Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 1
3D Object Retrieval
B.Priyanka1, G.Shivasai 2,V.Rohit3
1Assistant Professor: Dept. of ECE, Sreenidhi Institute of Science and Technology, Hyderabad
2UG Scholar: Dept. of ECE, Sreenidhi Institute of Science and Technology, Hyderabad
3UG Scholar: Dept. of ECE, Sreenidhi Institute of Science and Technology, Hyderabad
In the last few years, the various
technologies related to acquiring 3D models
of everyday objects has seen a steady
increase. These models are then being used
in many areas such as, engineering,
museums, cinematics and healthcare. Hench,
there has been an increasing need for 3D
content-based object retrieval and it has
become the focus of many research
activities. One of the important research area
is to find sufficient number of descriptors in
order to capture local and global
characteristics of an object. In this paper, we
propose joint learning of the view-model
relevance for retrieval of 3D objects by
formulating the objects using different
structures of graph such as hyper graphs.
Here the model-based and view-based
relevance are jointly explored in a
graph-based framework.
Index Terms—3D Object Retrieval,
view-based relevance, model-view-based relevance,
Joint Learning.
I. INTRODUCTION
Colossal measures of computerized
insights are being created each day.
Scanners convert the simple/substantial
data into virtual shape; virtual cameras
and camcorders immediately create
virtual data on the generation fragment.
Attributable to a portion of these sight
and sound devices, as of late data is in
all media sorts, comprehensive of
photographs, photographs, sound, and
video, notwithstanding the customary
printed content media kind. Not least
difficult is media records being produced
at a regularly developing rate, it's far
transmitted wherever on the planet as a
result of the broadening of the Internet.
Specialists state that the Internet is the
most vital library that at any point
existed, it's miles anyway also the most
disrupted library ever. Literary record
recovery has finished significant
advancement in the course of the keep
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 2 country of the specialty of motors like
google for media types separated from
content falls far behind their printed
substance partners. Printed ordering of
non-literary media, in spite of the way
that regular exercise, has a few
hindrances. The greatest magnificent
restrictions include the human exertion
required and the issue of portraying
accurately certain homes individuals
take as a privilege even as approaching
the media. Think about how human
indexers would depict the swells on a
sea; these may be selective underneath
conditions comprising of quiet climate
or a tempest. To adapt to this case, we
attempted the Multimedia Analysis and
Retrieval System (MARS) task to give
recovery capacities to rich mixed media
realities. Research in MARS tends to a
few levels including the media capacities
extricated, the recovery models utilized,
question reformulation techniques,
productive execution speed in general
execution and individual interface
issues. The utilization of pix in human
correspondence is scarcely ever new.
The utilization of maps and homes
intends to convey records nearly in all
actuality goes back to pre-roman
occurrences. Be that as it may, the 20 th
century has seen unbelievable increment
in the range, accessibility and hugeness
of photographs in varying backgrounds.
Pictures currently assume a fundamental
job inside the fields as different as cure,
news coverage, publicizing and
showcasing, structure, tutoring and
beguilement. Innovation, inside the state
of creations comprising of photography
and TV, has finished a top notch job in
encouraging the catch and verbal trade
of picture data. Be that as it may, the
genuine motor of imaging
transformation has been the PC, carrying
with it some of procedures for virtual
photograph seize, handling, stockpiling
and transmission. When computerized,
imaging wound up modest and it
immediately entered into areas that have
been customarily depending cautiously
on pictures for discussion, together with
designing, engineering and drug. Photo
libraries, fine art exhibitions and
galleries, as well, began to peer the
benefits of making their accumulations
to be had in virtual structure. The
coming of the World-Wide Web inside
the mid 1990's, empowering clients to
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 3 of media from wherever on this planet,
has given a what's more huge boost to
the misuse of computerized photos. The
assortment of photos on the Web turn
out to be as of late imagined to be
among 10 and 30 million. The technique
for digitization does no longer in itself
make photograph accumulations less
demanding to photograph. Some state of
classifying and ordering is as yet
fundamental to administer important
previews. Three-D object recovery
(3DOR) will turn into a functioning
exploration subject be tallied drawing in
analysts from particular zones, together
with PC inventive and farsighted, and
pics. Over the rest of the quite a while,
despite the fact that net look for isn't
constantly phenomenal for content
pictures and sound recovery the records
upheaval for 3-D realities is still in its
initial life. With the short advancement
of web period, PC equipment, and
programming application, three-d
models have been broadly utilized in
masses of bundles, which envelop pc
pics, PC vision, CAD and restorative
imaging. Adequately and viably recover
three-D demonstrate recovery has pulled
in a deal inquire about intrigue these
days. The three-d models fuse shape and
appearance information, that is difficult
to inquiry the use of best printed
substance to depiction. In appraisal,
content based absolutely three-D shape
recovery systems that utilization
structure and appearance properties of
the 3D models to look for tantamount
styles, beats message fundamentally
based strategies. The 3-D object at
present, the improvement of 3-D
displaying and digitizing advancements
has made the model creating strategy
stacks less muddled. The advantages of
the view-based absolutely approach are
twofold. 1) It does now not require the
express computerized model data, which
makes the methodology tough to
genuine functional bundles. 2) Image
preparing has been researched for some
quite a while. The view-based three-D
demonstrate assessment strategies might
be profited by existing photo preparing
innovations. In this specialized report,
we evaluation related works and cutting
edge advancements in view-based totally
3-d show recovery, particular spotlight
on the different view coordinating plan
and the product of present pack of-terms
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 4 addition of model-based absolutely
systems is they can safeguard the
worldwide spatial data of 3-d protests
For example, while the explorer
uncovers some energizing things and
needs to find equivalent ones inside the
dataset, it is hard to pick up the form
data anyway just take various pix. In this
circumstance, the form based absolutely
systems can't work and least complex
the imagebased methodologies can be
actualized. For model-based system,
CAD is an absolutely basic spot for
utility. Different regions where display
based methods work pleasantly are
delight, including 3-D TV and computer
games, and the clinical field,
comprehensive of tele-restorative cure
and investigation. It is refered to that the
visual data will turn out to be additional
urgent as of late in the above utility.
Both the model-records and take a
gander at-essentially based data can pass
on in valuable points, that could
furthermore improve the general
execution. As of late, extensive
investigations endeavors had been
committed to see fundamentally based
3D variant assessment. View-based
assessment has been utilized in loads of
other mechanical bundles. One preferred
standpoint of view-basically based
techniques is the fantastic adaptability of
the utilization of more than one points of
view for 3-D adaptation outline. That
way, every 3-D object is completely
spoken to by methods for a fixed of 2D
viewpoints. The multi-see coordinating
plays out an indispensable job inside the
view based absolutely 3-d adaptation
recovery. The view-based three-D object
look for can profit by existing obvious
assessment methods, alongside hunt
division, unmistakable adjusting and
following. Detecting the tangible
actualities plays out an imperative job
inside the area of computerized
photograph preparing. In the
improvement territory of mechanical age
tangible measurements is acquired
through the utilization of the
development contraptions especially
Sensors, Satellites, Radar, Camera,
Mobile so on. In any case, since from the
earliest starting point of the human life
Human Visual System (HVS) is handiest
and normally custom-made instrument to
see the tangible records fit as a fiddle
and notwithstanding common shape.
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 5
appraisal strategy assumes an
extraordinary job in picture handling
applications including division, object
acknowledgment, assurance related
systems like Steganographic.
II. CONSTRUCTION OF AN IMAGE-BASED FER SYSTEM
In this phase, we introduce the
view-version joint relevance mastering
technique for 3-D item retrieval. This
method explores each the view records and
the version data of 3-d items. The proposed
approach is composed of three key
components, as proven in Figure 2. Given
the view statistics of 3-d gadgets, the
proposed technique first constructs a hyper
graph to formulate the connection amongst
3D objects with the view connections. Then
with the model statistics, a spatial structure
circular descriptor is extracted from each 3D
model, and the distance among every
three-D models is used to generate a easy graph to
explore the relationship amongst 3-D
models. Finally, the learning the joint
view-version graphs is conducted to estimate the
relevance among 3-d items.
A.
View-based
hyper
graph
generation
Here the view-based totally hyper graph is
generated following the approach and in
short introduced as follows. Let, O =
O_1,O_2,…,O_N denote the n three-D items
inside the dataset, and V_i=
V_i1,V_i2,…,V_(〖in〗_i ) denote the ni
perspectives of the ith 3-d object O_i. In this
component, we aim to explore the relevance
among 3-D object with more than one view
facts.
Given the ni views V_i=
V_i1,V_i2,…,V_(〖in〗_i ) of O_i., we
behavior hierarchical agglomerative
clustering (HAC) to institution those views
into view clusters.
The HAC approach is chosen here because
of that it is able to guaranteethe intracluster
distance among every pair of views cannot
exceed a given threshold. Here the widely
hired Zernike moments are used as the view
functions, which are strong to picture
rotation, scaling and translation and had
been used in lots of 3-D object retrieval
responsibilities.
The 49-D Zernike moments are extracted
from each view of 3D items. With the view
clustering outcomes, one consultant view is
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 6
𝑉𝑖 = {𝑉𝑖1, 𝑉𝑖2, … , 𝑉(〖ℑ〗𝑖)}denote the mi
representative views for𝑂𝑖.. In our
experiments, mi mostly ranges from 5 to 20.
Hyper graph has been used in many
multimedia information retrieval tasks, such
as image retrieval. Hyper graph has shown
its superior on high-order information
representation.
In our work, we propose to employ star
expansion to construct an object hyper graph
with views to formulate the relationship
among 3D objects.
Here we denote the object hyper graph as
𝐺𝐻 = {𝑉𝐻, 𝐸𝐻, 𝑊𝐻}.for the n objects in the
dataset, there are n vertices in GH, where
each vertex represents one 3D object.
The hyper edges are generated as follows.
We anticipate there are totally
n_rrepresentative views for all n objects. We
first calculate the Zernike moments-based
distance among every two perspectives and
the pinnacle K closest perspectives may be
generated for each consultant view. For each
consultant view, one hyper edge is
constructed, which connects the gadgets
with perspectives inside the top K closest
views. In our experiment, K is ready as 10.
Figure 3 shows an example of hyper facet
generation. Generally, n_rhyper edges can
be generated forG_H. The weight of 1 hyper
part e_Hcan be calculated by way of
𝜔𝐻(𝑒) =
1
𝐾∑ 𝑒𝑥𝑝(
−𝑑(𝑣𝑥,𝑣𝑐)2
𝜎𝐻2 ) (1)
Where 𝑣𝑐is the centre view of the hyper
edge, 𝑣𝑥is one of the top K closest view to𝑣𝑐,
d (𝑣𝑥, 𝑣𝑐) is the distance between 𝑣𝑐 and𝑣𝑥,
and 𝜎𝐻is empirically set as the median of all
view pair distances.
Given the object hyper graph𝐺𝐻 =
{𝑉𝐻, 𝐸𝐻, 𝑊𝐻}, the incidence matrix H can be
generated by
ℎ(𝑣𝐻, 𝑒𝐻) = {
1𝑖𝑓𝑉𝐻 ∈ 𝑒𝐻
0𝑖𝑓𝑉𝐻 ∉ 𝑒𝐻 (2)
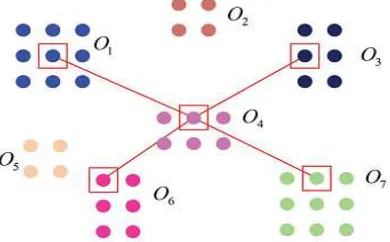
Fig. 3. An illustration of hyper edge construction. In this figure, there are seven objects with representative views. Here one view from O4 is selected as the centre view, and its four closest views are located in the figure, which are from 𝑂1 ,𝑂3,𝑂6 and 𝑂7. Then the
corresponding hyper edge connects𝑂1,𝑂3 ,𝑂4,
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 7
The vertex degree of 𝑉𝐻can be defined as
𝜌(𝑉𝐻) = ∑ 𝜔(𝑒𝐻)ℎ(𝑉𝐻, 𝑒𝐻)(3)
𝑒𝐻∈𝐸𝐻
The edge degree of 𝑒𝐻can be defined as
𝜌(𝑒𝐻) = ∑ ℎ(𝑉𝐻, 𝑒𝐻)(4)
𝑣𝐻∈𝑉𝐻
The vertex degree matrix and the brink
diploma matrix can be denoted by two
diagonal matrices D_v and D_e. In the
constructed hypergraph, while two three-D
gadgets share greater similar views, they can
be related by extra hyperedges with high
weights, that can imply the excessive
correlation amongst those 3-D gadgets.
B. Model-based graph generation
Given the version data of 3-D
gadgets, right here we further explore the
model-primarily based item relationship.
Here the spatial shape round descriptor
(SSCD) is hired because the model feature.
SSCD pursuits to represent the intensity data
of the version surface at the projection
minimum bounding box of the 3D model.
The depth histogram is generated because
the function for the 3-d version. Following,
the bipartite graph matching is conducted to
measure the gap between every two 3-D
models, d_SSCD i.e., (O_(i ),O_j). Here, the
connection among 3-d gadgets is formulated
in a simple item graph shape G = (V, E, W).
Here every vertex in G represents one 3-D
item, i.E., there are n vertices in G. The
weight of an edge e(i, j) in G is calculated
with the aid of the use of the similarity
among two corresponding 3-d objects O_(i )
and O_j as
𝑊(𝑉𝐼, 𝑉𝐽) = 𝑒𝑥𝑝 (
−𝑑𝑆𝑆𝐶𝐷(𝑉𝑖, 𝑉𝐽) 2
𝜎𝑆2 ) (5)
Where 𝑑𝑆𝑆𝐶𝐷(𝑉𝐼, 𝑉𝐽) is distance between
𝑂𝑖and 𝑂𝑗, and 𝜎𝑠is set as the median of all
modal pair distances.
C. Learning on the Joint Graphs
Now we've styles of system of courting
among 3-d items, i.e., view-based totally and
version-primarily based. Here these two
formulations are together explored to
estimate the relevance amongst 3D objects.
In this component, first we introduce the
learning framework when the view-based
and model-based information are seemed
with equal weight, and then we endorse a
collectively mastering framework to learn
the premiere combination weights for every
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 8
1) The initial learning framework:
Here we begin from the gaining knowledge
of framework which regards one of a kind
modalities, i.E., model and examine, as
same. The 3-d item retrieval project can be
formulated as the one-class category
paintings as proven. The fundamental
objective is to examine the ultimate pair
wise object relevance below both the graph
and hyper graph shape. Given the initial
categorised statistics (the query object in our
case), an empirical loss time period may be
added as a constraint for the learning
process
The transductive inference can be
formulated as a regularization as
𝑎𝑟𝑔𝑚𝑖𝑛𝑓{𝛺𝑉(𝑓) + 𝛺𝑀(𝑓) + 𝜇𝑅(𝑓)}(6)
In this method, f is the to-be-learnt relevance
vector; Ω_V (f) is the regularizes term on
the view-primarily based hypergraph shape,
Ω_M (f) is the regularizer time period on the
version-primarily based graph shape, R(f) is
the empirical loss. This objective feature
aims to reduce the empirical loss and the
regularizes on the version-based graph and
the view-based hyper graph simultaneously
that may cause the surest relevance vector f
for retrieval
The two regularizes and the empirical loss
terms are defined as follows.
The view-based hyper graph
regularizes 𝛺𝑉(𝑓)is defined as
𝛺𝑉(𝑓)
=1
2∑ ∑
𝜔𝐻(𝑒𝐻𝑖)ℎ(𝑢, 𝑒𝐻𝑖)ℎ(𝑣, 𝑒𝐻𝑖)
𝜌(𝑒𝐻𝑖)
𝑢,𝑣∈𝑉𝐻 𝑒𝐻
(𝑓(𝑢)
√𝜌(𝑢)
− 𝑓(𝑣)
√𝜌(𝑣))
2
=1
2∑ ∑
𝜔𝐻(𝑒𝐻𝑖)ℎ(𝑢,𝑒𝐻𝑖)ℎ(𝑣,𝑒𝐻𝑖)
𝜌(𝑒𝐻𝑖) 𝑢,𝑣∈𝑉𝐻
𝑒𝐻 (
𝑓2(𝑢)
𝜌(𝑢) − 𝑓(𝑢)𝑓(𝑣)
√𝜌(𝑢)𝜌(𝑣))
=𝑓𝑇(𝐼 −⊝𝑉)𝑓 (7)
where 𝛩𝐻is defined as 𝛩𝐻=
𝐷𝑣
−1
2𝐻𝑊𝐷
𝑒−1𝐻𝑇𝐷𝑣
−1
2. Here we denote 𝛥
𝐻 = 𝐼 −
𝛩𝐻, 𝛺𝑉(𝑓) can be written as
𝛺𝑉(𝑓) = 𝑓𝑇𝛥𝐻𝑓 (8)
The model-based graph regularizer
𝛺𝑀(𝑓)is defined as
𝛺𝑀(𝑓) =
1
2 ∑ 𝜔(𝑒𝑖)
𝑢,𝑣𝜖𝑉
( 𝑓(𝑢)
√𝑑(𝑢)−
𝑓(𝑣)
√𝑑(𝑣))
2
=∑𝑢,𝑣𝜖𝑉𝜔(𝑒𝑖)( 𝑓2(𝑢)
𝜌(𝑢) −
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 9
=𝑓𝑇(𝐼 −⊝𝑆)𝑓 (9)
Where ⊝𝑆= 𝐷
−1
2 𝑊𝐷−1 2⁄ .Here we
denote 𝛥𝑆= 𝐼 −⊝𝑆, 𝛺𝑀(𝑓)can be written as
𝛺𝑀(𝑓) = 𝑓𝑇𝛥𝑠𝑓 (10)
The empirical loss term R (f) is
defined as
R(f) = ‖𝑓 − 𝑦‖2 (11)
Where y is the initial label vector. In the
retrieval process, it is defined as an n × 1
vector, in which only the query is set as 1
and all other components are set as 0.
Now the objective function can be
rewritten as
𝑎𝑟𝑔𝑚𝑖𝑛𝑓{𝑓𝑇𝛥𝐻𝑓 + 𝑓𝑇𝛥𝑠𝑓 + 𝜇‖𝑓 − 𝑦‖2}(12)
f can be solved by
f = (𝐼 +1
𝜆(𝛥𝐻+ 𝛥𝑆)) −1
𝑦 (13)
F is the relevance of all of the items in the
dataset with admire to the question object. A
massive relevance cost suggests excessive
similarity between the object and the
question. The better the corresponding
relevance cost is, the extra similar the two
items are. With the generated object
relevance f, all the objects inside the dataset
may be looked after in a descending order in
step with f.
2) Learning the mixture weights
:We stated that the view records and the
version information may not proportion the
equal impact on 3-d item representation. In
some situations, the view information can be
extra critical, and in some different
instances, the version records may
additionally play an vital function. Under
such circumstances, we similarly examine
the top-rated weights for the view
information and the model data. In this
element, we introduce the studying
framework embedding the combination
weight studying. The goal for the mastering
method is composed of three components,
i.E., the graph/hyper graph shape
regularizes, the empirical loss and the
combination weight regularizes.Here we let
α and β denote the combination weights for
view-based and model-based information
respectively, where α + β = 1. After adding
the l2 norm on the combination weights, the
objective function can be further revised as
𝑎𝑟𝑔𝑚𝑖𝑛𝑓,𝛼,𝛽{𝛼𝑓𝑇𝛥𝐻𝑓 + 𝛽𝑓𝑇𝛥𝑠𝑓 + 𝜇‖𝑓 − 𝑦‖2
+ 𝜂(𝛼2+ 𝛽2)}(14)
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 10 The solotion for the above optimization task
is provided as follows. To solve the above
objective function, we alternatively optimize
f and α/β. We first fix α and β, and optimize
f. Now the objective function changes to
𝑎𝑟𝑔𝑚𝑖𝑛𝑓{𝛼𝑓𝑇𝛥𝐻𝑓 + 𝛽𝑓𝑇𝛥𝑠𝑓
+ 𝜇‖𝑓 − 𝑦‖2}(15)
According to Eq. (13), it can be
solved by
f= (𝐼 +1𝜆(𝛼𝛥𝐻+ 𝛽𝛥𝑆))
−1
𝑦(16)
Then we optimize α/β with fixed f. Here we
employ the Lagrangian method, and the
objective function changes to
𝑎𝑟𝑔𝑚𝑖𝑛𝛼,𝛽{𝛼𝑓𝑇𝛥𝐻𝑓 + 𝛽𝑓𝑇𝛥𝑠𝑓 + 𝜂(𝛼2+ 𝛽2)
+ 𝜉(𝛼 + 𝛽 − 1)}(17)
Solving the above optimization
problem, we can obtain
𝜉 =−𝑓
𝑇𝛥
𝐻𝑓 + 𝑓𝑇𝛥𝑠𝑓
2 − 𝜂(18)
𝛼 =1
2−
𝑓𝑇𝛥𝐻𝑓−𝑓𝑇𝛥𝑠𝑓
4𝜂 (19)
𝛽 =1
2−
𝑓𝑇𝛥𝑆𝑓−𝑓𝑇𝛥𝐻𝑓
4𝜂 (20)
The above opportunity optimization may be
processed under the ideal f price is achieved,
which can be used for the 3-d item retrieval.
With the discovered aggregate weights, the
model-based and look at-primarily based
records can be optimally explored
concurrently and the relevance vector f can
be obtained. The important benefit of the
proposed technique is that it mutually
explores the view statistics and the version
records of three-D gadgets in hyper
graph/graph frameworks for three-D object
Experimental Results
GUI of the proposed work
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 11 After the training, a query image is selected
Performance analysis of proposed work for RGB color space
Performance analysis of proposed work for YCbCr color space
Performance analysis of proposed work for CIELab color space
Performance analysis of proposed work for CIELuv color space
CONCLUSION
50 100 150 200 250 300 350 10 20 30 40 50 60 70 80 90 100 Performnace analysis
--Feature vector size
---R e c o g n it io n r a te R G B
50 100 150 200 250 300 350 10 20 30 40 50 60 70 80 90 Performnace analysis
--Feature vector size
---R e c o g n it io n r a te Y Cb Cr
50 100 150 200 250 300 350
0 10 20 30 40 50 60 70 80 90 Performnace analysis
--Feature vector size
---R e c o g n it io n r a te L a b
50 100 150 200 250 300 350
0 10 20 30 40 50 60 70 80 90 Performnace analysis
--Feature vector size
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 12 In this paper, a hyper-chart investigation
method was proposed by co-ordinating
many hyper diagrams for 3D object
retrieval. The methodology introduced in
this paper organises the various perspectives
of a 3D object into groups depending on
their views. Hyper charts were then applied
by which every vertex got transformed into
an item and angles got converted nto points
of views. It was seen that edges interface
more than one thing in the hyper charts.
Therefore, by changing the amount of views,
various hyper graphs were created.
REFERENCES
[1] A. Del Bimbo and P. Pala.,
"Content-based absolutely recovery of 3D designs,"
ACM Transactions on Multimedia
Computing, Communications, and
Applications, vol. 2, no. 1, pp. 20– 43, 2006.
2] A. Godil, H. Dutagaci, C. Akgul, A.
Axenopoulos, B. Bustos, M. Chaouch, P.
Daras, T. Furuya, S. Kreft, Z. Lian, T.
Napoleon, A. Mademlis, R. Ohbuchi, P. L.
Rosin, B. Sankur, T. Schreck, X. Sun, M.
Tezuka, A. Verroust-Blondet, M. Walter,
and Y. Yemez, "Shrec'09 tune: Generic
structure recovery," in Proceedings of
Eurographics Workshop on 3-D Object
Retrieval, Munich, Germany, 2009.
[3] B. Bustos, D. Keim, D. Saupe, T.
Schreck, and D. Vranic, "Highlight
essentially based likeness look for in 3D
object databases," ACM Computing
Surveys, vol. 37, no. 4, pp. 345– 387, 2005.
[4] C. B¨ohm, S. Berchtold, and D. Keim.
Seeking in high-dimensional zones: Index
frameworks for upgrading the general
execution of sight and sound databases.
ACM Computing Surveys, 33(three):322–
373, 2001.
[5] B. Bustos, D. Keim, D. Saupe, T.
Schreck, and D. Vrani'c. Highlight based
closeness look for in 3-D thing databases.
ACM Computing Surveys, 37(four):345–
387, 2005.
[6] B. Bustos, D. Keim, D. Saupe, T.
Schreck, and D. Vrani'c. A trial adequacy
correlation of strategies for 3D similitude
Available online: https://journals.pen2print.org/index.php/ijr/ P a g e | 13 Libraries, Special issue on Multimedia
Contents and Management in Digital
Libraries, 6(1):39– 54, 2006.
[7] J. W. H. Tangelder and R. C. Veltkamp,
"A review of substance based 3D structure
recovery methods," Multimedia Tools and
Applications, vol. 39, pp. 441– 471, 2008.
[8] Y. Gao, J. Tang, R. Hong, S. Yan, Q.
Dai, N. Zhang, and T. Chua, "Camera
requirement free view-based absolutely 3D
object recovery," IEEE Transactions on
Image Processing, vol. 21, no. 4, 2012.
[9] S. Mahmoudi, M. Benjelloun, and T.
Filali Ansary, "3d objects recovery utilizing
ebb and flow scale space and zernike
minutes," Journal of Pattern Recognition
Research, vol. 6, no. 1, 2011.
[10] A. Ad'an, P. Merch'an, and S.
Salamanca, "3-d scene recovery and
notoriety with power angle pictures," Pattern
Recognition Letters, vol. 32, no. Nine, pp.
1337– 1353, 2011.
[11] Y. Gao, M. Wang, R. Ji, X. Wu, and Q.
Dai, "3d object recovery with hausdorff
remove becoming acquainted with," IEEE
Transactions on Industrial Electronics, vol.
Sixty one, no. 4, pp. 2088– 2098, 2014.
[12] M. Wang, Y. Gao, K. Lu, and Y. Rui,
"View-based discriminative probabilistic
displaying for 3-d object recovery and
notoriety," IEEE Transactions on Image
Processing, 2013.
[13] M. Steinbach, G. Karypis, and V.
Kumar, "A differentiation of report
bunching methodologies," in Proceedings of
KDD Workshop on Text Mining, 2000