On Sanskrit and Information Retrieval
14
0
0
Full text
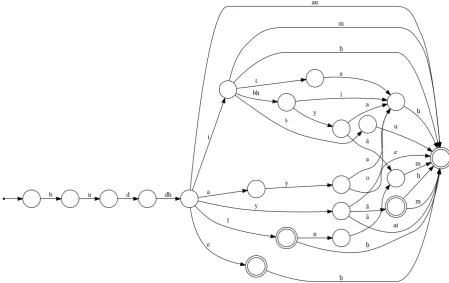
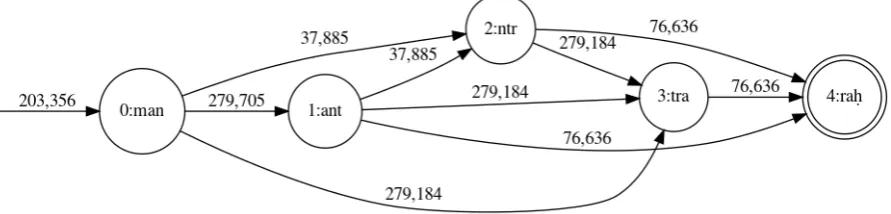
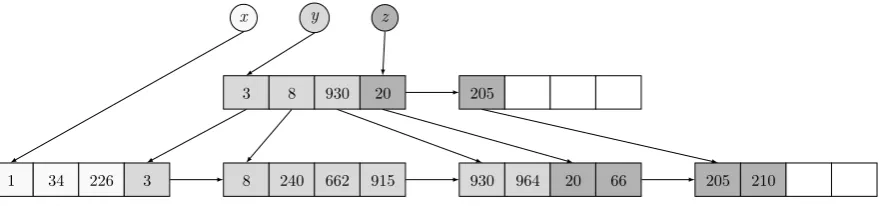
Figure

Related documents