Automatic Musical Pattern Feature Extraction Using Convolutional Neural Network
5
0
0
Full text
Figure
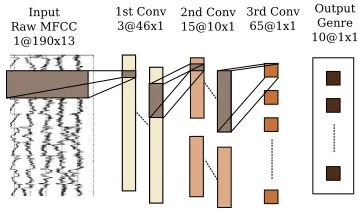
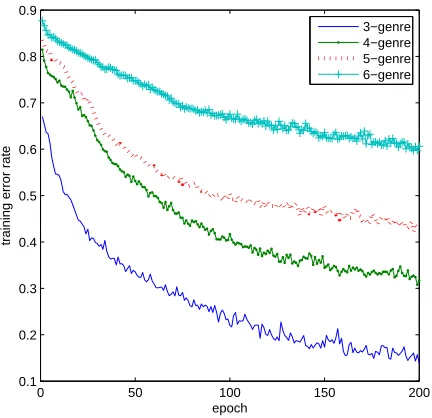
Related documents