2017 2nd International Conference on Computer Science and Technology (CST 2017)
ISBN: 978-1-60595-461-5
Improved Privacy Preserving Algorithm Based
on Association Rule Mining
Qing YAN
a*and Yi LIU
Faculty of Computer, Guangdong University of Technology, Guangzhou, China
*Corresponding author
Keywords: Association rule, Privacy preserving, Data mining, Matrix block, Set operations
Abstract. Multi-parameters randomized perturbation was a privacy preserving algorithm based on association rule mining, and had high data mining accuracy. However, the exponential complexity of reconstructing frequent itemset support led to the decrease of algorithm efficiency. Aiming at the insufficient, the method of matrix block and set operations was used to improve the algorithm, and when calculating the inverse matrix of the transformation matrix, calculating all the elements of the inverse matrix changed to the first line elements. In the case of maintaining accuracy, the improved algorithm simplifies the process of calculating synthetic itemsets, eliminates the exponential complexity of reconstructing itemset support. Experimental results and analysis show that the improved algorithm has better execution efficiency.
Introduction
In recent years, with the rapid development of information technology, all walks of life have accumulated large amount of data. How to dig out the deeper information from these data becomes a top priority. As an effective data analysis technology, data mining can discover the hidden knowledge and rules in the massive data. However, in the process of using general mining method, it is easy to leak privacy data. Therefore, protecting privacy data is an urgent problem to solve in the field of data mining[1].
Privacy preserving data mining is mainly divided into two categories: data disturbance and inquiry limitation. The data disturbance is disturbance the original data through transformation, discrimination and adding noise, such as MASK algorithm[2], anonymous algorithm[3] of attribute weights and neighborhood hiding algorithm[4]; The inquiry limitation uses hiding, sampling and partition of original data, then through probability statistical or distributed computational to get the required patterns and rules, such secure multi-party computation[5] and homomorphic encryption[6]. However, these two kinds of strategies both have inherent defect. The data disturbance strategy, all disturbed data are directly related to the original data; and the inquiry limitation strategy, all provided data are the real original data.
single use data disturbance and inquiry limitation strategy, but the computational complexity of reconstructing itemset support is exponential.
This paper focuses on the exponential time complexity of the MRD algorithm, using the method of matrix block and set operations, and when calculating the inverse matrix of transformation matrix, only need to find out the first line elements of inverse matrix. It simplifies the process of calculating synthetic itemsets, and eliminates the exponential complexity of reconstructing itemset support.
MRD Algorithm
Random Perturbation Process
For the transaction sets of 0-1 sequence, given three randomized parameters p1, p2 and
p3, which are satisfied with 0≤p1, p2, p3≤1 and p1+p2+p3=1. For any item of transaction
sets t∈{0, 1}, suppose f1=t, f2=1-t, f3=0, define a random function f(t), the function
value is fi by the probability pi , i=1, 2, 3. Let the total number of transaction sets is k,
by random perturbation, we can transform the original transaction T =(t1, ,t2 ,tk) to
1, ,2 , k)
(
D= d d d by D=F(T), where di= f(ti), di is equal to ti by the probability p1, equal to 1-ti by the probability p2, and equal to 0 by the probability p3.
Itemset Support Reconstruction
Suppose the original dataset is T, the distorteddataset is D. For any item i, c0T and c1T is
the number of '0' and '1' in the ith column of T respectively,
0 D
c and c1D is the number of
'0' and '1' in the ith column of D respectively. By probability formula, we can obtain:
1 1 2 0 1
2 3 1 1 3 0 0
( ) ( )
T T D
T T D
pc p c c
p p c p p c c
+ =
+ + + =
,MC C
T D
= ,CT=Μ−1CD, 1 2 2 3 1 3
M p p
p p p p
=
+ +
,
1 0 C
T T
T c c
=
,
1 0 C
D D
D c c
= The real support of 1-itemset is c1T= (c1D−p c2( 0D+c1D)) /p1−p2 (where
1 2 p ≠ p ).
According to the support reconstruction of 1-itemset, we can extend to k-itemset, at
this time, C 0 1 2 1k '
T T T T
c c c −
= , C 0 1 2 1k '
D D D D
c c c −
= , and M is a matrix of
order 2k, assume 1 ,
( )
M− = ai j , the support of k-itemset express as formula (1):
0 1 0,0
2 1k 0,2 1k 0,2k 2 2 1k
T D D D
c − =a −c +a − c + + a c − (1)
Through formula (1), we can estimate the k-itemset support, and get frequent
itemsets. But the time complexity is exponential, which is mainly consumed in the computation of M, M−1and the number of synthetic dataset in CD.
Improved Algorithm
Improvement Base on Matrix Block
In the MRD algorithm, we need to calculateMandM−1, the time complexity of M−1 is O(n3). Through the study of M−1, the method of matrix block is used to find that M−1
satisfies recursive relation. Therefore, we can directly calculate M−1 instead of M, the
Due toCD =MCT, the 1-itemset is
2
CD =M CT, and the transformation matrix is
expressed as 1 2
2
2 3 1 3
M p p
p p p p
= + +
. Similarly, the 2-itemset is C M C4
D = T, using the
idea of matrix block to divide M4, the transformation matrix is expressed as
2 2
1 1 2 1 2 2
1 2 2 2
1 2 3 1 2 3 2 2 3 2 1 3
4
2 3 2 1 3 2
1 2 3 2 2 3 1 1 3 2 1 3
2 2
2 3 2 3 1 3 2 3 1 3 1 3
( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( )( ) ( )( ) ( ) M M M M M
p p p p p p
p p
p p p p p p p p p p p p
p p p p
p p p p p p p p p p p p
p p p p p p p p p p p p
+ + + + = + + + + = + + + + + + + +
Similarly, 1 4 2 4
8
2 3 4 1 3 4
( ) ( )
M M
M
M M
p p
p p p p
= + +
.So,
1 /2 2 n/2 1 /2 2 /2 /2
2 3 /2 1 3 /2 2 3 /2 1 3 /2 /2
, 2 , 1,2,
( ) ( ) ( ) ( )
M M E E M
M
M M E E M
n n n n k
n
n n n n n
p p p p
n k p p p p p p p p
= = = =
+ + + +
Thus,
-1 -1 -1 -1
/2 1 /2 2 /2 1 /2 2 /2
1 /2
-1
/2 ( 2 3) /2 ( 1 3) /2 /2 ( 2 3) /2 ( 1 3) /2
M M M M M M
M
M M M M M M
n n n n n n
n
n n n n n n
p p p p
p p p p p p p p
− = =
+ + + +
Using Gaussian elimination method, we can obtain:
2 2
-1 /2 /2 1 2 1 2 1 /2 2 /2
2 3 /2 1 3 /2 1 1 /2 /2 1 2 1 2 1
( ) ( ) 1
E E M M M M E E n n n n n n n n p p
p p p p
p p
p p p p p p
p p p p
− − − − = + + − − − So, -1 -1
2 2 2 2
/2 /2 /2 /2
-1
1 2 1 2 1 2 1 2 1 /2
-1
-1 -1
1 1 1 1
/2
/2 /2 /2 /2
1 2 1 2 1 2 1 2
1 1
=
1 1
E E M M
M M
M E E M M
n n n n
n n
n
n n n n
p p p p
p p p p p p p p
p p p p
p p p p p p p p − − − − − − − − − = − − − − − − (2)
According to formula (2), M 1 n
− satisfies the recursive relation. When
p1, p2 and p3
are determined, 1
2
M− is uniquely determined. So, M 1 n
− can be calculated by 1 2
M−
. According to formula (2), the time complexity can be calculated as follows:
2 1 2 1
1
( ) ( 2) ( ) ( 4) ( 2) ( ) (2) (4) ( 2) ( ) (2) 2 (2) 2 (2) 2 (2) (2) (2 2 2 ) (2)
2(1 2 )
(2) (2) (2) (2 2) (2) (2) ( 2) (2), 2 , 1, 2, 1 2
n n
n
n n
T k T k S k T k S k S k T S S k S k
T S S S T S
T S T S T k S k n
− − − = + = + + = = + + + + = + + + + = + + + + − = + = + − = + − = = − (2)
T is the required time to calculate M2−1; (2)S is the required time to generate 1
2
M− ; since the time complexity of (2)T
and (2)S are O(1), it is a constant, so
= ( ) ( )
Improvement of Finding out the First Line Elements of Inverse Matrix
For CT =Μ−1CD, '
0 1 2 1
C k
T T T T
c c c −
= , C 0 1 2 1k '
D cD cD cD
−
= . Require to
calculate itemset support, only need to calculate 2 1k
T
c − . For 2 1k
T
c − , only let the first line
elements of M 1 n
− multiply with CD. So, just find out the first line elements of M 1 n
− .
According to M 1 n
− , the first line elements is a combination of
2 1 2
(1−p ) / (p − p ) and
2/ 1 2
p p p
− − . Replace (1− p2) / (p1−p2)with 0, replace −p2/p1−p2 with 1.There is:
The first line elements of 1 2
M− is (0, 1), the first line elements of 1 4
M− is (0*(0,1),1*
(0,1)), that is (00, 01, 10, 11), the first line elements of 1 8
M− is (0*(00, 01, 10, 11),
1*(00, 01, 10, 11)), that is (000, 001, 010, 011, 100, 101, 110, 111).
By this analogy, we can conclude: the k-itemset of the inverse matrix of the first
line elements corresponding to the k binary number from 0 to 2k-1.That is
2 2
1 2 1 2
1
[0][ ] ( p )k j( p )j
m i
p p p p
−
− −
=
− − (3)
Where j is the number of 1 of decimal number i corresponding to binary number.
According to formula (3), the k-itemset support is expressed as
[
'0 1
2 1k [0][0] [0][2 1] * 2k
T k D D D
c − = m m − c c c (4)
Differently with formula (1), the left side of formula (4) only use 2 1k
T
c − , not all the 2k
elements of CT, the right side only use the first line 2k elements of the inverse matrix,
not all the 22k elements, so that the efficiency is further improved. Improvement Based on Set Operations
The above algorithm improves calculating M−1, but as CT =Μ−1CD, also need to
calculate CD, that is the counting process of synthetic dataset. However, when
estimating the real support of k-itemset for the synthetic dataset, it is necessary to
consider 2n case that may occur after the original item is disturbed. Aiming at this
problem, the principle of set operations[8] can used to simplify calculation. According
to the feature of Boolean dataset, when calculating the 2-itemset {A, B}, we can find the
value of A and B is '0' or '1', only query the number of A and B values are '1', that is, the
number of '11', the other combinations of '10', '01', '00' can be expressed as:
| |=| | | |
10 : AB A − AB 01:| AB |=| | | B − AB | 00 :| AB |=U−| | | |+| B − A AB |
According to the principle of set operations reasoning:
1 2 1 2 n 1 2 1 2 n 1 2 n 1 2 m 1 2 n
|A AA B Bm B | |=A A A B Bm B | |=B BB | | (− A A A B B) B | Finally we can get:
1)
1 2 1 2 n 1 2 n 1 2 1 2
1 1
1
1 2 1 2 1 2 1
| | | | | | | |
| | ( | |
m m
m i n i j n
i i j i
m
m
i j k n m n
i j i k j
A A A B B B B B B A B B B A A B B B
A A A B B B A A A B B B = = >
− = > >
= − − +
− −
(5)
value of frequent itemsets is '1'. In the mining process, a dynamic hash list is created to store the counts of the itemsets which value of each element is '1', and provides the required intermediate results for subsequent mining. This can obviously reduce the overhead of counting the various combination of distorted dataset.
Improved Algorithm Description
In the improved algorithm, defining function sup(A) to calculate support number of
itemsets A in the distorted dataset, function cal(k) is used to calculate the combinations
number of the k-itemset, the hash table hashtab is used to store the number of frequent
itemsets which is '1'. The pseudo-code of the algorithm is as follows:
Input: distorted dataset D, perturbation parameters p1, p2 and p3, minimum support s.
Output: the frequent itemsets L in the original dataset T
scan D, for each i∈I, count i.count; // count each item i in item I of D
1 {{ }| ,( .count / 2) / ( 1 2) }
L = i i∈I i N− p p −p ≥s ;
1
for(k=2;Lk− ≠
φ
;k+ +){1
apriori_gen( );
k k
C = L − // generate Ckfrom frequent k-1 itemset
for( 0; 2 ;k ){
i= i< i+ + // calculate the first line element of inverse matrix
2 2
1 2 1 2
1
[0][ ] ( p )k j( p ) ;j
m i
p p p p
−
− −
=
− −
}
for each c∈Ck{ // calculate the real support of candidate itemsets
scan D, if (c=1) count c.count; // get the number of items which is '1' in c
cal(k); // use set operations to calculate the count of each combinations 2 1
1 2 0
re _ sup( ) [0][ ]*sup( );
k
k
j
c M j c
− −
=
=
// calculate the real support of itemsets( )
(
re _ sup)
if c /N≥s {
hashtab.add(c.count); // store the intermediate result into hash table
}
k {{ }| k, re _ sup( ) / };
L = c c∈C c N ≥s
} }
return L=kLk;
Experiments and Results Analysis
The experimental hardware platform is AMD Athlon (TM) P360 Dual-Core Processor 2.3GHz processor and 4GB memory, the operating system is Windows 7, the development of software is Microsoft Visual Studio 2010. The test dataset are all produced by the IBM Almaden generator. Its parameters are T10, I4, D100k, N100, the average length of data items is 10, the average length of frequent itemsets is 4, the total number of datasets is 1 000 000, the total number of items is 100, respectively.
Association rule mining error can be measured to two criteria: frequent itemset error and support error. Suppose that F is the frequent itemsets of T which is the original
dataset, and '
F is the frequent sets of D which is the distorted dataset, then the frequent
itemset error is | ' | / | |
support is sf , and the distorted support is s'f , then the support error of F is '
| | / | |
f f f f
SE = s −s s , and the total support error is f/ | |
f
SE=
SE F .Since the literature [10] adopts the method of divide and conquer strategy and set operations, it is comparable to this paper. So, literature [10] is added to compare.
The four groups of experiments are carried out on MRD algorithm, the algorithm of literature [10] and this paper algorithm, select parameters p1=0.6, p2=0.2, p3=0.2, the
minimum support is 3%. The experiment results are as follows.
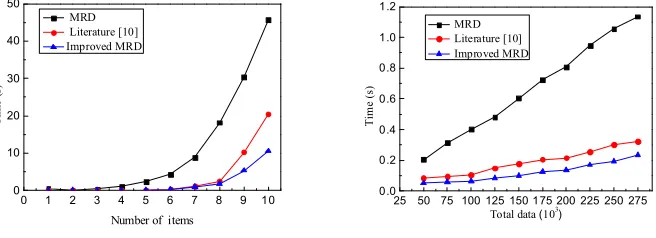
Fig. 1 shows a comparison of running time with the increase of n-itemset. The
experimental results show that, with the increase of n-itemset, the running time is
gradually increased. Compared with MRD algorithm, the improved algorithm is improved large, the bigger the n, the bigger the upgrade. Relative to the algorithm of
literature [10], when n≥8, the advantage is more obvious. So, the improved algorithm has a greater improvement in time performance than the other two algorithms.
Fig. 2 shows the time comparison of calculating 5-itemset. The experimental results show that with the increase of total dataset, the consumed time is gradually increased. Compared with MRD algorithm, the improved algorithm is improved large with linear increase. Relative to the algorithm of literature [10], there is also a larger upgrade.
0 1 2 3 4 5 6 7 8 9 10
0 10 20 30 40 50
Tim
e
(s
)
Number of items MRD
Literature [10] Improved MRD
25 50 75 100 125 150 175 200 225 250 275 0.0
0.2 0.4 0.6 0.8 1.0 1.2
Tim
e
(s
)
Total data (103
)
MRD Literature [10]
[image:6.612.141.469.324.443.2]Improved MRD
Figure 1. Runtime comparison. Figure 2. Time comparison.
Fig. 3 shows the variation of itemset error with the change of parameters p, where p1=p, p2=p3=(1-p1)/2. The experimental results show that, with the increase of
parameters p, the itemset error decreases and tends to be stable, the error of the three
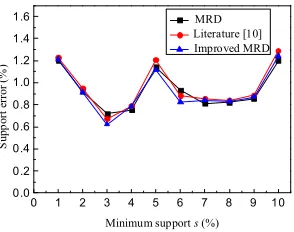
algorithms is basically the same, and the privacy destruction is relatively small. Fig. 4 shows the variation of support error with the change of minimum support s.
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0
1 2 3 4 5 6 7 8 9
It
em
se
t
err
or
(%
)
Random parameter p
MRD Literature [10] Improved MRD
0 1 2 3 4 5 6 7 8 9 10
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6
S
upp
or
t e
rr
or
(
%
)
Minimum support s (%) MRD Literature [10]
[image:7.612.320.467.83.199.2]Improved MRD
Figure 3. Itemset error comparison. Figure 4. Support error comparison.
Conclusions
Aiming at the low efficiency of MRD algorithm, this paper proposes matrix block and set operations to improve. When calculating CT =Μ−1CD, the improved algorithm
reduces the time complexity of M−1 by matrix block recursive calculating M−1. And
further improvement, only need to find out the first line elements of M−1 instead of all
the elements. When counting the support of the distorted dataset, using set operations to calculate the unknown items with the known items. Finally, the experiment shows the accuracy and high efficiency of the improved algorithm.
In this paper, the improved algorithm is mainly concerned with the time efficiency, privacy protection and accuracy have not been further improved. In the future, we will further improve the privacy protection and accuracy of the algorithm.
Acknowledgement
This paper was supported by the National Science Foundation of China (No.61572144), the science and technology project of Guangdong Province in China (2014B090901053, No.2016B090918125).
References
[1] Saranya, K., Premalatha, K., Rajasekar, S. S. A survey on privacy preserving data mining[C]. International Conference on Electronics and Communication Systems. IEEE, 2015: 1740-1744.
[2] Rizvi, S. J., Haritsa, J. R. Maintaining data privacy in association rule mining[C]. In Proceedings of the 28th VLDB Conference, Hong Kong. 2002: 682-693.
[3] Yong Xu, Xiao-lin Qing, Yi-tao Yang, et al. A QI weight_aware approach to privacy preserving publishing data set [J]. Journal of Computer Research and Research and development (In Chinese), 2012, 49(5): 913-924.
[4] Wei-wei Ni, Yong Zhang, Mao-feng Huang, et al. Vector equivalent replacing based privacy-preserving perturbing method[J]. Journal of Software (In Chinese), 2012, 23(12): 3198-3208.
Security Ios, 2005, 13(4): 593-622.
[6] Liu-sheng Huang, Miao-miao Tian, He Huang. Preserving privacy in big data: A survey from the cryptographic perspective[J].Journal of Software (In Chinese), 2015, 26(4): 945-959.
[7] Agrawal, S., Krishnan, V., Haritsa, J. R. On Addressing Efficiency Concerns in Privacy-Preserving Mining[C]. Database Systems for Advances Applications, International Conference, DASFAA 2004, Jeju Island, Korea, March 17-19, 2004, Proceedings. 2004: 113-124.
[8] Hao-liang Lou, Yun-long Ma, Feng Zhang, et al. Data mining for privacy preserving association rules based on improved MASK algorithm[C]. International Conference on Computer Supported Cooperative Work in Design. IEEE, 2014: 265-270.
[9] Rui Wang, Jie Liu. Research of privacy preserving association rules mining algorithm[J]. Computer Engineering and Applications (In Chinese), 2009, 45(26): 126-130.