Improved Max-Log-MAP Turbo Decoding by
Maximization of Mutual Information Transfer
Holger Claussen
Signals & Systems Group, University of Edinburgh, Edinburgh EH9 3JL, UK Email:[email protected];[email protected]
Hamid Reza Karimi
Bell Laboratories, Lucent Technologies, Swindon SN5 7DJ, UK Email:[email protected]
Bernard Mulgrew
Signals & Systems Group, University of Edinburgh, Edinburgh EH9 3JL, UK Email:[email protected]
Received 1 October 2003; Revised 7 May 2004
The demand for low-cost and low-power decoder chips has resulted in renewed interest in low-complexity decoding algorithms. In this paper, a novel theoretical framework for improving the performance of turbo decoding schemes that use the max-log-MAP algorithm is proposed. This framework is based on the concept of maximizing the transfer of mutual information between the component decoders. The improvements in performance can be achieved by using optimized iteration-dependent correction weights to scale the a priori information at the input of each component decoder. A method for the offline computation of the correction weights is derived. It is shown that a performance which approaches that of a turbo decoder using the optimum MAP algorithm can be achieved, while maintaining the advantages of low complexity and insensitivity to input scaling inherent in the max-log-MAP algorithm. The resulting improvements in convergence of the turbo decoding process and the expedited transfer of mutual information between the component decoders are illustrated via extrinsic information transfer (EXIT) charts.
Keywords and phrases:turbo decoding, max-log-MAP, correction weights, EXIT charts, mutual information.
1. INTRODUCTION
Since the discovery of turbo codes [1], there has been re-newed interest in the field of coding theory, with the aim of approaching the Shannon limit. Furthermore, with the proliferation of wireless mobile devices in recent years, the availability of low-cost and low-power decoder chips is of paramount importance. To this end, several techniques for reducing the complexity of the optimum MAP decoding al-gorithm [2] have been proposed. Examples include the log-MAP, max-log-log-MAP, and SOVA algorithms [3,4,5]. In the case of the latter two algorithms, the reduction in complex-ity is accompanied by some degradation in error correction performance. This issue has been addressed by a number of authors in the context of turbo decoding schemes.
In [6], the performance degradation caused by the SOVA algorithm is attributed to an incorrect scaling of the extrin-sic information, in addition, to nonzero correlation between the intrinsic and extrinsic information at the component
decoder outputs. Performance improvements were demon-strated through the use of correction factors computed as a function of soft-output statistics of the component decoders. The degradation caused by the max-log-MAP algorithm was addressed in [7,8]. Performance gains were achieved by scaling of the extrinsic information at the component de-coder outputs. The value of the scaling factor was derived empirically and is iteration independent.
mitigating the degradations resulting from any suboptimal decoding algorithm should maximize the mutual informa-tion at the outputs of the component decoders. It is shown here that effective maximization of mutual information can be achieved for the max-log-MAP algorithm through scal-ing of a priori information by iteration-specific correction weights. Such scaling essentially corrects the bias in the a pri-ori information that results from the max-log approximation in the previous component decoder.
The offline calculation of the correction weights is de-veloped in Section 4. Sections 2 and 3 provide the neces-sary background, andSection 5presents simulation results demonstrating the performance gains achieved by the pro-posed technique.
It is shown that the performance of a turbo decoder using the max-log-MAP algorithm with the proposed correction scheme approaches that of a turbo decoder using the opti-mum log-MAP or MAP algorithms. This is achieved at the expense of only two additional multiplications per system-atic bit per turbo iteration. Furthermore, the insensitivity of the max-log-MAP algorithm to an arbitrary scaling of its in-put log-likelihood ratios is maintained.
2. TURBO DECODING
Consider the received signal,rt = xt +nt, at the output of an AWGN channel at time instant t, wherext ∈ {+1,−1} is the transmitted binary symbol (corresponding to the en-coded bitbt∈ {1, 0}) andntis zero-mean Gaussian noise of varianceE{n2
t} =N0. Then the log-likelihood ratio (LLR) of the transmitted symbol is defined as
Lxt
=logP
xt=+1
Pxt= −1 = 2
N0rt, (1)
where P{A}represents the probability of event A. We also consider, without loss of generality, a parallel concatenated turbo encoding process of rate 1/3 at the transmitter. This consists of two 1/2 rate recursive systematic convolutional (RSC) encoders separated by an interleaving process, result-ing in transmitted systematic symbol xt,0 and parity
sym-bolsxt,1andxt,2. The corresponding signals at the output of
the channel (input of the decoder) may then be expressed as
Lc(xt,0),Lc(xt,1), andLc(xt,2).
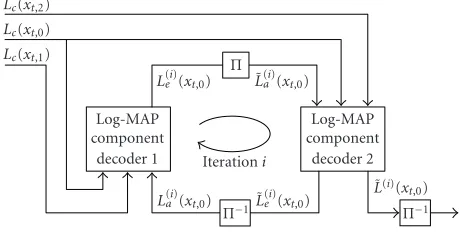
Figure 1depicts the turbo decoding procedure whereby decoding is performed in an iterative manner via two soft-output component decoders, separated by an interleaver, with the objective of improving the estimates ofxt,0from
it-erationito iterationi+ 1. The first decoder generates extrin-sic informationL(ei)(xt,0) on the systematic bits, which then
serves as a priori information ˜L(ai)(xt,0) for the second
decod-ing process. The symbol “∼” denotes interleaved quantities. The maximum a posteriori probability (MAP) algorithm is the optimum strategy for the decoding of RSC codes, as it results in a minimum probability of bit error. However, due to its high computational complexity, the MAP algorithm is usually implemented in the logarithmic domain in the form
Π−1
La(i)(xt,0) L˜(ei)(xt,0)
Π−1 ˜
L(i)(x t,0) Log-MAP
component
decoder 1 Iterationi
Log-MAP component
decoder 2
Le(i)(xt,0) L˜(ai)(xt,0) Π
Lc(xt,1)
Lc(xt,0)
Lc(xt,2)
Figure1: Turbo decoding for parallel concatenated codes.
of the log-MAP or max-log-MAP algorithms. While the for-mer is mathematically equivalent to the MAP algorithm, the latter involves an approximation which results in even lower complexity, albeit at the expense of some degradation in per-formance [3,4,5]. For purposes of brevity, the expressions presented in this paper are written for the first component decoder, with obvious extensions to the second component decoder.
2.1. Log-MAP algorithm
The log-MAP algorithm is the log-domain implementation of the MAP algorithm and operates directly on LLRs. Given the LLRs for the systematic and parity bits as well as a priori LLRs for the systematic bits, the log-MAP algorithm com-putes new LLRs for the systematic bits as described below:
Lxt,0
=log M−1
l=0 exp
¯
αt−1(l) + ¯γ[1]t (l,l) + ¯βt(l)
M−1
l=0 exp
¯
αt−1(l) + ¯γ[0]t (l,l) + ¯βt(l) (2)
=La
xt,0
+Lc
xt,0
+Le
xt,0
, (3)
where ¯γ[tq](l,l) is the logarithm of the probability of a tran-sition from statelto statelof the encoder trellis at time in-stantt, given that the systematic bit takes on valueq∈ {0, 1}
andMis the total number of states in the trellis. Note that the new information at the decoder output regarding the systematic bits is encapsulated in the extrinsic information term Le(xt,0). Coefficients ¯αt(l) and ¯βt(l) are forward- and backward-accumulated metrics at timet. For a data block of
τ systematic bits (x1,0· · ·xτ,0) and the corresponding parity
bits (x1,1· · ·xτ,1), these coefficients are calculated as follows.
Forward Recursion
Initialize ¯α0(l),l =0, 1,. . .,M−1 such that ¯α0(0) =0 and ¯
α0(l)= −∞forl=0. Then
¯
γ[tq](l,l)= 1 2
La
xt,0
+Lc
xt,0
xt[q,0]+Lc
xt,1
xt[,1q]
, (4)
¯
αt(l)=log M−1
l=0
q=0,1
expα¯t−1(l) + ¯γ[tq](l,l)
Backward Recursion
Initializeβτ(l),l =0, 1,. . .,M−1 such that ¯βτ(0) =0 and ¯
βτ(l)= −∞forl=0. Then
¯
βt(l)=log M−1
l=0
q=0,1
expβ¯t+1(l) + ¯γt[+1q](l,l)
, (6)
wherex[t,qn]=2q−1.
Equation (2) can be readily implemented via the Jaco-bian equality log(eδ1+eδ2)=max(δ1,δ2) + log(1 +e−|δ2−δ1|) and using a lookup table to evaluate the correction function log(1 +e−|δ2−δ1|).
2.2. Max-log-MAP algorithm
The complexity of the log-MAP algorithm can be further re-duced by using the max-log approximation log(eδ1+eδ2)≈ max(δ1,δ2) for evaluating (2). Clearly, this results in biased soft outputs and degrades the performance of the decoder. Nevertheless, the max-log-MAP algorithm is often the pre-ferred choice for implementing a MAP decoder since it has the added advantage that its operation is insensitive to a scal-ing of the input LLRs. Usscal-ing the max-log-MAP algorithm, the LLRs for the systematic bits can be calculated as
Lxt,0
≈max l α¯t−1(l
) + ¯γ[1]
t (l,l) + ¯βt(l)
−max l α¯t−1(l
) + ¯γ[0]
t (l,l) + ¯βt(l)
(7)
with
¯
αt(l)≈max
¯
αt−1(l) + ¯γt[q](l,l)
, (8)
¯
βt(l)≈max
¯
βt+1(l) + ¯γ [q]
t+1(l,l)
. (9)
The application of the max-log approximation implies that if the inputs of the decoder are scaled by a certain factor, then ¯αt(l), ¯βt(l), and ¯γ[tq](l,l), and consequently the out-putL(xt,0), are all equally scaled by the same factor. In other
words, the decoding process becomes linear, and as a result, knowledge of the channel noise varianceN0is not required for correct scaling of the decoder inputs. This is in contrast to the case of the log-MAP algorithm, where the decoder output is a nonlinear function of its input, and therefore a reliable estimate ofN0is essential for the computation of LLRs at the decoder inputs.
3. EXIT CHARTS
The performance and convergence behaviour of turbo codes can be analysed using extrinsic information transfer (EXIT) charts, as proposed in [9]. The idea is to visualize the evolu-tion of the mutual informaevolu-tion exchanged between the com-ponent decoders from iteration to iteration. EXIT charts op-erate under the following assumptions. (a) The a priori in-formation is fairly uncorrelated from channel observations. This is valid for large interleaver sizes. (b) The extrinsic in-formationLe(xt,0) has a Gaussian-like distribution, as shown
in [10] for the MAP decoder.
An EXIT chart consists of a pair of curves which repre-sent the mutual information transfer functions of the com-ponent decoders in the turbo process. Each curve is essen-tially a plot of a priori mutual informationIaagainst extrinsic mutual informationIefor the component decoder of interest. Here, the mutual information is a measure of the degree of dependency between the log-likelihood variablesLa(xt,0) or Le(xt,0) and the corresponding transmitted bitxt,0. The
mu-tual information takes on values between 0 for no knowledge and 1 for perfect knowledge of the transmitted bits, depen-dent on the reliability of the likelihood variables. The termsIa andIeare related to the probability density functions (pdfs) ofLa(xt,0) andLe(xt,0), the signal-to-noise ratioEb/N0, and the RSC encoder polynomials. If the component decoders are identical, the two curves are naturally mirror images. The re-quired pdfs can be estimated by generating histogramsp(La) andp(Le) ofLa(xt,0) andLe(xt,0), respectively, for a particular
value ofEb/N0whereEbdenotes the energy per information bit. This can be achieved by applying a priori information modelled asLa(xt,0)=µaxt,0+na,t,t=1,. . .,τ, to the input of a component decoder and observing the output Le(xt,0)
for a coded data block corresponding toτinformation bits. The random variable na,t is zero-mean Gaussian with vari-anceE{n2
a,t} =σa2such thatσa2=2µa. The latter is a require-ment forLa(xt,0) to be an LLR. The mutual informationIa may then be computed as
Ia=
q=−1,1
1 2
+∞
−∞ p
La|xt,0=q
log22p
La|xt,0=q
pa dLa
,
(10)
where pa = p(La|xt,0 = −1) +p(La|xt,0=+1). Similarly,Ie can be computed as
Ie=
q=−1,1
1 2
+∞
−∞ p
Le|xt,0=q
log22p
Le|xt,0=q
pe dLe,
(11)
where pe = p(Le|xt,0 = −1) +p(Le|xt,0 = +1). The
result-ing pair (Ia,Ie) defines one point on the transfer function curve. Different points (for the sameEb/N0) can be obtained by varying the value ofσ2
a.
Having derived the transfer functions, we may now ob-serve the trajectory of mutual information at various itera-tions of an actual turbo decoding process. At each iteration, mutual information is again computed as in (10) and (11), however the a priori LLR,La(xt,0), at the input of the
com-ponent decoder is no longer a modelled random variable but corresponds to the actual extrinsic LLR generated by the pre-vious component decoding operation.
Eb/N0=3 dB
Eb/N0=2 dB
Eb/N0=1 dB
Trajectory of iterative log-MAP turbo decoder atEb/N0=1 dB
0 0.2 0.4 0.6 0.8 1
OutputIeof 2nd decoder becomes inputIato 1st decoder 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Output
Ie
of
1st
d
ec
oder
bec
o
mes
input
Ia
to
2
n
d
d
ec
o
d
er
Figure2: EXIT chart for turbo decoder with log-MAP algorithm.
(Gr,G) = (1 +D+D4, 1 +D+D2+D3+D4), where Gr denotes the recursive feedback polynomial [9,11]. Note that while the mutual information trajectory for the log-MAP al-gorithm inFigure 2fits the predicted transfer function, the trajectory inFigure 3clearly indicates the impact of numer-ical errors resulting from the max-log approximation: the trajectory stalls after only the first iteration and the turbo decoder is unable to converge at the simulated Eb/N0 of 1 dB.
4. MAXIMUM MUTUAL INFORMATION COMBINING
(MMIC)
The poor convergence of the turbo decoder using the max-log-MAP algorithm is due to the accumulating bias in the extrinsic information caused by the max(·) operations. Since extrinsic information is used as a priori information,La(xt,0),
for the next component decoding operation and is com-bined with channel observations Lc(xt,0), as shown in (4),
this bias leads to suboptimal combining proportions in the decoder. To correct this phenomenon, the logarithmic tran-sition probabilities at the ith iteration may be modified as follows:
¯
γt[q](l,l)= 1 2
w(i)
a L(ai)
xt,0
+L(i)
c
xt,0
x[t,0q]+L(ci)
xt,1
x[t,1q]
.
(12)
In other words, the bias of the a priori information can be corrected by scaling it by a factorw(ai)at theith iteration, as depicted inFigure 4. This correction procedure for the max-log-MAP algorithm is far less complex than the correction function employed in the log-MAP algorithm. Furthermore, and perhaps more importantly from a practical point of view, the corrected max-log-MAP algorithm remains insensitive to
Eb/N0=3 dB
Eb/N0=2 dB
Eb/N0=1 dB
Trajectory of iterative max-log-MAP turbo decoder atEb/N0=1 dB
0 0.2 0.4 0.6 0.8 1
OutputIeof 2nd decoder becomes inputIato 1st decoder 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Output
Ie
of
1st
d
ec
oder
bec
o
mes
input
Ia
to
2
n
d
d
ec
o
d
er
Figure3: EXIT chart for turbo decoder with max-log-MAP algo-rithm.
× w(ai)
Π−1
L(ai)(xt,0) ˜L(ei)(xt,0)
Π−1 ˜
L(i)(x t,0) Max-log-MAP
component decoder 1
Max-log-MAP component
decoder 2
Le(i)(xt,0) L˜(ai)(xt,0)
Π ×
˜
w(ai)
Lc(xt,1)
Lc(xt,0)
Lc(xt,2)
Figure4: Turbo decoding with weighting of a priori information.
an arbitrary scaling of the LLR values at its input, thereby eliminating the need to estimate the noise variance at the channel output. From observations of the EXIT charts in the previous section, it is evident that rapid convergence of the turbo process relies on the effective exchange of mutual formation between the component decoders. It may be in-ferred that the optimum value for the weight factorwa(i)is that which maximizes the mutual information between the termζt(i)=w(ai)La(i)(xt,0) +Lc(i)(xt,0) and the vector of
“uncor-rupted” LLRsλ(ti) for each component decoder and at each iterationi. Using vector notation,ζt(i)may be modelled as
ζt(i)= wa(i) 1 L
(i)
a xt,0
L(ci)xt,0
=w(i)TL(ti)
=w(i)Tλ(i)
t +ε
(i)
t
=w(i)Tλ(i)
t +v
(i)
t ,
whereε(ti)represents the contributions of channel noise plus the numerical approximation error inherent in the max-log-MAP algorithm. Given variances
s(ζi)=E
w(i)Tλt(i)+ε(ti)λt(i)+εt(i)Tw(i)
=w(i)TR(i)
λ+εw(i),
(14)
s(i)
v =E
w(i)Tε(i)
t
ε(i)
t T
w(i)
=w(i)TR(i)
ε w(i)
(15)
and modellingvt(i)as a Gaussian random variable, the diff er-ential and conditional entropies ofζt(i)are
hζt(i)
=1
2log
2πes(ζi), (16)
hζt(i)|λ(ti)
=1
2log
2πes(i)
v
. (17)
By definition [12], the mutual information can be written as
Iζt(i);λ(ti)
=hζt(i)
−hζt(i)|λ(ti)
=1
2log
s(ζi) s(vi)
(18)
and the optimized weight factors can then be derived as
w(OPTi) =arg max
w(i) s(ζi) s(vi)
=arg max
w(i)
w(i)TR(i)
λ+εw(i)
w(i)TRε(i)w(i). (19)
Settingz= (Rε(i))T/2w(i), we arrive at the Rayleigh quotient problem [13]
z(OPTi) =arg max
z
zTR(i)
ε −1/2Rλ(i+)ε
R(εi)−T/2z
zTz (20)
with solutions
z(OPTi) =keigmax
Rε(i)−1/2Rλ(i+)εRε(i)−T/2, (21)
w(OPTi) =k
R(εi)−T/2eigmaxR(εi)−1/2R(λi+)εRε(i)−T/2, (22)
where eigmax(A) is the eigenvector ofAcorresponding to its largest eigenvalue. The scalarkis chosen such that the second element ofw(OPTi) , that is, the weight factor ofLc(i)(xt,0), equals
unity. Inspection of (13) to (22) reveals that the weights are functions of the iteration index, the error correcting capabil-ities of the component decoders (i.e., encoder polynomials), and the signal-to-noise ratio. The optimized weights w(OPTi) can be computed or “trained” offline based on time-averaged estimates of correlation matricesR(λi+)εandR(εi)derived over a sufficiently long data block corresponding toτ encoded in-formation bits. Specifically, assuming ergodicity,
R(λi+)ε=EL(ti)
L(ti) T=
lim τ→∞
τ
t=1 L(ti)
L(ti) T
. (23)
Table1: Optimized weight factors.
Decoder 1 Eb/N0=1.0 dB
Decoder 2 (UMTS) Eb/N0=0.7 dB
Iterationi w(ai) w˜a(i) w(ai) w˜a(i)
1 0∗ 0.505 0∗ 0.517
2 0.566 0.602 0.581 0.617 3 0.629 0.656 0.640 0.668 4 0.682 0.712 0.683 0.713 5 0.754 0.814 0.732 0.769 6 0.892 1.020 0.792 0.837
∗No a priori knowledge in iteration 1 for first component decoder.
Furthermore, the vectorλ(ti)of “uncorrupted” LLRs may be written as
λ(i)
t = λ
(i)
a
xt,0
λ(ci)
xt,0
= E
L(ai)xt,0
·xt,0
xt,0 EL(ci)xt,0
·xt,0
xt,0
(24)
so that
R(λi)=Eλ(ti)
λ(i)
t T=
lim τ→∞
ϕ(i)2 ϕ(i)θ(i) ϕ(i)θ(i) θ(i))2
, (25)
where
ϕ(i)=
1
τ
τ
t=1 L(ai)
xt,0
·xt,0,
θ(i)=
1
τ
τ
t=1 L(i)
c
xt,0
·xt,0.
(26)
Finally, assuming that vectors ε(ti) andλ(ti) are uncorre-lated, one may deriveR(εi)asR(λi+)ε−R
(i)
λ . The above training procedure should be performed underEb/N0conditions that are typical at the bit error rate range of interest.
5. SIMULATION RESULTS
Two different turbo encoders are considered at the input of an AWGN channel. The first 1/2 rate (punctured) turbo en-coder consists of two 1/2 rate component RSC codes of mem-ory 4, with polynomials (Gr,G)=(1+D+D4, 1+D+D2+D3+
D4) and an interleaver size of 105 bits. The second 1/2 rate
Eb/N0=3 dB
Eb/N0=2 dB
Eb/N0=1 dB
Trajectory of iterative max-log-MAP decoder with MMIC
atEb/N0=1 dB
0 0.2 0.4 0.6 0.8 1
OutputIeof 2nd decoder becomes inputIato 1st decoder 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Output
Ie
of
1st
d
ec
oder
bec
o
mes
input
Ia
to
2
n
d
d
ec
o
d
er
Figure5: EXIT chart for turbo decoder with max-log-MAP algo-rithm and MMIC.
Max-log-MAP turbo decoder Max-log-MAP turbo decoder + MMIC Log-MAP turbo decoder
0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 1.5
Eb/N0(dB) 10−4
10−3 10−2 10−1
Bi
t
er
ror
ra
te
Figure6: Performance of first turbo decoder (memory 4, 105-bit interleaver).
0.7 dB, respectively. The impact of the combining scheme of (12) on the mutual information trajectory of the first turbo decoder is indicated inFigure 5. In comparison to the orig-inal trajectory ofFigure 3, turbo decoding with MMIC and the max-log-MAP algorithm does not stall and is able to con-verge almost as well as turbo decoding with the log-MAP al-gorithm.
This is achieved at the expense of only two additional multiplications per iteration per systematic bit. Figure 6 shows the BER performance of the first turbo decoder after 6
Max-log-MAP turbo decoder Max-log-MAP turbo decoder + MMIC Log-MAP turbo decoder
0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 1.5
Eb/N0(dB) 10−4
10−3 10−2 10−1
Bi
t
er
ror
ra
te
Figure 7: Performance of the UMTS turbo decoder (memory 3, 5114-bit interleaver).
Max-log-MAP turbo decoder Max-log-MAP turbo decoder + MMIC Log-MAP turbo decoder
0.8 1 1.2 1.4 1.6 1.8 2
Eb/N0(dB) 10−4
10−3 10−2 10−1
Bi
t
er
ror
ra
te
Figure 8: Performance of the UMTS turbo decoder (memory 3, 1000-bit interleaver).
iterations with an interleaver size of 105bits. The results show
that the proposed MMIC scheme significantly improves the performance of the turbo decoder.
6. CONCLUSIONS
The theoretical framework for a maximum mutual informa-tion combining (MMIC) scheme was proposed as a means to improve the performance of turbo decoders whose com-ponent decoders use the max-log-MAP algorithm. The con-vergence behaviour of such turbo decoders was investigated by using extrinsic information transfer (EXIT) charts. The combining scheme is achieved by iteration-specific scaling of the a priori information at the input of each component decoder in order to maximize the transfer of mutual infor-mation to the next component decoder, as suggested by the EXIT charts. The scaling corrects the accumulated bias in-troduced by the max-log approximation. A method for off -line computation of the scaling factors was also described. It was shown that the proposed combining scheme signifi-cantly improves the performance of a turbo decoder using the max-log-MAP algorithm to within 0.05 dB of a turbo de-coder using the optimum log-MAP or MAP algorithms. The improved decoder retains the low complexity and insensi-tivity to input scaling which are inherent advantages of the max-log-MAP algorithm.
ACKNOWLEDGMENT
The authors wish to thank Stephan ten Brink and Magnus Sandell for their valuable input on the subjects of EXIT charts and MAP decoding.
REFERENCES
[1] C. Berrou, A. Glavieux, and P. Thitimajshima, “Near Shannon limit error-correcting coding and decoding: Turbo-codes. 1,” in Proc. IEEE International Conference on Communications (ICC 93), vol. 2, pp. 1064–1070, Geneva, Switzerland, May 1993.
[2] J. Hagenauer, E. Offer, and L. Papke, “Iterative decoding of binary block and convolutional codes,” IEEE Trans. Inform. Theory, vol. 42, no. 2, pp. 429–445, 1996.
[3] B. Vucetic and J. Yuan, Turbo Codes, Kluwer Academic Pub-lishers, Dordrecht, The Netherlands, 2000.
[4] P. Robertson, E. Villebrun, and P. Hoeher, “A comparison of optimal and sub-optimal MAP decoding algorithms operat-ing in the log domain,” inProc. IEEE International Conference on Communications (ICC ’95), vol. 2, pp. 1009–1013, Seattle, Wash, USA, June 1995.
[5] R. H. Morelos-Zaragoza, The Art of Error Correcting Coding, John Wiley & Sons, Chichester, England, 2002.
[6] L. Papke, P. Robertson, and E. Villebrun, “Improved decod-ing with the SOVA in a parallel concatenated (Turbo-code) scheme,” inProc. IEEE International Conference on Communi-cations (ICC ’96), vol. 1, pp. 102–106, Dallas, Tex, USA, June 1996.
[7] J. Vogt and A. Finger, “Improving the max-log-MAP turbo decoder,” IEE Electronics Letters, vol. 36, no. 23, pp. 1937– 1939, 2000.
[8] K. Gracie, S. Crozier, and A. Hunt, “Performance of a low-complexity turbo decoder with a simple early stopping crite-rion implemented on a SHARC processor,” inProc. 6th
Inter-national Mobile Satellite Conference (IMSC ’99), pp. 281–286, Ottawa, Canada, June 1999.
[9] S. ten Brink, “Convergence behavior of iteratively decoded parallel concatenated codes,” IEEE Trans. Commun., vol. 49, no. 10, pp. 1727–1737, 2001.
[10] T. Richardson and R. Urbanke, “The capacity of low-density parity-check codes under message-passing decoding,” IEEE Trans. Inform. Theory, vol. 47, no. 2, pp. 599–618, 2001. [11] M. S. C. Ho, S. S. Pietrobon, and T. Giles, “Improving the
constituent codes of turbo encoders,” inProc. IEEE Global Telecommunications Conference (GLOBECOM ’98), vol. 6, pp. 3525–3529, Sydney, NSW, Australia, November 1998. [12] S. Haykin, Neural Networks, Prentice-Hall, Upper Saddle
River, NJ, USA, 2nd edition, 1999.
[13] G. Strang,Linear Algebra and its Applications, Harcourt Brace Jovanovich Publishers, San Diego, Calif, USA, 1986.
[14] 3GPP, “Ts 25.212 v3.11.0 (2002-09),”Technical Specification Group Radio Access Network, Multiplexing and Channel Cod-ing (FDD), Release 1999.
Holger Claussenreceived his Diploma and
M.Eng. degrees in electronic engineering in 2000 from the University of Applied Sci-ences, Kempten, Germany, and the Univer-sity of Ulster, UK, respectively. He received his Ph.D. degree in signal processing for digital communications from the Univer-sity of Edinburgh, UK, in 2004. Since 2004, he has been with Bell Laboratories, Lucent Technologies, Swindon, UK. His research
interests include information and coding theory, multiple-input multiple-output radio communications, interference cancellation, and iterative detection and decoding algorithms for digital com-munication systems. Dr. Claussen received the Best Paper Award at the 5th European Personal Mobile Communications Conference EPMCC 2003 and the Excellent Paper Award at the 14th IEEE Inter-national Symposium on Personal, Indoor, and Mobile Radio Com-munications PIMRC 2003.
Hamid Reza Karimireceived the B.Eng.
de-gree in electronic engineering in 1988 from the University of Surrey, UK. He later ob-tained the M.S. degree in digital commu-nications in 1989 and the Ph.D. degree in adaptive array signal processing in 1993, both from Imperial College, University of London, UK. In 1994, he joined the startup Signals & Software Ltd., where he was in-volved in the design, development, and
Bernard Mulgrewreceived his B.S. degree in 1979 from Queens University, Belfast. Af-ter graduation, he worked for 4 years as a Development Engineer in the Radar Sys-tems Department, BAE SysSys-tems (formerly Ferranti), Edinburgh. From 1983–1986, he was a Research Associate in the Department of Electronics & Electrical Engineering, the University of Edinburgh, studying the per-formance and design of adaptive filter