An Industry Whitepaper
Contents
Executive Summary ... 1
Introduction to Policy Control and NFV ... 2
Considerations and Challenges ... 3
Maximizing Core Performance ... 3
Core Affinity ... 3
Intelligent Load Balancing ... 4
Load Balancer Options ... 6
DPDK and Core Performance ... 7
Maximizing System Performance ... 7
Amdahl’s Law ... 7
Preserving Core Affinity across Sockets ... 8
Memory Writes and Reads ... 9
Partitioning Functions ... 10
Example: Aggregating Statistics ... 10
Example: Network-Level Traffic Shaping .. 11
Example: Location-Specific Congestion Management ... 11
Conclusions ... 13
Summary of Solution Requirements ... 13
Additional Resources ... 14
Invitation to Provide Feedback ... 15
Executive Summary
Traditionally, the processing demands of policy control (e.g., stateful packet processing, complex decision-making, etc.) required proprietary hardware solutions, but technology
advances mean that virtualization now, or at the very least soon, provides an alternative.
Transitioning from a purpose-built, proprietary hardware
component – one in which a vendor likely controls every aspect – to a virtualized COTS model in which performance is dependent on clock speed and available cores, and in which drivers vary by hardware manufacturer is a formidable challenge.
Vendors who embark on this transition face a number of considerations and must overcome many challenges in order to preserve network policy control functionality in a virtualized environment.
By understanding these considerations and challenges,
communications service providers gain an informed position from which they can effectively evaluate alternatives.
To explore these topics, this paper asks and answers the questions:
How can a solution maximize the performance of each individual core?
How can a solution maximize the performance of the overall system (i.e., of all the cores working together)?
How can a solution effectively coordinate aggregate functions across many cores?
Implementing Policy Control as a Virtual
Network Function: Challenges and
Introduction to Policy Control and NFV
Network policy control (also called policy management) refers to technology that enables the definition and application of business and operational policies in networks. Policy control works by identifying conditions (e.g., subscriber entitlement, current network conditions, data traffic identity, etc.), evaluating decisions (e.g., determining if the network is congested, deciding whether certain traffic constitutes a distributed denial of service attack, etc.), and enforcing actions (e.g., record the usage into a database, decrement from a prepaid wallet, mitigate attack traffic, manage congestion, etc.). Policy control powers many innovative subscriber services, network management actions, and business intelligence (e.g., big data, customer experience management, analytics, etc.) initiatives.
Traditionally, the processing demands of policy control (e.g., stateful packet processing, complex decision-making, etc.) required proprietary hardware solutions, but technology advances mean that virtualization now, or at the very least soon, provides an alternative.
Network functions virtualization (NFV) is a carrier-led effort to move away from proprietary hardware, motivated by desires to reduce costs by dramatically increasing agility and simplifying deployment. In an NFV environment, software applications performing network functions share execution, storage, and network resources on COTS hardware.
By using standard x86 commercial off-the-shelf (COTS) hardware for everything – that is, by running all vendor solutions on the same hardware – an operator needs fewer spare parts, can standardize the provisioning systems, and can simplify their supply chain.
This paper explores some of the challenges and considerations of implementing policy control functions in virtualized environments.
To enable the discussion, it is worthwhile to quickly review some related terminology:
Socket: a physical connector on a motherboard that accepts a single processor chip
Core: a logical execution unit. In a multi-core processor, there are many cores that are each able to execute threads independently.
QuickPath Interconnect (QPI): an Intel-specific point-to-point processor interconnect that allows processors to access each other’s memory
Hyper-threading: an Intel technology that makes a single core appear logically as multiple cores on the same chip (usually as two threads per core)
Hypervisor: software, firmware, or hardware that creates and runs virtual machines
Virtual Machine: an operating system or application environment that is installed on software and imitates dedicated hardware
Bare Metal: a computer without its operating system. In the context of virtualization, ‘running on bare metal’ means installing a solution directly on hardware (i.e., without an operating system to slow things down)
Data Plane Development Kit (DPDK): an API consisting of a collection of C code libraries that live in userland (also known as “user space”). The primary function of DPDK is to memory map hardware into userland, thereby removing the need to copy from kernel to userland and achieving performance increases as a result. DPDK is not, strictly speaking, a virtualization technology, but it is a technology that has significant benefits for virtualization.
Considerations and Challenges
Transitioning from a purpose-built, proprietary hardware component – one in which a vendor likely controls every aspect – to a virtualized COTS model in which performance is dependent on clock speed and available cores, and in which drivers vary by hardware manufacturer is a formidable challenge. An additional degree of complexity comes in when you recognise that the hardware is shared by many vendors simultaneously, thus sizing and capacity of one workload can be dependent on another. Vendors who embark on this transition face a number of considerations and must overcome many challenges in order to preserve network policy control functionality and high performance density in a virtualized environment.
By understanding these considerations and challenges, communications service providers gain an informed position from which they can effectively evaluate alternatives.
The subsections that follow examine key subjects, and seek to answer several questions:
How can a solution maximize the performance of each individual core?
How can a solution maximize the performance of the overall system (i.e., of all the cores working together)?
How can a solution effectively coordinate aggregate functions across many cores?
Maximizing Core Performance
Getting the maximum performance out of each available core provides the building blocks out of which a scalable and efficient complete system is constructed.
In order to achieve the maximum performance, particular conditions must be met and specific problems must be solved.
Core Affinity
To maximize packet-processing performance in multicore and multiprocessor environments, a system must avoid costly memory lookups. The time to access memory varies widely, depending on that memory’s location, and core performance can be severely impacted. For instance, here are different types of memory available to a processor core, listed from fastest to slowest1:
Layer 1 (L1) cache
Layer 2 (L2) cache
Last Layer (LL) cache
Local memory (on-socket RAM)
Remote memory (RAM on a different socket)
Memory access impacts performance in two ways: first, in the actual time it takes to look up and to retrieve something from memory into the processor; second, by causing bottlenecks on the
interconnection paths that link cores and sockets together, which cause cores to wait until the bottleneck is relieved.
1
Actual values (e.g., cycles and time) for these accesses are available online, but vary by processor. For instance, here is a discussion on StackOverflow: http://stackoverflow.com/questions/4087280/approximate-cost-to-access-various-caches-and-main-memory
To maximize packet-processing performance in multiprocessor environments, memory look-ups that use core and socket interconnections must be kept to a minimum.
In the worlds of policy control and packet-processing (whether on proprietary hardware or in network functions virtualization), the only way to completely avoid foreign memory access is to maintain core affinity by ensuring all packets associated with a flow, session, and subscriber are processed by the same core, and memory associated with the flow, session, and subscriber is also bound to the same socket as the core. In this design, each core only needs to access its own dedicated memory cache. Today’s architectures attempt to minimize memory checks (for instance, Intel’s Flow Director
technology on the network interface tries to ensure that all packets from the same flow are assigned to the same processor), but these attempts are insufficient for applications that need to work across flows.
In fact, there is only one way to ensure core affinity, and that is through the use of an intelligent (i.e., session-, flow-, and subscriber-aware) load balancer.2
As an added benefit that will be explored later, ensuring core affinity in a shared-nothing (i.e., no shared state memory) architecture is also an enabler of maximal overall system scalability.
Intelligent Load Balancing
At present, the only way to completely avoid foreign memory access in a virtualized packet-processing application is to ensure that all packets associated with a flow, session, and subscriber are processed by the same core.
To achieve this result, two conditions must be met:
1. There must be an aggregate solution to resolve network asymmetry by ensuring all packets relating to a particular flow, session, and subscriber go to the same virtualized packet-processing system (it is sufficient if the single system is actually made up of smaller, connected, sub-systems)
2. The virtualized packet-processing system must include functionality that specifically directs associated packets to a common processor core
The first requirement is a system-level design, so will not be examined in this paper.3
The second requirement calls for an intelligent load balancer that makes up part of the virtualized solution.
This load balancer is the first point of inspection for incoming packets, and is dedicated to maintaining flow, session and subscriber affinity for maximum element throughput.
The load balancer automatically removes local asymmetry within a packet-processing element by steering packets from the same flow (and session and subscriber) to a single core, and then back out through the appropriate exit port.
Functionally, this is how the load balancer works:
2This topic is explored and explained in great detail in the whitepaper QuickPath Interconnect: Considerations in Packet Processing, which is available at www.sandvine.com
3
…but for those who are interested, the whitepaper Applying Network Policy Control to Asymmetric Traffic: Considerations and Solutions, available at www.sandvine.com, explains how this issue is solved in the physical world of proprietary hardware
1. Incoming packets are first examined to determine whether the traffic even needs to be inspected (i.e., passed to a core). For example, depending on the policy, traffic belonging to certain VLANs may not be inspected, which may be desired if the service provider chooses not to inspect traffic that belongs to a wholesale customer or business customer. Simply
performing this task in the load balancer already achieves performance advantages over equipment that requires core examination of all traffic.
2. For those packets that should be sent to a core, the load balancer creates and relies upon a map that determines which core will process particular flows, sessions, and subscribers, and directs the packets appropriately. This mapping ensures that the same core is always used for all packet-processing relating to a specific flow, session, and subscriber. To preserve
performance, the map must scale by the number of cores in the system, rather than packets per second.
3. Once the core has completed its tasks, the load balancer returns the packet through the appropriate exit path.
The load balancing solution as a whole works as a two-stage pipeline, with the first stage having 100% of the performance needed to perform its task under all circumstances (i.e., inspecting packets to appropriately direct them) and the second stage having a scale-out property to perform the packet processing and policy management.
In essence, the load balancer can be thought of as a Flow Director that is specifically designed for policy control and packet processing applications, and which completely eliminates foreign memory checks and maximizes device throughput.
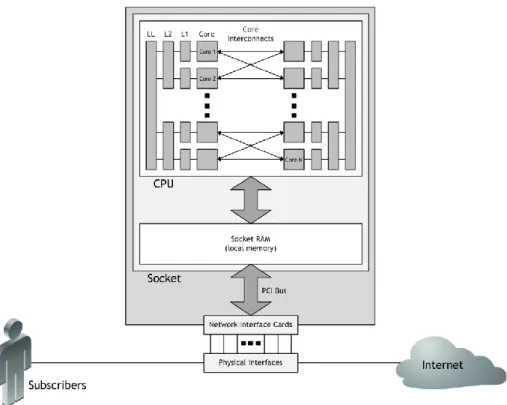
Figure 1 shows a simplified representation of the physical hardware being used by the virtualized solution. This example uses a single socket for simplicity (a configuration with multiple sockets will be examined later).
As a packet travels through the data plane, it hits a physical interface (e.g., 1 GE, 10 GE, 40 GE), and the associated network interface card (NIC) places the packet directly in the socket RAM, from which the CPU can access it for processing.4
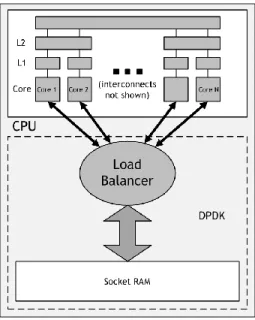
Functionally, this is the point at which the intelligent load balancer comes into play (Figure 2). The load balancer examines the packet in RAM, and directs it to the appropriate core for processing. In this manner, the core that is processing any existing flow always has the state of that flow in its dedicated cache, and foreign memory access is entirely avoided.
Only by fulfilling this intelligent load balancing requirement can a virtualized policy control solution achieve maximum core performance.
Figure 2 – The role of the intelligent load balancer: to avoid latency-inducing foreign memory access, the load balancer must direct packets to the appropriate core
Note, too, that the load balancer process itself consumes some processing capacity, and the amount of consumption varies by implementation.
Load Balancer Options
Broadly, there are two approaches to creating such an intelligent load balancer function: 1. Configure and modify Open vSwitch (OVS)5
2. Purpose-build a proprietary solution
Each approach has advantages and disadvantages, and network operators would do well to thoroughly quiz their solution vendors to understand the implementation.
4Note that while it is possible to have the NIC place the packet directly in a core cache via Intel’s Direct Data I/O
(http://www.intel.com/content/www/us/en/io/direct-data-i-o.html), doing so places the packet into the last layer of cache, because the NIC has no way of placing the packets in the correct L1 or L2 core cache (i.e., the core that will maintain affinity); neither RSS nor Flow Director can fulfill this requirement.
5
Open vSwitch is a production-quality open-source implementation of a distributed virtual multilayer switch, the main purpose of which is to provide a switching stack for hardware virtualization environments. More information is available at
DPDK and Core Performance
The Data Plane Development Kit (DPDK) plays an important role in maximizing the per-core performance by optimizing memory accesses.
In short, DPDK provides a map of the PCI memory so that userland can quickly access packets without needing costly kernel interrupts and many memory copies across the kernel/userland boundary. This approach results in massive performance increases and is a prerequisite for maximizing the performance of any single processing core.
Maximizing System Performance
Maximizing overall system performance demands, as a prerequisite, that the performance of the individual cores is maximized; next, those cores must be made to work together effectively and efficiently.
Combined, these many cores across many sockets are responsible for executing tasks that are simply too large for any one core or socket – and the manner in which the cores are combined has enormous implications on the total system performance.
Amdahl’s Law
When dividing processing between multiple nodes, the architects must decide whether or not any information will be shared between these nodes. Broadly, designs can be considered to be either ‘shared-nothing’ (i.e., literally nothing is shared) or ‘shared-something’ (e.g., subscriber state, 5-tuples6, etc.). The less that is shared, and the less frequently there are references across the shared context, the less locking/waiting will occur, and the greater the overall system performance as instances are added.
In the specific context of system (i.e., horizontal) scaling, a key consideration with regards to information sharing is Amdahl’s Law7, which is a law of diminishing returns in multi-system
architectures. Put simply, this means that if information is shared between processors then the return derived from adding additional processors decreases with each subsequent processor – eventually, adding a new processor will yield no additional processing capacity.
More specifically, each processor added to a system adds less usable power than the previous one; each time the number of processors is doubled, the speedup ratio diminishes as the total throughput heads toward the limit of 1/(1-P).
In contrast, a shared-nothing architecture scales linearly to infinity; that is, each new processor added to a group adds its entire capacity to that of the group.
Implementing a shared-nothing architecture is challenging, but worthwhile, and the benefits are extensive. For instance, sharing nothing means that a core never needs to access another core’s memory, and as a consequence foeign memory look-ups are avoided and per-core performance is maximized.
6 The set of five different values that comprise an Internet flow: source IP address, source port number, destination IP address,
destination port number, protocol. Strictly speaking, ‘connection’ is insufficient because it technically only applies to stateful protocols.
In fact, the shared-nothing architecture is so much better suited to achieving efficient horizontal system scale that this whitepaper considers it by its nature to be the ideal design; alternatives have already been condemned to inefficiency because a shared-something model requires a mesh of communication that increases with the square of the number of processors in the system.
Practically, though, it may not be possible to design a horizontally scalable system with no sharing, so it is important to understand a subtlety of sharing: it is the frequency of sharing that degrades performance, more so than the amount shared, because sharing means waiting. That is, a system that must occasionally share something large will have higher performance than a system that frequency shares small things.
The question then becomes, how does one build a scalable shared-nothing architecture, or at least how does one build something that shares very infrequently?
Preserving Core Affinity across Sockets
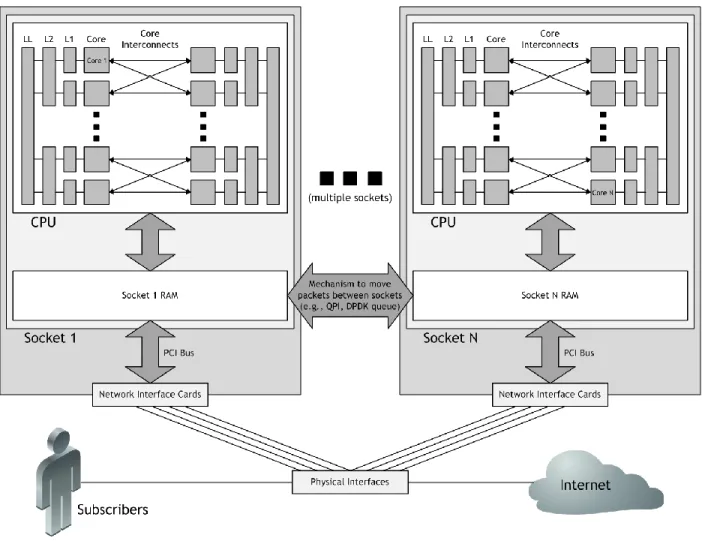
To explore this topic, let’s use Figure 3 as a guide. Figure 3 takes the example from Figure 1 and extends it to a higher-capacity network; now, a single socket is insufficient to provide the required performance, and the system extends to two or more sockets.
The packet follows a familiar path: on-the-wire, through an interface, and into a socket RAM. However, the packet is written into the RAM associated with whatever interface it happened to traverse, and there is no guarantee that this socket houses the particular processing core to which this packet is destined.
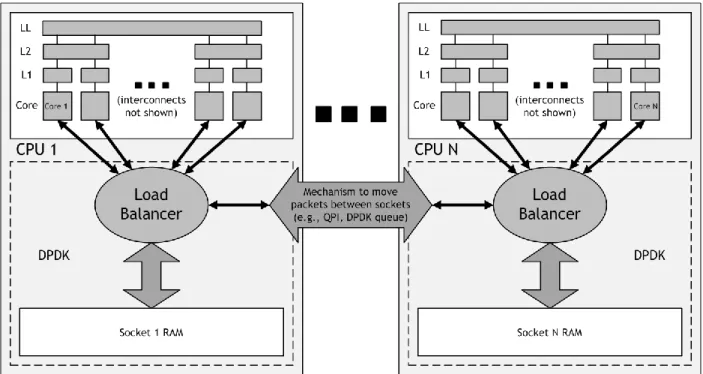
Consequently, in a multi-socket environment the intelligent load balancer must be able to direct a packet to a core on another socket, as depicted in Figure 4.
To facilitate packet movement between sockets there must be a mechanism that allows such transfers. One option, but by no means the only one, is to use the DPDK queue, which is a shared ring. An option that should explicitly be avoided is QuickPath Interconnect (QPI)8.
Figure 4 - The intelligent load balancer in a multi-socket environment
Memory Writes and Reads
An additional consideration when dealing with memory access in a virtualized environment is the cost of reads versus writes. Memory reads are very slow, as a read request is issued and then the processor must wait until the request is fulfilled. Writes, on the other hand, are very fast9: the write is issued and the processor keeps on processing.
This important and often-overlooked disparity can have enormous implications for the overall system performance, particularly when reading or writing across sockets.
The most frequent activity performed in a network policy control system is flow-lookup. Consequently to maximize performance it is imperative to have flow-state memory strictly local to a core.
8For the same reasons discussed in the whitepaper QuickPath Interconnect: Considerations in Packet Processing, available at www.sandvine.com. In short, while QPI is fantastic for some applications, it becomes a massive bottleneck in stateful packet-processing solutions.
Partitioning Functions
When tasks are divided between multiple systems, there is a fundamental issue of determining how to partition those tasks. For instance, in a packet processing application data traffic can be divided between processors based on a wide range of factors (e.g., subscriber IP address, subscriber service plan, application type, geographic location, etc.).
Partitioning also applies to the control plane; element statistics could be partitioned by type, with prepaid usage statistics going to one node, and postpaid usage statistics going to another.
The challenges associated with partitioning can be very complex, particularly when one must determine how to partition domain functionality across many smaller nodes.
Ensuring core affinity means that any per-subscriber policy control (e.g., measurements, billing and charging, policy enforcement) use cases can be fulfilled while preserving maximum performance; in other words, a single core can deal with all the policy control use cases that apply to a single subscriber, without needing to involve another core (either for processing assistance or for memory access).
But in the world of policy control, many use cases exist at an aggregate level. For instance, consider:
A policy that states that, during times of congestion, 50% of available network capacity shall be dedicated to ‘high priority’ applications, 35% to ‘medium priority’ applications, and 15% to ‘low priority’ applications
A policy that must apply congestion management only at locations of the network where congestion is manifesting (e.g., on a particular eNode B)
A policy to measure all YouTube traffic on the network
In each of these examples, applying the policy control requires coordinating between many separate cores – cores that themselves are split across many sockets, and so on.
In the first example, each core must have an idea of the amount of traffic of each priority that the other cores, collectively, are observing. Only with this knowledge can the cores as a set achieve the policy management targets.
In the second example, each core must know which subscribers are currently in a location that is congested, and must coordinate with other cores to collectively manage the congestion to a resolution. In the third example, the statistics from all of the cores have to be aggregated together to create a network-level measurement of YouTube.
In each example, a high-level task is split and shared between many processing elements. By investigating some example use cases, we can discover the challenges that must be overcome to effectively achieve them, and in doing so we can extract some specific solution requirements. Key is that the split is not done at the packet or flow level, but at some more manageable sharing rate.
Example: Aggregating Statistics
Combined, the many cores in the virtualization solution are performing lots of activities, and those activities generate statistics. In a simple example, the statistic itself might be the goal: for instance, a network operator might want to measure the total amount of YouTube traffic on the network. As
another example, the statistics might be a byproduct of other activities, and the operator wants to track general performance metrics.
In either case, the general challenge is that the system must be able to aggregate statistics from many cores, which themselves are distributed across physical sockets. In addition to questioning how these statistics are accurately rolled-up, any network operator investigating virtualization solutions should inquire about the performance impact and potential bottlenecks associated with the aggregation process itself.
Example: Network-Level Traffic Shaping
Consider this simple example: a communications service provider is running a network with 200 Gbps capacity and has a policy that peer-to-peer (P2P) traffic shall not exceed 100 Gbps. When P2P levels rise to this level, shaping policies being to act and enforce the 100 Gbps aggregate limit.
Assuming a per-core throughput of 10 Gbps, the 200 Gbps is split across 20 processing cores. In reality, the P2P traffic is non-uniformly shared across all the processing cores – that is, each core will likely see some of the P2P traffic.
In order to limit the aggregate amount of P2P traffic to 100 Gbps, some conditions must be met:
At any point in time, each core must be aware of the amount of P2P traffic on the network as a whole
To ensure a fair distribution of P2P among the subscriber base, each core must act proportionally
There is no perfect technical solution to this problem.10 Ensuring complete inter-core knowledge imposes overhead inter-core communication demands that are simply not achievable at the throughput rates with which packet processing must manage.
Nevertheless, this use case can be achieved approximately with known (probabilistic accuracy). To hit a particular P2P shaping target, in our case 100 Gbps, at time t, each core must be made aware of the amount of P2P traffic that was on the network at time t-1. Using this knowledge, each core can adjust its own share of P2P so that the overall amount of P2P on the network at time t approximately hits 100 Gbps.
At any infinitely fine point in time, the exact amount of P2P on the network will vary around 100 Gbps, but at practical or meaningful time intervals, the amount of P2P achieves the target.
The precise algorithms used and accuracy achieved vary by vendor, so network operators should be prepared to make detailed inquiries.
Example: Location-Specific Congestion Management
Finding an effective solution to network congestion is an important subject for network operators around the world.11
10Even shaping at the interface hardware level has significant shortcomings, not least of which is that the subscribers who are
impacted by the policy are ‘chosen’ arbitrarily, which could run afoul of network neutrality guidelines for reasonableness and proportionality.
11
The whitepaper Network Congestion Management: Considerations and Techniques, available at www.sandvine.com, explores this topic in detail.
For our example, suppose a mobile operator has detected that a particular eNode B is congested and needs to resolve the congestion by managing the traffic of only those subscribers who are currently using that eNode B.
In addition to subscriber awareness, and real-time knowledge of subscriber location, the solution requires that the many cores in the virtualized solution coordinate their efforts to resolve congestion with minimum subscriber management.
In our example, the group is the set of subscribers on a particular eNode B, but this example can easily be generalized to any ‘group’ of subscribers (e.g., all iPhone subscribers, all subscribers who signed up in the last 6 months, all subscribers who subscribe to an on-deck video service, etc.) and any type of policy enforcement (e.g., well beyond this simple congestion management example).
Conclusions
Transitioning from a purpose-built, proprietary hardware component – one in which a vendor likely controls every aspect – to a virtualized COTS model in which performance is dependent on clock speed and available cores, and in which drivers vary by hardware manufacturer is a formidable challenge. Vendors who embark on this transition face a number of considerations and must overcome many challenges in order to preserve network policy control functionality in a virtualized environment. Getting the maximum performance out of each available core provides the building blocks out of which a scalable and efficient complete system is constructed.
To maximize packet-processing performance in multiprocessor environments, it is necessary to maintain core affinity by ensuring all packets associated with a flow, session, and subscriber are processed by the same core. In this design, each core only needs to access its own dedicated memory cache. Achieving this requirement demands an intelligent load balancer.
When dividing processing between multiple nodes, there are additional considerations. Broadly, designs can be considered to be either ‘shared-nothing’ (i.e., literally nothing is shared) or ‘shared-something’ (e.g., subscriber state, 5-tuples, etc.). The less that is shared, and the less frequently there are references across the shared context, the less locking/waiting will occur, and the greater the overall system performance as instances are added.
Practically, though, it may not be possible to design a horizontally scalable system with no sharing, so it is important to understand a subtlety of sharing: it is the frequency of sharing that degrades performance, more so than the amount shared, because sharing means waiting. That is, a system that must occasionally share something large will have higher performance than a system that frequency shares small things.
To ensure a low frequency of sharing, the intelligent load balancer must be able to direct a packet to a core on another socket, and flow-state memory strictly local to a core (the most frequent activity performed in a network policy control system is flow-lookup).
When tasks are divided between multiple systems, there is a fundamental issue of determining how to partition those tasks. The challenges associated with partitioning can be very complex, particularly when one must determine how to partition domain functionality across many smaller nodes. Key is that the split is not done at the packet or flow level, but at some more manageable sharing rate.
Ensuring core affinity means that any per-subscriber policy control (e.g., measurements, billing and charging, policy enforcement) use cases can be fulfilled while preserving maximum performance, but in the world of policy control, many use cases exist at an aggregate level; for these use cases, applying the policy control requires coordinating between many separate cores – cores that themselves are split across many CPUs and sockets – to efficiently aggregate stats and apply policy control and management that extends beyond the subscriber level.
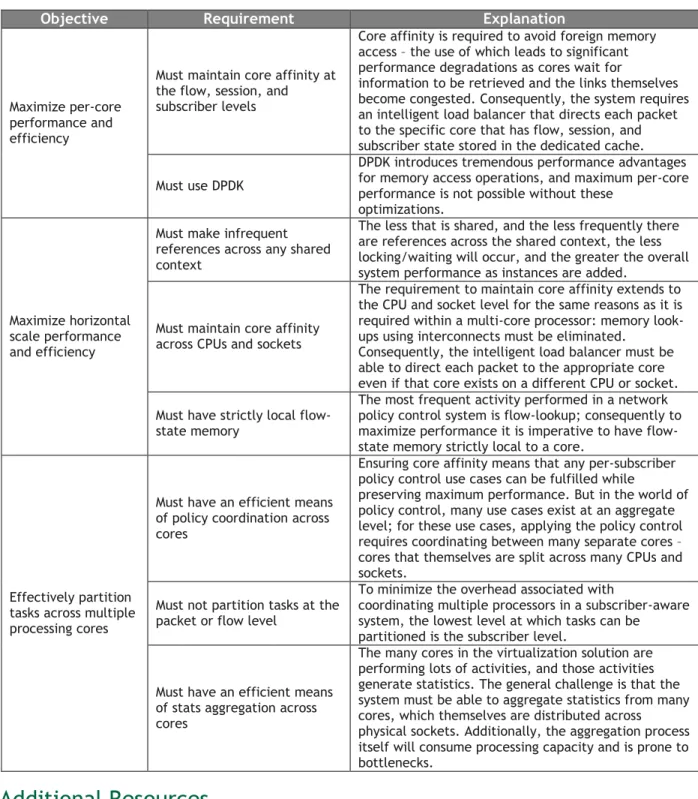
Summary of Solution Requirements
The following table summarizes the minimum requirements to effectively and efficiently implement real-time network policy control as a virtual network function.
Table 1 - Summary of solution requirements
Objective Requirement Explanation
Maximize per-core performance and efficiency
Must maintain core affinity at the flow, session, and subscriber levels
Core affinity is required to avoid foreign memory access – the use of which leads to significant performance degradations as cores wait for
information to be retrieved and the links themselves become congested. Consequently, the system requires an intelligent load balancer that directs each packet to the specific core that has flow, session, and subscriber state stored in the dedicated cache. Must use DPDK
DPDK introduces tremendous performance advantages for memory access operations, and maximum per-core performance is not possible without these
optimizations.
Maximize horizontal scale performance and efficiency
Must make infrequent references across any shared context
The less that is shared, and the less frequently there are references across the shared context, the less locking/waiting will occur, and the greater the overall system performance as instances are added.
Must maintain core affinity across CPUs and sockets
The requirement to maintain core affinity extends to the CPU and socket level for the same reasons as it is required within a multi-core processor: memory look-ups using interconnects must be eliminated.
Consequently, the intelligent load balancer must be able to direct each packet to the appropriate core even if that core exists on a different CPU or socket. Must have strictly local
flow-state memory
The most frequent activity performed in a network policy control system is flow-lookup; consequently to maximize performance it is imperative to have flow-state memory strictly local to a core.
Effectively partition tasks across multiple processing cores
Must have an efficient means of policy coordination across cores
Ensuring core affinity means that any per-subscriber policy control use cases can be fulfilled while
preserving maximum performance. But in the world of policy control, many use cases exist at an aggregate level; for these use cases, applying the policy control requires coordinating between many separate cores – cores that themselves are split across many CPUs and sockets.
Must not partition tasks at the packet or flow level
To minimize the overhead associated with
coordinating multiple processors in a subscriber-aware system, the lowest level at which tasks can be partitioned is the subscriber level.
Must have an efficient means of stats aggregation across cores
The many cores in the virtualization solution are performing lots of activities, and those activities generate statistics. The general challenge is that the system must be able to aggregate statistics from many cores, which themselves are distributed across physical sockets. Additionally, the aggregation process itself will consume processing capacity and is prone to bottlenecks.
Additional Resources
In addition to the resourced linked and footnoted throughout this document, please consider reading
The PTS Virtual Series: Maximizing Virtualization Performance (available at www.sandvine.com) to understand how Sandvine has implemented our network policy control as a highly scalable virtual network function.
Invitation to Provide Feedback
Thank you for taking the time to read this whitepaper. We hope that you found it useful, and that it contributed to a greater understanding of some of the challenges that must be overcome to implement policy control in a virtualized network.
Copyright ©2015 Sandvine Incorporated ULC. Sandvine and the Sandvine logo are registered trademarks of Sandvine Incorporated
European Offices
Sandvine Limited Basingstoke, UK Phone: +44 0 1256 698021
Headquarters
Sandvine Incorporated ULC Waterloo, Ontario Canada Phone: +1 519 880 2600