T
information systems engineering
David P. Silberberg and Glenn E. Mitzel
his article describes the science and technology vision of information systems engi-neering at ApL. information systems transform signal and data representations to high-level abstractions that enable people to perceive and interact with their environments. As information systems become more complex, they are expected to be more flexible, reusable, distributed, and extensible. To achieve these goals, information systems must be constructed upon solid software and system architecture foundations, and also must be created using sound software, cognitive, and information assurance methodologies. since the dimensions of well-engineered information systems are too numerous to describe here, we cannot adequately cover all of their aspects. Therefore, we discuss key paradigms that will guide the future development of information systems at ApL.
WHAT IS INFORMATION SYSTEMS
ENGINEERING?
Information systems are computer-based infrastruc-tures, organizations, personnel, and components that collect, process, store, transmit, display, disseminate, and act on information.1 information systems generally
provide computer-based assistance to people engaging their environment as illustrated in Fig. 1, where engage-ments and environengage-ments are often too complex and dynamic to be handled manually.
complex, dynamic engagements and environments require people to analyze and draw conclusions from an abstracted representation of the world, which enables them to make discrete decisions to achieve a desired effect in the world commensurate with their roles, tasks, and capabilities. The abstraction is sometimes portrayed as a hierarchy (Fig. 2) known as the Data, information, knowledge, and Wisdom (DikW) paradigm.2,3 The
definitions of the layers are not precise, but the layers give a sense that data are processed to higher levels of abstraction, enabling people to make judgments about a situation and to follow a course of action. The widths of the elements of the hierarchy represent the relative volumes of data stored at each level. Data are the small-est symbolic units that describe measured or small-estimated phenomena. For example, sensors produce large vol-umes of data, but very little is understood by humans. Information here is used in a more restrictive sense than when we refer to information systems. in the DikW paradigm, information is a more abstract understand-ing of the data derived by fusunderstand-ing data; it is typically the lowest layer where the symbolic units are interpretable by humans. Knowledge is belief about the information. in this layer, symbols are sufficiently abstract to enable
people to make decisions about and interact with their environments. knowledge implies the combination of information with ancillary data and discernment of his-torical patterns. Wisdom is knowledge combined with insights and common sense. it is typically achieved by humans based on knowledge, information, and data. unlike other levels of the DikW hierarchy, wisdom is hard to derive automatically from lower-level informa-tion representainforma-tions.
The engineering of information systems is the applica-tion of formal methods of analysis to create operaapplica-tional systems. information systems that incorporate mul-tiple technologies and processes must be designed and developed according to rigorous engineering standards to ensure that they support the requirements of their respective application domains and that they operate rapidly, accurately, and efficiently. Today, an exponen-tially increasing amount of data is available for process-ing and analysis, the number of decisions that must be made based on analysis is growing, the number of ana-lysts that can make these decisions is decreasing, the time frame to make the decisions is becoming smaller, the size of information systems that support decision sys-tems is increasing, and information syssys-tems are becom-ing more vulnerable to attack.
military information systems must deal with denial and deceit, deliberate enemy actions to keep data from being collected or to distort the user’s perception of the world to the point at which the user takes actions advan-tageous to the enemy. As the number of people needing to interact with information increases, the complexity of the corresponding information systems also increases.
Data and information must be fused and synthesized so that fewer users can interact with a smaller amount of data at higher levels of abstraction. information systems must present clear and reliable representations of their environments.
At ApL, we are advancing the state of the art in the technologies and processes that will address these chal-lenges. intelligent use of data, information, and knowl-edge will enable systems to access and process large amounts of information more easily and rapidly. Auto-mated decision systems will allow more rapid fusion of data from heterogeneous sources as well as apply polyno-mial-time approximations to exponential decision prob-lems. service- and agent-based technologies will enable developers to create increasingly complex systems by rapidly discovering and incorporating the capabilities of existing systems. Agile software engineering methodolo-gies will promote the creation of more robust and flexible systems. cognitive engineering systems will apply prin-ciples of analyzing user tasks and roles to streamlining user processes and to focusing users on the right level of abstraction for their task. Finally, information assurance (iA) methods will increase the integrity of information systems and reduce their vulnerabilities.
This article describes the science and technology (s&T) vision of selected technologies and processes at ApL that allow our information systems to address these critical challenges.
APL’S S&T VISION FOR
INFORMATION SYSTEMS
ENGINEERING
Intelligent Use of Data, Information, and Knowledge
As the volume and heterogeneity of data play an increasingly prominent role in information systems, and as they continue to proliferate among many disparate organizations, advanced intelligent techniques must be exploited to simplify access to the data, accelerate data integration, and extract higher-level meaning from their content. extracting higher-level meaning enables soft-ware to derive higher-level abstractions represented in the DikW hierarchy. The ApL s&T vision is to develop and use those techniques that will make access to data sources faster, easier, and less costly.
Data sources and their respective data management systems store and maintain information relevant to information systems. Data source representations gen-erally fall into three categories: (1) structured (e.g., rela-tional databases), (2) semi-structured (e.g., XmL docu-ments), and (3) unstructured (e.g., text documents). We envision that information systems incorporating new or legacy data sources of all three categories will use tools that provide simplified access to them and
Information system Perceived world Desired world Actions World Sensors Figure 1. Information systems context. Information Data Perceived world Desired world Actions World Sensors Wisdom Knowledge Figure 2. Information systems using the DIKW paradigm.
enable them to be integrated with other data sources and applications.
Applications and users requiring access to data sources often need detailed knowledge of the data source models, as well as the meanings and intent of the data terms, to formulate reasonable queries. A greater amount of knowledge is required to formulate queries to and integrate the results of heterogeneous data sources. conceptual models and ontologies, which capture the structure and semantics of data sources, will play an increasingly important role in automated software that helps users gain access to these sources. conceptual data models are machine-readable representations that describe the design of data sources, including the data represented, data groupings, and inter-data relation-ships. ontologies are machine-readable representations that describe the semantics of the data sources, includ-ing the intended meaninclud-ing of terms and relationships as well as their relationships to concepts outside the realm of what is represented in the data sources. ontologies may also play a key role in integrating unstructured and structured data sources.
using reasoning techniques over the conceptual models and ontologies, software tools will automatically
formulate queries to one or more data sources, facilitate the process of integrating heterogeneous data sources, and enable reasoning about the data to provide higher-level abstractions that can be inferred from the data. The next section describes how decision models will fuse information provided by automated query and integra-tion software to produce knowledge.
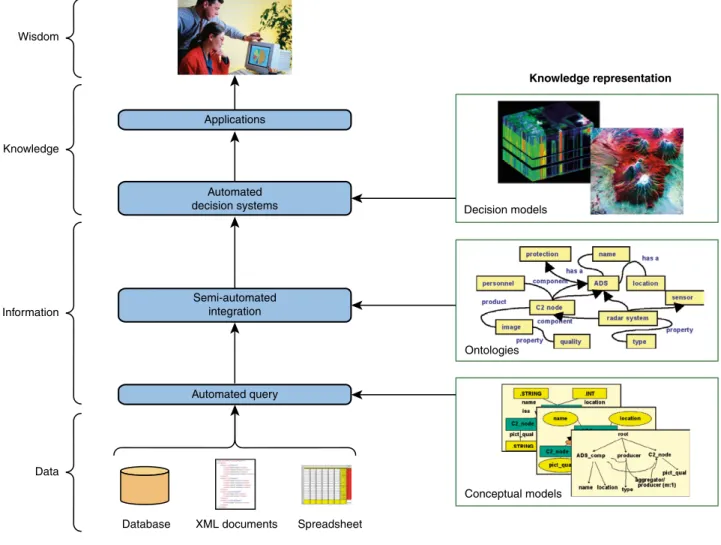
Figure 3 depicts this DikW information process-ing hierarchy with respect to knowledge representa-tion models, including conceptual models, ontologies, and decision models. Through the use of knowledge representation–supported capabilities, automated (or semi-automated) tools transform data to information to knowledge. Automated query tools that exploit conceptual schemas will enable simplified aggregation of information from individual data sources. semi-autonomous data source integration tools will use ontologies to integrate information from heterogeneous data sources. Decision systems supported by decision models will enable information to be abstracted into knowledge. Applications that are supplied knowledge input from decision systems will further refine that knowledge. Finally, users interacting with applications that are supported by knowledge representation–based
Applications Knowledge representation Wisdom Knowledge Information Data
Database XML documents Spreadsheet Automated decision systems Semi-automated integration Automated query Decision models Ontologies Conceptual models Figure 3. Information systems DIKW hierarchy using knowledge representation.
tools will gain wisdom to understand and act upon their environment at the abstraction level appropriate to their tasks.
Automated Decision Systems
Model-based Data Fusion
ApL programs will increasingly rely on model-based data fusion techniques, which use models and model relationships to help automate the integration of sensor data to create both information and knowledge in the DikW hierarchy. While overlaying sensor data are important in certain circumstances, model-based data fusion goes beyond sensor overlays by fusing information from multiple sensors to provide a picture of targets that have been detected, identified, and located with associ-ated confidence. Furthermore, model-based data fusion provides support for sensor management and manage-ment of attack assets.
Traditionally, targeting for surface targets has been imagery centric and tracking has been point-data cen-tric. model-based data fusion integrates these two tra-ditions. Tracking methods usually assume that sensor data are first processed to perform signal detection. The output of signal detection is observed point data in the form of kinematic quantities such as position, range rate, and time difference of arrival. Furthermore, signal detection provides signal-related data such as attributes and features that support the association of newly observed data with targets. using techniques that include hypothesis testing and parameter and state estimation methods from statistical decision theory, the point data and signal-related data are then fused over time to provide target detection, data association, iD, and location. imagery, on the other hand, can be fused at the pixel or feature level without first being processed to produce point data. Tracking and imagery fusion can be integrated by taking the results of imagery processing in the form of point- and signal-related data as input to tracking.
model-based data fusion allows the best use to be made of what is known in the form of prior knowl-edge. newly observed data are integrated with prior knowledge about targets, signatures, and sensors to rapidly produce the best information and knowledge. essentially, this provides a continuous ipb (intel-ligence preparation of the battlefield) that allows quick reaction to threats. The model-based methods draw explicitly on mathematical models; examples include model-based automatic target recognition and kinematic tracking methods. more generally, techniques such as template matching and neural nets are also based on modeling assumptions. The techniques that can make the most efficient use of prior knowledge will generally provide the best perfor-mance when new observations are made.
Learning and Reasoning Tools
Learning is a key element of many intelligent sys-tems. it is a fundamental way to acquire and assimilate new information to increase our knowledge of the world. Without learning, even the most seemingly intelligent entity is doomed to repeat the same mistakes endlessly.4
Learning and reasoning tools deal with unanticipated change in the environment and help to improve soft-ware responses and behavior over time. Learning recog-nizes that software engineers cannot possibly conceive of all possibilities and plan for all contingencies. Learn-ing tools identify new information and knowledge rep-resented in the DikW hierarchy.
The ApL vision is to increasingly incorporate learn-ing techniques that will address issues of scalability, model selection, communication constraints when oper-ating in a distributed environment, and effective incor-poration of domain knowledge. example learning tech-nologies are large-margin kernel machine and bayesian belief networks (bbn). Large-margin classifiers such as support vector machines are discriminative methods that generalize well in sparse, high-dimensional settings. bbns are probabilistic graphical models that provide a unified framework to manage computational uncertainty consistently through the fusion of computer science and probability theory. in particular, these graphical models enable robust incorporation of domain knowledge in machine learning and automated reasoning, which is difficult to achieve with traditional techniques based on statistical analysis and signal processing.
Distributed Computing
Web Services
The demand for near-universal access to data and applications will continue to grow throughout the next decade. The ApL vision is to meet this need for future generations of command and control (c2) systems by using a service-oriented architecture (soA), and, more specifically, by using a distributed web services approach.5
Although data transfer to and from legacy applications has been simplified over the past decade by using tech-nologies such as microsoft’s component object model (com) and omg’s common object request broker Architecture (corbA), a more extensible and scalable architecture is now available.
Future global c2 systems are likely to be based on web-service architectures like the net-centric enter-prise services (nces) approach used to develop the global information grid (gig; Fig. 4). This approach allows groups of users, called communities of interest, to assemble on-the-fly groupings of data sources, display surfaces, decision support tools, and other services to meet their particular needs without having to bear the cost of development each time. communities could be pulled together for short periods of time (e.g., for a single
engagement) or for longer-standing timeframes (e.g., for years or even decades).
The core enterprise services are tied together using standard web services components, listed here with their responsibilities.
• Discovery services centralize services into a common registry and provide easy publish/find functionality. currently handled via universal Description, Dis-covery, and integration (uDDi).
• Description services describe the public interface to a specific web service. currently handled via the Web service Description Language (WsDL).
• Messaging services encode messages in a common XmL format so that they can be understood at either end. currently includes XmL remote procedure call (XmL-rpc) and simple object Access proto-col (soAp).
• Transport services transport messages among applica-tions using protocols such as hTTp, smTp, or FTp. currently, web services are described in common uDDi registries by text that does not provide other applica-tions with insight into the use and intent of the services. ApL intends to develop ontology-based technologies
that will enable applications to automatically discover and integrate services based on higher-level semantic descriptions.
Agent-based Systems
Agent-based systems are an emerging paradigm for constructing large, complex systems, and the ApL s&T vision is to increase their incorporation into large information systems. Traditionally, large-scale systems are designed using the procedural approach achieved by functionally decomposing tasks into progressively smaller components until their coding can be managed by individual programming teams. shortcomings of the procedural approach include the rigidity of the design and the fragility of the software. When requirements change, modifications may be needed to the software throughout the entire system. The object-oriented para-digm improves upon some of the problems of the proce-dural approach. The object-oriented approach requires systems to be broken into smaller components or objects that are abstractions of real world “things.” objects encapsulate state via variables and methods that oper-ate on stoper-ate. objects also support inheritance. system Business mission area
User/entity
• Installation and environment • Human resources
• Strategic planning and budget • Accounting and finance • Logistics
• Acquisition
Warfighting mission
area National intelligence domain
ESM Security Mediation Security ESM Collaboration Security ESM Discovery Security ESM User assistant Security ESM Institutional COIs Expedient COIs Cross-domain COIs Information exchange ESM Security Security ESM Security ESM ESM
Application Storage Messaging
Security Core enterprise services
Controlled inf o. e xchange Controlled inf o. e xchange Allied/coalition and multinational
Transformational communications and computing infrastructure
Enterprise information environment mission area
ICSIS community space
Specialized functional area information and services
Domain COI capabilities IC org. spaces Figure 4. A holistic view of the GIG NCES. (Source: B. Appleby, NCES PM, Defense Information Systems Agency brief, “Net-Centric Enterprise Services OIPT,” Apr 2004). (COI = communities of interest, ESM = enterprise service management, ICSIS = intelligence com-munity system for information sharing.)
modifications usually are made only to a few objects, leaving the rest of the system intact.
The agent paradigm extends the object-oriented paradigm in many important respects, enabling the cre-ation of systems of multiple agents that are more flexible, adaptive, and self-organizing.6 Agents are independent
software components that exhibit autonomy, intelli-gence, the power to delegate, the ability to communi-cate, and sometimes mobility. Autonomy enables agents to act independently and with purpose. They solve goal-oriented requests of users and other agents but are not dependent on users and other agents for their operations. Intelligence enables agents to learn about their environ-ments, to reason over knowledge they have acquired, and to make appropriate decisions. They may learn from their interactions with users to improve themselves and are adaptive to uncertainty and change. For example, agents may encapsulate automated decision systems and automated data access systems to exhibit. Delegation enables agents to call upon other agents to help solve problems, which does not preclude users from being “in the loop.” Communication among agents is achieved through agent-communication languages, which are typically goal-oriented statements and requests. since agents are autonomous and are created by authors from multiple domains, assistance from ontologies is required to translate communications from the language of one domain to another. Mobility enables agents to move among machines, gathering information from each plat-form to achieve its goals.
sophisticated agent systems can allow agents to dis-cover, communicate with each other, and self-organize to solve critical tasks. in a limited analogy, they can be compared to groups of people who organize to solve problems. The people are autonomous, have intelli-gence, and collaborate by using each other’s expertise to achieve their goals.
Agent systems are anticipated to play a more promi-nent role in future ApL development. These systems will enable large communities of software systems to form and exchange services and data more automatically. They will also help bridge the gaps among disparate, stove-piped systems to meet the needs of our sponsors.
Software Engineering
much of the research in software engineering today, and for the foreseeable future, is rooted in one funda-mental characteristic of software systems—increasing complexity. As our ability to build software and software systems improves, we build ever-larger and more complex systems. As complexity increases, a host of other issues arise. systems must become more distributed because a single computer can no longer contain them. They also become more error-prone, and the errors become harder to find and fix. The teams needed to develop software systems also become larger, with the resultant
increase in communication complexity and the require-ment for more precision in their definition. related to this problem is the one of defining the systems’ behav-iors in the first place, as they also become increasingly difficult for users to visualize and describe all aspects of those behaviors in advance. Finally, as the systems become ever larger and less deterministic, it becomes impossible to fully define and test all of their behaviors. instead, systems must be developed that remain reliable and robust, even when handling conditions outside of design specifications.
in addressing the fundamental issue of system com-plexity, ApL envisions applying aspects of three recent foci in software engineering research to internally devel-oped systems. The first aspect is modeling to enable system developers to work with higher levels of abstrac-tion, both in system specification and systems opera-tions, using standards for describing modeling languages such as the meta-object Facility (moF) as well as run-time behavior via the model-integrated computing (mic) effort. The second aspect of software engineer-ing that ApL will apply to its systems is new software development methodologies that are evolving as quickly as systems are. keeping in mind that software devel-opment is not a “one-size-fits-all” prospect, ApL will pursue agile technologies such as eXtreme programming (Xp), scrum, and the Agile Development process (ADp) as well as more traditional approaches. The third aspect that ApL will pursue is software architectures that exploit technologies such as the soA and pub-lish-subscribe infrastructures, and architecture frame-works such as J2ee, the DoD Architecture Framework (DoDAF), and microsoft’s .net. These approaches will enable system developers to work at ever-higher levels of abstraction, managing the system development at the highest level—the architecture—as well as soft-ware. (see the article by hanke et al., this issue.)
Cognitive Engineering
As the power of software and hardware systems increases and the amount of data with which the sys-tems interact escalates, the requirement for more com-plex human interaction with greater volumes of data increases as well. systems often must support multiple users with different needs for access to information and distinct system interaction roles. unless the engineer-ing of information systems considers user roles and tasks as a fundamental aspect of their engineering, users may suffer the consequence of system–user impedance mis-matches. ultimately, users need to interact with systems at a level of abstraction and ease to simplify their tasks as well as increase the understanding of the goals they are accomplishing. Thus, ApL will increasingly incorporate cognitive engineering techniques in system development. The ApL vision for cognitive engineering is discussed at greater length in the article by gersh et al., this issue.
Information Assurance
The goal of iA is to ensure the confidentiality, integ-rity, and availability of information to authorized users and systems. Confidentiality is assurance that informa-tion is shared only among authorized people or organiza-tions. Integrity is assurance that information is authentic and complete. it also means that the information can be trusted to be sufficiently accurate for its purpose. Avail-ability is assurance that the systems responsible for deliv-ering, storing, and processing information are accessible when needed by those who need them. information sys-tems deployed by ApL will be iA enabled, which will raise the confidence level that our systems will operate reliably and consistently and will be more resistant to external threats. even with a well-engineered informa-tion system, loss of one or more of these attributes can threaten the credibility of the information provided by the system. ApL systems will increasingly integrate iA tools and methodologies in system development. our iA vision is discussed at greater length in the article by Lee and gregg, this issue.
SUMMARY
The engineering of information systems will increas-ingly rely on integrating a wide range of technologies and processes that enable users and systems to access, understand, and operate on large amounts of informa-tion. information must be presented at the right level of abstraction at the right time to allow users to make informed and timely decisions. Thus, information system technologies will be engineered to integrate and process information across the DikW continuum so that infor-mation is available at abstraction levels appropriate to user tasks and roles. ApL will engineer state-of-the-art
information systems by modeling data, information, and knowledge and by applying reasoning techniques to the models to automate information integration, fusion, and decision making. Furthermore, ApL information systems will be created to participate in larger communities of interest by discovering other services and software agents and by making their services and agents available to other applications. ApL software systems will be designed using the appropriate software engineering principles to ensure robustness and flexibility. in addition, good cognitive engineering techniques will be used to develop systems to ensure that users are working at appropriate levels of abstraction. Finally, iA tools and methodologies will be integrated into our information systems to protect their confidentiality, maintain their integrity, and ensure their availability.
AcknoWLeDgmenTs: We would like to acknowl-edge rosemary Daley, John gersh, peter Jacobus, susan Lee, Jennifer mckneely, David W. porter, roger rem-ington, and i-Jeng Wang for their valuable inputs to this article.
reFerences
1Doctrine for Command, Control, Communications, and Computers (C4)
Systems Support to Joint Operations, Joint pub 6-0 (30 may 1995); http://www.dtic.mil/doctrine/jel/new_pubs/jp6_0.pdf.
2Ackoff, r. L., “From Data to Wisdom,” J. Appl. Syst. Anal. 16, 3–9 (1989).
3cleveland, h., “information as resource,” The Futurist, 34–39 (Dec 1982).
4Yoon, b., “get smart: real World Learning”; http://www.darpa.mil/ DArpAtech2004/pdf/scripts/YoonrWLscript.pdf (2004).
5erl, T., Service-Oriented Architecture: A Field Guide to Integrating XML
and Web Services, prentice hall (2004).
6hendler, J., “Agents and the semantic Web,” IEEE Intel. Syst. 16(2), 30–37 (2001); http://www.cs.umd.edu/users/hendler/AgentWeb.html.
THE AUTHORS
David P. Silberberg is a member of ApL’s principal professional staff and serves as the Assistant supervisor of the system and information sciences group of the research and Technology Development center. in addition, Dr. silberberg is an
David p. silberberg
glenn e. mitzel
Assistant research professor in the Department of computer science at Jhu and teaches courses in both distributed database theory and XmL technologies at the Jhu engineering and Applied science programs for professionals. previously, he was a principal architect of the hubble space Telescope Data Archive and Delivery service and the nAsA national science space Data center Archive. Dr. silberberg received both s.b. and s.m. degrees in computer science from miT in 1981 and a ph.D. in computer science from the university of maryland, college park, in 2002. Glenn E. Mitzel is a member of ApL’s principal professional staff and serves as the chief scientist for the precision engagement business Area. From 1991 to 2000, Dr. mitzel supervised the ship systems group in the power projection systems Department. he has worked on a variety of new concepts and techniques in remote surveillance and targeting, including geospatial pattern recognition for ship discrimination, passive ranging of jamming aircraft, multimodal data fusion, and space-based surveillance. Dr. mitzel received b.s.e., m.s.e., and ph.D. degrees in electrical engineering from Jhu in 1973, 1975, and 1978, respectively. For further information, contact Dr. silberberg at [email protected].