International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
726
Understanding Web personalization with Web Usage Mining
and its Application: Recommender System
Manoj Swami
1, Prof. Manasi Kulkarni
2 1M.Tech (Computer-NIMS), VJTI, Mumbai. 2Department of Computer Technology, VJTI, Mumbai.
Abstract— Web is becoming an enormous storehouse of information and it will keep growing with improvements in internet technologies. But the human capability to read, access and understand content does not increase with that pace. Hence it becomes difficult to website owners to provide appropriate information to the users. This led to provide personalized web services to provide personalized web experience to users. One of the well-liked approaches in providing web personalization is Web Usage Mining. In this paper, we will discuss personalization process and its various modules. We will also discuss Recommender systems; which makes use of Web personalization for providing tailored recommendations to the user. After that we will discuss system architecture of recommender system.
Keywords—Recommender System, Web Personalization, Web Usage Mining
I. INTRODUCTION
Technological improvement has led to an explosive growth of recorded information, with the Web being a huge storehouse under no editorial control. Here, providing people with access to more information is not the problem; the problem is that more and more people navigate through large and complicated Web structures, find it difficult to access or get the information they want. Personalization can be the solution to this problem; since its objective is to provide users with information they want or need, without having to search for it explicitly. We meet cases of personalization in use in e-commerce applications, in information portals, in search engines and e learning applications.
Web personalization can be defined as any action that personalizes the Web experience to a particular user, or a set of users. The experience can be something as casual as browsing a Website or as significant as trading stocks. Principal components of Web personalization include modeling of Web objects (pages, etc.) and subjects (users), categorization of objects and subjects, matching between and across objects and/or subjects, and determination of the set of actions to be recommended for personalization. The actions can range from simply making the presentation more pleasing and providing customized information.
Recommender System:
Recommender systems can be utilized to efficiently provide personalized services in most e-business domains. Recommender Systems will help the customer by making to him suggestions on items that he is probably going to like. The two basic entities which come into view in any Recommender System are the user, one who uses the recommender system, and the item, that is to be recommended.
II. LITERATURE SURVEY
A) Personalization and Web usage mining:
The aim of personalization based on Web usage mining is to recommend a set of objects to the current user as determined by matching usage patterns. This task is accomplished by matching the active user session with the usage patterns discovered through Web usage mining. This process is performed by the recommendation engine which is the online component of the personalization system.
The process of Web personalization based on Web usage mining consists of three phases:
Data preparation and transformation
Pattern discovery
Recommendation
The data preparation phase transforms unprocessed Web log files into transaction data which can be then processed by data mining tasks. Various data mining techniques can be applied to this transaction data in the pattern discovery phase, such as clustering, association rule mining, and sequential pattern discovery. The results of the mining phase are transformed into aggregate usage profiles. These aggregate usage profiles are suitable for use in the recommendation phase. The recommendation engine takes into account the active user session in conjunction with the discovered patterns to provide personalized content.
B) Process of personalization:
The personalization process consists of following modules:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
727 1) Data Collection
Web personalization is based on three general types of data:
Data about the user, data about the Website usage and data about the software and hardware available on the user’s side.
Data about the user:
This category denotes information about personal characteristics of the user. Such as:
Demographics (name, phone number, geographic information, age, sex, education, income, etc.);
Skills and capabilities
Interests and preferences
Goals and plans (plan recognition techniques and identified goals allow the Website to predict user interests and needs and adjust its contents for easier and faster goal achievement).
There are two general approaches for collecting user data of the types described above: either the user is asked explicitly to provide the data, or the system implicitly derives such information.
Data about Website usage:
Usage data may be directly observed and recorded, or acquired by analyzing observable data. Usage data may either be:
Observable data consisting of selective actions like
clicking on an link and other confirmatory or
non-confirmatory actions (making purchases,
e-mailing/saving/printing a document, bookmarking a Web page and more), or
Data that derive from further processing the observed
and regard usage regularities (measurements of
frequency of selecting an option/link/service,
production of suggestions/recommendations based on situation-action correlations, or variations of this approach, for instance recording action sequences).
Data about software and hardware available on users’ side:
The variety of different hardware and software used on the client side is large and keeps growing. Thus such information should be taken into account to produce the adaptations. Environment data address information about
the available software and hardware at the client computer
(browser version and platform, availability of plug-ins, firewalls preventing applets from executing, available bandwidth, processing speed, display and input devices, etc.).
After data have been collected (a process that is in continuous), they need to be transformed into some form of internal representation (modeling) for further processing and easy update.
2) Data Analysis
Data analysis involves following phases:
Data preparation and preprocessing, Pattern discovery and Pattern analysis.
Data Preparation and Preprocessing
The objective of this phase is to derive a set of server sessions from raw usage data, as recorded in the form of
Web server logs. A server session is defined as a set of
page views served due to a series of HTTP requests from a
single user to a single Web server. A page view is a set of
page files that contribute to a single display in a Web browser window. Determining which log entries refer to a
single page view (a problem known as page view
identification) requires information about the site structuring and contents. A sequential series of page view
requests is termed click stream and it is its full contents that
we ideally need to know for reliable conclusions. A user
session is the click-stream of page views for a single user
across the entire Web, while a server session is the set of
page views in a user session for a particular Website. During data preparation the task is to identify the log data entries that refer to graphics or traffic automatically generated by spiders and agents. These entries in most of the cases are removed from the log data, as they do not reveal actual usage information. After cleaning, log entries are usually parsed into data fields for easier manipulation.
Apart from removing entries from the log data, in many cases data preparation also includes enhancing the usage information by adding the missing clicks to the user click stream. The reason dictating this task is client and proxy caching, which cause many requests not to be recorded in the server logs and to be served by the cached page views. The process of restoring the complete click-stream is called path completion and it is the last step for preprocessing usage data.
There are many more issues other than the path completion issue; which are to be overcome. One such
issue is user identification. A number of methods are
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
728 An embedded session ID requires dynamic sites and while it distinguishes the various users from the same IP/Agent, it fails to identify the same user from different IPs. Cookies and software agents accomplish both objectives, but are usually not well accepted (or even rejected and disabled) by most users. Registration also provides reliable identification but not all users are willing to go through such a procedure or recall logins and passwords. Alternatively, modified browsers may provide accurate records of user behavior even across Websites, but they are not a realistic solution in the majority of cases as they require installation and only a limited number of users will install and use them.
After that, there is an issue of session identification.
Trivial solutions tackle this by setting a minimum time threshold and assuming that subsequent requests from the same user exceeding it belong to different sessions (or use a maximum threshold for concluding respectively).
Pattern Discovery
Pattern discovery aims to detect interesting patterns in the preprocessed Web usage data by deploying statistical and data mining methods. These methods usually consist of (Eirinaki & Vazirgiannis, 2003):
Association rule mining: A technique used for finding frequent patterns, associations and correlations between sets of items. In the Web personalization domain, this method may indicate correlations between pages not directly connected and reveal previously unknown associations between groups of users with same interests.
Clustering: a method used for grouping together items that have similar characteristics. In our case items may either be users (that demonstrate similar online behavior) or pages (that are similarity utilized by users).
Classification: A process that assigns data items to one of several predefined classes. Classes usually represent different user profiles.
Sequential pattern discovery: An extension to the association rule mining technique, used for revealing patterns of co-occurrence, thus incorporating the notion of time sequence. A pattern in this case may be a Web page or a set of pages accessed immediately after another set of pages.
D) Pattern Analysis
In this final phase the objective is to convert discovered
rules, patterns and statistics into knowledge or insight
involving the Website being analyzed. Knowledge here is an abstract notion that in essence describes the transformation from information to understanding; it is thus highly dependent on the human performing the analysis and reaching conclusions.
3) Personalized Output
After gathering the suitable input data (about the user, the usage and/or the usage environment), storing them using an adequate representation and analyzing them for reaching secondary inferences, what remains is to decide upon the kind of adaptations the Website will deploy in order to personalize itself. These adaptations can take place at different levels:
Content: Typical applications of such adaptations are optional explanations and additional information, personalized recommendations, and more.
Structure: It refers to changes in the link structure of
hypermedia documents or their presentation.
Techniques deployed for producing this kind of adaptation comprise adaptive link sorting, annotation, hiding and unhiding, disabling and enabling, and removal/addition.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
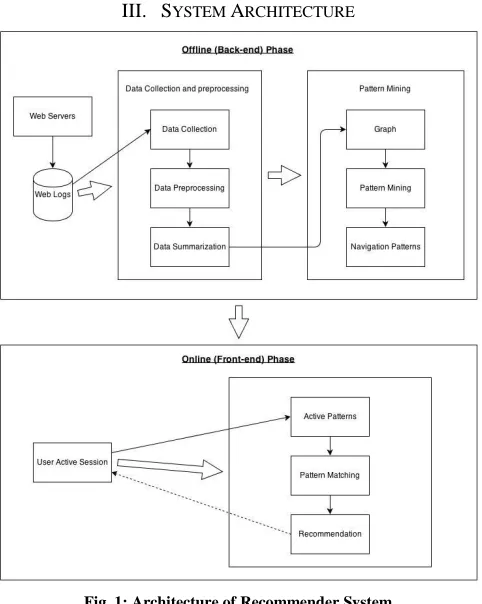
[image:4.612.49.290.136.438.2]729 III. SYSTEM ARCHITECTURE
Fig. 1: Architecture of Recommender System
There will be two phases in the whole process – I) Offline tasks that includes data preprocessing and cleaning followed by Pattern mining, II) online tasks that concern the generation of recommendations as shown in the fig., which outlines the architecture.
Data Preprocessing
The preprocessing phase is the first component in the architecture. Web server log file, which is the main source of input, generally contains noisy and irrelevant data. Preprocessing phase consists of data cleaning, user’s identification and session identification tasks. During preprocessing Web server log files are pruned to remove irrelevant requests such as non responded requests and requests made by software agents such as Web crawlers and search engines.
Pattern Mining
Following the data pre-treatment step, pattern mining is performed on the derived user access sessions. The representative user navigation pattern can be obtained by clustering algorithms. Clustering of user navigation pattern aims to group sessions into clusters based on their common properties.
Access sessions that are obtained by the clustering process are actual patterns of Web user activities. User navigation patterns are defined as follows:
Definition 1. A user navigation pattern np captures an aggregate view of the behaviour of a group of users based on their common interests or information needs. As the results of session clustering, NP = {np1, np2,. . . , npk} is used to represent the set of user navigation patterns, in
which each npi is a subset of P, the set of Web pages.
The process of the clustering takes three steps: are elaborated as follows:
(1) Compute the degree of connectivity between Web
pages and create an adjacency matrix.
(2) Create an undirected graph corresponding to the
adjacency matrix.
(3) Find connected component in the graph based on
graph search algorithm.
Online Recommendation Phase
The aim of a recommender system is to determine which Web pages are more likely to be accessed by the user in the future. In this phase active user’s navigation history is compared with the discovered Navigation patterns in order to recommend a new page or pages to the user in real time. Generally not all the items in the active session path are taken into account while making a recommendation. A very earlier page that the user visited is less likely to affect the next page since users generally make the decision about what to click by the most recent pages. Therefore the concept of window count is introduced. Window count
parameter ‘n’ defines the maximum number of previous
page visits to be used while recommending a new page.
IV. CONCLUSION AND FUTURE SCOPE
Web is growing rapidly, but on the other hand the user’s capability to access Web content remains constant. Currently, Web personalization is the most promising approach to alleviate this problem and to provide users with tailored experiences. Web-based applications (e.g.,e-commerce sites, e-learning systems, etc.) improve their performance by addressing the individual needs and preferences of each user, increasing satisfaction of user.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
730 There are a number of aspects that merit further improvement by the system. First is to take into account the semantic knowledge about underlying domain to improve the quality of the recommendations. Second is to integrate semantic Web and Web usage mining in achieving best recommendations from the dynamic and huge Web sites.
REFERENCES
[1] P. Markellou, Maria Rigou, Spiros S., Mining for Web Personalization, Web Mining: Applications and Technique. [2] Honghua Dai, Bamshad Mobasher, Integrating Semantic Knowledge
with Web Usage Mining for Personalization. Web Mining: Applications and Technique.
[3] C. Ramesh, Dr. K. V. Chalapati Rao, Dr. A. Goverdhan, A Semantically Enriched Web Usage Based Recommendation Model. International Journal of Computer Science and Information Technology (IJCSIT) Vol 3, No 5, Oct 2011.
[4] Daniar Asanov, Algorithms and Methods in Recommender Systems. [5] Emmanouil Vozalis, K.G. Margaritis, Analysis of Recommender
Systems’ Algorithms. Parallel and Distributed Processing Laboratory.
[6] A.C.M. Fong, B. Zhou, Jie Tang, Guan Y. Hong, Generation of Personalized Ontology Based on Consumer Emotion and Behavior Analysis. IEEE Transactions on Affective Computing, Vol 3, No 2, April-June 2012.
[7] Nizar R. Mabroukeh, C. I. Ezeife, Ontology-based Web Recommendation from Tags. ICDE Workshop 2011. 2011 IEEE. [8] A.C.M. Fong, B. Zhou, Jie Tang, Guan Y. Hong, Web Content