2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5
Image Annotation by Object Hypotheses-oriented Deep Neural Networks
Fang MA
1, Shao-he LV
1,*, Ke-xin ZHENG
1, Chi JIN
2, Fei CHEN
1, Ke YANG
1and Yong DOU
11National Laboratory for Parallel and Distributed Processing, National University of Defense
Technology, Deya Road, Kaifu District, Changsha City, Hunan Province, China
2University of South China, School of Computer Science and Technology
*Corresponding author
Keywords: Deep learning, Multi-label annotation, Object hypotheses.
Abstract. Image annotation generates a set of semantic labels that describe the contents of an input image. Recently deep learning techniques have achieved significant success in many areas of image processing. In this paper, we present a multi-label image annotation method that combines unsupervised object hypotheses generation and deep neural network. Given an image, object hypotheses are generated in an unsupervised manner. Then we extract the image features for each hypothesis with a deep neural network model. By combining the features of all hypotheses, we get the features of the entire image. Finally, we calculate for each label the probability of that the label is correlated with the given image. It can be trained in an end-to-end way using the standard backward propagation algorithm. Experimental results on multiple benchmark datasets show that our method is better than the state-of-the-art ones.
Introduction
Image annotation is a task of image processing that for a given image, one or more labels are automatically assigned to reflect the content of the image. Basically, after learning the correlation between the class label and the visual features, one can assign several labels to a given image according to the image features. As image acquisition and storage technology continues to evolve, image data grows rapidly. Retrieving these images is a major problem in the field of computer vision. In general, users tend to use text to find relevant images. This causes the automatic image annotation technology attracts the widespread attention of researchers. However, due to the Semantic Gap, automatic image labeling is a challenging task. Semantic Gap means it is difficult to establish the mapping between low-level visual features and high-level image semantics.
Due to the importance of image annotation, many researchers have tried various algorithms to analyze and solve annotation problems, and many image annotation algorithms have emerged. These image annotation algorithms can be divided into two classes based on whether using the ground-truth bounding box or not. H. Harzallah et al.[11] proposed INRIA. F. Perronnin[12] proposed Fisher kernel which combines the benefits of discriminative and generative approaches. A.S. Razavian et al. [13] proved the power of generic descriptors extracted from the convolutional neural networks. Wei Y et al.[9] proposed a flexible deep CNN infrastructure where an arbitrary number of object segment hypotheses are taken as the inputs. Y. LeCun et al proposed LeCun-ICML[17]. These methods do not need ground-truth bounding box. J. Donahue et al. [14] introduced a subcategory-aware object classification framework to boost category level object classification performance. Q. Chen et al.[15] investigated how to boost object classification and detection by taking the output from one task as the context of the other one. M. Oquab et al. proposed PRE-1000C[20]. S. Yan et al. proposed NUS-PSL[18]. These methods need the ground-truth bounding box. Some methods need other data like the ImageNet to pre-train the model.
features. Finally, we use machine learning algorithm to establish the association between the features and the labels.
The rest of this paper is organized as follows. The second section describes our proposed method in detail. The third section describes the results and the last part is the conclusion.
Method
Our proposed method has three main steps. First, we extract hypotheses of the input image. Second, we get the features of each hypothesis with deep network model. In this step, we use Spatial Pyramid Pooling[3] (SPP) to reduce the consumption of computing resources and improve the calculation speed. Third, we combine the features of hypotheses to get the features of the whole image and classify to get the labels of the input image. We use the backward propagation(BP) algorithm to train the model. The training is end-to-end. It's similar to the training strategy proposed by Gong Y et al. [4]
Hypotheses Extraction
[image:2.595.137.461.390.542.2]Global features of the image are only applicable to represent simple images. In our daily life, more images contain multiple objects. Global features cannot reflect the rich content of the images. Annotating images with global features is not satisfactory. So, we extract hypotheses of the input image and annotate the image by finding the relationship between labels and hypotheses' features. There are many ways to generate hypotheses. We use Selective Search[5][20][21] which combines the strength of both an exhaustive search and segmentation to generate possible object locations. The right part of Figure 1 shows partial results of Selective Search.
Figure 1. Partial results of Selective Search. The left part of Figure 1 is an image from voc2007[8] and the right part are partial results of Selective Search. Selective Search generates more than 100 hypotheses for each image and we use only
50 hypotheses in our experiment to save calculation source.
Features Extraction
Several deep neural network model can be used to extract features. We use GoogLeNet[2] in our experiment. GoogLeNet increases the depth of the network by improving the structure of the neural network without increasing the cost of computing resources. So it can efficiently extract image features. Due to the large number of parameters, we used the pre-trained model given by the author.
As there are many hypotheses for each image, the computational resource consumption can be unbearable. We use SPP to speed up. Conventional Deep CNN requires that the size of input image be fixed. Adding a Spatial Pyramid Pooling Layer allows the input to be imaged of any size and the output is fixed. After the Spatial Pyramid Pooling Layer, we get a N × f matrix. N is the number of hypotheses and f is the length of the hypotheses' features.
Cj = max(O1j, O2j, … , ONj ). (1)
𝐶𝑗 indicates the feature value that the input image contains class j and N indicates the number of hypotheses. Finally, we use softmax to get the probability. The formula is
F𝑗 =
exp(𝐶𝑗) ∑𝑐 exp(𝐶𝑗)
𝑗=1
. (2)
F𝑗 indicates the probability that the input image contains class j.
Training
We use similar method like [10] to train our model. Suppose the ground truth label of input image is G, and 𝐺𝑖 = 1 indicates there is label i in the input image while 𝐺𝑖 = 0 indicates there isn’t label i. The loss function is
J = − 1
𝑚∑ ∑ 𝑔𝑖𝑗log(𝑝𝑖𝑗) 𝑐
𝑗 𝑛
𝑖 = −
1 𝑚∑ ∑
1
𝑐+log(𝑝𝑖𝑗) 𝑐+
𝑗 𝑛
𝑖 . (3) 𝑔𝑖𝑗 indicates the probability that image i contains class j. c+ indicates the number of labels in certain image.
Experimental Analysis
Experimental Data
We have tested our method on three multi-label datasets respectively. They are VOC2007 [8], VOC2012 [8], and MIRFLICKR-25K [22].
The VOC2007 is provided by The PASCAL Visual Object Classes Challenge 2007. It is divided into 20 classes. The VOC2007 dataset contains 9,963 images, and 24640 tags. There is an average of 2.47 labels per image. In VOC2007, training and validation set contains a total of 5011 images, and there are 4952 images in test set. In our experiments, we use training validation set for training and test set for testing.
The VOC2012 and VOC2007 have the same type of labels. The VOC2012 dataset contains 22,531 images, and we only use 11540 labeled images in the training verification set. From these 11540 labeled images, we randomly select 2000 images as a test set, and the rest of these images as a training set.
The MIRFLICKR-25K dataset contains 25,000 multi-label images in 38 classes. In the experiment, 2000 images are randomly selected as a test set, and the rest of the images are used as a training set.
Evaluation Index
Precision and recall are single-value metrics. So, we use Mean Average Precision (MAP) [23] to evaluate the results. The average precision (AP) of a class k is:
𝐴𝑃𝑘 =∑ 1 𝑟𝑖 𝑛 𝑖=1
∑ 𝑟𝑖(∑ 𝑟𝑗 𝑖 𝑗=1
𝑖 ) 𝑛
𝑖=1 . (4)
Where 𝑟𝑖 is 1 if image i does contains the class, and 0 otherwise.
MAP =∑𝑁𝑘=1𝐴𝑃𝑘
𝑁 . (5) where N is the number of categories in the dataset.
Experimental Results
The MAPs of our method on each dataset are shown in Table 1.
Table 1. MAP (%) for VOC2007, VOC2012, MIRFLICKR-25K
VOC2007 VOC2012 MIRFLICKR-25K
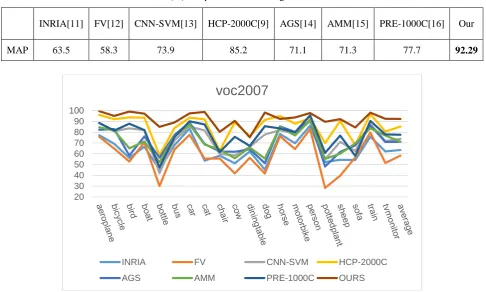
Table 2 reports our experimental results compared with the state-of-the-arts on VOC2007. We can see from Table 2, the MAP of our method has a certain degree of increase compared with previous methods. Fig.2 refers to the AP of each class based on the different methods in the VOC2007 dataset (AP in%). Compared with other methods, our method has a higher average precision on most classes.
Table 2. MAP (%) compared with other algorithms on VOC2007.
INRIA[11] FV[12] CNN-SVM[13] HCP-2000C[9] AGS[14] AMM[15] PRE-1000C[16] Our
MAP 63.5 58.3 73.9 85.2 71.1 71.3 77.7 92.29
Figure 2. Average precision of each class based on different methods on VOC2007 (AP in%).
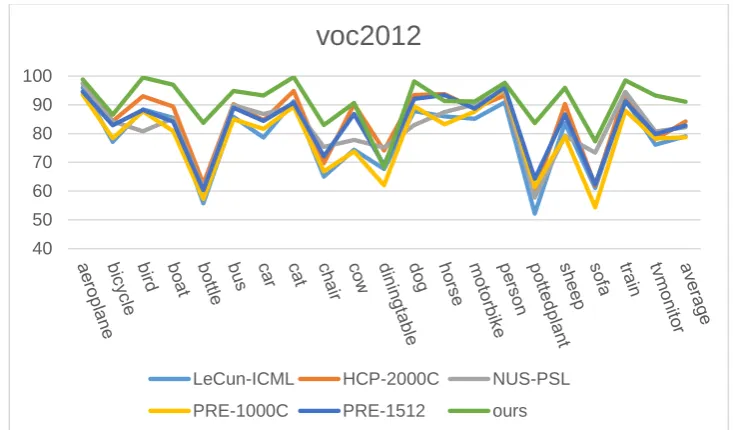
Table 3 reports our experimental results compared with the state-of-the-arts on VOC2012. As can be seen from Table 3, the average precision of our method compared with the previous algorithm has a certain degree of increase. Figure 5 refers to the precision of various classes based on the different methods in the VOC2012 dataset (AP in%). Compared with other methods, on most classes our method relatively has a higher precision.
Table 3. MAP (%) compared with other algorithms on the VOC2012 dataset.
LeCun-ICML[17] HCP-2000C[9] NUS-PSL[18] PRE-1000C[20] PRE-1512[20] Our
MAP 79.0 84.2 82.2 71.1 82.8 91.09
20 30 40 50 60 70 80 90 100
voc2007
INRIA FV CNN-SVM HCP-2000C
Figure 3. Precision of various classes based on different methods on the VOC2012 dataset (AP in%).
[image:5.595.114.481.353.562.2]Figure 4 shows the precision of top5 labels on MIRFLICKR-25K. From Fig.6, we can see precision of the baby, bird and food is low. This is because there are not enough images of these classes and the features cannot be learned fully.
Figure 4. The precision of top5 labels on MIRFLICKR-25K.
Summary
In this paper, we present an object Hypotheses-based deep learning framework to perform multi-label image annotation. Our framework doesn’t require the bounding box information. We evaluated our method on VOC2007, VOC2012 and MIRFLICKR-25K. The results demonstrate that the proposed method obtains significant performance gain over the state of the art methods. It is shown that, for the class labels with very few number of images, the deep neural network can be easily overfitting, leading to low precision. It is interesting to address this problem in future.
References
[1] Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. Computer Science, 2014:580-587.
40 50 60 70 80 90 100
voc2012
LeCun-ICML HCP-2000C NUS-PSL
PRE-1000C PRE-1512 ours
[2] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2015:1-9.
[3] He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 37(9):1904-1916.
[4] Gong Y, Jia Y, Leung T, et al. Deep Convolutional Ranking for Multilabel Image Annotation[J]. 2013.
[5] J.R.R. Uijlings, K.E.A. van de Sande, T. Gevers, and A.W.M. Smeulders. Selective Search for Object Recognition IJCV, 2013.
[6] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[7] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image
Recognition[J]. Computer Science, 2014.
[8] Everingham M. The Pascal Visual Object Classes (VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2):303-338.
[9] Wei Y, Xia W, Huang J, et al. CNN: Single-label to Multi-label[J]. Computer Science, 2014.
[10]Gong Y, Jia Y, Leung T, et al. Deep Convolutional Ranking for Multilabel Image Annotation[J]. 2013.
[11] H. Harzallah, F. Jurie, and C. Schmid. Combining efficient object localization and image classification. In Computer Vision and Pattern Recognition, pages 237-244, 2009.
[12] F. Perronnin, J. S´anchez, and T. Mensink. Improving the fisher kernel for large-scale image classification. In European Conference on Computer Vision, pages 143–156, 2010.
[13] A. S. Razavian, H. Azizpour, J. Sullivan, and S. Carlsson. Cnn features off-the-shelf: an astounding baseline for recognition. arXiv preprint arXiv:1403.6382, 2014.
[14] J. Dong, W. Xia, Q. Chen, J. Feng, Z. Huang, and S. Yan. Subcategory-aware object classification. In Computer Vision and Pattern Recognition, pages 827-834, 2013.
[15] Q. Chen, Z. Song, J. Dong, Z. Huang, Y. Hua, and S. Yan. Contextualizing object detection and classication. IEEE Trans. Pattern Analysis and Machine Intelligence, 2014.
[16] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Learning and transferring mid-level image representations using convolutional neural networks. arXiv, 2013.
[17] Y. LeCun and M. Ranzato. Deep learning tutorial. In International Conference on Machine Learning, 2013.
[18] S. Yan, J. Dong, Q. Chen, Z. Song, Y. Pan, W. Xia, H. Zhongyang, Y. Hua, and S. Shen. Generalized hierarchical matching for subcategory aware object classification. In Visual Recognition Challenge workshop, European Conference on Computer Vision, 2012.
[19] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Learning and transferring mid-level image representations using convolutional neural networks. arXiv, 2013.
[20] J. M. Geusebroek, A. W. M. Smeulders, and J. van de Weijer. Fast anisotropic gauss filtering. IEEE Trans. Image Processing, vol. 12, no. 8, pp. 938-943, 2003.
[21] P. Felzenszwalb and D. Huttenlocher. Efficient graph-based image segmentation,
[22] Huiskes M J, Lew M S. The MIR flickr retrieval evaluation[C]// ACM International Conference on Multimedia Information Retrieval. ACM, 2008:39-43.
![Figure 1. Partial results of Selective Search. The left part of Figure 1 is an image from voc2007[8] and the right part are partial results of Selective Search](https://thumb-us.123doks.com/thumbv2/123dok_us/295892.1030737/2.595.137.461.390.542/figure-partial-results-selective-search-figure-partial-selective.webp)