2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
A Reversible Data Hiding Scheme Based
on Prediction Difference
Ze-rui SUN
1,a*, Guo-en XIA
1,2, Guo-xiang LI
1, Yi-lin JIANG
11Office of Academic Affairs
Guangxi University of Finance & Economics, Nanning, China
2Department of Business Administration
Guangxi University of Finance & Economics, Nanning, China
*Corresponding author
Keywords: Data hiding, Reversible, Prediction difference.
Abstract. In this paper, we propose a new data hiding scheme based on prediction difference. The difference between prediction value and the real value in the corresponding position of the cover image is calculated, and the secret bits are embedded into the difference. That is changing or staying the original pixel of corresponding position in the original image to embed secret bits. Experimental results indicated that our scheme provides higher PSNR value with the same payload.
Introduction
Data hiding [1] is a technique which can achieve secret communication through cover multimedia with the secret information, and transfer the covered multimedia to the receiver without detection. Data hiding can be classified to two categories according to the cover image can be restore or not, reversible data hiding and irreversible data hiding. Reversible data hiding, also named as lossless data hiding, is an important way to hide the secret message and protect multimedia productions. The cover image can be completely recovered after embedded messages are completely extracted with the reversible data hiding. Therefore, it has been commonly used to the military, medical, and art productions etc. Recent years, researchers have proposed multiple reversible data hiding algorithms. Almost all of them are based on lossless compression [2, 3, 4], difference expansion (DE) [5, 6, 7], histogram shifting [8, 9, 10, 11], and interpolation images [12, 13].
The payload of the histogram-shifting based reversible data hiding scheme is limited for the peak size is small. Many researchers extended Ni’s method [9, 10, 11] and obtained the higher payload and the better visual effect. As the natural images have local similarity, the pixel grayscale values in a local area are often highly correlated and spatial redundancy. Therefore, the prediction value of one pixel is close to the real value, that is the difference between the prediction value and the real value is close to zero. The peak of the difference value histogram is expected to be very close to zero, thus, there are lots of candidates for embedding data.
By the observations above, we would like to integrate the prediction errors into the histogram-based scheme. The paper is organized as follows. In Section II we discuss how to generate the difference errors. In Section III we describe the proposed hiding and extracting algorithm. Simulation results are demonstrated in Section IV. Finally, we point out the contributions of our algorithm and conclude this paper in Section V.
The Generation of the Prediction Errors
[image:2.612.231.401.387.442.2]The ideas of difference error are always used in the coding process of digital image. The data hiding algorithm take the advantage of difference error. The errors between the prediction value and the real value are calculated, and then modified the errors with histogram shifting algorithm. The common errors are generated between two real pixels or between the prediction value and the real value. In order to obtain the higher payload, we would like to get an error value which has high frequency. As the pixels nearby have the closet values, so we can predict a pixel’s value by the value of pixels nearby.
Figure 1. Five consecutive pixels and values in one direction.
As shown in Fig. 1, it denotes 5 consecutive pixels and their values in one direction of the image, and the direction could be the vertical direction, horizontal direction and diagonal directions. The pixels of P2 and P4 are used to calculate the prediction errors
which have no background colour. The prediction values of P2 and P4 are generated by
the value of P1, P3 and P5. In order to get more same error, the prediction value of P2 is
choose the mode of y1, y3, 1+ 3
2
y y
( ) , and the prediction value of P4 are choose the
mode of y3, y5, y3+y5 2
( ) .
Suppose the cover image is C with the size of W*H. The prediction image of C is C'
which has the same size. The pixels are same in C and C' when the row and column
coordinates are odd number at the same time, the rest are the prediction pixels. The prediction error matrix is calculated by the Eq.1.
D(i,j) = C(i,j) - C'(i,j) (1)
D(i,j) = 0, i = 1,3,5…, j = 1,3,5 … (2) We can get an error matrix D by Eq. 1, which the value is 0 when the row and column
255, and the size of D is same with the cover image C. An error histogram H is obtained
by counting the errors in D, the secret bits are hiden in the errors.
The Proposed Hiding Algorithm
Using the histogram based hiding algorithm [8] to hide secret bits into the error histogram we get above. Find the most K common of errors in the error series, put the
secret bits into the errors to achieve embeding. Scanning the image from the top-left, choosing the second and the forth pixel of five consecutive pixels in one direction, and embeding the secret bits into the pixels. The details of hiding procedure is composed of 5 steps as follows.
Step1: Calculate the error matrix D and find the K common errors of the matrix,
suppose the mean value of K errors is M.
Step2: Scan the image from the top-left toward to the three directions with the step length of five, the second and the forth pixel are embeding pixels with the position (i, j).
Step3: Check the error matrix D(i, j), if the value of D(i, j) is not in the range of K
errors, the D(i, j) is changed by Eq. 3 to make space for embeding. That is shift the
histogram H. The new value of error can be calculated by the Eq.3.
( )
( )
( )
( )
( )
+1 +1
, 2 , 2
' , =
, - 2 , - 2
K K
D i j D i j M
D i j
K K
D i j D i j M
+ + ( ) > ( ) < (3)
If the value of D(i, j) is in the range of K errors, that is the value of D(i, j) is
[M-K2
,M +( K+1)2], the pixel of D(i, j) is changed to hide the secret by Eq.3. According to value of D(i, j) and M to embed the secret bit s, the new value of error can
be calculated by the Eq.4.
( )
( )
( )
( )
( )
( )
, 0 +1' , = , + 2 , & & 1
, - 2 , & & 1
D i j s
K
D i j D i j D i j M s
K
D i j D i j M s
= = = ( ) ≥ < (4)
The value of D(i, j)is unchanged if the secret value is 0. If the secret value is 1, we
should compare the value of D(i, j) and the mean value M. If M is not bigger than D(i, j),
the pixel of D(i, j) plus ( K+1)2 to embed 1. If M is bigger than D(i, j), the pixel of
D(i, j) minus K2 to embed 1.
Step4: Repeat step3 until all the embeding position of error matrix are embedded with the secret bits.
Step5: Add the new error matrix D' to the prediction image C' to get the stego-image Ste.
Ste(i,j) = C' (i, j) + D'(i, j) (5)
If the value of P1, P3 and P5 is close to 255 or to 0, the value of P2 and P4 in the
Step1: Calculate the prediction C' with same method form the stego-image and get
the error matrix D', and get the value of K and M from the sender.
Step2: Scan the matrix D' from the top-left, get secret bit s in the embeding position (i, j) with the Eq. 6. If the value of D'(i, j) is between (M-( K+1)2,M+K2], we can
extract 0 from the D'(i, j), if the value of D'(i, j) is between (M+K2, M K+ +1) or
between (M K- , M-( K+1)2], we can extract 1 from the D'(i, j). The error value of
D' (i, j) is changed by Eq. 7.
( )
( )
( )
+10 - 2 ' , + 2
= 1 + +1 ' , + 2
+1
1 - ' , - 2
K K
M D i j M
K
s M K D i j M
K M K D i j M
( ) < ≤
> >
( )
< ≤
(6)
( )
( )
( )
( )
( )
( )
' , 0
+1
, = ' , - 2 ' , & & 1
' , + 2 ' , & & 1
D i j s
K
D i j D i j D i j M s
K
D i j D i j M s
=
=
=
( ) ≥
<
(7)
Similarity, if the secret value is 0, the value of D'(i, j) is unchanged. If the secret
value is 1, we should compare the value of D'(i, j) and the mean value M. If M is not
bigger than D'(i, j), the pixel of D'(i, j) minus ( K+1)2 to recover. If M is bigger than
D'(i, j), the pixel of D'(i, j) plus K2 to recover.
Step3: Repeat step2 until all the secret bits are extracted.
Step4: Add the corrected error matrix D to the prediction image to recover the image C.
C(i, j) = C'(i, j) + D(i, j) (8)
Experimental Results and Analysis
In order to evaluate the advantages and efficiency of the proposed algorithm, we did lots of experiment with Tseng et al.’s scheme [10] on the common images. Four common test images sized 512×512 as shown in Fig. 2. The measure standard are the hiding capacity and the PSNR values. The payload and the PSNR values of different images are listed in Table 1 when K = 1, from which we can learn that the PSNR of our
algorithm is better than Tseng et al.’s scheme with the same payload. We can increase the embed payload by adding the value of K or appling the algorithm many times. The
Table 1. Comparisons between the proposed method and Tseng et al.’s scheme.
Image Payload The proposed scheme Tseng et al.’s scheme (bpp) PSNR (dB) Payload (bpp) PSNR (dB)
Lena 0.177 48.69 0.176 43.84
Barbara 0.160 47.87 0.132 43.32
F16 0.191 50.07 0.160 44.73
(a) Lena (b) Baboon (c) Barbara (d) F16
[image:5.612.158.471.84.278.2]Figure 2. Four test images used in the experiments.
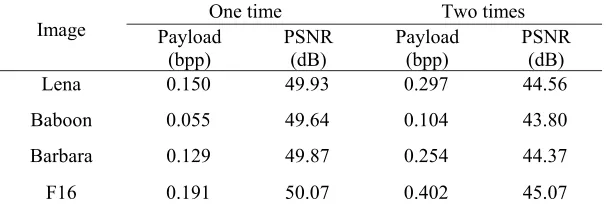
Table 2. The payload and PSNR when embed 1 and 2 times.
Image Payload One time Two times
(bpp)
PSNR (dB)
Payload (bpp)
PSNR (dB)
Lena 0.150 49.93 0.297 44.56
Baboon 0.055 49.64 0.104 43.80
Barbara 0.129 49.87 0.254 44.37
F16 0.191 50.07 0.402 45.07
Conclusions
In this paper, we proposed a new reversible data hiding method based on prediction error and histogram shift. The error is calculated by the prediction value and the real value of one pixel. As the prediction effect is good, the real value and prediction value is very close, more 0 are obtained and more pixels can be used to hide secret bits. The experimental results indicated that the stego-images generated by our data hiding scheme have a better visual quality, so it can be used in the real application such as the military or medical images. Future work include reversible data hiding with new prediction method or in the encrypted images, and so on.
Acknowledgment
[image:5.612.156.459.326.434.2]References
[1] Bender, W., Gruhl, D., Morimoto N., et al. Techniques for data hiding [J]. IBM systems journal, 1996, 35(3.4): 313-336.
[2] Fridrich, J., Golja,n M., Du R. Lossless data embedding: new paradigm in digital watermarking [J]. EURASIP Journal on Applied Signal Processing, 2002, 2002(1): 185-196.
[3] Fridrich, J., Goljan, M., Du, R. Lossless data embedding for all image formats [C]//Electronic Imaging 2002. International Society for Optics and Photonics, 2002: 572-583.
[4] Celik, M. U., Sharma, G, Tekalp A. M., et al. Lossless generalized-LSB data embedding [J]. IEEE transactions on image processing, 2005, 14(2): 253-266.
[5] Tian, J. Reversible data embedding using a difference expansion [J]. IEEE transactions on circuits and systems for video technology, 2003, 13(8): 890-896. [6] Tseng, H. W., Chang, C. C. An extended difference expansion algorithm for reversible watermarking [J]. Image and Vision Computing, 2008, 26(8): 1148-1153. [7] Lee, C. C., Wu, H. C., Tsai, C. S., et al. Adaptive lossless steganographic scheme with centralized difference expansion [J]. Pattern Recognition, 2008, 41(6): 2097-2106.
[8] Ni, Z., Shi, Y. Q., Ansari, N., et al. Reversible data hiding [J]. IEEE Transactions on circuits and systems for video technology, 2006, 16(3): 354-362.
[9] Lee, C. F., Chen, H. L., Tso, H. K. Embedding capacity raising in reversible data hiding based on prediction of difference expansion [J]. Journal of Systems and Software, 2010, 83(10): 1864-1872.
[10] Tseng, H. W., Hsieh, C. P. Prediction-based reversible data hiding [J]. Information Sciences, 2009, 179(14): 2460-2469.
[11] Dragoi, I. C., Coltuc, D. Local-prediction-based difference expansion reversible watermarking [J]. IEEE Transactions on image processing, 2014, 23(4): 1779-1790. [12] Jung, K. H., Yoo, K. Y. Data hiding method using image interpolation [J]. Computer Standards & Interfaces, 2009, 31(2): 465-470.