An Efficient Resume Extraction Model in
MapReduce Forming Clusters
Ajinkya More, Chetan Doifode, Devendra Bhat, Julie Jeswani, Subhash G. Rathod
B.E. Student, Dept. of Computer Engineering, MMIT, Lohagaon, Pune, India
B.E. Student, Dept. of Computer Engineering, MMIT, Lohagaon, Pune, India
B.E. Student, Dept. of Computer Engineering, MMIT, Lohagaon, Pune, India
B.E. Student, Dept. of Computer Engineering, MMIT, Lohagaon, Pune, India
Professor, Dept. of Computer Engineering, MMIT Lohegaon, Pune, India
ABSTRACT: Automated Resume Extraction and Candidate choice System (ARE & CSS) could be a product which might be best fitted to any organization’s achievement method. The system are going to be strong enough which can mechanically extract the resume content and store it during a structure type at intervals the information Base. Classification rule are going to be run on the profiles to spot profile classes or categories. Conjointly the HR will specify his criteria and conjointly decide the importance level. Because the web grows, quantity of text will increase speedily. This brings the advantage of reaching the knowledge sources during a low-cost and fast method. Keywords are helpful tools as they offer the shortest outline of the document. However they're seldom enclosed within the texts. There are planned ways for machine-controlled keyword extraction. This paper conjointly introduces such a way, that identifies the keywords with their frequencies and positions within the coaching set. It uses Hadoop MapReduce model for mapping and reducing and for expeditiously forming cluster of information or resume information we tend to use genetic rule for at the same time with MapReduce model .So plotter forms blocks and calculate their cost. Then reducer forms economical cluster of resume for extraction of resume as per HRs question.
KEYWORDS:Annotations , Extraction , Structuring Big Data, Clustering, Distributed processing, Hadoop MapReduce, Heuristics, Parallel Genetic Algorithm.
I. INTRODUCTION
The purpose of this project was to make Resume Extractor and Candidate achievement System which can be designed on Hadoop MapReduce model victimization Genetic algorithmic rule .Large enterprises and head-hunters receive many thousands of resumes from job candidates a day. HRs And Managers bear a many resumes manually. Resumes or Profiles square measure unstructured documents and have usually variety of various formats (eg: .doc, .pdf, .txt).As a result manually reviewing multiple profiles could be a terribly time intense processes. The way to make sure you have the suitable Candidate within the right jobs at the correct time. This is often a big downside featured by giant firms nowadays within the market.[11]
Now a day’s several job portals square measure offered however the essential downside in offered system square measure it needed manual efforts for each candidates and Employers. Candidate should give complete info in given text filed and leader additionally must apply several filters to pick the candidate. Even supposing leader has applied several filters he would get thousands of resume even browsing it and choosing candidates is incredibly inefficient and time intense task.
Some pricey extraction systems square measure offered within the market that additionally do the search on keyword basis and has several extraction limitations like Forcing candidates to fill templates and keep change the templates as per job profiles.[12]Not one intelligent tool offered within the market that has advantages of knowledge mining additionally as which can take thought of data gift in social networking.
SCOPE-It is usable in job portals or large organisation handling large amount of resumes on daily basis and need to performs operation on such unstructure data and also helps HRs to find Resumes or CV of candidates matching job profile.
II. LITRATURE SURVEY
1) Genetic clustering for automatic evolution of clusters and application to image classification Authors:SanghamitraBandyopadhyay, UjjwalMaulik
Description:In this article, we have a tendency to propose a GA primarily based bunch technique, GCUK-clustering, which may mechanically Evolve the acceptable bunch of a knowledge set. The body encodes the centres of variety of clusters, whose price might vary. Changed versions of crossover and mutation operators area unit used. Cluster validity index like Davies–Bouldin index is employed for computing the fitness of the chromosomes. The e5ectiveness of the bunch technique is incontestable for many artificial and reality knowledge sets with the quantity of clusters variable from 2 to 6, and therefore the range of dimensions variable from 2 to 9. Each overlapping and non-overlapping knowledge sets area unit thought-about for this purpose.
2)Job performance prediction in a call center using a naive Bayes classifier Author : Mauricio A. Valle , Samuel Varas , Gonzalo A. Ruz
Description:This study presents associate degree approach to predict the performance of sales agents of a call centre dedicated completely to sales and tele-commerce activities. This approach is predicated on a naive Bayesian classifier. the target is to understand what levels of the attributes are indicative of people United Nations agency perform well. A sample of 1037 sales agents was taken throughout the amount between March and Gregorian calendar month of 2009 on campaigns associated with insurance sales and repair pre-paid phone services, to make the naive mathematician network. it's been shown that, socio-demographic attributes don't seem to be appropriate for predicting performance. instead, operational records were accustomed predict production of sales agents, achieving satisfactory results. During this case, the classifier coaching and testing is completed through a stratified denary cross-validation. It classified the instances properly eighty.60% of times, with the proportion of false positives of eighteen.1% for sophistication no (does not win minimum) and twenty.8% for the category affirmative (achieves equal or higher than minimum acceptable). These results recommend that socio-demographic attributes has no prognosticative power on performance, whereas the operational info of the activities of the sale agent will predict the longer term performance of the agent.
3)Using Bayesian networks with rule extraction to infer the risk of weed infestation in a corn-crop Author:Gla´ uciaM.Bressan
Description :This paper describes the modelling of a weed infestation risk abstract thought system that implements a cooperative abstract thought theme supported rules extracted from 2 Bayesian network classifiers. The primary Bayesian classifier infers a categorical variable worth for the weed–crop fight victimisation as input categorical variables for the overall density of weeds and corresponding proportions of slender and deciduous weeds. The inferred categorical variable values for the weed–crop fight alongside 3 alternative categorical variables extracted from calculable maps for the weed seed production and weed coverage square measure then used as input for a second Bayesian network classifier to infer categorical variables values for the chance of infestation. Weed biomass and yield loss information samples square measure wont to learn the likelihood relationship among the nodes of the primary and second Bayesian classifiers in an exceedingly supervised fashion, severally. For comparison functions, 2 varieties of Bayesian network structures square measure thought-about, particularly AN expert-based Bayesian classifier and a naïve mathematician classifier. The abstract thought system cantered on the information interpretation by translating a Bayesian classifier into a group of classification rules. The results obtained for the chance abstract thought in an exceedingly corn-crop field square measure given and mentioned.
4) Improving Metadata Management for Small Files in HDFS Authors: Grant Mackey, SabaSehrish, Jun Wang
utilization of HDFS resources by providing additional economic data management for multi-file, information intensive scientific computing.
5) Big Data Clustering Using Genetic Algorithm On Hadoop Mapreduce Authors: Nivranshu Hans, Sana Mahajan, SN Omkar
Description:This Paper Introduces a completely unique Technique to position GA primarily based agglomeration. For this, we've bespoken Hadoop MapReduce by Implementing a twin section agglomeration. The speed up supported analysis square measure given. In Future, we tend to Hope to enhance Upon the Accuracy and Enhance the Speed Gains.
III. PROPOSED SYSTEM
Candidate has to provide complete information in given text filed and employer also needs to apply many filters to select the candidate. Even though Employer has applied many filters he would get thousands of resume even going through it and selecting candidates was very inefficient and time consuming task. Some costly extraction systems were available in the market that also do the search on keyword basis and has many extraction limitations like forcing candidates to fill templates and keep updating the templates as per job profiles.
A. SYSTEM MODEL
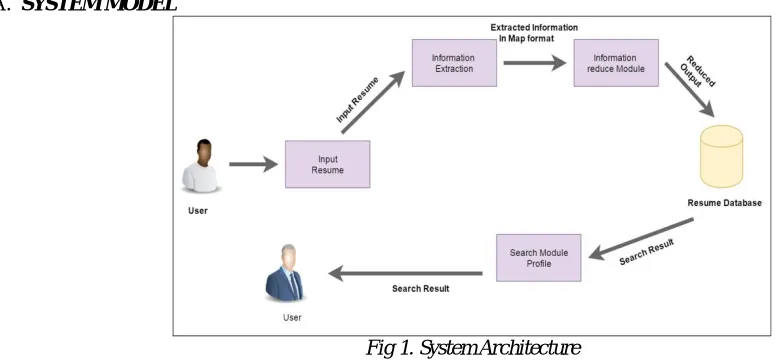
Fig 1. System Architecture
As shown in Fig. Resume extraction system consist large input of resumes and then we use Hadoop MapReduce Model for storing such large resume data and then simultaneously we apply Heuristic genetic algorithm on dataset for forming efficient clusters of dataset.
Information Extraction Mapper:
In MapReduce model Mapper preforms a splitting and mapping of dataset on which MapReduce model has to be implemented. According to size of dataset mapper divides dataset into a fix size data blocks. Each block contains a key and also some values. Also applying genetic algorithm on blocks form by mapper we calculate fitness value of contains in block to form parent and child relationship among contains.
Information Reduction Reducer:
IV. PSEUDO CODE
Algorithm:Generic Local Algorithm
Input of peerpi: F, RF = {R1,R2, . . . , T }, L, Xi,i, and Ni Ad hoc output of peerpi: F( Ki)
Data structure for pi: For each pj∈Ni Xi,j, |Xi,j|, Xj,i,|Xi,j|, last message
Initialization:last message ← −∞
On receiving a message X, |X| from pj:–Xj,i← X, |Xj,i| ← |X| On change in Xi,i, Ni, Ki or |Ki|: call OnChange()
OnChange() For each pj∈Ni:
– If one of the following conditions occur:
– 1. RF (Ki)=T and either Ai,j6= Ki or |Ai,j| 6= |Ki|
– 2. |Wi,j| = 0 and Ai,j6= Ki
– 3. Ai,j6∈ RF (Ki)or Wi,j6∈ RF(Ki)
– then
– – callSendMessage(pj)
SendMessage(pj):If time () − last message ≥ L
– If RF(Ki)= T then the new Xi,jand |Xi,j| are Wi,jand |Wi,j|, respectively
– Otherwise compute new Xi,jand |Xi,j| such that Ai,j∈ R(Ki)and either Wi,j∈ RF(Ki)or |Wi,j| = 0 – last message ← time ()
– Send Xi,j, |Xi,j| to pj Else
– Wait L − (time () − last message) time units and then call On Change ()
V. SIMULATION RESULTS
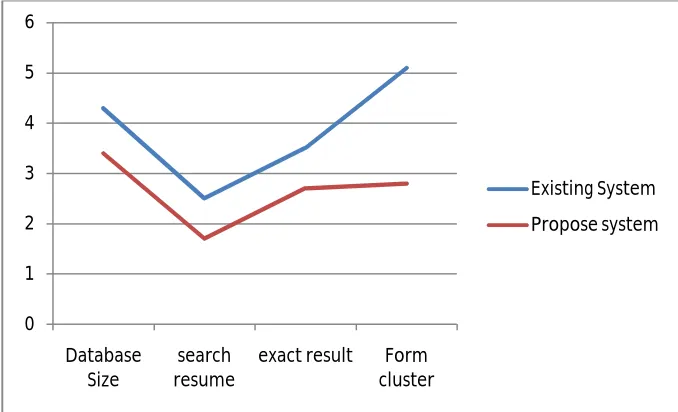
In simulation studies involve the processing of a job portal Fig 2 shows graphical results of comparison existingsystem and propose system on basis of Database size, Search resume, exact result and cluster forming. Existing system takes processing time of 4.3 ms on database and Propose system takes 3.4 ms. Existing system takes search time of 2.5 ms on database and Propose system takes 1.7 ms. Existing system takes 3.5 ms for exact result Propose system takes 2.7 ms. Existing system takes 5.1 ms for forming cluster on database and Propose system takes 2.8 ms.
Fig 2.Comparison between existing system and propose system
0 1 2 3 4 5 6
Database Size
search resume
exact result Form cluster
Existing System
VI.CALCULATIONS
Let I be the input set where I = {I1,I2, I3,I4,I5}
Let RC be the set of Rules & Constraints where RC = {H, S, ECA}
H= (Hard constraints) Where,
H = {H1, H2, H3} S= (Soft Constraints) Where,
S = {S1, S2, S3}
ECA= (Event-Condition-Action}
A. INFORMATION EXTRACTION (IE):
Resume or a Candidate Profile is typically unstructured data. We need to extract information and convert this into standard structured formats so that we can Analyse or query on this data in an effective manner.
B. DATA MAPPINGMODEL (DM):
First we convert the input resumea in different file types (.doc, .pdf) to .txt format. We need to maintain one dimension table for storing all the keywords that may appear in the input resumes. Then we have to traverse thorough the txt file which is obtained after processing the input resume.
Search Profile(SP):
to build and particularly useful for very large data sets. Along with simplicity, Naive Bayes is known to outperform even highly sophisticated classification methods.
Genetic algorithm provides a way of calculating Fitness probability P(c|x) from P(c), P(x) and P(x|c). Look at the equation below
Let F be the set of functions. Where F= {GA, BFOA}
Where GA= {F,S,C,M} and BFOA={Ch,Sw,R,E} Let O be the output set.
Where O={O1, O2, O3, O4, O5}
The inter cluster scatter of a cluster is computed as
=1 − =1 (1)
Here, Ai is the centroid point, is the cluster point, is the cluster size, p is 2 as we are calculating the Euclidian distance.
The intra cluster separation of two centroids and is computed as ,
,= ,− , =1 1 (2)
Here, k is the number of dimension of the data point and value of p is 2. Now the Davies-Bouldin index is
=1 =1(3)
Where Di:
Remove Duplication(RD):
In searched result if any user’s resume duplicated then by finding the most updated resume the result will be sent to the
HR. The updated resume will be selected by date and experienced field.
Output: The Predicted output will be resume extraction
V. ACKNOWLEDGMENT
We might want to thank the analysts and also distributers for making their assets accessible. We additionally appreciative to commentator for their significant recommendations furthermore thank the school powers for giving the obliged base and backing.
VI.CONCLUSION
Here we tend to are providing a singular system that is powerful enough to mechanically extract the resume content and store it in an exceedingly structure kind inside the information Base. This method can create the task of each candidate and 60 minutes Manager easier and quicker. This method avoids the agitated kind filling procedure of the candidates by directly asking the user to transfer solely the resume. The 60 minutes Manager additionally simply have to be compelled to fill his/her criteria rather than manually looking all the resumes.
REFRENCES
[1] Jain, Anil K., M. NarasimhaMurty, and Patrick J. Flynn. "Data clustering: a review." ACM computing surveys (CSUR) 31, no. 3 (1999): 264-323. [2] Bandyopadhyay, Sanghamitra, and UjjwalMaulik. "Genetic clustering for automatic evolution of clusters and application to image classification." Pattern Recognition 35, no. 6 (2002): 1197-1208.
[3] Schaffer, J. David. "Multiple objective optimization with vector evaluated genetic algorithms." In Proceedings of the 1st International Conference on Genetic Algorithms, Pittsburgh, PA, USA, July 1985, pp. 93-100. 1985.
[4] White, Tom. Hadoop: the definitive guide: the definitive guide. " O'Reilly Media, Inc.", 2009.
[5] Alan H., Kim, S., Millard, D.E., WeaL MJ., Hall, W., Lewis, P .R, and Shadbot, N.R (2003). Automatic Ontology-based KnomedgeExtractIOn from Web Documents, IEEE Intelligent Sy&ems, 1 8( 1) (January-February 2(03), pp 1 4-21.
[6] Ben AbdessalemKaraaWahiba Web -based recruiting (2009). A Frame QIk for CVs Handling.SecondIntemational Conference on Web and Infonnation Technologies "ICWIT'09" June 1 2-14 2009, kerkennah Island, Sfax, Tuuisia pp 395-406.
[7] Berio G, M Harzallah (2005). Knowledge Management for Competence Management.Journal of Universal Knowledge Management, vol. 0, no. I. 2005 pp21-28.
[8] Clech Jeremy, Djamel A. Zighed (2003). Data Mining et analyse des CV :une experience et des perspectives. EGC 2003 Lyon, France, 22-24 january 2003 pp 189-200.
[9] Colucci Simona, Tommas:> Di Noia, Eugenio Di Sciascio, Francesco M. Donin MarinaMongiello, Marco Mottola ( 2003). A Fonnal Approach to Ontology-Based Semantic Match of Skills IXscriptions.Joumal of Universal Computer Science, v ol 9, no . 12 (2003), pp 1441-1442.
[10] Cunningham, Dr Hamish and Maynard, Dr Diana and Bontcheva, Dr Kalina and Tablan, Mr Valentin (2002). GATE: A Frame\\QIk and Graphical IXvelopment Environment for Robust NLP Tools and Applications. Proceedings of the 40th Anniversary Meet ing of the Associationfo r Computational Linguistics (ACL'02), Philadelphia US 2002.