A Monthly Double-Blind Peer Reviewed Refereed Open Access International e-Journal - Included in the International Serial Directories.
IMPLEMENTING SOBEL AND EDGE DETECTION ALGORITHM FOR
RESTORING GRADIENT MAGNITUDE OF DISTORTED IMAGE USING
SIMULINK
R. Indra Gandhi | N. Saravanan | N. Kanniyappan 1
Professor , GKM College of Engineering and Technology, Chennai, India,
2,3
Assistant Professor, GKM College of Engineering and Technology, Chennai, India.
ABSTRACT
In recent techno-world languages are one of the medium of communication, which also act as a handy
tool to register many of the value based aged document information. Many techniques are available
for character recognition and many authors have contributed their work on character recognition for
good quality document images. Most of our valuable aged records have distortion. It might be because
of poor maintenance, poor paper quality, blurring of ink and damages done by bookworms. There is
a need to have many of these documents stored in electronic format to enhance their lifespan and
readability. There are many such electronic conversion solutions available in the market to restore the
clean and readable inputs. In some scenarios the conversion itself introduces distortions to the
document images. The accuracy of today’s document recognition algorithms fail abruptly when
document image quality distorted slightly. Related to this, many research works are in progress
globally. Pattern recognition places a vital role in resolving the above mentioned problems. Pattern
recognition research is complete only if it recognizes distorted document, which is deficient in the
present research works. This paper is an attempt to list some of the major causes of distortions and to
use efficient tool like Simulink to restore distorted documents. Edge thinning algorithm along with
Sobel is handled to ascertain the research work. Edge detection algorithm helps us to locate and
identify sharp discontinuities from an image that helps to find the edges in an input image by
approximating the gradient magnitude of the image.
Keywords— Edge detection, distortion, thinning, sobel , simulink
__________________________________________________________________________________ ____________________________
1. INTRODUCTION
The origin of character recognition can actually be dated back to 1870. This was the
and reading machines. The first conceptual idea of OCR is delivered by Tauschek. Initially in 1929, Tauschek obtained a patent on OCR in Germany, followed by Handel who obtained a US patent on OCR in USA in 1933 (U.S. Patent1, 915, 993). Tauschek was also granted a US patent on his method in 1935 (U.S. Patent 2,026,329). Tauschek's machine was a mechanical device that used templates. A photo-detector was placed so that when the template and the character to be recognized were lined up for an exact match, and a light was directed towards it, no light would reach the photo-detector.
The pioneer invention which was carried out by David Shepard’s in 1951, resulted in GISMO-A Robot Reader-Writer. GISMO-Author Jacob followed the footsteps of David Shepard and arrived with the prototype machine in 1954, which was able to read only upper case. In early 60’s, notable number of companies like IBM have conducted researches in OCR. IBM finally came out with its first marketable commercial OCR system called IBM 1418. Older OCR systems work by matching the scanned images against stored bitmaps based on specific fonts. The hit-or-miss results of such pattern-recognition systems helped to establish OCR’s reputation for inaccuracy.
Many a civilization was recognized only by the record of information that they left behind with the help of their best lingual potential. Hence raises the need to preserve the valuable information that treasures up the intelligence of human kind which should be retained by a safe mode of recovery when the registered material become worn out or torn out. The preservation needs some sort of computerized approach. Related to this, many research works are in progress globally.
Pattern recognition finds major part in resolving the above mentioned problems. Pattern recognition research is complete only if it
recognizes distorted characters, which is
deficient in the present research works. Most of our valuable records have distorted characters. However, it is challenging to develop an OCR system that can achieve high recognition rate as most of the distorted scripts are beyond
recognition state and requires complex
algorithms to reproduce the original scripts from them.
2.REVIEW OF LITERATURE
In recent past pattern recognition directly deals computer vision systems, orientation and intensity information about edges as primary input for further processing to document identification. The edge can have different meaning in various contexts. The main function of edge detection is to find the boundaries of image regions based on properties such as intensity and texture. Huttenlocher et al [1] expressed their techniques by comparing images using the Hausdorff distance to recognize an object. Shin et al [2] used an object recognition system for an
objective comparison of edge detectors.
Although many algorithms have been proposed to detect edges in noisy images, RRO are very commonly used in edge detection in noisy images and will be compared with the new approaches proposed.
discrimination ability, precision, and robustness ability of an edge detector.
Accordingly, different edge detection
algorithms can recognize edges in different forms of representation and each of them can be considered as a genuine edge detection algorithm. The edge detection process typically results in an edge map which is usually a binary image [8]. Edge detection is a low level operation used in
image processing and computer vision
applications. The main goal of edge detection is to locate and identify sharp discontinuities from an image. These discontinuities are due to abrupt changes in pixel intensity which characterizes boundaries of objects in a scene [9].
Edges give boundaries between different regions in the image. These boundaries are used to identify objects for segmentation and matching purpose [10]. The main of image analysis is to extract meaningful features from image data in order to reduce computational processing cost in higher level processes [11]. Image analysis can be considered as a data reduction process and its operations usually focus on reducing image data.
In First order derivative the input image is convolved by an adapted mask to generate a gradient image in which edges are detected by threshold. In second order derivative, these are based on the extraction of zero crossing points which indicates the presence of maxima in the image [12]. Since the second order derivative is very sensible to noise, and the filtering function is very important. Some methods are available for their automatic computation [13], but in most cases their values have to be fixed by the user. A significant problem of LoG is that the localization of edges with an asymmetric profile by zero-crossing points introduces a bias which increases with the smoothing effect of filtering [14]. An interesting solution to this problem was proposed by Canny [13] and Shen [15], which says in an optimal operator for step edge detection, includes three criteria: good detection,
good localization, and only one response to a single edge.
3. PROBLEM ON THE QUALITY OF THE ORIGINAL DOCUMENT
Some of the major causes of distortion commonly noted when dealing with analysis of original document [16].
a) The original is old, and has suffered physical distortion.
b) The original was produced on a manual
typewriter. So, the individual characters can show variations in pressure and position.
c) The original is a carbon copy produced on a
typewriter.
d) The original is low quality photocopy, and shows variations in toner density and character spread, as well as general copier “grunge” caused by a dirty glass or background.
Even a slight deter in the quality of document images results in a miserable fall of recognition accuracy. Distortion by natural calamities, physical distortion in the paper due to pressure
and position, distortion during printing,
distortions during scanning, distortions during photocopiers and fax machines are some of the well-known reasons in distortions of document images that play a fair role in increasing the
difficulty in recognition[16]. Distorted
documents do not include all the ideal properties of a document Li et al. [17] have discussed various defect models, their applications and methods for validating document defect models. Over the last few years, a lot of importance is being given to the problem of modeling document image defects so that a formal evaluation of the different OCR systems can be done.
the researcher’s choice of the training and the test data sets. As a result, such systems give excellent performance for the data sets chosen by the researcher. In many cases, however, the recognition accuracy falls sharply when even a slightly distorted image is chosen. The fall in recognition accuracy is often high compared to the visual nature of the distortion, i.e., the distortion as perceived by the human eye. It has, therefore, been felt necessary to model the defects quantitatively and experiment with extensive simulation to determine the nature of image defects that result in higher failure rate. There exist different steps for recognition of distorted documents. For each distortion type, we devise a unique system with its own set of steps.
4.IMPLEMENTATION
The Step by Step implementation procedure using the edge detection - Simulink block, for given distorted document images to detect resultant edges help us to explain each design in detail.
[image:4.595.320.549.323.529.2]Step 1: The Edge Detection Block enable to Simulink library Browser to process Video and Image Processing Blockset. ( refer Fig.1)
Fig. 1. Edge Detection Block of Simulink Library
Step 2: Select Parameters Method as “Sobel”
Step 2.1 : Choose output mode as binary.
Step 2.1.1 Check threshold scale factor detector
value as user define factor
Step 2.1.2 Check Edge thinning to thin the
unwanted edges.
Step 3: Construct various connection action
blocks using Video viewer to find edges
[image:4.595.62.549.539.752.2](refer Fig.2)
Fig. 2. Final Edge Detection Simulation Model
using Sobel Method
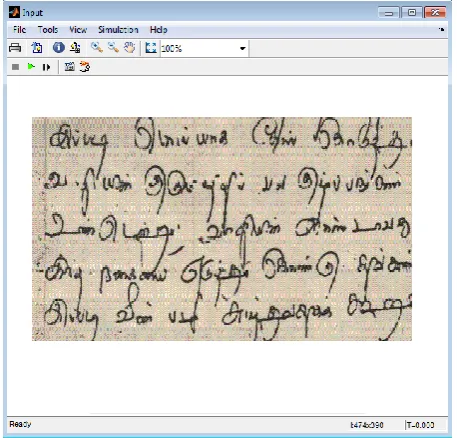
Fig. 3. Distorted Input Image File Loaded in
Simulation
Step 5: Linking input image happens in this
block which executes Color space
conversion.
Step 6: Image data type conversion happens at
this stage.
Step 7: Selection of Sobel Edge detection takes
place
Step 8: Boolean operation result to output file.
Step 9: Double click generate code & create
project operation to create respective
coding for the blocks.
Step 10: Build the project.
Step 11: By Double-click loading and running
option results will be displayed in the
screen
Fig. 4. Rendering GUI Model for Distorted Input
Image
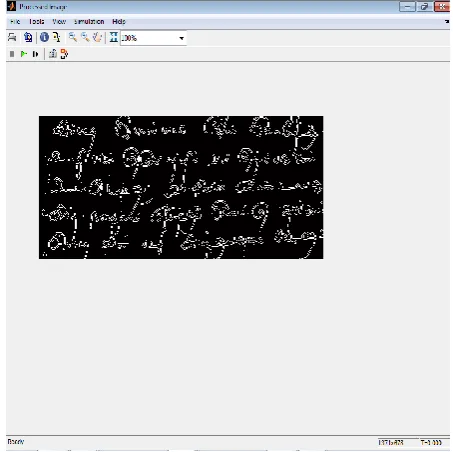
[image:5.595.326.543.121.303.2]Fig. 5. Edge Thinning Document Image after Edge
[image:6.595.65.555.356.756.2]Detection processing
Fig. 6. Reconstructed Distorted Image after Gray
Scale Processing
5.CONCLUSION
The proposed method proves to perform well regardless of the intensity differences between
foreground and background. Especially we have used edge thinning over distorted document to satisfy the fundamental requirement of thinning know as quality of thinned result. This process can remove irregularities in letters and in turn, make the recognition simpler because they only have to operate on one pixel wide. It also reduces the memory space required for storing the information about the input characters and no doubt, this process reduces the processing time too. This can be used in almost all the types of distortions to identify the original character structure. The resultant Reconstructed Distorted document Image after Gray Scale Processing evident the same.
REFERENCES
[1] D. Huttenlocher, G. Klanderman, and W.
Rucklidge, “Comparing images using the Hausdorff distance,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 15, pp. 850–863, 1993.
[2] M. C. Shin, D. Goldgof, and K. W. Bowyer,
“Comparison of edge detectors using an object recognition task,” Proceesings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 1, pp. 1360–1365, 1999.
[3] K. Bowyer, C. Kranenburg, and S.
Dougherty, “Edge detector evaluation using empirical ROC curves,” Computer Vision and Image Understanding, vol. 84, no. 1, pp. 77–103, 2001.
[4] M. Shin, D. Goldgof, K. Bowyer, and S.
Nikiforou, “Comparison of edge detection algorithms using a structure from motion task,” IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, vol. 31, no. 4, pp. 589–601, 2001.
[5] D. R.Martin, C. C. Fowlkes, and J.Malik,
“Learning to detect natural image boundaries using local brightness, color, and texture cues,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 26, no. 5, pp. 530–549, 2004.
[6] R. Moreno, D. Puig, C. Julia, and M. Garcia,
“A new methodology for evaluation of edge detectors,” in Proceedings of the 16th IEEE
International Conference on Image
Processing (ICIP), 2009, pp. 2157–2160.
[7] S.K.Thilagavathy and Dr.R.Indra Gandhi
[8] Saket Bhardwaj, Ajay Mittal, “A Survey on
Various Edge Detector Techniques”, Elsevier LtdProcedia Technology 4, Pgno: 220 – 226, 2012.
[9] H. Voorhees and T. Poggio, “ Detecting
textons and texture boundries in natural images” ICCV 87:250-25,198.
[10] S.E.Umbaugh, “Computer Imaging : Digital
Image Analysis and Processing”, CRC Press, 2005
[11] M. Juneja,P sandhu, “Performance evaluation
of edge detection Techniques for images in spatial domain” International Journal of Computer theory and Engineering, Vol. 1, No. 5, Dec, 2009 1793- 8201.
[12] Marr, hildreth., “Theory of edgedetection.”,
Proc.R. Soc. Lond.(1980), B 207, pp. 187-217.
[13] J F Canny, “A computational approach to
edge detection.” 1EEE Trans. PAMI (1986), 8, n ~ 6, pp. 679-698.
[14] Deriche . R, “ Fast algorithms for low-level
vision”, IEEE Trans. PAMI (1990), 12, n ~ 1, pp. 78-87.
[15] Shen J, Castan S, “An optimal linear operator
for step edge detection”, CVGIP: Graphical Models and Image Processing (1992), 54, n ~ 2, pp. 112-133.
[16] R. Indra Gandhi, K. Iyakutti and C. Jothi
Venkateswaran, “An analysis of various types of Distortions of Tamil Scripts”, World Tamil Internet Conference- Coimbatore 2010, June 23-27,pp362-371, 2010.
[17] Y. Li, D. Lopresti, G. Nagy and A. Tomkins,
“Validation of image defect models for
optical character recognition”, IEEE