SCHEMA EVOLUTION IN SOFTWARE ENGINEERING
DATABASES — A NEW APPROACH IN
ADELE
ENVIRONMENT
Mohamed
Ahmed-Nacer
Jacky
Estublier
ACTIMART Bat 8, Avenue de Vignate 38610 Gi`eres (Grenoble), France e-mail:{nacer, jacky}@imag.fr
Abstract. This paper discusses schema evolution in software engineering databa-ses. After a study of existing approaches, we show that these approaches do not satisfy software engineering requirements. Then, we present our model, which sup-ports multiple schema compositions and multiple evolution policies, each application being free to define its evolution strategy. Management of our system is based on class versioning. The consistency of the database and the various evolution policies are controlled by consistency constraints. The schema composition uses software configuration techniques and evolution policy definition uses the capability of the active database of the Adele system.
Keywords: Software engineering, schema evolution, databases, schema configura-tion, evolution policies.
1 INTRODUCTION
Schema evolution has attracted a considerable amount of attention in the database community [3, 4, 11, 13, 15, 18]. In conventional applications, schemas are unmod-ified for a long period of time whereas in other domains they change frequently. For instance, schemas are frequently modified in computer aided design or software engineering in order to incorporate new tools or new development methods. The update operations and associated semantics used to change a schema depend on the data model (O.O. data model, ERA data model, relational data model, etc.), the application domain and corporate policies. Some characteristics are common to a majority of systems and others are specific to the data model and application
domain. Section 2 presents the various approaches regarding software engineering requirements.
Software Engineering (SE) seeks to build a software product at a reasonable and predefined cost, quality and delay. SE requires the storage of many artifacts (source code, binaries and documentation); this management requires many tools (editors, compilers, design tools, test tools, etc.), activities and resources (humans, machines). All this has to be part of the database schema. Artifacts definition (static part only) is reasonably stable, but tools and resources definition vary constantly during the course of a SE project, requiring constant changes into the data schema.
Many applications in software engineering share the same database and each application would like to evolve its schema frequently. This frequent evolution of schemas is in conflict with other applications that need to have stable schemas. This is a crucial problem of schema evolution in software engineering. To solve this problem, we propose to associate a suitable schema with each application according to its needs, and independently from modifications to other schemas.
Our work is developed on top of the Adele software engineering environment. Section 3 presents the main characteristics of this environment. Section 4 describes our solution that supports multiple schemas. Each schema contains (potentially) a different description of the same class; we use class versioning. Schema composi-tion uses software configuracomposi-tion techniques, but applied modules to class definicomposi-tion instead of software components. We use the concept of modularity to reduce the complexity of class version management. A schema thus consists of a set of modules. Modification of a schema by an application has, potentially, an important effect on the database and on other applications, particularly on the application itself. Applications are thus not free to make all types of change. The consistency of the database and schemas is discussed in Section 5.
The term “evolution policy” refers to the modifications that an application is able to perform. In general, in all existing systems, evolution rules are imposed by the system. This straightforward approach is inconvenient as it offers users no way of adapting evolution rules to suit individual applications. In our approach, evolution policies can be described formally and it is thus possible to associate each application with its “own” evolution policy. This is discussed in Section 6.
2 SCHEMA EVOLUTION IN OODB
One approach used in schema evolution is to specialise/generalise a class definition; this enables it to evolve within a class hierarchy [27]. It is clear that much more flexible kinds of evolutions are also needed. A more general solution involves leaving the class to evolve “arbitrarily” [31]. However one of the main problem in schema evolution is to keep the correspondence between the internal format of instances in the database and the definition of their class. This explains why database reorgani-zation [22] is such a crucial problem.
2.1 The Various Approaches
The main systems studied in this paper are Orion [5], Encore [29], Gemstone [12], ECMA-PCTE [16], O2 [6], Object Store [24] and Oracle 8 [26]. These systems have been selected because their data models are representative of the object oriented concepts and because the approaches they used to manage schema evolution are different. The two first systems have been prototypes but have been very influ-ential in this area (Hitasca is the commercial version of Orion, and UNISQL has been designed by the Orion architect). PCTE is also discontinued but is the only commercial system that addressed specifically software engineering. O2 and Object-Store are good representatives of current commercial OODBMSs, and Oracle 8 is the commercial DMBS leader, and among the firsts to propose an object relational system. We illustrate these approaches with the following characteristics:
– Database reorganisation strategy. – Granularity of modifications.
– Invariants used for schema consistency.
– Nature and semantics of schema update operations.
2.1.1 Database Reorganisation
Two main database reorganisation strategies are used when a schema evolves: con-version and emulation. Concon-version involves converting database objects to make them comply with the description of their modified class [19], [20]. When conver-sion is immediate, such as in Gemstone, ObjectStore, Oracle, any inconsistencies in the database are eliminated. However this presents two major drawbacks, namely that the database remains inaccessible during the time required (fairly long) for object reorganisation and secondly the old schema cannot be used. When the con-version is deferred, such as in Orion [4], objects are updated only when they are accessed. However, inconsistent objects remain in the database temporarily and, as for immediate update, the old schema cannot be used. In both approaches, old applications become obsolete, which is inconvenient for software engineering appli-cations because since schema often changes, the cost of fixing appliappli-cations it is much too high.
The emulation strategy is based on class versioning [10], [11], [15], [23], [25], [29]. Old applications continue to use the old schema. This approach, used by ECMA-PCTE or Encore, allows the applications to be relatively independent of the multiple evolutions of a schema. It is suitable for software engineering applications: it is possible to have different representations of an object when it is used by simultaneous activities.
2.1.2 Granularity of Modification
The granularity of modification corresponds to the entities on which evolution (up-dates) is applied.
No versions
Systems using an approach based on immediate conversion, such as Gemstone, Ob-jectStore or Oracle, provide no evolution tracking. Modifications are applied directly to the schema, which is considered to be global and unique; the previous state of the schema is not kept.
Schema versions
In Orion, the entity to which the evolution is applied is the complete schema. A schema change involves a completely new database schema version. Difficulties arise when a large number of schema versions need to be managed.
Class versions
The entity to which changes apply is the class. A class change, in Encore, generates a new class and new versions of all the associated subclasses. The mechanism used to control class versions involves creating for each class its version-set containing all versions of that class. Each modification to a class generates a new version into its version-set. In addition, new versions of its associated subclasses are also generated and integrated into their respective version-sets.
Object consistency is maintained by a common interface relative to all versions of a class. This interface, called versions-set-interface, describes all the attributes and operations defined in these versions. It also allows to determine the exception procedures (handlers) required when a class is modified.
Schema views
The notion of a logical database view is valuable in software engineering environ-ments. ECMA-PCTE uses this notion, thanks to the Schema Definition Set (SDS) concept. Class definitions are organized into sets called SDSs. The current schema, called working-schema, is established by a list of SDSs, where each SDS corresponds to a logical database view.
The working schema is modified when adding new SDSs or updating the existing SDSs. Modifications are done without creating new versions. Changes to a schema are consequently considered as changes to a database view.
Another approach is developed in the TSE system [30]. This approach considers an initial global schema from which each developer defines his own view of the shared database. Schema evolution is realized by view generation: each schema change is directly specified to the view and the system is responsible for computing a new schema view reflecting the schema change. The schema change is realized by the system through virtual classes in the context of the view. The schema change is virtual; it avoids the potential impact of the change on other developer’s programs.
2.1.3 Invariants
Even if schema update operations are unpredictable and of various types (inheritance structure changes, property changes, etc), a schema must remain consistent struc-turally and dynamically. When a schema evolves, its dynamic consistency is defined in terms of constraints that must be satisfied in order to avoid dynamic inconsis-tencies, for instance, when calling a deleted or an invalid method [33, 34]. Schema structural consistency is defined in terms of subtyping invariants. For instance, class hierarchy invariant requires that the graph of the inheritance relationship be acyclic [4].
Complete solutions have not yet been defined for dynamic consistency in contrast to structural consistency. The majority of systems use the same minimum set of invariants to secure the structural consistency of the schema and database, even if they require some specific invariants with regard to their data models.
2.1.4 Schema Update Operations
The problem of schema evolution is tackled differently from one system to another. Each system has its own modification semantics. We shall consider, as identified in [4], three types of update operations: class modifications, inheritance relation modifications and class definition modifications.
Class modifications
In general, there is no problem for existing data when adding a leaf class (which has no subclasses) in a schema because this leaf class has no instances in the database. Conversely, deleting a class imposes some choices. In Orion, Oracle and Object-Store class deletion involves deleting all its instances including its components. In Gemstone, Encore and O2, deletion is not possible if the class has instances in the database.
Deleting is not allowed in O2 if the class is invoked in a method signature, while Oracle, after any class change, recompiles all dependent classes to check for inconsistencies. In PCTE, the instances of a deleted class remain in the database; however they can only be consulted.
Inheritance relation modifications
Adding a superclass in a class inheritance list can cause name conflicts. Orion solves this problem considering each new superclass as the last one in the superclass list.
When subclasses are defined in a schema with a unique superclass, deleting this superclass isolates these subclasses from the inheritance graph. Orion considers, in this case, that each subclass will have as new superclasses the same ones as the deleted class.
O2 provides the possibility of considering the same solution as Orion or consid-ering the predefined root class as the new superclass. Encore uses the same approach as Orion, but generates a version for each subclass of the deleted class. Inheritance relation modifications are not allowed in PCTE-ECMA and Gemstone.
ObjectStore allows adding or removing a superclass in a class hierarchy; in-stances are automaticallymigrated, however new fields are initialised to NULL unless a specific instance migration function is provided. Instances can also be reclassi-fied, i.e. migrated down the new hierarchy, but a reclassification function must be associated with the class whose instances are to be reclassified.
Oracle does not provide any inheritance facility.
Class definition modifications
When a property is added to a class, it is inherited in all its subclasses. This operation is not possible in Orion if it causes name conflicts. Gemstone is the only system that does not allow an inherited property to be added (no overloading).
It is not possible to delete an inherited property in all systems. When a property is deleted from a class definition, this operation is propagated to all the subclasses that have inherited this property. Propagation is not automatic in Gemstone; it must be explicit for each subclass. In ECMA-PCTE, a property cannot be deleted from a class.
Modifying the value domain of an attribute (property) is not allowed if this attribute is inherited. For non-inherited attributes, their value domain is not prop-agated to the subclasses in Gemstone. It is not allowed to rename a property in Encore and this operation is rejected in Orion if it causes name conflicts.
In Object Store, attribute definitions can be added, deleted; their type modi-fied, or their order changed. However, in some cases a specific migration function is to be provided, or the NULL value is inserted. Oracle 8.04 provides extremely re-duced evolution capabilities “You cannot change the existing properties (attributes, member subprogram, map or order function) or an object type, but you can add new member subprogram specification” [ch4, Alter type]. It contrasts with ta-bles where columns can be added or their definition modified (type, size or default value).
2.1.5 Conclusion
When a schema evolves, the problem to be solved in most systems is that of main-taining the compatibility between old applications and new modifications. There is no need in most application domains to use different schemas simultaneously. Class versions or schema versions, if they are created, are simply maintained to keep a record of the schema change. These approaches do not satisfy software engineering requirements. A software engineering environment has to fulfil user needs to take into account new functionalities during its exploitation and dynamically integrate tools into a development method [21]. Our goal is to develop a system with the following characteristics:
1. Multiple schemas and simultaneous object representations
In software engineering, an object must be manipulated differently and simultane-ously by multiple users (or tools) through the multiple activities. It is essential that an object be accessed simultaneously through its multiple class versions.
Sup-port is needed to compose and use multiple schemas simultaneously and evolution constraints must ensure compatibility between the different versions of a class.
2. Declarative evolution policy
Schemas should be defined independently; they do not necessarily have the same evolution constraint. The schema evolution can differ according to the required evolution strategy. User must be able to define their own evolution strategy.
Our approach is developed on top of theAdele software engineering database. We use its trigger mechanism. Below, we present the minimum requisite for the Adele environment to understand our work.
3 THEADELE SOFTWARE ENGINEERING ENVIRONMENT 3.1 The Data Model
The Adele environment supports software engineering applications in multi-version and multi-user contexts. It comprises a multi-user and multi-version object manager, a configuration manager and an activity manager to maintain database integrity, integrate tools and synchronize the different activities executed in the environment. The Adele data model is derived from the entity-relationship model [14] and in-tegrates object oriented concepts [1, 13]. The basic entities of the model are object classes and relation classes. Each entity (object or relation) has static properties (at-tributes) and dynamic properties (methods, events and triggers). This data model supports complex objects called aggregates. An aggregate is an object related to its components by relationships; the aggregate semantic is defined by relationship behaviour, which is user-defined. Thus, almost any kind of aggregate with any behaviour and consistency constraints can be defined.
The static aspects (attributes) are defined as attribute name/attribute-values pairs. In Adele, we use three types of attributes:
1) Adele attributes which provide some information on objects such as associated files, object type and usage context like current command or current user, 2) Unix attributes, which provide the value of variables defined in the Unix context
($PATH, etc.) and 3) user-defined.
Attributes, in Adele, can be defined with some characteristics. For instance, we define an attribute with the MONO characteristic in an object class C to indicate that this attribute cannot be instantiated more than once for an object of class C. By default, an attribute can be instantiated more than once. Another characteristic is to define a STATIC attribute: Once an attribute of an object O is instantiated with a given value, this attribute keeps its value during all its lifetime.
3.2 The Behavior Model
The dynamic aspects of the environments constructed on the Adele kernel are defined in the Adele language using trigger rule formalism [7, 8]. Triggers are defined in the class definition of objects and relations. Thus, they are structured and inherited along the class hierarchy.
Adele triggers take the following form “rule” name rule when event {action}
where “event” is a predicate over the system state, database state and the activities underway (queries, navigation as well as changes) occurring on objects and “action” is a method.
ClassDelete event delete class (class ClassName)
ClassDelete is defined as the event that occurs when command delete class be exe-cuted on object of class class and nameClassName.
A method is a program written in a simple imperative language; instructions can be logical instructions or Unix commands.
A trigger defined in an object class or relation class is executed when the asso-ciated event occurs for an instance of this class.
Some triggers will be executed before the action, acting as preconditions, others after the action, acting as postconditions (finish). Since triggers are (originally) intended to enforce consistency, any inconsistency found by a trigger must be able to undo (roll-back) the action. Thus for any action the following instructions will be executed:
{precondition triggers list} method {post-condition triggers list}
The whole operation is always a single transaction, even if the triggers or action call other actions. The execution of a primitive “ABORT”, anywhere in a block (precondition trigger/Action/postcondition-trigger) will undo everything that was done in this block.
Triggers defined in a relation class are executed whenever an action is done on an instance of this relation class (create, delete a relation, etc.). We have added some triggers to manage actions to objects linked by relations. Thus, we can define for each object a specific semantic depending on the relations linking it with other objects; that’s the way the aggregates, for instance, are managed.
The effect of an action on an object X is the execution of the triggers defined both for relations where X is the source object and relations where X is the desti-nation object. These triggers are defined by the keywordsorigin anddestination, respectively.
4 MULTIPLE SCHEMAS AND SIMULTANEOUS OBJECT REPRE-SENTATIONS
In software engineering, schemas evolve constantly and many applications must be executed simultaneously. Thus, it is essential to allow the use of different schemas si-multaneously and maintain compatibility between old applications and new schemas.
An object should be handled simultaneously by different users (or tools) for mul-tiple development activities. Hence, it is important that each activity has its own representation of the objects. The difficulty is to make an object instance consistent with the multiple definitions of its class. This problem concerns all database systems when a schema is modified. We shall consider below the mechanism that allows us to use multiple schemas simultaneously.
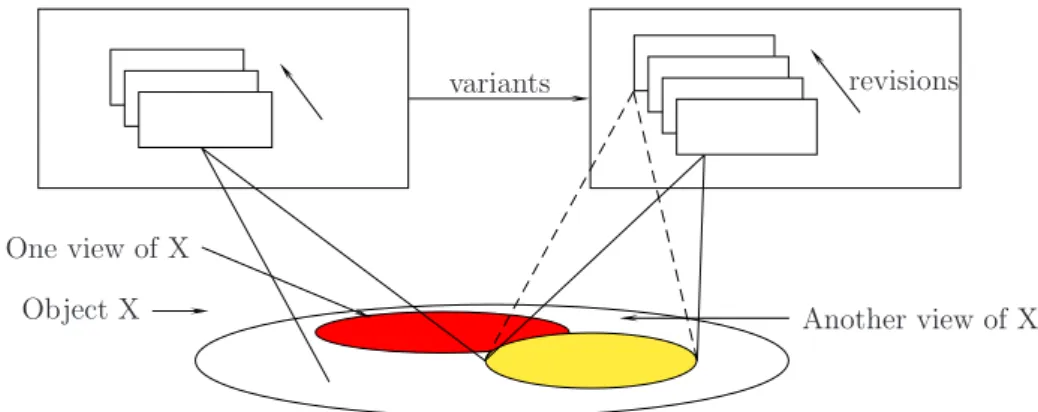
4.1 Class Versions: Variants and Revisions
We shall consider an object-oriented context : class definition contains a structural part (attribute definition) and a dynamic part (methods, events and triggers). To allow different representations of an object (or a relationship), classes must exist in different versions. Versions evolve in variants and revisions depending on the nature of the modification (Fig. 1). A variant is differentiated from another one by “major” modifications of its properties: the representation of an object is changed. A revision, which is generally created to improve the previous revision, differs only from other ones by “minor” modifications: the representation of an object remains unchanged regardless of the revision selected.
Major and minor modifications are introduced in Section 6.2.
variants revisions
Object X One view of X
Another view of X
Fig. 1. Variants and Revision
4.2 Schema Module
A schema may contain several classes, in the same way as software may contain several routines. Thus, it is useful to group class definitions intomodules. We apply the concept of modularity for schema definition1. A schema is designed as a set of
1 It is important to note that the module concept is onl used to enable better schema
definition and by users. Applications are not bound to modules; they continue to use a schema as a set of class definitions.
modules. This grouping offers several advantages:
1) schema evolution is managed easily using module versions rather than class versions,
2) the module offers a better vision of class definitions when the classes are brought together by the user into a single module for logic reasons, etc.
Module versions evolve in variants and revisions. A new version of a module M is a variant if one of the different modifications on its classes is a major modification.
4.3 Schema Composition: The Configuration Approach
A schema consists of a set of modules. To compose and manage schemas is not always easy when handling several modules, each module being defined in multiple versions. This problem is similar to the one used for software configuration management: a software product often consists of a set of modules, each one defined in multiple versions [17]. We shall apply this principle, considering a schema as a configuration of modules (Fig. 2). The configuration manager determines the appropriate version of each module belonging to the schema.
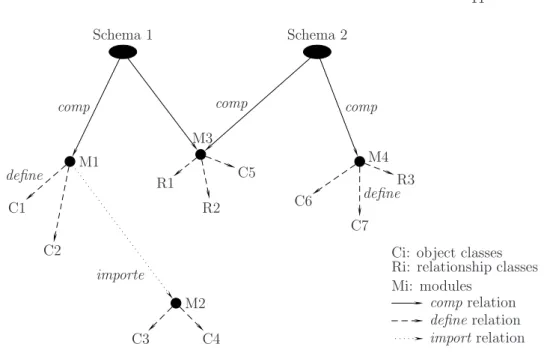
To manage this mechanism, modules and classes are represented as objects in a metabase. Modules, classes and objects are handled in the same way. Schemas are themselves complex objects and can be combined with other modules and other schemas to compose new schemas. Schemas can share a same module and can consist of one or several modules. However, only one version of each module can belong to a schema. Each schema, in a metabase, is linked to its modules by a composition relationship (notedcomp), and each module is linked to its classes by a predefined relationship noteddefine (Fig. 2).
Theimport relation between the modules M1 and M2 means that M1 imports the definitions of M2.
4.4 Configuration Process
The approach that we use to compose schemas is borrowed to software configuration management. A schema is a configuration, i.e. a set of modules computed from constraints provided by users. These constraints constitute a schema configuration declaration. They are based on the properties of the multiple module versions. The modules required to compose a schema must satisfy these constraints.
We consider two levels of granularity when the configuration declaration is com-puted: the configuration model and instance model.
The configuration model
A computed configuration is a configuration model when all the selected modules are variants. The model configuration is considered as a generic configuration (each variant being in several revisions).
C1 C2 comp Schema 1 Schema 2 M1 define importe M2 M4 C3 C4 comp R1 R2 C5 C6 C7 R3 define M3 comp
Ci: object classes Ri: relationship classes Mi: modules
comprelation
define relation
import relation
Fig. 2. Schema compositions
The configuration instance
A configuration instance, considered as an instance of the configuration model, is the result of the selection of only one appropriate revision for each module variant belonging to the configuration model. The appropriate revisions are those which satisfy the constraints expressed by the user. Thus, multiple configuration instances can be computed from one configuration model. They are considered as the revisions of the configuration model.
The constraints to select the configuration model and one of its configuration instances are expressed in the configuration declaration as in the example below:
CONFIGURATION schema dev:conf1 FOR program, document, possede doc MODEL SELIMP 1 [env = development] 2 [use = ok] INSTANCE 3 SELIMP [date>12/06/95]
4 SELDEF [author = !programme%responsible] END
This example shows a configuration declaration for a schemaschema dev:conf1
in a development environment from two basic modules (programanddocument) and from one relation class (possede doc).
The selected variants (of modules) must satisfy the constraints expressed in the MODEL clause. The appropriate revision for each selected variant must satisfy the constraints expressed in the INSTANCE clause. Two types of constraints are used: – Imperative constraints (SELIMP clause). Each selected module must satisfy
these constraints.
– Default constraints (DEFAULT clause). They are used to select one revision from the multiple revisions (of a variant module) which satisfy the imperative constraints. If multiple revisions satisfy these default constraints, the most recent one is selected. Later on, the same approach have been formalised in [9], and reformulated and extended using feature logic in [32]. The same kind of description can be done in these formalisms.
In this example, the selected variants of modules are those which are designed for a development environment (line 1) and whose use is allowed (line 2). The selected revision, for each selected variant (of module), is the one created after 12/06/95
(line 3). If several revisions satisfy this last constraint, the selected revision is the one that satisfies the default constraint, i.e. the revision created by the project manager (line 4). If several revisions satisfy this default constraint, the most recent revision is selected.
5 STRUCTURAL AND DYNAMIC CONSISTENCY
Simultaneous accesses to database, via several schemas, are only consistent in struc-tural terms, if object structures remain consistent with regard to the various schemas, and in semantic terms if operations handled through the various schemas are compatible.
5.1 Base Object Structural Consistency
We say that an object is consistent if the visibility rules and class transformation invariants are respected. The visibility rules ensure that an object can have multiple representations (simultaneous access to an object is thus possible). The class trans-formation invariants ensure that an object remains consistent when it is accessed through its multiple class versions.
Definition 1. A current schema is the schema through which the database is accessible.
Definition 2. A current version of a classC is the version of C belonging to the current schema.
Visibility rules
1. An object or a relationship instance is visible if a version of its object class or a version of its relationship class belongs to the current schema.
2. A property which is not defined in a current version of an object class or a relationship class, is hidden.
3. A property is visible if its value belongs to its current definition domain.
Example. Let S1 andS2 be two schemas and letC1 andC2 be two versions of the same classC. C1 belongs toS1 and defines two attributes:
– an enumerated attribute: document =(annotation, design, program) – a Boolean attribute: stability = BOOLEAN.
C2 belongs toS2 and defines only the attributedocument:
document= (annotation, specification, design, program).
• Each instance (object) of the class C is visible through schemas S1 and S2 (rule 1).
• The attributestabilityis visible only through schema S1 (rule 2).
• The attributedocument instantiated with the valuesannotation,design or pro-gram is visible through schemasS1 andS2 (rule 3).
• The attributedocument when instantiated with the valuespecification is visible only through schemaS2 (rule 3)
Class transformation invariant: Compatibility of attribute characteristics An attribute defined as STATIC in a classCmust remain static in all versions ofC.
Non-respect of this invariant will give an inconsistency because any modification on a static value is inconsistent.
5.2 Schema Structural Consistency
When a schema evolves, the subtyping invariants applied to ensure the structural consistency of the schema are the same as those defined in ORION [5], except the domain compatibility invariant which is different and the attribute/relationship characteristics invariants which are specific to the Adele data model.
Domain compatibility invariant
When an attributeAis redefined in a classC, it must have the same or restricted value domain as the one defined forAin the superclass ofC.
Attribute characteristics invariant
An attribute defined in a class C with the MONO or the STATIC characteristic must preserve this characteristic when it is redefined in a subclass ofC.
Example. LetAbe aMONOattribute defined in a classC. LetC1 be a subclass ofC;C1 redefines the attributeAwithout theMONO characteristic.
An instanceO1 ofC1 can thus exist in the database with several values for the attributeA. This gives an inconsistency inO1 becauseO1 is also an instance ofC (specialization inheritance) and must respect the definition of the attributeAinC (Ais aMONO attribute; only one value is allowed forA).
Relationship characteristics invariant
The cardinality defined in a relationship classR cannot be extended to a subclass ofR.
This invariant also preserves the base consistency because each instance of a subclass ofRis also an instance of R.
5.3 Dynamic Consistency
The management of multiple schemas requires particular attention for the global consistency of the system. We shall consider, in this case, the dynamic consistency constraints which ensure that the simultaneous use of the multiple schemas are compatible and that the different evolution semantics do not give rise to database inconsistencies. Respecting these constraints is fundamental to maintain the global consistency of the system and it is necessary to allow the multiple schemas to be used simultaneously.
Example of global constraints:
– The deletion of a class in a schema must not result in deleting its instances physically because they may still be used by other schemas.
– The domain of an attribute can only be restricted or generalized, etc.
Global constraints for system consistency are specified and defined in the root object of the system. The system administrator (superuser) is authorized to modify these constraints. Users can specify, locally for their schemas, some constraints ac-cording to their context use (with respect to the global constraints). For example, a project manager in a development environment can decide that whenever a compi-lation is required, the “debug” option must to be specified. This constraint is then applied to all the versions of the schema used in the development environment.
6 EVOLUTION POLICY
Schema modifications and their effects on both the database and the schema itself differ from one system to another. In Section 2, we showed the diversity of evolution policies (a complete study is presented in [2]). It seems that each system applies its own and unique evolution policy. This straightforward approach is inconvenient, as it does not offer users a way to adapt evolution rules to suit individual applications. Our evolution mechanism allows users to describe their own evolution policy and ensures global consistency when using schemas simultaneously. Each schema can have a suitable evolution policy.
Evolution rules can thus be different for the same class, depending on which schema the class belongs to. For instance, it would be possible to create, delete or modify classes when designing software components. This should be prohibited when testing these components to validate them.
To maintain database consistency when multiple evolution strategies are used in the different schemas, we have introduced specific global evolution rules. These global rules are applied to all the schemas.
6.1 Update Operations
We associate a semantic by default to each update operation. In addition, a library of defined multiple evolution semantics is available for each update operation, enabling users to choose their evolution strategy freely. This library is not mandatory. The database manager can modify it at any time by adding new types of behavior. The evolution system remains open and users decide how their schemas should evolve. The taxonomy of update operations proposed by default is the one proposed by Banerjee and al. [4], extended with specific update operations regarding Adele data model (update operations on attribute characteristics, events, triggers, etc.).
1. Inheritance relation modifications: They are considered asmajor modifications; the new created version is thus a variant:
• add a class, delete a class, rename a class in a schema
• add a superclass, delete a superclass, change the superclass list order. 2. Class definition modifications: It concerns the modification of class properties.
Minor modifications(The new created version is a revision)
• add, change, rename a default value of an attribute
• add, delete, change a constant attribute
• change the characteristics of an attribute or a relationship.
Major modifications(The new created version is a variant)
• add, delete and rename a property (attributes, methods, events and triggers)
• change the value domain of a property (attributes, method signatures)
6.2 Evolution Mechanism
In Adele, a schema is an aggregate linked to its components (modules) by compo-sition relations. Evolution policy is defined in these compocompo-sition relations. Using the Adele trigger mechanism on the relations (propagation effect on the composi-tion relacomposi-tion – see Seccomposi-tion 3.2), any change to a module or schema gives rise to
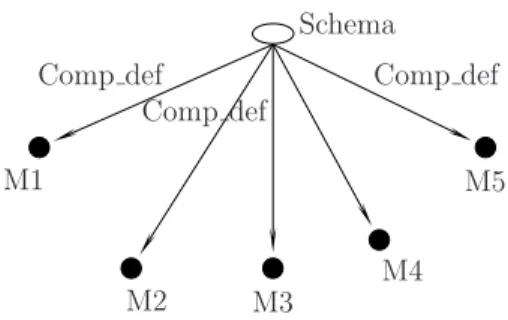
actions that update the schema and maintain its consistency (the aggregate). By default, a composition relation class notedcomp deflinks a schema to its module components (Fig. 3) and defines the evolution policy.
Schema Comp def Comp def Comp def M1 M2 M3 M4 M5
Fig. 3. Schema composition by default Comp defdefines the evolution policy by default as below: 1relation Comp deffrom schemato class extends define action,
check connection, check new . . . 2relation define actionfromschemato class
3 rule deletewhen delete class (class ClassName)on destination
4 {fortin destination -> define{
5 if (t== ClassName) rmr (this) ;}
}
6 rule renamewhen rename class (class ClassName)on destination {. . .
. . .
end define action;
7relation check connectionfrom schemato class
8 rule deletewhen delete class (class ClassName)finish on destination
9 {fortin destination -> define
{IF (t== ClassName ) foriIN ClassName←isa
{if (i-> isa == ClassName) abort}
} } endcheck connection;
Comp def (line 1) is defined as the subclass of multiple relation classes, where each relation class defines the default semantic of a particular update operation. For instance, the relation check connection which defines the semantic of delete class operation (line 7). The relation class defined action (line 2) defines all update
op-erations that are allowed by default (delete class – line 3, rename class – line 6, . . . ).
Operators “<-” and “->” make it possible to navigate through relations. “->” means to navigate the relation from its origin (denoted origin) to its destination (denoted destination) and “<-” the reverse. The expression X->ISA means all the superclasses of X and X<-ISA all the subclasses of X. The operator “==” is the complete set equality.
For instance, when deleting a class from a schema “delete class (class, Class-Name)”, the delete action (line 3) is validated when the constraint (line 8) associ-ated to the event delete class is checked. This post-condition (finish) checks that the subtype graph (schema) remains connected after class deletion: if the graph is not connected, the delete command is aborted (abort).
In line 4,destination means the destination of the current relation (the module), “destination->define” means all the classes of the module (a module is linked to its classes by the define relation – see Section 4.3). In line 5, this means the current object or relation.
Line 9 means that if one subclass (of the deleted class ( ClassName)) has as superclasses no more than this deleted class, then deletion is rejected (abort) because the graph will not be connected.
Generation of a new evolution policy
To create a new evolution policy, we create a new class of composition relations in the metabase. This new class will inherit actions described in thedefine action
and will define new evolution semantics. These new evolution semantics are simply defined thanks to the inheritance of existing relations or directly redefined in new relations.
For instance, to move from the default evolution policy to the Encore evolu-tion policy, one only has to create the relaevolu-tion classesno instance, connect to and
no renamewhich express the new evolution semantics, different from those proposed by default.
1relation comp encorefrom schema to classextends define action,
no instance,connect to,no rename. . .
relation no instancefrom schemato class
2 rule deletewhen delete class (class ClassName)on destination
if (class::extent ! ={}) abort;
end no instance;
relation connect tofrom schemato class
rule connectwhen delete class (class ClassName)finish on destination
3 {foriin desination<- isa
{if (i->ISA == destination) new ISA (i, destination ->isa)}
};
relation no renamefrom schemato class
4 rule renamewhen rename (class ClassName)on destination abort;
end no rename;
A new composition relationcomp encore(line 1) inherits these new semantics. The constraint (line 2) defined in no instance means that the deletion of a class is rejected (abort) if this class has instances in the database. The new semantic defined inconnect tomeans that if the subtype graph achieved after the class deletion is not connected, then all the subclasses of the deleted class are linked to the immediate superclasses (of the deleted class) (line 3).
The constraint (line 5) ensures that a class and its properties cannot be renamed.
7 CONCLUSION
In this paper, we have considered the problem of schema evolution in software en-gineering databases. With respect to software enen-gineering requirements, it quickly appears that the existence of a metabase and the possibility associating each appli-cation with its particular schema are necessary. This possibility gives rise to new problems: class version management and class evolution control. An approach has been presented as a contribution to solve these problems.
Classes are grouped into modules and the composition schema mechanism uses a configuration approach: a configuration manager checks the association of the different module versions to compose a schema. A schema is thus considered as a configuration of modules.
We have implemented a prototype using the Adele software configuration man-ager, which relies on its own active data base. A prototype of multiple evolution policies has been developed, requiring 1000 code lines: 700 lines to develop the kernel, 200 lines to write the default evolution policy and 100 lines to develop the standard library of evolution semantics. Evolution semantics are easily defined with the Adele language and we have found a great flexibility when defining new policies. For instance, it suffices to add one relation class (comp encore) and 50 code lines to the default evolution policy to express the evolution policy of the Encore system.
Class versions have been introduced by others, we only extended this versioning distinguishing revision and variants as it is usual in software engineering, and later grouping classes in modules. In all work we know, class evolution control is imposed, at least to a large extent, by the tool. The major contribution comes from the fact we made explicit and easily definable class evolution policies, and schema evolution policies. We believe that our system is able to accept, simultaneously, the execution of multiple schema evolution policies; typically each class of application can be associated with a different policy. So far other system propose multiple schema views, but not multiple schema evolution policies.
We also believe our system will contribute in showing how techniques com-ing from software configuration management, (versioncom-ing and configuration descrip-tions), active data base (triggers) and meta modelling (explicit classes as entities)
can be put together to propose a simple and elegant solution to this difficult problem. Conversely, this is a drawback, since no single commercial system proposes all these features, which may explain why, this has not been investigated and commercially available so far.
REFERENCES
[1] Ahmed, S.—Wong, A.—Sriram, D.—Logcher, R.: Object-oriented database
management systems for engineering: a comparison journal of Object Oriented Pro-gramming, June 1992, pp. 27–43.
[2] Ahmed-Nacer, M.: Schema evolution in software engineering databases. PhD
the-sis, INPG – IMAG Grenoble, France 1994 (in French).
[3] Andany, J.—Leonard, M.—Palisser, C.: Management of schema evolution in
database. In Proc. of the 17th VLDB Conf., Barcelona 1991, pp. 161–170.
[4] Banerjee, J.—Kim, W.—Kim, H. J.—Korth, H. F.: Semantics and
implemen-tation of schema evolution in object oriented databases. Proc. of the ACM SIGMOD conference, San Francisco 1987, pp. 311–323.
[5] Banerjee, J.—Chouand, H. T.—Garzaa, J. F.—Kim, W.—Woelk, D.— Ballou, N.—Kim, H. J.: Data model issues for object-oriented applications. ACM
Transactions on Office Information Systems, Vol. 5, 1987, No. 1, pp. 3–26.
[6] Barbedette, G.: Schema modifications in the LISPO2 persistent object-oriented
language. In Proceedings of ECOOP’91 (P. America, ed.), LNCS 512, Geneva, Switzerland, July 1991, Springer-Verlag.
[7] Belkhatir, N.—Estublier, J.—Melo, W. L.—Ahmed-Nacer, M.:
Support-ing software maintenance evolution processes in the Adele system. In Proc. of the 30th annual ACM Southeast Conf (Pancake, C. M. and Reeves, D. S., eds.), Raleigh, NC 1992, pp. 165–172.
[8] Belkhatir, N.—Ahmed-Nacer, M.: Major issues on PSEE. Information Sciences
Journal, Vol. 83, March 1995, No. 1 and 2, pp. 1–21.
[9] Bielikova, M.—Navrat, P.: Modelling software systems in configuration
manage-ment. Applied Mathematics and Computer Sciences, Vol. 5, 1995, No. 4, pp. 751-764. [10] Bjornerstedt, A. and Hulten, C.: Version control in an Object-Oriented
Archi-tecture. In Object-Oriented Concepts, Databases, and Applications (Won Kim and Frederick H. Lochovsky, eds.), Addison-Wesley, 1990, Chapter 18, pp. 451–485. [11] Bratsberg, E.: Unified Class Evolution by object oriented views. Proc. of the 11th
Int. Conf. on the relationship approach, LNCS N0645, Springer Verlag, October 1992. [12] Butterworth, P.—Otis, A.— Stein, J.: The Gemstone object management. In
Comm. of the ACM, Vol. 34, 1991, No. 10, pp. 64–77.
[13] Cattel, R.: The object database standard. In ODMG – 93 (Cattel, R., ed.), Morgan
Kaufmann 1993.
[14] Chen, P. S.: The entity-relationship model-towards a unified view of data. ACM
[15] Clamen, S. M.: Type evolution and instance adaptation. Technical Report
CMU-CS-92-133, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213-3890, USA, 1992.
[16] ECMA-PCTE: Standard ECMA-149 Portable Common Tool Environment (PCTE).
Abstract Specification. Technical report, 1993.
[17] Estublier, J.: Configuration management: the notion and the tools. Workshop on
Software Version and Configuration Control, TubnerVerlag, Grassau 1988.
[18] Ferrandina, F.—Meyer, T.—Zicari, R.—Ferran, G.—Madec, J.: Schema
and database evolution in the O2 object database system, VLDB’95, Zurich 1995, pp. 170–181.
[19] Ferrandina, F.—Meyer, T.—Zicari, R.: Measuring the performance of
imme-diate and referred updates in object database systems. OOPSLA Workshop on object database behavior, Benchmarks and Performance, Austin, Texas 1995, pp. 1–6. [20] Ferrandina, F.—Meyer, T.—Zicari, R.: Implementation lazy database updates
for an object database system. 20th VLDB Conference, Santiago, Chile 1994, pp. 261–272.
[21] Godart, C.—Charoy, F.: Bases de donnes pour le gnie logiciel. In Masson (ed.),
1992.
[22] Lerner, B. S.—Habermann, A. N.: Beyond schema evolution to database
reor-ganization. SIGPLAN Notices, Vol. 25, 1990, No. 1, pp. 67–76.
[23] Monk, S.—Sommerville, I.: Schema evolution in OODBs using class versioning.
SIGMOD RECORD, Vol. 22, 1993, No. 3, pp. 16–22. [24] Object Store 6.01 reference.
[25] Odberg, E.: Multiperspectives: The classification dimension of schema modification
management for object-oriented databases. In proceeding of TOOLS USA’ 94, Santa Barbara, California, August 1994.
[26] Oracle 8 SQL Reference. Release 8.0. A58225-01.
[27] Perdersen, C. H.: Extending ordinary inheritance schemes to include
generaliza-tion. Proc. of the OOSPSLA’89, New Orleans 1989, pp. 407–417.
[28] Penny, D.— Stein, J.: Class modification in the Gemstone Object-Oriented
DBMS. Proc. of the ACM Conf. on Object-Oriented programming, Orlando 1987, pp. 111–117.
[29] Skarra, A. H.—Zdonik, S. B.: Type evolution in an Object-Oriented Databases.
In Research Directions in Object-Oriented (Shriver, B. and Wegner, P., eds.), MIT Press 1986.
[30] Young-Gook, Ra—Rundensteiner, E. A.: A transparent Object-Oriented
Schema Change Approach Using View Evolution. Technical Report CSE-TR-211-94, Dept. of EECS, Univ. of Michigan, Feb. 1994.
[31] Zdonik, S. B.: Object-Oriented type evolution. In Advances in Databases
Program-ming Languages (Kim, W., ed.),, ACM Press 1990, pp. 277–293.
[32] Zeller, A.—Snelting, G.: Unified versioning through feature logic. ACM
[33] Zicari, R.: Primitives for schema updates in an Object-Oriented database system. In
Building an object-oriented database system (Bancilhon, F., Delobel, C. and Kanel-lakis, P., eds.). The story of O2, Chapter 7, Morgan Kaufmann 1992.
[34] Zicari, R.: A framework for schema updates in an object oriented database system.
Proceeding of the 7th International Conference on Data Engineering, Kobe, Japan 1991, pp. 2–13.
Manuscript received 30 January 1996; revised 12 April 1999
Mohamed Ahmed-Nacer received the PhD degree in
com-puter science from the Polytechnic National Institute INPG) in Grenoble, France in 1994. He is a research scientist in the Computer engineering Laboratory of Grenoble University. His current research interests are in process modelling and database schema evolution.
JackyEstublieris a research director at the National
Depart-ment of Scientific Research (CNRS). He is responsible of the soft-ware engineering team in the Computer Engineering Laboratory at Grenoble University. His research interests are in software databases, configuration management and process modelling.