Hadoop Based Link Prediction
Performance Analysis
Yuxiao Dong, Casey Robinson, Jian Xu
Department of Computer Science and EngineeringUniversity of Notre Dame Notre Dame, IN 46556, USA
Email: [email protected], [email protected], [email protected]
Abstract—Link prediction is an important problem in social network analysis and has been applied in a variety of fields. Link prediction aims to estimate the likelihood of the existence of links between nodes by the known network structure. The time complexity of link prediction algorithms in huge-scale networks remains unsolved, especially for sparse networks. In this project, we explored how parallel computing speeds up link prediction in huge-scale networks. We implemented similarity based link prediction algorithms based on MapReduce, which have the time complexity ofO(n)in sparse networks. We analyzed the perfor-mance of our algorithms on the Data Intensive Science Cluster at University of Notre Dame. We evaluate the performance with different configurations, monitor the resource utilization of the distributed computation, and optimize accordingly. After analyzing the efficiency with different configurations, we show that 6 reducers is optimal for the Live Journal data set and allows for simultaneous runs.
Index Terms—Social network analysis, Link prediction, MapReduce, Parallelization
I. INTRODUCTION
Social networks are an important part of our society. These networks are in constant flux and understanding how nodes relate is of great interest. Barab´asi demonstrated that networks expand continuously by the addition of new vertices which preferentially attach to existing, well connected vertices [1]. Many researchers have studied the network evolution and modeling the dynamic network structure [2]–[4].
Link prediction is used to understand and identify the mech-anisms of network growth and evolution. Link prediction aims to estimate the likelihood of the existence of links between nodes based on the known network structure information. The classical problem of link prediction is the prediction of existing yet unknown links - called missing links. Most of previous work on link prediction employs cross-validation by splitting the data into two sets: training and testing.
Consider this motivating example. People in the real world meet new friends. The relationship is represented by the appearance of a new connection in his or her social graph. Through the new relationship, both people’s social circle enlarges. Predicting these relationships before they are formed is vital to the success of a social networking service. Link prediction attempts to address the issue of discovering future connections.
We can experience the results of link prediction through the friend recommendation engine on Facebook. However, there
are now more than 1 billion users on Facebook. The massive scale is an impediment to fast and successful prediction. Moreover, beyond friend recommend engines, currently there is no framework for solving general link prediction problem in big data. A scalable and efficient solution is needed.
Challenge: The major challenge of link prediction stems from the sparse, yet gigantic, nature of social networks. A sparse network implies that the existing links between nodes represent a small fraction of the total possible links. Employing link prediction with gigantic networks years of computation time.
To solve the strongly unbalanced data between unexisting links and existing links, we can undersample the holdout test set [5] or only sample negative instances in the test set [6]. Modifying the sampling method changes the data distribution and the data no longer presents the same challenges at the real-world distribution. Since the algorithm no longer reflects the capabilities and limitations of the prediction model, the results are uninterpretable [7].
Thus, parallelization is the only feasible and meaningful method for studying link formation and consequently pro-viding the motivation for our work. Three designed patterns, based on MapReduce, have been proposed to speed up network analysis algorithms [8]. PEGASUS is a MapReduce based framework for graph mining which implements most of the classical graph mining algorithms [9].
The MapReduce framework, with good scalability and good performance for big data, is ideal for the large-scale link pre-diction problem. Although a large amount research has been conducted on MapReduce based graph mining, no MapReduce framework exists for link prediction. In this project, we design, implement, and analyze the performance of similarity based link prediction algorithms on Data Intensive Science Cluster at University of Notre Dame. In addition, the analysis also show that our approach is suitable for running multiple link predicting computations. Our implementation is not limited to social network, but can solve general link prediction problem that involve big data.
II. RELATEDWORK
Our work is related to link prediction and graph mining in huge-scale networks. Link prediction has attracted consid-erable attention in recent years both from computer science
and physics community. Existing work can be classified into two categories: unsupervised methods [10] and supervised methods [7], [11]–[13]. Most unsupervised link prediction algorithms are based on a similarity measure between nodes of graph. A seminal work by Liben-Nowell and Kleinberg for unsupervised methods addresses the problem from an algo-rithmic point of view. The authors investigate how different proximity features can be exploited to predict the occurrence of new links in social networks [10]. For the supervised methods, Lichtenwalter et al. motivated the use of a binary classification framework and vertex collocation profiles [7], [11]. Place features can be exploited into the supervised model for link prediction on location-based social networks [12]. To recommend friends on Facebook, a supervised random walk is designed for link prediction and recommendation [13].
Recently, the focus of graph mining is huge-scale networks. In 2004, Google presented its MapReduce framework for large-scale data indexing and mining [14], which guides the direction of analyzing big data. Three design patterns, based on MapReduce, to speed up nework analysis algorithms have been proposed [8]. Moreover, Kang et al. propose two frameworks for huge-scale graph management and analysis: one is GBASE [15]: a scalable and general graph management and mining system based on MapReduce, the other one is a MapReduce based spectral analysis system in billion-scale graphs [16]. Then Yang et al. propose a Self Evolving Distributed Graph Management Environment for partition management of large graphs [17].
The existing work either focuses on link prediction in a par-ticular network without consideration for general parallelized design of large-scale networks, or focuses on parallelized graph mining in large-scale graphs but not optimized for the link prediction problem, but not both. Here we make use of the scalability and performance advantages of MapReduce for big data and propose an optimized framework for large-scale link prediction problem.
III. OVERVIEW
In this project, we demonstrate how link prediction al-gorithms benefit from parallel computing. We evaluate the performance of our Hadoop implementation on Data Intensive Science Cluster (DISC) at University of Notre Dame.
We design the parallelized strategy for link prediction algorithms using MapReduce model, test the the validity and performance of our MapReduce implementations on DISC, and demonstrate how the number of Mapper tasks and Reducer tasks affect the overall performance. In addition, we explore how graph properties influence the performance of the link prediction problem by testing graphs of different size, type, and clustering coefficient.
Finally, we seek to analyze the microscopic details of our implementations. We will monitor the resource utilization of the program, find computation bottlenecks, and attempt to improve our implementation. We will monitor the load balance by comparing completion time in different nodes.
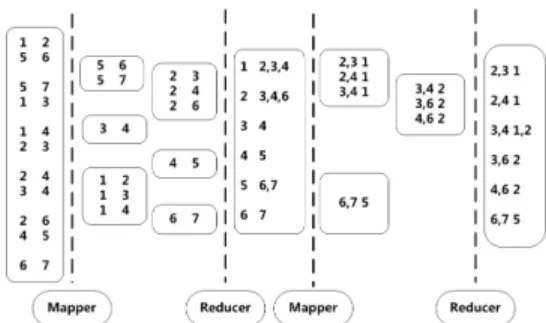
Fig. 1: The coreMapReduceprocess for our algorithms.
Communication time between nodes is an important factor which will also be explored.
Big data is divided into small parts for distributed com-putation and parallel comcom-putation can be utilized to reduce the link prediction time. We discover issues that will affect the performance and propose the best approach of performing parallelized link prediction for big data using DISC. The core parallelized solution for our framework is shown in Figure 1. DISC contains 26 nodes, consisting of 32 GB RAM, 12 x 2 TB SATA disks, 2 x 8-core Intel Xeon E5620 CPUs @ 2.40 GHz, and Gigabit Ethernet, which is sufficient for big-data manipulation. The software required is Hadoop and the Java runtime environment, both are already installed.
IV. EVALUATIONSETUP
The main thrust of our research is to investigate the performance of link prediction algorithms. Our evaluation approach is divided into three parts. Each part will be focused on reducing the number of variables to explore at the next level down. We will start with a macroscopic analysis by treating our link prediction implementation as a black box. The lowest level looks at individual machines and attempts to find performance bottlenecks.
We use five data sets as the basis for our evaluation. The data sets range from small (12,000 nodes, 237,000 connections, and 3MB) to large (4.8M nodes, 68M connections, and 1GB). The data sets each represent different types of graphs: citation networks, collaboration networks, social networks, and web networks. See Appendix??for a detailed description of each data set.
We analyze the performance at a variety of levels; each providing a unique perspective of the system. To evaluate the macroscopic behavior of our link predictor we wrapped the entire system with a timer; allowing us to obtain a measurement of the completion time of each run. We chose to use this metric for performance because it is the most relevant to an end user.
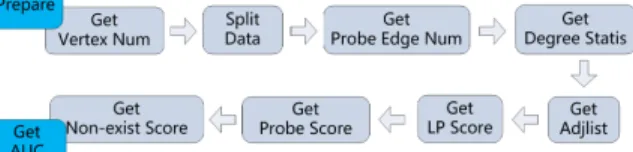
At the next level down, we measure the running time of each hadoop submission. Our implementation consists of ten consecutive Hadoop jobs as demonstrated in Figure 2. The breakdown of time provided at this level allows us to focus our detailed analysis at the next level. Focused testing is important because each evaluation run lasts many hours.
Fig. 2: Steps involved in Link Prediction
The lowest level explores the performance of the most time consuming Hadoop submissions. In this level we analyze disk I/O, network traffic, and CPU usage. The information gained from theses tests allows us to pinpoint performance bottlenecks and recommend future improvements specific to the machines we are using.
V. RESULTS
In this section, we examine the scalability and efficiency of our MapReduce based link prediction framework from three aspects: overall performance, graph influence, and breakdown performance.
A. Overall performance
The highest level analyzes the total running time while varying the number of Reducers as well as the data set under observation. Before discussing the performance of our framework, we first analyze the tradeoff of the number of reducers.
Tradeoff. By varying the number of Reducers from 1 to
50 for the ND Web data set, in Figure 3(b) we see that the average completion time follows three distinct trends. First is the rapid decrease occuring between 1 and7 reducers. Here we witness the benefits of parallelization: with few reducers the work is under-parallelized. In other words, each Reducer is operating at maximum throughput.
The second trend is a steady state where the average time does not increase or decrease. At this stage the benefits of additional Reducers is approximately equal to the additional overhead.
On the right portion of the graph, 25 to 50 reducers, we observe an increase in completion time. Here, the amount of data in each chunk is sufficently small, causing the setup time to dominate the total run time.
The performance for the ND Web data set has a large variance. We attribute the unpredictable behavior to overhead of disk access and network I/O in this distributed computation platform. This overhead is important for the smaller data sets since the data processing portion of our framework is much shorter than in the large data sets. However, while the overhead of Hadoop based link prediction still exists for a larger data set, the Live Journal, the variance of performance is much smaller, which is shown in Figure 3(c). Because the Live Journal data set is of magnitudes larger than the ND Web one, more time is spent on the actual computing the scores for potential links, thus the variation caused by the overhead of distributed computing is a small percentage of the total run
TABLE I
RUNNING TIME ON DIFFERENT DATA SETS WITH25 REDUCERS Data set Time (s) Relative Size
HepPh Collaboration 94.9±23.1 1×
ND Web 1089±192 7.14×
LiveJournal 6818±414 357.78×
time. As a consequence, our implementation of Hadoop based link prediction has been shown to be suitable for big data.
Scalability.We use Live Journal data set as a representative of big data to see how our approach of parallel computing can help speed up the performance. Ideally, if the overhead of distributed computation can be ignored, and the job is evenly distributed to the computing nodes, the job will complete in
t = NT = T N−1, where T is the time to complete the job on a single machine, andN is the number of Reducers which is no more than the number of computers. However, as the overhead of distributed computation such as distributing the job to different computers and collecting the results through network does exist, the completion of time cannot be as good as a inversely propotional function, in other words, the power ofN cannot be ideally−1, but should lie between−1and0. Note that −1 < α < 0 delivers a concave curve, the speed-up increases first rapidly then slowly as the number of Reducers increases. This indicates that if we have multiple jobs running on the same distributed computing cluster, for each job we can set a relatively small number of Reducers for optimal overall performance. For example, if we want to simultaneously run link prediction on four data sets that are of similar size as the Live Journal data set, we can set the number of Reducers R= 6 for every job, so that every job sees the benefits of parallelization, while4∗R = 24<25minimizes the overhead of running multiple reducing procedures on a single machine.
B. The impact of graph properties
Besides the Reducer parameter, we also investigate the impact of graph properties on computation time in the highest level. We control the variables by using fixed 25 Reducers and analyze the performance on small, medium and large networks1, shown in Table I.
Graph Size.From Table I we see that the time consumed for different graphs is proportional to the number of nodes in the graph, or we can say, our approach has a time complexity of O(N). The reason is that the link prediction algorithm we used is based on common neighbors. As a consequence, if two nodes do not have a common neighbor, the score of connection between these two nodes must be 0. In other words, if node a and b have a common neighbor c, then a
and b must simultaneously exist in Adj[c], otherwise a and
b will never coexist in the adjacency list of any node. With this fact, we only have to calculate the scores of connections in the adjacency list, rather than to calculate the scores of connections between every two nodes.
(a) HEP Physics (b)ND Web (c)Live Journal Fig. 3: Runtime with varying numbers of reducers
Time complexity analysis. The observation that we do not have to compute scores for every potential connection significantly reduces the time complexity of our approach. If the average degree of nodes in the network isk= 2E/N, then for the adjacency list of every node, the number of pairs to deal with is k(k2−1), and the total numbers of scores to compute for the whole network is k(k−21)N. As a result, the time complexity for link prediction based on common neighbors is O(N k2), and space complexity O(N k).
Barab´asi and Albert proposes the power law distribution of degrees in real-life networks [1], i.e., the probability that a node has a degree of k is inversely propotional tok. As a consequence, the degrees of most nodes in empirical networks are small, giving us a small average degree. Therefore, for real-life networks which are big but sparse, the time complexity of link prediction based on common neighbors is O(N). In our Hadoop based link prediction implmentation, since the data will be distributed to multiple processing units, the time complexity isO(N/U), whereU is the number of computing nodes.
C. Breakdown of jobs
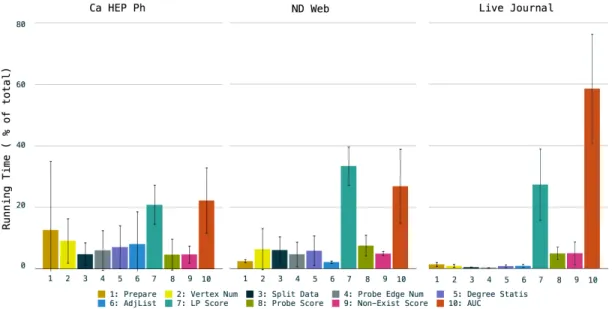
To analyze which procedures take the most time in our implementation, we breakdown the jobs for a more insightful performance analysis. Our implmentation consists of ten con-secutive Hadoop jobs which are shown in Figure 2. Again we control the variables by using fixed 25 Reducers and analyze the performance of the ten consecutive procedures for small, medium and large networks, as shown in Figure V-C.
Heavyweight jobs.In all three of these breakdown graphs, the seventh procedure getLPScore and the tenth procedure
getAUC occupy the majority of the time. The prominence of these two procedures is within expectation: getLPScore is the procedure that actually computes the scores for potential connections with the algorithm based on common neighbors. As analyzed above, the time complexity of getLPScore is
O(N). The reason that getAUC takes another big share of total time is different from that of getLPScore. In this last step, the scores of potential links that are stored on the
25 machines need to be transfered via the network to the controlling machine, during which the overhead of disk opera-tions and network communication is heavy and non-negligible. Also, after collecting and merging the results from those 25
machines, the calculation of AUC score must be completed on the controlling machine. The calculation of AUC score further
makes the proceduregetAUCunder-parallelized, therefore this step grows in superlinear time against the network size. In a word, the larger the network, the more proportion the last step
getAUC will take.
Procedures 1–6 can be completed in constant time, such as splitData, or in sublinear time, so getLPScore takes a larger proportion of time compared with procedures 1–6 when dealing with bigger data sets.
Lightweight jobs. Based on the analysis above, proce-dures 1–6 can be completed in constant time or in sublinear time, which coincides with the actual experiment running time. We can read more from the breakdown of jobs. For example, in data sets HepPh Collaboration and Live Journal,
getAdjList (Procedure6, the grey bar) is slightly higher than
getDegreeStats (Procedure 6, the purple bar), while in ND Web,getAdjList is noticeably lower thangetDegreeStats. This phenomenon is due to time complexity ofgetAdjListisO(E), while the complexity of getDegreeStats is O(N). As the average degree is proportional to E/N, we can infer from the breakdown that the average degree in ND Web data set is smaller than that of the other two data sets. Our inference can be verified that the average degree of nodes of ND Web data set (≈ 4.6) is indeed less than that of HepPh Collaboration (≈19.7) and that of Live Journal (≈ 14.2). As we can see, the breakdown graphs reflects the nature of algorithms we used as well as the intrinsic properties of networks.
Last but not least, the breakdown graphs confirm our approach works better on big data sets than on small ones. The error bars in the median-sized network ND Web and in the large-sized network Live Journal are good, while in the small-sized network HepPh Collaboration the variation is not acceptable. Also, the actual two steps of performing link prediction (Procedure 7 and 10) in the small data set comprises of less than half (44%) of the total time, indicating the efficiency of Hadoop based link prediction on small data sets is unsatisfactory, while on large networks such as Live Journal the efficiency is much higher (85%).
D. Resource Monitoring
At the lowest level of performance analysis we measure the CPU usage, disk access, and network traffic to each of the DISC machines. To interpret the measurements we first need to analyze the system specifications for each machine. Every computer in the cluster has32GB of RAM, four disks dedicated to hadoop storage,16processing cores, and gigabit
Fig. 4: Time Breakdown with 25 Reducers
ethernet. To monitor the utilization of each resource we run
iostat andnetstat with various flags and store the results to a file. We also place a timestamp at the beginning of each file to enable synchronization of data across all of the machines. In order to find bottlenecks we will look at overall utilization across all machines in the cluster.
The results for each resource are displayed in a composite graph with the x-axis representing time and the y-axis showing the resource utilization. There is no averaging or combination of data because these transformations would disguise the bottleneck. The data collected from each machine is overlayed on the same plot. This presentation choice produces a plot which displays an aggregate summary of the data. We are not concerned with the utilization at any given machine. Since mappings and reducings can be run on any machine the aggregate statistics are more useful to analyze performance over multiple runs.
First we will look at the CPU usage of the cluster. Figure V-D shows the percentage of CPU utilization while running our link prediction framework with the Live Journal data set. The two sections of interest, LP Score and AUC, are highlighted with a red bar. In LP Score the CPU utilization is 25% on average, with brief spikes to 80%. These results indicate that CPU is not the bottleneck for LP Score com-putation. Beyond the first 20 seconds of AUC CPU usage is 6% on average, which is the equivalent of one individual processing core. This phenomenon is likely to happen if the AUC job is not parallelized, but rather it is running on one core. The hypothesis has been verified by monitoring top
during subsequent runs and analyzing the source code. The use of one core is a strong indication that CPU is a bottleneck for AUC.
Next we discuss disk usage. The number of blocks read, figure V-D, are less than10%of total disk throughput capacity, thereby proving that reading data is not a bottleneck in our
Fig. 5: CPU Utilization during Live Journal Run
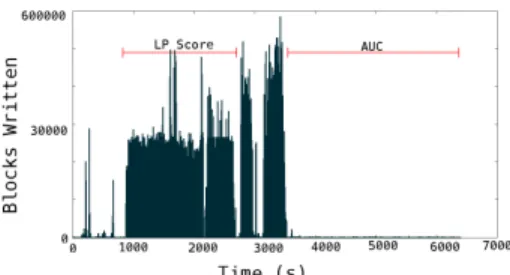
system. Figure V-D shows the number of blocks written. No blocks are written during the AUC computation; providing further evidence that CPU is the bottleneck for AUC. During LP Score the DISC machines continually write300,000blocks per second, which corresponds to100%usage of the storage system. Thus the number of writes is a bottleneck for LP Score.
Fig. 6: Disk reads during Live Journal Run
Finally we investigate the network traffic throughout the cluster. Figure V-D contains the amount of data received by each machine. Both LP Score and AUC never reach 1Gbps. Thus, receiving data is not a bottleneck for either process.
Fig. 7: Disk writes during Live Journal Run
The same conclusion holds for outbound traffic in AUC. However, every machine reaches1Gbpsoutbound traffic for an extended period of time during LP Score as showin in figure V-D, and occupies the network bandwidth of DISC cluster to the maximum capacity. Consequently, introducing another bottleneck for LP Score.
Fig. 8: Inbound Traffic during Live Journal Run
Fig. 9: Outbound traffic during Live Journal Run After analyzing the data we have found the bottlenecks for LP Score and AUC. In LP Score the bottlenecks are outbound network traffic and disk writes. The disk writing bottleneck may be removed due to an abundance of RAM in the machines. It may be possible to store all intermedary data in memory. The main bottleneck in AUC is CPU. Our implementation only uses a single core on one machine, while theoretically the computation consists of 39 million independant calculations. Therefore it is possible to parallelize this algorithm with either map reduce or threading.
VI. CONCLUSION ANDFUTUREWORK
In this project, we developed a link prediction framework for large-scale networks using MapReduce. We tested the framework on three data sets of different size and monitored the performance. We divided our analysis into three levels.
In the top level, we treated our system as a black box and measured the total run time with different numbers of reducers. Our system works better for data sets larger than
1 GB. Increasing the number of reducers beyond 6 produces negligible improvements in total run time.
For the next level, we narrow our search for bottlenecks by measuring the run time of each Hadoop submission. For the Live Journal data set, we found the LPScore and getAUC jobs requires the most amount of time up to 85% of the total run time.
After we found the two most time-consuming jobs in our framework, we monitored the resource utilization on each machine and determined the bottleneck for LPScore and getAUC. For LPScore the bottleneck was disk writes and network transmit, whereas for getAUC the bottleneck was CPU usage.
Future work is to alleviate these bottlenecks. For LPScore we can store the data in memory instead writing to the disk because it is not used in the future. With getAUC the computation is not fully parallelized. Either threading or MapReduce can be applied to improve the performance.
REFERENCES
[1] A.-L. Barab´asi and R. Albert, “Emergence of Scaling in Random Networks,”Science, pp. 509–512, 1999.
[2] L. Backstrom, D. Huttenlocher, J. Kleinberg, and X. Lan, “Group formation in large social networks: membership, growth, and evolution,” inKDD’06, 2006, pp. 44–54.
[3] J. Leskovec, L. Backstrom, R. Kumar, and A. Tomkins, “Microscopic evolution of social networks,” inKDD’08, 2008, pp. 462–470. [4] J. E. Hopcroft, T. Lou, and J. Tang, “Who will follow you back?
reciprocal relationship prediction,” inCIKM’11, 2011.
[5] M. A. Hasan, V. Chaoji, S. Salem, and M. Zaki, “Link prediction using supervised learning,” inWorkshop on LACS of SDM’06, 2006, pp. 322– 331.
[6] C. Wang, V. Satuluri, and S. Parthasarathy, “Local probabilistic models for link prediction,” inICDM’07, 2007, pp. 322–331.
[7] R. N. Lichtenwalter, J. T. Lussier, and N. V. Chawla, “New perspectives and methods in link prediction,” inKDD ’10. ACM, 2010.
[8] J. Lin and M. Schatz, “Design patterns for efficient graph algorithms in MapReduce,” inMLG ’10, 2010.
[9] U. Kang, C. E. Tsourakakis, and C. Faloutsos, “Pegasus: A peta-scale graph mining system implementation and observations,” inICDM ’09, 2009.
[10] D. Liben-Nowell and J. Kleinberg, “The link prediction problem for social networks,” inCIKM’03. ACM, 2003.
[11] R. N. Lichtenwalter and N. V. Chawla, “Vertex collocation profiles: subgraph counting for link analysis and prediction,” inWWW’12, 2012. [12] S. Scellato, A. Noulas, and C. Mascolo, “Exploiting place features in link prediction on location-based social networks,” inKDD ’11. ACM, 2011.
[13] L. Backstrom and J. Leskovec, “Supervised random walks: predicting and recommending links in social networks,” inWSDM’11, 2011, pp. 635–644.
[14] J. Dean and S. Ghemawat, “MapReduce: Simplified data processing on large clusters,” inOSDI’04, 2004, pp. 10–10.
[15] U. Kang, H. Tong, J. Sun, C.-Y. Lin, and C. Faloutsos, “GBASE: a scalable and general graph management system,” inKDD ’11, 2011. [16] U. Kang, B. Meeder, and C. Faloutsos, “Spectral analysis for
billion-scale graphs: discoveries and implementation,” inPAKDD’11, 2011. [17] S. Yang, X. Yan, B. Zong, and A. Khan, “Towards effective partition