Explain How To Find And Removing Web Application Vulnerabilities
With Static Investigate And Data Mining
Bavirisetty Srivalli& M.Sridevi
1M-Tech, Dept. of CSE,Laqshya Institute of Technology and Sciences, Khammam
2HOD, Dept. of CSE,Laqshya Institute of Technology and Sciences, Khammam
Abstract
Yet a monstrously goliath explore exertion on
web application security has been continuing
for over 10 years, the security of web
applications sustains to be a problem. A vital
piece of that dilemma gets from powerlessly
helpless source code, frequently indited in risky
dialects like JAVA. Source code static
examination executes are an answer for
discover susceptibilities, yet they slope to cause
wrong positives, and require impressive
exertion for software engineers to physically
calibrate the code. We investigate the usage of a
combination of strategies to find susceptibilities
in source code with less deceptive positives. We
amalgamate spoil investigation, which discovers
applicant susceptibilities, with information
mining, to forecast the esse of deceptive
positives. [7] This approach collects two
methodologies that are apparently orthogonal:
people coding the savviness about
susceptibilities (for spoil investigation), joined
with the apparently
orthogonal approach of naturally getting that
intellect (with machine learning, for information
mining). Given this upgraded type of
identification, we propose doing programmed
code amendment by embeddings calibrates in
the source code. Our approach was actualized
in the WAP execute, and a trial assessment was
performed with a tremendously giant
arrangement of JAVA applications. Our
actualize discovered 388 susceptibilities in 1.4
million lines of code. Its accuracy and exactness
were around 5% superior to JAVA MinerII's
and 45% superior to Pixy's.
Key words: - Automatic aegis, information
mining, mistaken positives, input approval
susceptibilities, programming security, source
code static investigation, web applications.
1. INTRODUCTION
Since its Web developed from a stage to get to
content and other appearance in the mid 1990s,
the World Wide media to a structure for running
involute web applications. These applications
home-made to cosmically massive scale business
facilities (e.g., Google Docs, Twitter, Face
book). Be that as it may, web applications have
been tormented with security scrapes. For
instance, a current report means an
incrimination of web assaults of around [1].
Debatably, a purpose behind the uncertainty of
web applications is that numerous software
engineers need compatible learnedness about
secure coding, so they leave applications with
defects. Be that as it may, the instruments for
web application security fall in two extremes.
On one hand, there are procedures that set the
software engineer aside, e.g., web application
firewalls and other runtime securities .On the
other hand, there are systems that find
susceptibilities yet put the encumbrance of
abstracting them on the developer, e.g., coal
black box testing and static investigation. This
paper investigates an approach for consequently
forfending web applications while keeping the
developer tuned in. The approach comprises in
breaking down the web application source code
examining for input approval susceptibilities,
and embeddings adjusts in a similar code to
redress these flaws. The software engineer is
kept on the up and up by being authorized to
comprehend where the susceptibilities were
found, and how they were changed. This
approach contributes specifically to the security
of web applications by abstracting
susceptibilities, and in a roundabout way by
giving the developers a chance to gain from
their mix-ups. This last viewpoint is empowered
by embeddings tweaks that take after ordinary
security coding rehearses, so developers can
take in these practices by outwardly seeing the
susceptibilities, and how they were dreamy. [4]
We investigate the use of a novel mixture of
strategies to distinguish this sort of
powerlessness: static examination with
information mining. Static examination is an
effective instrument to discover susceptibilities
in source code, however slopes to report
numerous deceptive positives
(non-susceptibilities) because of its un choose
competency. This difficulty is solidly strenuous
with dialects, for example, JAVA that are
ineptly indited, and not formally assigned.
Thusly, we supplement a type of static
examination, spoil investigation, with the use of
information mining to soothsay the subsistence
of mistaken positives. This arrangement mixes
two apparently disjoint methodologies: people
coding the intelligence about susceptibilities
(for corrupt examination), in blend with
consequently acquiring that awareness (with
directed machine picking up sustaining
information mining). To foretell the subsistence
origination of surveying if the susceptibilities
identified are duplicitous positives using
information mining. To do this appraisal, we
evaluate traits of the code that we saw to be
related with the nearness of mistaken positives,
and use a cumulation of the three best
positioning classifiers to hail each vulnerability
as deceptive positive or not. We investigate the
usage of a few classifiers: ID3 Desultory Forest,
Arbitrary Tree, K-NN, Ingenuous Bayes, Bayes
Net, MLP, SVM, and Logistic Regression.
Additionally, for each helplessness consigned as
incorrect positive, we use an enlistment control
classifier to demonstrate which characteristics
are related with it. We investigate the JRip,
PART, Prism, and Rider enlistment control
classifiers for this objective. Classifiers are
naturally arranged using machine learning
predicated on named weakness data.[8]
Ascertaining that the code amendment is done
accurately requires evaluating that the
susceptibilities are preoccupied, and that the
right disposition of the application is not altered
by the adjusts. We propose using program
change and relapse testing to bear witness to,
separately, that the adjusts work as they are
modified to (blocking threatening information
sources), and that the application stays filling in
not surprisingly (with kind data sources). Notice
that we don't assert that our approach can
redress any discretionary weakness, or to
distinguish it; it can just dress the info approval
susceptibilities it is modified to manage.
2. RELEGATED WORK
2.1Existing System
There is a sizably voluminous corpus of related
work, so we simply condense the principle
ranges by talking about agent papers, while
leaving numerous others unreferenced to
moderate space. Static investigation executes
computerize the evaluating of code, either
source, twofold, or middle of the road. [2] Taint
investigation actualizes like CQUAL and Splint
(both for C code) utilize two qualifiers to
comment on source code: the untainted qualifier
assigns either that a capacity or parameter
returns reliable information (e.g., a purification
work), or a parameter of a capacity requires
dependable information (e.g., mysql_query).
The spoiled qualifier assigns that a capacity or a
parameter returns non-reliable information (e.g.,
capacities that read utilizer input).
2.2Proposed System
This paper investigates an approach for
naturally bulwarking web applications while
keeping the software engineer on the up and up.
The approach comprises in investigating the
web application source code examining for
input approval susceptibilities, and embeddings
The developer is kept on top of it by being
authorized to comprehend where the
susceptibilities were found, and how they were
rectified.[5] This approach contributes
straightforwardly to the security of web
applications by abstracting susceptibilities, and
in a roundabout way by giving the software
engineers a chance to gain from their mix-ups.
This last perspective is empowered by
embeddings tweaks that take after commonplace
security coding rehearses, so developers can
take in these practices by outwardly seeing the
susceptibilities, and how they were
disconnected. We investigate the usage of a
novel amalgamation of strategies to distinguish
this sort of vulnerability: static examination with
information mining. Static examination is a
useful system to discover susceptibilities in
source code, however grades to report numerous
duplicitous positives (non-susceptibilities)
because of its un decidability To foretell the
esse of deceptive positives, we present the novel
origination of surveying if the susceptibilities
identified are duplicitous positives using
information mining. To do this evaluation, we
measure properties of the code that we saw to be
related with the nearness of deceptive positives,
and use an amalgamation of the three best
positioning classifiers to signal each
defenselessness as mistaken positive or not.
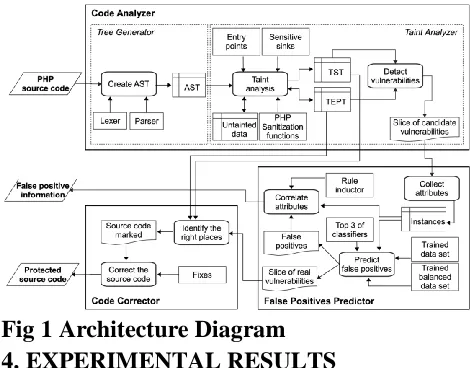
3. IMPLEMENTATION
3.1 Taint Analysis:
The corrupt analyzer is a static investigation
execute that works over an AST induced by a
lexer and a parser, for JAVA 5 for our situation.
In the initiation of the examination, all images
(factors, capacities) are untainted unless they are
an entrance point. The tree ambulates fabricate a
polluted image table (TST) in which each cell is
a program verbal articulation from which we
optate to store up information. Every cell
contains a sub tree of the AST in addition to
some data.[3] For example, for verbalization $x
= $b + $c; the TST cell contains the sub tree of
the AST that speaks to the reliance of $x on $b
and $c. For every image, a few information
things are put away, e.g., the image category,
the line number of the verbalization, and the
taintedness.
3.2 Predicting False Positives:
The static investigation scrape is kenned to be
related to Turing's stopping difficulty, and
subsequently is un decidable for non-pointless
dialects. [6] by and by, this exhaustingness is
explained by making just a fractional
investigation of some dialect develops, driving
static examination executes to be unsound. In
our approach, this difficulty can show up, for
instance, with string control operations. For
a polluted string that is prepared by operations
that arrival a substring or link it with another
string. The two operations can untainted the
string, yet we can't choose with perfect
conviction. We picked to give the string a
chance to be corrupted, which may prompt
duplicitous positives yet not deceptive
negatives.
3.3 Code Correction:
Our approach includes doing code correction
consequently after the recognition of the
susceptibilities is performed by the pollute
analyzer and the information mining part. The
spoil analyzer returns information about the
powerlessness, including its class (e.g., SQLI),
and the defenselessly helpless cut of code. The
code corrector uses these information to
characterize the calibrate to embed, and the
place to embed it. An adjust is a call to a
capacity that sterilizes or approves the
information that achieves the delicate sink.
Purification includes changing the information
to kill risky Meta characters or metadata, on the
off chance that they are available. Approval
includes checking the information, and
executing the delicate sink or not relying upon
this confirmation.
3.4 Testing:
Our calibrates were intended to dodge changing
the (right) mien of the applications. Up until this
point, we saw no cases in which an application
tweaked by WAP started to work erroneously,
or that the adjusts themselves worked
mistakenly. Be that as it may, to increase the
trust in this perception, we propose using
programming testing systems. [9] Testing is
likely the most broadly embraced approach for
finding out programming rightness. The
origination is to apply an arrangement of
experiments (i.e., contributions) to a program to
decide for example if the program by and large
contains blunders, or if adjustments to the
program presented mistakes. This confirmation
is finished by checking if these experiments
cause incorrect or surprising comportment or
yields. We use two programming testing
procedures for doing these two checks,
separately: 1) program transformation, and 2)
relapse testing.
Fig 2 Admin View All Users Page
Fig 3 File Upload Page
Fig 4 Getting Result From Query Page
Fig 5 Admin Attackers Page
Fig 6 File Download Page 5. CONCLUSION
This paper introduces an approach for finding
and reviewing susceptibilities in web
applications, and an execute that actualizes the
approach for PHP projects and information
approval susceptibilities. The approach and the
execute scan for susceptibilities using a
cumulation of two procedures: static source
code investigation, and information mining. [10]
positives using the main 3 machine learning
classifiers, and to legitimize their quality using
an acceptance administer classifier. All
classifiers were separated after a comprehensive
correlation of a few options. It is weighty to take
note of that this blend of identification
procedures can't give altogether revise comes
about. The static examination dilemma is un
decidable, and turning to information mining
can't bypass this un decidability, yet just give
probabilistic outcomes. The actualize redresses
the code by embeddings adjusts, i.e., cleansing
and approval capacities. Testing is used to
confirm if the calibrates truly dynamic the
susceptibilities and don't trade off the (right) air
of the applications. The actualize was explored
different avenues regarding using manufactured
code with susceptibilities embedded
purposefully, and with an extensive number of
open source PHP applications. It was withal
contrasted and two source code examination
actualizes: Pixy, and Java MinerII. This
assessment proposes that the actualize can
distinguish and review the susceptibilities of the
classes it is customized to deal with. It could
discover 388 susceptibilities in 1.4 million lines
of code. Its accuracy and exactness were around
5% superior to anything Java MinerII's, and
45% superior to Pixy's.
6. REFERENCE
[1] Ibéria Medeiros, Nuno Neves, Member,
IEEE, and Miguel Correia, Senior Member,
IEEE, “Detecting and Removing Web
Application Vulnerabilities with Static Analysis
and Data Mining,” IEEE TRANSACTIONS ON
RELIABILITY, VOL. 65, NO. 1, MARCH 2016.
[2] W. Halfond, A. Orso, and P. Manolios,
“WASP: protecting web applications using positive tainting and syntax aware evaluation,”
IEEE Trans. Softw. Eng., vol. 34, no. 1, pp. 65–
81, 2008.
[3] T. Pietraszek and C. V. Berghe, “Defending
against injection attacks through
context-sensitive string evaluation,” in Proc. 8th Int.
Conf. Recent Advances in Intrusion Detection,
2005, pp. 124–145.
[4] X. Wang, C. Pan, P. Liu, and S. Zhu,
“SigFree: A signature-free buffer overflow
attack blocker,” in Proc. 15th USENIX Security
Symp., Aug. 2006, pp. 225–240.
[5] J. Antunes, N. F. Neves, M. Correia, P.
Verissimo, and R. Neves, “Vulnerability
removal with attack injection,” IEEE Trans.
Softw. Eng., vol. 36, no. 3, pp. 357–370, 2010.
[6] R. Banabic and G. Candea, “Fast black-box
testing of system recovery code,” in Proc. 7th
ACM Eur. Conf. Computer Systems, 2012, pp.
281–294.
[7] Y.-W. Huang et al., “Web application
behavior monitoring,” in Proc. 12th Int. Conf.
World Wide Web, 2003, pp. 148–159.
[8] Y.-W. Huang et al., “Securing web
application code by static analysis and runtime
protection,” in Proc. 13th Int. Conf. World Wide
Web, 2004, pp. 40–52.
[9] N. Jovanovic, C. Kruegel, and E. Kirda,
“Precise alias analysis for static detection of
web application vulnerabilities,” inProc.
2006Workshop Programming Languages and
Analysis for Security, Jun. 2006, pp. 27–36.
[10] U. Shankar, K. Talwar, J. S. Foster, and D.
Wagner, “Detecting format string vulnerabilities with type qualifiers,” in Proc. 10th USENIX
Security Symp., Aug. 2001, vol. 10, pp. 16–16.
Authors Profiles
MRS.BAVIRISETTY SRIVALLI
She did B-Tech in Information Technology
from vazir sultan college of engineering
khammam, i got 82% aggregate and pursuing
M-Tech from JNTUH khammam from Laqshya
Institute of Technology and sciences. She has
knowledge about java & .net.
MRS. M. SRI DEVI
She did M-Tech in Computer Science and
Engineering from G.Narayanamma Institute of
Technology and Sciences for Women,
Hyderabad and pursuing Ph.D(Web Security)
from JNTUH, Hyderabad. She has 18 years of
total work experience. Mrs. Sridevi has been
working for LITS since its inception in 2008. As
Head – Department of CSE, She maintains the
facilities in the department and teaches CSE
subjects, like Computer Programming, Java,
Operating Systems, Software Engineering, Data
Structures, DBMS, Information Security, and