ABSTRACT
WEST, CHARLES RYAN. Pylon GPS and Hyperchord. (Under the direction of Edward Grant.)
This paper details the architecture and implementation of two independent systems.
Pylon GPS is a differential GPS update sharing system which allows easy sharing of the updates
from differential GPS base stations to an arbitrary number of clients over the Internet. This system (meant to replace the existing NTRIP protocol) has been implemented, tested and functions as
intended.
Hyperchord is an authenticated version of the Chord peer to peer network protocol which is meant to be used to create secure overlay networks for robotics applications. It prevents
unautho-rized nodes from participating in the network and has some resistance to attacks made by corrupted
© Copyright 2016 by Charles Ryan West
Pylon GPS and Hyperchord
by
Charles Ryan West
A thesis submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Master of Science
Electrical Engineering
Raleigh, North Carolina
2016
APPROVED BY:
Wesley Snyder Edgar Lobaton
Michael Kay Edward Grant
DEDICATION
BIOGRAPHY
The author was born in a Candler, NC and home schooled. Since coming to NC State in 2007, he has acquired a Bachelor in Industrial Engineering, started a (failed) custom tile mosaic business,
built integrated drone systems, completed work in networking, neural networks and computational
intelligence, gotten married and had his first child.
ACKNOWLEDGEMENTS
TABLE OF CONTENTS
LIST OF FIGURES. . . vii
Chapter 1 Pylon GPS . . . 1
1.1 Introduction . . . 1
1.2 Overview . . . 4
1.2.1 High Level Goals . . . 4
1.2.2 Pylon GPS 1.0 . . . 4
1.2.3 Pylon GPS 2.0 . . . 5
1.3 Software Design and Implementation . . . 6
1.3.1 Software Overview . . . 6
1.3.2 Software Details . . . 9
1.4 Implementation . . . 14
1.4.1 Reactor . . . 14
1.4.2 Protobuf/SQLite Interface . . . 15
1.4.3 Security . . . 17
1.4.4 Unit Testing . . . 18
1.4.5 Caster . . . 18
1.4.6 Caster Message Formats . . . 19
1.4.7 Queries . . . 19
1.4.8 Transceiver . . . 20
1.4.9 Caster GUI . . . 20
1.4.10 Command Line Caster . . . 21
1.4.11 Transceiver GUI . . . 21
1.4.12 Command Line Transceiver . . . 22
1.4.13 Cloud Deployment . . . 22
1.4.14 Testing . . . 23
1.5 Conclusions . . . 26
Chapter 2 Hyperchord . . . 27
2.1 Introduction . . . 27
2.2 Peer to Peer Networks Overview . . . 28
2.2.1 Chord . . . 28
2.2.2 OneHop . . . 29
2.2.3 EpiChord . . . 30
2.2.4 CAN . . . 31
2.2.5 Hierarchical Peer to Peer Networks . . . 31
2.2.6 Common Themes . . . 33
2.3 Hyperchord Specification . . . 33
2.3.1 Overview . . . 33
2.3.2 Address Owner Resolution Procedure . . . 34
2.3.3 Pseudo-Processes and Pseudo-Threads . . . 35
2.4 Link Table Design . . . 40
2.5 On the Wire Message Formats . . . 41
2.6 Testing . . . 41
2.7 Unit Tests . . . 41
2.7.1 Convert IP Addresses to Binary and Back . . . 41
2.7.2 Link Table . . . 41
2.7.3 Test Circular Iterator . . . 42
2.7.4 Test Offset Addresses Generation . . . 42
2.7.5 Test Small Range Offset Address Generation . . . 42
2.7.6 Test Small Range Offset Address Generation with Non-Zero Base . . . 42
2.7.7 Test Signed Contact Info . . . 42
2.7.8 Test Chord Address . . . 43
2.7.9 Test Virtual Port Router . . . 43
2.7.10 Test Node Integration . . . 43
2.8 Conclusions . . . 44
LIST OF FIGURES
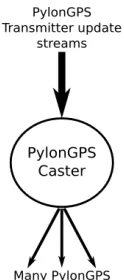
Figure 1.1 Simple Caster Architecture . . . 7
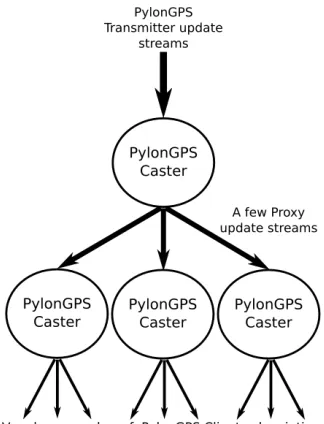
Figure 1.2 Tree Caster Architecture . . . 8
Figure 1.3 Multi-tree Caster Architecture . . . 8
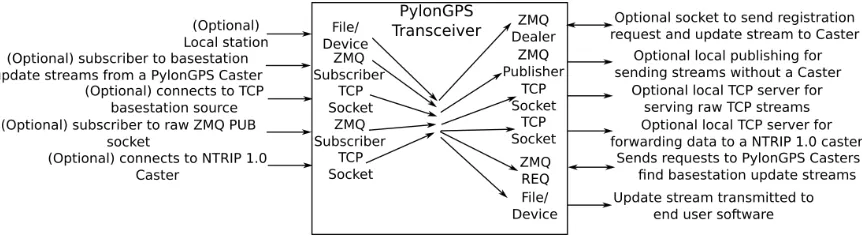
Figure 1.4 PylonGPS Transceiver . . . 9
Figure 1.5 PylonGPS Caster . . . 10
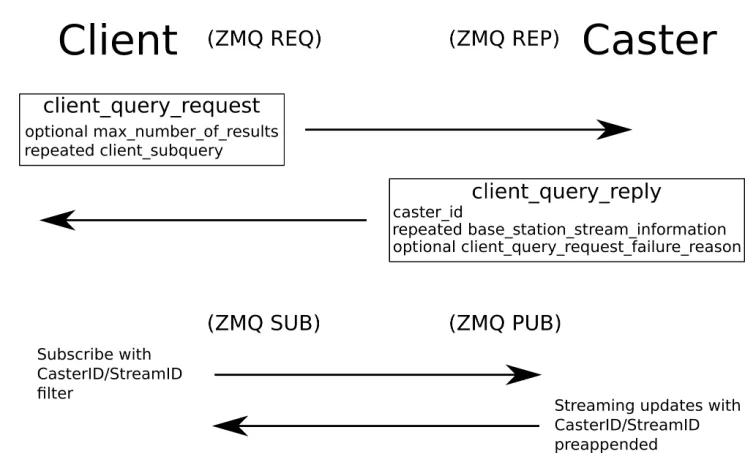
Figure 1.6 Client Query And Streaming . . . 12
Figure 1.7 Proxy Streaming . . . 13
CHAPTER
1
PYLON GPS
Introduction
Accurate localization is a necessary prerequisite for most mobile robot applications. While there are a large number of possible solutions for this problem, GPS is most widely used due to its inexpensive
equipment, global application and overall resilience. Most drones use it as their primary means of navigation and nearly every cell phone produced has a integrated GPS module.
Most modern GPS modules offer global accuracy on the order of a few meters. This precision
was a huge step forward in navigation when it was introduced and lead to a explosion of mapping and navigation applications such as dynamically adjusting walking/driving directions. However,
there are a number of emerging applications where meters precision is not enough. In the case
of sidewalk navigation, a few meters can mean the difference between being safe on the sidewalk and in the middle of the road. In the case of aerial robotics, a few meters can make the difference
between landing safely and hitting a fence.
There are two main sources of error in consumer grade GPS devices. Consumer GPS makes position fixes using the 1023 bit Pseudo Random Noise blocks transmitted from the GPS satellites
every millisecond[Zog09, p. 48], which limits precision due to limits on the time accuracy. More
1.1. INTRODUCTION CHAPTER 1. PYLON GPS
in perfect conditions should allow centimeter accuracy[Zog09, p. 103]. In practice, the precision of the signal is degraded by atmospheric conditions which distort the signal[Zog09, p. 101]. These
distortions can be both regional and local in scope, which means that the pattern of errors in the
received signal can vary over as little as 10 km.
The PPP (precise point positioning) approach to correcting these errors uses high precision
modeling of the GPS system and atmospheric conditions. A central database gathers weather data
and then transmits this global model for modules to use for corrections[Che13, p. 2]. This approach can increase the accuracy of solutions, but has not (so far at least) delivered centimeter accuracy with
consumer (single frequency) devices. The accuracy of PPP can be improved with a dual frequency
receiver but all current two frequency GPS offerings are prohibitively expensive (>$5,000).
The differential GPS approach overcomes the atmospheric distortion problem using a stationary
base station with a known location near the mobile GPS module. The base station records the
distortion from the GPS satellites and sends corrections to the mobile GPS module[Oga11, p. 53-57]. The corrections received from the base station degrade in accuracy roughly linearly moving out
from the base station, with excellent accuracy at 10 km, decent at 20 km and little improvement
further than 100 km[Pes15]. The distortions change on the order of seconds, so as long as the latency of the corrections arriving is<1.5 seconds, there is little degradation of the accuracy. Differential
GPS is a well tested technology that is widely used for surveying.
In 2013, Swift Navigation launched a Kickstarter for a differential GPS module called the "Piksi" [Pik]. This module can measure phase and includes an Xbee module to allow differential GPS updates to be transmitted between modules. The modules were to be used by setting one up as a base station and allowing the other to roam. The Piksi didn’t have any new technology, but was sold at $500
per module. This was a roughly 10x reduction in cost and brought differential GPS into the reach
of robotics/drone hobbyists. Drone builders recognized the potential of high accuracy GPS and enthusiastically supported the campaign. That success encouraged other startups, resulting in the
release of the $250 Emlid Reach in June of 2015 and the continued development by Radiosense.
Despite the success of low cost differential GPS to date, it could be argued that it has not really reached its full potential because of the requirement for users to setup their own base station and
the inability of the hobbyist community to share their corrections with each other (despite being
valid up to 20 km away). Removing the base station requirement would effectively cut the cost of the modules in half (removing the base station cost) and potentially make it much easier to get started
with differential GPS.
The potential of differential GPS was recognized in the late 1980s by the US Government, leading the establishment of differential GPS base stations near ports and eventually most of the United
1.1. INTRODUCTION CHAPTER 1. PYLON GPS
differential corrections coverage across the United States using marine radio frequencies and NOAA’s denser Continuously Operating Reference Stations (CORS) network. The CORS network offers
updates according to policies varying by state and charges a $500 flat fee per user for real time access
in North Carolina[All15]. A radio receiver could be added to the low cost differential GPS modules to allow them to receive corrections from the U.S. Nationwide DGPS network but the network is
too sparse to allow more than 1 meter accuracy in most locations. The CORS network could be
sufficient in many locations, but the network base stations use a somewhat inefficient method to share corrections over the Internet and the combination of small numbers of users, vendor lock-in
and inefficient distribution has lead to some states charging high rates for access.
The CORS network primarily uses the Networked Transport of RTCM via Internet Protocol (NTRIP) version 1.0 protocol for sharing differential GPS updates. This standard was released in
2004 and has a number of features which make using it somewhat difficult. In addition, the standard
is behind a paywall. An NTRIP 1.0 implementation consists of 4 parts. An NTRIP Source is some source of differential GPS corrections. An NTRIP Server is responsible for transferring data from
an NTRIP Source to an NTRIP Caster. The NTRIP Caster then proceeds to broadcast the updates it
receives from NTRIP Servers to NTRIP Clients. The NTRIP Clients then forward the corrections they receive to whatever requires them locally[HG03].
In principle, the standard accomplishes its goals (which is part of why it is so widely used). It appears to work well for surveyors, but has a few problems when extended to more general
use cases. Connections between NTRIP casters are made via TCP with HTTP headers that break
compatibility with HTTP in arbitrary places (preventing the use of standard HTTP libraries in NTRIP 1.0 implementations)[HG03, p. 12]. The standard also does not support searching, there is no way
to automatically add or remove a base station (the standard states to email an administrator), there
is no concept of base station trustworthiness (important for community driven efforts) and a TCP connection must exist for every base station that a client listens to a caster, which makes proxying a
caster difficult.
In addition, at the beginning of this project, there was only one open source implementation of the NTRIP standard. That implementation deliberately placed restrictions on its users in an
effort to drive them to purchase the commercial version. In addition, the company that made the
implementation has officially dropped support for it. The combination of the limits in the standard and the limits of the implementations make it difficult to use NTRIP 1.0 on a large scale, leading in
part to the restricted utility of the CORS network and the ineligibility of the hobbyist community to
make a replacement despite the prevalence of low cost differential GPS modules.
The author contacted 3 low cost differential GPS startups (Swift Navigation, Emlid and
sug-1.2. OVERVIEW CHAPTER 1. PYLON GPS
gested that it might be good to start with an NTRIP 1.0 compatible implementation and then improve from there. This lead to the creation of the PylonGPS 1.0 release.
Overview
High Level Goals
• Support for easy sharing of community generated and trusted entity (government, etc) base
station data, with officials sources marked as reliable.
• Creation of a cloud based central broadcaster/software for GPS updates which is scalable to handle arbitrary load levels while still being possible for 3rd parties to use for private
broadcasters.
• Allowing future changes to message types and applications via extensible message formats and
network protocols (including aggregators providing virtual reference stations via information collected from the network).
• Support for filtered lists of available base-stations and their associated statistics (real update
frequencies, etc).
• A graphic user interface for each part of the system, including a web interface to explore
available base-stations and a graphic user interface to setup and configure both clients and sources.
Pylon GPS 1.0
The primary goal for PylonGPS 1.0 was to create an open source implementation of the NTRIP 1.0 standard with an extension that allowed for automatic registration of base stations. A secondary
goal was to further understand the needs of the differential GPS community to enable the creation
of the Pylon GPS 2.0 release, which addresses many of the perceived problems with NTRIP 1.0. The Pylon GPS 1.0 release focused on providing an open source NTRIP Caster and NTRIP server
with an auto registration extension. The NTRIP Source is a local provider of data and the NTRIP
Client is often already implemented in differential GPS libraries such as RTKLib. In terms of the design, the NTRIP Caster is a TCP server which supports Server and Clients connections (each
of which have their own plain-text request/response headers loosely based on HTTP) and the
1.2. OVERVIEW CHAPTER 1. PYLON GPS
It was not possible to use the POCO library’s HTTP server implementation for the NTRIP caster because of the arbitrary changes made to the HTTP headers used with NTRIP 1.0. However, the
POCO TCP server could still be used. In the POCO module, there is a thread pool which handles
incoming connections and constructs a object to deal with each incoming connection using a factory provided by the application writer. In the case of the NTRIP Caster, the incoming connection’s header
was scanned to determine if it is a "SOURCE" request (which breaks HTTP compatibility) and handle
it specially in that case. If it is a normal HTTP request, the POCO library classes are used to parse it and check for the required fields. Once a NTRIP Server connection is accepted, the data it sends is
published internally using the ZMQ library’s inter-thread communication interface to "publish"
the data to any listening threads. Client connections listen to the publisher they are interested and forward the received information over the TCP connection to the NTRIP client software.
The NTRIP Caster also exposes a ZMQ request interface which accepts registration requests
from new base stations which are serialized/deserialized using Google’s Protobuf library. This allows automatic registration of new base stations and in combination with the previously mentioned
features, enables the creation of NTRIP Casters and Servers which are capable of sharing updates
from a small set of base stations.
Pylon GPS 2.0
The Pylon GPS 1.0 release was submitted for inspection by Swift Navigation, Emlid and Radio sense
on July 2nd, 2015. Discussions with the companies and review of the Pylon GPS 1.0 code lead to the conclusion that it would be desirable to refactor the code and add new features. Conversations
with companies made it clear that they did not care if the solution was NTRIP complaint so long
as it could get data to and from their modules. It also became apparent that while they were very interested in seeing the problem solved, they would be perfectly happy to direct their customers
to other software/didn’t have any real desire to administrate the solution. To meet these goals and
enable global free access to differential GPS updates, the Pylon GPS 2.0 system was designed so that one central system could distribute all differential GPS updates over the Internet (though nothing
about the design precludes independent distribution).
The end goal for Pylon GPS was to make adding a new base station as simple as turning it on and using existing base stations as easy as connecting to a caster. It would be desirable for rovers to
be able to automatically find base stations that are sufficiently trusted, have been operating reliably and are sufficiently close. To aid that goal, allowing clients to be able to perform a SQL like search
over available base stations was proposed as a feature in the new release.
break-1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
ing older software using it. The proposed Pylon GPS 2.0 design used Google’s Protobuf serialization library to allow future changes to be made without breaking backwards compatibility. The open
source Protobuf library allows message schemas to be specified and then serialized/deserialized in
most popular languages. It also allows optional message parts to be added at a later date while still allowing the messages to be read by older software (unrecognized optional parts are ignored). This
allows the standard to be changed later while still allowing backwards compatibility.
To address the scalability goals for Pylon GPS 2.0, the concept of Caster proxying was introduced. When one Caster proxies another, it become indistinguishable from the original caster to clients.
This allows a single caster to receive updates from base stations and then have many proxies forward
those updates to clients. This tree topology allows a single caster and many proxies to serve a relatively arbitrary number of clients. If the number of base stations grows too large, it also become
possible to split the load between multiple top level casters and have the proxies read from more
than one parent caster. Taken together, this allows the system to scale to an arbitrary size without software changes.
The proxying architecture is also a natural fit for Casters that live in the Cloud. One of the notable
features of virtual computers in the cloud is that new instances can be created and shut down quickly. This means that the number of proxies can be dynamically scaled depending on the load
from clients and base stations, allowing a single caster solution to handle loads of an arbitrary size using the same technology that drives most large scale websites.
The detailed proposal for the Pylon GPS 2.0 architecture was submitted to differential GPS
companies on July 20th, 2015. The response was fairly positive, so the research moved forward (despite being slowed down somewhat by obligations such as the drone demo for NGAT’s display at
the 2015 State Fair and work at Primal Space Systems).
Software Design and Implementation
Software Overview
The software consists of 2 primary components and an optional third component, detailed below. Each of these components are implemented as one or more classes included in LGPL license so that
custom applications can easily be built on top of it. Wrapper programs which use these classes have
also been written to allow use of the normal operations of the library.
PylonGPS Transceiver (offering functionality similar to NTRIP "server" and "client"): This is a
class/program offered with both a GUI and via command line.
1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
what streams are available from PylonGPS 2.0 Casters.
The transceiver supports retrieving data streams from files/devices, raw TCP servers, raw ZMQ
publishers, PylonGPS 2.0 casters. It also supports hooking the data stream from any one of these
sources to one or more output methods, including files/devices, creating a raw TCP server, creating a ZMQ publisher, or sending to a PylonGPS 2.0 caster. Outgoing PylonGPS 2.0 connections include
both authenticated and unauthenticated options.
A PylonGPS 2.0 caster supports a fairly rich set of search options via a ZMQ REP socket. This makes querying as simple as making a query object and sending it to the caster. To further simplify
searching, the Transceiver offers a convenience function to serialize/deserialize and send/receive
queries to a Caster.
This class/program is used to distribute information from PylonGPS Transmitters and support
proxying of any and all streams via other PylonGPS Casters to enable simple scaling. Increasing
scale can be handle by having all sources point toward a central Caster and then creating other casters as proxies to disseminate the received flows. The associated star topology should be able
to serve very large numbers of receiving clients (assuming the number of clients>>the number
of transmitters). If the number of transmitters gets too large, the star topology can be fragmented so there are separate instances with each taking a fraction of the transmitters. In that case, the
proxies simply proxy multiple Casters. Each Caster supports requests for filtered base station results and returns a stream ID for clients to subscribe to. The clients can then use the ZMQ subscribe
mechanism to receive updates from one or more streams.
1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
Figure 1.2Tree Caster Architecture
1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
Software Details Common Patterns
Each class with network interfaces tends to follow a similar design. They expose one or more ZMQ
network interfaces for communication and start a thread to execute their functionality upon
initial-ization (using the actor model). All public members are thread safe and untouched by code executing in the separate thread once initialization has completed (the constructor returns). Internally, the
thread is polling on its interfaces with a poll timeout determined by the time to the next event in its discrete event queue (containing the time of possible messages timeouts and other events). When a
message is received, the appropriate functionality is called and often a response is sent. Otherwise,
the next event is processed (such as removing stream information from the database after it has been silent too long) and further events added to the queue. Most messages are serialized Protobuf
objects specifically designed for the interfaces and all events are a serialized "event_message" type
with member objects denoting the details of the event. All GUI functionality is derived from external graphics classes which communicate with these interfaces. This allows simple extension to network
based GUIs due to the ability to bind ZMQ sockets to multiple interface types (including sockets).
Pylon GPS Transceiver
Figure 1.4PylonGPS Transceiver
The Pylon GPS Transceiver is composed of one manager class and a number of classes that adhere to either a "dataReceiver" or a "dataSender" abstract class interface.
"dataReceiver" classes (such as "fileDataReceiver") open/connect to the data source type they
1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
source. The second address bound is used with a ZMQ PUB socket to publish notification messages indicating any status changes or error conditions encountered in processing data from the source.
"dataSender" classes (such as "fileDataSender") are given the data publishing address of a
"dataReceiver". They bind an ZMQ interthread communication address for reporting errors and connect/open their associated destination to forward data.
The Transceiver class offers convenience functions for creating/storing/destroying
"dataRe-ceiver" and "dataSender" classes as well as sending a query to a Pylon GPS 2.0 caster and getting the result. The exact function details depend on the details of the underlying class.
Pylon GPS Caster
Figure 1.5PylonGPS Caster
The Pylon GPS Caster is composed of one class. Upon initialization, the caster class binds 5
public ZMQ interfaces on different ports.
The transmitter interface (Ca1) receives registration requests and either accepts and rejects them (metadata conflicting with existing entries or ill-formed requests can cause rejection). During
a successful handshake, the caster adds the source metadata to the list of available sources. It then
expects a steady stream of updates and stores/associates statistics about the update stream in the entry regarding the stream. If a empty message is received on the stream or a stream fails to send
a message before the maximum between message time elapses, the caster sends a stream closed
message and then removes the stream metadata/deconstructs the stream connection.
If a stream is connected, the messages that it forwards will be prefaced with the associated 64 bit
caster ID and stream ID then published on the client publisher socket (Ca5). This allows clients to
use the ZMQ PUB/SUB socket functionality to select which streams to listen to by filtering based on the stream ID (only feeds that they subscribe to are sent to them over the network). The messages
are also prefaced with the class’s caster ID and stream ID then published on the proxy publisher
1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
while still being able to tell the streams apart (assuming casters are trustworthy, which they should be since they are owned by trusted parties).
Each time a stream connects, exits or times out, a notification message is published on the
stream status publisher interface. The notification message is always prefaced by the caster ID and the stream ID, which allows clients and proxies to either filter for the ones they are subscribed to or
be notified as new streams become available so that they can subscribe.
The Caster class creates the client request interface to receive and answer requests about the streams available from the caster. The Caster maintains a SQLite database containing the metadata
of each base station. It supports the union of subqueries in a single request, allowing searching
for base stations based on characteristics (message type, etc) as well as rectangular and circular location queries covering particular areas.
Authenticated sources are also supported, wherein a base station claiming authenticated status
must have a signed credentials message by a recognized key. Organizations that are trusted can be given recognized signing keys and generate credentials for their base stations (official base stations).
Alternatively, individual connection keys/credentials can be generated and distributed on a base
station by base station basis (registered community).
Signing keys are added/removed via a request sent to the key management ZMQ REQ socket. All
such transactions must be signed by the key management key that was assigned when the caster was created.
Instructing a caster to proxy another one can be accomplished using thread safe functions. There
is not currently a network interface for controlling proxying functionality, but there is no reason one cannot be added at a later time.
Scaling
ZMQ is a powerful networking library which can handle large loads gracefully while maintaining a
simple interface. This should allow a single caster to handle reasonably large numbers of clients.
However, it is possible that the number of base stations and users could grow considerably and load seems to be a problem that concerns many existing users of NTRIP based servers. To address
this issue, the caster class has been designed in such a way that it can be scaled to a more or less arbitrary size simply by adding more servers (potentially dynamically according to load) as proxies.
One caster can act as a clone or proxy of another by first subscribing to the stream status publisher
interface, querying the original caster for the metadata for all its streams and then subscribing with an open filter (accept all) to the proxy publisher interface. The proxy accepts all of the stream metadata
1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
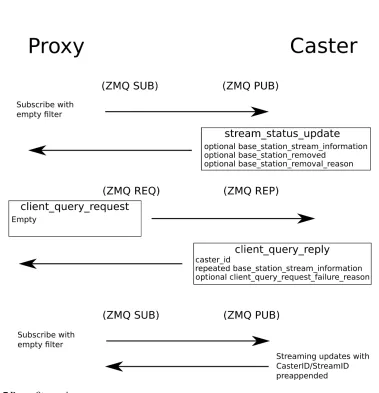
Figure 1.6Client Query And Streaming
received over the stream status publisher interface and then answers queries and simply republishes
all messages received via the proxy publisher interface and stream status publisher interface (after changing the caster ID). The behavior of a proxy should be more or less indistinguishable from the
original to the client.
In the simplest load case, there are a moderate number of sources and a moderate number of clients. In this situation, a single caster instance can be deployed and have both stream sources and
clients directly connect to it.
In the case where there is a moderate number of stream sources and a large number of clients, all stream sources can connect to a single caster and all client requests can be handled by proxies of
that caster.
In the case where there is a large number of both stream sources and clients, the caster system can be broken into multiple independent subsections in which each part take responsibility for a
fraction of the sources. In this case, clients query a proxy from each group and subscribe to a stream
from the group that meet their requirements the best.
All 3 scenarios can be accommodated without changes to the caster software, though it might
be beneficial to pass to the client which architecture is being used so that they know if they need to
query multiple locations (and if so, who to query). Balancing among proxies can be done via round robin DNS and other standard server distribution solutions. With some extra work (dynamically
1.3. SOFTWARE DESIGN AND IMPLEMENTATION CHAPTER 1. PYLON GPS
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
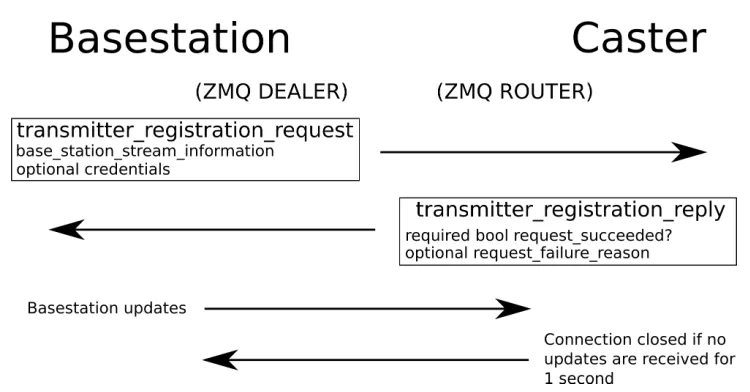
Figure 1.8Basestation Registration and Streaming
be a problem with load.
Implementation
Reactor
The actor model is used throughout the Pylon GPS code. The actor model entails creating objects
which have threads associated with them and using inter-thread communication to allow them to
allow them to coordinate.
Since the actor model is used throughout the code, a template class was created simplify creating
actor objects. This class is known as a "reactor" and is used create/associate a standard library thread
with an objects and register/manage the ZMQ sockets and file descriptors associated with the object. For each registered socket or file descriptor, the reactor calls the function that was given with the
socket. These functions change the internal state of the object and often send their own messages
using sockets which may or may not have been registered with reactor. In addition, the reactor object maintains an priority queue of events and calls a member function of the owning class to
handle events as they occur (defined by the POCO time stamp when an event is schedule to occur).
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
Protobuf/SQLite Interface
SQL like query capability was a stated goal for the Pylon GPS 2.0 release and the most efficient way
to provide that capability for Pylon GPS was to use a SQL library to do query processing. SQLite was
selected due to the author’s familiarity with it, the simplicity of installation (it can be used as a linked library) and the fact that it supports RAM only databases (which enables fast query processing).
In the rest of the application and over the network, base stations are represented using a Protobuf
object. Answering queries about the available base stations would require entering most of the base station details into the database and then either reconstituting the Protobuf objects that met query
criteria or storing them in a separate map/retrieve with a key. While it was be possible to do this serialization/deserialization of the base station objects manually, this requirement had appeared
across several other projects and a more general solution was required.
The core requirement was to be able to serialize an arbitrary Protobuf object into a SQLite database and then retrieve it. If this operation was possible, the only manual SQL statement creation
that would be required was the query to locate the primary keys associated with the proper base
stations. An initial attempt to address this problem used a template object object and macros to register the storage/status/retrieve functions associated with the primitive types associated with
a Protobuf message and then construct a representation using function pointers. This
represen-tation was then used to create and store the appropriate SQL statements so that the object could be stored/retrieved and the appropriate tables created. The function pointer/macro approached
worked for Protobuf objects which did not contain sub messages, but required approximately a half
page of code to make a template for a specific Protobuf object (code length depending on schema length). The amount of code needed to handle Protobuf objects with sub messages would quickly
grow unmanageable, even if the approach supported it.
The function pointer/macro approach worked well enough to be used for the library as it was being developed, but started segmentation faulting whenever it was used after a system upgrade
(currently unknown what library or system change caused the segmentation fault). The function
pointer/macro approach had been difficult to debug as it was being developed due to the difficulty of getting the function pointer type correct and the unhelpful but remarkably verbose error messages
that resulted when they were not quite right. Given the debugging issue, brittleness and overall
kludginess of the function pointer/macro approach, it was decided that the Protobuf/SQLite code should be rewritten. Investigation revealed that Protobuf offered significant reflection information
on the objects that it generated. This allowed most of the information that had previously been
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
and recursion to be used to allow messages with sub messages (which may in turn also have sub messages) to be processed (as long as it is not possible to create a sub message at an infinite depth).
Taken together, the result is a interface that will allow a reasonably arbitrary Protobuf object to be
stored and retrieved from a SQLite database efficiently with a minimal amount of code written. In addition, the interface remained similar enough that minimal outside code needed to be rewritten
to accommodate the new interface.
Protobuf/SQLite implementation
One of the challenges of creating a general protobuf/SQLite converter is the composability of Protobuf messages. Each Protobuf message can be have of any number of Protobuf message subparts.
These subparts can in turn have their own submessages. This makes representing any given message
type challenging and automatic generation of SQL statements that will be able to store/retrieve the objects difficult. The approach that was used in the second iteration of the Protobuf/SQLite
converter used the reflection methods that are provided with Protobuf to construct a recursive
definition of the messages. The components of a given message can be broken down into 6 parts:
• Singular primitive fields (integers, doubles, strings)
• Singular sub-message fields
• Repeated primitive fields (integers, doubles, strings)
• Repeated sub-message fields
Submessages are permitted to contain definitions of other submessages, leading to a tree
struc-ture which fully defines a given message. This allows the definition to be fully general as long as the message definition tree is acyclic. In the event of a cyclical message definition, the converter will
enter an infinite loop (since it does not recognize repeated occurrences of the same message type
and must generate insertion/retrieval statements at each level of the tree).
Protobuf’s message composability also created challenges for representing the objects in the
database. Messages containing solely singular fields can be represented in a SQL database as a single
row. However, submessages and repeated fields must be represented in a seperate table that points back to the message’s singular field entry using an index due to their variable size. In the case of
submessages, these entries can in turn have their own repeated and submessage fields. This leads
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
the table which they point back to, allowing visual inspection of the tables which are automatically generated in the database.
Entries in a database are required to have a primary key which is unique. This could be
automat-ically generated, but that presents some difficulties when checking if an entry has been placed in the database already. The converter handles this issue by requiring that the given Protobuf messages
have at least one integer field and automatically selecting the first integer field in the message as the
primary key (fields can be ordered arbitrarily in a message by altering the number associated with it). This allows for efficient search on a primary key and reduces code to create a converter for a
given message type.
A converter for a particular type of message is created using a connection to the SQLite database and the Protobuf "Descriptor" that is associated with the message type. This "Descriptor" is a
statically defined structure associated with the C++definition for the message. It contains reflection
information for the message type such as the fields, their associated type and name. The converter saves hooks for each field’s descriptor and generates the recursive definition of the message. As
part of creating the recursive definition of the message, the converter automatically generates and
runs SQL statements to create the SQLite tables that the message instances will be stored in. It also creates and stores prepared statements for inserting and retrieving from each of the tables that it
makes (it being necessary to create the tables before prepared statements can be made for them). Once the definition has been created, the converter can perform operations on instances of the
message type by pairing its reflection based methods with the associated prepared statements.
The converter supports storing/retrieving/deleting an object via its primary key as its main functionality. Updating an object is currently supported in the converter only for fields in the primary
row of the object. Searching for an object with particular characteristics requires some familiarity
with the tables that the converter generates. This familiarity is most easily acquired by looking at the tables generated by the message (though the table name patterns are completely deterministic).
The converter is used with Pylon GPS 2.0 to store/update/retrieve/delete and search
base_-station_stream_information objects. It enables all of the querying functionality that Pylon GPS 2.0 supports.
Security
A major problem with anonymous resources providers is the quality of the results and potential for malicious action. It is desirable for Pylon GPS 2.0 to be able to support non-critical operations (such
as allowing a robot to navigate around the lawn) and more critical operations (such as any sort of
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
Pylon GPS 2.0 provides this capability by providing an authenticated option. In this mode, registering base stations provide a "credentials" submessage and sign each of the data pieces that
they forward to the caster. A "credentials" message is required to have a serialized
"authorized_-permissions" sub-message which defines what the basestation’s key owner is permitted to do (how many base stations it can be used with), how long it is valid and the public key associated with
the signer. It also has one or more "signature" objects which contain a signing public key and the
cryptographic signature associated with that signer.
When an authenticated base station registers, the caster checks that the signature appended
to each message actually matches the public key that is stated in the credentials and drops the
connection immediately if it does not. It then checks each of the signatures to ensure that they match for the given signing public key signing the given serialized "authorized_permissions" object
and drops the connection if they do not match. Next, it checks if the date for the permissions expires
has passed. If it has, the connection is dropped. Lastly, it checks if the key has been blacklisted and if any of the signing keys that are recognized by the caster. If at least one of the signing keys is
recognized, the base station is permitted to connect and given the highest type authorization that
it’s signatures allow (OFFICIAL or REGISTERED_COMMUNITY).
Unit Testing
Unit testing is an important part of modern software development practices. It has been the
experi-ence of the author that it is incredibly difficult to write software that is past a certain threshold of complexity without it. Accordingly, the Pylon GPS software uses a unit test framework (Catch) and
tests reasonably extensively. All tests are passing as of the time of writing.
Caster
The PylonGPS 2.0 Caster is composed of 3 reactors acting on one large class.
The clientAndDatabaseRequestHandlingReactor reactor is responsible for answering client
queries regarding the available base stations as they come in and handling internal (inter-thread) requests to make changes to the database (adding or removing base stations). It essentially
trans-forms requests into database operations, applies them and returns the results. It is the only thread
that accesses the SQLite database. Most operations on the database are carried out using the Proto-buf/SQLite interface, with the sole exception being retrieving the primary keys of base stations that
meet a client’s requirements.
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
dropping connections if they haven’t sent an update for longer than the max wait time (currently 5 seconds). New base stations can connect and start sharing data without any credentials but any data
stream without accepted credentials will be marked as a "community" base station. Alternatively, if
the registering base station has a credentials message signed by one of the trusted "official" or "reg-istered_community" keys then it will be able connect with and forward its data with the appropriate
label.
The statisticsGatheringReactor analyses corrections as they are published from the caster and then uses that information to update the sending rate associated with the stream (which can be
seen by querying clients). Since ZMQ messages don’t necessarily correlate with complete correction
update messages, the acquired information merely gives a very vague sense of how active the base station is.
Caster Message Formats
As previously mentioned, most interactions with the Caster (except for receiving corrections) take the form of exchanged Protobuf messages. As part of developing this library, many convenience
functions were created. One of these functions allows automatic RPC calls to be carried out with
a socket, allowing one of these transactions to be carried out (including serialization, sending, receiving and deserialization of the response) in a single function call. Some of the details for the
Protobuf messages used are as follows:
Queries
As mentioned in the goals section, the Pylon GPS 2.0 Caster is suppose to support SQL like queries on the available base stations. These queries are carried out using the client_query_request Protobuf
message. The query message contains just two fields. One is an upper limit on how many base stations can be returned (potentially useful if network load becomes a problem) and the other is
a set of zero or more client_subquery objects (zero sub-queries results in all base stations being
returned). In processing a given query, the union of all the base stations recovered from sub-queries is returned while within a sub-query all requirements results are intersected together. This allows
for complex queries to be constructed, such as "give all base stations within 10 km of this point
that are not in this latitude longitude box". The client_subquery messages allow filtering results based on the class of the base station (Official, etc), the message format the base station is using
(RINEX, etc), an arbitrary number of conditions on the latitude, longitude, how long the base station
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
distance from a particular point on Earth. With a well formed query, the base station information for all base stations that meet the required criteria is returned to the client.
Transceiver
The Pylon GPS 2.0 transceiver employs an architecture similar to the internals of the Pylon GPS 1.0
Caster. The transceiver class offers functions to allow the creation and storing of one of several dif-ferent types of data receivers (currently file, connection to TCP server, connection to ZMQ publisher
and receiving from a Caster). On creation, each of the data receivers creates a token which can be used to forward the data they receive between threads. This token is actually the ZMQ connection
string to use to connect to the interthread ZMQ publisher socket that they forward data to. An
arbitrary number of data senders can be made that subscribe to any given data receiver and then forward to their associated data sink (currently file, a TCP server which forwards to any connected
client, a ZMQ publisher and registration as a base station with a Caster). This allows one class to be
used to connect a module to a Caster as a base station, take data from a Caster and forward it to a module as corrections or distribute the data locally in several different ways (simultaneously if
needed).
The Transceiver also offers a static function that can be used to send a query request to a caster, making it straightforward to create methods to automatically select base stations.
GUI development was done using Qt5 widgets, Marble and JsonCPP. QtQuick was considered
for GUI development but was considered not to be mature enough (in particular, there did not seem to be a straight forward way to ensure all dependencies had been installed).
Caster GUI
The Pylon GPS library passes around Protobuf objects and key strings as C++objects. This isn’t necessarily practical for a novice/non-programmer user. While the end goal is that the user will need
to do little to no configuration (and not have to setup or administrate a Caster), it was considered a
good idea to create a GUI to simplify managing a Caster process.
The Caster GUI can be used to set the ports that a (command line) Caster process process uses,
as well as the key management key that it will recognize for requests to add/remove signing keys.
It also enables generation of new public/private signing key pair files with a button and save file dialog. These signing key files are simply the fixed length keys saved to a file in Z85 format but they
make transporting and saving keys much easier. In addition to being used for caster configuration,
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
be selected as well as the keys to sign for it. At the conclusion of the process, a credentials file is generated that can be used with a transceiver. The credentials file is just a Protobuf credentials
file with the size of the serialized object preceding it (saved in a machine independent format).
Most other file types associated with Pylon GPS follow a similar format and are save/retrieved using a file/Protobuf utility function. Lastly, the GUI allows a user to connect to a running Caster and
add/remove official or registered community signing keys with an expiration time.
Command Line Caster
This program can either take a Caster configuration file or be configured using command line
options. It runs a Caster process which Transceivers can connect to.
Transceiver GUI
The Transceiver GUI is much more complex than the Caster GUI and a fair amount of effort was expended attempting to make the user experience simple and pleasant. Upon opening the GUI,
the main portion of the window should immediately zoom to an Open Street Map view of the city
they are running the client in, showing all base stations which are available nearby both on the map as labeled points of interest and on a side pane sorted by distance from the center of the view. On
the top left there is a button that allows none base station data sources to be selected, opening a
dialog menu which allows files, TCP servers or ZMQ publishers to be selected as data sources. Below that is a line edit which allows the user to enter their address, causing the map to center on it. It is
also possible to navigate by zooming in and out on the map using the mouse wheel or clicking and
dragging on the map. The details of a particular base station can be view either by hovering over the associated widget or clicking on its map marker. Any of the base stations can be selected as a
data source by clicking on their "+" icon, at which point they are cloned onto the right pane. Any local data sources appear on the right pane as well. Selected data sources can be removed simply by
pressing the "-" button on the associated widget. Any new or removed base stations will have their
changes reflected on the map within approximately 10 seconds (though the change might cache until the user moves).
Once the appropriate data sources are selected, the user can press the button on the bottom right
to move to the data sender management frame. A data sender that forwards data from a particular data receiver can be made by pressing the "+" button on a particular data receiver. This opens up
a dialog box which allows the type of data sender and its characteristics to be selected (sending
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
sender is created, it appears on the right pane of the senders frame with a black line connecting it to the associated data sender. This makes it clear which data source a sender is forwarding from and
the widgets are arranged so that the lines never cross. A single sender can be removed by pressing
the "-" button on its widget and if a data source is removed, so are all of its associated senders. Once a user is happy with their settings, they can save them as a Transceiver configuration file
using the buttons on the bottom left (which also allow the settings to be loaded). This configuration
file can also be used with a command line transceiver program.
Qt5 provides the bulk of the widgets used for the GUIs, while Marble provides the map widget.
Auto-detection of the user’s city is carried out by a Json web call to a website which provides your IP
address and estimated location based on that IP address. Resolution of the latitude/longitude of a user’s address is carried out by a Json call to Open Street Map’s Nominatim service.
Internally, the program uses a model/view design pattern to display the available base stations,
selected data sources and data senders. The available base stations are refreshed periodically using Pylon GPS client requests depending on where the user moves the map. Functionally, the program
just acts as a wrapper to the Transceiver class.
Command Line Transceiver
The command line version of the transceiver offers functionality similar to the transceiver GUI
with-out requiring the graphic libraries. It allows searching of base stations based on their characteristics,
allowing base stations to sorted relative to a specific place on Earth. It also allows the sorted base stations to be used to automatically select a data source to forward, loading of configuration files
created using the GUI and forwarding to/from the same set of local data sources/sinks..
Cloud Deployment
The best possible outcome for Pylon GPS would be for all of the differential GPS updates in the
world to flow through a single cloud based Caster array which would make it available to anyone
that uses differential GPS (aiding the "just turn it on and it works" goal).
A single Caster node (running on a $5 per month cloud server) has been created and given DNS
address pylongps.com. By default, the Transceiver GUI points to this caster. With a small amount of
money ($60 a month or so), this could be expanded into a redundant and extremely resilient service which can be scaled to an arbitrary size. This is likely to occur if industry partners take interest, as it
would allow them to greatly expand their potential market at a very low cost.
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
being experienced. Most cloud services support automatic addition/removal of nodes, so scaling integration should be possible with minimal changes.
Testing Unit Tests
A large number of unit tests were constructed as the development of Pylon GPS was carried out. Characteristics such as key generation, base station registration, client query and many others have
a number of tests devoted to them. Currently all of those tests are passing and all of the GUI features
seem to be working as expected.
CommandLineArgumentParser
1.4.14.1.1.1 Single Argument Options Arguments Passes a set of programName -option1 option1Argument -option2 option2Argument as a string array (emulating normal program argu-ments) and then tests if the options and arguments were correctly retrieved.
1.4.14.1.1.2 Multiple Argument Options Passes a set of programName -option1 option1Argument1 option1Argument2 as a string array (emulating normal program arguments) and then tests if the
options and arguments were correctly retrieved.
1.4.14.1.1.3 Multiple Occurrences of a Single Option Passes a set of programName -option1 option1Argument1 option1Argument2 -option2 -option1 option1Argument3 option1Argument4 as
a string array (emulating normal program arguments) and then tests if the options and arguments
were correctly retrieved.
1.4.14.1.1.4 Clamping an Option’s Number of Arguments Passes a set of programName -option1 -option1Argument1 -option1Argument2 -option2 --option1 -option1Argument3 -option1Argument4 as a string array (emulating normal program arguments) and then tests if the options and arguments
were correctly retrieved (ignoring all except for the first using the clamping option).
1.4.14.1.1.5 Testing Case Sensitivity Passes in two options which differ only in case and checking that they remain separate.
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
Test messageDatabaseDefinition
1.4.14.1.2.1 Store and Retrieve Message Object Creates a complex protobuf_sql_converter_-test_message, an in memory connection to a sqlite3 database and a messageDatabaseDefinition
templated on the definition of protobuf_sql_converter_test_message. It then stores and retrieves the created message in the database using the messageDatabaseDefinition and then compares to
the original. Lastly, it does an update operation on the message in the database and then deletes it.
Key Management Functions
1.4.14.1.3.1 Test Key Generation/Format Conversion Functions Generates a binary pub-lic/secret key pair and confirms that they are the right size. It then converts them both to to Z85
format and back, then confirms that the binary keys were unchanged by the transition.
Test ZMQ/Protobuf Convenience Functions
1.4.14.1.4.1 Test Send/Receive Creates a ZMQ socket pair and Protobuf message. It then sends/receives the Protobuf message using the created convenience functions and confirms that
the message is unchanged by the transition.
Caster Initializes
1.4.14.1.5.1 Create and Destroy Caster Creates/initializes a caster object to ensure cre-ation/deletion completes without error.
Test Stream Registration and Caster Transceiver
1.4.14.1.6.1 Send a Query, Send/Receive Update Initializes a caster, creates a transceiver, registers a unauthenticated base station stream and connected receiver looking for the stream. A
query is then sent and confirms that the registered base station is in the returned results. A update is
then sent via the base station and it is confirmed to be received unaltered at the connected receiver.
1.4.14.1.6.2 Register a Official Authenticated Stream Initializes a caster, creates a transceiver, registers a authenticated base station stream and connected receiver looking for the stream. A query
1.4. IMPLEMENTATION CHAPTER 1. PYLON GPS
Test Simple Proxying
1.4.14.1.7.1 Build Two Casters, Add Stream to First Caster, Proxy Second to First, and Add Second Stream to First Caster, Then Send/Receive Messages Creates two casters and ensures that if one proxies the other, messages will be forwarded correctly.
Test Transceiver
1.4.14.1.8.1 Ping Pong Updates Across Many Different Receivers/Senders This test makes a series of connected message senders and receivers. It creates chain of transceiver objects (zmq pub sender→zmq pub receiver→file data sender→file data reciever→tcp data sender→tcp
data receiver ) and forwards a message through the chain to make sure all the links work.
Capacity Testing
PylonGPS 2.0 was designed to be extremely scalable via proxying. Despite that, it is worthwhile to ensure that the system can work in a real world application. As part of this practical testing, a Pylon
GPS 2.0 caster was deployed on a $5 per month Digital Ocean hosted virtual machine and subjected
to various degrees of load.
One of the primary considerations was how many base stations a single caster could handle
before it became overwhelmed. This was tested by creating processes which simulated a number
of connecting base stations (registering and sending a constant stream of updates). For practical reasons, it was found best to limit each process to make only 100 fake basestations each. These fake
basestations where then created on nano instances in Amazonâ ˘A ´Zs Web Services framework and
directed to connect to the Digital Ocean hosted caster.
Initial load testing indicated that the system had difficulties handling more than 400 connecting
fake base stations (4 Amazon instances each simulating 100 basestations streaming 1 Kb updates once per second). The underlying cause for this performance was discovered to be the per process file
descriptors limit of the Casterâ ˘A ´Zs Ubuntu Linux operating system. The per process file descriptor
limit was able to be raised by adding two lines to the "/etc/security/limits.conf" file. Once this change had been completed, the caster was able to handle up to 7000 fake basestations and was
only limited by the number of Amazon instances that could be rented for testing (max 70).
As far as the author is aware, there are not more than 7000 differential GPS base stations in the world. This indicates that demand could be satisfied for the foreseeable future by provisioning a
single well provisioned node. PylonGPS 2.0 was able to handle 7000 base stations for $5 per month,
1.5. CONCLUSIONS CHAPTER 1. PYLON GPS
updates in the world.
Alpha Testing
According to software development practice, Pylon GPS is ready for alpha testing. It needs a number
of people unfamiliar with its inner workings to try to use it and report what doesn’t work. It is likely
that there are bugs in the code, but it seems fair to say that as much testing as one person reasonably be expected to do has already been done.
Conclusions
Pylon GPS was created to solve several technical challenges that made it difficult for differential GPS to be used low cost robotics applications. The software that has been crafted seems to solve these
problems while offering a much more fluid and intuitive user experience than any of the existing
CHAPTER
2
HYPERCHORD
Introduction
The current intersection of the Internet of Things, inexpensive computing via devices such as the Raspberry Pi 3, cheap aerial drones and Deep Learning implies that the field of robotics is primed
to rapidly move forward. The concept of Robotics as a Service enables the development of business models that can develop these technologies to generate large amounts of revenue (Starship is a
good example of this concept in practice). It seems probable that we will see the deployment of large
fleets of robots operating in public spaces and moving between diverse sets of work environments. While this development is likely to bring many positive changes to the economy, it does pose
some unique challenges. So far, computer security breaches have leaked private information, allowed
the theft of financial assets and destruction of data. We are now entering a time where a security break could allow the theft of physical assets (ordering robots to load themselves on a van) and the
destruction/manipulation of physical objects as well as people. This change has the potential to
move computer hacking from a problem to something that is potentially life threatening. In the face of this challenge, solutions are needed that will allow us to control large numbers of robots in a
robust and secure manner.
2.2. PEER TO PEER NETWORKS OVERVIEW CHAPTER 2. HYPERCHORD
of the Society of Machines communication architecture. Its purpose is to allow members of a peer group to find each other, divide responsibility for digital resources between them and prevent
outsiders from being able to join/query the members of the group. In practice, it allows an individual
or organization to implement a robust distributed hash table using their own devices, prevents unauthorized nodes from participating in the network and is robust in presence of a limited number
of hacked/corrupted nodes.
In the context of Society of Machines, the Hyperchord system would be used to distribute tags/address pairs associated with information streams among the "more secure" nodes of the
network and answer queries regarding which nodes to ask about particular information stream
types. This allows the formation of a distributed database which can answer SQL like queries in the face of dropped or corrupted nodes.
Peer to Peer Networks Overview
There are two main flavors of peer to peer systems currently active: structured and unstructured.
Structured systems use formal structure and maintain routing tables (usually sending periodic
messages to keep the tables up to date). Their strength is that they have proved time bounds for lookup of any resource in the network. Unstructured systems do not impose structure on their
routing tables and use flooding variants to locate content. Their strength is that they are quite
resilient to peer churn, can support complex queries (rather than having to have an exact match) and locate popular content quickly. The downside of unstructured systems is that they can be very
slow (and sometimes fail) when they try to locate unpopular resources[She10].
Chord
Chord is one of the first distributed hash table based structured systems to be developed[She10,
p. 230]. It focuses on providing a single service: Given a resource identifier (key), return the IP of
the node that has it[Sto03]. The Chord system does not require any central servers and allows any resource in the network to be found in O(log(n)) hops, where n is the number of peers. It uses a
key ring with consistent hashing so that any key can be mapped onto a node and which node is
associated with which key doesn’t change significantly as nodes enter and leave. Chord maintains routing tables on each node of size log(n) where n is the number of nodes in the system. It degrades
gracefully when route table information is out of date and all queries will eventually find their
2.2. PEER TO PEER NETWORKS OVERVIEW CHAPTER 2. HYPERCHORD
less than it in the ring), which can lead to unbalanced load with uniform distribution of resources (each node receiving a maximum of (1+O(log(n))*K/N keys, where K is the total number of keys [Sto03, p. 4]). This can be mitigated by each node hosting one or more virtual nodes, at the cost of increased hop length (by increasing n).
Nodes are informed if the range of keys they are responsible for changes (due to new nodes
joining or old nodes leaving). Data stored in the Chord network can be replicated by storing it with
multiple keys (such as the original key and offset variants). Many of the bounds provided with Chord assume a random distribution of keys and resources. However, the authors point out that these
bounds could be violated by an adversary picking a set of keys which all map to the same node [Sto03, p. 4]. Queries are answered by determining the entry in querying node’s routing table which is closest to the required hash value and then recursively using the found routing tables to find nodes
closer to the requested value until the proper node is found (exponentially reducing the distance) [Sto03, p. 6]. Each node runs a periodic check to ensure that its routing tables are up to date. Both analysis and simulation show Chord to be resilient against considerable peer churn[Sto03, p. 9-12].
Chord is of particular interest as a base system for robot swarms because it is relatively simple,
has been extensively analyzed and has guaranteed log(n) query run times. It represents a good mix of slow routing table/hop growth and low traffic. Its weakness is that it ignores network topology and
generally requires a several hops for a query to reach its destination. This translates to somewhat long network latencies, which several other proposals seek to address (almost always with the cost
of faster routing table growth).
OneHop
Some recent work has focused on systems that have O(n) growth routing tables and traffic but approximately constant lookup times. The assumption is that memory for routing tables is relatively
inexpensive (on hosts) and most systems only grow so large. A good example of this sort of system is
OneHop, which aims to deliver single hop lookups with high probability. OneHop is built on top of the Chord framework, but each node maintains a routing table with each of the other nodes [Fon09, p .1-2]. To maintain accuracy of routing tables, each node sends keep alive messages to its predecessors and successors (similar to the Chord stabilization algorithm) and transmits updates to the system using dissemination trees when something changes[Fon09, p .2]. The dissemination
trees are formed by dividing the Chord address space into k pieces and choosing a "slice leader" to be responsible for aggregating event updates that happen in that region. Each formed "slice"
is further subdivided into a certain number of "units", which have "unit leaders" similar to slice
2.2. PEER TO PEER NETWORKS OVERVIEW CHAPTER 2. HYPERCHORD
leader, enabling their slice leader to aggregate multiple updates into one message[Fon09, p .3]. As slice leaders require more bandwidth and computation than normal nodes, OneHop allows for the
selection of supernodes to be slice leaders[Fon09, p .3-4]. Bandwidth requirements for supernodes
scale linearly with the number of peers, making it required to use more powerful supernodes as the system scales (35 kbps upload with 100,000 nodes and 350 kbps upload with 1,000,000 nodes)[Fon09,
p .4]. OneHop is only practical for 300,000 to 1,000,000 nodes with its original architecture, but could
be scaled to the 10,000,000 range with a hierarchy based architecture ("TwoHop")[Fon09, p .6]. As the number of nodes increases past the number TwoHop can support, log(n) growth schemes such
as Chord begin to have similar latencies[Fon09, p .6].
In some ways, OneHop seems a step backward from log(n) based systems. It requires a lot more maintenance traffic, much more memory and it can’t scale much past 1,000,000 nodes without
severe changes. Its main advantage is that it offers much faster lookup times. For small systems,
it will outperform something like Chord but linearly increasing traffic requirements make it seem impractical for any system that has the potential to grow. In addition, systems like Chord also have
the ability to reduce the expected number of hops for a query. By increasing the number of entries
in the Chord routing table to O(d*log(n)), the expected number of hops could be reduced to O(log base(d+1) (n))[Sto03, p. 14].
EpiChord
EpiChord is another attempt to build on the Chord framework to achieve O(1) lookup latency. EpiChord also removes the O(log(n)) restriction on routing tables, but attempts to restrict the
amount of additional traffic required to keep the routing tables current (perhaps more successfully
than OneHop)[Leo06, p. 1-2]. In contrast to OneHop, EpiChord relies mainly on passive observation of lookup traffic and piggybacking addition information onto query replies to maintain routing
tables[Leo06, p. 2]. Parallel lookups are used to reduce latency and assist in generating traffic
to maintain routing tables. Despite issuing multiple queries for each lookup, EpiChord actually generates comparable or lower amounts of network traffic compared to Chord due to shorter path
length[Leo06, p. 2]. Since messages inform EpiChord nodes about the characteristics of their sender,
new nodes automatically inform their predecessors when they request a copy of the predecessor routing table. The ring is also maintained by sending keep alive messages to their immediate
neighbors in the Chord address space[Leo06, p. 4-5]. The proportion of routing entries that are updated goes down as the number of nodes increase, but is still at least 25% with 1,000,000 nodes
(depending on assumptions made about traffic patterns)[Leo06, p. 7]. Overall, EpiChord seems to