2018 IX International Conference on Optimization and Applications (OPTIMA 2018) ISBN: 978-1-60595-587-2
One-Level Menu Optimization:
How to Make Conventional Things Better
Evgeny IVANKO
1,2Institute of Mathematics and Mechanics, Ural Branch, Russian Academy of Sciences, S.Kovalevskaya str. 16, 620990 Ekaterinburg, Russia
Ural Federal University, Lenin ave. 51, 620000 Ekaterinburg, Russia
Keywords: Menu optimization, HCI, access time, convenience, balance, UPGMA, Fitt’s law.
Abstract. In this article, I address the problem of 1-level horizontal menu access time minimiza- tion while preserving the menu’s conventional appearance. The proposed mathematical formal- ization shows high computational complexity even for the considered simplified problem. As an alternative, a heuristic is proposed to produce feasible solutions in polynomial time; 2 results of the application of the heuristic are presented.
Introduction
Menu design is a complex interdisciplinary problem with a wide range of applications as we all want to have convenient, efficient and good-looking menus at hand. Menus design was born at the crossroads of such fields as cognitive science, mathematical optimization, and graphical design. Presently, there are increasing attempts to combine convenience and efficiency of menus with the help of mathematics [1–5, 9, 10, 12, 15, 17, 20, 23, 25, 32]. It proved to be a hard problem due to the two main reasons: 1) the detailed models of user, where psychophysiology meets biomechanics, are relatively weakly studied [6–8, 13, 16, 19, 21, 24, 26–31]; 2) the balance between minimization of the expected access time and preservation of the accustomed appearance is ambiguous [11]. In this article, I will address the second issue.
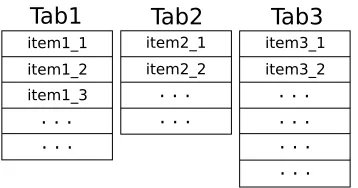
One-level menu may be formalized as an ordered sequence of “tabs”, where each tab is an ordered sequence of items (commands). In this article, I will talk only about the most common horizontal menus (see Fig.1), however, all the results may be directly extended to the case of vertical menus. The idea of optimization of one-level horizontal menus is based on placing the most frequently used menu items (or commands) top-left since, in accordance with cognitive science models, it minimizes the access time [1]. Whereas the “optimization” criterion tells us to put the most frequently used items at the most readily accessible places, the “appearance” criterion requires each item to be easy to find in context (it should lie within a reasonably named menu tab and should stay together with similar items).
Formulism in optimization here will lead to the situation, where e.g. “Save” and “Close” items are situated far from each other (since “Save” is used frequently and will stay top-left whereas “Close” will be pushed out to down-right by more frequently accessed items). To avoid this “overoptimization”, the arrangement of the items is replaced with the arrangement of unsplittable clusters of the items (Section 2). However, unsplittable clusters is not a panacea. The “appearance” criterion reveals itself in a more complex problem of constructing semantically consistent tabs (in
1
2
Tab1 Tab2 Tab3
item1_1 item1_2 item1_3
. . . . . .
item2_1 item2_2
. . . . . .
item3_1 item3_2
. . . . . .
[image:2.612.218.397.88.182.2]. . . . . .
Figure 1. One-level horizontal menu
other words, the tabs that can be easily named). The leftmost tab, constructed by straightforward optimization techniques, may e.g. contain two frequently used groups “Open, Save, Save As” and “Cut, Copy, Paste”, which not only breaks the conventional user expectations but also makes it hard to give this tab a head. Section 3 is devoted to the development of the heuristic that conducts optimization taking into account the above described specific issues.
Mathematical statement of simplified problem
The mathematical statements in the current and next sections are given using standard nota-tion, which however should be explained for a broader audience: AtB =C means thatA∪B =C
andA∩B =∅;P(X) is the set of all subsets ofX;f[X] is the image of the setX; Argmaxx∈Xf(x) is the set of the elements of X, at whichf(x) takes the maximum value; a singleton is a 1-element set.
Let I be the set of all items,f: I →Rbe the frequency of usage function, C={C1. . . Cn} be
the set of unsplittable clusters constructed a priori on the basis of some similarity function and let
n G
i=1
Ci =I.
Let N be the number of tabs. If N is not known in advance, it can be taken large enough, e.g. N = M; the optimization process will pull all the clusters leftward and leave the redundant right tabs empty. The optimization problem consists of four interconnected parts: 1) optimal distribution of the clusters from C among N tabs; 2) optimization of the order of the tabs from left to right; 3) optimization of the clusters within each tab; 4) optimization of the items within each cluster. The problem statement in this section is simplified: the semantic consistency of the tabs is not considered.
Letti ={C1i, . . . , CKii}, i∈1, N, be the set containing the clusters assigned to thei-th tab, and
N G
i=1
ti =C.
One of the approaches to minimization of access time is to balance the load of the tabs:
max
i∈1,N
{F(ti)} → min
t1t...ttN=C
, (1)
where F(Xi) is the summary cost of the i-th tab, computed based on the best possible order of
the weighted tab’s clusters:
F(ti) = min γ: 1,Ki↔1,Ki
( Ki X
j=1
W(Cγi(j))
)
. (2)
The weightW of each cluster is summed from the weights of its items, and the weight of each item is the product of its frequency and its distance from the top-left corner of the menu:
W(Cji) = |Ci
j|
X
l=1
h
f(c(li,j))((i−1) +4(i, j) +l)i, (3)
where c(li,j) is the l-th item of the j-th cluster in the i-th tab (in this notation, the elements of each cluster are assumed to be sorted by descending frequency ∀i ∈ 1, N ∀j ∈ 1, Ki (k < l) ⇒
(f(c(ki,j)) ≥ f(cl(i,j)))); f(c) is the frequency of the item c; (i−1) is the items’ distance shift due to the horizontal position of the whole i-th tab; 4(i, j) is the distance shift due to the position of the cluster in the tab, which depends on the summary power of the “upper” clusters
4(i, j) =
j−1
X
k=1
|Cγi(k)|. (4)
The distance components of (3) may be taken with different weightsω1, ω2, ω3, if such weights can be estimated from some cognitive model
W(Cji) = |Ci
j|
X
l=1
h
f(c(li,j))(ω1(i−1) +ω24(i, j) +ω3l)
i
. (5)
Problem (1) is a complicated variant of the partition problem [22] (NP-hard). Problem (2) is a TSP-like problem with a possible dependence of the cost function on a task list [14] (NP-hard). If problem (1)–(4) appears too complex from the computational point of view, the distribution and ordering components can be separated from each other. In this case, for example, at the first step, the clusters can be distributed among the tabs with the help of some simple functionFe(t) (instead
of the unknown optimalF(t) from (2)), and at the second step, where the clusters composing each tab are known, the problem (2)-(4) can be solved independently for each tab to find the optimum order of the clusters.
Algorithms
As it was noted before, a good menu should solve at least two (often conflicting) problems: 1) group similar items together; 2) provide fast access to the most frequently used items. The priority here should be given to the grouping, since a user could put up with the increasing access time, but would be definitely annoyed at the destruction of the groups he got used to. The optimization process considered in the previous section preserves conventional item groups (for example, the elements of the group {“Cut”, “Copy” and “Paste”} are not spread over different tabs). In this section, I consider a more careful grouping, which allows assembling reasonable “homogeneous” tabs that could be given reasonable names and provide navigation hints.
The primary grouping problem is addressed by a specific 2-level UPGMA-based (Unweighted Pair Group Method with Arithmetic Mean) [18] clustering method. At the first level of the proposed method, a known association function on unordered pairs of items is used to create unsplittable clusters of highly associated items. At the second, these clusters are merged into tabs. The frequency-connected optimization is conducted during the grouping process whenever possible, as far as it does not contradict the main clustering.
The first-level clustering method (Algorithm 1) is a variant of the classical UPGMA, which is used to construct unsplittable groups of closely related menu items. The merging process continues until there are no clusters, the similarity between which exceeds some preselected threshold. It should be noted that UPGMA algorithms implemented with heaps have polynomial time complex-ity O(n2logn) [18].
The second-level tab formation (Algorithm 2) is a UPGMA-inspired approach. The merging elements here are the unsplittable clusters generated at the first level. The second-level merging process continues until the largest cluster becomes large enough to be taken as one single tab. After that, the constructed tab is withdrawn, the remaining second-level cluster structure is destroyed and a new second-level merging process is started over the rest of the first-level unsplittable clusters. The resulting tabs are ordered by descending summary frequency, the first-level clusters within each tab are ordered by descending average frequency and the items within each first-level cluster are ordered by decreasing frequency. The number of tabs in this approach is not predefined. Different numbers of tabs are tried to construct the resulting menus and the one with the best value of frequency-motivated criterion is selected.
Algorithm 1 (First-level UPGMA clustering: find unsplittable groups).
// Data
1. I, a set of items; use it to construct the set of unordered pairs of the items
P :={B ∈ P(I) : |B|= 2};
2. A1: P →[0,1], an association function defined on P (the larger the closer);
3. τ, the stop threshold, which takes one of the following values: mean, mean ± standard
deviation or some percentile of A1[P];
// Results
4. C={C1, . . . , Cn}, the set of clusters such that tni=1Ci =I;
5. A2: {B ∈ P(C) : |B| = 2} → [0,1], an association function, defined on the unordered
pairs of the clusters, where A2({Ci, Cj})< τ if i6=j;
// Initialize
7. let C (current set of clusters) initially be the set of all possible singletons {x}, x∈I;
8. A2 is the association function defined on the singleton clusters as follows:
A2({{x},{y}}) :=A1({x, y});
9. C is the set of all unordered pairs of different clusters from C, the members of which are
close enough to be merged: C:={{X, Y} ∈ P(C) :X 6=Y & A2({X, Y})≥τ};
// Main cycle
while C6=∅ do:
10. select an arbitrary element z0 ={Ci, Cj} from Argmaxz∈CA2(z);
11. replace Ci and Cj with their union in the current set of clusters C:
C:= (C\ {Ci, Cj})∪ {Ci∪Cj};
12. extend the association function A2 considering the new item:
∀C∈C\ {Ci∪Cj} A2({C, Ci∪Cj}) :=w1A2({C, Ci}) +w2A2({C, Cj}),
where w1 =|Ci|/(|Ci|+|Cj|), w2 =|Cj|/(|Ci|+|Cj|);
13. refresh the set of pairs to join:
C:={{X, Y} ∈ P(C) :X 6=Y & A2({{X, Y})≥τ};
end
return C, A2.
Algorithm 2 (Second-level “careful” hierarchical clustering: build tabs).
// Data
1. C, a set of clusters;
2. A2, an association function, defined on the unordered pairs of the clusters;
3. f: I →R, the frequency of usage of the items;
// Result
4. T= (T1, . . . , TN), a sequence of disjoint tabs, where each tab Ti is a sequence of “ordered
clusters”(s(Ci
1). . . s(CKii))and each “ordered cluster” s(C
i
j)is a sequence of the elements
of the cluster Cji ∈C such that tN
i=1t
Ki
j=1C
i j =C;
// Initialize
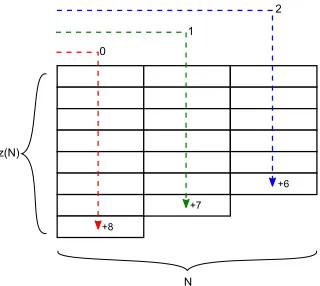
5. find the maximum size z(N) of a tab for the given number of tabs N and the known
number of items |I| (see Fig.2): (z(N)−0) + (z(N)−1) +. . .+ (z(N)−(N −1)) =|I|,
from where z(N) = IntegerPartOf ((2|I|+N2−N)/(2N) + 0.5);
6. build a frequency function on the clusters: ∀C∈C F(C) := P
x∈Cf(x)
/|C|
(alterna-tively, one could use the median);
7. for each C ∈C let s(C) be the sequence of the items x∈C sorted by descending f(x);
8. Q∗is an upper bound for the criterion functionQ(M)from (6), e.g. Q∗ = 2|I|4max
x∈If(x);
Figure 2. Second-level “careful” hierarchical clustering: build tabs (initialization part). Different sizes of “ideal” tabs depending on their distance from the upper-left corner (due to Fitt’s law [1,7]). Here we assume that the horizontal unit steps (from one tab to the next) and the vertical unit steps (between neighbor items in a tab) have equal weight
// Main cycle
for N ∈2,|C| do: //go through all reasonable numbers of tabs
9. Ce:=C; Ae2 :=A2;
10. M := min{z(N), N −2}; //limit the number of tabs to reduce the number of empty ones
11. for i∈0, M do: //construct the i-th of M tabs
a. continue an UPGMA-like clustering process (“second-level”) similar to that one de-scribed in Algorithm 1, iteratively merging the clusters from Ce into tabs (instead of
merging the items into clusters in Algorithm 1) and updating the similarity functionAe2 (instead of A1) until the overall number of the items in the largest second-level cluster is greater than z(N)−i;
b. letTi0+1 be any one of the largest second-level clusters resulted from the previous step;
c. exclude the clusters of Ti0+1 from the initial cluster set, forget about the remaining constructed tab structure and forget about the extensions made to Ae2:
e
C:=C\ i+1
[
j=1
Tj0, Ae2 :=A2|
e
C;
end
12. let M be i+ 2; put all the remaining first-level clusters (if any) into the last second-level cluster: TM0 :=eC;TM0 is a “freak tab” consisting of the first-level clusters that could hardly
be associated with any other first-level clusters (have small values of A2) and thus were not included into the previously formed second-level clusters at step 10;
13. rearrange the indexes 1. . . M such that T10, . . . , TM0 become sorted by the summary fre-quency of the contained items (P
C∈T0
P
i∈Cf(i)) in descending order;
14. for each i ∈ 1, M construct the tab Ti from the corresponding second-level cluster Ti0 by
sorting the first-level clusters of Ti0 by the average frequency F(C) in descending order;
15. the resulting ordered sequence (T1, . . . , TM), where each tab Tk is an ordered sequence
(s(Ck
1), . . . , s(C|kTt0|)) of “ordered clusters” and where each “ordered cluster” C
k
i is an
or-dered sequence of items (x(1k,i), . . . , x(|Ck,ik)
i|
), is referred to as a “candidate menu”; compute the “quality” (expected access efficiency) of this menu:
Q(M) :=
M X
k=1 |Tk0|
X
i=1 |Ck
i|
X
j=1
f(x(jk,i))
*
(k−1) +
i−1 X
q=1
Cqk
+j +!
; (6)
16. remember the new “candidate menu” if it is better than all the previous: if Q(M)< Q∗, then Q∗ :=Q(M) and T:= (T1, . . . , TM).
end
return T
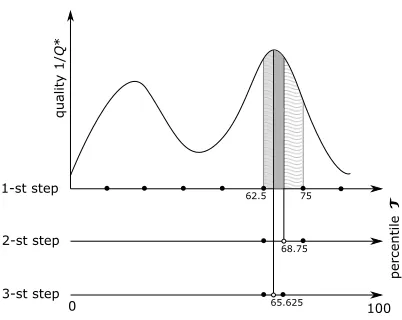
If there is a considerable amount of equal values of the association functions A1 and/or A2, the clustering process may become random since an arbitrary best pair is selected for merging. In this case, multiple runs of both algorithms could result in multiple feasible solutions with different structures, which can be compared on the basis of pure “quality”Q∗ as well as by human designers. The proposed heuristic is parametrized by the only parameter – stop threshold τ. In the general case, where no additional information is available, from practical experience it can be recommended to divide the percentile interval [1,99] regularly into L almost equal parts and to construct the menus for the values ofτ equal to all the obtained endpoints. For example, if L= 5, the endpoint percentiles could be {1,20,40,60,80,99}. After that, the designer (human) could select a couple of neighbor percentile endpoints corresponding to the menus that have the smallest values of Q∗ (or just those he prefers from the structural point of view) and use the bisection method between them, iteratively generating new percentiles and the corresponding menus that may converge finally to some local “optimum” (see Figure 3).
Results
The examples of application of Algorithms 1,2 are given in the following tables. Tables 1– 3 show the results of construction of menus using the 51 items of the Firefox browser original menu system (version 36). This problem is referred to below as “Firefox problem”. The values of frequency (f in Algorithm 2) and association (A1 in Algorithm 1) functions (Tables 1,2) were taken initially from the Mozilla Lab Test Pilot project (not supported anymore).
Table 4 shows the results of application of Algorithms 1,2 to a demonstrative toy problem, where a group of 44 organisms is organized into a virtual “menu system” (this demonstrative case is referred to below as “taxonomy problem”). “Taxonomic” association between two or-ganisms here is the number of shared taxonomic ranks, for example, the blue whale (Eukary-ota/Animalia/Chordata/Mammalia/Artiodactyla/Balaenopteridae/Balaenoptera) and the telephone-pole beetle (Eukaryota/Animalia/Arthropoda/Insecta/Coleoptera/Micromalthidae/Micromalthus)
quali
ty 1/
Q
*
percentil
e
100
62.5 75
65.625 68.75
0 1-st step
2-st step
[image:8.612.205.406.86.246.2]3-st step
Figure 3. Iterative application of the proposed heuristic by the bisection method
have only two shared taxons: Eukaryota/Animalia, so the association between them (function A1 in Algorithm 1) will be equal to 2/7 (where 7 is the maximum number of taxon ranks considered). The “frequency” of an organism is the number of the results Google Search returned for the name of the species on July 6, 2017, for example, the frequency for Giraffe is 130·106 search results. The purpose of this toy problem is to show that in an ideal situation the application of the proposed method allows one to construct the tabs that could have been given sensible names.
Acknowledgements
This research was supported by the Russian Science Foundation, grant no. 14-11-00109. The author wants to thank Prof. Antti Oulasvirta, MSc. Morteza Shiripour and Dr. Niraj Dayama from Aalto University, Finland for the fruitful discussions and valuable comments
Table 1. The correspondence between menu items, their labels and frequency for the “Firefox problem”
Abbreviation Menu item Frequency Abbreviation Menu item Frequency
A Recently Closed Tab 0.1798 b New Window 0.062
B Recently Closed Windows 10-4 c Open Location 0.0124
C User History Item 0.5146 d Open File 0.0496
D Show All Bookmarks 10-4 e Close Tab 10-4
E Bookmark This Page 0.9857 f Close Window 10-4
F Subscribe To This Page 10-4 g Save Page As 0.11717
G Bookmark All Pages 0.0744 h Email Link 10-4
H Unsorted Bookmarks 10-4 i Page Setup 10-4
I Minimize 10-4 j Print 0.1302
J Zoom 10-4 k Work Offline 0.1674
K Start Page 10-4 l Undo 10-4
L About Mozzila Firefox 0.124 m Redo 10-4
M Add-ons 0.16987 n Cut 10-4
N Check for Updates 0.4836 o Copy 0.0558
O Clear Recent History 0.16987 p Paste 0.031
P Customize 0.7254 q Delete 0.0186
Q Downloads 0.2852 r Select All 0.0124
R Private Browsing 0.0806 s Find 0.0558
S Reload 0.0124 t Find Again 10-4
T Stop 10-4 u Start Dictation 10-4
U Reset 0.093 v Back 0.0062
V Zoom In 0.0124 w Forward 10-4
W Zoom Out 10-4 x Home 0.0124
X Web Search 10-4 y Show All History 10-4
Y Page Info 0.031 z Restore Previous Session 10-4
[image:9.612.95.508.421.708.2]a New 0.12151
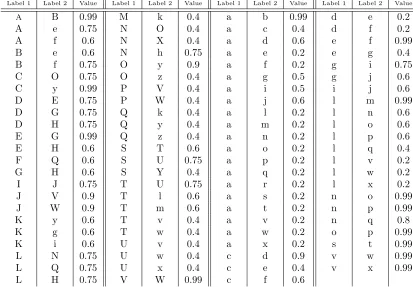
Table 2. Association functionA1 for the “Firefox problem” (all absent pairs have zero associa-tion)
Label 1 Label 2 Value Label 1 Label 2 Value Label 1 Label 2 Value Label 1 Label 2 Value
A B 0.99 M k 0.4 a b 0.99 d e 0.2
A e 0.75 N O 0.4 a c 0.4 d f 0.2
A f 0.6 N X 0.4 a d 0.6 e f 0.99
B e 0.6 N h 0.75 a e 0.2 e g 0.4
B f 0.75 O y 0.9 a f 0.2 g i 0.75
C O 0.75 O z 0.4 a g 0.5 g j 0.6
C y 0.99 P V 0.4 a i 0.5 i j 0.6
D E 0.75 P W 0.4 a j 0.6 l m 0.99
D G 0.75 Q k 0.4 a l 0.2 l n 0.6
D H 0.75 Q y 0.4 a m 0.2 l o 0.6
E G 0.99 Q z 0.4 a n 0.2 l p 0.6
E H 0.6 S T 0.6 a o 0.2 l q 0.4
F Q 0.6 S U 0.75 a p 0.2 l v 0.2
G H 0.6 S Y 0.4 a q 0.2 l w 0.2
I J 0.75 T U 0.75 a r 0.2 l x 0.2
J V 0.9 T l 0.6 a s 0.2 n o 0.99
J W 0.9 T m 0.6 a t 0.2 n p 0.99
K y 0.6 T v 0.4 a v 0.2 n q 0.8
K g 0.6 T w 0.4 a w 0.2 o p 0.99
K i 0.6 U v 0.4 a x 0.2 s t 0.99
L N 0.75 U w 0.4 c d 0.9 v w 0.99
L Q 0.75 U x 0.4 c e 0.4 v x 0.99
L H 0.75 V W 0.99 c f 0.6
1 U s e r H is to ry I te m ( 1 .7 4 ) N e w ( 3 .5 9 ) S h o w A ll B o o k m a rk s ( 2 .2 5 ) Zoo m ( 2 .5 5 ) C u t (3 .3 8 ) R e c e n tly C los e d Tab ( 2 .3 4 ) B a c k ( 1 .9 8 ) A d d -o n s ( 0 .1 7 ) N e w ( 0 .1 2 ) B o o k m a rk This P a g e ( 0 .0 9 9 ) C u s to m iz e ( 0 .0 7 2 ) P riv a te B ro w s ing ( 0 .0 0 8 1 ) R e c e n tly C los e d Tab ( 0 .0 1 8 ) R e s e t (0 .0 0 9 3 ) W o rk Of fli n e ( 0 .0 1 7 ) N e w W ind o w ( 0 .0 0 6 ) B o o k m a rk A ll P a g e s ( 0 .0 0 7 4 ) ---R e c e n tly C los e d W ind o w s ( 0 .0 0 0 1 ) R e loa d ( 0 .0 0 1 2 ) ---S h o w A ll B o o k m a rk s ( 0 .0 0 0 1 ) Find ( 0 .0 0 5 6 ) C o p y ( 0 .0 0 5 6 ) C los e Tab ( 0 .0 0 0 1 ) S to p ( 0 .0 0 0 1 ) C lea r R e c e n t H is to ry ( 0 .1 7 ) S a v e P a g e A s ( 0 .1 2 ) ---Find A g a in (0 .0 0 0 1 ) P a s te ( 0 .0 0 3 1 ) C los e W ind o w ( 0 .0 0 0 1 ) ---U s e r H is to ry I te m ( 0 .0 5 ) S ta rt P a g e ( 0 .0 0 0 1 ) C h e c k f o r U p d a te s ( 0 .0 4 8 ) ---C u t (0 .0 0 0 1 ) ---P a g e I n fo ( 0 .0 0 3 1 ) S h o w A ll H is to ry ( 0 .0 0 0 1 ) P a g e S e tu p ( 0 .0 0 0 1 ) E m a il L ink ( 0 .0 0 0 1 ) S e lec t A ll (0 .0 0 1 2 ) ---0 .0 1 8 ---D e let e ( 0 .0 0 1 9 ) H o m e ( 0 .0 0 1 2 ) D o w n loa d s ( 0 .0 3 ) P rint ( 0 .0 1 3 ) A b o u t M o z z ila Fire fo x ( 0 .0 1 2 ) Zoo m I n ( 0 .0 0 1 2 ) ---B a c k ( 0 .0 0 0 6 2 ) S u b s c ribe To T h is P a g e ( 0 .0 0 0 1 ) ---U n s o rt e d B o o k m a rk s ( 0 .0 0 0 1 ) Zoo m ( 0 .0 0 0 1 ) U n d o ( 0 .0 0 0 1 ) For w a rd ( 0 .0 0 0 1 ) ---Op e n Fil e ( 0 .0 0 5 ) ---Zoo m Ou t (0 .0 0 0 1 ) R e d o ( 0 .0 0 0 1 ) ---R e s to re P re v iou s S e s s ion ( 0 .0 0 0 1 ) Op e n L o c a tion ( 0 .0 0 1 2 ) W e b S e a rc h ( 0 .0 0 0 1 ) ---0 .0 1 6 ---M inim iz e ( 0 .0 0 0 1 ) 0 .0 1 9 0 .4 4 0 .2 6 0 .1 7
--- Sta
rt D ic ta tion ( 0 .0 0 0 1 )
--- 0.0
8 1 output_30 1 U s e r H is to ry I te m ( 1 .7 4 ) Zoo m ( 2 .5 5 ) S h o w A ll B o o k m a rk s ( 2 .2 5 ) N e w ( 2 .3 9 ) C u t (3 .3 8 ) B a c k ( 1 .9 8 ) Find ( 0 .9 9 ) A d d -o n s ( 0 .1 7 ) C u s to m iz e ( 0 .0 7 2 ) C h e c k f o r U p d a te s ( 0 .0 4 8 ) N e w ( 0 .1 2 ) P riv a te B ro w s ing ( 0 .0 0 8 1 ) R e s e t (0 .0 0 9 3 ) Find ( 0 .0 0 5 6 ) W o rk Of fli n e ( 0 .0 1 7 ) ---E m a il L ink ( 0 .0 0 0 1 ) N e w W ind o w ( 0 .0 0 6 2 ) ---R e loa d ( 0 .0 0 1 2 ) Find A g a in (0 .0 0 0 1 ) ---S a v e P a g e A s ( 0 .1 2 ) ---C o p y ( 0 .0 0 5 6 ) S to p ( 0 .0 0 0 1 ) ---C lea r R e c e n t H is to ry ( 0 .1 8 ) P rint ( 0 .0 1 3 ) B o o k m a rk This P a g e ( 0 .0 9 8 ) R e c e n tly C los e d Tab ( 0 .0 1 8 ) P a s te ( 0 .0 0 3 1 ) ---0 .0 0 5 7 U s e r H is to ry I te m ( 0 .0 5 1 ) S ta rt P a g e ( 0 .0 0 0 1 ) A b o u t M o z z ila Fire fo x ( 0 .0 1 2 ) R e c e n tly C los e d W ind o w s ( 0 .0 0 0 1 ) C u t (0 .0 0 0 1 ) P a g e I n fo ( 0 .0 0 3 1 ) S h o w A ll H is to ry ( 0 .0 0 0 1 ) P a g e S e tu p ( 0 .0 0 0 1 ) B o o k m a rk A ll P a g e s ( 0 .0 0 7 4 ) C los e Tab ( 0 .0 0 0 1 ) ---S h o w A ll B o o k m a rk s ( 0 .0 0 0 1 ) C los e W ind o w ( 0 .0 0 0 1 ) D e let e ( 0 .0 0 1 9 ) H o m e ( 0 .0 0 1 2 ) D o w n loa d s ( 0 .0 2 8 ) S e lec t A ll (0 .0 0 1 2 ) U n s o rt e d B o o k m a rk s ( 0 .0 0 0 1 ) ---B a c k ( 0 .0 0 0 6 2 ) S u b s c ribe To T h is P a g e ( 0 .0 0 0 1 ) ---Op e n Fil e ( 0 .0 0 5 ) S ta rt D ic ta tion ( 0 .0 0 0 1 ) For w a rd ( 0 .0 0 0 1 ) ---Zoo m I n ( 0 .0 0 1 2 ) W e b S e a rc h ( 0 .0 0 0 1 ) Op e n L o c a tion ( 0 .0 0 1 2 ) ---R e s to re P re v iou s S e s s ion ( 0 .0 0 0 1 ) Zoo m ( 0 .0 0 0 1 ) ---U n d o ( 0 .0 0 0 1 ) 0 .0 1 6 ---Zoo m Ou t (0 .0 0 0 1 ) 0 .1 7 0 .1 5 R e d o ( 0 .0 0 0 1 ) 0 .4 4 ---M inim iz e ( 0 .0 0 0 1 ) 0 .0 1 9
--- 0.2
T1 (Artiodactyla) T2 (Primates) T3 (Rodents) T4 (Snakes and lizards)
Bactrian camel (14·104) Orangutan (23·104) Ural field mouse (10·104) Marine iguana (6·104)
—–C1
1—– —–C12—– —–C13—– —–C14—–
Llama (211·106) Gorilla (103·106) Beaver (136·106) King cobra (769·104)
Giraffe (130·106) Chimpanzee (17.3·106) Black rat (5.9·106) Marine iguana (122·104)
Boar (34.1·106) Gibbon (14·106) Capybara (3.95·106) Ornate monitor (50·104)
Blue whale (12.1·106) Orangutan (13·106) Ural field mouse (4.72·104) Tokay gecko (34.7·104)
Sperm whale (302·104) Aye-aye (491·104) ————– Scincus scincus (8.03·104)
Bactrian camel (120·104) Pygmy marmoset (63.4·104) 145897200 Echis carinatus (5.69·104)
Bottlenose dolph. (114·104) ————– Typhlops verm. (2.54·104)
————– 152844000 ————–
392560000 9919600
T5 (Crocodiliaand turtles) T6 (Various insects) T7 (Beetles)
Aldabra giant tortoise (4·104) European mantis (10.4·104) Orthogonius baconi (14·104)
—–C5
1—– —–C16—– —–C17—–
American alligator (327·104) European mantis (57.8·104) Telephone-pole beetle (11.8·104)
Nile crocodile (252·104) Deroplatys desiccata (218·102) Cucujus (494·102)
Gharial (52.5·104) —–C26—– Dorcus rectus (1.31·104)
—–C25—– Lepisma saccharina (11.3·104) Mormolyce phyllodes (1.16·104)
Mary River turtle (120·104) Thermobia domestica (3.34·104) Orthogonius baconi (413)
Pig-nosed turt. (107·104) —–C6
3—– Paracupes ascius (134)
Loggerhead sea turt. (54.8·104) Velia caprai (2.18·104) ————–
Leatherback sea turt. (53.6·104) Ranatra fusca (2.09·104) 192647
Aldabra giant tort. (22.9·104) ————–
————– 788900
[image:11.612.57.572.87.435.2]9898000
Figure 5. Seven-tab “menu” constructed of 44 animals by Algorithm 1,2 (τ is equal to the mean of A1[P]) basing on “taxonomic” association function (see the details in the text); the names in parentheses in the first row near Ti are possible names of the tabs, given by the author; for the
details on other notation see the caption of Fig. 4
References
[1] David Ahlstr¨om. Modeling and improving selection in cascading pull-down menus using fitts’ law, the steering law and force fields. In Proceedings of the SIGCHI Conference on Human
Factors in Computing Systems, CHI ’05, pages 61–70, New York, NY, USA, 2005. ACM.
[2] Andre R. S. Amaral. An exact approach to the one-dimensional facility layout problem.
Operations Research, 56(4):1026–1033, 2008.
[3] Andre R.S. Amaral. On the exact solution of a facility layout problem. European Journal of
Operational Research, 173(2):508 – 518, 2006.
[4] Miguel F. Anjos and Anthony Vannelli. Computing globally optimal solutions for single-row layout problems using semidefinite programming and cutting planes. INFORMS Journal on
Computing, 20(4):611–617, 2008.
[5] Miguel F. Anjos and Manuel V.C. Vieira. Mathematical optimization approaches for facility layout problems: The state-of-the-art and future research directions. European Journal of
Operational Research, 261(1):1 – 16, 2017.
[6] Myroslav Bachynskyi, Antti Oulasvirta, Gregorio Palmas, and Tino Weinkauf. Is motion capture-based biomechanical simulation valid for hci studies?: Study and implications. In
Proceedings of the 32Nd Annual ACM Conference on Human Factors in Computing Systems,
CHI ’14, pages 3215–3224, New York, NY, USA, 2014. ACM.
[7] Myroslav Bachynskyi, Gregorio Palmas, Antti Oulasvirta, J¨urgen Steimle, and Tino Weinkauf. Performance and ergonomics of touch surfaces: A comparative study using biomechanical sim-ulation. InProceedings of the 33rd Annual ACM Conference on Human Factors in Computing
Systems, CHI ’15, pages 1817–1826, New York, NY, USA, 2015. ACM.
[8] Myroslav Bachynskyi, Gregorio Palmas, Antti Oulasvirta, and Tino Weinkauf. Informing the design of novel input methods with muscle coactivation clustering. ACM Trans.
Comput.-Hum. Interact., 21(6):30:1–30:25, January 2015.
[9] Gilles Bailly, Antti Oulasvirta, Duncan P. Brumby, and Andrew Howes. Model of visual search and selection time in linear menus. In Proceedings of the 32Nd Annual ACM Conference on
Human Factors in Computing Systems, CHI ’14, pages 3865–3874, New York, NY, USA, 2014.
ACM.
[10] Gilles Bailly, Antti Oulasvirta, Timo K¨otzing, and Sabrina Hoppe. Menuoptimizer: Inter-active optimization of menu systems. In UIST 2013 - Proceedings of the 26th Annual ACM
Symposium on User Interface Software and Technology, pages 331–342, 10 2013.
[11] Gilles Bailly, Antti Oulasvirta, Timo K¨otzing, and Sabrina Hoppe. Menuoptimizer: Inter-active optimization of menu systems. In UIST 2013 - Proceedings of the 26th Annual ACM
Symposium on User Interface Software and Technology, pages 331–342, 10 2013.
[12] Joseph L. Balintfy. Menu planning by computer. Commun. ACM, 7(4):255–259, April 1964. [13] Xiuli Chen, Gilles Bailly, Duncan P. Brumby, Antti Oulasvirta, and Andrew Howes. The
emergence of interactive behavior: A model of rational menu search. In Proceedings of the
33rd Annual ACM Conference on Human Factors in Computing Systems, CHI ’15, pages
4217–4226, New York, NY, USA, 2015. ACM.
[14] A. G. Chentsov and P. A. Chentsov. Routing under constraints: Problem of visit to mega-lopolises. Automation and Remote Control, 77(11):1957–1974, Nov 2016.
[15] A. I. Danilenko and M. V. Goubko. Semantic-aware optimization of user interface menus.
Automation and Remote Control, 74(8):1399–1411, Aug 2013.
[16] Robert G. Feyen. Bridging the gap: Exploring interactions between digital human models and cognitive models. In Proceedings of the 1st International Conference on Digital Human
Modeling, ICDHM’07, pages 382–391, Berlin, Heidelberg, 2007. Springer-Verlag.
[17] Mikhail V. Goubko and Alexander I. Danilenko. An automated routine for menu structure optimization. InProceedings of the 2Nd ACM SIGCHI Symposium on Engineering Interactive
Computing Systems, EICS ’10, pages 67–76, New York, NY, USA, 2010. ACM.
[18] Ilan Gronau and Shlomo Moran. Optimal implementations of upgma and other common clustering algorithms. Information Processing Letters, 104(6):205 – 210, 2007.
[19] Sujin Jang, Wolfgang Stuerzlinger, Satyajit Ambike, and Karthik Ramani. Modeling cumula-tive arm fatigue in mid-air interaction based on perceived exertion and kinetics of arm motion.
In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, CHI
’17, pages 3328–3339, New York, NY, USA, 2017. ACM.
[20] Birgit Keller and Udo Buscher. Single row layout models. European Journal of Operational
Research, 245(3):629 – 644, 2015.
[21] David E. Kieras and Anthony J. Hornof. Towards accurate and practical predictive models of active-vision-based visual search. In Proceedings of the 32Nd Annual ACM Conference on
Human Factors in Computing Systems, CHI ’14, pages 3875–3884, New York, NY, USA, 2014.
ACM.
[22] Richard E. Korf. Multi-way number partitioning. In Proceedings of the 21st International
Jont Conference on Artifical Intelligence, IJCAI’09, pages 538–543, San Francisco, CA, USA,
2009. Morgan Kaufmann Publishers Inc.
[23] Lilly M. Lancaster. The history of the application of mathematical programming to menu planning. European Journal of Operational Research, 57(3):339 – 347, 1992.
[24] Jamie Lennon. Connecting cognitive and physical worlds with dynamic cost function defini-tion. InProceedings of the 19th National Conference on Artifical Intelligence, AAAI’04, pages 989–990. AAAI Press, 2004.
[25] Robert Love and Jsun Wong. On solving a one-dimensional space allocation problem with integer programming.INFOR: Information Systems and Operational Research, 14(2):139–143, 1976.
[26] Michael Nielsen, Moritz St¨orring, Thomas B. Moeslund, and Erik Granum. A procedure for developing intuitive and ergonomic gesture interfaces for hci. In Antonio Camurri and Gualtiero Volpe, editors, Gesture-Based Communication in Human-Computer Interaction, pages 409–420, Berlin, Heidelberg, 2004. Springer Berlin Heidelberg.
[27] Erik Lloyd Nilsen. Perceptual-motor Control in Human-computer Interaction. PhD thesis, Ann Arbor, MI, USA, 1991. UMI Order No. GAX91-35659.
[28] Kent L. Norman. The Psychology of Menu Selection: Designing Cognitive Control at the
Human/Computer Interface. Greenwood Publishing Group Inc., Westport, CT, USA, 1991.
[29] Fabrizio Nunnari, Myroslav Bachynskyi, and Alexis Heloir. Introducing postural variability improves the distribution of muscular loads during mid-air gestural interaction. InProceedings
of the 9th International Conference on Motion in Games, MIG ’16, pages 155–160, New York,
NY, USA, 2016. ACM.
[30] Bryan Robbins, Daniel Carruth, and Alexander Morais. Bridging the gap between hci and dhm: The modeling of spatial awareness within a cognitive architecture. InProceedings of the 2Nd International Conference on Digital Human Modeling: Held As Part of HCI International 2009, ICDHM’09, pages 295–304, Berlin, Heidelberg, 2009. Springer-Verlag.
[31] Dario D. Salvucci and Frank J. Lee. Simple cognitive modeling in a complex cognitive archi-tecture. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’03, pages 265–272, New York, NY, USA, 2003. ACM.
[32] S. P. Singh and R. R. K. Sharma. A review of different approaches to the facility layout problems. The International Journal of Advanced Manufacturing Technology, 30(5):425–433, Sep 2006.
![Figure 5. Seven-tab “menu” constructed of 44 animals by Algorithm 1,2 (τparentheses in the first row nearof is equal to the mean A1[P]) basing on “taxonomic” association function (see the details in the text); the names in Ti are possible names of the tabs,](https://thumb-us.123doks.com/thumbv2/123dok_us/257443.1025833/11.612.57.572.87.435/constructed-algorithm-tparentheses-taxonomic-association-function-details-possible.webp)