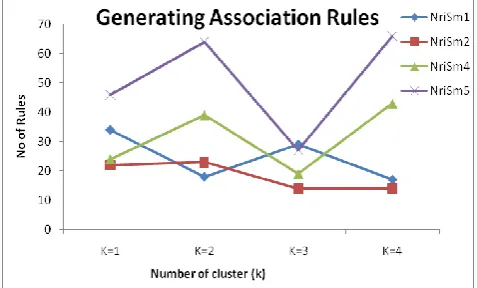
The next step to compute association rules is to apply two threshold criteria: minimum support and minimum confidence. Thus suppose to set two thresholds into cells for examples suppose set 50% minimum support and 75% minimum confidence. Minimum Support = 50%, Minimum Confidence = 75% Different threshold value will produce broader or stricter rules. . In this experiment the four different datasets are denoted by Nrism1, Nrism2, Nrism3 and Nrism4 for the Food dataset, IBM
dataset, Symbolic dataset and Medical dataset
respectively The Table 4. shows the association rules discovered for them in four individual clusters and Fig 3. Show the graph for the same.
Table 4
No of Rules Generated in different dataset of database.
For example, if set the minimum support to 30% and minimum confidence to 70%. This research paper will be obtained 6 association rules.
Fig 3. Generated Association Rules on four different datasets
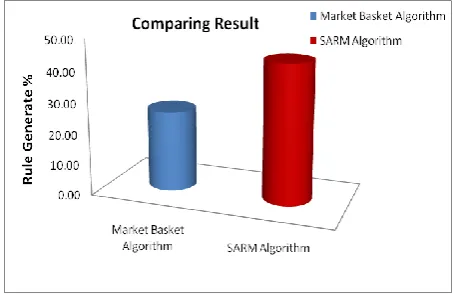
After comparing the performance of SARM algorithm to market basket algorithm it is clear that SARM algorithm is approximate 80% more accurate after using same data set. SARM algorithm generating time is less than 12 sec but Market Basket algorithm is more than 46 sec. fig 4 show comparing result of both algorithm.
Number of cluster (k)
Data set type K=1 K=2 K=3 K=4
NriSm1 34 18 29 17
NriSm2 22 23 14 14
NriSm4 24 39 19 43
[image:4.595.49.286.561.720.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
[image:5.595.50.277.135.282.2]786
Fig 4. Comparing result of both Market Basket Algorithm and SARM Algorithm using same dataset
As mentioned above, an advantage of this proposal is that it provides understandable rules and allows a context-free grammar to be adapted and applied to each specific problem.
V. CONCLUSION
SARM algorithm for mining association rules from real-world and large data sources are presented in this paper. From uses of SVM Classification it is possible that allows both categorical and numerical attributes is defined in our algorithm. Among sets of items in transaction databases, the use of any type of dataset without the need of a pre-processing step is one of the main advantages of SVM Classification. One of the most remarkable features of this algorithm and one that differentiates it from other algorithms is the use of some logical operators which allow to obtained frequent items in datasets where there are not too many frequent patterns are generated. Because of this discovery of association rules allows us to obtain more understandable and close relations between items sets, since these rules are more usable and understandable. The performance of SARM algorithm is analyzed in two different evaluation criteria are the rule generation percentage and elapsed time to obtain the association rules. The first criterion is compared with Market Basket algorithm and the second one with the AVI algorithm shows on Fig 4. and Fig 2. respectively. The SARM algorithm is found better in both comparisons and also requires low computational time than other algorithms for same categorical attributes. This research work is implemented and analyzed in matlab
REFERENCE
[1] Sarvesh Mishra, Nitin Mishra, “A Novel Approach for Discovery of an Association Rule Based On SVM Classification”, International Journal of Advanced Technology & Engineering Research (IJATER) ISSN No: 2250-3536 Volume 3, Issue 2, March 2013.
[2] J. Han and M. Kamber, “Data Mining: Concepts and Techniques”, 2nd ed.San Fransisco, CA: Morgan Kaufmann, 2006.
[3] B. Liu, W. Hsu, and Y. Ma, “Integrating classification and association rule mining,” in Proc. Int. Conf. Knowl. Discov. Data Mining, New York, 1998, pp. 80–86.
[4] R. Rak and L. K. M. Reformat, “A tree-projection-based algorithm for multi-label recurrent-item associative-classification rule generation,” Data Knowl. Eng., vol. 64, no. 1, pp. 171–197, 2008.
[5] C. Zhang and S. Zhang, Association Rule Mining: Models and Algorithms Series (Lecture Notes Computer Science Series 2307). Berlin, Germany: Springer-Verlag, 2002.
[6] V. Cherkasski and F. Mulier, Learning from Data: Concepts, Theory, and Methods. New York: Wiley-Interscience, 1998. [7] P. Tan, M. Steinbach, and V. Kumar, Introduction to Data
Mining. Boston, MA: Addison-Wesley/Longman, 2005. [8] Marcos Aurelio Domingues and Solange Oliveira Rezende “Using
Taxonomies to Facilitate the Analysis of the Association Rules” The Second International Workshop on Knowledge Discovery and Ontologies, 2007.
[9] Jes´us Alcal´a-Fdez, Rafael Alcal´a, and Francisco Herrera, “A Fuzzy Association Rule-Based Classification Model for High-Dimensional Problems With Genetic Rule Selection and Lateral Tuning”, IEEE TRANSACTIONS ON FUZZY SYSTEMS, VOL. 19, NO. 5, OCTOBER 2011 857.
[10] Raorane A.A. Kulkarni R.V. and Jitkar B.D. “Association Rule – Extracting Knowledge Using Market Basket Analysis”, Research Journal of Recent Sciences ISSN 2277-2502 Vol. 1(2), 19-27, Feb. (2012).
[11] Faten Kharbat, Haya Ghalayini, “New Algorithm for Building Ontology from Existing Rules: A Case Study”, International Conference on Information Management and Engineering, pg no.12-16, 2009.
[12] Hongyu Zhang, Yuan-Fang Li, Hee Beng Kuan Tan, “Measuring design complexity of semantic web ontologies”, The Journal of Systems and Software 83 (2010) 803–814 at ElSEVIER. [13] Claudia Marinica, Fabrice Guillet, “Knowledge-Based Interactive