An Accelerated Map Reduce Framework
Utilized Network Levitated Merge Mechanism
Vinod Bhosale, Ajit Khutal, Chetan Kurhade, Shubhangi Said
Students, Department of Computer Engineering, Jaihind College of Engineering, Kuran, University of Pune, India
ABSTRACT: Hadoop technology may well be a customary open code document of the Map Reduce programming model for cloud computing. It faces a multiple of issues to achieve the foremost effective performance from the particular systems. These embody a commercial enterprise barrier that delays the size back half, cyclic merges, and disk accesses, and so the dearth of movable solid ground to fully totally different interconnects. To remain up with the increasing volume of information sets, Hadoop to boot wants economical I/O capability from the underlying computer systems to methodology and analyse data.Wehave a tendency to tend to explain Hadoop-A, associate acceleration framework that optimizes Hadoop with plug-in components for fast data movement, overcoming the prevailing limitations. Novel network-levitated merge rule is introduced to merge data whereas not repetition and operation. To boot, a full pipeline is supposed to overlap the shuffle, merge, and reduce phases. Our experimental results show that Hadoop-A significantly hastens data movement in MapReduce and doubles the output of Hadoop. To boot, Hadoop-A significantly reduces disk accesses caused by intermediate data.
KEYWORDS- Hadoop, MapReduce, Network-Levitated Merge, Hadoop Acceleration, Cloud Computing.
I. INTRODUCTION
Preparing substantial datasets has gotten to be essential in development and business correspondence. Separation interest devices to rapidly handle progressively larger measures data and organizations request new answers for data reposting and business data. Brooding once more data handling motors have encountered an unbelievable development. One all told the principle difficulties connected with handling datasets is that the endless base needed to store and procedure the info. Adapting to the gauge high work-burdens would request intensive beforehand interests in framework. Distributed computing displays the possibility of obtaining a huge scale on interest foundation that obliges changing workloads. Typically, the primary system for information crunching was to makeover the info to the procedure hubs that were shared. The dimensions of today's datasets hascomethis pattern, and prompted move the calculation to face live where data are place away. this system is trailed by thought MapReduce executions (e.g. Hadoop). These frameworks expect that data is accessible at the machines that will handle it, as data is place away throughout a circulated file framework, as Associate in Nursing example, GFS or HDFS.To address these crucial issues for Hadoop MapReduce framework, we've designed Accelerated MapReduce, a mobile acceleration framework which is able to advantage of plug-in components for performance improvement and protocol optimizations.Several enhancements unit introduced: 1) a novel rule that allows Reduce Tasks to perform data merging whereas not repetitive merges and any disk accesses; 2) a full pipeline is meant to overlap the shuffle, merge, and shrink phases for Reduce Tasks; and 3) A mobile implementation of Accelerated Map Reduce which is able to support every TCP/ science and remote direct access (RDMA). Since Reduce Tasks unit ready to merge data by staying on high of local disks, we tend to tend to speak to the present new rule as network-levitated merge (NLM).We've administrated Associate in Nursing thorough set of experiments to determine the performance of Hadoop-A.
model it will extends all of its choices in addition add its new choices but unable to feature or perform all form of vast data operation in Acceleration Mechanism.
RELATED WORK
1. Data Mining Using High Performance Data Clouds: Experimental Studies Using Sector and Sphere AUTHORS: Robert Grossman(2009)
We have represented a cloud-based infrastructure designed for data processing giant distributed knowledge sets over clusters connected with high performance wide space networks. Sector/Sphere is opening supply and accessible through supply Forge. We've got used it as a basis for many distributed data processing applications. The infrastructure consists of the arena storage cloud and also the Sphere cipher cloud...
2. MapReduce: Implied Data Processing on Large Clusters AUTHORS: JeffreyDean and Sanjay Ghemawat(2004)
The MapReduce programming model has been successfully used at Google for many entirely totally different functions. We have a tendency to tend to attribute this success to several reasons. First, the model is straightforward to use, even for programmers whereas not experience with parallel and distributed systems, since it hides the most points of parallelization, fault-tolerance, neck of the woods improvement, and merchandise feat. Second, AN outsized kind of problems square measure merely speak ready as MapReduce computations.
3]The Google File System
AUTHORS: Howard Gobioff, and Shun-TakLeung(2003)
The Google file system demonstrates the qualities essential for supporting large-scale process workloads on artefact hardware. Whereas some vogue decisions unit specific to our distinctive setting, many would possibly apply to process tasks of an even magnitude and worth consciousness. We have got an inclination to started by re-examining ancient file system assumptions in light-weight of our current and anticipated application workloads and technological setting. 4]Hierarchical Merge for Scalable MapReduce
Authors:XinyuQueYandong Wang Cong XuWeaken Yu(2016)
Description: we've projected hierarchal Merge as a brand new strategy to effectively improve the performance of MapReduce for data-intensive applications over high speed networks. The hierarchal Merge extends and enhances our previous effort. Our analysis shows that the hierarchal merge are able to do sensible measurability in memory consumption. Our experimental results demonstrate that hierarchal Merge. Improvesthe execution time by up to twentyseventh for Treasury programs compared to the first Hadoop.
II. PROPOSED ALGORITHM
totally different information merge algorithms. EveryMOF supplier andnet Merger area unit rib C++ implementations, with all components following the object-oriented principle.
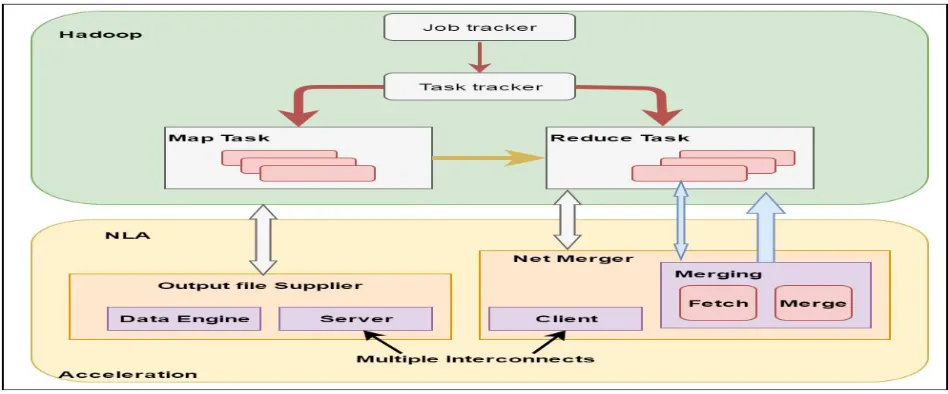
A. System Architecture
1. User TransparentPlug-in:
A primary demand of NLA acceleration is to stay up constant programming and management interfaces for users. To the present end, we've an inclination to vogue the MOF supplier and Net-Merger plug-in as C++ programs which will be launched by Task hunter. A user can favour to vary or disable the acceleration that's controlled by a parameter among the configuration file. With this run-timeplug-in, we've an inclination to create certain that NLA acceleration is user-transparent in a pair of ways.
2.Multithreaded and Componentized MOF provider and web Merger:
MOF supplier contains degree RDMA server that handles fetch requests from reduce Tasks It to boot contains associate degree info engine that manages the index and knowledge files for all MOFs that area unit generated by native Map Tasks. Every half is implemented with multiple threads in MOF supplier. InternetMerger is to boot a multithreaded program. It provides one thread for each Java reduces Task. It to boot contains totally different threads along with degree RDMA shopper that fetches data partitions and a staging thread that uploads data to the Java-side reduce Task.
3. Event-Driven Progress and Coordination:
(To synchronize with Java-side elements, we provide event channels between MOF Supplier/ net Merger plug-in and Hadoop. These event channels are used to coordinate activities and monitor progress for internal elements of MOF supplier and net Merger.All channels area unit implemented through asynchronous loopback sockets which will awaken threads once there unit tasks, and allow them to travel back to sleep once tasks do not appear to be out there. Run-time progress reports and execution statistics area unit collected and keep as a neighbourhood of Hadoop work files. Such work utilities area unit capable of observation and dissecting the execution of Hadoop jobs.
4.Network Levitated Merge:
&let;key, Val&get; combine may be fetched as allowed by the accessible memory. As a result of it fetches solely satiny low quantity of information per section, this formula doesn't got to store or merge segments onto native disks. Rather than merging segments once the quantity of segments is over a threshold, we have a tendency to keep build up the PQ till all headers arrive and square measure integrated. As shortly because the PQ has been established, the merge part starts.The leading &let;key, Val&get; combine are the start purpose of merge operations for individual segments, i.e., the merge purpose. This can be shown in Fig. b. Our formula merges the accessible &let;key, Val&get; pairs within the same means as is completed in Hadoop. Once the PQ is totally established, the foundation of the PQ is that the initial &let;key, Val&get; combine among all segments. We have a tendency to extract the foundation combine because the initial &let;key, Val&get; within the final incorporate knowledge.Then we have a tendency to update the order of PQ supported the primary &let;key, Val&get; pairs of all segments. Ensuing root are the primary &let;key, Val&get; among all remaining segments. It will be extracted once more and hold on to the ultimate incorporate knowledge. Once the accessible knowledge records in a very section square measure depleted, formula will fetch ensuing set of records to resume the merge operation. In fact, our formula perpetually ensures that the attractive of forthcoming records happens at the same time with the merging of accessible records. As shown in Fig. c, the headers of all 3 segments square measure safely merged; additional knowledge records square measure fetched, and therefore the merge point’s square measure settled consequently. Simultaneous knowledge attractive and merging continues till all records square measure incorporate.
Fig.1. System Model
III.MATHEMATICAL MODEL
Input data is spilt into multiple splits Let S be a set of split I
S = {s1, s2, s3...si}
Ti 2 S (ti => Si)
We have, Pair = key, value Value = occurrence in each split
Solution criteria => minimum support count
In Hadoop instead of processing MOF per reduce
Process MOF per core
C = No. of cores
R= No. of Reducers Number of shuffles will be
M * R M= no. of mappersto improve performance M * R should be less
Performance is inversely proportional to M*R No. of disk access = 1 / M*R
RESULTANALYSIS
We Propose an Accelerated map reduce Scheme to avoid serialization barriers in Hadoop processing of Map Reduce . A network levitated merge algorithm Is implemented to Accelerate the processing of Map Reduce Scheme In Hadoop. Network levitated Merge algorithm forms a pipeline of shuffle, merge and reduce phase. It avoids repetitive merge operation of map reduce.Hadoop MapReduce data model takes large data for processing and extracting require result by mapping and reducing dataset.But this model faces some problem such as serialization barrier and large processing time.So implement Network levitated Merge algorithm with MapReduce model for parallel processing on large dataset.Hadoop MapReduce is an open source implementation for processing large dataset and extractingrequired result from such a large datasets. But Hadoop MapReduce faces serializationproblem and some lengthy computations so our propose model is hadoop accelerationto overcome MapReduce model limitations.
MapReduce programming model for cloud computing. However, it faces a number of issues to achieve the best performance from the underlying systems. These include a serialization barrier that delays the reduce phase, repetitive merges, and disk accesses, and the lack of portability to different interconnects. To keep up with the increasing volume of data sets, Hadoop also requires efficient I/O capability from the underlying computer systems to process and analyse data. System describe Hadoop-A, an acceleration framework that optimizes Hadoop with plug-in componentsfor fast data movement, overcoming the existing limitations. A novel network levitated merge algorithm is introduced to merge data without repetition and disk access. In addition, a full pipeline is designed to overlap the shuffle, merge, and reduce phases.
Planning significant datasets has been able to be fundamental being developed and business correspondence. Partition intrigue gadgets to quickly deal with dynamically bigger measures information and associations ask for new responses for information reposting and business information. Agonizing afresh information taking care of engines have experienced a staggering improvement. One everything considered the rule troubles associated with taking care of datasets is that the perpetual base expected to store and system the information. Adjusting to the gage high work-weights would ask for serious in advance interests in system. Conveyed registering shows the likelihood of acquiring a gigantic scale on intrigue establishment that obliges evolving workloads. Commonly, the essential framework for data crunching was to makeover the information to the method centre points that were shared. The measurements of today's datasets has come this example, and incited move the estimation to confront live where information are place away. This framework is trailed by thought Map Reduce executions (e.g. Hadoop).
IV.CONCLUSION
We have examined the look and style ofHadoop’s MapReduce framework in nice detail. Notably, our analysis has targeted on process among prune Tasks. we tend to tend to reveal that there are several vital issues Janus-faced by the current Hadoop implementation, along with its merge formula, its pipeline of shuffle, merge, and prune phases, what is more as its lack of mobility for multiple interconnects. We've designed and implements AN Accelerated MapReduce mechanism as a protractile acceleration framework that canal low plug-in components to cope with of those issues. By introducing a fresh network- levitated formula that merges data whereas not touching disks and coming up with a full pipeline of shuffle, merge, and prune phases for prune Tasks, we've successfully accomplished AN accelerated Hadoop framework, Accelerated MapReduce mechanism. In addition, Accelerated MapReduce mechanism has been designed as a moveable framework which is able to run on every superior RDMA protocol and gift TCP/IP protocol. Our experimental results demonstrate that Accelerated MapReduce mechanism doubles the data method turnout of Hadoop, that Accelerated MapReduce mechanism is capable of effectively utilizing multiple threads to browse data from multiple disks. because of the employment of network-levitate demerge formula, it'll significantly prune disk accesses throughout Hadoop’s shuffling and merging phases ,there by dashing up data movement. What's a lot of, we've quantified the performance edges of network-levitated merge and additionally the RDMA protocol, severally, on the Hadoop MapReduce.
ACKNOWLEDGMENT
We might need to give thanks the analysts and additionally distributers for creating their assets accessible. We have a tendency to in addition appreciative to commentator for his or her vital recommendations what is more give thanks the varsity powers for giving the obligated base and backing.
REFERENCES
[1] J. Dean and S. Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters,” Proc. Sixth Seep. Operating System Design and Implementation (OSDI ’04), pp. 137- 150, Dec. 2004.
[2] Apache Hadoop Project, http://hadoop.apache.org/, 2013.
[3] D. Jiang, B.C. Obi, L. Shi, and S. Wu, “The Performance of MapReduce: An In-Depth Study,” Proc. VLDB Endowment, vol. 3, no. 1, pp. 472-483, 2010.
[4] T. Condi, N. Conway, P. Alvaro, J.M. Heller stein, K. Elmeleegy, and R. Sears, “MapReduce Online,” Proc. Seventh USENIX Sip. Networked Systems Design and Implementation (NSDI), pp. 312-328, Apr. 2010.
[5] M.Zaharias,A. Kaminski, A.D. Joseph, R.H. Katz, and I. Stoics, “ImprovingMapReduce Performance in Heterogeneous Environ- mentis,” Proc. Eighth USENIX Seem. Operating Systems Design and Implementation (OSDI ’08), Dec. 2008.
[6] Infinite band Trade Association, http://www.infinibandta.org. 2013.
[7] R. Recto, P. Culled, D. Garcia, and J. Hill and, “An RDMA Protocol Specification (Version 1.0),” Oct. 2002. [8] Open Fabrics Alliance, http://www.openfabrics.org. 2013.
[9] IP over Infinite Band (IPoIB), http://www.ietf.org/wg/concluded/ ipoib.html, 2013.
[10] Y. Chen, S. Alspeech, and R.H. Katz, “Interactive Query Processing in Big Data Systems: A Cross Industry Study of MapReduce Workloads,” Technical Report UCB/EECS-2012-37, EECS Dept., Univ. of California, Berkeley, Apr. 2012.
[11]A. Singh, L. Liu, and B. Jain, “Purlieus: Locality- Aware Resource Allocation for MapReduce in a Cloud,” Proc. Conf. High Performance Computing Networking, Storage and Analysis, pp. 58:1-58:11, Nov. 2011.
[12] H. Heroand S. Babe, “Profiling, What-If Analysis, and Cost- Based Optimization of MapReduce Programs,” Proc. 37th Int’l Conf. Very Large Data Bases, 2011.