Modeling and forecasting carbon dioxide emissions in China using Autoregressive Integrated Moving Average (ARIMA) models
13
0
0
Full text
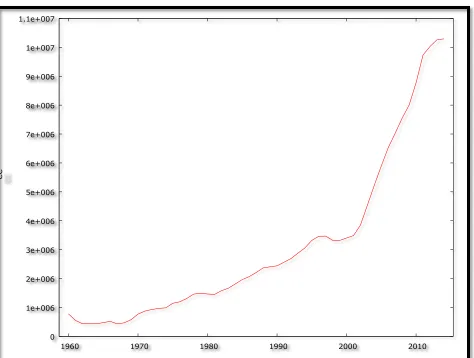
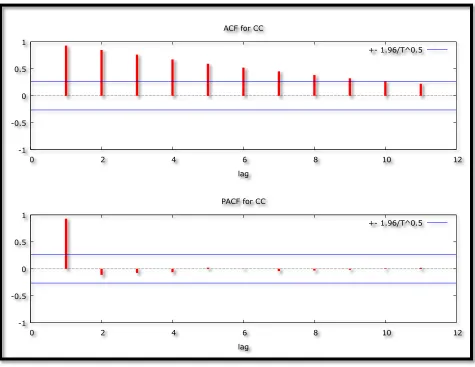
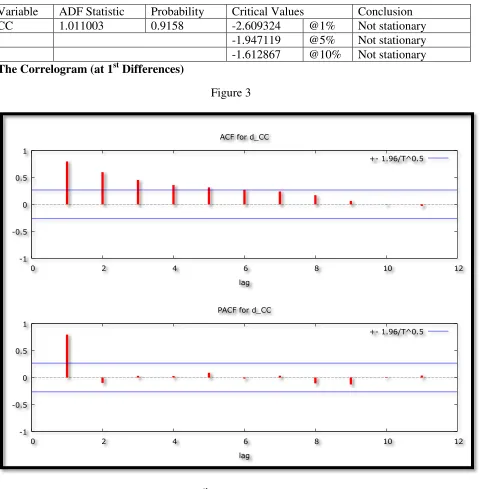
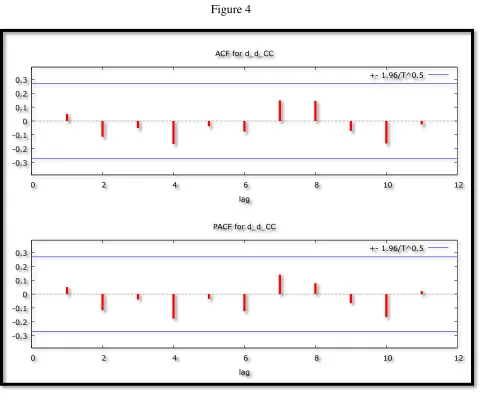
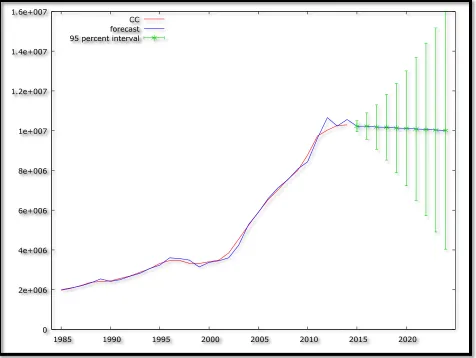
Figure
+3
Related documents