Current Issues in Software Engineering for Natural Language Processing
Full text
Figure
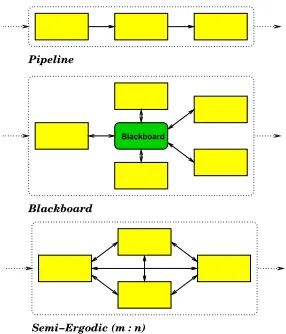
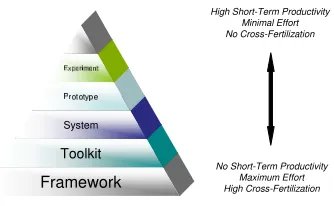
Related documents
10 per cent under controlled drainage and this is attributed to reduce nitrate concentration in soil. water due to increased
a)Consider any set X and any lattice of subsets of X,. We shall always assume, without loss of generality for our purposes, that ,X. The definitions of the following terms are found
Intensified PA counseling supported with an option for monthly thematic meetings with group exercise proved feasible among pregnant women at risk for gestational diabetes and was
In the present work, we demonstrate that carrying out two vaccination programs with successive heterologous vaccines in wild animals from Spanish zoos can be the key to widely pro-
The M method is a design method that introduces the viewpoint of the “M model” into both design and analysis of ideas and analysis. This method supports the derivation
REQUIREMENTS : A Bachelor’s degree/NQF 7 or equivalent qualification in a Health related or Public Health field, At least five (5) years experience at a senior
Past performance is no guarantee of future results and current performance may be higher or lower than the performance shown. This data represents past performance and investors
conventional extrusion), pasta from parboiled rice flours did not reach a peak viscosity but rather 231. exhibited high stabilities during
