International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)168
Implementation of web access pattern discovery
Sheetal chouhan
1, Dr.Manish Shrivastava
2, Kavita Deshmukh
31
M.Tech, Dept. of Information Technology, LNCT, Bhopal, India
2Head, 3Ast. professor, PG Dept. of Information Technology, LNCT, Bhopal, India
Abstract — in this era of technology about 70% of people are use internet or web services and moreover it they consume and generate more data in a fraction of small time. This data is helpful to discover new dimensions of knowledge. In this paper we include the implementation of web access pattern discovery in a small scale data source. For that purpose we implement a proxy server and add requested data and response data over log to extract knowledge which kind of data is frequently used by different kind of web users. This access pattern is helpful in different domains i.e. cyber-crime, search engines prefetching concepts. In this paper we also include the algorithm that is helpful to discovery of patterns, results and our conclusion.
Keywords— proxy, log mining, pattern discovery, cyber-crime, knowledge.
I. INTRODUCTION
Examination of useful statistics from the World Wide Web required web mining. That is the application of data mining techniques to discover patterns from the Web. According to analysis objective, web mining can be divided into three different types, which are Web usage mining, Web content mining and Web structure mining.
Web usage mining: this domain allows for the collected works of Web access information for Web pages. This usage data provides the paths leading to accessed Web pages. This information is often gathered automatically into access logs via the Web server.
Web content mining: this technique is also known as text mining, is generally the second step in Web data mining. Content mining is the scanning and mining of text, pictures and graphs of a Web page to determine the significance of the content to the search query.
Web structure mining: that is one of three categories of web mining for data, is a tool used to recognize the connection stuck between Web pages linked by information or direct link connection. This organization of data is discoverable by the condition of web structure schema through database techniques for Web pages. This relationship allows a search engine to pull data concerning to a search query directly to the connecting Web page from the Web site the content rests upon.
In this discussion we found a fact web access log and its mining is not a correct way to discover data consumed by different kind of users this is restricted over a simple web server and their served domains.
For example if there is a web server and host about 10 web sites on it then the access log of that server is able to locate knowledge about only 10 web sites and their contains. But if we want to know which kind of data is consumed by the particular user the mining of different web servers is not a good idea. Thus there is a need to analyze the low level data analysis.
In the next section we include problem formulation, their possible solutions, adoptable solution, system architecture, implementation and their results.
II. BACKGROUND
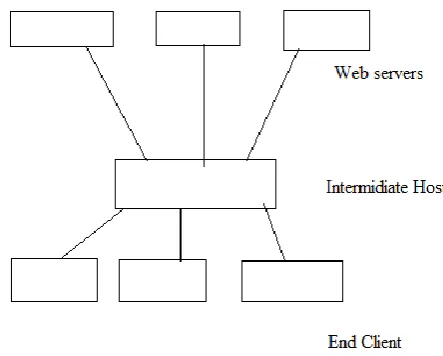
[image:1.595.327.549.428.606.2]With the explosive growth of data available on the World Wide Web, detection and investigation of useful information from the World Wide Web becomes a practical requirement. Web mining is the application of data mining technologies to massive Web data repositories.
Fig 1 basic web access
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)169
Thus there is a need to design and implement a system by which we can get the information of a particular user’s web access pattern. And this knowledge is helpful for different research domain.
III. EXPERIMENTAL SETUP
To demonstrate our entire concept we prepare an
experimental environment. In this environment
participate one server node with a self-designed proxy server that maintains log for each and every request and their corresponding responses. These request is comes from the remain four clients that is directly connected to the server system to get the web access services. The designed or managed log file in such format where fewer efforts are required to call and mining them.
A. Literature review:
To mine the collected data to discover pattern from the web logs there are various tools and technique are available to get the formal and some special information. Most of them respond with some common parameters and results. Moreover it they are format dependent w3c or tomcat format.
For literature survey we study different latest and old web uses mining research papers and we found that the results are most the time is in common format.
If we go through the method by which data pattern is recognize most of the papers contains or favour Apriori algorithm, some papers are favour decision trees and some papers are used KNN algorithm. But most of the paper favour with Apriori algorithm. Thus we work with first Apriori algorithm then a frequently and well known best fit for nominal data set algorithm ID3. After that we change a bit on ID3 algorithm to get higher performance.
B. work involve
In this section we summarize the complete work that is belongs to achieve our target goal.
1.Implement a proxy server
2.Arrange the data in the form of request and response
3.Apply Apriori algorithm to extract data pattern and evaluate their performance parameters
4.Apply ID3 algorithm and evaluate their
performance parameters
5.Apply changes over ID3 algorithm and evaluate their performance.
6.Produce the results
C. Algorithms used
1. Apriori algorithm: Following the original definition by Agrawal et al. the problem of association rule mining
is defined as: Let be a set of
n binary attributes called items.
Let be a set of
transactions called the database. Each transaction in D has a unique transaction ID and contains a subset of the items in I. A rule is defined as an implication of the form
where and .
The sets of items (for short item sets) X and Y are called antecedent (left-hand-side or LHS) and consequent (right-hand-side or RHS) of the rule respectively.
To illustrate the concepts, we use a small example from the supermarket domain. The set of items is I = {milk, bread, butter, beer} and a small database containing the items (1 codes presence and 0 absence of an item in a transaction) is shown in the table to the right. An
example rule for the supermarket could be
meaning that if butter and bread is bought, customers also buy milk. Note: this example is extremely small. In practical applications, a rule needs a support of several hundred transactions before it can be considered statistically significant, and datasets often contain thousands or millions of transactions.
2. ID3: The algorithm is as follows:
ID3 (Examples, Target_Attribute, Attributes) Create a root node for the tree
If all examples are positive, Return the single-node tree Root, with label = +.
If all examples are negative, Return the single-node tree Root, with label = -.
If number of predicting attributes is empty, then Return the single node tree Root, with label = most common value of the target attribute in the examples.
Otherwise Begin
o A = The Attribute that best classifies examples. o Decision Tree attribute for Root = A.
o For each possible value, vi, of A,
Add a new tree branch below
Root, corresponding to the test A = vi.
Let Examples(vi) be the subset of examples that have the value vi for A
If Examples(vi) is empty
Then below this new
branch add a leaf node with label = most common target value in the examples
Else below this new branch
add the subtree ID3 (Examples(vi),
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)170
End
Return Root
3. Changes over ID3
There are not much changes are included with the mounting of tree nodes in tree that is as it is that defined in previous section.
We make changes over the computation of entropy and information gain in both places all the calculations are derived using log with base 2 and in this part of calculation we replace 2 with base of 10.
IV. IMPLEMENTATION
Implementation of the complete system is based on visual studio 2008 with framework version 3.5. That is an IDE that provide programmers friendly environment to debug, develop and deploy web or desktop application. Moreover it that IDE contains a reach collection of classes and library to make development faster and easy.
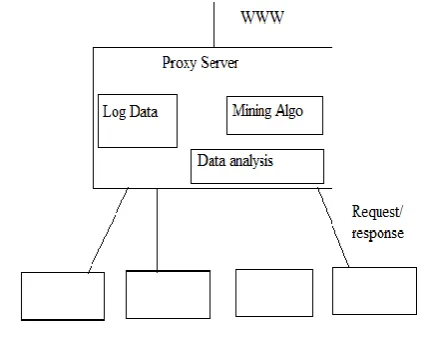
[image:3.595.310.570.147.247.2] [image:3.595.57.268.375.544.2]A. system architecture
Fig 2 shows the basic system design
Fig 2 shows the basic system design that contains some end clients and they are able to send request to the different web servers and get response according to their request. All these request and response is managed using a data base that is designed using MS SQL Server After saving all the request and responses over data base, there available a provision to select data mining algorithm to discover the pattern over data.
And in last phase we conclude with the discovery of data patterns with data and performance analysis of the system.
B. Input data format
Client IP Server IP Time Method URL Por
t
192.168.1 .6
202.185. 122.151
11/23/20 11 4:00:01 PM
Get Index
.
80
The designed table in the MS SLQ server is looking like the above table that contains client and server IP address, time slot, method, port and URL.
V. RESULTS
To collect experimental performance we keep first five records of our performance calculations.
A. Accuracy: here accuracy is achieved using n cross validation process.
Data set
size
Apriori ID3 Modified
ID3
147 73 72 78
562 71 76 72
829 78 73 81
1425 75 78 83
2831 81 79 81
Above given graph and chart shows the accuracy of all three pattern mining algorithms and we found that modified algorithm perform much better results than traditionally used algorithms.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)171
Data set
size
Apriori ID3 Modified
ID3
147 32867 33811 34282
562 34279 33627 33251
829 33155 33982 34821
1425 38291 34828 35288
2831 38291 35726 35754
The above given chart and diagram of the results show the comparative results of the memory used. And our modified algorithm is performing here with average results.
C. Mining Time: Mining time is defined as the time to process the data and prepare the data model for navigation all results provided below is in milliseconds
Data set
size
Apriori ID3 Modified
ID3
147 132 62 61
562 247 81 87
829 291 142 128
1425 402 167 226
2831 488 253 218
0 100 200 300 400 500 600
147 562 829 1425 2831
Apriori ID3 modified ID3
As above table and graph shows the mining our proposed algorithm is performed much better than other two algorithms that are previously used.
VI.CONCLUSIONS
As we assumed in start of this paper and after implementation of proposed algorithm we found the following facts.
1.We are able to collect all the transection driven by any end client system.
2.We use three text mining algorithm to test for classifying them and performance are calculated 3.We implement successfully the changes over ID3
and able to calculate their performance parameters
4.The modified ID3 algorithms’ performance is
considerably acceptable for data analysis and pattern discovery.
As we can say our main goals are achieved to implement the web access pattern discovery using proxy concept. In near future we with same domain and provide the high effective and efficient algorithm for web uses mining.
REFERENCES
[1 ] R. Agrawal and R. Srikant. Fast algorithms for mining association
rules. In Proc. 1994 Int. Conf. Very Large Data Bases, pages 487{499, Santiago, Chile, September 1994.
[2 ] R. Agrawal and R. Srikant. Mining sequential patterns. In Proc. 1995 Int. Conf. Data Engineering, pages 3{14, Taipei, Taiwan, March 1995.
[3 ] C. Bettini, X. Sean Wang, and S. Jajodia. Mining temporal
relationships with multiple granularities in time sequences. Data Engineering Bulletin, 21:32{38, 1998.
[4 ] R. Cooley, B. Mobasher, and J. Srivastava. Data preparation for mining World Wide Web browsing patterns. In Journal of Knowledge & Information Systems, Vol.1, No.1, 1999.
[5 ] J. Graham-Cumming. Hits and misses: A year watching the Web.
In Proc. 6th Int'l World Wide Web Conf., Santa Clara, California, April 1997.
[6 ] J. Han, G. Dong, and Y. Yin. E_cient mining of partial periodic patterns in time series database. In Proc. 1999 Int. Conf. Data Engineering (ICDE'99), pages 106{115, Sydney, Australia, April 1999.
[7 ] H. Lu, J. Han, and L. Feng. Stock movement and n-dimensional
inter-transaction association rules. In Proc. 1998 SIGMOD Workshop on Research Issues on Data Mining and Knowledge Discovery (DMKD'98), pages 12:1{12:7, Seattle, Washington, June 1998.
[8 ] H. Mannila, H Toivonen, and A. I. Verkamo. Discovery of
frequent episodes in event sequences. Data Mining and Knowledge Discovery, 1:259{289, 1997.
[9 ] B. Ozden, S. Ramaswamy, and A. Silberschatz. Cyclic association
rules. In Proc. 1998 Int. Conf. Data Engineering (ICDE'98), pages 412{421, Orlando, FL, Feb. 1998.
[10 ]M. Perkowitz and O. Etzioni. Adaptive sites: Automatically
learning from user access patterns. In Proc. 6th Int'l World Wide Web Conf., Santa Clara, California, April 1997.
[11 ]M. Spiliopoulou and L. Faulstich. WUM: A tool for Web
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)172
[12 ]R. Srikant and R. Agrawal. Mining quantitative association rules in large relational tables. In Proc. 1996 ACM-SIGMOD Int. Conf. Management of Data, pages 1{12, Montreal, Canada, June 1996. [13 ]T. Sullivan. Reading reader reaction: A proposal for inferential
analysis of Web server log _les. In Proc. 3rd Conf. Human Factors & The Web, Denver, Colorado, June 1997.
[14 ]L. Tauscher and S. Greeberg. How people revisit Web pages:
Empirical _ndings and implications for the design of history systems. In Int'l Journal of Human Computer Studies, Special Issue on World Wide Web Usability, 47:97-138, 1997.