2018 International Conference on Computer, Communications and Mechatronics Engineering (CCME 2018) ISBN: 978-1-60595-611-4
Research Hotspots Evolving Action Detection based on Time Sequence
Journal Topic Model
Chun-xiu DU, Fang HUANG
*, Shao-yong WANG,
Yi-jian ZHAO and Cheng-yuan ZHANG
School of Information Science and Engineering, Central South University, Changsha, 410083, China
*Corresponding author
Keywords: Time sequence journal topic model, KL divergence, Research hotspot, Evolving action.
Abstract. Since the research hotspot development in academic fields is mainly reflected through academic journal contents, how to analyze the evolving action of academic journal related topics is a huge factor for researchers in grasping the tendency of research hotspots. This paper considered and combined two characteristics of academic journals: 1) topic property and 2) time-sequence feature to realize journals’ time-sequence topic extraction, which also puts forward the TS-JTM (Time Sequence Journal Topic Model) at the same time. On the basis of TS-JTM, we developed topic-snapshot journal hotspot evolution model based on time sequence, and proposed a method which could detect the continuing, emerging, splitting, amalgamating or disappearing between two neighbor topic-snapshots, with adopting topic similarity measurement based on Kullback-Leibler (KL) Divergence. Our experiments show that the proposed method could realize evolving analysis of journals’ research hotspots effectively.
Introduction
Research hotspots are changing and evolving along with the development of science research and exploration. Because of the permeation among various subjects and utility of new technology, academic research hotspots are evolving over time. In this process, some outdated research problems will disappear and there will be emerging research topics appearing meanwhile. Also, some topics or directions will either split or get combined, which all lead to the evolution of research hotspots. Therefore, analyzing the hotspot evolution and seizing related traces are huge factors in predicting the research hotspot developing tendency. It could not only help to inform researchers about current research hotspots, but also could help scientific personnel and administrators to grasp researching trends. Additionally, the scientific researchers’ achievement and progress are mainly reflected among the journals where their papers are published. And these academic journals also collect and classify a large amount of research achievements. Due to the periodical publication, indeed, they keep track of the academic development of related fields which journals focus on. So, it will make sense to analyze hotspot evolving action with time through documents’ topic extraction.
algorithm which could detect evolving action between two neighbor topic-snapshots, adopting Kullback-Leibler Divergence (Relative Entropy) to realize granule analysis.
Related Work
Topic model could search for latent topic information among an incredible amount of data automatically, which is used for information retrieval, classification, clustering, abstract extraction, info similarity, relationship judgment and etc. Princeton professor Blei firstly proposed LDA (Latent Dirichlet Allocation) model in 2003. It is the most fundamental one among topic models and it is constructed with a framework: document-topic-word[1], namely, topic is the multinomial distribution of documents and word is the multinomial distribution of topics. Later, many researcher proposed a lot of improved model based on LDA. In 2004, ATM (Author-Topic-Model) was brought out by Rosen-Zvi[2], which realized building model of authors’ interests through excavation of documents and got the possibility distribution about authors’ contribution towards each topic. CTM (Correlated Topic Model) was proposed by Blei team[3], which adopted logarithm normal distribution to depict the relying relationship between two topics and solved the problem that standard LDA is not suitable for analyzing inner topic relativity. Because the number of topics in LDA model needs to set by researchers, in 2006, Teh proposed the HDP (Hierarchical Dirichlet Processes) [4]. He replaced the traditional Dirichlet distribution with Dirichlet process, and its property is that it takes advantage of DP infinite dimension feature to make topics cluster. In other words, it could generate topics automatically without setting the number. In 2014, F. Ying added the Dirichlet processes to LDA model[5], which could not only get the topic latent variable but also update Dirichlet priori parameters dynamically. In 2015, S. Liu brought out HB-HDP model[6]. It combined time info, user interests with topic labels and could realize Weibo topic clustering efficiently, which overcame the deficiency of Weibo sparse data caused by Weibo short length data genres. In 2016, C. Ying brought up discipline hotspots mining based on hierarchical Dirichlet topic clustering and co-word network[7], which could excavate research hotspots.
Since the generation of topic are evolving through time sequence, DTM[8] (Dynamic Topic Model), considering the influence from priori topics, breaks up time sequence into slices and then Markov Chain is brought in to connect time slices. This approach could bring the time sequence into topic model building. In 2013, Dubey et al. proposed npTOT[9] (non-parametric Topic Over Time), which allows a flexible distribution of infinite changing topics with topics' strength over time. In 2016, Fu proposed the DOHDP[10] (Dynamic Online Hierarchical Dirichlet Process), which was developed by using the OnlineHDP model between each period. And the exponential decay function was also used internally to develop the model of time dependence towards historical period. As a result, it could discover the topic evolution of Chinese social documents to a large extent. In 2010, Zhang brought up evolutionary hierarchical Dirichlet processes[11] based on HDP for multiple correlated time-varying corpora.
The Analyzing Process of Hotspots Evolving Action
The analysis of hotspots evolving action based on journal topic is composed of four main steps: 1) data preprocess 2) dynamic topic extraction 3) neighbor topic similarity measurement 4) detecting analysis of topic evolving action.
Step 1: We do a preprocessing for technological document and build up eigenvectors package for document. Firstly, get document information from the public document repository, including titles, abstract, key words, journal name, publishing time and etc. And then, we make a standard form process for the raw information with word segmentation, deleting stop words to establish document feature vectors, which would build up a corpus with time property.
Step 2: We combine the journal topic property with time-sequence feature to build up TS-JTM. Then it could realize topic extraction for above mentioned corpus depending on time-sequence and get the distribution of journal topics of each time slice.
Step 3: Measure the similarity of two neighbor topics in one journal randomly through building up topic-snapshot journal research hotspot evolution model with Kullback-Leibler divergence. We could develop the related-relationship between two time slices depending on the above similarity measurement.
Step 4: Analysis of journal topic evolution. On the basis of similarity of topics in neighbor time slices, detect topic evolving action of the continuing, emerging, amalgamating, splitting or disappearing through Step 3 analysis result.
Time Sequence Journal Topic Model
It is common that there are many journals under one of academic fields. And the topic of all documents which belong to one journal is the journal’s topic. In order to analyze journal topic distribution, we bring journal’s topic property and time-sequence feature into the model. Also, we re-define and re-infer parameters of the model base on reference[2] [8], which leads to the formation of TS-JTM.
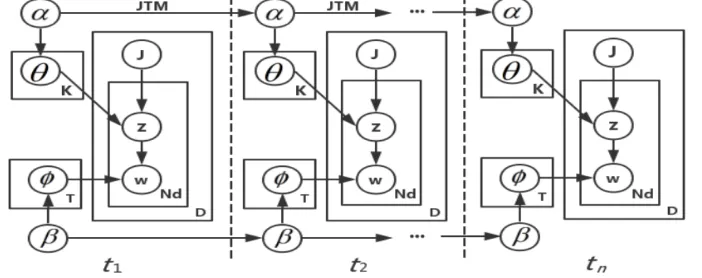
TS-JTM means the journal topic model(JTM) stuck inside each time slice. TheTS-JTM is shown
[image:3.612.133.484.523.662.2]in Figure 1. In journal topic model, α and β are respective priori parameters of the Dirichlet distributions toward journal-topic distribution θ and topic-word distribution ϕ, K means the total number of whole journals, T refers to the number of topics. The main idea of journal topic model is that: 1) select one topic z from the topic distribution θ of a journal J which covers a target paper, 2) then generate a word w randomly depending on the word distribution ϕ of the above selected topic z, 3) finally do not stop repeating above process 1) and 2) until generate each word of the target paper.
Figure 1. Time Sequence Journal Topic Model (TS-JTM).
framework of TS-JTM. In Figure 1, the model inside each time slice is just the JTM and neighbor time slices are connected through parameter α and β. The most important thing is that the influence of journal-topic distribution θ and topic-word distribution ϕ in the priori time slice will transmit to the model parameters in the next time slice.
Model Parameter
There are two parameters in the TS-JTM: 1) journal-topic distribution θ and 2) topic-word distribution ϕ. The parameter interference adopts Gibbs Sampling method. Each word inside the model is sampled from journals and topics according to Eq. 1. The right side of the equation is
p(topic|journal)·p(word |topic), which is the possibility of that journal chooses one topic and a word is selected from the topic meanwhile. Because the number of topics is T and there are K journals, the physical meaning of Eq. 1 is to exert sampling process in the T×K traces.
' '
' '
( , | , , )
KT WT
kj mj
i i i i i KT WT
kj m j
j m
C C
p z j x k w m Z X
C T C N
α
β
α
β
− −
+ +
= = = ∝
+ +
∑
∑
(1) zi=j and xi=k means that the word i in a paper or essay are allocated to the topic j and journal k.wi=m means the number of above word i is NO.m in the prepared dictionary. Z–iand X–i respectively represent the remaining topic and journal allocation except for the word i. WT
mj
C refers to that how many times has the word m been allocated to the topic j before. KT
kj
C means that how many times has the
journal k been allocated to the topic j. N is the number of words in the dictionary. And the dictionary is composed of words appearing in the data set uniquely. The only task of the parameter estimation in Eq. 1 is to keep track of two matrices. One is the word by topic counting matrix N×T and the other one is the journal by topic counting matrix K×T. Then, according to these two counting matrices, we could estimate topic-word distribution ϕ and journal-topic distribution θ. The estimating approaches are shown in Eq. 2 and Eq. 3.
' '
W T m j
m j W T
m j m
C
C
N
β
φ
β
+
=
+
∑
(2)' '
K T k j
k j K T
k j j
C
C T
α θ
α
+ =
+
∑
(3)
ϕmj represents the possibility of word m used in topic j and θkjrepresents the possibility that journal
k selects topic j.
2
1 1
| ~ ( , )
t t N t I
β
β
−β
−σ
(4)2
1 1
| ~ ( , )
t t N t I
α α − α − δ (5)
In the Figure 1, the parameter transmitting process between two neighbor time slice are as follows. Eq. 4 represents the priori parameter βt of topic-word distribution ϕt in current time slice is influenced by the generated from model training of previous neighbor time slice. βt and βt-1 conform
to the prerequisite of Markov process. Likewise, Eq. 5 represents the priori parameter αt of journal-topic distribution θt in current time slice is influenced by the αt-1 generated from model
Analysis of Topic-snapshot Journal Research Hotspot Evolving Action
We could attain journal-topic distribution in each time slice from TS-JTM and we will analyze research hotspot evolving action through establishing journal topic-snapshot model. With the help of Kullback-Leibler divergence to build up the relationship of neighbor time slice inside topic, we do a detection of topic evolving action.
Topic-snapshot Journal Research Hotspot Evolution Model
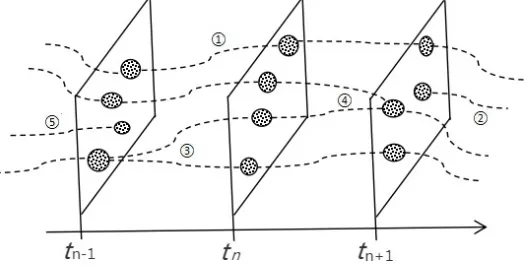
[image:5.612.176.440.273.406.2]The model is shown in the Figure 2. The three parts in the figure represent three topic snapshots inside their successively neighbor time slices. The several dotted lines represent topic relationships and there are five kinds of relationship are shown in the figure: 1) ‘one-to-one’ means that the current topic is the continuing of previous one. 2) ‘null-to-one’ represents an emerging topic which has no relationship with previous one. 3) ‘one-to-many’ means that the previous topic is divided into more topics. 4) ‘many-to-one’ represents several previous topics are amalgamated into one topic. 5) ‘one-to-null’ refers to that the previous topic has no relationship with the next time slice and it naturally perishes.
Figure 2. Topic-snapshot journal research hotspot evolution model.
The Detection of Topic Evolving Action Based on Kullback-Leibler Divergence
The topic will change and evolve along with the time, including disappearing, emerging, splitting and amalgamating. All of these conditions lead to topic evolving action. We will detect the evolving action and develop the relationship of topics inside neighbor time slices through Kullback-Leibler divergence measurement.
Topic Similarity Measurement Using Kullback-Leibler Divergence. Kullback-Leibler Divergence was proposed by Solomon Kullback and Richard Leibler[12], which is also called Relative Entropy. It is usually used to measure the similarity of two possibility distribution. Here, we use Kullback-Leibler Divergence to measure the similarity for each pair of topics inside neighbor time slices. Eq. 6 is the calculating approach of Kullback-Leibler Divergence. P(x) and Q(x) are two respective possibility distributions. If they are same, the value of KL divergence is zero.
( )
( | | ) ( ) l o g
( )
x X
P x
D P Q P x
Q x ∈
=
∑
(6)When it comes to measuring the similarity of topic A and topic B, it actually calculates their topic-word distribution (ϕA and ϕB) similarity. We build up the relationships of topics inside two neighbor time slices through calculating the KL divergence of each pair of their topics.
of detecting evolving action. As for the five actions which drive the topic evolving, related five detecting rules are listed in Eq. 7.
(
)
{
}
(
)
(
)
+ 1 1
+ 1 1
1 1
+ 1 + 1
+ 1 1
0 ( ) m i n ( || ) ,
& & ( || ) ,
1( ) m i n ( || ) ,
2 ( ) m i n ( || ) ,
3 ( ) ( || ) , ,
t
t t t
i j
t t t
i k
t t t
j i
t t t
i j
t t t
i j
i T
s
j
C o n t i n u i n g D T H R
H t a
j T
D T H R k T j
E m e r g i n g D T H R j T
D i s a p p e a r i n g D T H R j
l
t u s T
S p i t t i n g T R j T
φ φ φ φ φ φ φ φ φ φ + + − ∈ − + < ∈ ≥ ∈ − > < = ∈ > ∈ ∈ , , , ,
{
}
{
}
+ 1 1
1 1
1 1
2
& & ( || ) ,
4 ( ) ( || ) , , 2
& & ( || ) ,
t t t
i k
t t t
j i
t t t
k i
D T H R k T j
A m a l g a m a t i n g D T H R j T j
D T H R k T j
φ φ φ φ φ φ + − − − − ≥ < ≥ − ≥ ∈ ∈ ≥ ∈ − , (7)
The collection of topics in current time slice is t
T , and t i
φ is the topic distribution of topic i.
t
i T
status∈ represents the evolving action state of topic i in the time slice t. THR is the similarity threshold. The principle of detecting evolving action is to calculate the similarity of topic distribution in neighbor time slices. What matters is that: 1) if the topic i in current time slice is only similar with one of topics in next time slice and is different with others, the topic i will be a continuing in the next time slice; 2) if the topic i in current time slice is different with all of topics in previous time slice, it is a emerging one; 3) accordingly, if it is different with all of topics in next time slice, it just has perished; 4) if the topic i in current time slice has more than one similar topic in next time slice, the dividing action is happening; 5) on the contrary, if it is similar with more than one topic in previous time slice, it is amalgamating.
The first step of detecting topic evolving action is to use TS-JTM to achieve topic clustering. It will help to attain the topic distribution of each time slice. Then we use KL divergence to measure similarity of each pair of topics in neighbor time slices. Take advantage of Eq. 7 to detect evolving actions of all the topics in each time slice and build up topic relationship according to previous and follow-up topic ID. Finally, we are able to analyze the evolving action of journals.
Analysis of TS-JTM Performance and Evolutionary Actions Detection
Model Performance
In order to estimate the validity of TS-JTM, we adopt the perplexity to contrast the robustness of ATM and DTM with TS-JTM. The experiment is excused in the environment of Windows7 system with 8G memory and double kernels on a PC. Related algorithms are realized through Python.
Data Pre-process. We develop topic and word set through the technological documents gathered from China National Knowledge Infrastructure (CNKI) public resources. We select 6487 records of papers in computer science field dated from 2010 to 2016, including their abstracts, journals and publication time, as the experiment data. And we divide all of the data into 7 time slices according their publication year. Then we use the NLPIR system which is used to realize Chinese word segment on the abstracts and also delete stop words. This process helps us establish the collection
w={c1,c2,…,cn} of topic words for each paper and (wi,vi) represents paper-journal feature vector. wi
refers to the feature words collection of the paper i and vi represents the journal which the paper i
belongs to. In the time slice t, the data set Ct that is composed of n papers could be represented as Ct = {(w1,v1), (w2,v2),…,(wn,vn)}, which naturally forms the document feature vectors collection based on
Estimation of Model Performance. Eq. 8 is the calculation of perplexity. Dtest represents testing data, which is a collection of M documents. p(wd) represents the chosen possibility of words in the
paper. Nd represents the number of words in the paper d. wd = (w1d, w2d,…, wid,…, wnd) represents the
form of words vector of paper d. The less value of perplexity, the better performance of the model. Three parameters are set for the model before experiments. The parameter |T| which is the number of topic will ascend from 10. The two hyper parameters of ATM’s Dirichlet distribution was set as
α=50/|T| and β=0.01.
1
1
log ( )
P er ( ) exp
M
d d
test M
d d
p plexity D
N =
=
= −
∑
∑
w
(8)
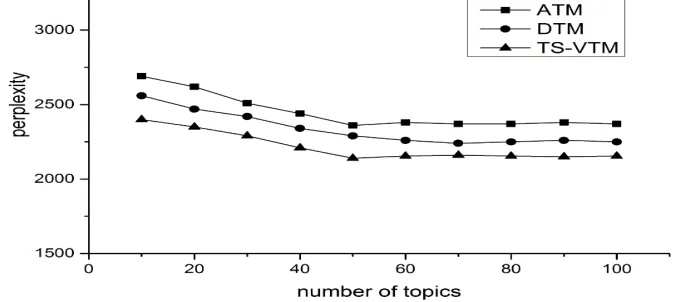
[image:7.612.137.479.321.472.2]The two hyper parameters of DTM’s and TS-JTM’s Dirichlet distribution in the first time slice is set as α=50/|T| and β=0.01. The rest of α and β parameters will be set automatically in the model. The comparison of results is showed in the Figure 3. The horizontal axis represents the number of topics and the vertical axis represents perplexity value. As you can see, with the increase of topics, the perplexity value of TS-JTM is always the smallest, which reflects that the performance of TS-JTM is the best among three models. Additionally, perplexity value will descend with the increase of topics and when the number of topics is greater than about 50, the perplexity value is almost static later. We could infer that setting the number of topics 50 in the TS-JTM is also suitable.
Figure 3. The curve of changing perplexity along with number of topics.
Analysis of Topic Evolution
Use the TS-JTM to achieve topic clustering. The number of topics (|T|) is set as 50, α = 50/|T| and β =
0.01. Then we get the journal topic distribution in each time slice. The selection of similarity threshold (THR) is influenced by the actual condition of data set. According to the principle of detecting topic evolving action and our iterative experiments, it is rational to set THR at 0.4.
Table 1. The topic-word distributions of Face Recognition.
Year Topic-word Distribution
2010
image(0.066) feature(0.061) algorithm(0.055) face recognition(0.042) classification(0.037) amalgamation(0.033) texture(0.027) sampling(0.025) threshold(0.019) dimension reduction(0.016)
2011
image(0.063) feature(0.059) amalgamation(0.057) Algorithm(0.052) face recognition(0.045) segment(0.038) classification(0.031) dimension reduction(0.026) extraction(0.022) training(0.017)
2012
image(0.078) feature(0.062) noise(0.055) algorithm(0.046) extraction(0.038) edge(0.032) face recognition(0.026) watermark(0.020) detection(0.018) threshold(0.014)
2013
image(0.083) algorithm(0.066) feature(0.052) sampling(0.044) filtering(0.040) face recognition(0.035) genetic algorithm(0.031) segment(0.024) edge(0.019) extraction(0.017)
2014
image(0.074) feature(0.061) algorithm(0.057) noise(0.052) classification(0.046) segment(0.043) face recognition(0.039) genetic algorithm(0.027) filtering(0.020) threshold(0.015)
2015
image(0.069) feature(0.059) amalgamation(0.052) algorithm(0.043) face recognition(0.037) SVM(0.032) deep learning(0.028) training(0.023) classification(0.022) segment(0.019)
2016
image(0.071) feature(0.064) algorithm(0.060) amalgamation(0.056) deep learning(0.047) face recognition(0.035) classification(0.033) perception(0.029) segment(0.024) contour(0.022)
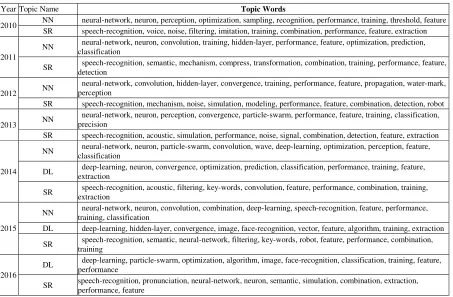
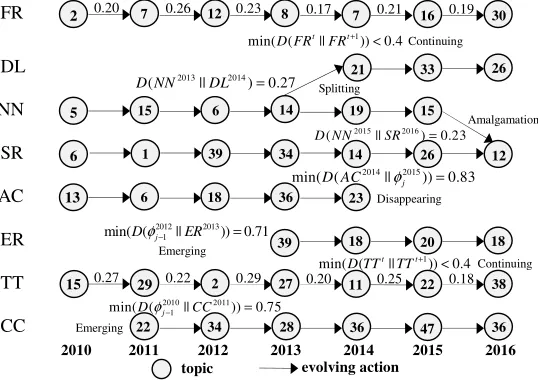
Journal Topics Evolve Over Time. In order to describe concisely, we will replace topic names with their abbreviations in the following part. Table 2 shows the top 10 possibility topic words of ‘Neural Network (NN)’, ‘Deep Learning (DL)’ and ‘Speech Recognition (SR)’ topics from 2010 to 2016. The kernel words of topic NN were almost static, except some edge words such as ‘sampling’ and ‘particle swarm’ distributions were changing obviously. The overlapping words between topic NN in 2013 and topic DL in 2014 are ‘training’, ’performance’, ‘feature’, ‘classification’ and ‘neuron’. Because of the similar word distributions of these two topics, the KL divergence of them is 0.27 which is kind of small. And it is smaller than THR. In 2013, the KL divergences between topic NN with all of topics in the next time slice are respectively 0.55, 0.27, 0.21, 0.69, 1.84, 1.16, 0.92, 1.53. The least two of them are related to topic DL and NN, and the rest of them are all greater than THR. In this case, the topic DL separated from topic NN.
Table 2. The word distributions of three topics: NN, DL, SR from 2010 to 2016.
Year Topic Name Topic Words
2010 NN neural-network, neuron, perception, optimization, sampling, recognition, performance, training, threshold, feature SR speech-recognition, voice, noise, filtering, imitation, training, combination, performance, feature, extraction
2011
NN neural-network, neuron, convolution, training, hidden-layer, performance, feature, optimization, prediction, classification
SR speech-recognition, semantic, mechanism, compress, transformation, combination, training, performance, feature, detection
2012 NN
neural-network, convolution, hidden-layer, convergence, training, performance, feature, propagation, water-mark, perception
SR speech-recognition, mechanism, noise, simulation, modeling, performance, feature, combination, detection, robot
2013 NN
neural-network, neuron, perception, convergence, particle-swarm, performance, feature, training, classification, precision
SR speech-recognition, acoustic, simulation, performance, noise, signal, combination, detection, feature, extraction
2014
NN neural-network, neuron, particle-swarm, convolution, wave, deep-learning, optimization, perception, feature, classification
DL deep-learning, neuron, convergence, optimization, prediction, classification, performance, training, feature, extraction
SR speech-recognition, acoustic, filtering, key-words, convolution, feature, performance, combination, training, extraction
2015
NN neural-network, neuron, convolution, combination, deep-learning, speech-recognition, feature, performance, training, classification
DL deep-learning, hidden-layer, convergence, image, face-recognition, vector, feature, algorithm, training, extraction SR speech-recognition, semantic, neural-network, filtering, key-words, robot, feature, performance, combination,
training
2016
DL deep-learning, particle-swarm, optimization, algorithm, image, face-recognition, classification, training, feature, performance
[image:8.612.82.535.445.742.2]Analysis of Journal Topic Evolution. The topic evolution of journal (ID:003) from 2010 to 2016 is shown in Figure 4. Because the same topics are formed as different ID by clustering in different time slices, the topic abbreviations is used to represent them. From the Figure 4, the KL divergences between all of topics in 2015 and topic SR in 2016 are 0.74, 0.46, 0.23, 0.16, 0.81, 0.95, 1.37. Among them, the values that are smaller than THR are topic NN and topic SR and the rest are greater than THR. This phenomenon means that topic NN was amalgamated into the topic SR, the KL divergences between topic ‘Aircraft’ in 2014 and all of topics in 2015 are 1.72, 1.46, 1.25, 1.07, 1.20, 0.83, 1.59. The least value is 0.83 which has been greater than THR. So in this case, the topic ‘Air Craft(AC)’ was perishing at that time. Furthermore, the KL divergences between all of topics in 2010 and the topic ‘Cloud Computing(CC)’ in 2011 are 1.16, 0.75, 1.37, 2.32, 1.51. The least of them is 0.75 which has been greater than THR. So the topic ‘Cloud Computing’ was an emerging one. Accordingly, the topic ‘Target Tracking(TT)’ was always in the state of continuing. The emerging topic in 2013 was ‘Entity Recognition(ER)’.
Figure 4. Topic evolving snapshot model of journal (ID:003).
In addition, to make a measurement of the running time of TS-JTM, we compared the running time of TS-JTM with ATM and DTM. Feeding them with same input, their running time are respectively 23.8 minutes, 25.6 minutes and 24.2 minutes. So TS-JTM is close to DTM, and ATM’s running time is the longest. Combined with the perplexity performance in the Figure 3, TS-JTM has not only low perplexity value, but also good running time performance.
Summary
The topic evolution of academic journals indeed reflects the tendency of research hotspots. Since the topic property and time-sequence feature will influence topic distributions and evolving processes, and also there are several evolving actions, the analysis of research hotspots tracing is becoming complicated. Combining the topic property with time-sequence feature, we proposed TS-JTM model. We realize research hotspots extraction through it and make a comparison depended on perplexity to prove its performance. On the basis of it, we develop topic-snapshot journal research hotspot evolution model based on time sequence and use the KL divergence to measure similarity, making a detection of continuing, emerging, splitting, amalgamating or disappearing between two neighbor topic-snapshots which realize the particle analysis of journal research hotspots evolution. Based on all of above mentioned research, our next work is to how to recognize topic layer semantic relationship and topic conception evolution.
0.18 0.20 0.25
1
min( ( t|| t )) 0.4 D FR FR+ < Continuing
2014 2015
min( (D AC ||φj ))=0.83
2015 2016
( || ) 0.23
D NN SR =
Amalgamation
2013 2014
( || ) 0.27
D NN DL =
0.26
1
min( ( t|| t )) 0.4 D TT TT+ < Continuing
2010 2011 1
min( (Dφj− ||CC ))=0.75
2012 2013 1
min( (Dφj− ||ER ))=0.71
Splitting
0.19 0.21
0.17
0.20 0.23
topic evolving action
2
16
DL 21 33 26
NN 15
FR 2 2 7 2 12 2 28 7 2 30 2
5 6 14 19 15
SR 6 1 39 34 14 26 12
AC 13 6 18 36 23 Disappearing
ER 20
0.22
0.27 0.29
TT
CC
18 18
Emerging 39 2
11
2010 2011 2012 2013 2014 2015 2016
Emerging 22 34 28 36 2 47 36 2
2
Acknowledgment
This work was supported by Project 2016JC2011 of Science and Technology Plan of Hunan Province and Project 61073105 of National Natural Science Foundation of China.
References
[1] Blei David M, A. Y. Ng, and M. I. Jordan, Latent dirichlet allocation, Journal of Machine Learning Research. 3. Jan (2003) 993-1022.
[2] M. Rosen-Zvi, T. Griffiths, M. Steyvers, The Author-Topic Model for Authors and Documents, Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. 2004.
[3] Blei David M, John D. Lafferty, A Correlated Topic Model of Science, Annals of Applied Statistics. 1.1 (2007) 17-35.
[4] Teh, Yee Whye, et al, Hierarchical Dirichlet processes, Journal of the American Statistical Association. 101.476 (2006) 1566-1581.
[5] Fang Y, Huang H Y, Xin X, et al, Topic Evolutionary Analysis for Dynamic Topic Number, Journal of Chinese Information Processing. 2014.
[6] Liu S P, Yin J, Huang Y, et al, Topic Mining from Microblogs Based on MB-HDP Model, Chinese Journal of Computers. 38.7 (2015) 1408-1419.
[7] Cai Y, Huang F, Peng M Y, Discipline Hotspots Mining Based on Hierarchical Dirichlet Topic Clustering and Co-word Network, Journal of Software. 11.11 (2016) 1089-1101.
[8] Blei David M, John D. Lafferty, Dynamic Topic Models, Proceedings of the 23rd International Conference on Machine Learning. 2006.
[9] Dubey A, Hefny A, Williamson S, et al, A non-parametric mixture model for topic modeling over time, Statistics. 2013.
[10] Fu, Xianghua, et al, Dynamic Online HDP model for discovering evolutionary topics from Chinese social texts, Neurocomputing. 171.C (2016) 412-424.
[11] Zhang, Jianwen, et al, Evolutionary hierarchical dirichlet processes for multiple correlated time-varying corpora, Acm Sigkdd International Conference on Knowledge Discovery & Data Mining. 2010.