International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
151
A New Hybrid Algorithm of Differential Evolution Algorithm
and Particle Swarm Algorithm
Ting Xiang, Dazhi Pan
1College of Mathematic and Information, China West Normal University, Nanchong 637009, China
Abstract—In this paper, we point out some shortcomings of Differential evolution algorithm (DE) with lower search efficiency and advance to the local optimal value easily.
Combining with particle swarm algorithm (PSO)’s
advantages of convergence rate, we put forward a new hybrid algorithm (DPM) to overcome these shortcomings. Instead of dividing all individuals into two equal size groups, in DPM algorithm, according to the concentration parameter, all individuals dynamic divided into two different size groups after a certain iterations. And then, merger the two groups, a novel mutation has been developed to some individuals to generate the new individuals. Finally, we will apply six famous benchmark functions to test and evaluate the performance of DPM. Compared with DE and PSO, we obtain that DPM has a faster and better convergence rate to the global optimum from the experimental results.
Keywords—Differential evolution algorithm, Particle
swarm algorithm, Concentration parameter, Novel mutation, Group dynamic division.
I. INTRODUCTION
Differential evolution algorithm (DE) and particle swarm algorithm (PSO) are two relatively new global optimization algorithms. Both of them are based on swarm intelligence and random strategy and according to their own search mechanism to find the optimal value. They are simple but effective with the advantages of less parameter. Recently, it has aroused many scholars’ attention for having been successfully applied in many areas of optimization problems.
Differential evolution algorithm (DE) was first introduced by Price in 1997[1], just like Genetic Algorithms (GA). DE consists of three main operations: mutation, crossover and selection. After iterated operations, generated individuals we can find the global optimum. DE has been used in many areas, such as filter design [2], image segmentation [3]. When individuals’ difference is decreasing and the increase of iterations, we find it easy to fall into local optimal value. Moreover DE has a considerably slow convergence rate. Besides we all can find that.
While Particle swarm algorithm (PSO) was first put forward by Kennedy and Eberhart in 1995(see [4], [5]). Based on swarm intelligence strategy, every particle’s trajectory can be decided by the global best position (Gbest) and the particle’s past best position (Pbest). Improved particle swarm algorithm is mainly applied to many aspects, such as Transmission Planning [6], the Unit Start-Stop [7] and etc. In the early evolution, PSO’s convergence rate is very fast, but when there is no better particle update the optimal position of history, all the particles will quickly gathered to the region of the current historical best position. In this consideration, algorithm will prone to fall into the local optimal value and remain stagnant.
To improve the performance of single DE and PSO algorithm, a number of hybrid algorithms have been developed to integrate the advantages both of them. For instance, Ye[8] proposed an evolutionary strategy in PSO’s Mutation operation, which eliminated half of the particles with low fitness and another half execution speed and location update operation and mutation operation with evolution strategies. A new evolutionary strategy was put forward in [9] to select half of the individuals for DE or PSO randomly and assign the best particle of each generation to PSO. In [10], the author apply DE’s mutation and selection operation to generate new individuals and PSO and DE’s crossover and selection operation for local search. In [11], let the method DE be applied for half individuals, PSO for another. And then information sharing mechanism can be used to reach the synergies of two groups.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
152
II. THE TRADITIONAL DEALGORITHM AND PSO
ALGORITHM
A. The traditional DE algorithm
Let the minimization problem be defined in D
dimensional space and one population consists of NP
individuals. For all iteration t, individual
1 2
( ) ( ( ), ( ), ( ))
i i i iD
X t x t x t x t , i
1, 2, ,NP
. and thevariables’ search range is[xjl,xju],j
1, 2, D
. Theinitial individuals are randomly determined, then mutation and crossover will be employed to generate new individuals and selection is applied to determine whether the new individual or the original one who will survive into the next generation. The process in details is described as follows.
A.1 Mutation
In the traditional DE, several strategies of DE are proposed in the mutation. In this paper, we choose the former strategies of DE/rand/1/bin. The mutation vector
( 1)
i
V t is generated by three randomly chosen target vectors
1 r
X ,Xr2,Xr3and a mutation parameter F. And the formula is:
1 2 3
( 1) ( ) ( ( ) ( ))
i r r r
V t X t F X t X t (1)
A.2 Crossover
Crossover is used to swap the dimensions between the target vectors and its original vectors controlled by crossover parameter CR. Swap mode is described as follow:
( 1); 0,1 ;
( 1)
( ), .
ij
ij rand
ij
v t if rand CR or j j
u t
x t otherwise
(2)
Where u tij( 1) is the j-th number of trial vectorU ti( ), j
is a randomly generated dimension to make sure that at least one dimension of the trial vector is closed to the mutant vector.
A.3 Selection
Selection is applied to determine whether the new individual or the original one who will survive into the next generation on the basis of the vectors’ fitness. Greedy selection is used:
( 1); ( ( 1)) ( ( ));
( 1)
( ); .
i i i
i
i
U t if f U t f X t
X t
X t otherwise
(3)
B. The traditional PSO algorithm
Particle swarm algorithm is to mimic the process of foraging birds. The solution of the optimization problem is regarded as a no volume and quality of birds. Every particle’s trajectory is decided by the Global best position (Gbest) and the particles’ past best position (Pbest) and after continuous motion until it reaches the optimal value. Procedure is as follows:
A minimization problem defined in D dimensional space, at each iteration t, Particle
1 2
( ) ( ( ), ( ), ( ))
i i i iD
X t x t x t x t , i
1, 2 NP
. The velocity is1 2
( ) ( , , , )
i i i iD
V t v v v , the global best position is
1 2
( , , )
best g g gD
G P P P , the particle’s past best
positionPi best (P Pi1, i2, PiD). In the iterative process, the
position X ti( ) is updated by the velocity V ti( ), for the next iteration using the following equation:
( 1) ( ) ( 1)
i i i
X t X t V t (4)
The velocity
( )
i
V t
can be calculated as below:1 1 2 2
( 1) ( ) ( ( )) ( ( ))
i i i best i best i
V t w V t c r P X t c r G X t (5)
The learning constant
c
1 andc
2are popularly equal to2.0. The inertia parameter
w
is an important parameter, which affects the performance of the algorithm. Whenw
is large enough, will help improve the global search ability of the algorithm. Whenw
is lower, it will improve the local searching ability properly. In order to make the algorithm better convergence to global optimal solution, we generally setw
0.9
initially, with the increase of iteration t, wdecreases to 0.4 in a linear way. Equation as follows:
w
0.9 0.5
t
T
(6)Where T is the maximum iteration number.
III. THE HYBRID ALGORITHM DPM
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
153
In PSO, when there is a better individual update best position in history, all particles will soon move closer to the position. In this consideration, the convergence is quite fast, but in later iterations, as the diversity of individuals decrease, individuals are closer to the local optimum region.For the cause to overcome DE's low search efficiency and remain PSO’s fast convergence rate, we introduce DPM. After iteration
p
t , dynamically changes the size of two subgroups. And then novel mutation will be applied in merger the two groups. The details are described as follows.
A. The group dynamic division of DPM
Setting an iteration parameter p
t ( p
t is divisible by T),
after each p
t , all individuals dynamic divided into two
different size groups according to the concentration parameter
max / avg
k f f , which is used to characterize the degree of evolution. In DE, the proportion of individuals consists is l:
max 1
0 2
1 1
4 4
1 3
4 4
3 3
4 4
p
f or t t
k l
k k
k
(7)
Where fmax represents maximum fitness value in the group, favg is average fitness, t is the current number of
iterations. About
l100%
individuals will be randomly selected to form a subgroup of DEDPM , and the rest swamp into the subgroup of PSO
DPM
. After each subgrouprunning
p
t generations, individuals merge into a new group, and then enter into the mutation operation.
In this way, at the early iterations, individuals posse a high diversity, which indicates that fmax is much larger than favg and k is comparatively small. DPM based on PSO
will contribute to speed up the search rate. But as the increase of t, diversity of individuals drops, fmax and favg
move considerable closer and k becomes larger, therefore DPM based on DE can improve the global search rate. Piecewise function (7) can ensure that DE and PSO work well.
B. A novel mutation for some individuals
With the continuation of iterative algorithm and the decrease of the group diversity, DE and PSO will get a global optimal solution or a local one. Local optimum makes evolutionary stagnation, and gradually the entire group fall into local optimum so that there does not exist the global optimum. Right now the algorithm escapes from local optima urgently, e.g. [13].
In DPM, after each
p
t generation, individuals merged into a new group and apply mutation operation once for it. This operation is mainly based on the mutation of DE to do a local perturbation for part of individuals in the population. Specific method is as follows:
Setting a parameter of probability (MP), individuals in the new group about MP will be reassigned (see [14]). (For example, MP=1, which indicates that all individuals except the best individual are mutated; while MP=0 that means all individuals are not mutated). Suppose those selected individuals are close to the optimal solution in their own history, enhance their greed and accelerate the convergence speed to achieve the global optimum. IndividualX t si( ) '
variation formula is:
1
( ) ( ) sin( ) ( ( ) ( ))
2
i ibest i r
t
X t P t m X t X t
T
(8)
Where
P
ibest is the past best position ofX ti( ),X
r1( )
t
isa randomly selected individual in the group and
r
1
i
, T isthe maximum iteration number, m is a disturbance parameter.
This local variation ensure diversity of the group within enhancing the greed of some selected individuals, letting algorithms run faster and has a better convergence rate to the global optimal solution. But we have to admit that, to some extent, the presence of MP makes the mutation is only for some individuals, which limits the greedy algorithm. From the formula (8), with the increase of iteration t, disturbance range becomes larger as mutation individuals near the optimal position in history. Moreover the disturbance growth rate will gradually slow down from the property of the sine function. At the end of the iteration, the range of disturbance expanded. In this way, DPM is qualified with a better and rapid convergence rate to the global optimal solution rather than the local one.
C. Working steps of DPM
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
154
Step1: Setting algorithm parameters.They are mutation parameter F, crossover parameter CR, the population size NP, maximum iteration number T, learning constant
1
c
and2
c , iteration parameter tp ,
mutation probability parameter MP, disturbance parameter
m.
Step 2: Randomly generated initial population.
The initial solutions are generated from a uniform distribution in the ranges[ , ],
1, 2
jl ju
x x j D . D is the
number of variables. Let the initial generation number t=1 and parameter a=1.
Step 3: Evaluation and dividing.
Calculate the current population of the fitnessf X t( i( )) to
find the maximum fitnessfmax, average fitness
avg
f
so as to work out the concentration parameter k. And then according to k and formula(7) we divide the population into subgroups DEDPM and DPMPSO .
Step 4: Run subgroups.
Let subgroup DE
DPM and DPMPSO run
p
t generation according to (1),(2),(3) and (4),(5) respectively. At the end of per
p
t generations, all the individuals merged into a new group to apply the mutation operation. After running each generation, t updated by t=t+1.
Step 5: Mutation.
Let subgroups merged into a new group and enter into the mutation operation. According to the probability parameter MP, mutation happens to those individuals who are randomly selected and the process of mutation based on the formula (8).
Step 6: Iteration termination.
The iteration goes to an end if
/
p
a
T t
, or the parameter a will be updated by a=a+1, and then algorithm jumps to the step3.IV. EXPERIMENTAL RESULTS AND RELATIVELY ANALYSIS
The proposed DPM algorithm procedure is coded in MATLAB. In order to evaluate the performance of DPM, six famous benchmark functions will be tested to do the comparison with DE and PSO.
A. Benchmark functions
In this section six benchmark functions are given in table 1. We denote D the dimension of test functions, S the ranges of the variables,
min
f
the function value of globaloptimum.
1
f
(Sphere) is a simple single-peak function,which is used mainly to examine the convergence rate.
2
f
(Rastrigrin) and3
f
(Griewank) are two typical nonlinear multimodal functions (That is a function with more than one local minimum value and not easy to find the global solution). The optimal solution of function4
f
(Rosenbrock) is defined in a smooth, long and narrowparabolic valley, which makes it difficult for algorithm to identify search direction.
5
f
( Shubert) andf
6(schaffer) aretwo-dimensional complex functions with a lot of local minimums and not easy to find the global solution.
TABLE 1.
BENCHMARK FUNCTIONS
function D S
f
min2 1
1
D
i i
f
x
30 [-100,100] 02 2
1
[ 10 cos(2 ) 10] D
i i
i
f x x
30 [-5.12,5.12] 02 3
1 1
cos( ) 1 4000
D D
i i
i i
x x
f
i
30 [-600,600] 01
2 2 2
4 1
1
[100( ) ( 1) ]
D
i i i
i
f x x x
30 [-30,30] 02 5 5
1 1
cos[( 1) j ] i
j
f i i x i
2 [-10,10] -186.73092 2 2 1 2
6 2 2 2
1 2
(sin ) 0.5
0.5
(1 0.001( ))
x x
f
x x
2 [-100,100] 0
B. Parameters setting and the value of
t
pIn order to ensure the algorithm DPM has a better and faster convergence rate to the global optimum. We set algorithm parameters as follows, NP=80, F=0.2, CR=0.4,
c1=c2=2.0, MP=0.8, m=1.9.
In DPM, after each
p
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
155
Therefore the value ofp
t
has an important influence onthe performance of the proposed algorithm. For this reason, we will discuss the value of
p
t
according to the functionrastingrin as follows.
To avoid the complexity of calculation, first we set
p
t
such that T can be divided by
p
t
. Second, we have got toknow that if we set
p
t
too small, it will consume muchtime in computation, especially in the high dimensional operation. Now we restrain tp T 2%and state examples
for T=2000 and T=1000. In table2, we will show results of different
p
t
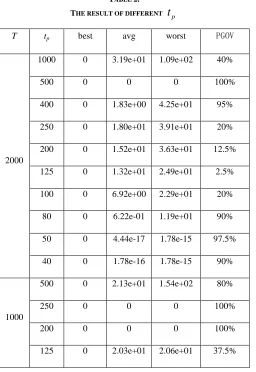
after DPM runs 40 times’ test, including the best value(best), average value(avg), worst value(worst) and the percentage of global optimum value (PGOV).TABLE 2.
THE RESULT OF DIFFERENT
t
pT tp best avg worst PGOV
2000
1000 0 3.19e+01 1.09e+02 40%
500 0 0 0 100%
400 0 1.83e+00 4.25e+01 95% 250 0 1.80e+01 3.91e+01 20% 200 0 1.52e+01 3.63e+01 12.5% 125 0 1.32e+01 2.49e+01 2.5% 100 0 6.92e+00 2.29e+01 20% 80 0 6.22e-01 1.19e+01 90% 50 0 4.44e-17 1.78e-15 97.5% 40 0 1.78e-16 1.78e-15 90%
1000
500 0 2.13e+01 1.54e+02 80%
250 0 0 0 100%
200 0 0 0 100%
125 0 2.03e+01 2.06e+01 37.5%
100 0 1.98e+01 4.78e+01 22.5% 50 3.54e-11 6.90e+00 2.59e+01 0 40 9.41e-14 5.72e-01 1.29e+01 0 25 0 1.95e-14 2.81e-13 42.5% 20 0 5.33e-16 7.11e-15 77.5%
From table 2, it is not difficult to get the conclusion that
with the decrease of
t
p, average value and worst valuedecreased gradually, while the operation is more complicated in time. From the view of the percentage of global optimum, for T=2000, percentage of the algorithm achieves global optimal is above 90% only when
500, 400,50, 40
p
t
. For T=1000, percentage of the algorithm achieves global optimal is above 90% only when250, 200
pt
. Taken together, we chooset
p
500
whenT=2000,
t
p
250
when T=1000, namelyT t
/
p
4
, fourtimes mutation and recombination.
C. Comparing DPM with DE and PSO
To evaluate the performance of DPM, six famous benchmark functions will be tested to compare with DE and PSO. In this section, we choose T=2000 and
500
p
t
, each function with 30 dimensions (function5
[image:5.612.44.300.346.718.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
156
TABLE 3. THE TEST RESULTS
best avg worst std PGOV
1
f
DE
9.66e-63 7.77e-25 2.33e-23 4.18e-24 0
PSO
6.82e-01 4.21e+00 9.17e+00 2.35e+00 0 DPM 0 1.52e-19 4.83e-18 7.73e-19 85.0%
2
f
DE 0 7.81e-01 4.31e+00 2.34e+00 7.5%
PSO
3.39e-01 2.16e+00 1.08e+01 1.93e+00 0
DPM 0 0 0 0 100%
3
f
DE 0 8.09e-02 1.81e+00 9.54e-01 12.5%
PSO
1.70e-01 7.81e-01 1.32e+00 2.96e-01 0 DPM 0 3.69e-04 1.48e-02 2.31e-03 95.0%
4
f
DE 2.09e
+01 4.60e+01 6.60e+01 2.99e+01 0
PSO 3.42e
+01 7.24e+01 1.66e+02 4.59e+01 0
DPM 2.24e
+00 2.32e+01 7.66e+01 1.78e+01 0
5
f
DE -186.7
309 -186.7308
-185.9031 1.16e-04 52.5%
PSO -186.7
309
-181.51 -123.27 1.27e+01 32.5%
DPM -186.7
309 -186.7309
-186.7309 0 100%
6
f
DE 0 2.59e-03 9.72e-03 2.20e-03 15.0%
PSO
2.64e-05 8.77e-03 2.30e-02 3.70e-04 0
DPM 0 0 0 0 100%
Judging from Table 3, DPM performs better than DE and PSO, especially for the convergence behavior. It is stable and can achieve global optimization better. Furthermore, in order to examine the convergence rate of DPM and get the advantages of DPM more clearly, we give the iterative process of the six functions of the three algorithm through fig1~fig6. In particular, to reflect the convergence effect of three algorithms better, we evaluating logarithm value of the fitness in some graphics. We note that mutation DPM can quickly converge to 0, while 0 is a singularity point of logarithm function, so the DPM’s image is only a part and the rest portion not shown that means the algorithm achieves global optimal value 0.
In figure 1~3, DPM shows a rapid convergence rate to the global optimal solution 0 in the 500th generation through a mutation and it is not easy to fall into local optimum. But it is difficult for algorithm to find the solution identify through function
4
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
157
In figure 4, we obtain that DPM has a strong ability to jump out of local optimum and converges to the global optimum.5
f
andf
6 are two-dimensional complexfunctions. In figure 5 and 6, we can further obtain that the global search ability of DPM is much stronger and converges to the optimal solution faster and better.
All in all, compared with the traditional DE and PSO, DPM has a faster convergence speed and stronger global search ability. Thus improved DPM is feasible and effective, as desired.
V. CONCLUSION
All in all, the new hybrid algorithm (DPM) we put forward overcomes shortcomings of differential evolution algorithm (DE) with low search efficiency and keeps advantages of particle swarm algorithm (PSO) with convergence rate. On this basis, it changes the size of the two subgroups of DE
DPM
andDPM
PSO dynamically,and then apply them with a novel mutation. From what we have stated above, the process of DPM is simple and easy to implement. Four famous benchmark functions’ results show that DPM can convergence to the global optimum with a faster and better speed, that is DPM we improved is feasible and effective.
Acknowledgement
Project supported by the Natural Science Foundation of Sichuan Education (11ZA040, 14ZA0127) and Doctor Foundation of China West Normal University (12B022).
REFERENCES
[1] Price K V. Differential evolution: A fast and simple numerical
optimizer. Proceedings of the 1996 Biennial Conference of the North American Fuzzy Information Processing Society[C]. Piscataway, NJ,USA: IEEE, 1996: 524-527.
[2] Storn Redesigning, Nonstandard filters with differential evolution,
IEEE Signal Processing Magazine,2005,22(1):103-106.
[3] Aslantas V,Tunckana T.Differential evolution algorithm for
segmentation of wound images: proceeding of 2007 symposium on
Intelligent Signal Proceeding, Madrid,October 3-5, 2007[C]. [s.l.]:
IEEE Explore,2007.
[4] Eberhart R, Kennedy J. A new optimizer using particle swarm theory.
Proceedings of the International Symposium on Micro Machine and Human Science [C]. Piscataway, NJ, USA: IEEE, 1995:39-43.
[5] Kennedy J, Eberhart, R. Particle swarm optimization. Proceedings of
the IEEE International Conference on Neural Networks[C]. Piscataway, NJ, USA: IEEE, 1995:1942-1948
[6] Rui-jun Ni,Min-xiang Huang.Transmission network expansion
planning based on improved particle swarm optimization algorithm. Energy Engineering, 2013, 4(1):7-10.
[7] Zhen-yu Zhang, Shao-yun Ge, LIU Zi-fa. Particle swarm
optimization algorithm and its application in unit commitment. Electric Power Automation Equipment, 2006, 26(5):28-31.
[8] Ye B, Zhu C Z, Guo C X. Generating extended fuzzy basis function
networks using hybrid algorithm. Proceedings of the 2nd International Conference on Fuzzy Systems and Knowledge Discovery [C].Berlin, Germany: Springer-Verlag. 2006. 79-88.
[9] Hong Zhan, De-yong Jiang. A new global optimization algorithm
based on differential evolution algorithm and the particle swarm optimization algorithm of double evolution mode. Heilongjiang Science and Technology Information.2012(32):8.
[10] Yuan-cheng Chi, Jie Fang, Guo-biao Cai. Hybrid optimization
algorithm based on differential evolution and particle swarm optimization. Computer Engineering and Design.2009, 30(12):2963-2965.
[11] Li-jun Luan, Li-jingTan, Ben Niu. A Novel Hybrid Global
Optimization Algorithm Based on Particle Swarm Optimization and Differential Evolution. Information and control.2007, 36(6):708-714.
[12] Min-feng Lang. Improvement of Genetic Algorithm and Its
Application in Combinatorial Optimization. East China Normal University, 2004.
[13] Hai-bin Ou-Yang, Li-qun Gao,Xiang-Yong Kong. Random Mutation
Differential Evolution Algorithm. Journal of Northeastern University (Natural Science).2013, 34(3):330-334.
[14] Guang-quan Zhao, Xi-Yuan Peng, Ning Sun. A Modified
Differential Evolution Algorithm with Local Enhanced Operator. Acta Electronica Sinica.2007, 35(5):849-853.
[15] Yinzhi Zhou, Xinyu Li, Liang Gao. A different evolution algorithm