International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
530
Preservation of Privacy for Multiparty Computation System
with Homomorphic Encryption
B. Murugeshwari
1, R. Sujatha
21
Assistant Professor, Department of Computer Science Engineering,Sree Sastha Institute of Engineering and Technology,Chembarambakkam, Chennai-600123, Tamil Nadu.
2Department of Computer Science Engineering,Sree Sastha Institute of Engineering and Technology,Chembarambakkam,
Chennai-600123, Tamil Nadu.
Abstract— Data mining is the task of discovering significant patterns/rules/results from a set of large amount of data stored in databases, data warehouse or in other information repositories. Even though the focus on data-mining technology has been on the discovery of general patterns some data-mining applications may require to access individual’s records having sensitive privacy data. Abundance of recorded, personal information available in electronic form coupled with increasingly powerful data-mining tools; pose a threat to privacy and data security. The aim of this work is to develop unique privacy preservation data-mining system with homomorphic encryption.
Keywords—Privacy Preserving Data Mining, Homomorphic encryption.
I. INTRODUCTION
Data mining refers to the techniques of extracting rules and patterns from data. It is also commonly known as KDD (Knowledge Discovery from Data). Traditional data mining operates on the data warehouse model of gathering all data into a central site and then running an algorithm against that warehouse. This model works well when the entire data is owned by a single custodian who generates and uses a data mining model without disclosing the results to any third party. However, in a lot of real life application of data mining, privacy [13] concerns may prevent this approach.
The first problem might be the fact that certain attributes of the data or a combination of attributes might leak personal identifiable information. The second problem might be that the data is horizontally partitioned across multiple custodians none of which is allowed to transfer data to the other site. The data might be vertically partitioned in which case[14], different custodians own different attributes of the data and they have the same sharing restrictions. Finally, the use of the data mining model might have restrictions - some rules might be restricted, and some rules might lead to individual profiling in ways which are prohibited by law.
Privacy preserving data mining [5, 16, 23] (PPDM) has emerged to address this issue. Most of the techniques for PPDM uses modified version of standard data mining algorithms, where the modifications usually using well known cryptographic techniques ensure the required privacy for the application for which the technique was designed. In most cases, the constraints for PPDM are preserving accuracy of the data and the generated models and the performance of the mining process while maintaining the privacy constraints. The several approaches used by PPDM can be summarized as below:
The data is altered before delivering it to the data miner.
The data is distributed between two or more sites, which cooperate using a semi-honest protocol to learn global data mining results without revealing any information about the data at their individual sites.
While using a model to classify data, the classification results are only revealed to the designated party, who does not learn anything else other that the classification results, but can check for presence of certain rules without revealing the rules.
In this paper, a privacy-preserving distributed mining algorithm has been presented.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
531 The malicious model assumes that parties can arbitrarily cheat and such cheating will not compromise either security or the results, i.e. the results from the malicious party will be correct or the malicious party will be detected. Most of the PPDM techniques assume an intermediate model, - preserving privacy [6] with non-colluding parties. A malicious party may corrupt the results, but will not be able to learn the private data of other parties without colluding with another party. This is a reasonable assumption in most cases.
II. RELATED WORK
This paper deals with classification and well-known privacy techniques such as homomorphic encryption and secure multi-party computation. Our goal is to achieve a better balance between data quality and privacy.
Data perturbation techniques have been proposed in order to obfuscate data such that when users submit their data to the data analyser individual data privacy is being protected but specific data mining algorithms can be applied on it. Privacy preserving data mining by adding noise on data has been first proposed in [1, 2]. The solution has been proposed for privacy preserving decision trees as a solution to derive association rules [11] from databases. In [21, 27] the authors proposed geometrical transformation for data clustering[7]. Transformation though are data dependent and do not scale for multidimensional data.
Data anonymization asks for unlinkability on data records and users. K-anonymity [28] has been proposed as a solution to protect the release of data to an untrusted party such that the personal private information for each data record cannot be distinguished from k-1 other users. Suppression and generalization are two techniques to achieve k-anonymity. By generalization, [12] specific attributes are generalized in order to protect user anonymity. For instance, instead of releasing the exact date of birth, only the month and the year is released. With suppression [26] no data is released. Solutions for data anonymity imply an information loss throughout the described techniques and operations after the release of the data are inconsistent.
Data separation in [11] cryptographic tools are being used to protect user data privacy when the id3 tree is constructed for association rules [24]. The id3 tree is a widely known technique for data classification. The categorical data of a set of records is being constructed by choosing the attributes than containing the higher information gain.
Information gain is expressed as conditional entropy and the problem of id3 construction is approximated by finding the attributes that information gain is maximized. The authors assume that data are split horizontally, thus the data analyser in order to compute the conditional entropy of two users should separately and privately obtain the data from both. It turns out that information gain for an attribute between two users is expressed as . The problem has been addressed as a secure multi-party computation of this expression for two users.
Privacy preserving data classification on horizontally partitioned data has been addressed in [6, 18] as well. The solution is based on a privacy preserving protocol for sum computation based on randomization and privacy preserving union set computation. Those two functionalities can securely be used by an untrusted party to infer the global confidence of an attribute in order to infer the association rules [29] that will classify the data. In [22] privacy preserving clustering on vertically partitioned data is addressed by submitting only the similarities on objects and not the real data. However, how the users are computing the similarities while at the same time preserving their privacy is not clearly addressed. Vaidya et al. tackle this issue by constructing a protocol for secure dot product computation without the use of a trusted party. However the communication cost for computing all the dot products between users is high [9].
Moreover, data separation techniques in which data are split in between different sites are not always a real world scenario in which each user holds its data in its entire form.
In Homomorphic encryption most previous works considered as homomorphic operations on ciphertexts encrypted under the same key [8]. These schemes do not directly apply in our case, since if participants encrypted their rules under the aggregator’s public key; the aggregator would not only be able to decrypt the aggregate statistics, but also each individual’s values. By contrast, our cryptographic construction allows additive homomorphic operations over ciphertexts encrypted under different users’ secret keys.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
532 As pointed out by Magkos et al. [17], their construction only supports a single time step, and an expensive re-keying operation is required to support multiple time steps. Secure multi-party computation (SMC) [10] is a well-known cryptographic technique allowing n parties with inputs respectively to privately compute functions . At the end of the protocol, party i learns the value of but nothing more. In a sense, SMC is orthogonal and complementary to differential privacy techniques. SMC does not address potential privacy leaks through harmful inferences from the outcomes of the computation, but one can potentially build differential privacy techniques into a multi-party protocol to address such concerns. Most SMC constructions are interactive. Therefore, directly employing SMC in our setting would require participants to interact with each other whenever an aggregate statistic needs to be computed. Such a multi-way interaction model may not be desirable in practical settings, especially in a client-server computation.
III. MATERIALS AND METHODS
A. C5.0 Classifier
The C5.0 algorithm [19, 20] is a new generation of Machine Learning Algorithms (MLAs) based on decision trees. Decision tree based classifiers are better for organizational decision support systems. The decision trees are built from list of possible attributes and set of training cases. The trees can be used to classify subsequent sets of test cases.
C5.0 offers a number of improvements on C4.5. Some of these are:
Rulesets - often more accurate, much faster, and much less memory
Decision trees – faster, smaller.
Boosting - several decision trees are generated and combined to improve the predictions.
New attributes - dates, times, timestamps, ordered discrete attributes and case labels.
Variable misclassification costs - it makes it possible to avoid errors which can result in harm.
Winnowing - C5.0 automatically winnows the attributes to remove those that may be unhelpful for particular cases.
Supports sampling and cross-validation.
C5.0 builds decision trees from a set of training data, using the concept of information entropy. The training data is a set of already classified samples.
Each sample consists of a p-dimensional vector where the represent attributes
or features of the sample, as well as the class in which falls. The training data is augmented with a
vector where represent the
class to which each sample belongs and n is total number of classes. A C5.0 model works by splitting the sample based on the attribute that provides the maximum information gain. Each sub sample defined by the first split is then split again, usually based on a different field, and the process repeats until the sub samples cannot be split any further. Finally, the lowest-level splits are re-examined.
Algorithm: Generate_decision_tree.
Input: The training samples, samples, represented by
discrete-valued attribute; the set of candidate attributes, attribute-list.
Output: A decision tree.
Method:
1. create a node N;
2. if samples are all of the same class, C then 3.return N as a leaf node labelled with the class C; 4. if attribute-list is empty then
5.return N as a leaf node labelled with the most common class in samples;
6. select test-attribute, the attribute among attribute-list with the highest information gain;
7. label node N with test-attribute;
8. for each known value of test-attribute;
9.grow a branch from node N for the condition test-attribute = ;
10.let be the set of samples in samples for which test-attribute = ; // a partition
11.if is empty then
12. attach a leaf labelled with the most common class in samples;
13.else attach the node returned by Generate_decision_tree( ,attribute_list_test_attribut e);
B. Homomorphic Encryption
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
533 In particular, it will be interested in additively homomorphic encryption schemes where the message space is a ring (or, more commonly, a field). Here, there exists an efficient algorithm whose input is the public key of the encryption scheme and two cipher texts, and
whose output is .
(Namely, it is easy to compute, given the public key alone and the encryption of the sum of the plaintexts of two cipher texts.) There is also an efficient algorithm , whose input consists of the public key of the encryption scheme, a cipher text, and a constant c in the ring, and whose output
is .
Encryption Algorithm:
1. The algorithm uses a large number 𝑁, such that 𝑁 = 𝑃 × 𝑄, where 𝑃 and 𝑄 are large security prime numbers.
2. Given X, which is a plaintext message, the encrypted value is computed:
Where 𝑚𝑜𝑑 ( ) is a common modulo 𝑁 – operation, 𝑅 is a random number within the uniform distribution (1, 𝑄).
Decryption Algorithm:
Given y, this is a cipher text message, the security key p to recover plaintext.
Note that for any X although , which means there is one to
many relationships between plaintext 𝑋 and cipher text 𝐸(X).
C. Framework
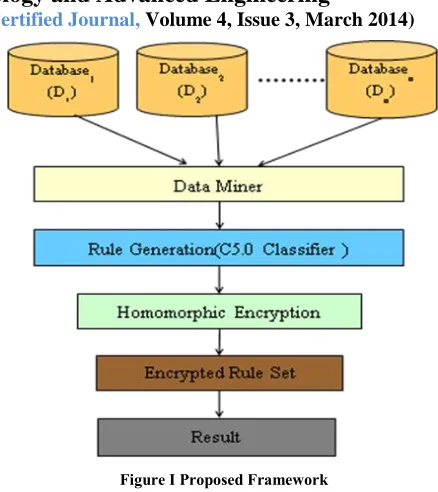
[image:4.612.332.551.115.361.2]Framework of proposed method, data miner collects the data from horizontally partitioned databases. In first phase data miner generates the rule based on C5.0 Classifier. In next phase this rule is encrypted by homomorphic encryption. Encrypted rule set is a result set. This result set to be used for cryptographic based secure data transfers, which is initialize secure rule set transaction.
Figure I Proposed Framework
IV. COMPARISON ANALYSIS
The accuracy of the proposed algorithm is more than 80% when compared to the existing algorithm like CHAID (Chi Square Automatic Interaction Detection) algorithm and Neural Network technique [3, 15, 25].
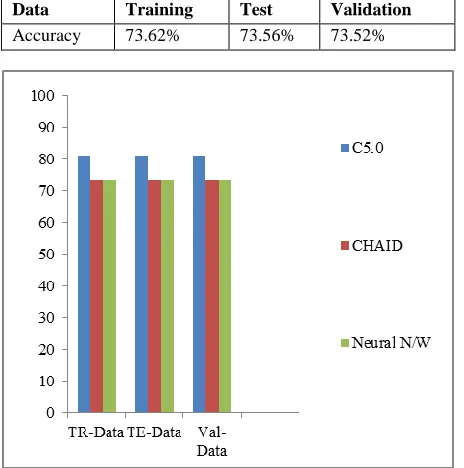
Table I, II and III provide the comparisons of classification accuracy among three algorithms: C5.0, CHAID, and Neural Network technique. Results show that the C5.0 algorithm achieves an accuracy of 81.23%, 81.20%, and 81.09 % for the training set (TR-Data), test set (TE-Data), and validation set (Val-Data) respectively. CHAID algorithm achieves an accuracy of 73.64%, 73.56%, and 73.51% for the training set, test set, and validation set respectively. Neural network algorithm achieves an accuracy of 73.62 %, 73.56%, and 73.52% for the training set, test set, and validation set respectively.
TABLEI
THE OVERALL CLASSIFICATION ACCURACY OF C5.0ALGORITHM
Data Training Test Validation Accuracy 81.23% 81.20% 81.09%
TABLEII
THE OVERALL CLASSIFICATION ACCURACY OF CHAIDALGORITHM
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
534
TABLEIII
THE OVERALL CLASSIFICATION ACCURACY OF NEURAL NETWORK
ALGORITHM
Data Training Test Validation Accuracy 73.62% 73.56% 73.52%
Figure II Comparison Analysis Of C5.0 With CHAID, Neural Network Algorithm
V. CONCLUSION
Privacy-preserving distributed mining algorithm has been presented. As demonstrated, the proposed algorithm is based on the technology of C5.0 algorithm and homomorphic encryption which is semantically secured. Future work will concentrate on homomorphic encryption with genetic algorithm.
REFERENCES
[1] R. Agrawal and R. Srikant, (2000) ―Privacy-preserving data mining‖, Proceedings of the ACM SIGMOD Conference on Management of data, pp. 439-450.
[2] D. Agrawal and C. C. Aggarwal, (2001) ―On the design and quantification of privacy preserving data mining algorithms‖, Proceedings of the Twentieth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, pp. 247–255. [3] M. Barni, C. Orlandi, and A. Piva. (2006) ―A Privacy Preserving
Protocol for Neural-Network-Based Computation‖, Proceedings of the eighth Workshop on Multimedia and Security, pp. 146–151. [4] C. Castelluccia, A. C.-F. Chan, E. Mykletun, and G. Tsudik. (2009)
―Efficient and provably secure aggregation of encrypted data in wireless sensor networks‖, Proceedings of the ACM Transactions on. Sensor Networks, Vol 5, Issue 3, pp. 1–36.
[5] Chris Clifton, Murat Kantarcioglu, and Jaideep Vaidya. (2002) ―Defining Privacy for Data Mining‖, Proceedings of the National Science Foundation Work shop on Next Generation Data Mining, pp. 126–133.
[6] C. Clifton, M. Kantarcioglu, J. Vaidya, X. Lin, and M. Y. Zhu, (2003) ―Tools for privacy preserving distributed data mining‖, Proceedings of the eighth ACM SIGKDD Explorations, pp. 639-644. [7] Geetha Jagannathan and Rebecca N. Wright. (2005) ―Privacy Preserving Distributed k-Means Clustering over Arbitrarily Partitioned Data‖, Proceedings of the eleventh ACM SIGKDD International conference on Knowledge discovery in data Mining (KDD), pp. 593–599.
[8] C. Gentry. (2009) ―Fully homomorphic encryption using ideal lattices‖, In STOC, pp. 169–178.
[9] B. Goethals, S. Laur, H. Lipmaa, and T. Mielikainen, (2005) ―On private scalar product computation for privacy-preserving data mining‖, Proceedings of the seventh international conference on Information Security and Cryptology, pp. 104–120
[10] O. Goldreich, (2004) ―Foundations of Cryptography‖. Vol 2, Basic Applications, Cambridge University Press.
[11] Gui Qiong, Cheng Xiao-hui. (2009) ―A privacy – preserving distributed for mining association rules‖, Proceedings of the International Conference on Artificial Intelligence and Computational Intelligence, pp. 294-297.
[12] V. S. Iyengar, (2002) ―Transforming data to satisfy privacy constraints‖, Proceedings of the eigthth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 279–288. [13] Jaideep Vaidya, C.Clifton (2003) ―Privacy-Preserving Data Mining‖,
Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 206-215
[14] Jaideep Vaidya and Chris Clifton. (2005) ―Privacy-Preserving Decision Trees over Vertically Partitioned Data‖, Proceedings of the nineteenth Annual IFIP WG Conference on Data and Applications Security, pp. 139–152.
[15] Jimmy Secretan, Michael Georgiopoulos, and Jose Castro. (2007) ―A Privacy Preserving Probabilistic Neural Network for Horizontally Partitioned Databases‖, Proceedings of the International Joint Conference on Neural Networks, pp. 1554–1559. [16] Y. Lindell and B. Pinkas, (2002) ―Privacy preserving data mining‖,
In CRYPTO, pp. 36–54.
[17] E. Magkos, M. Maragoudakis, V. Chrissikopoulos, and S. Gritzalis. (2009) ―Accurate and large-scale privacy-preserving data mining using the election paradigm‖, In Data & Knowledge Engineering. [18] Murat Kantarcioglu and Chris Clifton. (2004) ―Privacy Preserving
Distributed Mining of Association Rules on Horizontally Partitioned Data‖, IEEE Transactions on Knowledge and Data Engineering, Vol 16, Issues 9, pp. 1026–1037.
[19] B.Murugeshwari, C.Jayakumar and K.Sarukesi (2012) ―Secure Multiparty Computation Technique For Classification Rule Sharing‖, International Journal Of Computer Application (Ijca), Vol 9, Issue 9, pp. 1086-1091.
[20] B.Murugeshwari, C.Jayakumar and K.Sarukesi (2013) ―Preservation of the privacy for multiple custodian systems with rule sharing‖, Journal of Computer Science, Vol 73, pp.469-479.
[image:5.612.54.286.170.404.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
535 [22] S. R. M. Oliveira and et al., (2004) ―Privacy-preserving clustering by
object similarity-based representation and dimensionality reduction transformation‖, proceedings of the workshop on privacy and security aspects of data mining (PSADM04) in conjunction with the fourth IEEE international conference on data mining (ICDM04), pp.21–30.
[23] Rakesh Agrawal and Rama krishnan Srikant. (2000) ―Privacy Preserving Data Mining‖, Proceedings of the ACM Special Interest Group on Management of Data Conference (SIGMOD), pp. 439-450.
[24] Rizvi S & Harista JR, (2002) ―Maintaining data privacy in association rule Mining‖, Proceedings of the Twenty-Eigth Conference on Very Large Data Bases, pp.682-693.
[25] Saeed Samet and Ali Miri. (2008) ―Privacy-Preserving Protocols for Perception Learning Algorithm in Neural Networks‖, Proceedings of the fourth IEEE International Conference on Intelligent Systems, pp. 1065–1070.
[26] P. Samarati and L. Sweeney, (1998) ―Protecting privacy when disclosing information: k-anonymity and its enforcement through generalization and suppression,‖ In Tech. Rep.
[27] Somesh Jha, Louis Kruger, and Patrick Mc Daniel. (2005) ―Privacy Preserving Clustering‖, Proceedings of the tenth European Symposium on Research in Computer Security (ESORICS), pp. 397–417.
[28] L. Sweeney, (2002) ―Achieving K-Anonymity Privacy Protection Using Generalization and Suppression‖, International Journal of Uncertain Fuzziness Knowledge-Based Systems, Vol. 10, Issue. 5, pp. 571–588.
[29] V. S. Verykios,, Ahmed K. Elmagermld , Elina Bertino, Yucel Saygin, Elena Dasseni, (2004) ―Association Rule Hiding‖, IEEE Transactions on knowledge and data engineering, Vol.6, Issue.4. [30] B. Yang, Qian Li and Ling Jing, (2011) ―Privacy-preserving SVM of
horizontally partitioned data for linear classification‖, Proceedings of the fourth International Conference on Image and Signal Processing(CISP), Vol 5, pp. 2771 - 2775