Available at http://www.ijcsonline.com/
Towards Security and Authorization Based Data Deduplication Using Hybrid
Cloud
Tushar Bhimrao Meshram Ȧ, Prof. Sujata DeshmukhḂ
Ȧ
Computer Engineering Department, University of Mumbai, India Ḃ Computer Engineering Department, University of Mumbai, India
Abstract
Cloud computing is mostly used technology these days, it allows users to share and store the data, online utilization of services and resources on various types of devices. One of the important challenge of cloud computing is the management of the increasing volume of data stored at the cloud servers. To look at this problem data deduplication technique is being applied. To save bandwidth and storage area in cloud Data Deduplication is an important technique to reduce repeated data.
Although deduplication has lots of benefits but it also adds concerns to privacy and security of data as it can lead to insiders and outsiders attacks. To have secure data deduplication in cloud environment makes it more difficult. To have protection and confidentiality of sensitive data along with supporting data deduplication, the technique called convergent encryption has been proposed to encrypt the data before sending it to the storage servers. To protect security of data better, this paper makes an attempt to address the authorized data deduplication. Other than traditional data deduplication systems differential privileges of the users are also being taken into knowledge while duplicate check besides the data itself. Here we also provides several traditional deduplication system and addressed their problem using our hybrid cloud approach.
Keywords: Deduplication, Convergent encryption, Authorized duplicate detection, Confidentiality, Hybrid cloud
I. INTRODUCTION
Cloud computing technology is the more highly popular technology in these days. Every computer user knowingly or unknowingly regularly uses cloud services in its day to day life, it could be during using social networking sites or mailing sites or many others. Network giants such as Facebook, Google ,Gmail, Amazon etc. are using these cloud resources to stored there huge amount of data. As cloud computing becoming popular these day, the amount of data is being stored in the cloud and shared by users is also increased. One important challenge of cloud space is the management of the ultimate-increasing volume of data space.
To handle the data in the cloud, data deduplication[18] technique is being applied. Data deduplication[5][9] is a special data minimizing technique for eliminating matching copies of repeated data in the cloud storage. So this type of process is being used to increase the storage usage and could be used for network data transfers to decrease the number of bytes that are to be sent by the network cables, inspite of having the many such copies with the similar contents, data deduplication technique eliminates matching data by keeping only one copy set and then referring other similar data to that file. Deduplication of Data occur at file level or block level.
In case of deduplication at files level[20], a complete file is used for checking for if any other file
with similar data is present or not. If the same data copy is found then another copy of same file will not be stored. Advantages of file level deduplication is that it just need less metadata knowledge and is comparatively extremely easy to implement and handle it. In the case of deduplication at the block level [19], file is divided into chunk of same sizes or of at different sizes. At the time of deduplication, each chunk is being used for verification. In case similar chunk of same or other data is caught then the data deduplication stores only a reference to this chunk in spite of its all real contents[10].
Fig. 1. Deduplication of Data File at File and Block Level
techniques different users will generate different ciphertext for the same data which is not feasible for the deduplication to occur. To overcome these problem convergent encryption techniques is being used.
It performs decryption and encryption of a file with an convergent key which is found by applying cryptographic hash value of the content of the file . After generation of the encrypted data user keeps the key and send the ciphertext to cloud server. As the operation of encrypting data file is deterministic and is extracted from the data contents itself, same data copies will present the exactly same convergent key and the same ciphertext which makes deduplication feasible, if no duplicate is found the encrypted file will be going to uploaded to the server, and if duplicate is found a pointer to the stored file is provided to the user to retrieve that file later without storing it, to avoid unauthorized access a secured proof of ownership protocol [3] is applied to provide the proof that the user has the same file. To further enhance the security to have a differential authorized deduplicate check a hybrid cloud approach[21] is applied in which every user is provided with the set of privileges at the initialization of the system. Each and every files uploaded to the cloud storage server is also being bounded by a set of privileges[6] to point what kind of users is allowed to perform the duplicate check and access the files. The user of the file is only able to find the duplicate for his file if and only if there is a copy of that file and a matching privilege already stored in cloud. To upload or access the file the user first need to contact the private cloud if it authorizes the user then only user can do further checks for the duplicate.
II. KEY CONCEPTS
To understand this paper well we placed some key concepts here as follows
A. Convergent Encryption
Convergent encryption [1], [2] is used to provide data confidentiality in data deduplication process. The data owner retrieves the convergent key from original data then encrypts it with convergent key. In addition to it users also creates a tag for the data file, such that the tag will be used to find duplicate copy of the data file. Here it is assumed that tag correctness property [4] is being hold, means if two data are same, then their tags are also going to be the same. To find duplicate data, user initially send tag to server to check whether similar copy has been stored already or not. Now the convergent key and the its tag value for the file both of them are retrieved independently, and the tag could not be used to find the convergent key and decrease confidentiality of the data file. The data which is encrypted and its tag are going to be stored at server side.
B. Proof of Ownership
Proof of ownership (PoW) [3] makes users to verify their ownership over the data file to the cloud server provider. Actually, PoW is performed as an interactive algorithm run by a user i.e. prover and a storage server i.e. verifier. The verifier gets a short value ϕ(M) from a data
M. To verify the ownership of the data M, the user will have to send ϕ′ to the verifier so that the ϕ′ = ϕ(M).
C. Identification Protocol
A identification protocol can be used described with two terms: Proof and Verify. In the stage of Proof , user U can provide his identity to the verifier by doing some of the identification proof which are related to the users identity. The Input from the user is his private key skU which is a crucial information's like private key of a public key in the certificate or credit card number of him which he do not want to share with the different other users. Then the verifier does the verification with input of public information pkU which are related to the skU. In the end of the protocol the verifier may accept or reject to see whether the proof is passed or failed. There are too many identification protocols in the literature, which includes certificate-based, identity-based identification etc. [7][8].
D. Token Generation
For having authorized deduplication, the tag of the file F will be obtained by applying hash like SHA-1 to file F and the privilege . And to generate token from this tag a secret key kp will be attached with a privilege p and the file tag is being associated and then applied hash like HMAC-SHA-1 to create the file token. Let ϕ′Fp = TagGen(Fkp) denote the file token of file F which is only permitted to be accessed by the user with privilege p. As a result of this, suppose a file has been uploaded by a user which is having a token ϕ′F,p and which is duplicate, then the duplicate check of the file sent from another user be successful if he has the file F with the privilege p.
III. RELATED WORK
As we have discussed Deduplication is the technique to manage the ever increasing data in the cloud servers, but as deduplication provides lots of benefits it also has some security issues which are implemented by the external or internal advisories of the cloud infrastructure. To look up into these issues some deduplication techniques[20] were developed.
A. Encryption with client specific key
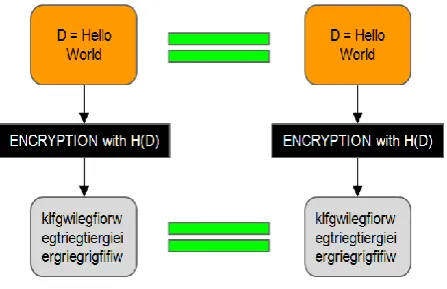
Fig. 2. Tradition Encryption not supporting Deduplication
B. Encryption with Convergent key
To support confidentiality while deduplication convergent encryption is found to be useful. At the time of convergent key encryption same key is being utilized to encrypt and decrypt the data copy as key is obtained by using cryptographic hash value of the data copy[11][12]. As the convergent key is obtained from data it generates same ciphertext for identical data. It helps to have data deduplication on cloud storage. But the limitation of convergent encryption technique is that it is compromised by the brute force attack for data or files falling into known sets. In the typical storage systems with deduplication enabled the client will first only send the hash value of the file, then cloud server will check whether its hash value of the file is already being present in its database or not. If file is present already on the server it will asks the client not to send the file again and marks client additional other owner of the file, the attacker monitors the network flow and determines nothing is transfer from the client side and can predict data is already stored or owned by the other user. So as seen above client side deduplication leads to security issues and could reveal other client has same file. This problem can be taken into the consideration by the proof of ownership protocol (PoW)[3].
Fig. 3. Convergent Encryption supporting Deduplication
C. Secure deduplication technique for Single cloud
Till now other above deduplication systems does not support differential authorization duplicate check, which is very important in many applications. In the system which is having authorization and deduplication, user is being assigned a set of privileges when user are added. The data file which is being added to the cloud server is also assigned a set of privileges which specify that which kind of users are permitted to the perform the duplicate check and allowed to access the data. At the time of duplicate check user required to take his file and privileges as inputs. The duplicate check happens only if copy of file and privileges that matches the user privileges is stored in cloud storage. This system works as follows.
Here Initially user is required to obtain the file token TagGen(F,kp) of the file as described in the section above. The main idea of this basic system is to provide corresponding privilege keys to every user, who will be going to compute the file tokens and do the duplicate check based on the privilege keys and files. In details, if there are N users within the system and the privileges in universe is defined as P = {p1,...,ps}. The set of keys {kpi}pi∈PU will also be assigned to the User U with the privileges set PU.
To uploading a file if a data owner has a privilege U with privilege set PU and wants to upload and share the file F with users who have the privilege set PF = {pj}. The user executes and sends the Cloud server Provider the token ϕ′Fp = TagGen(Fkp) for all p∈ PF.
If duplicate is found by the Cloud Provider then the user will performs proof of ownership of this data file with the Cloud Storage Provider. Suppose the proof is passed, the user will be provided with a pointer, which allows him to have the access to the file.
On the other hand if no duplicate is found, the user compute the encrypted file Cf = EncCE(kf,F) with the convergent key kf = KeyGenCE(F) and then uploads (CF,{ϕ′F,p}) to the cloud server. Convergent key kf which is generated from the file is stored locally by the user.
For accessing and downloading the file F It first send a request and the file name to the cloud storage provider. After receiving the request and file name, the cloud storage provider will check whether the user is eligible to download F or not. If not or he fails, the storage provider sends an cancel signal to the user to indicate unsuccessful in downloading. Otherwise, then the cloud provider will return the corresponding ciphertext Cf. After receiving the encrypted data from the cloud storage provider, the user uses the key kf which is stored locally to recover the original file F.
Although this technique is improved over above techniques but it also has some problems associated with it.
protect the security of predictable data files. One of the crutial reasons is that the traditional convergent encryption technique can only protect the semantic security of unpredictable files.
2) Every user is going to be provided with the private keys {kpi}pi∈PU for their respective privileges, which is being denoted by PU in the above construction. These private keys {kpi} pi∈PU can be provided by the user to creaate the token of the file for duplicate check of the data. As during file uploading, the user required to compute file tokens for sharing with other different users with privileges PF. For computing the token of the file, the user is also required to get know the private keys for the PF, which can be considered that PF could only be chosen from the set PU.
3) The above deduplication technique cannot prevent the privilege private key sharing which is done among the users of the files. The users will also be provided with the similar private key for the same privilege in this technique. As a result of this the users may collude and generate privilege private keys for a new privilege set P∗ which does not belong to any colluded user. Consider an example, a user with the set of privilege P'U1 may be collude with the another user with the set of privilege P'U2 to get a privilege set P∗=P'U1∪P'U2.
D. DupLess: Deduplicated storage by Server-aided encryption.
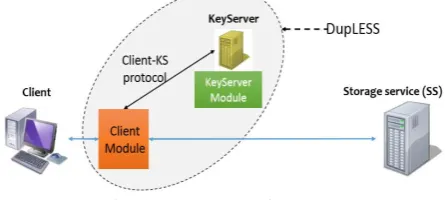
Fig. 4. Dupless Architecture
To handle the problem of convergent encryption to some extent The DupLESS system introduces a Key Server, here client first generates the hash of the data file and instead of using this as the key for encryption as in the case of traditional convergent encryption, this hash value is send to the key server. Using this hash value the key server generate the key to encrypt the file and send it to the client, which then encrypt the file using this key, and send it to the storage provider along with the key which also encrypted by the users secret key. Drawback is If an attacker get to know the secret, the whole of the system is compromised and the confidentiality of unpredictable files is no longer guaranteed. Also, this technique is limited to file-level deduplication and is not scalable in the case of block-level deduplication, which provides higher space savings.
E. ClouDedup: Cloud Storage with Secure
Deduplication using Encrypted Data
Fig. 5. ClouDedup Architecture
This technique works on block level, it consists of four main components - Client, Key server, Metadata manger and Cloud storage provider. This technique includes an addtional layer of the deterministic and symmetric encryption on the top of the convergent encryption. This extra encryption would be included by component placed between user and the cloud space provider such as a local server or gateway. This component will going to take care of the encrypting or decrypting of the data from or to the users. For permiting the cloud provider for finding the duplicates, encryption and decryption are being performed with one of the unique set of secret keys. This set of the secret keys is being securely stored by the component and would not be shared with anyone for any of the reason it may be. Here one more additional component is introduced called Metadata manager. The main aim of this extra component is to store the encrypted block keys (key management) and to perform data deduplication on this encrypted blocks[22].
Considering all everything at once, the structure of the system is as follows:
The number of users who, before uploading data files to the Cloud, split data into blocks, encrypt blocks with convergent encryption and send to the server (or gateway) the encrypted blocks together with their associated encrypted keys.
A server which then further encrypts the blocks and keys with a set of the unique and the secret keys. The metadata manager which updates the metadata (in order to again the structure of the each file) , which stores encrypted block of keys and then performs deduplication on encrypted blocks of data. Here those blocks can be stored that are already not there.
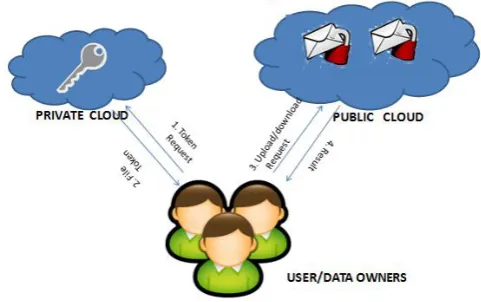
IV. HYBRID CLOUD APPROACH
To address the problem of the above construction Hybrid cloud approach[17][24] is being considered as secure and authorized deduplication[23]. This system uses multiple cloud architecture which contains public and private cloud. Here now the private cloud is a proxy cloud which permites data owners and users to securely perform check on the duplicate data using differential privileges[14]. Here Users stores data on the public cloud and data operation will be managed by private cloud. The user will be allowed to perform duplicate check for all those files with user privileges[13].
A. Goals to achieve
To support preserving privacy in the deduplication following things are to be achieved in this system
• Differential Authorization. Every authorized user is being able to get his file token to do the duplicate check of the data by looking to his privileges. Because of this the other user cannot be able obtain a token of the file for the duplicate check of the data out of his privileges or without any of the help of the private cloud.
• Authorized Data Duplicate verification. Each Authorized user is able to use his private keys to provide the query for the certain file and the privileges he owned with the aid of private cloud, on the other hand if any duplicate data is found the private cloud will notify which checks duplicate data.
• File token Unforgeability. Users without appropriate privileges or file should be prevented from getting the file tokens for duplicate check of files stored at the Cloud storage provider. The users are not permitted to collude with the public cloud server to breach the unforgeability of file tokens. The provider of Cloud in this system will faithfully perform the duplicate check on getting any duplicate request found from the users side. Duplicate check token of the users has to be provided from private cloud server in this scheme.
• File token Indistinguishability. Any user without querying or requesting the private cloud server for some file token, cannot get any useful information from the file token, which has the file and privilege information.
• Data Confidentiality. Unauthorized users without having the appropriate privileges and the files should be prevented from the access to the underlying plaintext stored at the Cloud Storage Provider. In another word the main aim of the adversary is that to obtain the files that do not belong to them. In this system a higher level confidentiality is defined and achieved.
Fig. 6. Authorized Deduplication Architecture
B. Elements of the System
There are three important entities in this approach which are important for secure authorized deduplication they are as follows
a) User: In this system the user is considered as an entity who wants to store data on cloud server. Every user is being given a set of privileges consider an example, we may define a role based privilege [4] or according to job positions (for example. The The Director and the technical lead and the engineer), or time-based privileges which indicate validity of the time period. A user lets Ramesh be assigned two privileges “technical lead” & “access right valid till "2016-08-08”, so that Ramesh can access any file whose access role is “a technical lead” which is accessible till "2016-08-08". The system with the data deduplication technique will not upload any of the duplicate data to the server in order to the save bandwidth.
b) Private Cloud: This is a new entity for permitting the users for secure use of cloud services. Private keys for the privileges are being maintained by the private cloud servers , the role of it is to provide the token of the files to the users The interface offered by the private cloud server allow users to publish files and query to be securely stored and computed it accordingly.
c) Public cloud: This entity provides data storage service. To decrease storage cost in the system it try reduces redundant data by performing deduplication.
going to check and verify the identity of the user's before giving the corresponding token of the files to the user. This authorized data duplicate check for this data file is also performed by the user with the public cloud server before uploading of this file. On the basis of the results of duplicate check, the user either uploads this file or runs Proof of ownership.
At this system one binary relation R = {((p,p′)} is being given for the two privileges p and p′, p matches with the p′ if R(p,p′) = 1.In the case of the hierarchical relation, if p is at higher-level privilege then p matches with the p′. If in a enterprise , there are three hierarchical privilege levels are given as for Director, Project leader, and Engineer there Director would be at the high level and the Engineer is at the below level. In this example, the privilege of the Director matches with the privileges of the Project lead and the Engineer.
Setup. At this system P is considered as privilege universe and kpi as symmetric key for every pi ∈ P will be defined and the {kpi}pi∈P keys set will be sent to the server of private cloud. A protocol Π = (Proof,Verify) is considered as identification protocol is defined, where Proof and Verify are the proof and verification algorithms respectively. Each user U is considered to be having a secret key skU for performing the identification verification with the cloud servers. Consider that the user U has the set of the privilege PU. It also used initializes a proof of ownership protocol, it is for the file ownership proof. The private cloud manage a table which is going to store every user's public information pkU and also its related privilege set PU.
File Uploading. In case owner of the data wants to upload or wants to share a file F . The owner required to contact with the private cloud before performing check for with the public cloud. The owner of the data file proves its identity with skU the private key. After passing the private cloud server will going to find out its respective PU privileges set of the user from its list of the stored table. User or the owner of the data file computes and then it sends the ϕF = TagGen(F) tag of the file to private server which then returns ϕFpT = TagGen(ϕF kpT ) to the user for all the values of pT . Then the user going to contact and send token { ϕ F pT } of the file to public cloud.
If in case a replicated data is found then the user is required to run the Proof of Ownership protocol along with public cloud to prove the ownership of its file. Suppose in case if the proof provided is passed then the user will be given a pointer to the file.
On the other hand suppose if no duplicate is found, a proof from cloud provider is returned, which will be a signature on {ϕ′F,pτ}, pkU and time stamp. The privilege set PF of the file and the proof send by the user to private server. After receiving request private cloud verifies the proof from the Cloud Storage Provider. When it is passed private cloud computes
{ϕ′F,pτ = TagGen(ϕFk,pτ )} for all pτ while satisfying R(p,pτ) = 1 and also p ∈ PF. At the end, user then computes the encrypted file Cf = EncCE(kF,F) with the convergent key kF = KeyGenCE(F) and then uploads {Cf,{ϕ′Fpτ}} with privilege PF.
Retrieving File. If a user wants to download file F. It initially Required to login into the system with all its credentials and privilege key and send a request and the file name to the Cloud Storage Provider. On receiving the request and file name, the Cloud Storage Provider checks whether the user is eligible to download F. If the user fails, the Cloud Storage Provider will send an cancel signal to user to indicate that the download is not completed. Otherwise, the Cloud Provider returns the related ciphertext Cf. After receiving encrypted data from the Cloud Provider, user use the key kF in oreder to recover the original file F.
C. Advantages of System
1) Users are permitted to perform check for the duplicate files marked with the related privileges.
2) It also handles the challenge of cloud storage services to maintenance of the increasing volume of data in the storage server.
3) This technique provides a complex way to have support for stronger security to the files by encrypting it with differential privilege keys.
4) It Allows Deduplication to be done by only Authorized users.
5) Since Deduplication is performed it increases Storage capacity of the servers and reduces bandwidth to transfer data.
6) Confidentiality is provided to data in the cloud.
V. Future Work
Applying Block Level Deduplication- The above given system uses file level deduplication to deduplicate data, According to the survey from the other different system block level deduplication provides higher level extra storage capacity since each chunk of data is being verified and being checked for the duplicate since even chunks/blocks from the different data can be identical this results in higher level of deduplication.
source based duplicate at the client or the user side, if duplicate is found then no data will be send and pointer will get provided and if no duplicate is found then data is transferred this way will can save network bandwidth.
Sending fake data to avoid network monitoring attack- As questions may arise that deduplication at the source may leads to network monitoring attacks as attackers regularity monitors the networks whether data is being sent or not through network channels. if no data is sent then they can predict that the users data is already present in the storage server. To avoid this a face data can be sent through a automated program at the user/client side if the duplicate is found and after reaching at the destination it will get automatically deleted using some automated deletion program of the fake data at the server side. this keep attacker in the misconception that some data is being sent from the server which means its data its data is not already stored in the server it is new data. This method can avoid network monitoring attack and removes drawback from the source based deduplication and improves the bandwidth.
VI. CONCLUSION
In this paper we have addressed the ever increasing data over the cloud storage infrastructure and showed how to manage this by using Deduplication Technique. We also addressed varies Deduplication techniques their drawbacks and some confidentiality problems in that. Here in this paper we are presenting a hybrid cloud approach which is more secure than the previous ones, using this twin cloud approach we are able to provide authorized and secured data deduplication.
VII. SCREENSHOTS
Fig. 7. Screenshot of Public cloud/Admin Login Page
Fig. 8. Screenshot of Private cloud Login Page
Fig. 9. Private cloud Activate or Deactivate users
Fig. 10. Provide cloud provides Access rights to the users
Fig. 12. Users have to enters unique token generated by Public cloud while login
Fig. 13. User Uploads the file
Fig. 14. Duplicate file exists so the current file is not uploaded
REFERENCES
[1] M. Bellare, S. Keelveedhi, and T. Ristenpart. Message-locked encryption and secure deduplication. In EUROCRYPT, pages296– 312, 2013.
[2] J. R. Douceur, A. Adya, W. J. Bolosky, D. Simon, and M. Theimer. Reclaiming space from duplicate files in a serverless distributed file system. In ICDCS, pages 617–624, 2002.
[3] S. Halevi, D. Harnik, B. Pinkas, and A. Shulman-Peleg. Proofs of ownership in remote storage systems. In Y. Chen, G. Danezis, and V. Shmatikov, editors, ACM Conference on Computer and Communications Security, pages 491–500. ACM, 2011.
[4] D. Ferraiolo and R. Kuhn. Role-based access controls. In 15th NIST-NCSC National Computer Security Conf., 1992.
[5] S. Quinlan and S. Dorward. Venti: a new approach to archival storage. In Proc. USENIX FAST, Jan 2002.
[6] R. S. Sandhu, E. J. Coyne, H. L. Feinstein, and C. E. Youman. Role-based access control models. IEEE Computer, 29:38–47, Feb 1996
[7] M. Bellare, C. Namprempre, and G. Neven. Security proofs for identity-based identification and signature schemes. J. Cryptology, 22(1):1–61, 2009.
[8] M. Bellare and A. Palacio. Gq and schnorr identification schemes: Proofs of security against impersonation under active and concurrent attacks. In CRYPTO, pages 162–177, 2002.
[9] M. Bellare, S. Keelveedhi, and T. Ristenpart. Dupless: Serveraided encryption for deduplicated storage. In USENIX Security Symposium, 2013.
[10] Divyesh Minjrola, Rakesh Rajani, “Optimal Authorized Data Deduplication”, In Cloud, Oct 2014.
[11] Ms. Madhuri A. Kavade, Prof. A.C.Lomte , “A Literature Survey On Secure De-Duplication Using Convergent Encryption Key Management”, Nov 2014.
[12] Jin Li, Xiaofeng Chen, Mingqiang Li, Jingwei Li, Patrick P.C. Lee, and Wenjing Lou, “Secure Deduplication with Efficient and Reliable Convergent Key Management”.
[13] Jin Li, Yan Kit Li, Xiaofeng Chen, Patrick P. C. Lee, Wenjing Lou, “A Hybrid Cloud Approach for Secure Authorized Deduplication”, 2014.
[14] Amit Harish Palange , Prof.Deepak Gupta, “Differential Privilege based Secure Authorized Deduplication Using Public Private Cloud”, 2014.
[15] Approach Boga Venkatesh, Anamika Sharma, Gaurav Desai, Dadaram Jadhav , “Secure Authorised Deduplication by Using Hybrid Cloud”, Nov 2014.
[16] Usha Dalvi, Sonali Kakade, Priyanka Mahadik, Arati Chavan, “A Secured and Authenticated Mechanism for Cloud Data Deduplication Using Hybrid Clouds”, Dec 2014.
[17] E.Mounika, P.Manvitha, U.Shalini, Mrs. K.Lakshmi, “A Hybrid Cloud Move Toward For Certified Deduplication”, Oct 2014.
[18] Application of Data Deduplication And Compression Techniques In Cloud Design Amrita Upadhyay,2011.
[19] Pasquale Puzio, Refik Molva , Melek Onen, Sergio Loureiro , “Block-level De-duplication with Encrypted Data”.
[20] Prajakta Patil, Mr. Anilkumar Warad, “A Survey on Data Deduplication Techniques”.
[21] Bhavanashri Shivaji Raut, Prof. H. A. Hingoliwala, “A Review of Secure Authorized Deduplication with Encrypted Data for Hybrid Cloud Storage”, 2015
[22] Pasquale Puzio, Refik Molva, Melek ¨Onen,Sergio Loureiro , “ClouDedup: Secure Deduplication with Encrypted Data for Cloud Storage”.
[23] Gaurav Kakariya, Prof. Sonali Rangdale, “A Hybrid Cloud Approach for Secure Authorized Deduplication”, 2014.